有单向、双向、三向3种认证方式,前两者必须检查时间戳以防重放攻击,单向因为只有一个消息传递,如果仅靠一次性随机数是无法判断消息是否重放。双向有两个消息传递,一来一回,仅靠一次性随机数只能检测到发响应那方的重放。最后者则不必,可仅通过一次性随机数检测自己是否遭遇重放攻击,因为接收第二个消息的那方,通过判断第二个消息中随机数是否等于自己先前已发送第一个消息中的那个,若不等于则为重放,若等于则发第三个确认消息给对方,对方收到并判断确认消息中的随机数是否等于先前它已发送第二个消息中的随机数,若等于则说明第它收到的第一个消息的确是另一方发送的即非重放,否则为重放。因此三向认证可不必同步双方时钟。但正因为不强制检查时间戳而可能导致
中间人攻击:假设通信双方为A、B,中间人为C,攻击步骤如下
1. C与B认证时,发送先前已截获的A到B请求消息给B
2. 截获并存储B到A的响应消息x,但不转发,开始与A认证
3. 收到A的请求消息后,解密x取出其中的随机数Rb作为响应给A消息中的随机数,用自己私钥签署整个消息后发给A
4. 收到并转发A的确认消息给B
以上完成后,C就能冒充A与B通信了。一种简单的改进方法是先用对方的公钥加密消息中的随机数,再用自己的私钥签署整个消息。关于网络协议的安全性分析,主流方法是形式化分析,可以借助相关工具来验证找出漏洞
posted @
2023-09-30 08:00 春秋十二月 阅读(527) |
评论 (0) |
编辑 收藏
1.
对于RSA,给定大整数n分解的一对素因子p和q,p或q是否素数决定不了安全性,但决定算法的正确性,也就是说p或q不能为合数,而安全性取决于n的位数及p、q的距离,n越大则难于素因子分解(因为素数测试是一个P问题,而因子分解是一个NP问题,其耗时是关于n的指数),|p - q|要大是为抵抗一种
特殊因子分解攻击,论证如下:由(p+q)
2/4 - n = (p+q)
2/4 - pq = (p-q)
2/4,若|p - q|小,则(p-q)
2/4也小,因此(p+q)
2/4稍大于n,(p+q)/2稍大于n
1/2即根号n。可得n的如下分解法:a) 先顺序检查大于n
1/2的每一整数x,直至找到一个x使得x
2 - n是某一整数y的平方;b) 再由x
2 - n = y
2 得 n = (x+y)(x-y)。另外,p - 1和q - 1都应有大素因子(所有因子皆是大素数),以抵抗可能的
重复加密攻击(重复加密较少步后可恢复出明文)
2.
对于DH密钥交换,通常选择阶为素数的有限循环(子)群,这时素数决定了安全性。因素数不能再因子分解,故避免了针对阶为合数的质因子分解且利用中国剩余定理求离散对数的(已知最好)攻击。具体讲就是为了防
index-calculus方法求解离散对数,底层循环群G的素数模p要足够大,长度1024位可实现80位安全等级,长度3072位可实现128位安全等级;另为了防
Pohlig-Hellman攻击,G的阶p-1必须不能因式分解为全部都是小整数的素数因子,且为了p-1的每个因子构成的子群防
baby-step giant-step或
Pollards's rho攻击,要求对80位安全等级而言,p-1的最小素因子必须至少为160位,而对128位安全等级,其至少为256位
3.
对于Hash函数,安全性要求有三点:第一是单向性,由于压缩函数理论上存在碰撞,因此单向性是指计算不可行,为什么要单向性?因为若不单向,则可从结果比如签名逆出原文消息;第二是抗弱冲突性即
第1类生日攻击,计算不可行;第三是抗强冲突性即
第2类生日攻击,计算不可行。这三点要求,取决于压缩函数是否能抗差分、线性等密码分析
4. 周知
Shamir门限方案基于多项式的拉格朗日插值公式,普遍的设计采用GF(q)域上的多项式,秘密s为f(0),q是一个大于n的大素数(n是s被分成的部分数)。正常来讲,参与者个数必须至少是设计时的k,才能恢复出正确的s。如果个数少于k比如k-1,则只能猜测s0=f(0)以构建第k个方程,那么恢复得到的多项式g(x)等同设计时的多项式f(x)的概率是1/q。因为g(x)的项系数可以看作关于s0的同余式即h(s0)=(a+b*s0)mod q的形式,因q为素数,故依模剩余系遍历定理,当s0取GF(q)一值时,则h(s0)唯一对应另一值。所以h(s0)等于f(0)的概率为1/q。由此可见,当q取80位以上,敌手攻击概率不大于1/2
80,这已经很低了。这种门限方案如同RSA加密,再次佐证了素数越大安全性越高
5.
