由于traceroute只能诊断UDP通信的包路由,不能确定TCP通信的实际路由(可能变换),因此编写了本文。为方便描述,下面的IP、MAC和端口均为示例,实际诊断中可更换为具体的值
1. 如何判断客户端到服务器的TCP包,是否经过了网关
在客户端执行 tcpdump -i eno16777728 ether dst b0:b9:8a:69:65:3e and host 192.168.0.26 and tcp port 80 抓取经过网关且往返服务器的TCP端口为80的包
eno16777728 接口名称;ether 以太网链路,dst 目标(src表示源);b0:b9:8a:69:65:3e 网关MAC地址;192.168.0.26 服务器IP地址,80 监听端口
输出结果分析
● 有输出,则表示经过了网关
● 有部分输出而TCP通信还在进行,则表示先前的包经过了网关,后来路由表项缓存被重定向更新,没经过网关了
● 不断输出,则表示一直经过网关
2. 如何判断路由表项缓存被重定向更新
在客户端执行 tcpdump -i eno16777728 src 192.168.1.1 and dst 192.168.1.45 and icmp 抓取来自网关和到达客户端的所有icmp包
192.168.1.1 网关IP;192.168.1.45 客户端(出口)IP
输出结果分析
● 没有输出,则表示没有收到rerdirect包,路由表项缓存不变
● 有输出类似ICMP redirect 192.168.0.26 to host 192.168.0.26(前面一个IP表示到达服务器的直接路由IP,后一个表示服务器IP)
● 则表示收到了ICMP重定向包,内核会更新路由表项及缓存网关为192.168.0.26,下次通信时就直接发往192.168.0.26了
3. 如何控制接收ICMP重定向
● echo 0 | tee /proc/sys/net/ipv4/conf/*/accept_redirects 禁止所有网卡接收,可避免路由表项缓存被修改
● echo 1 | tee /proc/sys/net/ipv4/conf/*/accept_redirects 启用所有网卡接收ICMP重定向消息
4. 查看、刷新路由表项缓存
● ip route get 192.168.0.26 可以从输出中看到通住目标IP的实际路由
● ip route flush cache 清空路由表项缓存,下次通信时内核会查main表(即命令route输出的表)以确定路由
posted @
2017-12-29 17:24 春秋十二月 阅读(2047) |
评论 (0) |
编辑 收藏
近期有机会,深入了SSL/TLS协议原理与细节,并分析了相关密码学内容,心得颇多,历经半月,终于写成了这份文档。
本人水平尚有限,错误难免,欢迎指正,不胜感激。
目录
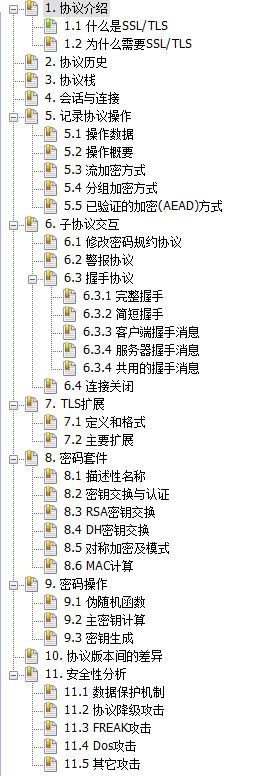
部分章节预览
第3章
第5章第4节
第11章第3节
全文
下载地址:
深入理解SSL/TLS技术内幕
posted @
2016-12-15 17:16 春秋十二月 阅读(1718) |
评论 (0) |
编辑 收藏
【公开密钥】
p是512到1024位的素数
q是160位长,并与p-1互素的因子
g = h^((p-1)/q) mod p,其中h<p-1且g>1
y = g^x mod p
【私有密钥】
x < q,长160位
【签名】
k为小于q的随机数,k^-1为k模q的逆元,m为消息,H为单向散列函数
r = (g^k mod p) mod q
s = (k^-1(H(m)+xr)) mod q
【验证】
w = s^-1 mod q
u1 = (H(m)w) mod q
u2 = (rw) mod q
v = ((g^u1 * y^u2) mod p) mod q
若v = r,则签名被验证
验签推导
1. 先证明两个中间结论
因(h,p)=1(p为素数且h<p,(a1,a1)是数论中的符号,记为a1与a2的最大公约数),故依费马小定理有h^(p-1)=1 mod p,则对任意整数n,有
g^(nq) mod p = (h^((p-1)/q))^(nq) mod p
= h^(n(p-1)) mod p
= (h^(p-1) mod p)^n mod p
= (1^n) mod p = 1 (1)
对任意整数t、n,可表示为t=nq+z,其中z>0,则有
g^t mod p = g^(nq+z) mod p
= (g^(nq) mod p * (g^z mod p)) mod p
= g^z mod p
= g^(t mod q) mod p (2)
