def sm4_sbox(byte):
v = V([(byte >> i) & 1 for i in range(S_M-1, -1, -1)])
v1 = A1 * v + C1
r_byte = sum(int(v1[i]) << i for i in range(S_M-1, -1, -1))
elem = byte_to_poly(r_byte)
if elem != 0:
inv_elem = elem^-1
inv = poly_to_byte(inv_elem)
else:
inv = 0
v2 = V([(inv >> i) & 1 for i in range(S_M)])
r = A2 * v2 + C2
return sum(int(r[i]) << (S_M-1-i) for i in range(S_M))
def sm4_sbox_create():
table = [sm4_sbox(i) for i in range(S_SIZE)]
return table
def sm4_sbox_print(S):
print(f"const uint8_t sm4_sbox[{S_SIZE}] = {{")
for i in range(0, S_SIZE, 16):
row = ", ".join(f"0x{s:02X}" for s in S[i:i+16])
print(" " + row + ",")
print("};", end="\n\n")
运行输出如下
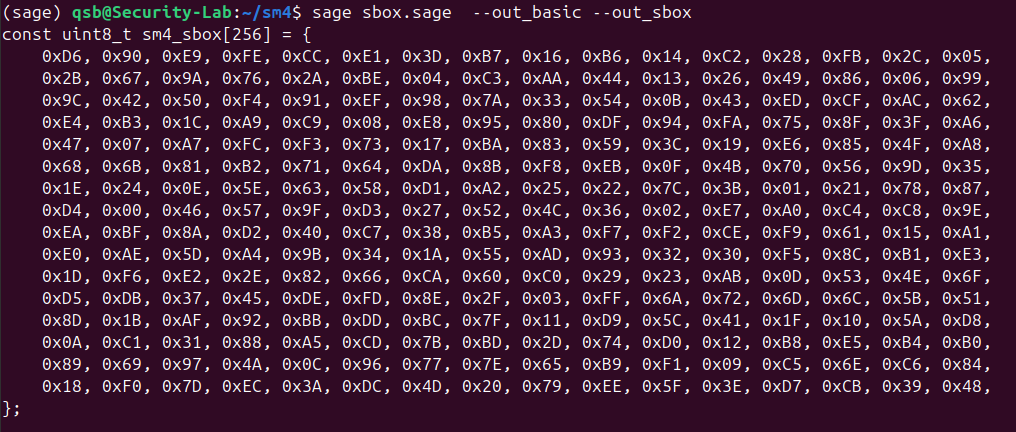 以上输出表格与文献[1] 给出的完全一致
以上输出表格与文献[1] 给出的完全一致
S盒的代数性质
主要是平衡性、代数次数、非线性度、Walsh谱、差分均分度、SAC、扩散准则PC(k),具体计算根据它们的定义。代码如下
###########################################################
def sbox_balance(S):
for j in range(S_N):
cnt = sum((S[i]>>j)&1 for i in range(S_SIZE))
print(f"Output bit {j}: {cnt} ones")
###########################################################
def max_nonlinearity(n):
if n % 2 == 0:
return 2^(n-1) - 2^(n//2 - 1)
else:
return 2^(n-1) - 2^((n-1)//2)
def sbox_boolfun_property(S):
min_nl = infinity
for j in range(S_N):
bf = BooleanFunction([(S[i]>>j)&1 for i in range(S_SIZE)])
deg = bf.algebraic_degree()
nl = bf.nonlinearity()
min_nl = min(min_nl, nl)
walsh_max = max(abs(w) for w in bf.walsh_hadamard_transform())
print(f"Bit {j}: degree={deg}, nonlinearity={nl}, max|Walsh|={walsh_max}")
print(f"the minimum nonlinearity is {min_nl}, theory max nonlinearity is {max_nonlinearity(S_N)}")
###########################################################
def sbox_fixed_points(S):
fps = []
for x in range(S_SIZE):
if S[x] == x:
fps.append(hex(x))
return fps
###########################################################
def flip_bit(x, i):
return x ^^ (1 << i)
def sbox_sac(S):
sac_matrix = matrix(QQ, S_M, S_N, 0)
for x in range(S_SIZE):
for i in range(S_M):
xp = flip_bit(x, i)
dx = S[xp] ^^ S[x]
for j in range(S_N):
if (dx >> j) & 1:
sac_matrix[i, j] += 1
# Normalize to probability
sac_matrix = sac_matrix / S_SIZE
return sac_matrix
def sbox_check_pck(S, k):
bool_funcs = []
bf_satisfy_pcks = []
for i in range(S_N):
bf = BooleanFunction([(S[x] >> i) & 1 for x in range(S_SIZE)])
