构建系统数据模型时,有2共选择,以:group->account->son account举例
1、系统由多个group组成;
2、一个group有多个account;
3、一个account有多个son account.
有2种数据模型构建方式选择;
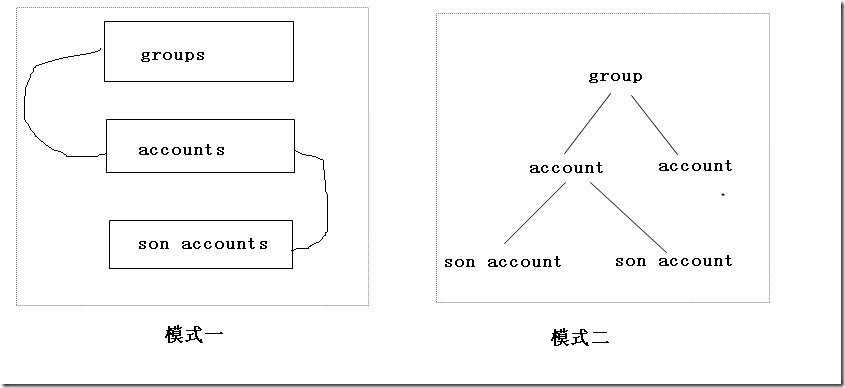
1、模式一的数据模型由3张表构成:groups表,accounts表,son accounts表。是浅层数据结构(结构型),每张表的深度是1。accounts表将有一个[group]字段关联到groups表里面的某条记录;son accounts表将有一个[account]字段关联到accounts表里面的某条记录。可以说这是一种经典的数据结构,结构型数据库就是由这样深度为1的二维型数据表构成,多张表之间的关系通过增加关联字段来标明;
2、模式二的数据模型中,把group视作一个整体,它是数据层的一个基本单元(unit),数据层由多个group对象组成,group对象的深度是3,是深层数据结构(聚合型)。现实的模型对应为对象型数据库;
现在的问题是:模式一简单还是模式二简单?哪一种是更为优越的选择?我倾向于模式一,因为:
1、结构型数据建模是经典的,目前依然是主流的,得到数据库的广泛支持,即使不使用数据库,也容易序列化到存储,并且我相信群众,相信主流意志的正确性;
2、模式二的对象型数据建模,group是数据元,是数据操作的唯一入口,所以需要提供account,son account的操作接口,account又需要提供son account的操作接口,假设对象深度再多增加几层,那这是一个庞大且累赘的冗余。另外一点是树形的对象不容易序列化,没有太多数据库支持;
3、模式二的层次太深,复杂度级数上升,违反了系统弱化成小类模型的原则(多个类,每个类的复杂度都很低),而这里,group将是一个很大的类。
4、第一感觉:模式一的复杂度我能控制,模式二就没有把握,所以心里更认同模式一;
5、虽然模式二直观的表明了数据的聚合-组合关系,与现实模型完全隐射,在理论上应该是更好的选择。但是就人的理解能力的倾向来说:我认为理解广度的事务比较理解深度的事务而言更有优势;
6、写到这里,我突然想说一句:化深度为广度,符合人的认知规律,降低了复杂度。