一、搜索引擎介绍
搜索引擎发展阶段:
1、分类目录的一代
2、文本检索的一代
3、链接分析的一代
4、用户中心的一代
搜索引擎的三个目标:更全,更快,更准
搜索引擎的3个核心问题:
1、用户真正的需求是什么,搜索词背后的含义
2、哪些信息是和用户需求真正相关,关键词匹配
3、哪些信息是用户可以依赖的,返回给用户重要的,可依赖的网页
优秀的云存储与云计算机平台已经成为大型商业搜索引擎的核心竞争力
posted @
2013-09-05 14:27 胡满超 阅读(501) |
评论 (0) |
编辑 收藏
You need compile boost and add libs path in project or makefile.
Compile boost run:
bjam stage --toolset=msvc-10.0 link=static runtime-link=static threading=multi debug release
posted @
2013-08-20 15:52 胡满超 阅读(418) |
评论 (0) |
编辑 收藏http://blog.chinaunix.net/uid-23766031-id-2386460.html
死锁:一种情形,此时执行程序中两个或多个线程发生永久堵塞(等待),每个线程都在等待被 其他线程占用并堵塞了的资源。例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
gdb调试死锁的方法:
gdb
attach pid
thread apply all bt
找到_lll_lock_wait 锁等待的地方。
然后查找该锁被哪个线程锁住了。
例如:
查看哪个线程拥有互斥体(然后list代码,查看使用互斥变量的名称)
(gdb) print AccountA_mutex
$1 = {__m_reserved = 2, __m_count = 0, __m_owner = 0x2527,
__m_kind = 0, __m_lock
= {__status = 1, __spinlock = 0}}
(gdb) print 0x2527
$2 = 9511
(gdb) print AccountB_mutex
$3 = {__m_reserved = 2, __m_count = 0, __m_owner = 0x2529,
__m_kind = 0, __m_lock = {__status = 1, __spinlock = 0}}
(gdb) print 0x2529
$4 = 9513
(gdb)
从上面的命令中,我们可以看出AccontA_mutex是被线程 5(LWP 9511)加锁(拥有)的,而AccontB_mutex是被线程 3(LWP 9513)加锁(拥有)的。
posted @
2013-08-20 15:40 胡满超 阅读(1680) |
评论 (0) |
编辑 收藏1、能准确领会上级领导的意图和需求
2、能对任务进行分解,驱动下属完成任务
3、能够在资源有限的情况下,笼络下属,驾驭团队
posted @
2013-08-16 10:59 胡满超 阅读(476) |
评论 (0) |
编辑 收藏1、开展工作就事论事,在管理下属时不要纠缠于细节
2、把驱动自己做事,变成驱动团队做事
3、对任务和模块进行切割,把事情和责任分到人头
4、把“驱动员工,分派任务,检查进度”变成“分割责任,收集信息,帮助下属清除困难”
5、培训和开会必不可少,做培训和主持会议的水平是领导者重点培养的核心技能
posted @
2013-08-08 15:58 胡满超 阅读(482) |
评论 (0) |
编辑 收藏
VC控制台使用CSocket要点:
1、在Stdafx.h中加入#include "afxsock.h"
2、在CPP中加入
if (!AfxSocketInit())
{
_tprintf(_T("Fatal Error: Socket initialization failed\n"));
return 1 ;
}
3、在工程生成的时候支持MFC是必须的步骤
做上上述几点在Debug版本调用CSocket::Create函数的时候就不会出现Assert了
posted @
2013-06-27 14:45 胡满超 阅读(417) |
评论 (0) |
编辑 收藏
最使用VC编写base64的程序,找了半天发现ATL本身就提供此功能,以下几个函数就可以满足常见需要:
int Base64EncodeGetRequiredLength(
int nSrcLen, DWORD dwFlags=ATL_BASE64_FLAG_NONE){

}
int Base64DecodeGetRequiredLength(
int nSrcLen)
throw(){
}
BOOL Base64Encode( _In_count_(nSrcLen)
const BYTE *pbSrcData, _In_
int nSrcLen, _Out_z_cap_post_count_(*pnDestLen, *pnDestLen) LPSTR szDest, _Inout_
int *pnDestLen, _In_ DWORD dwFlags = ATL_BASE64_FLAG_NONE)
throw(){
}
BOOL Base64Decode(LPCSTR szSrc,
int nSrcLen, BYTE *pbDest,
int *pnDestLen)
throw(){
}
posted @
2013-05-09 13:32 胡满超 阅读(689) |
评论 (0) |
编辑 收藏 1 std::vector<int> vec;
2 vec.push_back(1);
3 vec.push_back(2);
4 vec.push_back(3);
5 vec.push_back(4);
6 vec.push_back(5);
7 vec.push_back(6);
8 vec.push_back(7);
9 vec.push_back(8);
10
11 std::vector<int>::iterator ite = vec.begin();
12 while (ite != vec.end())
13 {
14 if (*ite == 2)
15 {
16 ite = vec.erase(ite);
17 }
18 else
19 {
20 printf("%d\n", *ite);
21 ++ite;
22 }
23 }
posted @
2013-04-22 14:05 胡满超 阅读(342) |
评论 (0) |
编辑 收藏多线程在访问类不同对象的成员函数时,是否需要同步?如果不需要是为什么呢?