PGP是密码学经典应用,体现在首先支持保密与认证业务的正交,即独立或组合,且组合时按认证、压缩、加密的顺序,这个顺序是经考究有优势的;其次会话密钥是一次性的,由安全伪随机数生成器生成,且按公钥加密;最后使用自研的密钥环与信任网解决公钥管理问题。理论本质上,PGP提供的是一种保密认证业务的通用框架,因为具体的对称加密算法、随机数生成、公钥算法,都可依需要灵活选配扩展。PGP有两个问题跟组合与概率相关,一个是算密钥环N个公钥中,密钥ID(64位)至少有两个重复的概率?设所求概率为p,先算任意两个不重复的概率q,令m=2
64,则q=m!/((m-N)!*m
N),则p=1-q,不难看出,N越小则q越大则p越小,因实际应用N<<m,故p非常小可忽略,即PGP取公钥中最低64有效位作密钥ID,是可行的。另一个是签名摘要暴露了前16位明文,对哈希函数安全的影响有多大?这问题意思应该是敌手拿到消息后但没发送方的私钥作签名,只能穷举变换原消息并求哈希值,使之与消息摘要剩余位组相等。这本质是求
两类生日攻击碰撞概率大于0.5时所需的输入量。在仅认证模式中,抗弱碰撞计算量降低为原来的1/2
16,抗强碰撞计算量至少降低为原来的1/2
8。另外,考虑到这16位明文可能的特殊性,有没更快的代数攻击,需进一步研究
posted @
2023-09-28 08:04 春秋十二月 阅读(3103) |
评论 (0) |
编辑 收藏posted @
2023-09-26 16:47 春秋十二月 阅读(2214) |
评论 (0) |
编辑 收藏
周知编译原理龙书阐述的基本块指令调度算法,它所使用的空的资源预约表RTD与每个指令的资源预约表RT,可以看作二维矩阵,行表示时钟周期、列表示cpu资源,其定位的元素值1表示占用/预约,0表示空闲/非预约。前者是随周期递增而动态扩大的矩阵,后者是固定尺寸(维数)的矩阵(指令花费周期与每周期预约资源皆已知)。在调度时,按带优先级比如关键路径的拓扑排序基本块内的指令,顺序选取一条指令Inst,计算每前驱发射周期加延迟的结果tmp,取所有tmp的最大值tmax作为Inst的发射周期,再判断处理器资源是否可用,即RTD和RT作
与运算,得到一个新矩阵RTN,若RTN为
全零矩阵则tmax为Inst的最终发射周期,否则递增tmax再做矩阵与运算,直至得到全零矩阵。最后更新RTD,即RTD与RT作
或运算结果存于RTD。重复上述过程直到基本块末尾。
综上不难看出,如果一个基本块很大比如有1000条指令,平均每指令花2个周期,则RTD需要2000个条目,若一条目即矩阵每行占用32字节(256种资源数),则总量约64k。当然这对于现代内存体量来说不算什么,但可以有更好的节省内存的做法:RTD尺寸其实可以相对固定,其上限为基本块中耗费周期最多指令的周期的一个大于1常数因子倍(为兼顾指令并行性),这样一来就要增加当指令完成时(当前指令发射周期大于前一条的终止周期时复位前一条指令的RTD)从发射周期处复位RTD即作一个矩阵反运算的操作,其它步骤对应的矩阵与、矩阵或运算的操作保留不变。另由于RTD固定了尺寸,因此发射周期递增后要取模
