之前因为时间匆忙,大区里产生唯一ID只是简单写了一个方法,今天趁着有时间,把里面一些过程写出来,也算是个总结。 首先说说需求,现在游戏里数据库为了分散热点,都采用分表方式,以前那种一张表AUTO_INCREMENT的方式显然不行了,那么将唯一ID放到业务进程里可行吗?这个也不好,因为现在后台都是多个部署,每个进程可以保证ID唯一,但是存到数据库的时候就可能重复,所以我们还是得在DB上做文章。 因此就有了上篇文章的解决方案,单独一张表,这张表的作用就是专门产生唯一ID,而且为多个业务提供唯一ID,多进程情况下也不需要锁表,效率比较高,是不是很像设计模式里的工厂。接着我来分析下这张表。我们再来看看表结构和用法
create table SeqTab (
iSeqNo bigint(20) not null default 0, //表示唯一ID
iSeqType int(11) not null default 0, //表示业务ID
primary key(iSeqNo,iSeqType));
insert into SeqTab values(0,1); //初始化,假设一个业务编号为1
update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=1;
select last_insert_id(); //这两句是获取一个业务的唯一ID,供业务进程使用。 其实说到这张表,关键是说LAST_INSERT_ID()这个方法。它有两种形式LAST_INSERT_ID(),LAST_INSERT_ID(expr)。 这个东西的特点是,1.属于每个CONNECTION,CONNECTION之间相互不会影响 2.不属于某个具体的表 3.返回最后一次INSERT AUTO_INCREMENT的值 4.假如以此使用INSERT插入 多行数据,只返回第一行数据产生的值 5.如果你UPDATE某个AUTO_INCREMENT的值,不会影响LAST_INSERT_ID()返回值 LAST_INSERT_ID(expr)与LAST_INSERT_ID()稍有不同,首先它返回expr的值,其次它的返回值会记录在LAST_INSERT_ID()。 我们这里主要使用到了第一和第二个特点,每个进程并发执行update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=1;,就获取属于进程自己的iSeqNo并且记录在 LAST_INSERT_ID中,通过第二句取出该值。 接着我们在比较下其他一些办法。 第一种是直接一张表,里面有一个ID字段,设置成AUTO_INCREMENT。这个的问题是每个业务ID不是连续的,是离散的。 第二种是使用GUID或者UUID,但是这个问题我个人觉得是效率上的差异,字符串没有数字的效率好,另外数字ID今后也可以拼接一些区信息,之后跨区的时候可以方便获取对象是哪个区的.
posted @
2012-12-06 23:01 梨树阳光 阅读(2339) |
评论 (2) |
编辑 收藏
Mysql中除了使用auto_increment字段作为自增序号以外 还有另外一种办法 可以提供唯一序列号并且可以由一张表完成对多个序列
要求的满足。
大致如下:
1.创建一个简单表
create table SeqTab
( iSeqNo int not null default 0,
iSeqType int not null default 0);
2.插入一调记录
insert into SeqTab values(0,13); // 0表示SeqNo初始值,13为SeqType,同一张表可对多个应用提供Seq序列服务
3.不管多进程 or 单进程对SeqTab表同时进行访问,使用一下方法获取序列号
1st->update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=13;
2nd->select last_insert_id();
4.因多进程对SeqTab同时访问,进行update SeqTab set iSeqNo=last_insert_id(iSeqNo+1);时,数据库保证了update的事务
完整性,且last_insert_id()是与当前mysql连接相关的,所以多进程同时使用时,也不会冲突。
posted @
2012-12-05 11:54 梨树阳光 阅读(1806) |
评论 (2) |
编辑 收藏
相信大家在开发后台的过程中都遇到过中文乱码的问题,今天我就来讲讲其中的原因。 我这建了3张表,test_latin1,test_utf8,test_gbk,表结构如下 +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| name | char(32) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
我的前端是gbk的编码
执行下面的语句
set names 'latin1'
insert into test_latin1 set name='王';('王'字是GBK编码)
select name from test_latin1;
结果是否为乱码?