答:不需要,因为类的成员函数在程序的代码段,在调用类的成员函数时,会传入对象this指针,不同对象的this指针不同。代码段访问的函数都在数据段或堆栈段,只要数据段与堆栈段地址不存在访问竟态,访问就是线程安全的。
posted @
2013-02-01 16:09 胡满超 阅读(639) |
评论 (0) |
编辑 收藏posted @
2012-12-26 17:08 胡满超 阅读(3193) |
评论 (0) |
编辑 收藏
题目描述:
一个循环有序数组(如:3,4,5,6,7,8,9,0,1,2),不知道其最小值的位置,要查找任一数值的位置。要求算法时间复杂度为log2(n)。
问题分析:
我们可以把循环有序数组分为左右两部分(以mid = (low+high)/ 2为界),由循环有序数组的特点知,左右两部分必有一部分是有序的,我们可以找出有序的这部分,然后看所查找元素是否在有序部分,若在,则直接对有序部分二分查找,若不在,对无序部分递归调用查找函数。
代码如下:
#include <iostream>
using namespace std;
int binarySearch(int a[],int low,int high,int value) //二分查找
{
if(low>high)
return -1;
int mid=(low+high)/2;
if(value==a[mid])
return mid;
else if(value>a[mid])
return binarySearch(a,mid+1,high,value);
else
return binarySearch(a,low,mid-1,value);
}
int Search(int a[],int low,int high,int value) //循环有序查找函数
{
int mid=(low+high)/2;
if(a[mid]>a[low]) //左有序
{
if(a[low]<=value && value<=a[mid] ) //说明value在左边,直接二分查找
{
return binarySearch(a,low,mid,value);
}
else //value在右边
{
return Search(a,mid+1,high,value);
}
}
else //右有序
{
if(a[mid]<=value && value<=a[high])
{
return binarySearch(a,mid,high,value);
}
else
{
return Search(a,low,mid-1,value);
}
}
}
int main()
{
int a[]={3,4,5,6,7,8,9,0,1,2};
cout<<Search(a,0,9,0)<<endl;
return 0;
}
posted @
2012-12-26 16:15 胡满超 阅读(513) |
评论 (0) |
编辑 收藏
By unanao
<sunjianjiao@gmail.com>
一、什么是大小端问题
(From《Computer Systems,A Programer's Perspective》)在几乎所有的机器上,多字节对象被存储为连续的字节序列,对象的地址为所使用字节序列中最低字节地址。
小端:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,这种最低有效字节在最前面的表示方式被称为小端法(little endian) 。这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
大端:某些机器则按照从最高有效字节到最低有效字节的顺序储存,这种最高有效字节在最前面的方式被称为大端法(big endian) 。这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567. 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
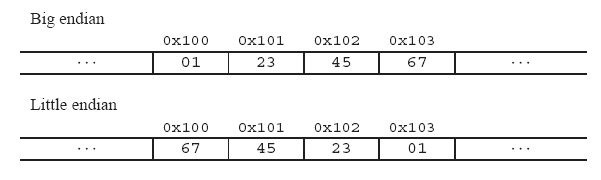
二、为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模 式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
三、如何区分大小端问题:
方法1:
#include <stdio.h>
int main(void)
{
int i = 1;
unsigned char *pointer;
pointer = (unsigned char *)&i;
if(*pointer)
{
printf("litttle_endian");
}
else
{
printf("big endian\n");
}
return 0;
}
C中的数据类型都是从内存的低地址向高地址扩展,取址运算"&"都是取低地址。小端方式中(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0。大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i,则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
方法2:
#include <stdio.h>
int main(void)
{
union {
short a;
char ch;
} u;
u.a = 1;
if (u.ch == 1)
{
printf("Littel endian\n");
}
else
{
printf("Big endian\n");
}
}
利用联合体的特点,数据成员共享内存空间,union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
四、需要考虑大小端(字节顺序)的情况
1、所写的程序需要向不同的硬件平台迁移,说不定哪一个平台是大端还是小端,为了保证可移植性,一定提前考虑好。
2. 在不同类型的机器之间通过网络传送二进制数据时。 一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反之时,接受程序会发现,字(word)里的字节(byte)成了反序的。为了避免这类问 题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接受方机器则将网络标准转换为它的内部标准。
3. 当阅读表示整数的字节序列时。这通常发生在检查机器级程序时,e.g.:反汇编得到的一条指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
3. 当编写强转的类型系统的程序时。如写入的数据为u32型,但是读取的时候却是char型的。如:0x1234, 大端读取为12时,小端独到的是34。
六、提高程序的可移植性
使用宏编译
#ifdef LITTLE_ENDIAN
//小端的代码
#else
//大端的代码
#endif
七、大、小端之间的转换
1、小端转换为大端
#include <stdio.h>
void show_byte(char *addr, int len)
{
int i;
for (i = 0; i < len; i++)
{
printf("%.2x \t", addr[i]);
}
printf("\n");
}
int endian_convert(int t)
{
int result;
int i;
result = 0;
for (i = 0; i < sizeof(t); i++)
{
result <<= 8;
result |= (t & 0xFF);
t >>= 8;
}
return result;
}
int main(void)
{
int i;
int ret;
i = 0x1234567;
show_byte((char *)&i, sizeof(int));
ret = endian_convert(i);
show_byte((char *)&ret, sizeof(int));
return 0;
}
posted @
2012-12-26 16:06 胡满超 阅读(961) |
评论 (0) |
编辑 收藏转自:http://www.fredosaurus.com/notes-cpp/misc/random-shuffle.html
// File : misc/random/deal.cpp - Randomly shuffle deck of cards.
// Illustrates : Shuffle algorithm, srand, rand.
// Improvements: Use classes for Card and Deck.
// Author : Fred Swartz 2003-08-24, shuffle correction 2007-01-18
// Placed in the public domain.
#include <iostream>
#include <cstdlib> // for srand and rand
#include <ctime> // for time
using namespace std;
int main() {
int card[52]; // array of cards;
int n; // number of cards to deal
srand(time(0)); // initialize seed "randomly"
for (int i=0; i<52; i++) {
card[i] = i; // fill the array in order
}
while (cin >> n) {
//--- Shuffle elements by randomly exchanging each with one other.
for (int i=0; i<(52-1); i++) {
int r = i + (rand() % (52-i)); // Random remaining position.
int temp = card[i]; card[i] = card[r]; card[r] = temp;
}
//--- Print first n cards as ints.
for (int c=0; c<n; c++) {
cout << card[c] << " "; // Just print number
}
cout << endl;
}
return 0;
}
posted @
2012-12-26 15:59 胡满超 阅读(614) |
评论 (0) |
编辑 收藏转自:http://blog.csdn.net/fuyangchang/article/details/5637464
wiki地址http://en.wikipedia.org/wiki/Hamming_distance
在信息领域,两个长度相等的字符串的海明距离是在相同位置上不同的字符的个数,也就是将一个字符串替换成另一个字符串需要的替换的次数。
例如:
- "toned" and "roses" is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
对于二进制来说,海明距离的结果相当于 a XOR b 结果中1的个数。
python代码如下
def hamming_distance(s1, s2):
assert len(s1) == len(s2)
return sum(ch1 != ch2 for ch1, ch2 in zip(s1, s2))
print (hamming_distance("gdad","glas"))
结果是2
C语言代码如下
unsigned hamdist(unsigned x, unsigned y)
{
unsigned dist = 0, val = x ^ y;
// Count the number of set bits
while(val)
{
++dist;
val &= val - 1;
}
return dist;
}
int main()
{
unsigned x="abcdcc";
unsigned y="abccdd";
unsigned z=hamdist(x,y);
printf("%d",z);
}
posted @
2012-12-26 15:49 胡满超 阅读(690) |
评论 (0) |
编辑 收藏
摘要: 转自:http://www.codinglabs.org/html/theory-of-mysql-index.htmlMySQL索引背后的数据结构及算法原理摘要本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。为了避免...
