摘要: IOCP(I/O Completion Port,I/O完成端口)是性能最好的一种I/O模型。它是应用程序使用线程池处理异步I/O请求的一种机制。在处理多个并发的异步I/O请求时,以往的模型都是在接收请求是创建一个线程来应答请求。这样就有很多的线程并行地运行在系统中。而这些线程都是可运行的,Windows内核花费大量的时间在进行线程的上下文切换,并没有多少时间花在线程运行上。再加上创建新线程的开销...
阅读全文
posted @
2011-07-13 16:19 胡满超 阅读(852) |
评论 (0) |
编辑 收藏转自:http://yinkai210.blog.163.com/blog/static/287483452009050256466/
大家在启动服务器时,有时正常启动有时又启动不了是怎么回事呢??那为什么关掉迅雷等软件就又好了呢??现在就来给大家讲解一下,

这些端口如果被其他程序占用就不能正常启动,比如有时启动时会提示WEB启动失败,其实就是80端口被占用了,而迅雷等下载软件恰恰就是占用了80端口,关掉就行了。但有时迅雷等都没有开也启动不了,那就是别的东西占用了,那怎么办呢?我来叫你查看端口并关掉的方法。
1.在开始--运行 里面输入cmd点回车,会出现运行窗口。
2.在提示符后输入netstat -ano回车,找到tcp 80端口对应的pid,比如1484.
3.ctrl+alt+del打开任务管理器,选进程,这里有很多正在运行的程序怎么找?别急点上面的 查看--选择列--在PID(进程标示符)前面打钩。好了,下面的进程前面都有了PID号码。这时上一步找到的PID就有用了,找到1484,比如PEER.EXE什么的,结束进程吧。这时再开服务器,看WEB可以启动了!
如上面的不清楚还有简明的:
假如我们需要确定谁占用了我们的80端口
1、Windows平台
在windows命令行窗口下执行:
C:\>netstat -aon|findstr "80"
TCP 127.0.0.1:80 0.0.0.0:0 LISTENING 2448
看到了吗,端口被进程号为2448的进程占用,继续执行下面命令:
C:\>tasklist|findstr "2448"
thread.exe 2016 Console 0 16,064 K
很清楚吧,thread占用了你的端口,Kill it
如果第二步查不到,那就开任务管理器,看哪个进程是2448,然后杀之即可。
如果需要查看其他端口。把 80 改掉即可
posted @
2011-05-03 11:20 胡满超 阅读(1070) |
评论 (7) |
编辑 收藏本文转自:http://blog.csdn.net/miromelo/archive/2010/04/04/5450460.aspx
笔者现在了解一种比较简单的方法,即:
修改CXXAPP中的InitInstance函数,将原来的模态对话框改为非模态对话框,及修改
view plaincopy to clipboardprint?
INT_PTR nResponse = dlg.DoModal();
INT_PTR nResponse = dlg.DoModal();
为
view plaincopy to clipboardprint?
dlg.Create(CModalHideDlg::IDD); //创建为非模态对话框
dlg.ShowWindow(SW_HIDE); //创建完毕后,可以设置对话框的显示方式,正常为“SW_SHOW”,
//在此,我们使用“SW_HIDE”将对话框隐藏,但是在进程列表中仍然可以看到
dlg.RunModalLoop(); //消息循环
dlg.Create(CModalHideDlg::IDD); //创建为非模态对话框
dlg.ShowWindow(SW_HIDE); //创建完毕后,可以设置对话框的显示方式,正常为“SW_SHOW”,
//在此,我们使用“SW_HIDE”将对话框隐藏,但是在进程列表中仍然可以看到
dlg.RunModalLoop(); //消息循环
还有其他一些朋友的方法:
有很多应用程序要求一起动就隐藏起来,这些程序多作为后台程序运行,希望不影响其他窗口,
往往只在托盘区显示一个图标。这些程序通常都是对话框程序,而对话框在初始化的过程上与SDI
、MDI的初始化是不同的,对话框只需要DoModule或者是CreateDialog等等对话框函数调用一次便
可,SDI、MDI则要好几步才行。这样看来,对话框在使用方法上面是隐藏了不少细节的,其中就
没有SDI、MDI所要求的ShowWindow(nCmdShow)这一步。因此对话框要想一运行就隐藏,并不是很
直接的。有一些方法可以做到这一点,下面我们就来看看几种方案。
1.定时器
最直观,又是最无奈的一个方法就是使用定时器。既然我们在对话框开始显示之前不能用ShowWin
dow(SW_HIDE)将其隐藏,那就给一个时间让它显示,完了我们在隐藏它。
方法:
1.在OnInitDialog()函数里设置定时器:(WINDOWS API里面响应消息WM_INITDIALOG)
SetTimer(1, 1, NULL);
2.添加处理WM_TIMER的消息处理函数OnTimer,添加代码:
if(nIDEvent == 1)
{
DeleteTimer(1);
ShowWindow(SW_HIDE);
}
这种方法的缺点是显而易见的,使用定时器,使得程序的稳定性似乎打一个折扣;窗口是要先显
示出来的,那么效果就是窗口闪了一下消失。
2.改变对话框显示状况
在对话框初始化时改变其显示属性可以让它隐藏起来。方法是调用SetWindowPlacement函数:
