存储格式
Oracle Number数据类型是变长的,占0~22字节,不像编程语言中的2/4字节整数或4/8字节浮点数,关于它的存储格式与解析,DSI上有详细的描述,如下所示
 符号位/指数字节
符号位/指数字节描述如下
 数字字节
数字字节描述如下
 正数或零值的计算
正数或零值的计算
 负数值的计算
负数值的计算
 解析实现
解析实现
由于Oracle Number的精度高达38位,远超出了基本定长整数或浮点数表达的数值范围,因此解析实际上是大整数/实数的四则运算,为避免造轮子,本文使用了
GMP开源库(
https://gmplib.org/),用于任意精度的算术运算,操作有符号整数、有理数和浮点数,除了在GMP机器上运行的可用内存所暗示的精度之外,对精度没有实际的限制。解析实现的核心函数是
orcl_raw2number
1 #include <stdio.h>
2 #include <assert.h>
3 #include <gmp.h>
4
5 #define MAX_PREC 256
6
7 static mpf_t s_base100;
8 static mpf_t s_one;
9
10 static void init_mpf_globals()
11 {
12 mpf_init_set_ui(s_base100, 100);
13 mpf_init_set_ui(s_one, 1);
14 }
15
16 static void clear_mpf_globals()
17 {
18 mpf_clear(s_base100);
19 mpf_clear(s_one);
20 }
21
22 static void orcl_raw2number(unsigned char *data, unsigned int len, mpf_t result)
23 {
24 unsigned int sign = *data, digit, i;
25 int exp = sign>=128 ? sign-193 : 62-sign;
26 int exp_val;
27 mpf_t tmp;
28
29 mpf_init2(tmp, MAX_PREC);
30 mpf_init2(result, MAX_PREC);
31
32 if(sign & 0x80){
33 for(i=1; i<len; ++i){
34 digit = data[i] - 1;
35 assert(0<=digit && digit<=99);
36
37 exp_val = exp - i + 1;
38 if(exp_val < 0){
39 mpf_pow_ui(tmp, s_base100, -exp_val);
40 mpf_div(tmp, s_one, tmp);
41 }else
42 mpf_pow_ui(tmp, s_base100, exp_val);
43
44 mpf_mul_ui(tmp, tmp, digit);
45 mpf_add(result, result, tmp);
46 }
47
48 }else{
49 --len; //ignore the last byte
50 for(i=1; i<len; ++i){
51 digit = 101 - data[i];
52 assert(0<=digit && digit<=99);
53
54 exp_val = exp - i + 1;
55 if(exp_val < 0){
56 mpf_pow_ui(tmp, s_base100, -exp_val);
57 mpf_div(tmp, s_one, tmp);
58 }else
59 mpf_pow_ui(tmp, s_base100, exp_val);
60
61 mpf_mul_ui(tmp, tmp, digit);
62 mpf_add(result, result, tmp);
63 }
64
65 mpf_neg(result, result);
66 }
67
68 mpf_clear(tmp);
69 }
测试用例
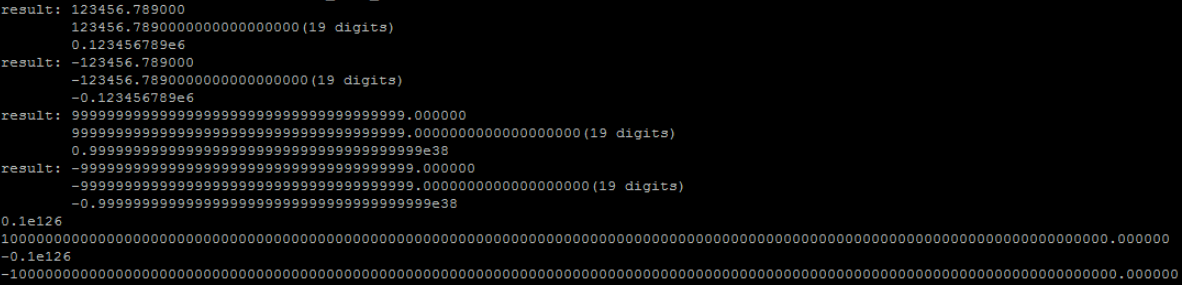
测试了123456.789、-123456.789、Oracle Number实际最大最小值、Oracle Number理论最大最小值
1 int main(int argc,
char *argv[])
2 {
3 int n = 19;
4 char buf[256];
5 mpf_t r;
6
7 init_mpf_globals();
8
9 //123456.789
10 unsigned
char data[] = {0xc3,0xd,0x23,0x39,0x4f,0x5b};
11 orcl_raw2number(data,
sizeof(data), r);
12 gmp_snprintf(buf,
sizeof(buf), "%Ff\n\t%.*Ff(%d digits)", r, n, r, n);
13 printf("result: %s\n", buf);
14 printf("\t"); mpf_out_str(NULL, 10, 0, r); printf("\n");
15 mpf_clear(r);
16
17 //-123456.789
18 unsigned
char data2[] = {0x3c,0x59,0x43,0x2d,0x17,0xb,0x66};
19 orcl_raw2number(data2,
sizeof(data2), r);
20 gmp_snprintf(buf,
sizeof(buf), "%Ff\n\t%.*Ff(%d digits)", r, n, r, n);
21 printf("result: %s\n", buf);
22 printf("\t"); mpf_out_str(NULL, 10, 0, r); printf("\n");
23 mpf_clear(r);
24
25 //0
26 unsigned
char zero[] = {0x80};
27 orcl_raw2number(zero,
sizeof(zero), r);
28 gmp_snprintf(buf,
sizeof(buf), "%Ff\n\t%.*Ff(%d digits)", r, n, r, n);
29 printf("result: %s\n", buf);
30 printf("\t"); mpf_out_str(NULL, 10, 0, r); printf("\n");
31 mpf_clear(r);
32
33 //test actual max value:9999 9(the number of 9 is 38)
9(the number of 9 is 38)
34 unsigned
char max_data[] = {0xd3,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64,0x64};
35 orcl_raw2number(max_data,
sizeof(max_data), r);
36 gmp_snprintf(buf,
sizeof(buf), "%Ff\n\t%.*Ff(%d digits)", r, n, r, n);
37 printf("result: %s\n", buf);
38 printf("\t"); mpf_out_str(NULL, 10, 0, r); printf("\n");
39 mpf_clear(r);