阅读全文
posted @
2012-12-21 10:38 胡满超 阅读(380) |
评论 (0) |
编辑 收藏搜索质量评估是搜索技术研究的基础性工作,也是核心工作之一。评价(Metrics)在搜索技术研发中扮演着重要角色,以至于任何一种新方法与他们的评价方式是融为一体的。
搜索引擎结果的好坏与否,体现在业界所称的在相关性(Relevance)上。相关性的定义包括狭义和广义两方面,狭义的解释是:检索结果和用户查询的相关程度。而从广义的层面,相关性可以理解为为用户查询的综合满意度。直观的来看,从用户进入搜索框的那一刻起,到需求获得满足为止,这之间经历的过程越顺畅,越便捷,搜索相关性就越好。本文总结业界常用的相关性评价指标和量化评价方法。供对此感兴趣的朋友参考。
Cranfield评价体系
A Cranfield-like approach这个名称来源于英国Cranfield University,因为在二十世纪五十年代该大学首先提出了这样一套评价系统:由查询样例集、正确答案集、评测指标构成的完整评测方案,并从此确立了“评价”在信息检索研究中的核心地位。
Cranfield评价体系由三个环节组成:
- 抽取代表性的查询词,组成一个规模适当的集合
- 针对查询样例集合,从检索系统的语料库中寻找对应的结果,进行标注(通常人工进行)
- 将查询词和带有标注信息的语料库输入检索系统,对系统反馈的检索结果,使用预定义好的评价计算公式,用数值化的方法来评价检索系统结果和标注的理想结果的接近程度
查询词集合的选取
Cranfield评价系统在各大搜索引擎公司内有广泛的应用。具体应用时,首先需要解决的问题是构造一个测试用查询词集合。
按照Andrei Broder(曾在AltaVista/IBM/Yahoo任职)的研究,查询词可分为3类:寻址类查询(Navigational)、信息类查询(Informational)、事务类查询(Transactional)。对应的比例分别为
Navigational : 12.3% Informational : 62.0% Transactional : 25.7%
为了使得评估符合线上实际情况,通常查询词集合也会按比例进行选取。通常从线上用户的Query Log文件中自动抽取。
另外查询集合的构造时,除了上述查询类型外,还可以考虑Query的频次,对热门query(高频查询)、长尾query(中低频)分别占特定的比例。
另外,在抽取Query时,往往Query的长短也是一个待考虑的因素。因为短query(单term的查询)和长Query(多Term的查询)排序算法往往会有一些不同。
构成查询集合后,使用这些查询词,在不同系统(例如对比百度和Google)或不同技术间(新旧两套Ranking算法的环境)进行搜索,并对结果进行评分,以决定优劣。
附图:对同一Query:“社会保险法”,各大搜索引擎的结果示意图。下面具体谈谈评分的方法。






Precision-recall(准确率-召回率方法)
计算方法
信息检索领域最广为人知的评价指标为Precision-Recall(准确率-召回率)方法。该方法从提出至今已经历半个世纪,至今在很多搜索引擎公司的效果评估中使用。
顾名思义,这个方法由准确率和召回率这两个相互关联的统计量构成:召回率(Recall)衡量一个查询搜索到所有相关文档的能力,而准确率(Precision)衡量搜索系统排除不相关文档的能力。(通俗的解释一下:准确率就是算一算你查询得到的结果中有多少是靠谱的;而召回率表示所有靠谱的结果中,有多少被你给找回来了)。这两项是评价搜索效果的最基础指标,其具体的计算方法如下。
Precision-recall方法假定对一个给定的查询,对应一个被检索的文档集合和一个不相关的文档集合。这里相关性被假设为二元的,用数学形式化方法来描述,则是:
A表示相关文档集合
A表示不相关集合
B表示被检索到的文档集合
B表示未被检索到的文档集合
则单次查询的准确率和召回率可以用下述公式来表达:

(运算符∩ 表示两个集合的交集。|x|符号表示集合x中的元素数量)
从上面的定义不难看出,召回率和准确率的取值范围均在[0,1]之间。那么不难想象,如果这个系统找回的相关越多,那么召回率越高,如果相关结果全部都给召回了,那么recall此时就等于1.0。
| | 相关的 | 不相关 |
被检索到 | A∩ B | A∩ B |
未被检索到 | A∩B | A∩B |
Precision-Recall曲线
召回率和准确率分别反映了检索系统的两个最重要的侧面,而这两个侧面又相互制约。因为大规模数据集合中,如果期望检索到更多相关的文档,必然需要“放宽”检索标准,因此会导致一些不相关结果混进来,从而使准确率受到影响。类似的,期望提高准确率,将不相关文档尽量去除时,务必要执行更“严格”的检索策略,这样也会使一些相关的文档被排除在外,使召回率下降。
所以为了更清晰的描述两者间的关系,通常我们将Precison-Recall用曲线的方式绘制出来,可以简称为P-R diagram。常见的形式如下图所示。(通常曲线是一个逐步向下的走势,即随着Recall的提高,Precision逐步降低)

P-R的其它形态
一些特定搜索应用,会更关注搜索结果中错误的结果。例如,搜索引擎的反作弊系统(Anti-Spam System)会更关注检索结果中混入了多少条作弊结果。学术界把这些错误结果称作假阳性(False Positive)结果,对这些应用,通常选择用虚报率(Fallout)来统计:

Fallout和Presion本质是完全相同的。只是分别从正反两方面来计算。实际上是P-R的一个变种。
再回到上图,Presion-Recall是一个曲线,用来比较两个方法的效果往往不够直观,能不能对两者进行综合,直接反映到一个数值上呢?为此IR学术界提出了F值度量(F -Measure)的方法。F-Measure通过Presion和Recall的调和平均数来计算,公式为:

其中参数λε(0,1)调节系统对Precision和Recall的平衡程度。(通常取λ=0.5,此时  )
)
这里使用调和平均数而不是通常的几何平均或算术平均,原因是调和平均数强调较小数值的重要性,能敏感的反映小数字的变化,因此更适合用来反映检索效果。
使用F Measure的好处是只需要一个单一的数字就可以总结系统的检索效果,便于比较不同搜索系统的整体效果。
P@N方法
点击因素
传统的Precision-Recall并不完全适用对搜索引擎的评估,原因是搜索引擎用户的点击方式有其特殊性,包括:
A 60-65%的查询点击了名列搜索结果前10条的网页; B 20-25%的人会考虑点击名列11到20的网页; C 仅有3-4%的会点击名列搜索结果中列第21到第30名的网页
也就是说,绝大部分用户是不愿意翻页去看搜索引擎给出的后面的结果。
而即使在搜索结果的首页(通常列出的是前10条结果),用户的点击行为也很有意思,我们通过下面的Google点击热图(Heat Map)来观察(这个热图在二维搜索结果页上通过光谱来形象的表达不同位置用户的点击热度。颜色约靠近红色表示点击强度越高):

从图中可以看出,搜索结果的前3条吸引了大量的点击,属于热度最高的部分。也就是说,对搜苏引擎来说,最前的几条结果是最关键的,决定了用户的满意程度。