BOOL CDialogExDlg::OnInitDialog()
{
CDialog::OnInitDialog();
//DO something
WINDOWPLACEMENT wp;
wp.length=sizeof(WINDOWPLACEMENT);
wp.flags=WPF_RESTORETOMAXIMIZED;
wp.showCmd=SW_HIDE;
SetWindowPlacement(&wp);
return TRUE;
}
在需要显示时(通常是响应热键或者托盘图标的鼠标消息):
WINDOWPLACEMENT wp;
wp.length=sizeof(WINDOWPLACEMENT);
wp.flags=WPF_RESTORETOMAXIMIZED;
wp.showCmd=SW_SHOW;
SetWindowPlacement(&wp);
这样的效果很不理想:窗口显示在屏幕的左上角,并且是只有标题栏,要正常显示,还需加上如
下代码:
定义一个成员变量CRect rect;
在OnInitDialog()里面:
GetWindowRect(&rect);
在需要显示的地方:
SetWindowPos(&wndNoTopMost, wndRc.left, wndRc.top, wndRc.right, wndRc.bottom,
SWP_SHOWWINDOW);
CenterWindow();
即使这样,效果还是很差。
这种方法还有一个弊端是当程序开始运行并且隐藏起来后,原来激活的窗口变成了非激活状态了
,而当对话框显示出来后,对话框自身也是非激活状态的。
3.不绘制窗口
当对话框显示时将要响应消息WM_PAINT绘制客户区,相应消息WM_NCPAINT绘制窗口边框。我们在
窗口第一次自绘自身时隐藏窗口,可以收到比较良好的效果。由于窗口是先画窗口边框,所以我
们仅需处理WM_NCPAINT即可。代码如下:
添加WM_NCPAINT处理函数。
void CMyDialog::OnNcPaint()
{
static int i = 2;
if(i > 0)
{
i --;
ShowWindow(SW_HIDE);
}
else
CDialog::OnNcPaint();
}
这里有个问题:为什么要定义静态变量i而且设其值为2呢?
我们只要窗口隐藏第一次,所以定义这个变量可以判断是否时首次显示窗口。当程序开始运行时
,系统发送(SendMessage)WM_NCPAINT消息,此时程序的窗口边框应该被显示,但是此时我们没
有作任何显示的操作,而是将窗口隐藏,ShowWindow(SW_HIDE)将把窗口的WS_VISIBLE属性去掉,
继续执行,程序将检查WS_VISIBLE属性,如果没有则显示窗口,所以又发送了一个WM_NCPAINT消
息。所以我们要处理两次WM_NCPAINT消息。
在需要窗口显示时,调用ShowWindow(SW_SHOW)即可。
程序执行的结果是,原来处于激活状态的窗口可能会闪动两下,然后仍然处于激活状态。这种处
理方式比上面的方式要优越得多。
4.将对话框作为子窗口
这种方法是采用SDI框架,主窗口始终隐藏,对话框作为主窗口的成员变量,在CMainFrame::OnCr
eate()里面加入下代码:
if(!dlg.Create(IDD_MYDIALOG, this))
{
return –1;
}
dlg.ShowWindow(SW_HIDE);
在要显示对话框的地方用dlg.ShowWindow(SW_SHOW);即可。注意,主窗口一定要隐藏,否则对话
框可能会闪现一下。
隐藏状态栏窗口
上面介绍了几种检查对话框的方法,大家如果试过的话可能已经注意到系统状态栏里在程序启动
时会有程序的图标闪过,在隐藏对话框的时候这个也是要隐藏的,方法很简单:
在OnInitDialog()函数里面加上ModifyStyleEx(WS_EX_APPWINDOW, WS_EX_TOOLWINDOW);即可。在
要显示窗口的地方加上代码ModifyStyleEx(WS_EX_TOOLWINDOW, WS_EX_APPWINDOW);即将窗口的扩
展样式改回来。
以上是我的一点经验总结,有错误或不完善的地方还望大家提出指正。欢迎大家与我联系。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/miromelo/archive/2010/04/04/5450460.aspx
posted @
2010-12-03 16:02 胡满超 阅读(10883) |
评论 (6) |
编辑 收藏
You will only need to do four things:
1) At the top of your cpp file (under the #includes) add: #define WM_UPDATEFIELDS WM_APP + 1
2) Go to your Message Map section and add: ON_MESSAGE(WM_UPDATEFIELDS, UpdateDisplay)
3) Add a member function: LRESULT UpdateDisplay(WPARAM wParam, LPARAM lParam)
4) Add the following to the function:
UpdateData((BOOL)wParam);
return 0;
This should now allow you to pass UpdateData TRUE or FALSE from within a thread.