2. 再假设签名{r,s}和消息m均没被修改,令H(m)=h,开始推导v
v = ((g^u1 * y^u2) mod p) mod q
= (g^(hw mod q) * ((g^x mod p)^(rw mod q) mod p)) mod q
= ((g^(hw mod q) mod p * ((g^x mod p)^(rw mod q) mod p)) mod p) mod q
= ((g^(hw mod q) mod p * (g^(x * (rw mod q)) mod p)) mod p) mod q
= ((g^(hw) mod p * ((g^(rw mod q) mod p)^x mod p)) mod p) mod q
= ((g^(hw) mod p * ((g^(rw) mod p)^x mod p)) mod p) mod q
= ((g^(hw) mod p * (g^(rwx) mod p)) mod p) mod q
= (g^(hw+rwx) mod p) mod q
= (g^((h+rx)w) mod p) mod q (3)
又因w = s^-1 mod q
故(sw) mod q = 1
=>(((k^-1(h+xr)) mod q)w) mod q = 1
=>((k^-1(h+xr))w) mod q = 1
=>(h+xr)w = k mod q (4)
将(4)式代入(3)式中得
v = (g^(k mod q) mod p) mod q
= (g^k mod p) mod q
= r
3. 最后由(4)式知,若h、r和s任一个有变化(s变化导致w变化),则v ≠ r
posted @
2016-11-24 19:39 春秋十二月 阅读(5484) |
评论 (0) |
编辑 收藏
随机选择两个大的素数 p、q ,且p ≠ q,计算n = pq、r = (p-1)(q-1),依欧拉定理,r即为与n互质的素数个数;选择一个小于r的整数e(即加密指数),求得e关于模r的逆元d(即解密指数),则{n,e}为公钥、{n,d}为私钥;根据模的逆元性质有ed ≡ 1 (mod r);设m为明文,则加密运算为m^e ≡ c (mod n), c即为密文;则解密过程 c^d ≡ m (mod n)。
证明会用到费马小定理,即
若y为素数且x不为y的倍数, 则 x^(y-1) ≡ 1 (mod y)(费马小定理的证明需先证明欧拉定理,此处略)。符号≡表示同余,^表示
幂,|表示整除,*表示相乘。
算法证明
第一种证明途径
因 ed ≡ 1 (mod (p-1)(q-1)),令 ed = k(p-1)(q-1) + 1,其中 k 是整数
则 c^d = (m^e)^d = m^(ed) = m^(k(p-1)(q-1)+1)
1.若m不是p的倍数,也不是q的倍数
则 m^(p-1) ≡ 1 (mod p) (
费马小定理)
=> m^(k(p-1)(q-1)) ≡ 1 (mod p)
m^(q-1) ≡ 1 (mod q) (
费马小定理)
=> m^(k(p-1)(q-1)) ≡ 1 (mod q)
故 p、q 均能整除 m^(k(p-1)(q-1)) - 1
=> pq | m^(k(p-1)(q-1)) - 1
即 m^(k(p-1)(q-1)) ≡ 1 (mod pq)
=> m^(k(p-1)(q-1)+1) ≡ m (mod n)
2.若m是p的倍数,但不是q的倍数
则 m^(q-1) ≡ 1 (mod q) (
费马小定理)
=> m^(k(p-1)(q-1)) ≡ 1 (mod q)
=> m^(k(p-1)(q-1)+1) ≡ m (mod q)
因 p | m
=> m^(k(p-1)(q-1)+1) ≡ 0 (mod p)
=> m^(k(p-1)(q-1)+1) ≡ m (mod p)
故 m^(k(p-1)(q-1)+1) ≡ m (mod pq)
即 m^(k(p-1)(q-1)+1) ≡ m (mod n)
3.若m是q的倍数,但不是p的倍数,证明同上
4.若m同为p和q的倍数时
则 pq | m
=> m^(k(p-1)(q-1)+1) ≡ 0 (mod pq)
=> m^(k(p-1)(q-1)+1) ≡ m (mod pq)
即 m^(k(p-1)(q-1)+1) ≡ m (mod n)
第二种证明途径
先证明m^ed ≡ m (mod p)恒成立
1.若p为m的因子,则p | m^ed - m显然成立,即m^ed ≡ m (mod p)
2.若p不为m的因子,令ed = k(p-1)(q-1) + 1,则 m^(ed-1) - 1 = m^(k(p-1)(q-1)) - 1
m^(p-1) ≡ 1 (mod p) (