康乃尔大学的研究人员通过eye tracking实验获得了更为精确的Google搜索结果的用户行为分析图。从这张图中可以看出,第一条结果获得了56.38%的搜索流量,第二条和第三条结果的排名依次降低,但远低于排名第一的结果。前三条结果的点击比例大约为11:3:2 。而前三条结果的总点击几乎分流了搜索流量的80%。
另外的一些有趣的结论是,点击量并不是按照顺序依次递减的。排名第七位获得的点击是最少的,原因可能在于用户在浏览过程中下拉页面到底部,这时候就只显示最后三位排名网站,第七名便容易被忽略。而首屏最后一个结果获得的注意力(2.55)是大于倒数第二位的(1.45),原因是用户在翻页前,对最后一条结果印象相对较深。搜索结果页面第二页排名第一的网页(即总排名11位的结果)所获得的点击只有首页排名第十网站的40%,与首页的第一条结果相比,更是只有其1/60至1/100的点击量。
因此在量化评估搜索引擎的效果时,往往需要根据以上搜索用户的行为特点,进行针对性的设计。
P@N的计算方法
P@N本身是Precision@N的简称,指的是对特定的查询,考虑位置因素,检测前N条结果的准确率。例如对单次搜索的结果中前5篇,如果有4篇为相关文档,则P@5 = 4/5 = 0.8 。
测试通常会使用一个查询集合(按照前文所述方法构造),包含若干条不同的查询词,在实际使用P@N进行评估时,通常使用所有查询的P@N数据,计算算术平均值,用来评判该系统的整体搜索结果质量。
N的选取
对用户来说,通常只关注搜索结果最前若干条结果,因此通常搜索引擎的效果评估只关注前5、或者前3结果,所以我们常用的N取值为P@3或P@5等。
对一些特定类型的查询应用,如寻址类的查询(Navigational Search),由于目标结果极为明确,因此在评估时,会选择N=1(即使用P@1)。举个例子来说,搜索“新浪网”、或“新浪首页”,如果首条结果不是 新浪网(url:www.sina.com.cn),则直接判该次查询精度不满足需求,即P@1=0
MRR
上述的P@N方法,易于计算和理解。但细心的读者一定会发现问题,就是在前N结果中,排序第1位和第N位的结果,对准确率的影响是一样的。但实际情况是,搜索引擎的评价是和排序位置极为相关的。即排第一的结果错误,和第10位的结果错误,其严重程度有天壤之别。因此在评价系统中,需要引入位置这个因素。
MRR是平均排序倒数(Mean Reciprocal Rank)的简称,MRR方法主要用于寻址类检索(Navigational Search)或问答类检索(Question Answering),这些检索方法只需要一个相关文档,对召回率不敏感,而是更关注搜索引擎检索到的相关文档是否排在结果列表的前面。MRR方法首先计算每一个查询的第一个相关文档位置的倒数,然后将所有倒数值求平均。例如一个包含三个查询词的测试集,前5结果分别为:
查询一结果:1.AN 2.AR 3.AN 4.AN 5.AR 查询二结果:1.AN 2.AR 3.AR 4.AR 5.AN 查询三结果:1.AR 2.AN 3.AN 4.AN 5.AR
其中AN表示不相关结果,AR表示相关结果。那么第一个查询的排序倒数(Reciprocal Rank)RR1 = 1/2=0.5 ;第二个结果RR2 = 1/2 = 0.5 ; 注意倒数的值不变,即使查询二获得的相关结果更多。同理,RR3= 1/1 = 1。 对于这个测试集合,最终MRR=(RR1+RR2+RR3)/ 3 = 0.67
然而对大部分检索应用来说,只有一条结果无法满足需求,对这种情况,需要更合适的方法来计算效果,其中最常用的是下述MAP方法。
MAP
MAP方法是Mean Average Precison,即平均准确率法的简称。其定义是求每个相关文档检索出后的准确率的平均值(即Average Precision)的算术平均值(Mean)。这里对准确率求了两次平均,因此称为Mean Average Precision。(注:没叫Average Average Precision一是因为难听,二是因为无法区分两次平均的意义)
MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题:
主题1有4个相关网页,主题2有5个相关网页。
某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;
对于主题2检索出3个相关网页,其rank分别为1,3,5。
对于主题1,平均准确率MAP计算公式为:
(1/1+2/2+3/4+4/7)/4=0.83。
对于主题2,平均准确率MAP计算公式为:
(1/1+2/3+3/5+0+0)/5=0.45。
则MAP= (0.83+0.45)/2=0.64。”
DCG方法
DCG是英文Discounted cumulative gain的简称,中文可翻译为“折扣增益值”。DCG方法的基本思想是:
- 每条结果的相关性分等级来衡量
- 考虑结果所在的位置,位置越靠前的则重要程度越高
- 等级高(即好结果)的结果位置越靠前则值应该越高,否则给予惩罚
我们首先来看第一条:相关性分级。这里比计算Precision时简单统计“准确”或“不准确”要更为精细。我们可以将结果细分为多个等级。比如常用的3级:Good(好)、Fair(一般)、Bad(差)。对应的分值rel为:Good:3 / Fair:2 / Bad:1 。一些更为细致的评估使用5级分类法:Very Good(明显好)、Good(好)、Fair(一般)、Bad(差)、Very Bad(明显差),可以将对应分值rel设置为:Very Good:2 / Good:1 / Fair:0 / Bad:-1 / Very Bad: -2
评判结果的标准可以根据具体的应用来确定,Very Good通常是指结果的主题完全相关,并且网页内容丰富、质量很高。而具体到每条

DCG的计算公式并不唯一,理论上只要求对数折扣因子的平滑性。我个人认为下面的DCG公式更合理,强调了相关性,第1、2条结果的折扣系数也更合理:

此时DCG前4个位置上结果的折扣因子(Discount factor)数值为:
i | log2 (i+1) | 1/log2 (i+1) |
1 | 1 | 1 |
2 | 1.59 | 0.63 |
3 | 2 | 0.5 |
4 | 2.32 | 0.43 |
取以2为底的log值也来自于经验公式,并不存在理论上的依据。实际上,Log的基数可以根据平滑的需求进行修改,当加大数值时(例如使用log5 代替log2),折扣因子降低更为迅速,此时强调了前面结果的权重。
为了便于不同类型的query结果之间横向比较,以DCG为基础,一些评价系统还对DCG进行了归一,这些方法统称为nDCG(即 normalize DCG)。最常用的计算方法是通过除以每一个查询的理想值iDCG(ideal DCG)来进行归一,公式为:

求nDCG需要标定出理想情况的iDCG,实际操作的时候是异常困难的,因为每个人对“最好的结果”理解往往各不相同,从海量数据里选出最优结果是很困难的任务,但是比较两组结果哪个更好通常更容易,所以实践应用中,通常选择结果对比的方法进行评估。
怎样实现自动化的评估?