40
41 //test actual min value:-99999(the number of 9 is 38)
42 unsigned
char min_data[] = {0x2c,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x2,0x66};
43 orcl_raw2number(min_data,
sizeof(min_data), r);
44 gmp_snprintf(buf,
sizeof(buf), "%Ff\n\t%.*Ff(%d digits)", r, n, r, n);
45 printf("result: %s\n", buf);
46 printf("\t"); mpf_out_str(NULL, 10, 0, r); printf("\n");
47 mpf_clear(r);
48
49 clear_mpf_globals();
50
51 //test max oracle number value
52 mpf_init2(r, 256);
53
54 mpf_set_str(r, "1e125", 10);
55 mpf_out_str(NULL, 10, 0, r); printf("\n");
56 gmp_printf("%Ff\n", r);
57
58 //test min oracle number value
59 mpf_set_str(r, "-1e125", 10);
60 mpf_out_str(NULL, 10, 0, r); printf("\n");
61 gmp_printf("%Ff\n", r);
62
63 mpf_clear(r);
64
65 return 0;
66 }
输出如下
posted @
2020-05-08 12:23 春秋十二月 阅读(1016) |
评论 (0) |
编辑 收藏
选择ENet代替TCP用于弱网环境(通常丢包率高)的数据传输,提高可靠性及传输效率。为了说明怎样正确有效地应用ENet,本文按照TCP C/S同步通信的流程作了对应的接口封装实现,取库名为
rudp。
接口对照
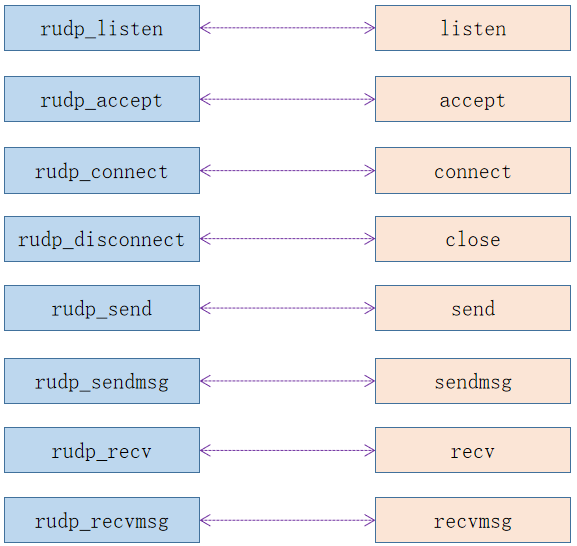
左边为rudp库的API,右边为标准的Berkeley套接字API。rudp库所有API前缀为rudp,rudp_listen和rudp_accept仅用于服务端,rudp_connect和rudp_disconnect仅用于客户端;其它接口共用于两端,其中rudp_send调用rudp_sendmsg实现,rudp_recv调用rudp_recvmsg实现。
具体实现
所有接口遵循Berkeley套接字接口的语义,为简单起见,错误描述输出到标准错误流。
◆
监听,成功返回0,失败返回-1
1 int rudp_listen(const char *ip, int port, ENetHost **host)
2 {
3 ENetAddress address;
4
5 if(!strcmp(ip, "*"))
6 ip = "0.0.0.0";
7
8 if(enet_address_set_host_ip(&address, ip)){
9 fprintf(stderr, "enet_address_set_host_ip %s fail", ip);
10 return -1;
11 }
12
13 address.port = port;
14
15 assert(host);
16 *host = enet_host_create(&address, 1, 1, 0, 0);
17 if(NULL==*host){
18 fprintf(stderr, "enet_host_create %s:%d fail", address.host, address.port);
19 return -1;
20 }
21
22 int size = 1024*1024*1024;
23 if(enet_socket_set_option((*host)->socket, ENET_SOCKOPT_RCVBUF, size)){
24 fprintf(stderr, "enet set server socket rcvbuf %d bytes fail", size);
25 }
26
27 return 0;
28 }
◆
接受连接,成功返回0,失败返回-1
1 int rudp_accept(ENetHost *host, unsigned int timeout, ENetPeer **peer)
2 {
3 int ret;
4 ENetEvent event;
5
6 ret = enet_host_service(host, &event, timeout);
7 if(ret > 0){
8 if(event.type != ENET_EVENT_TYPE_CONNECT){
9 if(event.type == ENET_EVENT_TYPE_RECEIVE)
10 enet_packet_destroy(event.packet);
11 fprintf(stderr, "enet_host_service event type %d is not connect", event.type);
12 return -1;
13 }
14
15 assert(peer);
16 *peer = event.peer;
17
18 }else if(0==ret){
19 fprintf(stderr, "enet_host_service timeout %d", timeout);
20 return -1;
21
22 }else{
23 fprintf(stderr, "enet_host_service fail");
24 return -1;
25 }
26
27 return 0;
28 }
◆
建立连接,成功返回0,失败返回-1,conn_timeout是连接超时,rw_timeout是收发超时,单位为毫秒
1 int rudp_connect(const char *srv_ip, int srv_port, unsigned int conn_timeout, unsigned int rw_timeout, ENetHost **host, ENetPeer **peer)
2 {
3 assert(host);
4 *host = enet_host_create(NULL, 1, 1, 0, 0);
5 if(NULL==*host){
6 fprintf(stderr, "enet_host_create fail");
7 goto fail;
8 }
9 if(enet_socket_set_option((*host)->socket, ENET_SOCKOPT_RCVBUF, 1024*1024*1024)){
10 fprintf(stderr, "enet set server socket rcvbuf 1M bytes fail");
11 }
12
13 ENetAddress srv_addr;
14 if(enet_address_set_host_ip(&srv_addr, srv_ip)){
15 fprintf(stderr, "enet_address_set_host_ip %s fail", srv_ip);
16 goto fail;
17 }
18 srv_addr.port = srv_port;
19