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
reference from: codeproject
http://www.codeproject.com/KB/cpp/avoidupdatedata.aspx
posted @
2010-09-28 13:29 胡满超 阅读(556) |
评论 (0) |
编辑 收藏
#include
<stdlib.h> #include <iostream>
using namespace std;
class tgh
{
public:
tgh():i(3){}
const int a() const {return 5;}
int a(){return i;}
protected:
int i;
private:
};
void main()
{
const tgh v;
tgh s;
const int i=s.a();//调用的是int a()
int const j=s.a();//调用的是int a()
printf("%d,%d",j,i);
const int k = v.a();//调用的是const int a()
cout<<k<<endl;
system("pause");
}
结果是3,35
转自:http://www.cppblog.com/tgh621/archive/2008/04/15/47100.aspx?opt=admin
posted @
2010-08-09 17:16 胡满超 阅读(224) |
评论 (0) |
编辑 收藏
 [转]写好代码的10个秘密
收藏
[转]写好代码的10个秘密
收藏
作者:飞哥 (百度)
先给大家看一段据说是史上最强的程序:
e100 33 f6 bf 0 20 b5 10 f3 a5 8c c8 5 0 2 50 68 13 1 cb e 1f be a1 1 bf 0 1
e11b 6 57 b8 11 1 bb 21 13 89 7 4b 4b 48 79 f9 ad 86 e0 8b c8 bd ff ff e8 20
e134 0 3d 0 1 74 1a 7f 3 aa eb f3 2d ff 0 50 e8 f 0 5a f7 d8 8b d8 26 8a 1 aa
e14f 4a 75 f9 eb de cb 57 bb 21 13 8b c1 40 f7 27 f7 f5 8b fb ba 11 1 4f 4f 4a
e168 39 5 7f f9 52 8b c5 f7 25 f7 37 2b c8 95 f7 65 2 f7 37 95 2b e8 fe e fe
e181 10 79 6 c6 6 fe 10 7 46 d0 14 d1 d1 d1 e5 79 ec 5a b8 11 1 ff 7 4b 4b 48
e19b 3b d0 75 f7 5f c3 83 f7 83 a6 5d 59 82 cd b2 8 42 46 9 57 a9 c5 ca aa 1b
.............................................................................
这段程序是1997年世界程序设计大赛的一等奖作品的部分代码(完整的代码下载,把代码复制粘贴到cmd的debug命令中,回车看到效果)。这个程序运行后将是一个3D的且伴随着音乐的动画。震撼吧!
是不是从事软件开发的人员都希望成为这样的武林高手呢?然而真要是用这样的高手来设计、编写我们的产品代码,恐怕某一天,我们什么都不用干了,只能人手一本机器代码,一句一句进行翻译了;那么对于软件产品开发而言,如何写好代码呢?一流的软件产品的代码具备哪些特征呢?
一流代码的特征
1、稳定可靠(Robustness)
代码写出来以后,一定要能够运行得非常好,非常稳定可靠。在现
今的IT行业,软件产品都是是24*7,即要保证系统一天24小时,一星期7天中都可以无间断的正常运行。比如我们百度的搜索引擎系统,比如我们的通信系
统,等等。到了产品开发后期,大部分的成本都将投入到产品稳定性的提高。
2、可维护且简洁(Maintainable and Simple Code)
在写代码时,首先要考
虑的是:写出来的代码不但要自己可以读懂,而且我们的同事、测试工程师都可能要修改这些代码,对其进行增减。如果代码很复杂,不容易读懂,如程序中的递归
一大堆、程序不知何时或从何地跳出,则会使程序的可维护性和简洁性降低。所以必要的注释、统一的编程规范等都是非常重要的。
3、高效(Fast)
在软件行业中效率是非常重要的,比如搜索引擎。有些软件的搜索效率就不高,搜索过
程特别缓慢,让人难以接受。当然这里面有一个带宽的问题,但是程序效率不高也是一个重要的原因。而实际上程序的效率提高,有时候很简单,并没有什么神秘之
处,如使用数组索引时候,可以用指针方式而不使用数组下标;数组的空间定义应该定义为2的N次幂等等。
4、简短(Small)
这方面大家的感受可能不是很深,但是我的感受是很深的。配置过PSTN程控交换
机、路由器、VoIP网关设备的人都知道,这些设备的软件都是从PC机通过网口或串口下载到这些设备的Flash上(类似PC机的BIOS)再通过设备上
的CPU启动。如果程序写的很罗嗦,随着特性不断增加,程序规模将变大的巨大,Flash空间告急、内存告急、下载升级变的不可忍受,等等,带来的就是成
本不断增加,利润不断下降。
5、共享性(Reusable)
如果做大型产品开发,程序的共享性也是非常重要的。我们产品有那么多开
发人员,如果每一个人都自己定义字符串、链表等数据结构,那么开发效率就会降低,我们的产品恐怕到今天也不能出台。我所说的“共享”不是指将别人的代码复
制到自己的代码中,而是指直接调用别人的代码,拿来即可用。这一方面可以减少代码的冗余性,另一方面可以增强代码的可维护性。如果别人的代码里有Bug,
只需修改他的代码,而调用此代码的程序不用进行任何修改就可以达到同步。这同时要求我们在设计的时候,如何考虑系统的内聚和耦合的问题。
6、可测试性(Testable)
我们的产品开发里,除了软件开发人员,还有一部分工程师负责软件测
试。软件测试人员会将开发代码拿来,一行一行地运行,看程序运行是否有错。如果软件开发人员的代码不可测试,那测试工程师就没有办法进行工作。因此可测试
性在大型软件开发里是很重要的一点。可测试性有时候与可维护性是遥相呼应的,一个具有好的可测试性和可维护性的代码,测试人员可以根据开发提供的维护手
册、debug信息手册等就可以判断出程序出错在哪个模块。
7、可移植性(Portable)
可移植性是指程序写出来以后,不仅在windows
2000里可以运行,在NT/9X下可以运行,而且在Linux甚至Macintosh等系统下都可以运行。所有这些特性都是一流代码所具备的特性。但是
其中有些特性是会有冲突的。比如高效性,程序写的效率很高,就可能变得很复杂,牺牲的就是简洁。好的代码要在这些特性中取得平衡。
写好代码的10个秘密
1、百家之长归我所有(Follow Basic Coding Style)
其实写代码的方式有很多,每个人都有自己的风格,但是众多的风格中总有一些共性的、基本的写代码的风格,如为程序写注释、代码对齐,等等。是不是编程规范?对就是编程规范。
2、取个好名字(Use Naming Conventions)
取个好的函数名、变量名,最好按照一定的规则起名。还是编程规范。
3、凌波微步,未必摔跤(Evil goto's?Maybe Not...)