以上所介绍的搜索引擎量化评估指标,在Cranfield评估框架(Cranfield Evaluation Framework)中被广泛使用。业界知名的TREC(文本信息检索会议)就一直基于此类方法组织信息检索评测和技术交流。除了TREC外,一些针对不同应用设计的Cranfield评测论坛也在进行进行(如 NTCIR、IREX等)。
但Cranfield评估框架存在的问题是查询样例集合的标注上。利用手工标注答案的方式进行网络信息检索的评价是一个既耗费人力、又耗费时间的过程,只有少数大公司能够使用。并且由于搜索引擎算法改进、运营维护的需要,检索效果评价反馈的时间需要尽量缩短,因此自动化的评测方法对提高评估效率十分重要。最常用的自动评估方法是A/B testing系统。
A/B Testing

A/B Testing系统
A/B testing系统在用户搜索时,由系统来自动决定用户的分组号(Bucket id),通过自动抽取流量导入不同分支,使得相应分组的用户看到的是不同产品版本(或不同搜索引擎)提供的结果。用户在不同版本产品下的行为将被记录下来,这些行为数据通过数据分析形成一系列指标,而通过这些指标的比较,最后就形成了各版本之间孰优孰劣的结论。
在指标计算时,又可细分为两种方法,一种是基于专家评分的方法;一种是基于点击统计的方法。
专家评分的方法通常由搜索核心技术研发和产品人员来进行,根据预先设定的标准对A、B两套环境的结果给予评分,获取每个Query的结果对比,并根据nDCG等方法计算整体质量。
点击评分有更高的自动化程度,这里使用了一个假设:同样的排序位置,点击数量多的结果质量优于点击数量少的结果。(即A2表示A测试环境第2条结果,如果A2 > B2,则表示A2质量更好)。通俗的说,相信群众(因为群众的眼睛是雪亮的)。在这个假设前提下,我们可以将A/B环境前N条结果的点击率自动映射为评分,通过统计大量的Query点击结果,可以获得可靠的评分对比。
Interleaving Testing
另外2003年由Thorsten Joachims 等人提出的Interleaving testing方法也被广泛使用。该方法设计了一个元搜索引擎,用户输入查询词后,将查询词在几个著名搜索引擎中的查询结果随机混合反馈给用户,并收集随后用户的结果点击行为信息.根据用户不同的点击倾向性,就可以判断搜索引擎返回结果的优劣,
如下图所示,将算法A和B的结果交叉放置,并分流量进行测试,记录用户点击信息。根据点击分布来判断A和B环境的优劣。

Interleaving Testing评估方法
Joachims同时证明了Interleaving Testing评价方法与传统Cranfield评价方法的结果具有较高的相关性。由于记录用户选择检索结果的行为是一个不耗费人力的过程,因此可以便捷的实现自动化的搜索效果评估。
总结
没有评估就没有进步——对搜索效果的量化评测,目的是准确的找出现有搜索系统的不足(没有哪个搜索系统是完美的),进而一步一个脚印对算法、系统进行改进。本文为大家总结了常用的评价框架和评价指标。这些技术像一把把尺子,度量着搜索技术每一次前进的距离。
感谢张凯峰对 本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家加入到InfoQ中文站用户讨论组中与我们的编辑和其他读者 朋友交流。
posted @
2012-12-19 11:03 胡满超 阅读(470) |
评论 (0) |
编辑 收藏转自:http://www.itivy.com/ivy/archive/2011/11/24/something-that-architecture-must-be-aware-of.html
对于大多数架构师而言,“可扩展性”在软件架构方面是最虚无缥缈的说法。这毫不奇怪,因为可扩展性正是如今软件设计领域最值得优先考虑的要素。然 而,计算机科学家们还无法了解一套单独的架构如何才能扩展至各类应用环境当中。相反,我们在数量繁多的方案中所设计出的可扩展性架构,往往以业界较为通用 的已知可扩展模式及个人偏好为标准。简单来讲,打造一套具备可扩展性的系统已经变得更像是一门艺术而不单单是技术。
我们常常会通过观摩杰作体会并学习艺术的精髓,而可扩展性也应该遵循同样的路线!