费马小定理)
=> m^(k(p-1)) ≡ 1 (mod p)
=> m^(k(p-1)(q-1)) ≡ 1 (mod p)
=> m^(ed-1) ≡ 1 (mod p)
=> m^ed ≡ m (mod p)
同理可证m^ed ≡ m (mod q)
故m^ed ≡ m (mod pq),即m^ed ≡ m (mod n)
又因 c^d = m^e^d = m^(ed)
故 c^d ≡ m (mod n),证毕
总结
第二种比第一种简单直观,以上证明途径对RSA私钥签名与验签同样适合。
posted @
2016-11-18 17:05 春秋十二月 阅读(2717) |
评论 (0) |
编辑 收藏 由于很多应用项目依赖诸多第三方开源库,这些开源库各有不同的核心目录、库目标和输出位置,这里的核心目录是指
仅产生so库的工程目录,库目标是指
仅产生so库的make目标,输出位置是相对于核心目录的,但不必是子目录,可用..来回溯到父目录的某位置,更高层目录的位置,依次类推。为了统一支持它们,使用了一些技巧,详见示例脚本如下
1 .PHONY: all clean lib core
.PHONY: all clean lib core
2
3thirdlib=openssl-1.0.1u?build_ssl ACE_wrappers/ace json ncurses-6.0??lib
4coremod=main
5
6dir = `echo $@ | awk -F? '{print $$1}'`
7aim = `echo $@ | awk -F? '{print $$2}'`
8out = `echo $@ | awk -F? '{print $$3}'`
9
10copy=\cp -Pf ${dir}/${out}/*.so* output
11
12define MAKE_SUBDIR
13echo "${dir},${aim},${out}"; \
14if [ "$(MAKECMDGOALS)" != "clean" ]; then \
15$(MAKE) ${aim} -C ${dir}; \
16if [ "$$is_cp" -eq "1" ]; then \
17$(copy); \
18fi \
19else \
20$(MAKE) clean -C ${dir}; \
21fi
22endef
23
24all: lib core
25
26lib: $(thirdlib)
27
28$(thirdlib)::
29 @is_cp=1; $(MAKE_SUBDIR)
30
31core: $(coremod)
32
33$(coremod)::
34 @is_cp=0; $(MAKE_SUBDIR)
35
36clean: $(thirdlib) $(coremod) 实现技巧 1)使用?作为分隔符,所分隔的3个域依次为核心目录、库目标、输出位置;使用awk来获取各域,分别为dir、aim和out;在运行过程中,值dir一定非空,而aim为空则表示默认目标,out为空表示输出位置即为dir目录。
2)copy为命令变量,功能为每当一个库编译完成后,将输出的so库拷贝到output下,并保持软链接;对于有的开源库,需在编译前,使用对应的选项来调用configure,使其生成so库。
3)为了重用代码,定义了MAKE_SUBDIR命令包,参数变量为is_cp,当is_cp为1时,表示当前编译的是依赖库,否则是主程序。
4)thirdlib和coremod为依赖文件,使用了双冒号规则,这样一来,只要在thirdlib中加入新的依赖库,指定核心目录、库目标和输出位置即可,其它地方不用改。
posted @
2016-10-19 15:11 春秋十二月 阅读(3301) |
评论 (0) |
编辑 收藏脚本概述 当需要在很多(比如几十至几百)台机器上编译同一程序时,如果一个个地手工拷贝源码、再编译,那么效率就很低,为了能大量节省手工、并行地编译,因此写了一个脚本,该脚本基于自动化脚本语言expect(expect基于tcl)实现,基本原理是针对每个远程主机,创建一个子进程,在该子进程内先调用scp拷贝源码到远程主机,再用ssh登录到远程主机、发送cd、configure和make命令,交互期间的命令输出多用正则分析,最终的编译输出保存到当前目录output子目录下。其命令行参数说明如下:
● 第1参数为远程主机配置文件:一个多行文本文件,每行格式为IP 用户名 密码,空格符分隔,支持#注释。
● 第2参数为本地主机源码目录:要求该目录存在Makefile和configure文件。
● 第3参数为远程主机目标目录:用于存放源码的位置。
脚本实现 拷贝源码