【备注】以上是我针对简单机器模型(每种资源数量仅一个,比如整数运算单元1个,内存访问单元1个,浮点运算单元1个)用布尔矩阵作的优化。如果是复杂的超标量机器即每种资源数有多个,那么只需修改如下:布尔矩阵换成整数矩阵;新增一个机器资源可用总数整数矩阵RDA(单列资源数同值),布尔矩阵与运算换成加法并与RDA比较,若大于RDA则递增tmax;布尔矩阵或运算换成加法;布尔矩阵反运算换成减法,RTD减RT存于RTD
posted @
2023-09-23 12:14 春秋十二月 阅读(428) |
评论 (0) |
编辑 收藏曾因朋友问到监控,致使我探究了kretprobe的实现,想到编译中的尾调用优化,作个小结
1. kretprobe_trampoline_holder该跳转函数无参是必须的或说最好的通用设计,因为替换返回地址是非正常程序流程,即被探测函数的调用者无感知,不存在为跳转函数准备入参。若要设计传参且只读,则不会破坏被探测函数调用者的上下文,但跳转函数内部流程怎么用参数是个问题,这需要一种约定
2. 跳转函数为调用trampoline_handler准备入参,即在栈上构造一个(不完整的)pt_regs,再把它地址即栈顶赋给rdi,rdi是x86_64上传入第一参数使用的寄存器,同时预留一个栈单元存放原返回地址(为什么要预留?因为被探测函数返回时,其调用者存放返回地址的栈空间被释放了,所以得在跳转函数内造一个)。由于trampoline_handler内调到用户自定义handler而传入pt_regs,因此自定义handler内要注意最好别改动pt_regs,否则会破坏被探测函数调用者的上下文
posted @
2023-09-13 02:26 春秋十二月 阅读(416) |
评论 (0) |
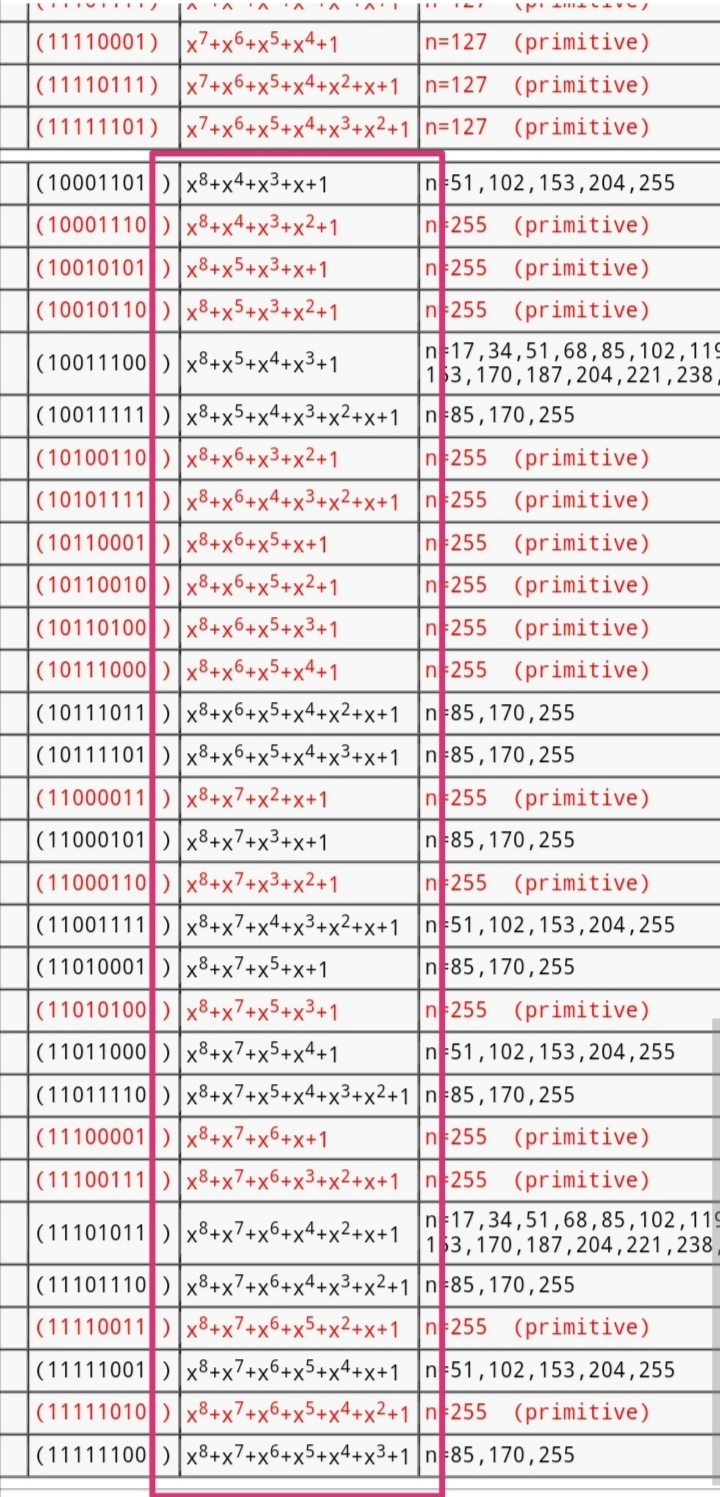
编辑 收藏有理数域的本原多项式与有限域的本原多项式定义不同,前者不要求不可约(由高斯引理知两个本原多项式的乘积还是本原),后者则必须不可约(确保生成的有限域其每个元素有逆元)。aes基于有限域F{0,1}设计,故使用的模8次多项式不可约
P(x)=x^8+x^4+x^3+x+1,但不是本原多项式,因为它的阶是51而非255。有限域次数为8的本原多项式有16个、不可约多项式有30个(由莫比乌斯反演推出),具体多项式影响s盒与列混合操作的实现。不可约加之0的逆元规定为0,保证正确加解密。若0的逆元规定为非0比如x,则导致x有两个逆元,便违反了逆元唯一性,除非s盒不用有限域设计。逆元等于其自身的非0元素只有1,原因可类比模素数二次剩余的求解
posted @
2023-09-13 02:00 春秋十二月 阅读(498) |
评论 (0) |
编辑 收藏1. 若DFA D是用子集构造法从NFA N构造出来的,则L(D)=L(N)