在这篇文章中,我将列出数款为大家所耳熟能详的可扩展性架构。通常情况下,架构师们完全可以借鉴已知的可扩展架构模式,进而创造出新的可扩展架构。
- LB (负载平衡器) + 无共享单位 - 该模型中包含一系列单元,各单元彼此间不共享任何内容,且一致指向一个将输入文讯按一定条件发往单元处的负载平衡器(这构成一个循 环,以负载等情况为基础)。每个单元可以是一个单独的节点或是紧密耦合的节点所构成的集群。用户可以使用DNS循环、硬件负载平衡器或者软件负载平衡器达 成负载平衡效果。创建一套负载均衡的层次结构,并在其中结合前面提到的各种负载平衡器也是可行的。在由Michael Stonebraker撰写的《 无共享体系架构实例 》一文中,专门讨论了此类架构。
- LB + 无状态节点 + 可扩展存储 - 传统的 三层式Web架构 使用的就是这种模型。该模型包括数个与可扩展存储交互的无状态节点以及一个分布于节点间负载中的负载平衡器。在这一模型中,存储通常作为限制因素存在,但NoSQL存储则可以利用这套模型创建出具备相当可扩展性的系统。
- 点对点架构 (分布式Hash列表 (简称DHT)以及内容寻址网络(简称CAN)) -这套模型提供了一些传统的 可扩展算法,这些算法的各个方面几乎全部按对数进行了等比例增加。举例来说,像Chord、Pastry(特指免费版)以及CAN都属于此类。而以 Cassandra为代表的、基于P2P架构的几款NoSQL系统也是其中的成员。《 展望P2P系统中的数据 》一文就深入探讨了这类模型的各种细节。
- 分布式队列 – 这种模型以将队列实施(即先进先出交付机制)作为网络服务处理为基础。该模型通过JMS队列而广泛得到采用。一般会遵循这种做法的有任务队列以及通过保持队列分级体系实现扩展性的任务队列版本,后者在负载无法及时处理时,任务会由低级层面向高级层面传递。
- 发布/订阅模式 - 一般用于通过网络向彼此发布订阅讯息。《 发布与订阅的多面性 》这一经典论文中详细的介绍这一模型,该模型方面最典型的例子即 NaradaBroker与 EventJava 。
- 小道消息与自然灵感式模型 - 这种模型源自日常生活中小道消息的传播途径,也就是每个节点将随机选择后续节点以交 换信息。正如现实生活中的实际反馈,这种八卦型算法在信息传播方面出奇地迅速。该模型的另一大分支则是受到生物学影响的启发式算法。自然世界中存在着大量 协调及扩展方面极为卓越的固有算法。举例来说,蚂蚁、人类以及蜜蜂等等,都能够以最简洁的交流方式协调好扩展性方面的需要。模型中的算法正是借鉴了这些实 际存在的现象。在论文《 从流行病的蔓延到分布式计算 》中对这种模型有着详尽的叙述。
- 地图缩小/数据流 - 这一概念首先由谷歌公司提出,地图缩小为工作的描述及执行提供了一套可扩展的模式。虽然内容 简单,但它仍然成为联机分析处理方面的首要处理模式。数据流则是一种更先进的方式,用来表达执行信息;而像Dryad及Pig这样的项目为数据流的执行提 供了可扩展的框架。论文《 地图缩小:大型集群上的简化数据处理 》中设置了专门的主题,详细讨论这一内容。Apache的Hadoop就是这种模型的代表性产品。
- 责任树形图 - 这种模型打破了递归问题的束缚,将整个流程以树状形式加以处理;每个父节点将工作下放至子节点。这种模型扩展性强,并已经被应用于数款可扩展性架构当中。
- 流处理 - 这种模型被用于处理源源不断的数据流及数据。这种处理方式通过网络中的处理节点获得支持(例如Aurora、Twitter Strom以及Apache S4等)。
- 可扩展存储 – 该模型的应用范围从数据库、NoSQL存储、服务注册到文件系统都有体现。 链接中的这篇文章 以可扩展性为切入点对其进行了深入讨论。
综上所述,可扩展性的实现只有三种方式,即:分布、缓存及异步处理。前文所提到的各种架构事实上都是把这三种方式进行不同组合并加以实施。而另一方 面,不利于可扩展性的因素,除了糟糕的编码本身,全局性协调也起到了重要的影响。简单来说,任何一种全局性协调都会限制系统的可扩展性。本文中所提到的各 种架构也只是在做好了本地性协调,而非全局性协调。
然而,将它们有机地结合起来以创建一套极具可扩展性的架构可不像说起来那么容易,除非我们能找到一种全新的扩展模式。不过经验告诉我们,比起搞一套全新的架构,采用为我们所熟知且更易驾驭的可扩展性解决方案永远是更好的选择。
posted @
2012-12-19 10:58 胡满超 阅读(571) |
评论 (0) |
编辑 收藏技术型企业即要关注财务指标和交付指标:产出
也要关注货架建设:技术积累,员工能力的提升和任职资格
保证产出的同时,保证技术积累和员工任职资格能力的提升是技术型企业必须解决的难题
技术型企业的组织建设的原则:
1、 有利于按产出线和专业分工
基于产出进行核算
突出资源线、专业线进行组织设计
在专业技术领域不增加的情况下,增加项目不增加部门,产出规模的扩展不会带来组织规模的扩张
2、 有利于建立员工按专业的职业生涯设计,建立个人专业发展方向
3、 有利于对产出按项目 方式进行管理和控制
4、 有利于按产出建立跨部门的团队,全流程、全要素地进行项目和产品开发
5、 有利于建立委员会对项目进行评审
6、 保证产品经理,市场经理,客户经理,项目经理在一线,能调动公司所有资源,为产品线能够快速响应客户负责
组织建设不一定一步到位,但活动必须到位,关键人才必须培养
技术型企业的活动分类:
一、规划类活动
系统部:产品规划
系统部:技术规划
市场部:市场规划
市场部:客户群规划
公司高层:产业链管理的规划
公司高层:资本动作的规划
公司高层:高层人才的引进计划和规划
公司高层:风险管理的评审机制
二、产出开发类活动
预研、产品开发、定制项目开发、解决方案
技术开发支撑产品开发
产品开发支撑解决方案开发
三、资源线的管理活动
支撑管理:财务管理,项目管理,质量管理,人力资源管理
支持产出管理:营销部,产品线管理,市场部
典型技术型企业组织结构:
1、 委员会:规划、评审、决策负责
2、 产出线:对产出负责,按照项目的方式动作
3、 资源线:对人的培养,成长,知识积累和职业通道负责
六大分离:
1、 技术开发和产品开发分离
技术体系的核心业务:
(1) 构建技术平台,形成技术储备,发现新的技术增长点
(2) 建立技术标准和技术规划,形成核心技术以主动引导客户,在技术上领先竞争对手,同步培养优秀的技术人员
产品体系的核心业务:
(1) 以成熟的技术和平台快速、低成本地满足客户要求
(2) 在周期,成本和可靠性及可生产性,可保障性上领先对手,在市场和财务指标上构建核心竞争力