20 assert(peer);
21 *peer = enet_host_connect(*host, &srv_addr, 1, 0);
22 if(*peer==NULL){
23 fprintf(stderr, "enet_host_connect %s:%d fail", srv_ip, srv_port);
24 goto fail;
25 }
26
27 enet_peer_timeout(*peer, 0, rw_timeout, rw_timeout);
28
29 int cnt = 0;
30 ENetEvent event;
31
32 while(1){
33 ret = enet_host_service(*host, &event, 1);
34 if(ret == 0){
35 if(++cnt >= conn_timeout){
36 fprintf(stderr, "enet_host_service timeout %d", conn_timeout);
37 goto fail;
38 }
39
40 }else if(ret > 0){
41 if(event.type != ENET_EVENT_TYPE_CONNECT){
42 fprintf(stderr, "enet_host_service event type %d is not connect", event.type);
43 goto fail;
44 }
45 break; //connect successfully
46
47 }else{
48 fprintf(stderr, "enet_host_service fail");
49 goto fail;
50 }
51 }
52
53 #ifdef _DEBUG
54 char local_ip[16], foreign_ip[16];
55 ENetAddress local_addr;
56
57 enet_socket_get_address((*host)->socket, &local_addr);
58 enet_address_get_host_ip(&local_addr, local_ip, sizeof(local_ip));
59 enet_address_get_host_ip(&(*peer)->address, foreign_ip, sizeof(foreign_ip));
60
61 printf("%s:%d connected to %s:%d", local_ip, loca_addr.port, foreign_ip, (*peer)->address.port);
62 #endif
63
64 return 0;
65
66 fail:
67 if(*host) enet_host_destroy(*host);
68 return -1;
69 }
◆
断开连接,若成功则返回0,超时返回1,出错返回-1。先进行优雅关闭,如失败再强制关闭
1 int rudp_disconnect(ENetHost *host, ENetPeer *peer)
2 {
3 int ret;
4
5 #ifdef _DEBUG
6 char local_ip[16], foreign_ip[16];
7 ENetAddress local_addr;
8
9 enet_socket_get_address(host->socket, &local_addr);
10 enet_address_get_host_ip(&local_addr, local_ip, sizeof(local_ip));
11 enet_address_get_host_ip(&peer->address, foreign_ip, sizeof(foreign_ip));
12
13 printf("%s:%d is disconnected from %s:%d", local_ip, local_addr.port, foreign_ip, peer->address.port);
14 #endif
15
16 ENetEvent event;
17 enet_peer_disconnect(peer, 0);
18
19 while((ret = enet_host_service(host, &event, peer->roundTripTime)) > 0){
20 switch (event.type){
21 case ENET_EVENT_TYPE_RECEIVE:
22 enet_packet_destroy (event.packet);
23 break;
24
25 case ENET_EVENT_TYPE_DISCONNECT:
26 ret = 0;
27 goto disconn_ok;
28 }
29 }
30
31 ret = 0==ret ? 1 : -1;
32
33 fprintf(stderr, "enet_host_service with timeout %d %s", peer->roundTripTime, 1==ret?"timeout":"failure");
34
35 enet_peer_reset(conn->peer);
36
37 disconn_ok:
38 enet_host_destroy(host);
39 return ret;
40 }
◆
发送数据,若成功则返回已发送数据的长度,否则返回-1
1 int rudp_sendmsg(ENetHost *host, ENetPeer *peer, ENetPacket *packet)
2 {
3 int ret;
4
5 if(enet_peer_send(peer, 0, packet)){
6 fprintf(stderr, "enet send packet %lu bytes to peer fail", packet->dataLength);
7 return -1;
8 }
9
10 ret = enet_host_service(host, NULL, peer->roundTripTime);
11 if(ret >= 0){
12 if(peer->state == ENET_PEER_STATE_ZOMBIE){
13 fprintf(stderr, "enet peer state is zombie");
14 return -1;
15 }
16 return packet->dataLength;
17
18 }else{
19 fprintf(stderr, "enet host service %u millsecond failure", peer->roundTripTime);
20 return -1;
21 }
22 }
23
24 int rudp_send(ENetHost *host, ENetPeer *peer, const void *buf, size_t len)
25 {
26 int ret;
27
28 ENetPacket *packet = enet_packet_create(buf, len, ENET_PACKET_FLAG_RELIABLE);
29 if(NULL==packet){
30 fprintf(stderr, "enet create packet %lu bytes fail", sizeof(int)+len);
31 return -1;
32 }
33
34 return rudp_sendmsg(host, peer, packet);
35 }