1proc copy_file {host user srcdir dstdir passwd {to 10} } {
2 if [catch "spawn scp -rq $srcdir $user@$host:$dstdir" msg] {
3 send_error "failed to spawn scp: $msg\n"
4 exit 1
5 }
6
7 set timeout $to
8 expect_after eof {
9 send_error "$host scp died unexpectedly\n"
10 exit 1
11 }
12 expect {
13 "(yes/no)?" { send "yes\r"; exp_continue }
14 -re "(?:P|p)assword:" { send "$passwd\r" }
15 timeout { do_timeout "$host scp" }
16 }
17
18 expect {
19 full_buffer { exp_continue }
20 timeout { exp_continue }
21 eof
22 }
23}
第2行调用spawn命令执行scp命令,并用catch捕捉错误;当执行成功后,第12行用expect等待远端输出(超时默认为10秒),第13、14行自动输入用户名和密码,当过程中网络连接断开时,会匹配到第8行的eof;当输出完成连接关闭时,会匹配到第21行的eof;如果输出太多超过expect内部的buffer时,会匹配到第19行的full_buffer,这里由于为了提高效率,使用了静默方式的scp,因些实际会匹配到第20行的timeout,不管匹配到哪种情况,都要继续直到eof。
执行编译
1proc do_make {host user passwd subdir {to 10} } {
2 if [catch {spawn ssh $user@$host} msg ] {
3 send_error "failed to spawn ssh: $msg\n"
4 exit 1
5 }
6
7 set timeout $to
8 expect_after eof {
9 send_error "$host ssh died unexpectedly\n"
10 exit 1
11 }
12
13 expect {
14 "*yes/no" { send "yes\r"; exp_continue }
15 -re "(?:P|p)assword:" { send "$passwd\r" }
16 timeout { do_timeout "$host ssh" }
17 }
18 wait_cmd $spawn_id passwd
19
20 send "cd $subdir\r"
21 wait_cmd $spawn_id cd
22
23 send "source configure\r"
24 wait_cmd $spawn_id configure
25
26 send "make\r"
27 wait_cmd $spawn_id make
28
29 send "exit\r"
30 expect eof
31}
关于spawn和expect的解释与上节
拷贝源码相同,不同的是依次发送命令cd、source configure、make,每个命令须等到命令提示符后(调用自定义函数wait_cmd)再发下一个,最后发送exit退出ssh、导致连接关闭,匹配到最后一行的eof。对于有的项目源码,可能没有或不用配置,那么configure文件可以不存在或内容为空,如果不存在导致报错也没关系,不影响make;如果configure出错,那么make也会出错。这里使用source是为了使配置在当前shell中生效。
主循环
1set f [open $file r]
2set curtime [clock seconds]
3
4log_user 0
5set s {[:blank:]}
6set pattern "^(\[^#$s]+)\[$s]+(\[^$s]+)\[$s]+(\[^$s]+)"
7
8while { [gets $f line] != -1 } {
9 if { ![regexp $pattern [string trimleft $line] ? host user passwd] } {
10 continue
11 }
12 send_user "$host $user $passwd\n"
13 if { ![fork] } {
14
15 set filename output/${host}_[clock format $curtime -format %y.%m.%d_%H.%M.%S].log
