Lex 和 Yacc 是 Unix 和Linux 下词法和语法的分析,解析工具,有了这两个工具,你可以自己制作想要的编译器,也可以重新制作已有程序语言的解析器。需要注意的是linux下的这两个工具生成的程序源码只能是C和C++语言,当然现在早已有类似可以生成Java源码的语法分析器,如较常用的JavaCC(Java Compiler Compiler),相关内容可以去网上搜索。Lex和Yacc已被移植到windows下,现在常用的工具有Parser Generator。本文只介绍Linux 下Lex和Yacc的使用方法。
Lex介绍
Lex 通过对.lex或.l文件定义的格式生成一个C语言源码文件,通过编译这个源码,就生成了.lex文件或.l文件定义的编译器。.lex或.l文件的格式分三段:
1.全局变量声明部分
2.词法规则部分
3.函数定义部分
以下是一个简单的例子:lex_example.l文件
%{ //全局声明部分
/*林木100 linux
www.linmu100.com
*/
#include <stdio.h>
extern char *yytext;
extern FILE *yyin;
int sem_count = 0;
%}
//规则定义部分,
%%
[a-zA-Z][a-zA-Z0-9]* {printf("WORD[%s] ", yytext);}
[a-zA-Z0-9\/.-]+ printf("FILENAME ");
\" printf("QUOTE ");
\{ printf("OBRACE ");
\} printf("EBRACE ");
; {sem_count++; printf("SEMICOLON ");}
\n printf("\n");
[ \t]+ /* ignore whitespace */;
%%
//以下为函数定义部分
int main(int avgs, char *avgr[])
{
yyin = fopen(avgr[1], "r");
if (!yyin)
{
return 0;
}
yylex();
printf("sem_count : %d\n", sem_count);
fclose(yyin);
return 1;
}
Lex 常用格式如下表,常规表达式:
|
字符
|
含义
|
|
A-Z, 0-9, a-z
|
构成了部分模式的字符和数字。
|
|
.
|
匹配任意字符,除了 \n。
|
|
-
|
用来指定范围。例如:A-Z 指从 A 到 Z 之间的所有字符。
|
|
[ ]
|
一个字符集合。匹配括号内的任意 字符。如果第一个字符是 ^ 那么它表示否定模式。例如: [abC] 匹配 a, b, 和 C中的任何一个。
|
|
*
|
匹配0个或者多个上述的模式。
|
|
+
|
匹配1个或者多个上述模式。
|
|
?
|
匹配0个或1个上述模式。
|
|
$
|
作为模式的最后一个字符匹配一行的结尾。
|
|
{ }
|
指出一个模式可能出现的次数。 例如: A{1,3} 表示 A 可能出现1次或3次。
|
|
\
|
用来转义元字符。同样用来覆盖字符在此表中定义的特殊意义,只取字符的本意。
|
|
^
|
否定。
|
|
|
|
表达式间的逻辑或。
|
|
"<一些符号>"
|
字符的字面含义。元字符具有。
|
|
/
|
向前匹配。如果在匹配的模版中的“/”后跟有后续表达式,只匹配模版中“/”前面的部分。如:如果输入 A01,那么在模版 A0/1 中的 A0 是匹配的。
|
|
( )
|
将一系列常规表达式分组。
|
常规表达式举例
|
常规表达式
|
含义
|
|
joke[rs]
|
匹配 jokes 或 joker。
|
|
A{1,2}shis+
|
匹配 AAshis, Ashis, AAshi, Ashi。
|
|
(A[b-e])+
|
匹配在 A 出现位置后跟随的从 b 到 e 的所有字符中的 0 个或 1个。
|
使用lex扫描上述举例文件 lex_example.l:
lex lex_example.l
缺省会生成lex.yy.c文件,然后用gcc编译这个文件,注意要有-ll选项:
gcc lex.yy.c -o analyse -ll
这样就生成了一个简单的词法分析器analyse,假设有文件demo,其内容如下所示:
firstword;
secondword;
thirdword
fourthword{
fifthword
}
输入命令:
./analyse demo
会有如下显示:
WORD[firstword] SEMICOLON
WORD[secondword] SEMICOLON
WORD[thirdword]
WORD[fourthword] OBRACE
WORD[fifthword]
EBRACE
sem_count : 2
实际上,对于上述lex_example.l文件,函数定义部分可以完全省略,因为lex会自动为你生成main函数。这时仍然按上述方法生成analyse,输入命令:
./analse < demo
结果如下:
WORD[firstword] SEMICOLON
WORD[secondword] SEMICOLON
WORD[thirdword]
WORD[fourthword] OBRACE
WORD[fifthword]
EBRACE
在上述lex_example.l文件中我们还使用了两个变量:
extern char *yytext;