预研体系的核心业务:
(1) 对未来的技术和产品进行探索和研究,形成企业的技术储备
(2) 提高企业技术领域的影响力
2、 市场体系和销售体系分离
引导研发和高水平的客户经理转入市场部进行市场需求和产品规划
3、 产出线与资源线分离
4、 决策与职能体系管理及职能体系执行分离
5、 系统设计与实现相对分离
鼓励公司高手参与规划和设计,保证研发质量,低水平研发人员从实现积累经验,逐步上升到系统级工程师,参与设计。避免低手做设计,高手救火的情况发生。
6、 开发与测试和验证分离
设立独立的测试部门和验证部门可以有效的保证产品的质量
完整的产出线要素:
1、 面向客户提供有外部收入或内部转换收入的项目或产品
2、 从需求到交付统一全程管理
3、 有一个项目总的责任人全程负责
4、 涉及产出的所有元素,研发,销售,市场,采购,生产及中试测试,以矩阵方式参与并为产出统一服务,由产出线进行统一绩效管理
产出线五种表现形态:
1、 产品开发项目
2、 预研项目
3、 技术平台开发项目
4、 定制项目
5、 管理项目:管理体系建设也可以立项,通过项目管理的方式来推进和完成
产出线的组织层次分为四层:
决策层:IRB,对项目资源策略负责
管理层:IPMT,对产品的市场成功和财务成功负责
执行层:PDT,对项目从立项到发布负责
维护服务层:LMT,对产品生命周期管理及更改负责
产品经理与项目经理的区别
1、 产品经理是一个固定的职位,项目经理是一个临时性的职位
2、 产品经理管理所有的产品版本,V版本,R版本,M版本,项目经理管理目前的R版本
3、 在新产品开发时,产品经理兼任项目经理
4、 产品经理对产品的全生命周期的管理负责,是例行职位,项目经理对产品开发全过程负责,是一个项目职位
5、 产品规模小时,产品经理兼任项目经理;规模大时,产品经理主要负责老产品推广,项目经理负责新产品开发,项目经理向产品经理汇报
资源经理与项目经理区别:
1、 项目经理对产出负责,资源经理对资源负责,对人的任职资格通道负责
2、 项目经理是临时职位,负责项目开发,对交付负责;资源经理是固定职位,负责人的培养,专业发展
3、 资源经理是一个资源池的管理者,项目经理从资源经理处承接资源,或委托资源经理承接开发任务
4、 资源经理管理人员的固定绩效,项目经理管理人员的变动绩效
实施矩阵管理必须具备的条件:
1、 企业要具备承诺文化
2、 产品线与资源线划分合理
3、 单项目管理和多项目管理分离,项目经理管单项目,项目管理部管理多项目
4、 三级计划体系结构清晰,层次合理
5、 项目流程清晰,大项目可以划分成多个小项目,实现资源分阶段投入和评审
6、 需求管理流程初步实现,保证一段时间内项目需求规划的准确性
矩阵管理三种模式:
强矩阵:参加项目的人直接由项目经理管理
弱矩阵:一个人同时参加两个以上的项目,汇报给资源经理,抄送给项目经理
混合矩阵:一部分参与强矩阵团队,一部分参与弱矩阵团队
不是所有的企业都要实施矩阵管理,实施矩阵管理必须完成一些基础建设
posted @
2012-12-18 14:44 胡满超 阅读(538) |
评论 (0) |
编辑 收藏企业典型的考核办法 | 缺少的配套措施 | 导致的结果 |
平衡记分卡、严格的KPI制度 | 没有考虑研发过程的难度与风险评估,尤其是技术攻关和技术探索 | 高手做高风险项目不如低手做低风险项目收益大,无法鼓励优秀的研发人员创新 |
实行矩阵管理,对项目进行考核,项目周期长,一个人长期承担多个项目开发 | 没有按阶段把大项目规划成小项目 | 绩效管理工作量巨大,绩效管理变成了简单应付 |
对研发人员进行强制分布 | 没有任职资格建设,没有规定行为准则,不先对项目进考核 | 业绩好的团队和业绩差的团队区别不大,影响了业绩好的团队的绩效管理 |
| 不进行财务成本考核 | 研发人员没有组织绩效,只注重个人能力的提升,钻研新技术,最终企业研发人员能力提升了,但是企业组织绩效没有提高 |
| | |
研发绩效需要区分以下误区:
1、 区分组织绩效和个人绩效,组织绩效主要是市场和财务的成功,个人绩效必须在组织绩效上进行分解
2、 组织绩效的首要任务是在老产品改进上的毛利率提升,其次才是新产品、新技术的开发
3、 将预研,产品开发和需求及规划人员的绩效考核进行区分,产品开发人员必须与当年所支撑的产品收入挂钩,预研人员可以与三年内预研成果转化成产品成果所带来的收入挂钩
4、 研发人员的能力,过程和结果及项目的关键点分别以不同的绩效手段管理和考核
5、 尽量将项目划分成一个个阶段,减少每个阶段的时间,使得一个人在一段时间内尽量承接的项目少,实现精力聚集的同时,减少绩效考核的工作量
6、 将产品维护工作与产品开发的工作分开,产品维护的项目按任务数进行考核,产品开发的项目按计划进度及质量要素考核
7、 建立任职资格,将不同层级的研发人员的考核模式与薪酬结构分开,低层次人员主要考核基本行为规范,中,高级人员的考核应该结合过程考核结果,高层次人员主要考核结果
8、 创新性的预研工作主要考核领军人物的任职资格
绩效管理的五种手段:
1、 任职资格:对员工的能力进行评价
2、 行为准则:每一个职位必做的相关工作职位要求活动的基本要求,PI(Performance Indicator);
3、 PCB:(Personal Business Commitments)主要对员工的过程进行评价,来自年度,季度计划,必须完成的一些工作
4、 KPI:(Key Performance Indicator)关键绩效指标,通常对组织进行考核,来自企业的发展战略财务指标、市场指标及必须要解决的问题,更多的是强调组织绩效,强调实现战略目标的挑战性指标
5、 KCP:(Key Control Point)对项目关键路径上的关键资源的活动进行绩效管理,以区分项目成功的贡献和风险
不同层级、不同类别的研发人员的考核手段:
1、 高层管理人员:KPI,KPC和任职资格
2、 预研人员:任职资格、KCP、PBC
3、 产品开发的高级别人员:KPI、任职资格、PBC
4、 产品开发的低级别人员:行为准则、任职资格、PBC
5、 研发体系的职能部门:最好不要考核KPI,主要考核其任职资格和行为准则及PBC
薪酬包:
1、 基本工资:任职资格
2、 扣款:行为准则
3、 月度/季度绩效资金:PBC
4、 年度绩效奖金:KPI
5、 项目特别奖励:KCP
组织绩效考核工具是KPI,承接单位为营销体系,研发体系。
KPI是组织考核工具,个人KPI必须建立在组织KPI的基础之上。
公司级KPI指标通常包括五类指标:
1、 销售收入及增长率