发送数据时需根据对端状态判断是否断线,并且packet标志设为可靠
◆
接收数据,若成功则返回已接收数据的长度,否则返回-1
1 int rudp_recvmsg(ENetHost *host, ENetPeer *peer, ENetPacket **packet, unsigned int timeout)
2 {
3 int ret;
4 ENetEvent event;
5
6 ret = enet_host_service(host, &event, timeout);
7 if(ret > 0){
8 if(event.peer != peer){
9 fprintf(stderr, "enet receive peer is not matched");
10 goto fail;
11 }
12 if(event.type != ENET_EVENT_TYPE_RECEIVE){
13 fprintf(stderr, "enet receive event type %d is not ENET_EVENT_TYPE_RECEIVE", event.type);
14 goto fail;
15 }
16
17 *packet = event.packet;
18 return (*packet)->dataLength;
19
20 fail:
21 enet_packet_destroy(event.packet);
22 return -1;
23
24 }else {
25 fprintf(stderr, "enet receive %u millsecond %s", timeout, ret?"failure":"timeout");
26 return -1;
27 }
28 }
29
30 int rudp_recv(ENetHost *host, ENetPeer *peer, void *buf, size_t maxlen, unsigned int timeout)
31 {
32 ENetPacket *packet;
33
34 if(-1==rudp_recvmsg(host, peer, &packet, timeout))
35 return -1;
36
37 if(packet->dataLength > maxlen) {
38 fprintf(stderr, "enet packet data length %d is greater than maxlen %lu", packet->dataLength, maxlen);
39 return -1;
40 }
41
42 memcpy(buf, packet->data, packet->dataLength);
43 enet_packet_destroy(packet);
44
45 return packet->dataLength;
46 }
◆
等待所有确认,若成功返回0,超时返回1,失败返回-1
1 int rudp_wait_allack(ENetHost *host, ENetPeer *peer, unsigned int timeout)
2 {
3 int ret, cnt = 0;
4
5 while((ret = enet_host_service(host, NULL, 1)) >= 0){
6 if(enet_peer_is_empty_sent_reliable_commands(peer, 0,
7 ENET_PROTOCOL_COMMAND_SEND_RELIABLE|ENET_PROTOCOL_COMMAND_SEND_FRAGMENT))
8 return 0;
9
10 if(peer->state == ENET_PEER_STATE_ZOMBIE){
11 fprintf(stderr, "enet peer state is zombie");
12 return -1;
13 }
14
15 if(0==ret && ++cnt>=timeout){
16 return 1;
17 }
18 }
19
20 fprintf(stderr, "enet host service fail");
21 return -1;
22 }
等待已发送数据的所有确认时,需根据对端状态判断是否断线
示例流程
左边为客户端,压缩并传输文件;右边为服务端,接收并解压存储文件。
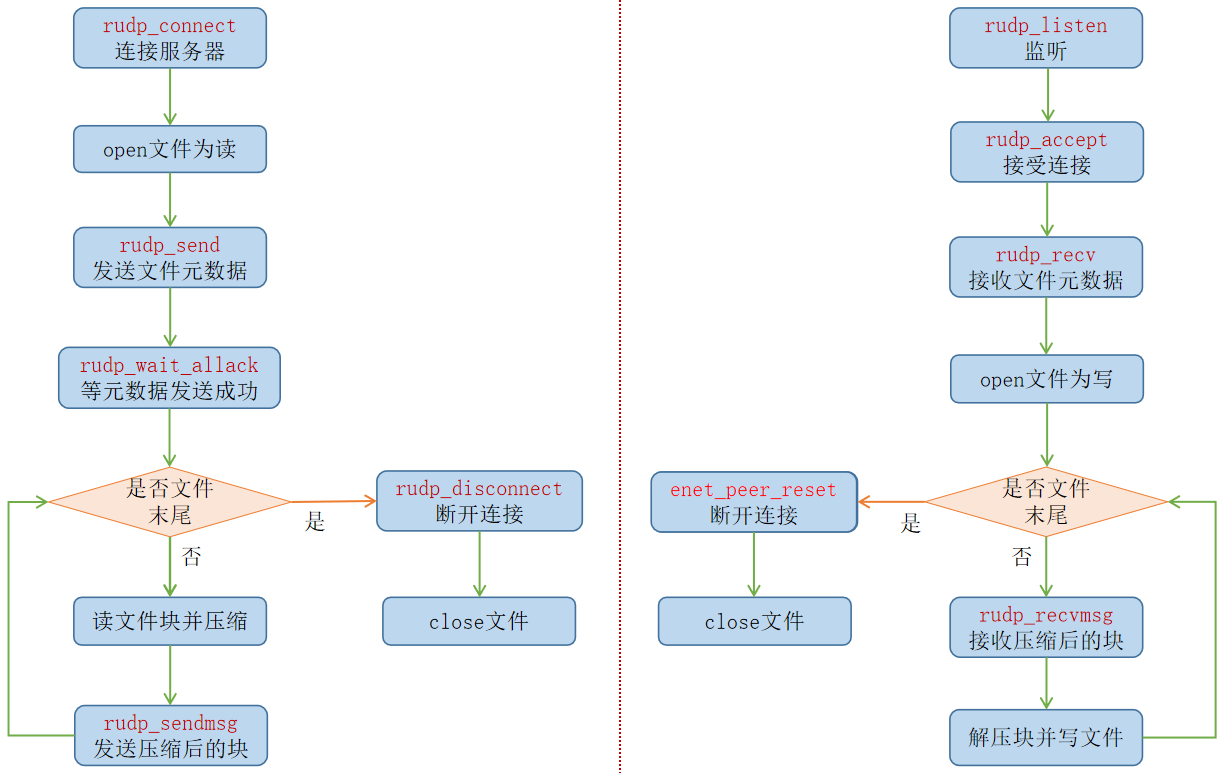
客户端【读文件块并压缩】这个环节,需要显式创建可靠packet,并将压缩后的块拷贝到其中
posted @
2020-05-04 19:08 春秋十二月 阅读(2581) |
评论 (0) |
编辑 收藏
VSS是Windows系统的卷影像拷贝服务,用于解决如下问题:
◆ 许多备份工具涉及打开文件
◆ 但是若一个应用程序已经以独占方式打开文件并进行访问时,备份工具则不能访问该文件
◆ 即使备份工具能够访问已打开的文件,也可能造成备份文件的不一致性
在实际数据灾备中,主流厂商实现SQL Server的热备并不会使用数据库自带的
backup database/
backup log命令,因为这种方式在应急容灾(此时源数据库已宕机)挂载数据时要先还原,而还原要连接数据库运行
restore database/
restore log命令,这样就需要部署一台机器装上SQL Server专用于还原,不仅增大了成本而且延长了
RTO;而使用VSS,备份的就是SQL Server的数据文件及日志文件,在应急容灾挂载时可直接打开并用于增删改查,无须还原,免去了机器成本并降低了RTO(只存在数据库挂载时的事务恢复时间)。
VSS架构
VSS包括Requestor、Writer、Provider和VSS核心模块四部分,如下图所示
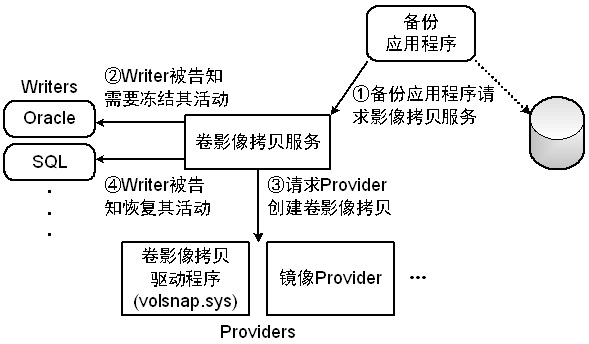
Requestor在本文中表示热备份应用程序;Writer主要功能是保证数据的一致性,使得那些能够感知影像拷贝的应用程序能够接收到冻结(freeze)和解冻(thaw)通知,以确保其文件的备份拷贝是内在一致的,在本文中即指SQL Server自带的
SQL Writer;Provider主要功能是创建影像拷贝即打快照,允许将ISV特定的存储方案与影像拷贝服务集成起来,在本文中即
volsnap.sys存储过滤型驱动程序,位于文件系统和卷管理器之间;VSS核心模块即图中的卷影像拷贝服务,主要功能是协调各个模块的协作运行,并提供创建及管理卷影像拷贝的API接口。
VSS原理示例
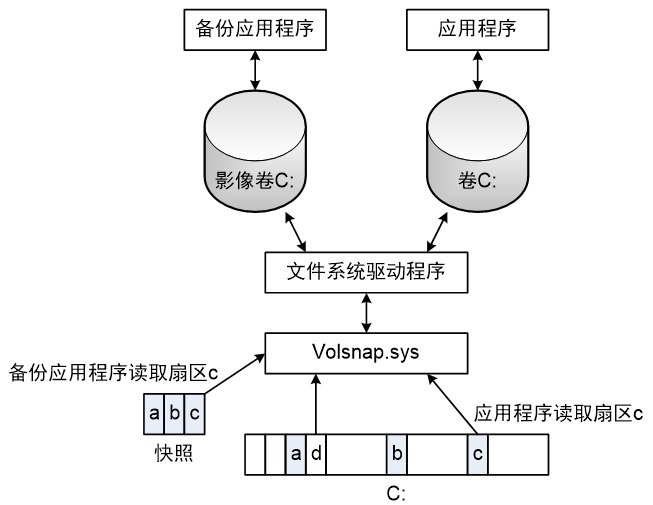
无论何时,当卷影像拷贝驱动程序看到一个针对原始卷的写操作时,它把将要被修改的扇区的内容复制到一个与影像卷相关联的、由页面文件支持的内存区中
◆ 对于已修改扇区的影像卷读操作,从该内存区中读取数据
◆ 对于未修改扇区的影像卷读操作,从原始卷中读取
备份应用程序、Provider和SQL Writer的局限
◆ 只能备份Windows系统支持的本地文件系统上的文件,不支持远程共享或交叉挂载的文件系统
◆ 对于系统提供者(Windows系统默认自带的Provider,使用写时拷贝技术),被拷贝的源卷不必是NTFS卷,但影像卷必须是NTFS卷
◆ SQL Writer支持全量备份及恢复、支持差异备份及恢复和Copy Only备份,但不支持备份连续事务日志、文件和文件组,不支持页恢复
怎样使用VSS
微软官网提供的VSS SDK 7.2(
https://www.microsoft.com/en-us/download/details.aspx?id=23490)中自带了