extern FILE *yyin;
这两个变量是lex提供的外部借口,用户可以根据自己需要自己更改,lex提供了以下接口:
Lex 变量
|
yyin
|
FILE* 类型。 它指向 lexer 正在解析的当前文件。
|
|
yyout
|
FILE* 类型。 它指向记录 lexer 输出的位置。 缺省情况下,yyin 和 yyout 都指向标准输入和输出。
|
|
yytext
|
匹配模式的文本存储在这一变量中(char*)。
|
|
yyleng
|
给出匹配模式的长度。
|
|
yylineno
|
提供当前的行数信息。(lexer不一定支持。)
|
Lex 函数
|
yylex()
|
这一函数开始分析。 它由 Lex 自动生成。
|
|
yywrap()
|
这 一函数在文件(或输入)的末尾调用。如果函数的返回值是1,就停止解析。 因此它可以用来解析多个文件。代码可以写在第三段,这就能够解析多个文件。 方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。最后,yywrap() 可以返回 1 来表示解析的结束。
|
|
yyless(int n)
|
这一函数可以用来送回除了前憂? 个字符外的所有读出标记。
|
|
yymore()
|
这一函数告诉 Lexer 将下一个标记附加到当前标记后。
|
以下是一个计算字符个数的.l文件内容,有兴趣的朋友可以编译试试
%{
/*
林木100 linux
www.linmu100.com
*/
int wc = 0; /* word count */
%}
%%
[a-zA-Z]+ { wc++; }
\n|. { /* gobble up */ }
%%
int main(void)
{
int n = yylex();
return n;
}
int yywrap(void)
{
printf("word count: %d\n", wc);
return 1;
}
yacc介绍
Yacc 是 Yet Another Compiler Compiler的缩写。 Yacc 的 GNU 版叫做 Bison。它是一种语法解析工具。它用巴科斯范式(BNF, Backus Naur Form)来书写。按照惯例,Yacc 文件有 .y 后缀。
实际上,yacc才是真正分析语法的核心,.y文件格式和.l文件一样分三段,但每一段的意义有所不同:
1.全局变量声明,终结符号(终端符号)声明
2.语法定义
3.函数定义
以下是一个简单的yacc_example.y文件,定义了一个简单的计算器:
%{
//全局变量声明
#include <ctype.h>
#include <stdio.h>
#define YYSTYPE double /*double type for YACC stack; for yylval*/
/*林木100 www.linmu100.com */
void yyerror(const char *str)
{
fprintf(stderr, "error:%s\n", str );
}
%}
//终结符声明
%token NUMBER
%%
lines : lines expr '\n' { printf("%g\n", $2); }
| lines '\n'
| /* e */
| error '\n' { yyerror("reenter last line:"); /*yyerrok(); */}
;
expr : expr '+' term { $$ = $1 + $3; }
| expr '-' term { $$ = $1 - $3; }
| term
;
term : term '*' factor { $$ = $1 * $3; }
| term '/' factor { $$ = $1 / $3; }
| factor
;
factor : '(' expr ')' { $$ = $2; }
| '(' expr error { $$ = $2; yyerror("missing ')'"); /*yyerrok(); */}
| '-' factor { $$ = -$2; }
| NUMBER
;
%%
//以上部分为语法定义,以下部分为函数定义
int main(void)
{
return yyparse();
}
int yylex(void)
{
int c;
while ((c = getchar()) == ' ');
if (c == '.' || isdigit(c)) {
ungetc(c, stdin);
scanf("%lf", &yylval);
return NUMBER;
}
return c;
}
使用yacc扫描这个文件:
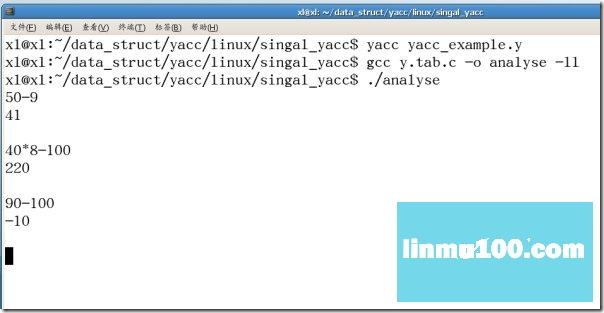
yacc yacc_example.y
缺省会生成一个y.tab.c文件,然后用gcc编译这个文件,注意要有选项 -ll 或 -ly:
gcc y.tab.c -o analyse -ll
运行./analyse:结果如下图所示:
现在对照yacc_example.y文件讲解一下.y文件的规则:
1.在全局变量声明部分,声明了一个接口函数yyerror,这个函数是用来在出错时调用的。这一段主要是声明一些变量,数据结构,函数用。
2.%token NUMBER则声明了一个终端符(终结符),这个符号是由Lex返回的,会在yacc语法规则中用到。