这里我用“凌波微步”来形容goto语句。通常,goto语句使程序跳来跳去,不容易读,而且不能优化,但是在某种情况下,goto语句反而可以增强程序的可读性。Just go ahead,not go back。
4、先发制人,后发制于人(Practic Defensive Coding)
Defensive
Coding指一些可能会出错的情况,如变量的初始化等,要考虑到出现错误情况下的处理策略。测试时要多运行几个线程。有些程序在一个线城下运行是正常
的,但是在多个线程并行运行时就会出现问题;而有些程序在一个CPU下运行几个线程是正常的,但是在多个CPU下运行时就会出现问题,因为单CPU运行线
程只是狭义的并行,多CPU一起运行程序,才是真正的并行运算。
5、见招拆招,滴水不漏(Handle The Error Cases:They Will Occur!)
这里的Error Case(错误情况),是指那些不易重视的错误。如果不对Error Case进行处理,程序在多数情况下不会出错,但是一旦出现异常,程序就会崩溃。 6、熟习剑法刀术,所向无敌(Learn Win32 API Seriously)
用“剑法刀术”来形容一些API是因为它们都是经过了很多优秀开发人员的不断开发、测试,其效率很高,而且简洁易懂,希望大家能掌握它,熟悉它,使用它。是不是象我们的ULIB。
7、双手互搏,无坚不摧(Test,but don't stop there)
这里的测试不是指别人来测试你的代码,而是指自己去测试。因为你是写代码的原作者,对代码的了解最深,别人不可能比你更了解,所以你自己在测试时,可以很好地去测试哪些边界条件,以及一些意向不到的情况。
8、活用断言(Use,don't abuse,assertions)
断言(assertion)是个很好的调试工具和方法,希望大家能多用断言,但是并不是所有的情况下都可以用到断言。有些情况使用断言反而不合适。
9、草木皆兵,不可大意(Avoid Assumptions)
是指在写代码时,要小心一些输入的情况,比如输入文件、TCP的sockets、函数的参数等等,不要认为使用我们的API的用户都知道什么是正确的、什么是错的,也就是说一定要考虑到对外接口的出错处理问题。
10、最高境界、无招胜有招(Stop writing so much code)
意思就是说尽量避免写太多的代码,写的越多,出错的机会也越多。最好能重用别人开放的接口函数或直接调用别人的api。
posted @
2010-08-05 17:53 胡满超 阅读(440) |
评论 (0) |
编辑 收藏
转自:http://blog.csdn.net/pennyliang/archive/2010/07/07/5717498.aspx
中文分词方法有很多,其中基于词典的分词方法有:
正向最大匹配、逆向最大匹配法、双向匹配法
最少分词法
基于统计的分词方法有:
- 统计语言模型分词(2-gram,3-gram)
- 串频统计的汉语自动分词
除了这些基本的方法,为了获得最佳的效果,也可以引入动态规划的方法获得最优解。
设句子P = W0W1W2⋯Wn , 其中Wi (0≤i≤n) 为句子P中的第i 个汉字。Si(0≤i≤n+1)为句子的第i个间隙(切分位置)
那么一个句子P理论上有多少种分词法呢?
分词分法总数的通项:F(n)表示一个有n个单词的句子包含的全部不同的分词方法。
F(n)=1+ F(n-1)+F(n-2)+F(n-3)+F(n-4)+..F(1)
F(1)=1
F(2)=2
F(3)=4
F(4)=8
…
F(n)=2F(n-1)
则F(n)=2n-1
如果将词频看做是距离,则求解最佳切分方法等价于在2n-1的解空间中寻找1种最佳的切分方法使得路径最短。为此我们举个例子:
早起先刷牙
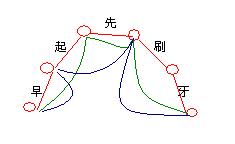
图中红圈为切分点,切分点之间的连线表示确定的一种分词
图中给出了三种分法,分别是[早][起][先][刷][牙]、[早起][先][刷牙]和[早][起先][刷牙]
假定我们有这样一个字频和词频表,分别如下
早 400
早起 100
起 500
起先 150
先 500
刷 300
刷牙 100
牙 500
则以上三种切分法的代价分别为
[早][起][先][刷][牙]:400+500+500+300+500 = 2200
[早起][先][刷牙]:100+500+100 = 700
[早][起先][刷牙]:400+150+100 =750 (此处应为650)
因此选用第2种切分法。
动态规划的伪代码大致为:
Segment(S,low,high,cost,last)
{
Mincost = MAX;
If(high-low<=1)
{
mincost = Costof(cost,L(low,high-low)); //其中L(start,length)的含义表示从start开始从P中取length长度的文本,Costof为该段文本的字频,或者词频,如果不存在则为无穷大;如果cost数组中已经计算过,则不重复计算,直接取值返回。
cost[low][high] = mincost;
Return mincost;
}
for(i = low+1 to high )
{
a = Segment(S,low,i,cost,last);//为了简单这里做了精简,事实上如果a返回的是无穷大,则后面不用继续计算,直接跳出,因为这种情况下无论如何也不可能是最优解,可以直接剪枝。
b = Segment(S,i,high,cost,last);
if(a+b<Mincost)
{
Mincost = a + b;
Cost[low][high]=Mincost;
Last[low][high] = i;//Last记录最佳切分点
}
}
ExtractSegmentPos(Last,low,high);//该函数是将切分点一一展开。
}
ExtractSegmentPos(Last,low,high)
{
SegPos=MAX;
if(high-low>1)