vshadow和
betest工具源码,经过笔者修正一些bug(win 10 + vs2010),并为了备份配置方便将原来的文本换成xml格式,成功地实现了SQL Server的全量热备及恢复、差量热备及恢复
vshadow用法
以管理员身份在ms-dos窗口下执行vshadow.exe /?,可得到所有的帮助
示例
可用vshadow -wm获取当前系统所有写者的元数据,再从中查找SQL Server Writer的写者ID及它下面COM组件的逻辑路径和名称
betest用法
以管理员身份在ms-dos窗口下执行betest.exe /?,可得到所有的帮助
示例
1. 全量备份SQL Server
betest.exe /v
/b /t
FULL /s backupfull.xml /d f:\backupfull /c SQLWriter.xml
/v -- 输出详细信息,可选的
/b -- 备份
/t -- 备份类型
/s -- 备份/恢复组件XML格式文档,内含写者及其下组件的元数据(非常重要)
/d -- 备份目录
/c -- 相关写者的配置文件,文件内含写者ID及其下COM组件的逻辑全路径名
全量恢复SQL Server
betest.exe /v
/r /s backupfull.xml /d f:\backupfull /c SQLWriter.xml
/r -- 恢复
其它选项说明同上,下同
2. 差异备份SQL Server
betest.exe /v /b /t
DIFFERENTIAL /s backupdiff.xml
/pre backupfull.xml /d f:\backupdiff /c SQLWriter.xml
/pre -- 表示前次基准的全量备份生成的组件XML格式文档
差异恢复SQL Server
a) betest.exe /v /r
/AdditionalRestores /s backupfull.xml /d f:\backupfull /c SQLWriter.xml
/AdditionRestores -- 用于差异恢复的选项,表示全量后面需要紧跟差异恢复才能完成数据库恢复
b) betest.exe /v /r /s backupdiff.xml /d f:\backupdiff /c SQLWriter.xml
注意,此时/s跟的是差异备份生成的backupdiff.xml文件,/d跟的是差异备份目录
3. SQL Writer配置
xml格式说明
writer节点
id属性 --- 写者唯一ID
server_name属性 --- SQLServer服务名
stop_restore_start属性(可选) --- 表示恢复时是否先停止数据库服务再启动,yes表示先停再启,no则反之,这个用于恢复系统数据库master,因为master不支持在线恢复
component节点
pathname属性 --- 逻辑路径名
file节点
src_path节点 --- SQL Server文件所在路径的匹配模式
alternate_path节点 --- 恢复时的备选路径,用于合成差异增量
示例
<?xml version="1.0" encoding="utf-8"?>
<betest>
<writer id="{a65faa63-5ea8-4ebc-9dbd-a0c4db26912a}" service_name="MSSQLSERVER" stop_restore_start="no">
<component pathname="DESKTOP-JUP320L\master">
<file>
<src_path>E:\*...</src_path>
<alternate_path>f:\sqlserver\</alternate_path>
</file>
</component>
<component pathname="DESKTOP-JUP320L\model">
<!--file>
<src_path>E:\*...</src_path>
<alternate_path>f:\sqlserver\</alternate_path>
</file-->
</component>
<component pathname="DESKTOP-JUP320L\test">
<!--file>
<src_path>E:\*...</src_path>
<alternate_path>f:\sqlserver\</alternate_path>
</file-->
</component>
</writer>
</betest>
posted @
2020-05-02 16:31 春秋十二月 阅读(1607) |
评论 (0) |
编辑 收藏
阅读《MySQL Innodb无锁化设计的日志系统》(
https://zhuanlan.zhihu.com/p/53037796)后的心得:
与oracle日志子系统异曲同工的差异
1. 空洞:对于并发会话copy重做日志造成的空洞,oracle是由lgwr判断并等待持有redo copy闩锁的会话释放后,这时空洞已被填充,可以刷到磁盘了;mysql则是由log writer线程监测到空洞被填充后,再写入一段连续最大lsn的日志到磁盘
2. io方式:oracle的lgwr是direct io;mysql的log writer是写到os的page cache,后由独立的log flusher线程刷盘,比oracle多了一个过程
3. 唤醒会话:oracle由lgwr扫描所有等待的会话,只唤醒满足写入条件(事务提交log已刷盘)的会话;mysql则由独立的log flush notifier通过满足条件对应的分片消息队列来唤醒,比oracle多了一个过程
总结:mysql通过原子变量来管理全局log buffer的几个内存位置来实现无锁化,而原子操作在多核上仍不利于线性扩展。oracle的闩锁也存在类似问题,但通过私有redo缓存和多个全局log buffer(相关闩锁量与cpu核数正比),来提升了扩展性。故整体上oracle更优
阅读《MySQL/InnoDB数据克隆插件(clone plugin)实现剖析》(
https://zhuanlan.zhihu.com/p/76255304)后的心得:
与oracle老式热备异曲同工的差异
1. page追踪:oracle老式热备实际当每行更新时将整个关联的page记录在redo日志中;mysql热备则是记录变化page的id在单独一个地方,用于page copy阶段从buffer pool读取并发送页数据到备库
2. redo归档:oracle老式热备在拷贝数据文件的全过程,只要数据文件被修改就会有redo归档;mysql热备则仅在page copy阶段启用redo归档,可看做是临时的
3. 一致性恢复:oracle老式热备存在数据块分离现象,对此应用被冻结scn及日志序列号后的redo log来恢复;mysql则通过page copy及应用clone lsn后的redo log来恢复
总结:oracle老式热备必须处于归档模式,由于记录整块而非行变化,因此重做日志写放大而增加了cpu和io的开销,由于可能判断并修复分离的块,因此延长了恢复时间;mysql通过page追踪和临时redo归档来减少应用redo的体量而缩短了恢复时间。故mysql热备整体更优,但相对oracle的现代rman备份则并不更优
posted @
2020-04-21 11:19 春秋十二月 阅读(6039) |
评论 (0) |
编辑 收藏