2、 新业务在销售中所占的比例
3、 人均创造利润空间及增长率
4、 核心技术平台上收入所占比重
5、 核心竞争力提升的四大指标:
(1) 产品收入、利润收入、区域收入及客户群收入结构的合理性
(2) 商业模式及产业链竞争能力的合理性
(3) 组织层次合理性及人员结构的合理性
(4) 高质量的快速的产品交付能力
任职资格管理:某公司的研发人员分级
一、基本条件:经历,学历,现职状况
二、参考项:绩效情况,品行
三、资格标准:业务活动,基本素质,知识技能
七级 | |
六级 | 完整的系统方案设计和需求分析的过程 |
五级 | 原型设计到工程设计到小批量设计到产品转产的过程经历 |
四级 | 市场的经历 |
三级 | 技术支持和售后服务的经历 |
二级 | 有测试的经历 |
一级 | |
KCP管理要点:
1、 是否在关键项目的关键路径上
2、 是否要付出个人额外的努力
3、 是否有独特贡献
4、 是否是关键资源
5、 是否冒一定的风险
6、 是否代表一定的价值导向
绩效管理结果分布:
工资、职位:对现在的肯定
资金:对过去的肯定
福利、补贴、带薪休假:公共福利
期权、股票、分红、培训、出国考察、导师制、岗位轮换:对未来肯定
posted @
2012-12-18 14:42 胡满超 阅读(1208) |
评论 (0) |
编辑 收藏技术型企业即要关注财务指标和交付指标:产出
也要关注货架建设:技术积累,员工能力的提升和任职资格
保证产出的同时,保证技术积累和员工任职资格能力的提升是技术型企业必须解决的难题
技术型企业的组织建设的原则:
1、 有利于按产出线和专业分工
基于产出进行核算
突出资源线、专业线进行组织设计
在专业技术领域不增加的情况下,增加项目不增加部门,产出规模的扩展不会带来组织规模的扩张
2、 有利于建立员工按专业的职业生涯设计,建立个人专业发展方向
3、 有利于对产出按项目 方式进行管理和控制
4、 有利于按产出建立跨部门的团队,全流程、全要素地进行项目和产品开发
5、 有利于建立委员会对项目进行评审
6、 保证产品经理,市场经理,客户经理,项目经理在一线,能调动公司所有资源,为产品线能够快速响应客户负责
组织建设不一定一步到位,但活动必须到位,关键人才必须培养
技术型企业的活动分类:
一、规划类活动
系统部:产品规划
系统部:技术规划
市场部:市场规划
市场部:客户群规划
公司高层:产业链管理的规划
公司高层:资本动作的规划
公司高层:高层人才的引进计划和规划
公司高层:风险管理的评审机制
二、产出开发类活动
预研、产品开发、定制项目开发、解决方案
技术开发支撑产品开发
产品开发支撑解决方案开发
三、资源线的管理活动
支撑管理:财务管理,项目管理,质量管理,人力资源管理
支持产出管理:营销部,产品线管理,市场部
典型技术型企业组织结构:
1、 委员会:规划、评审、决策负责
2、 产出线:对产出负责,按照项目的方式动作
3、 资源线:对人的培养,成长,知识积累和职业通道负责
六大分离:
1、 技术开发和产品开发分离
技术体系的核心业务:
(1) 构建技术平台,形成技术储备,发现新的技术增长点
(2) 建立技术标准和技术规划,形成核心技术以主动引导客户,在技术上领先竞争对手,同步培养优秀的技术人员
产品体系的核心业务:
(1) 以成熟的技术和平台快速、低成本地满足客户要求
(2) 在周期,成本和可靠性及可生产性,可保障性上领先对手,在市场和财务指标上构建核心竞争力
预研体系的核心业务:
(1) 对未来的技术和产品进行探索和研究,形成企业的技术储备
(2) 提高企业技术领域的影响力
2、 市场体系和销售体系分离
引导研发和高水平的客户经理转入市场部进行市场需求和产品规划
3、 产出线与资源线分离
4、 决策与职能体系管理及职能体系执行分离
5、 系统设计与实现相对分离
鼓励公司高手参与规划和设计,保证研发质量,低水平研发人员从实现积累经验,逐步上升到系统级工程师,参与设计。避免低手做设计,高手救火的情况发生。
6、 开发与测试和验证分离
设立独立的测试部门和验证部门可以有效的保证产品的质量
完整的产出线要素:
1、 面向客户提供有外部收入或内部转换收入的项目或产品
2、 从需求到交付统一全程管理
3、 有一个项目总的责任人全程负责
4、 涉及产出的所有元素,研发,销售,市场,采购,生产及中试测试,以矩阵方式参与并为产出统一服务,由产出线进行统一绩效管理
产出线五种表现形态:
1、 产品开发项目
2、 预研项目
3、 技术平台开发项目
4、 定制项目
5、 管理项目:管理体系建设也可以立项,通过项目管理的方式来推进和完成
产出线的组织层次分为四层:
决策层:IRB,对项目资源策略负责
管理层:IPMT,对产品的市场成功和财务成功负责
执行层:PDT,对项目从立项到发布负责
维护服务层:LMT,对产品生命周期管理及更改负责
产品经理与项目经理的区别
1、 产品经理是一个固定的职位,项目经理是一个临时性的职位
2、 产品经理管理所有的产品版本,V版本,R版本,M版本,项目经理管理目前的R版本
3、 在新产品开发时,产品经理兼任项目经理
4、 产品经理对产品的全生命周期的管理负责,是例行职位,项目经理对产品开发全过程负责,是一个项目职位
5、 产品规模小时,产品经理兼任项目经理;规模大时,产品经理主要负责老产品推广,项目经理负责新产品开发,项目经理向产品经理汇报
资源经理与项目经理区别:
1、 项目经理对产出负责,资源经理对资源负责,对人的任职资格通道负责
2、 项目经理是临时职位,负责项目开发,对交付负责;资源经理是固定职位,负责人的培养,专业发展
3、 资源经理是一个资源池的管理者,项目经理从资源经理处承接资源,或委托资源经理承接开发任务
4、 资源经理管理人员的固定绩效,项目经理管理人员的变动绩效
实施矩阵管理必须具备的条件:
1、 企业要具备承诺文化
2、 产品线与资源线划分合理
3、 单项目管理和多项目管理分离,项目经理管单项目,项目管理部管理多项目
4、 三级计划体系结构清晰,层次合理
5、 项目流程清晰,大项目可以划分成多个小项目,实现资源分阶段投入和评审
6、 需求管理流程初步实现,保证一段时间内项目需求规划的准确性
矩阵管理三种模式:
强矩阵:参加项目的人直接由项目经理管理
弱矩阵:一个人同时参加两个以上的项目,汇报给资源经理,抄送给项目经理
混合矩阵:一部分参与强矩阵团队,一部分参与弱矩阵团队
不是所有的企业都要实施矩阵管理,实施矩阵管理必须完成一些基础建设
posted @
2012-12-18 14:40 胡满超 阅读(447) |
评论 (0) |
编辑 收藏