{
If(Last[low][high]>0)
{
SegPos = Last[low][high];
output(SegPos);
}
else
{
return;
}
}
ExtractSegmentPos(Last,low, SegPos);
ExtractSegmentPos(Last, SegPos,high);
}
参考文献
[1] 孙 晓, 黄德根 基于动态规划的最小代价路径汉语自动分词 [J]小型微型计算机系统 第27 卷第3 期 2006 年3 月
其他推荐阅读
http://www.leadbbs.com/MINI/default.asp?230-2682632-0-0-0-0-0-a-.htm
posted @
2010-07-30 09:06 胡满超 阅读(803) |
评论 (0) |
编辑 收藏
1,功能过于复杂,被微软牵着走
OO的前身是StarOffice,我想它的初衷肯定不是想做成微软这么复杂的办公软件,但现在的发展方向是微软能做到的,OO也希望可以做到;
2,架构、代码、数据处理算法,质量整体不高
如果从一般意义来讲OO的架构与代码也算不错,但如果用市场一线软件的标准去度量OO,它显然还有相当大的改进空间;
3、商业价值至今不够显现
几个参与OO的开发的厂商目的不一样,所专注的侧重点也不一样,但有两点是一致的,一是不能让微软落太远,二是谁也没在OO身上挣到钱;
4、投入太少,被微软越落越远
与微软相比的财力与人力,各厂商的投入尚不是一个层次。当然,商业上的成功与研发的投入是正相关的一个循环体,大家各有各个考虑,是情理之中的事情。
5、二次开发功能太弱,接口尚不能十分稳定
二次开发是让一个系统起飞的翅膀,良好的二次开发功能会创造出软件编写都想像不出来的应用,但开源的OO恰恰做的不好;
我一直觉得这个OO赶超微软唯一的切入点,可以说只要你能想到的应用,理论上微软的Office都可以实现,但大家不相信它,应该它不开源,不安全,还可能有版权问题,但OO在这方面显然有一定的心理优势;
6、在主流用户平台,用户群较少
这主指windows,当然在linux上OO还是很牛的,反正也没有别的选择。但从主流用户平台上抢不到客户,估计每一个做OO的人都够郁闷的了,包括我。
7、未能找到未来的发展方向
OO阵营大家不能找到一个共同而明确的方向,形成合力,使有限力量显得有些分散,为OO的开展带来很多的不可预见性。
简单的谈了一下自己的看法,如果说的不对,还请见谅小弟。
posted @
2010-03-05 10:29 胡满超 阅读(421) |
评论 (0) |
编辑 收藏
1、不愿意将就的人
程序设计工作是一项地地道道的脑力劳动,把工作做得很好和做的很差往往只在工作中的一个小小的细节,我发现我身边优秀的程序员都不太喜欢将就,始终把自己的计算机和自己的开发环境调整到最佳状态,原来带我的老员工甚至会自己写一些小工具,来提高工作效率。
2、不喜欢蛮干
脑力劳动与体力劳动不同,很多时候很难通过简单的量的积累达到目的,尤其是处理一些难题的时候。一味的强调蛮干,加班几乎天生与高手无缘。没有思路的时候,换个环境,也许答案就在明天上班的路上想起。
3、愿意思考、专注改进
程序员与其他劳动者相似,熟练了以后都会形成惯性思维,会不自觉的用自己习惯的方式解决问题,但问题的形式与本质总会变化,只有不断的改进才能使工作效率不断提高。而把脑力劳动变成体力劳动的现象在实际工作中比比皆是。
4、良好的基础和不断的学习
良好的基础与不断的学习是天生的一对孪生兄弟,因为基础好所以学的快,因为学得快,所以基本功好。良好学习习惯不是不停的简单追踪新技术,一方面是了解新技术,另一方面需要不断的弥补思维盲区,学习可以有很多种状态,有一种是闻一而知一,技也,有一种是闻一而知三,术也,有一种是闻一而知十,道也。
5、直接切入问题的能力
在解决一个问题的时候,有些人总是能够直接切入问题核心,而有些人总是喜欢关注边缘问题。直入主题是一种核心能力,需要思考,实践,改进,积累,提高,周而复使,螺旋上升。另外我觉得这与思维方式与知识面关系很大,多涉猎一些领域没有坏处。
***英语***:呵呵,对,还是英语,流利的听说读写。
posted @
2009-12-16 17:39 胡满超 阅读(289) |
评论 (0) |
编辑 收藏
1、 查找一个字符串中最长的重复子串;
2、 查找一个字符串中重复最多的子串;
查找“重复子串最长的”和“子串出现次数最多的”解决方案相似:
首先、生成一个指针数组,数组的成员依次指向字符串中每一个的字符地址,如
String: “banana”
那么指针数组分别代表字串:
banana
anana
nana
ana
na
a
之后按指针数组指向的字符串值,对数组进行排序,排序结果如下:
a[0]: a
a[1]: ana
a[2]: anana
a[3]: banana
a[4]: na
a[5]: nana
有个这个数组,统计“重复的最长子串”和“重复次数最多子串”就非常容易了。
“重复的最长子串”代码如下:
1 int comlen(char *p, char *q)
2 {
3 i = 0
4 while *p && (*p++ == *q++)
5 i++
6 return i
7 }
8
9 maxlen = -1
10 for i = [0, n)
11 for j = (i, n)
12 if (thislen = comlen(&c[i], &c[j])) > maxlen
13 maxlen = thislen
14 maxi = i maxj = j
这个方法出自《编程珠玑》。
posted @
2009-12-16 14:07 胡满超 阅读(583) |
评论 (1) |
编辑 收藏
这些算法与内容包括:
1、 查找一个短串在一个长串中位置;
2、 查找一个字符串中最长的重复子串;
3、 查找一个字符串中重复最多的子串;
4、 两个字符串最长的公共子串(连续);
5、 两个字符串最长的公共子序列(不连续);
6、 介绍一种强大的数据结构,Suffix tree.