nginx是一款著名的高性能开源Web与反向代理服务器,支持windows和linux操作系统,因为在windows系统上还不支持SCM(服务控制管理),所以只能以控制台方式运行,但这样并不是在后台运行,也不能在系统登录前启动。针对这些问题,本方法通过改进源码,使nginx良好地支持了SCM,方便了部署运行
特点
最大地复用了nginx源码;支持SCM,并兼容控制台运行方式;统一处理异常退出而报告服务停止
实现 变换原主函数
将原来的main函数更名为ngx_main,并增加第3个参数is_scm来标识运行方式,非0表示服务方式,0表示控制台方式,流程如下
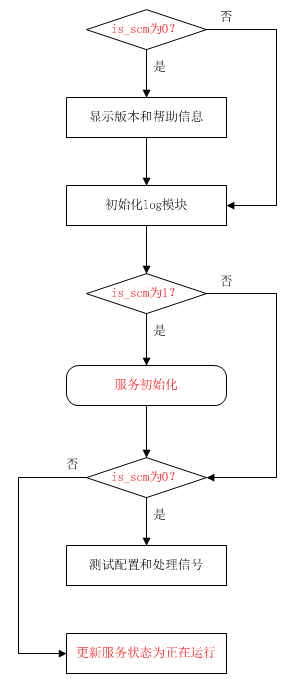
图上红色部分为插入的逻辑,其它部分为nginx原来的逻辑。由于服务初始化须将错误记录在log(日志)中,所以应在初始化log模块后调用
增加主函数
这个主函数也就是程序入口main,可被控制台或SCM调用,当被SCM调用时,注册服务以及启动服务控制调度程序,流程如下
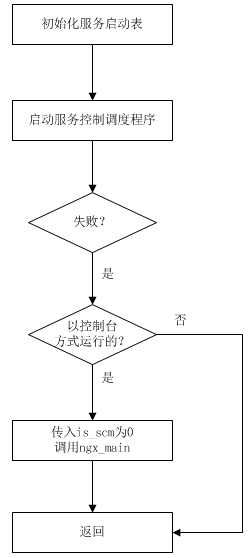
如果以命令行启动nginx 也就是master进程(管理进程),或nginx产生worker进程(工作进程)时,那么以控制台方式调用main,进而以is_scm为0调用ngx_main,当ngx_main返回时,就表示master或worker进程退出了
服务主函数
由SCM生成的一个逻辑线程调用,流程如下
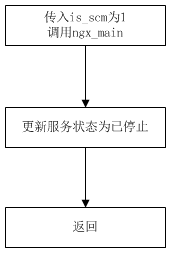
这里的逻辑线程代替了nginx的master进程,到这里就表明已经以SCM方式运行了,所以以is_scm为1调用ngx_main,当ngx_main返回时,就表明master进程退出了,应该更新服务状态为已停止,然后返回表明当前服务结束了
服务初始化 由ngx_main调用,见变换原主函数流程图,流程如下
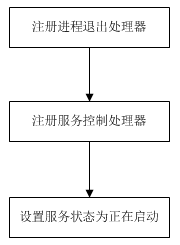
由于在nginx实现中,有多处出现异常错误而直接退出,因此首先注册了进程退出处理器,在其内报告服务状态为已停止,这样只要当进程退出了,在SCM上就能看到已停止的状态了
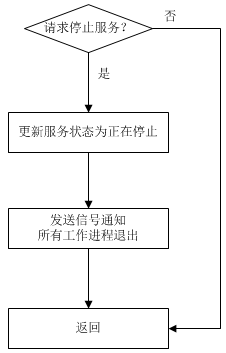
服务控制处理器 由SCM的主线程调用,流程如下
 调用关系
调用关系 下图左边为master进程调用模块与函数,右边为worker进程调用模块与函数,委托主函数是
ngx_main 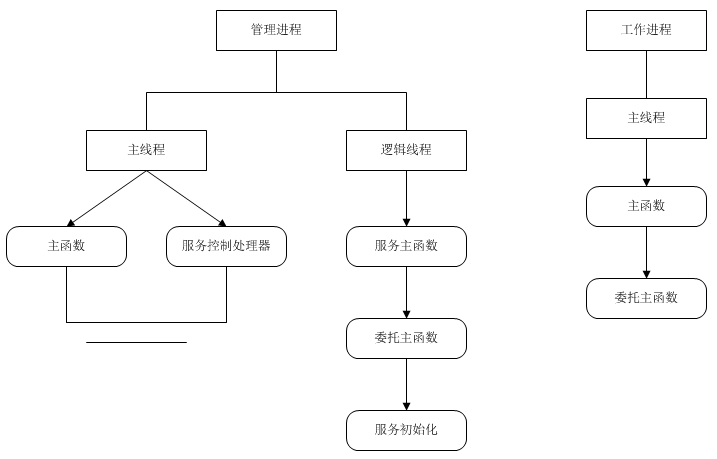
posted @
2019-11-20 19:45 春秋十二月 阅读(943) |
评论 (0) |
编辑 收藏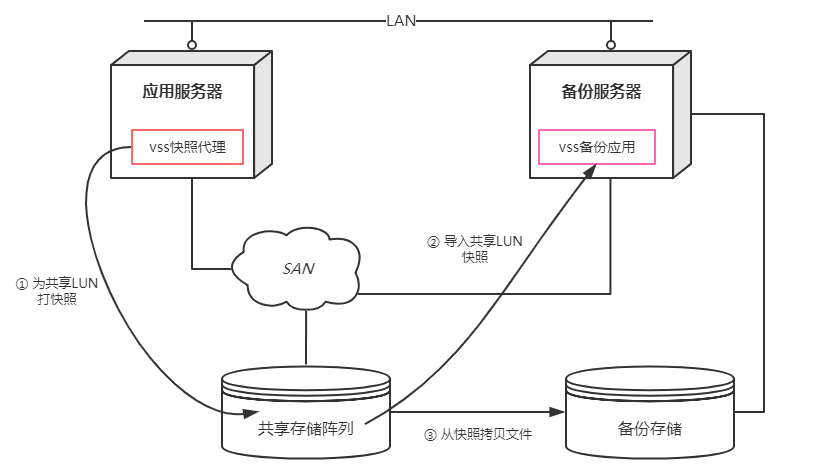
传统的vss备份架构由于备份应用部署在应用服务器内,因此比较耗应用服务器的CPU和IO,特别是拷贝大量的文件,为了降低对应用服务器的干扰,可采用server-free架构,将耗时的拷贝移到另一机器即备份服务器实现,而应用服务器只负责占用资源及耗时很少的打快照。这种架构运用了vss可传输卷影拷贝的特性,要求快照处于共享存储中,适用于Windows Server 2003 sp1以上版本
协作流程图 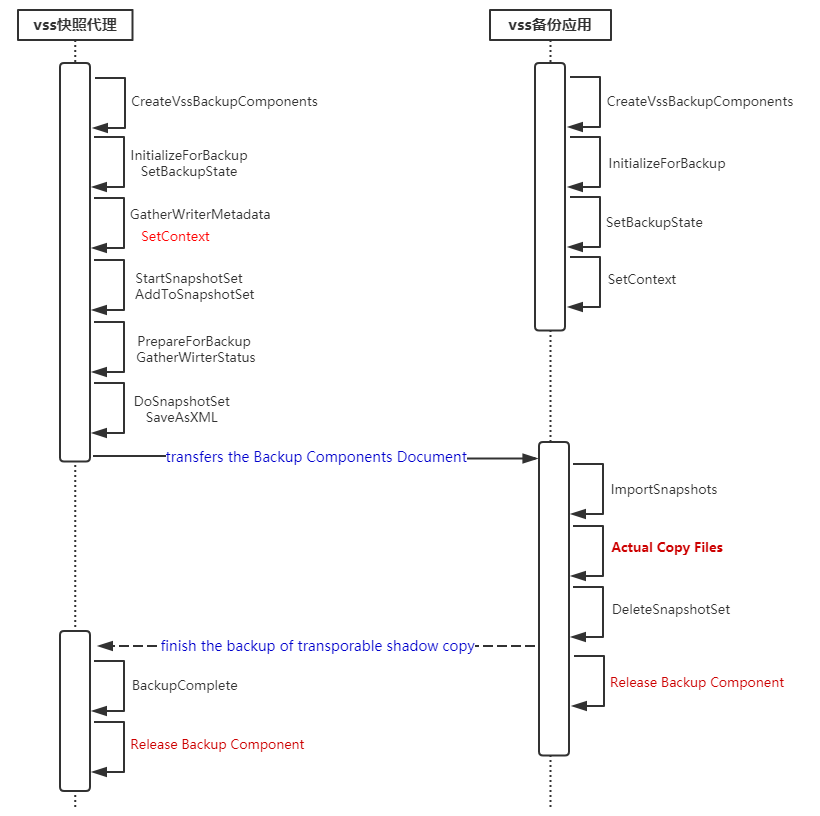
VSS快照代理端的SetContext要求设置成
VSS_CTX_APP_BACKUP | VSS_VOLSNAP_ATTR_TRANSPORTABLE
posted @
2019-11-06 18:01 春秋十二月 阅读(985) |
评论 (0) |
编辑 收藏1. 绑定变量作为一种优化查询处理的方法,在性能上有利有弊,是一把双刃剑。它的优势在于可以共享库缓存中的父游标,从而避免了硬解析及相关的开销;劣势在于因绑定变量扫视增加了查询优化器选择(非常)低效执行计划的风险,即使支持自适应游标共享,也引入了游标感知判断和谓词选择率估算的代价,而且在生成高效的执行计划前至少有一次是无效率的。因此,是否使用绑定变量,需要衡量实际字面值与处理数据量带来的解析执行的收益与损害,当损害大于收益时就不应该使用,反之当处理较少数据硬解析耗时比执行多时,就可以使用了
2. 存储快照一般有三种层次:物理卷、文件系统和应用程序
◆ 物理卷快照基于卷扇区映射表实现,宜采用CoFW法,因为它不必每次写io都去遍历映射表,比RoFW快
◆ 文件系统快照基于inode树即元数据复制实现,每当写io时更新快照或源inode的指向,必要时向上回溯至根inode。有的文件系统比如NetApp公司的WAFL则更优,只须复制根inode,因为每次写io时它会变但其下所有的inode不会变
◆ 应用程序快照最典型的就是数据库,原理本质与上述两种一样,基于页改变位图,当page首次(相对于快照创建时刻)改变时拷贝到快照文件(一种稀疏文件),另外当撤消未提交事务或回滚事务时也会发生拷贝(此时快照慢慢不再稀疏),这是为了保证快照的可用一致性
3.
数据块的加锁有单机和分布式两种情景,前者是为了同步单实例事务的并发,后者是为了协调分布式事务的同步,并与缓存一致性协议紧密联系。undo,redo,undo/redo三种日志对数据脏块与提交日志记录落盘的顺序要求各不同,因此恢复方式不同。脱服务器备份架构比较好,具有不占用应用服务器资源的优势,而微软的vss可传输卷影拷贝提供了这一支持,足见其技术的先进前瞻性
4. Oracle的
实例恢复完全靠在线重做日志,介质恢复必须靠归档重做日志,以及在线重做日志。然而在线重做日志是有限数量的,那么Oracle是怎样保证宕机经实例恢复后不丢数据?答案是检查点。检查点是数据库中一个很重要的机制,被重做日志切换触发,由DBWn执行刷新脏块,并清除老的无用的在线重做日志,以允许被覆盖
5. Linux内核的swap高速缓存和其它的缓存(比如page缓存)不太一样,因为它存在的主要原因不是为了减少磁盘IO提高性能,而是解决换入换出共享匿名页同步即并发swap的问题。那么它是唯一的方法吗?不一定,可以遍历所有的anon_vma链表,查找匿名页对应的页框是否已建立,但该方法没有swap缓存快。当然,在换入操作很多的情景,swap缓存确实能提高系统性能
6. Linux内存回收的核心是LRU链表,Oracle的buffer cache也有个LRU,这两种LRU的共同点是引用计数(标志)和非活跃链表,引用计数会影响一个对象是否移到非活跃链表,非活跃链表用于回收或覆盖这个对象。对于Linux这个对象是页框,移到非活跃链表取决于swap tendency;而Oracle则是数据块buffer及其TCH
7. Linux内核中的反向映射让我想起了Oracle中的反向键索引,它们的共同点都是为了高性能,前者是为了快速定位引用同一页框的所有页表项,从而方便共享内存的回收;后者是为了减少右侧索引叶块的竞争,从而降低缓冲区忙等待、提高并发量
8. mvcc与read uncommitted(简称RU)隔离级别的关系究竟如何?这取决于现代数据库的实现。对于Oracle,RU和RC的读实现都基于mvcc实现,换句话说Oracle其实没有脏读;对于MySQL innodb引擎,mvcc不适用于RU而只适用于RC/RR级别,因为RC/RR必须读取修改已提交的数据,但基准点不同,前者查询开始时、后者事务开始时,而RU则可读取未提交的数据,当然用mvcc模拟实现RU应该也可以,只需要读取当前新版本而非旧版本
