大小端问题
By unanao
<sunjianjiao@gmail.com>
一、什么是大小端问题
(From《Computer Systems,A Programer's Perspective》)在几乎所有的机器上,多字节对象被存储为连续的字节序列,对象的地址为所使用字节序列中最低字节地址。
小端:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,这种最低有效字节在最前面的表示方式被称为小端法(little endian) 。这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
大端:某些机器则按照从最高有效字节到最低有效字节的顺序储存,这种最高有效字节在最前面的方式被称为大端法(big endian) 。这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
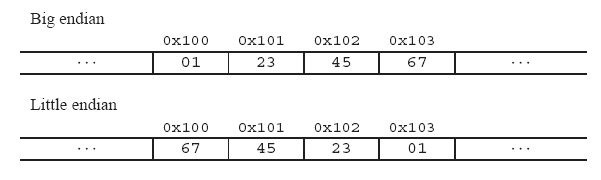
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567. 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
二、为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
三、如何区分大小端问题:
方法1:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 int i = 1;
6 unsigned char *pointer;
7
8 pointer = (unsigned char *)&i;
9 if(*pointer)
10 {
11 printf("litttle_endian");
12 }
13 else
14 {
15 printf("big endian\n");
16 }
17
18 return 0;
19 }
C中的数据类型都是从内存的低地址向高地址扩展,取址运算"&"都是取低地址。小端方式中(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0。大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i,则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
方法2:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 union {
6 short a;
7 char ch;
8 } u;
9 u.a = 1;
10
11 if (u.ch == 1)
12 {
13 printf("Littel endian\n");
14 }
15 else
16 {
17 printf("Big endian\n");
18 }
19 }
利用联合体的特点,数据成员共享内存空间,union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
四、需要考虑大小端(字节顺序)的情况
1、所写的程序需要向不同的硬件平台迁移,说不定哪一个平台是大端还是小端,为了保证可移植性,一定提前考虑好。
2. 在不同类型的机器之间通过网络传送二进制数据时。 一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反之时,接受程序会发现,字(word)里的字节(byte)成了反序的。为了避免这类问 题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接受方机器则将网络标准转换为它的内部标准。
3. 当阅读表示整数的字节序列时。这通常发生在检查机器级程序时,e.g.:反汇编得到的一条指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
3. 当编写强转的类型系统的程序时。如写入的数据为u32型,但是读取的时候却是char型的。如:0x1234, 大端读取为12时,小端独到的是34。
六、提高程序的可移植性
使用宏编译
#ifdef LITTLE_ENDIAN
//小端的代码
#else
//大端的代码
#endif
七、大、小端之间的转换
1、小端转换为大端
1 #include <stdio.h>
2
3 void show_byte(char *addr, int len)
4 {
5 int i;
6
7 for (i = 0; i < len; i++)
8 {
9 printf("%.2x \t", addr[i]);
10 }
11 printf("\n");
12 }
13
14 int endian_convert(int t)
15 {
16 int result;
17 int i;
18
19 result = 0;
20 for (i = 0; i < sizeof(t); i++)
21 {
22 result <<= 8;
23 result |= (t & 0xFF);
24 t >>= 8;
25 }
26
27 return result;
28 }
29
30 int main(void)
31 {
32 int i;
33 int ret;
34
35 i = 0x1234567;
36
37 show_byte((char *)&i, sizeof(int));
38 ret = endian_convert(i);
39 show_byte((char *)&ret, sizeof(int));
40
41 return 0;
42 }
本文转自:http://www.cppblog.com/humanchao/archive/2012/12/26/196684.html
posted on 2013-01-07 16:33
王海光 阅读(862)
评论(0) 编辑 收藏 引用 所属分类:
算法