这里有一个PPT:
http://www.cppblog.com/Files/humanchao/StringAlg.zip
-------------------------------------------------
查找一个短串在一个长串中位置
这个问题传统的解法时间复杂度为O(m*n),m、n为两个串的长度。有一个Sunday算法,可以最大限度的优化这个比较过程,原理如下:
1、建立一个hash table,依次把search各个字符值作为table索引,为table相应的位置一个值(表示字符存在),如果出现重复,后面的位置会覆盖前面的位置。
例:我们要在"WHICH-FINALLY-HALTS.—AT-THAT-POINT"(简称string)查找" AT-THAT "(简称pat),刚开始时,把pat与string对齐,查看串string中与串pat 相对应的字符(F),在pat的位置,这个查找的过程时间复杂度通过hash table的下标索引为 O(1):
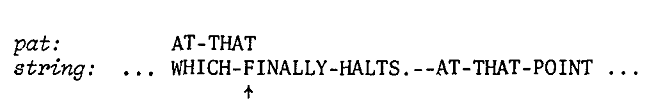
2、如果发现没有,说明字符F之前已经无法与pat匹配,直接跳到position(F)+stringlength(pat)
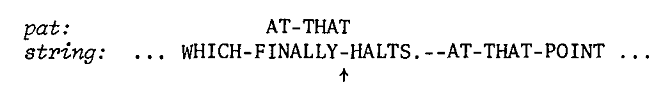
3、发现”-”在pat位置3,于是重新定位对齐两串为:
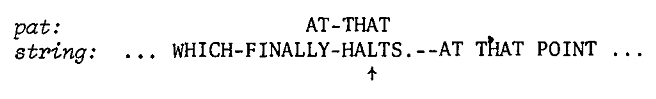
4、倒序(从最后一个向前)比较两串,发现无法匹配,继续跳转->查找->定位
因为上面已经有一个T匹配成功,这次要从HALTS的S来查找,于是定位为:
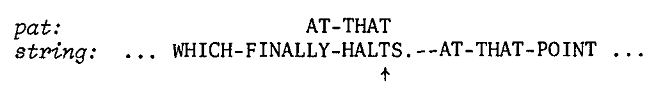
5、上图无法匹配,从”--AT-“中A后的”-”继续查找,重复上过程,最终匹配如图:
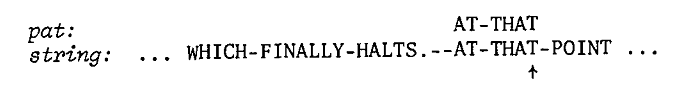
这个算法关键点:
1、建立为pat建立hash表,以提高查找字符的速度;
2、对齐跳转,快速的后移比较,使比较次数减少。
具体的代码实现可以参考链接:
http://blog.csdn.net/unicode1985/archive/2007/05/30/1631038.aspx
posted @
2009-11-25 17:20 胡满超 阅读(3181) |
评论 (0) |
编辑 收藏正确的做法在wikipedia上有所描述,请大家参考:
http://en.wikipedia.org/wiki/Longest_common_substring_problem
与
http://hellobmw.com/archives/dynamic-programming-longest-common-substring.html
posted @
2009-11-25 17:09 胡满超 阅读(206) |
评论 (0) |
编辑 收藏将字符串里词顺序倒置,如"Times New Roman"变为"Roman New Times"。以空格为分隔符。
解决方案为:先将整个字串倒置,然后依次把倒置后串中的每一个单词倒置。
这个问题解答的思路很简单,但是要考虑到很多种的情况,比如字符串的头、尾有多余的空格怎么办,如果字符串中只有空格,还有字符串中间可能会有两个以上并列的空格。
程序如下:
1 void ReverseStr(char *pStr, int len)
2 {
3 assert(pStr);
4
5 char ch;
6 for (int i = 0; i < len/2 ; i++)
7 {
8 ch = pStr[i];
9 pStr[i] = pStr[len-1-i];
10 pStr[len-1-i] = ch;
11 }
12 }
13
14 void ReverseStrWord(char *pStr, int len)
15 {
16 assert(pStr);
17
18 if (len <= 1)
19 return;
20
21 // 倒置整个字符串
22 ReverseStr(pStr, len);
23
24 // 处理头多余的空格
25 int i = 0;
26 if (pStr[0] == ' ') while (pStr[i] == ' ' && i < len) i++;
27
28 // 整个串都是空格
29 if (i == len)
30 return;
31
32 // 处理尾多余的空格
33 if (pStr[len - 1] == ' ') while (pStr[len - 1] == ' ' && len - 1 > 0) len--;
34
35 for (int start = i; i < len; i++)
36 {
37 // 最后的end要+1
38 if (i == len-1)
39 {
40 ReverseStr(pStr+start, i-start+1);
41 break;
42 }
43
44 // 倒置一个单词
45 if (pStr[i] == ' ')
46 {
47 ReverseStr(pStr+start, i-start);
48 start = i+1;
49 // 处理内部并列的空格
50 if (pStr[start] == ' ')
51 {
52 while(pStr[start] == ' ') {i++;start++;};
53 }
54 }
55 }
56 }
57
说实话,如果是突然面对这样一个问题,要在一张纸上写下比较完整的程序是不大可能。能边调试边写程序有的时候也是一件幸事。
中秋节要到了,我要换工作了,告别已经工作两年多熟悉的环境,感觉这两年没有太大的进步,奋斗吧,趁着自己还年轻!