3.语法规则部分则声明了语法:
3.1语法规则对外只有一个接口,这一点要注意,初学者常常会犯语法对外有多个接口的错误。
3.2无论是lex文件还是yacc文件都要注意最大可能性的词法和语法规则要放在冲突规则的前面,这样保证了最大可能规则会被最先匹配,比如lex文件中:
temperator return T1;
temp return T2;
在yacc文件中,例子如下
command:
NUMBER CHAR
| NUMBER
;
对于.y文件还要注意全局语法,以及递归的调用。
初学者对于yacc文件规则可能会较为生疏,关键还要多做一些练习。
Lex 和 Yacc 的结合
lex和yacc结合时需要注意的是
lex文件头要引用yacc生成的头文件:"y.tab.h"
以下是一个lex和yacc结合的实例:
lex_yacc_exp.l文件:
%{
/*林木100
www.linmu100.com
*/
#include <stdio.h>
#include <string.h>
#include "y.tab.h"
extern char *yytext;
%}
%%
[0-9]+ yylval.number=atoi(yytext); return NUMBER;
heater return TOKHEATER;
heat return TOKHEAT;
on|off yylval.number=!strcmp(yytext,"on"); return STATE;
target return TOKTARGET;
temperature return TOKTEMPERATURE;
[a-z0-9]+ yylval.string=strdup(yytext);return WORD;
\n /* ignore end of line */;
[ \t]+ /* ignore whitespace */;
%%
lex_yacc_exp.y文件:
%{
/*林木100
www.linmu100.com
*/
#include <stdio.h>
#include <string.h>
void yyerror(const char *str)
{
fprintf(stderr,"error: %s\n",str);
}
int yywrap()
{
return 1;
}
main()
{
yyparse();
}
char *heater="xl's test";
%}
%token TOKHEATER TOKHEAT TOKTARGET TOKTEMPERATURE
%union
{
int number;
char *string;
}
%token <number> STATE
%token <number> NUMBER
%token <string> WORD
%%
commands:
| commands command
;
command:
heat_switch | target_set | heater_select
heat_switch:
TOKHEAT STATE
{
if($2)
printf("\tHeater '%s' turned on\n", heater);
else
printf("\tHeat '%s' turned off\n", heater);
}
;
target_set:
TOKTARGET TOKTEMPERATURE NUMBER
{
printf("\tHeater '%s' temperature set to %d\n",heater, $3);
}
;
heater_select:
TOKHEATER WORD
{
printf("\tSelected heater '%s'\n",$2);
heater=$2;
}
;
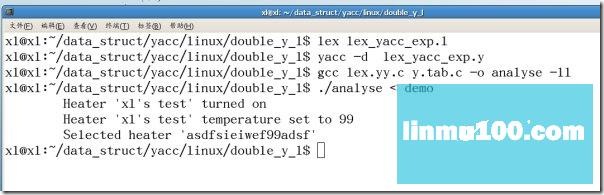
输入以下命令,分别生成lex.yy.c,y.tab.c,y.tab.h三个文件:
lex lex_yacc_exp.l
yacc -d lex_yacc_exp.y
gcc lex.yy.c y.tab.c -o analyse -ll
创建一个语法用例demo,内容如下:
heat on
target temperature 99
heater asdfsieiwef99adsf
输入./analyse <demo分析demo文件,会得到以下结果:
结语:
Lex 和 Yacc 是很强大的工具,这里只简单介绍了一些入门知识。
The Lex & Yacc Page 中有很多有趣的历史参考,以及 非常好的 lex 和 yacc 文档。
参考文档:
http://www.ibm.com/developerworks/cn/linux/l-lexyac.html
http://blog.csdn.net/ThinkinginLinux/archive/2005/03/19/323379.aspx
/
/*-----Lex & Yacc ----www.linmu100.com ----*/
/
/*-----linux工具,Lex & Yacc,基本操作----*/
/
/*-----linux配置,UNIX,开源软件,linux技术,makefile----*/
/
/*----------------------@xiaolin--------------------*/
/