9. 借助内核page cache的数据库或者存储引擎,一定程度上讲,是粗暴懒惰的表现,这会导致系统负载比较重的情况下,io性能很差。所以为高性能,必须得处理好direct io,设计self cache,这样一来,就避免了浪费在原先内核页缓存的页框,避免处理内核页缓存和预读的多余指令而提高了系统调用read和write的效率,同时减少了一次数据拷贝
10. SQL半连接的本质是在内连接的基础上对内表去重,即使内表有符合多个连接条件的元组,也只匹配一条,从而减少了连接返回的结果集。一般地,简单的in、exists和any子句,都采用半连接实现,但若内表本身保证了唯一性,则半连接可消除转为内连接实现,或者内表数据量很小且外表存在索引,那么也会消除半连接,生成由内表驱动外表,外表走索引的执行计划。由此一例看出,SQL优化器偏爱内连接,因为内连接带来了驱动表选择和谓词下推的灵活,便于产生更优的执行计划
11. 从Oracle数据库内核角度讲,游标代表SQL语句的句柄,包含了依赖对象及执行计划等信息,它相当于linux的文件描述符和windows的句柄。打开或缓存的游标是指对应SQL语句所占的内存(父游标句柄、父堆0和子游标句柄的chunk)被加上kgl lock和pin锁,意味着第三次后解析同样的SQL不必再从library cache hash chain中加锁查找而直接从PGA的子堆6地址中获取并调用执行计划,如此优化提高了并发度加快了查询,这正是软软解析;软软解析前必须软解析2次,目的是将library cache的执行计划在PGA中做一份链接,软解析前必须硬解析,目的是将执行计划放在library cache中。然而,如果共享池空闲内存不足,或者依赖对象发生DDL操作导致执行计划失效,那么执行计划所占chunk可以被覆盖释放,这样一来,软(软)解析时就需要重新生成执行计划了
12. Oracle的内存管理粗略地类似于Linux内核,所不同的是内存分配单元,前者叫granule通常大小4M~16M,后者叫page通常4K;数据块缓冲的分配类似伙伴算法,共享池(主要用于sql缓存)的chunk分配类似slab算法,共享池中的保留池类似基于slab的内存池
13. Oracle数据库究竟是怎样构建表数据块的读一致性版本?这是个比较复杂、细致和有趣的问题,核心流程如下
◆ 克隆数据块,若不存在则先从磁盘读,下面几步以克隆块为目标
◆ 根据ITL中的flag及lck,对所有已提交的事务做清除操作,即延迟块清除。延迟块清除为了获取足够精确的提交SCN填充到ITL,分2种情况,若事务表槽没被覆盖,则直接用其提交SCN;否则先从事务控制区获取SCN,并判断对于上界提交是否足够精确,若不够则需要回滚事务表一直找到合适的SCN或报错ORA-01555
◆ 根据ITL中的uba,反向更改所有未提交的事务,也就是应用事务的undo记录
◆ 根据ITL中的SCN,不断反向更改大于目标SCN的已提交事务,直至遇见合适的已提交事务。这里也是应用undo记录,但不同的是,除了应用行数据,还会从事务的第一个undo记录找到先前即前一个已提交事务的ITL项拷贝回当前块的对应ITL项
14. Oracle的多版本控制机制,为dml不仅提供了一致且正确的结果,还提高了并发性,可谓鱼和熊掌兼得。那么它的缺点是什么?可能会导致热表的IO增高,因为读一致性需要不断回滚多个事务对数据块的修改,直到查询开始时的数据。事务隔离级别read committed与read uncommitted的相同是不会脏读,区别是前者会不可重复读或幻读
15. Sql*plus的ARRAYSIZE对查询数据性能有重要的影响,这个值过大过小都不好,而是要接近一个数据块所拥有的行数,如此仅一次逻辑IO就拿到了一批行。那么设置合适的ARRAYSIZE就一定能提高性能吗?不一定,还要看所查询的表使用了什么索引列及表数据在磁盘上的物理布局,若数据分散即聚簇因子低,则优化器会选用全表而非索引区间扫描,去执行这个查询
16. IOT表如果为非主键列再建索引,那么就成二级索引。这时候查询数据,需要两次扫描,一是扫描二级索引得到IOT中的位置,二是扫描IOT本身匹配那个位置,之所以这样是因为行记录在IOT中的位置会变。而堆组织表,仅需一次扫描索引结构,得到rowid,再直接读磁盘获取行记录。因此IOT上再建二级索引,并非明智的选择
17. 相容性矩阵是封锁调度的核心结构; 任意一个无环优先图的封锁调度都是冲突可串行化的; 基于树协议的无环优先图的封锁调度,其整个事务集合的任意一个拓扑顺序都是等价可串行化的
18. 总结解决数据库丢失更新问题的方案
◆ 对于表不会被悲观锁锁定的情景:使用基于select+update的乐观锁方法,查询保存前映像,以便定位更新。前映像列可为全列,或新增一个时间戳列作为版本列
◆ 对于表可能会被悲观锁锁定的情景:使用select…for update nowait+update的悲观锁方法,可以以全列的hash(虚拟列)来定位更新
19. 如果能够在备库上打开闪回,那么就可以做到既让生产系统没有承担闪回的开销,又能快速地为错误或故障恢复到以前某个时刻。一举两得比较完美,重做日志的创新使用真是太棒了
20. Oracle的索引聚簇表是个创新,它能将多个不同表的行按照索引列存储在同一块中,属于物理上的join,这样一来既可减少data buffer缓存的块数而提高效率,又可提高多个相关表连接查询的性能,比如通过外键约束的父子表。最典型的应用就是数据字典,数据字典对于查询优化的成本估算很重要,由此可见oracle的设计之明智,mysql的innodb只有索引组织表,sql server有堆表和索引组织表,但它们都没有索引聚簇表
21. 分布式事务处理是工程难题。Oracle的serializable串行隔离级别以乐观锁实现,所以并发度与非串行相当,需要注意的是:串行并不是说一个事务提交了才能处理下一个,而是多个事务间没有冲突表现地像只有一个事务在运行,否则Oracle的serializable级别就不存在抛出ORA-08177错误了
22. 理清read uncommitted事务隔离级别的锁策略:读不加共享锁,写加排它锁直至提交,这里的锁是指lock;块的缓冲区并发操作必须加锁,这里的锁是指latch,若不加,那脏读读到的数据可能是错的。脏读隔离级别允许读修改但未提交的行记录,这意味着读不能被写阻塞,也不能阻塞写,所以不会申请共享锁(显式锁定读除外)
23. 与MySQL不同,Oracle的行锁无需索引列的限制,是真正的行锁,其实现为数据块的属性而非传统的锁管理器,但是它需要在事务commit或rollback时才释放,如果存在慢sql,那么导致的阻塞会比较严重
24. 隔离是实现安全的一种办法,其结果常被称作“沙箱”。从这个意义上讲Oracle很明智,因为它的事务没有也不需要read uncommitted隔离级别,Oracle最低且默认的隔离级别是read committed,因为它有基于undo的多版本控制,天生非阻塞读,根本不会脏读。我想不出read uncommitted有什么好处,除了非阻塞读及可能的高并发,要谨慎脏读是危险不安全的
25. windows内存映射和linux内存映射的实现机制不太一样,前者使用了内存区section的专用数据结构而不像后者重用了页缓存,内存区的映射完全由内存管理器负责包括物理页分配及脏页面写入器,与缓存管理器无关;缓存管理器基于内存管理器维护了文件块数据的视图,并提供了自己的延迟写入器。这两种写入器即回刷,独立并行地工作
posted @
2019-11-06 11:29 春秋十二月 阅读(8198) |
评论 (0) |
编辑 收藏 由于某些sdk或软件依赖众多的第三方库,而从官网下载到windows主机或从linux传到windows时,所依赖的so库往往丢失符号链接,给编译运行带来不便,因此编写了