posted @
2008-09-12 20:42 胡满超 阅读(2269) |
评论 (5) |
编辑 收藏
解答:这个问题用递归解决最简单,代码如下:
1 #define MAX_NUM 20 //要足够大
2 int log[MAX_NUM]; //记录和数
3 int index = 0; //log[]数组的当前指针
4
5 void calc(int start, int n)
6 {
7 if (n == 0)
8 {
9 for(int j = 0; j < index; j++)
10 printf("%d ", log[j]);
11 printf("\n");
12 }
13 else
14 {
15 for(int i = start; i<=n; i++)
16 {
17 log[index++] = i;
18 calc(i + 1, n - i);
19 }
20 }
21
22 index--;
23 }
如果允许重复只需要将上面第18条代码改为:
calc(i, n - i);
即可。
扩展问题:在数组{5,1,7,9,2,10,11,4,13,14}中找到和为28的所有集合,集合中不允许有重复的数。
解答:第一步要先对数组排序,然后按照上去的思路,对程序略做一些改动。
代码如下:
1 #define MAX_NUM 20 //要足够大
2 int log[MAX_NUM]; //记录和数
3 int index = 0; //log[]数组的当前指针
4
5 void calc__(int *nArr //数组,
6 int start //数组起始元素下标,
7 int nArrLen //数组长度,
8 int sum)
9 {
10 if (sum == 0)
11 {
12 for(int j = 0; j < index; j++)
13 printf("%d ", log[j]);
14 printf("\n");
15 }
16 else
17 {
18 for(int i = start; i < nArrLen; i++)
19 {
20 log[index++] = nArr[i];
21 calc__(nArr, i+1, nArrLen, sum - nArr[i]);
22 }
23 }
24
25 index--;
26 }
这个问题的解答思路是相当简单的,但如何把程序写的细致、简捷是除了解答思路以外的另一个关键。就像迷宫最短路径的那个问题,言语描述很简单,但把实现的程序写好确要花一些时间。
posted @
2008-08-29 16:13 胡满超 阅读(1085) |
评论 (0) |
编辑 收藏
struct NODE
{
NODE *pLeft;
NODE *pRight;
char chValue;
};
int CharInStrFirstPos(char ch, char *str, int nLen)
{
char *pOrgStr = str;
while (nLen > 0 && ch != *str)
{
str++;
nLen--;
}
return (nLen > 0) ? (str - pOrgStr) : -1;
}
void ReBuild_PreIn(char *pPreOrder, char *pInOrder, int nTreeLen, NODE **pRoot)
{
if (pPreOrder == NULL || pInOrder == NULL)
{
return;
}
NODE *pTemp = new NODE;
pTemp->chValue = *pPreOrder;
pTemp->pLeft = NULL;
pTemp->pRight = NULL;
if (*pRoot == NULL)
{
*pRoot = pTemp;
}
if (nTreeLen == 1)
{
return;
}
int nLeftLen = CharInStrFirstPos(*pPreOrder, pInOrder, nTreeLen);
assert(nLeftLen != -1);
int nRightLen = nTreeLen - nLeftLen -1;
if (nLeftLen > 0)
{
ReBuild_PreIn(pPreOrder + 1, pInOrder, nLeftLen, &((*pRoot)->pLeft));
}
if (nRightLen > 0)
{
ReBuild_PreIn(pPreOrder + nLeftLen + 1, pInOrder + nLeftLen + 1,
nRightLen, &((*pRoot)->pRight));
}
}
已知后序和中序:
void ReBuild_AftIn(char *pAftOrder, char *pInOrder, int nTreeLen, NODE **pRoot)
{
if (pAftOrder == NULL || pInOrder == NULL)
{
return;
}
NODE *pTemp = new NODE;
pTemp->chValue = *pAftOrder;
pTemp->pLeft = NULL;
pTemp->pRight = NULL;
if (*pRoot == NULL)
{
*pRoot = pTemp;
}
if (nTreeLen == 1)
{
return;
}
int nLeftLen = CharInStrFirstPos(*pAftOrder, pInOrder, nTreeLen);
assert(nLeftLen != -1);
int nRightLen = nTreeLen - nLeftLen -1;
if (nLeftLen > 0)
{
ReBuild_AftIn(pAftOrder + nRightLen + 1, pInOrder, nLeftLen, &((*pRoot)->pLeft));
}
if (nRightLen > 0)
{
ReBuild_AftIn(pAftOrder + 1, pInOrder + nLeftLen + 1,
nRightLen, &((*pRoot)->pRight));
}
}
我上传了一个工VC的工程,有兴趣的朋友点此下载。代码参考于《编程之美》。
posted @
2008-08-27 17:51 胡满超 阅读(962) |
评论 (0) |
编辑 收藏
int Add1to10(int a, int b)
{
return a +b;