bool_funcs.append(bf)
bf_satisfy_pcks.append(True)
for i, f in enumerate(bool_funcs):
w = f.walsh_hadamard_transform()
for a in range(1, S_SIZE):
if bin(a).count('1') <= k:
if w[a] != 0:
# D = f.derivative(a)
# if not D.is_balanced():
bf_satisfy_pcks[i] = False
break
r = bf_satisfy_pcks[i]
print(f"bf[{i}] satify PC({k}):{r}")
sbox_check_pck函数内注释部分为用布尔函数导数的方法,结果与使用Walsh谱的方法一致。当k=1时等价于SAC。运行脚本,输出如下
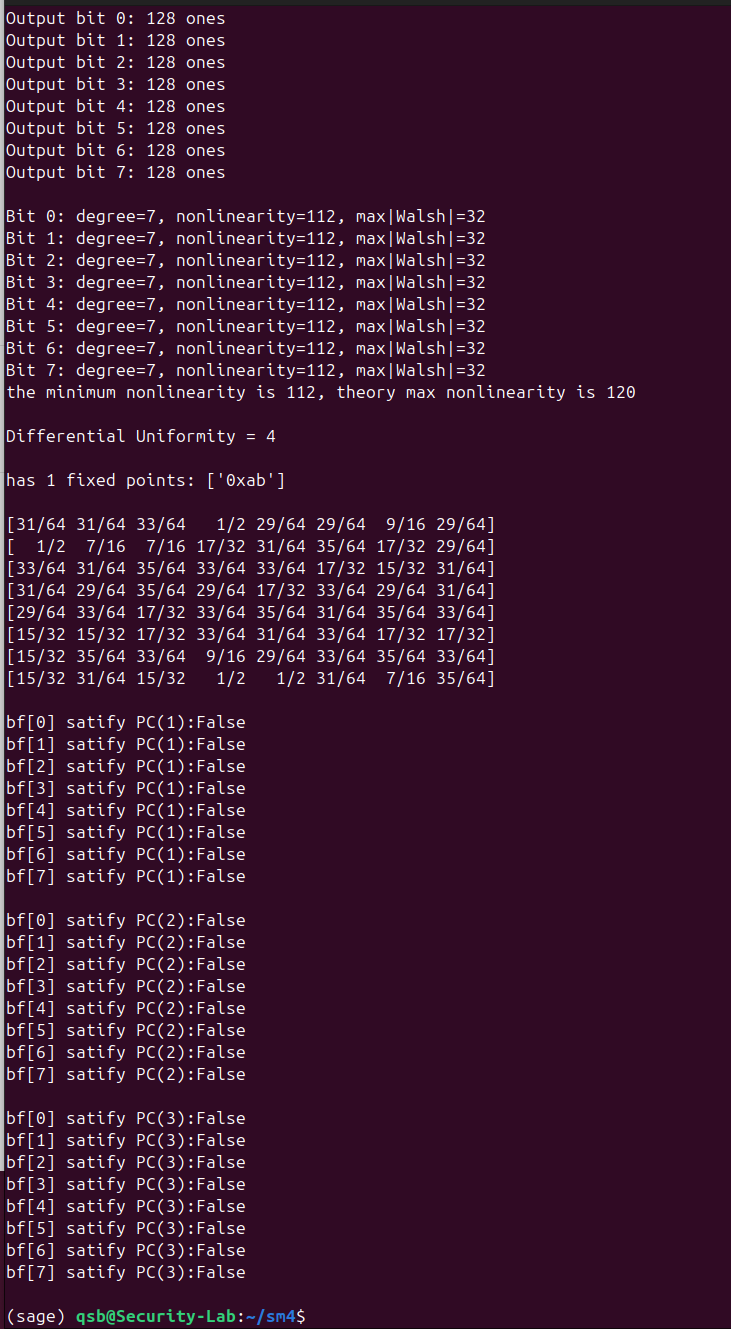
可以看出S盒不严格满足PC(k),SAC则是接近满足。其它指标良好。
S盒的差分分布表 差分分布表用于计算差分均匀度,及找到最大概率的差分特征。代码如下
def sbox_ddt_make(S):
ddt = {}
for dx in range(1, S_SIZE):
for x in range(S_SIZE):
dy = S[x] ^^ S[x^^dx]
ddt[(dx, dy)] = ddt.get((dx, dy), 0) + 1
return ddt
def sbox_differential_uniformity(DDT):
delta = max(DDT.values())
print("Differential Uniformity =", delta)
###########################################################
DDT = sbox_ddt_make(sbox_table)
sbox_dict_print(DDT); print()
sbox_differential_uniformity(DDT)
由于表格比较大,就不展示运行输出了
S盒的线性逼近表
用于找到最佳逼近(偏差最大)的输入输出线性掩码。代码如下
load("sbox.sage")
from sage.crypto.sbox import SBox
# Note: this method is rather slow
def sbox_lat_make(S):
lat = {}
D = 2^(S_M-1)
for a in range(S_SIZE):
v_a = V([(a >> i) & 0x1 for i in range(S_M-1, -1, -1)])
for b in range(S_SIZE):
v_b = V([(b >> i) & 0x1 for i in range(S_M-1, -1, -1)])
for x in range(S_SIZE):
v_x = V([(x >> i) & 0x1 for i in range(S_M-1, -1, -1)])
y = S[x]
v_y = V([(y >> i) & 0x1 for i in range(S_N-1, -1, -1)])
if v_a.dot_product(v_x) == v_b.dot_product(v_y):
lat[(a, b)] = lat.get((a,b), 0) + 1
lat[(a,b)] -= D
return lat
# LAT = sbox_lat_make(sbox_table)
# sbox_dict_print(LAT)
###########################################################
def sbox_best_lat_item(LAT):
max_val = 0
best_a, best_b = None, None
for a in range(1, 256):
for b in range(1, 256):
val = abs(LAT[a,b])
if val > max_val:
max_val = val
best_a, best_b = a, b
print(f"The best lat item is [0x{best_a:02x},0x{best_b:02x}], |bias| is {max_val/256}")
S = SBox(sbox_table)
LAT = S.linear_approximation_table()
print(LAT); print()
sbox_best_lat_item(LAT)
由于手写方法构造LAT比较慢,所以采用了内置的SBox实现,两种方法的输出数据是一致的
完整代码下载:
https://github.com/cq12yue/sm4_analysis
参考文献
[1] GB/T32907—2016 信息安全技术 SM4分组密码算法
[2] Algebraic Cryptanalysis of SMS4: Gr¨obner Basis Attack and SAT Attack Compared