ctlsolink脚本,用于自动为单个so或某目录下的众多so或创建/删除一级/二级符号链接。该脚本的用法如下:
● 第1参数为mk或rm子命令,mk表示创建,rm表示删除
● 第2参数为文件或目录
● 第3参数是可选的-r,且只能是-r,如果指定了,则表示不断递归子目录
脚本实现
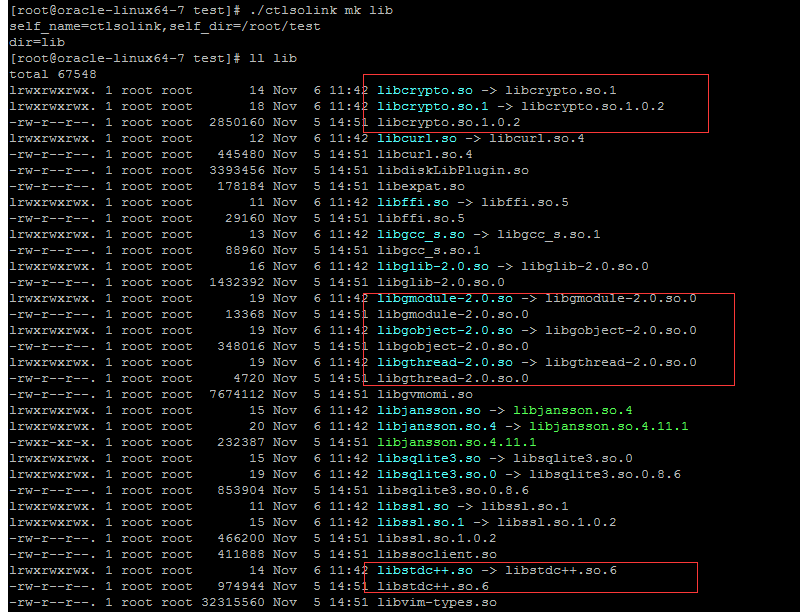
考虑到so库带版本一般多为libx.so.1,libx.so.1.2,libx.so.1.2.3这三种形式(x为库名),对于前一种创建/删除一级符号链接即可,后两种则创建/删除二级符号链接。为了精确地抽出一级和二级链接名称,这里使用awk来匹配,用shell变量的最短匹配模式从尾部逐步删除点号及数字,核心代码如下
1 if [ "$dir" != "$self_dir" ] || [ "$name" != "$self_name" ]; then
if [ "$dir" != "$self_dir" ] || [ "$name" != "$self_name" ]; then
2 if echo $name | awk '{if($0~/\.so\.[0-9]{1,}\.[0-9]{1,}\.[0-9]{1,}$/) exit 0; else exit 1}'; then
3 link_name=${name%.[0-9]*}
4 link_name=${link_name%.[0-9]*}
5 link_name=${link_name%.[0-9]*}
6 link_name2=${name%.[0-9]*}
7 link_name2=${link_name2%.[0-9]*}
8 elif echo $name | awk '{if($0~/\.so\.[0-9]{1,}\.[0-9]{1,}$/) exit 0; else exit 1}'; then
9 link_name=${name%.[0-9]*}
10 link_name=${link_name%.[0-9]*}
11 link_name2=${name%.[0-9]*}
12 elif echo $name | awk '{if($0~/\.so\.[0-9]{1,}$/) exit 0; else exit 1}'; then
13 link_name=${name%.[0-9]*}
14 else
15 return
16 fi
17
18 if [ $do_mk = "yes" ]; then
19 #echo "name=$name, link_name=$link_name, link_name2=$link_name2"
20 if [ -n "$link_name2" ]; then
21 ln -sf $name $link_name2
22 ln -sf $link_name2 $link_name
23 else
24 ln -sf $name $link_name
25 fi
26 else
27 if [ -n $link_name2 ]; then
28 rm -f $link_name2
29 fi
30 rm -f $link_name
31 fi
32 fi 要注意的是,这儿不能使用%%删除最长匹配的尾部来得到
link_name,因为它的模式是
.[0-9]*,这可能会错误地匹配了so前的部分,比如libx.1.so.2得到libx,而期望的是libx.1.so
完整脚本下载:
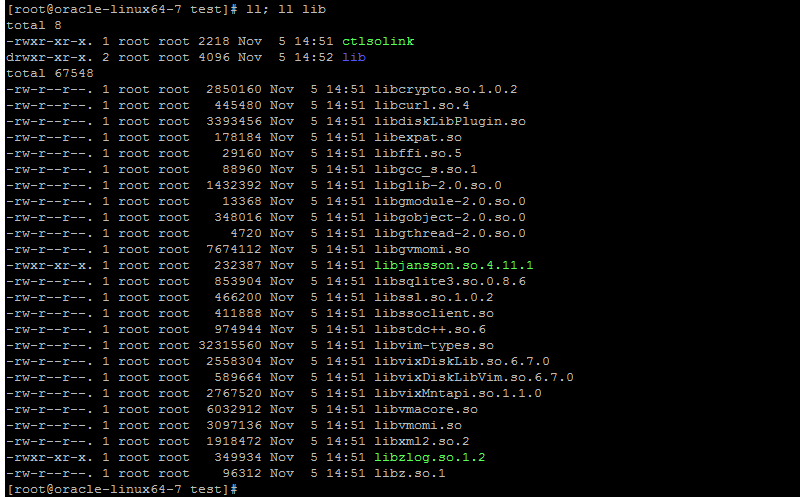
ctlsolink 运行效果 初始状态
运行ctlsolink创建软链接后
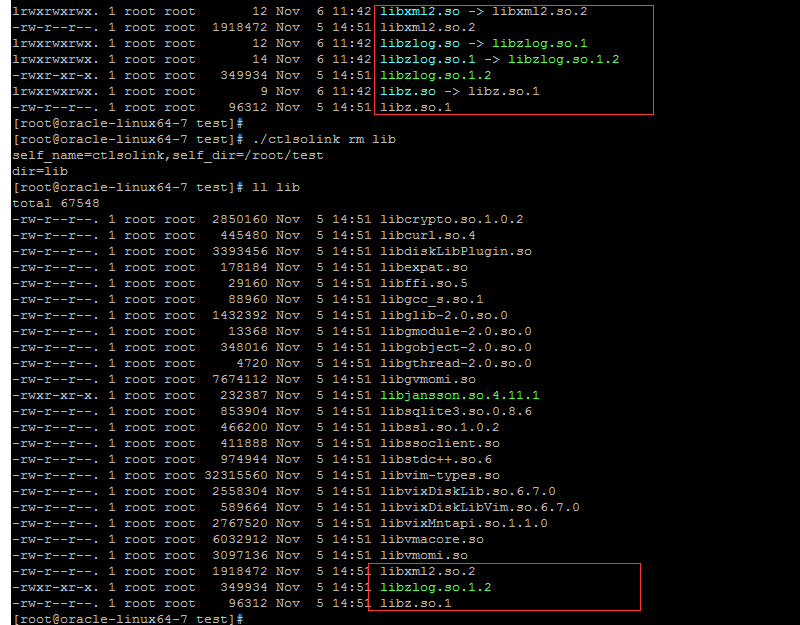
运行ctlsolink删除软链接后
posted @
2019-11-05 18:17 春秋十二月 阅读(2064) |
评论 (0) |
编辑 收藏
为了减少程序中的硬编码,灵活按需管理字符串空间,使用了ATL中的CString类,代码如下
1 CString bstrComPathName;
2 WCHAR componentPathName[1];
3 DWORD dwNameLen = 1;
4
5 if (!GetComputerNameEx(ComputerNamePhysicalDnsFullyQualified, componentPathName, &dwNameLen))
6 {
7 DWORD dwErr = GetLastError();
8 if(ERROR_MORE_DATA==dwErr)
9 {
10 if (!GetComputerNameEx(ComputerNamePhysicalDnsFullyQualified, bstrComPathName.GetBuffer(dwNameLen), &dwNameLen))
11 {
12 zlog_error(g_zc, "GetComputerNameEx with ComputerNamePhysicalDnsFullyQualified fail: %d", GetLastError());
13 return -1;
14 }
15 }
16 else
17 {
18 zlog_error(g_zc, "GetComputerNameEx with ComputerNamePhysicalDnsFullyQualified for fail: %d", dwErr);
19 return -1;
20 }
21 }
22 bstrComPathName.ReleaseBuffer();
需要注意的是,GetBuffer方法虽提供方便了直接修改CString对象的内部缓冲区,但违背了面向对象设计的原则(由公开方法修改内部数据),因此不保证对象的完整性,在操作完成后一定要调用ReleaseBuffer
posted @
2019-07-31 12:51 春秋十二月 阅读(8058) |
评论 (0) |
编辑 收藏 在GNU make中文手册这本书中,3.14节讲到了依赖文件的自动生成,如下图

图中的规则对C源文件和Makefile在同一目录,是正确的。但是不在同一目录的又希望依赖文件在对应的目录下,比如src/log/log_file.c,希望依赖文件log_file.d生成在src/log/下。因为gcc(aix平台xlc编译器亦如此)生成的依赖文件内容中目标文件名没有带路径,例如下所示
log_file.o: src/log/log_file.c src/log/log_file.h src/log/log_type.h \
src/log/../base/io_ext.h
所以sed就找不到src/log/log_file.o而替换了,改正后的规则如下
%.d: %.c
$(CC) $(CFLAGS) $(INCS) $< $(MFLAGS) $@.$$$$;\
sed 's,$(*F).o[ :]*,$*.o $@: ,g' < $@.$$$$ > $@;\
$(RM) $@.$$$$
该规则对C源文件和Makefile在同一目录也适合,生成后的依赖文件内容如下
src/log/log_file.o src/log/log_file.d: src/log/log_file.c src/log/log_file.h src/log/log_type.h \
src/log/../base/io_ext.h
posted @
2018-11-16 12:08 春秋十二月 阅读(918) |
评论 (0) |
编辑 收藏