}
但是一般我们还需要加上几条代码:
int Add1to10(int a, int b)
{
assert(a >= 1 && a <= 10);
assert(b >= 1 && b < =10);
if ( a < 1 || a > 10 || b < 1 || b > 10)
return -1;
return a +b;
}
加上上面几条代码的作用是检查函数的输入参数,当参数不正确的时候不光要在返回值上得到体现,而且会触发assert断言,提醒我们参数有误。
断言式编程体现一个编程的思想,在我们的程序执行偏离预想的路线时给出提醒。当程序执行偏离预想的路线时一般会出现两种可能:即断言以上的程序没有理解下面程序的调用条件、或断言以下的程序需要接受更为宽泛输入条件。以下分别讨论修改方法:
1、如果函数的输入参数是我们编程的一个疏漏,我们认为根本就不应该出现或产生这样的值,那我们应该修改调用函数处的代码,避免非预想的值出现。
2、如果无法避免出现或者产生一个非法输入值,那我们要么在函数调用处加入判断,产生符合条件的值时调用函数,不符合参数条件else处理;要么修改函数,使函数可以接受更为宽泛输入条件,并调整断言内容和参数判断逻辑。
断言不仅可以出现在函数的参数检查的场合,也可以出现在其他的上下文调用的场合。而且它还会随着程序的开发进程逐渐的增加、删除和调整。它可以验证程序是按照我们预想的思路在执行,当出现意外时及时的给出提醒,提醒我们修正程序或者自己的思路。
posted @
2008-08-19 10:00 胡满超 阅读(842) |
评论 (0) |
编辑 收藏void QuickSort(int* pData,int left,int right)
{
int i = left, j = right;
int middle = pData[(left+right)/2]; // midlle value
int iTemp;
do
{
while (pData[i] < middle && i < right) i++;
while (pData[j] > middle && j > left) j--;
if (i < j) // swap
{
iTemp = pData[i];
pData[i] = pData[j];
pData[j] = iTemp;
i++; j--;
}
else if (i == j)
{
i++; j--;
}
} while (i < j);
if (left < j) QuickSort(pData,left,j);
if (right > i) QuickSort(pData,i,right);
}
没的说,理解不了就是背也得把这段代码背下来。
posted @
2008-08-18 17:02 胡满超 阅读(806) |
评论 (0) |
编辑 收藏
B树的删除
B树的生长过程
三元组表的转置
中序线索化二叉树
串的顺序存储
二分查找
二叉排序树的删除
二叉排序树的生成
二叉树的建立
克鲁斯卡尔算法构造最小生成树
冒泡排序
分块查找
单链表结点的删除
单链表结点的插入
图的深度优先遍历
基数排序
堆排序
头插法建单链表
寻找中序线索化二叉树指定结点的前驱
寻找中序线索化二叉树指定结点的后继
尾插法建表
希儿排序
开放定址法建立散列表
循环队列操作演示
快速排序
拉链法创建散列表
拓扑排序
数据结构和算法Flash动画演示.rar
最短路径
朴素串匹配算法过程示意
构造哈夫曼树的算法模拟
构造哈夫曼树过程
栈与递归
...更多
点击下载
posted @
2008-07-24 16:19 胡满超 阅读(3357) |
评论 (1) |
编辑 收藏
SetOutPath '$INSTDIR'
ExecWait '$INSTDIR\A.bat'
如果BAT需要参数时,要把带参数的命令写入另外一个新的BAT中,执行新BAT:
B.bat内容:
CALL A.bat install
NSIS 脚本:
SetOutPath '$INSTDIR'
ExecWait '$INSTDIR\B.bat'
posted @
2008-07-23 16:47 胡满超 阅读(6138) |
评论 (3) |
编辑 收藏
#import "scrrun.dll" raw_interfaces_only
// 参数格式:"c:\" 或 "c:\test"
ULONGLONG GetPathUseSpace(const char *szPath)
{
ASSERT(szPath != NULL);
int nLen = strlen(szPath);
if (nLen == 0)
return 0;
ULONGLONG result = 0;
if (nLen == 3) // c:\
{
ULARGE_INTEGER nFreeBytesAvailable;
ULARGE_INTEGER nTotalNumberOfBytes;
ULARGE_INTEGER nTotalNumberOfFreeBytes;
//
if (GetDiskFreeSpaceEx(szPath,
&nFreeBytesAvailable,
&nTotalNumberOfBytes,
&nTotalNumberOfFreeBytes))
{
result = nTotalNumberOfBytes.QuadPart - nFreeBytesAvailable.QuadPart;
}
}
else
{
CoInitialize(NULL);
{
try
{
Scripting::IFileSystem3Ptr fs;
fs.CreateInstance(__uuidof(Scripting::FileSystemObject));
Scripting::IFolderPtr folder;
fs->GetFolder(_bstr_t(szPath),&folder);
_variant_t vsize;
folder->get_Size(&vsize);
result = (double)vsize;
}
catch(_com_error &e)
{
result = -1;
}
}
CoUninitialize();
}
return result;
}
VC取得目录的大小可以用COM方式,但是在某些操作系统上使用COM方式取根目录大小(即某一个盘已用空间)会出现问题,可以用GetDiskFreeSpaceEx,上面是我写了一个小函数。
posted @
2008-07-02 16:33 胡满超 阅读(2976) |
评论 (13) |
编辑 收藏