16 log_file -noappend -a $filename
17
18 copy_file $host $user $srcdir $dstdir $passwd 30
19 do_make $host $user $passwd $subdir 30
20
21 send_user "$host finish\n"
22 exit
23 }
24}
打开远程主机配置文件,读取每一行直到文件尾,忽略注释行,用正则提取IP、用户名和密码,创建子进程,按IP和当前时间命名log文件(由于前面调用log_user 0关闭了控制台输出,因此为了能记录输出到日志文件,一定要加-a选项),最后调用函数copy_file和do_make。
完整脚本下载:
autobuild.zipposted @
2016-09-28 11:04 春秋十二月 阅读(3915) |
评论 (0) |
编辑 收藏
云查杀平台以nginx作为反向代理服务器,作为安全终端与云查询服务的桥梁。当安全终端需要查询黑文件时,HTTP请求及其响应都会经过nginx,为了获取并统计一天24小时查询的黑文件数量,就得先截获经过nginx的HTTP响应,再做数据分析。截获HTTP数据流有多种方法,为了简单高效,这里使用了挂接HTTP过滤模块的方法,另外为了不影响nginx本身的IO处理,将HTTP响应实体发送到另一个进程即统计服务,由统计服务来接收并分析HTTP响应,架构如下图
统计服务由1个接收线程和1个存储线程构成,其中接收线程负责接收从nginx过滤模块发来的HTTP响应实体,解析它并提取黑文件MD5,加入共享环形队列;而存储线程从共享环形队列移出黑文件MD5,插入到临时内存映射文件,于每天定时同步到磁盘文件。
特点
这种架构减少了nginx IO延迟,保证了nginx的稳定高效运行,从而不影响用户的业务运行;本地连接为非阻塞的,支持了统计服务的独立运行与升级。
实现
nginx过滤模块
该流程运行在nginx工作进程。
由于nginx采用了异步IO机制,因此仅当截获到HTTP响应实体也就是有数据经过时,才有后面的操作;若没有数据,则什么也不用做。这里每次发送前先判断是否连接了统计服务,是为了支持统计服务的独立运行与升级,换句话说,不管统计服务是否运行或崩溃,都不影响nginx的运行。
统计服务
接收线程
这里的接收线程也就是主线程。
存储线程
存储线程为另一个工作线程。
同步文件定时器的时间间隔要比新建文件定时器的短,由于定时器到期的事件处理是一种异步执行流,所以将它们当做并行,与“从q头移出黑文件MD5”操作画在了同一水平方向。
posted @
2016-08-25 11:10 春秋十二月 阅读(1171) |
评论 (0) |
编辑 收藏
拦截Linux动态库API的常规方法,是基于动态符号链接覆盖技术实现的,基本步骤是
1. 重命名要拦截的目标动态库。
2. 创建新的同名动态库,定义要拦截的同名API,在API内部调用原动态库对应的API。这里的同名是指与重命名前动态库前的名称相同。
显而易见,如果要拦截多个不同动态库中的API,那么必须创建多个对应的同名动态库,这样一来不仅繁琐低效,还必须被优先链接到客户二进制程序中(根据动态库链接原理,对重复ABI符号的处理是选择优先链接的那个动态库)。 另外在钩子函数的实现中,若某调用链调用到了原API,则会引起死循环而崩溃。本方法通过直接修改ELF文件中的动态库API入口表项,解决了常规方法的上述问题。
特点
1. 不依赖于动态库链接顺序。
2. 能拦截多个不同动态库中的多个API。
3. 支持运行时动态链接的拦截。
4. 钩子函数内的实现体,若调用到原API,则不会死循环。
实现
拦截映射表
为了支持特点2和3,建立了一个拦截映射表,这个映射表有2级。第1级为ELF文件到它的API钩子映射表,键为ELF文件句柄,值为API钩子映射表;第2级为API到它的钩子函数映射表,键为API名称,值为包含最老原函数地址和最新钩子函数地址的结构体,如下图
当最先打开ELF文件成功时,会在第1级映射表中插入记录;反之当最后关闭同一ELF文件时,就会从中移除对应的记录。当第一次挂钩动态库API时,就会在第2级映射表插入记录;反之卸钩同一API时,就会从中删除对应的记录。
计算ELF文件的映像基地址
计算映像基地址是为了得到ELF中动态符号表和重定位链接过程表的内容,因为这些表的位置都是相对于基地址的偏移量,该算法在打开ELF文件时执行,如下图
EXE文件为可执行文件,DYN文件为动态库。对于可执行文件,映射基地址为可执行装载段的虚拟地址;对于动态库,可通过任一API的地址减去它的偏移量得到,任一API的地址可通过调用libdl.so库API dlsym得到,偏移量通过查询动态链接符号表得到。