2. 一个语言L被某个DFA接受,当且仅当被某个NFA接受
3. 一个语言L被某个£-NFA接受,当且仅当被某个DFA接受
4. 若对于某个DFA A,L=L(A),则存在一个正则表达式R使得L=L(R)
5. 每一个用正则表达式定义的语言也可用有穷自动机定义
6. 若通过填表算法不能区分两个状态,则它们是等价的
7. DFA的状态等价性是传递的
8. 若对于DFA每个状态q及与q等价的所有状态组成块,则不同的状态块形成状态集合的划分。也就是说,每个状态恰好属于一个块,同一块中的所有成员都是等价的,从不同块中选择的状态对都不是等价的
9. 根据等价状态划分算法最小化DFA D得到的DFA M是唯一的。也就是说,不存在其它等价于D的DFA N,其状态数比M少
----------------------------------------------------------------------------------------
10. 对于正则表达式,空集是并运算的单位元、连接运算的零元,空串是连接运算的单位元
11. 若L和M都是正则语言,则L和M的并、交、差也是
12. 若L是字母表T上的正则语言,则~L=T*—L也是
13. 若L是正则语言,则L的反转也是
14. 若L是字母表T上的正则语言,h是T上的一个同态,则h(L)也是正则的
15. 若h是字母表A到字母表T的同态,且L是T上的正则语言,则逆同态h^-1(L)也是正则的
posted @
2023-09-09 08:11 春秋十二月 阅读(1213) |
评论 (0) |
编辑 收藏1. 空性:对于R,若给定形式是自动机比如£-NFA,则等价于判定能否从初始状态到达接受状态,这需计算可达状态集合,若任一接受状态在里面,则为非空,否则为空。耗时不超过O(n^2),n为自动机的状态数。若给定形式是正则表达式,则可先转为£-NFA,再计算可达状态集合,如此增多转化时间O(s),s为正则表达式的长度。也可不转为自动机,直接根据基础归纳规则用递推法判定,耗时为O(s)。 对于CFL,等价于判定开始符号是否为产生的,若是则非空,否则为空。如直接用产生变元的基础归纳法计算,那耗时O(n^2),n为文法G的规模,接近变元的个数。一个改进的算法实现,预先建立以变元为索引的数组、每个变元的链接(产生式内链接、产生式间链接),则耗时O(n)
2. 成员性:设串w的长度为n。对于R,等价于判定自动机能否接受w,若给定形式是DFA,则耗时O(n)。若给定形式是NFA,则耗时O(n*s^2),s为状态数,如NFA有£转移,那需先计算它的闭包,耗时增多O(s^2),可见总耗时还是O(n*s^2)。若给定形式是正则表达式,则先转为NFA,耗时增多O(r),r为表达式的长度。 对于CFL,等价于判定从文法G的开始符号S能否推导出w,一般用CYK算法构造产生式三角表,再查看S是否属于表的顶点集合,若属于则能推导出w,否则不能,耗时为O(n^3)