打开ELF文件
为了支持特点2即拦截不同动态库的多个API,节省每次挂钩API前要打开并读文件的开销,独立提供了打开ELF文件的接口操作,流程如下图
若输入ELF文件名为空,则表示打开当前进程的可执行文件,此时要从伪文件系统/proc/self/exe读取文件路径名,以正确调用系统调用open。当同一ELF文件被多次打开时,只须递增结构elf的引用计数。
挂钩API
当打开ELF文件后,就可挂钩API了,流程如下图
当第一次挂钩时,需要保存原函数以供后面卸钩;第二次以后继续挂钩同一API时,更新钩子函数,但原函数不变。
卸钩API
当打开ELF文件后,就可卸钩API了,流程如下图
关闭ELF文件
因为提供了打开ELF文件的接口操作,所以得配有关闭ELF文件的接口操作。当不需要挂钩API的时候,就可以关闭ELF文件了,流程如下图
运行时动态拦截装置
在初始化模块中打开当前可执行文件,挂钩libdl.so库的API dlopen和dlsym;在转换模块中,按动态库句柄和API名称在拦截映射表中查找钩子函数,若找到则返回钩子函数,否则返回调用dlsym的结果;在销毁模块中,卸钩dlopen和dlsym。
当动态库被进程加载的时候,会调用初始化模块;当被进程卸载或进程退出的时候,会调用销毁模块;当通过dlsym调用API时,则会在dlsym的钩子函数中调用转换模块。通过环境变量LD_PRELOAD将动态库libhookapi.so设为预加载库,这样就能拦截到所有进程对dlopen及dlsym的调用,进而拦截到已挂钩动态库API的调用。
posted @
2016-08-25 11:10 春秋十二月 阅读(2378) |
评论 (0) |
编辑 收藏
本方法适用于linux 2.6.x内核。
1. 先获取dentry所属文件系统对应的挂载点,基本原理是遍历文件系统vfsmount树,找到与dentry有相同超级块的vfsmount,实现如下
next_mnt函数实现了
先根遍历法,遍历以root为根的文件系统挂载点,p为遍历过程中的当前结点,返回p的下一个挂载点;vfsmnt_lock可通过内核函数kallsyms_on_each_symbol或kallsyms_lookup_name查找获得。
2. 再调用内核函数d_path,接口封装如下
posted @
2016-08-24 19:22 春秋十二月 阅读(5971) |
评论 (0) |
编辑 收藏
原始套接字具有广泛的用途,特别是用于自定义协议(标准协议TCP、UDP和ICMP等外)的数据收发。在Linux下拦截套接字IO的一般方法是拦截对应的套接字系统调用,对于发送为sendmsg和sendto,对于接收为recvmsg和recvfrom。这种方法虽然也能拦截原始套接字IO,但要先判断套接字的类型,如果为SOCK_RAW(原始套接字类型),那么进行拦截处理,这样一来由于每次IO都要判断套接字类型,性能就比较低了。因此为了直接针对原始套接字来拦截,提高性能,发明了本方法。
本方法可用于防火墙或主机防护系统中,丢弃接收和发送的攻击或病毒数据包。
特点
运行在内核态,直接拦截所有进程的原始套接字IO,支持IPv4和IPv6。
实现
原理
在Linux内核网络子系统中,struct proto_ops结构提供了协议无关的套接字层到协议相关的传输层的转接,而IPv4协议族中内置的inet_sockraw_ops为它的一个实例,对应着原始套接字。因此先找到inet_sockraw_ops,再替换它的成员函数指针recvmsg和sendmsg,就可以实现拦截了。下面以IPv4为例(IPv6同理),说明几个流程。
搜索inet_sockraw_ops
该流程在挂钩IO前进行。由于inet_sockraw_ops为Linux内核未导出的内部符号,因此需要通过特别的方法找到它,该特别的方法基于这样的一个事实:
◆ 所有原始套接字接口均存放在以SOCK_RAW为索引的双向循环链表中,而inet_sockraw_ops就在该链表的末尾。
◆ 内核提供了注册套接字接口的API inet_register_protosw,对于原始套接字类型,该API将输入的套接字接口插入到链表头后面。
算法如下
注册p前或注销p后,链表如下
注册p后,链表如下
挂钩IO
该流程在内核模块启动时进行。
卸钩IO
该流程在内核模块退出时进行。
运行部署
该方法实现在Linux内核模块中,为了防止其它内核模块可能也注册了原始套接字接口,因此需要在操作系统启动时优先加载。
posted @
2016-07-14 10:27 春秋十二月 阅读(2746) |
评论 (3) |
编辑 收藏