posted @
2023-09-09 08:09 春秋十二月 阅读(157) |
评论 (0) |
编辑 收藏因为一个整数p,若检测为合数,这永远是真命题;而检测为素数,这命题只以较大概率成立。 可构造一种NP检测算法,步骤如下:
1. 猜测p(位长度n)的因子列表{p1,p2,…pi},这是非确定的,每个分支耗时O(n)
2. 验证p1*p2*…pi?=p-1,耗时不超过O(n^2)
3. 若各因子乘积等于p-1,则用当前算法递归验证每个因子都是素数
4. 随机选择p最小剩余系内的一个数x,计算x^((p-1)/q) (q遍历上述列表经过步骤3验证过的素因子)是否都不同余于1模p,若是则必有x^(p-1)同余于1模p,则由指数整除p的欧拉数及费马小定理,知p为素数,考虑到有少量的合数也满足费马小定理,故需多次选择x重复验证,选择个数最多为log(p)
分析:本算法涉及的数论定理——设p是奇素数,p-1的所有素因子是q1,q2,…qs,那么g为原根的充要条件是,g^((p-1)/qj)不同余1模p,j=1,2…,s
结论:第3步可以看成递归调用树,每个顶点为待检测整数,其每个子结点为一个因子,则最多n层,每层至多耗时O(n^4),所以每个路径即检测p是否素数的非确定任一分支中,总耗时O(n^5)。 2002年,印度科学家发现素检测确定性多项式时间算法,于是从NP前进到了P
posted @
2023-09-09 08:07 春秋十二月 阅读(761) |
评论 (0) |
编辑 收藏为什么命题逻辑有效性是可判定的,而谓词逻辑有效性是不可判定的?
因为命题逻辑由有限个合式公式及原子命题构成,且原子命题的取值只有真、假两种,简单的判定方法是真值表穷举,其复杂度为指数级:2^N,N为原子命题数量。快速的方法是先转成合取范式(输入是由否定、而且、或者、蕴含四种连接词构成的语法正确的命题逻辑公式,经过对公式结构归纳作蕴含释放、否定原子、分配律变换三步处理,同时运用DAG优化:共享终止即叶子结点、删除冗余的测试结点、删除重复的有相同子图结构的内部结点,输出等价最小的合取范式),再检测合取范式的有效性(检查所有子句,若每个子句包含至少一个原子及其否定形式,则有效,否则因为存在一种真值指派使其为假而导致整个合取范式无效),其复杂度为多项式级:N*logN+N,N为公式长度。谓词逻辑基于命题逻辑扩展,添加了变元、函数、量词“所有”与“存在”,如果量词没有约束变元范围即定义域无限,那么函数值域也是无限的,另外可能引入的自由变元不受限制,这导致了解空间是无限的,所以不存在通用算法去判定任意谓词逻辑公式是否有效,具体证明可以用pcp归约,即构造一组特定的谓词逻辑公式,它是有效的当且仅当pcp实例有解,又已知pcp是不可判定的,故该特定谓词逻辑有效性是不可判定的,由于任意包括特定,所以谓词逻辑有效性是不可判定的
posted @
2023-09-09 08:05 春秋十二月 阅读(196) |
评论 (0) |
编辑 收藏