执行下面的语句
set names 'gbk' insert into test_latin1 set name='王';('王'字是GBK编码) select name from test_latin1; 结果是否为乱码? 执行下面的语句 set names 'latin1' insert into test_utf8 set name='王';('王'字是GBK编码) select name from test_utf8 ; 结果是否为乱码? 我们举个例子,假设一个汉字的字符编码为0xFFFF,它在屏幕上能够正常显示,如果汉字存入数据库的时候和从数据库中取出的时候,编码一致,那么它肯定不是乱码。反过来,如果输出的时候是乱码,那么它肯定被转码了,至于为什么被转码了,我们得看看mysql里面做了什么(mysql难道会把无码片变成了有码片?) 首先mysql里面有2个概念,一个叫character set,一个叫collation。我们先说说character set。字符集就是数字,英文字符,汉字等编码格式,我们常见的是utf8,gbk,gb2312。mysql里面比较复杂,有4个东西跟它有关,分别是character_set_client,character_set_connection,character_set_database,character_set_results。set names (latin1)其实就是character_set_client=latin1,character_set_connection=latin1,character_set_results=latin1,它的流程是character_set_client ==> character_set_connection ==> Table Character ==> character_set_results。 我们按照上面的流程,来分析第一个问题。 set names 'latin1'----执行了character_set_client=latin1,character_set_connection=latin1,character_set_results=latin1; insert into test_latin1 set name='王';这句话,mysql做了什么事呢?首先,character_set_client,它会把王字的编码当成latin1的编码传递给character_set_connection(此时不会转码),character_set_connection会把编码传递给Table Character,因为表本身是latin1,所以此时也不需要转码,select name from test_latin1;mysql会把test_latin1中的编码传递给前端,此时也不需要转码,所以,走个流程下来,我们输入的是什么编码,输出的还是相同的编码,因此,第一个问题的答案是不会是乱码。我画个流程图latin1==>latin1==>latin1==>latin1,没有转码的过程 我们在来看第二个问题。 set names 'test_gbk'----执行了character_set_client=gbk,character_set_connection=gbk,character_set_results=gbk; insert into test_latin1 set name='王';character_set_client,它会把王字的编码当成gbk的编码传递给character_set_connection(此时不会转码),character_set_connection会把编码传递给Table Character,因为表是lanti1的编码格式,这个过程的时候就会进行转码,但是latin1的字符集小于gbk的字符集,所以它会找不到对应字符的编码,此时会以?代替。select name from test_latin1,此时会从latin1转码成gbk,但是此时latin1已经是错误的数据了,所以得到的gbk编码也是错误的了。流程gbk==>gbk==>latin1==>gbk,其中gbk==>latin1出了问题,我们select出来的数据也就不可能是输入时候的数据了。因此,这个问题的答案是乱码。 第三个。 set names 'test_latin1' insert into test_utf8 set name='王';character_set_client,它会把王字的编码当成latin1的编码传递给character_set_connection(此时不会转码),character_set_connection会把编码传递给Table Character,此时表是utf8的格式,因此会进行转码,latin1==>utf8,因为utf8的字符集>latin1字符集,因此,转码正常。select name from test_utf8;会从utf8转码成latin1,此时可以转码成功,因此我们最终得到的和输入的时候是一致的,因此答案不是乱码。流程latin1==>latin1==>utf8==>latin1,从小的字符集到大的字符集再到小的字符集,转码是不会有问题的。 屁话了这么多,无非想告诉大家一个万精油方法,表创建的字符集和set names都设置成同一个字符集,就基本可以满足输入数据不会在转换过程中失真,也就是说输入是什么,输出就是什么。建议有中文的都设置成utf8字符集,一劳永逸。
posted @
2012-11-26 19:56 梨树阳光 阅读(2636) |
评论 (2) |
编辑 收藏
这是Riot的Design Director Tom Cadwell专门为中国玩家写的讲解匹配系统工作原理的帖子。
同时为了让大家更好的理解匹配系统,如果您觉得您遇到了特别不公平的匹配,请回复游戏开始时间和比赛结束截图,我们会调查该局匹配是如何完成的,坑爹的玩家是为何加入到这一局的。
很多人抱怨看不懂,我来个精简比喻版的:
有个篮球联盟,有无数个球员和大概20个等级的联赛。
所有球员都是10级联赛的成员,他们自由组合互相比赛,赢的人,升级到11级联赛,输的人降到9级联赛。
然后每个等级联赛再次开赛,又有的人升级有的人降级,最终这20级的联赛都有球员参加。
我们的大量的数据证明,一个球员的水平,会让其稳定在大约3个联赛之间,也就是科比是参加20级联赛的,且当他和4个17级联赛的人组队,基本不会输给17级联赛的人。且,把科比降到10级联赛,他会轻松的在20局之内回到20级。
理想情况下,球员都是在跟自己同样经历的球员玩,一个中等水平玩家完全不会匹配到科比,科比也不会匹配到刚玩游戏的玩家。
事实上匹配系统的分级会比这个更复杂更智能,采用的是国际象棋所采用的elo系统。
再增加个FAQ:
Q:系统为了保持胜率50%,是否会在我连胜后故意塞给我一些菜队友让我输?
A:系统的目的不是为了保持你的胜率,而是让水平差不多的玩家一起玩。当你和水平差不多的玩家一起玩时胜率会趋近50%,所以,系统是不会故意坑你的。
Q:我才100胜,为什么系统老匹配600胜的玩家给我?
A:胜场并不能反应一个人的水平。如果把匹配系统比作跑步,练习了3年才能跑进11秒的和第一次就跑进11秒的人我们是同等看待的。匹配系统基于水平而不是基于经验。
Q:我胜率60%,为什么匹配40%胜率的队友、60%胜率的对手给我?
A:胜率也不能反映水平。匹配系统不但要看你是否赢了,也要看你赢了谁。就像war3的sky在职业圈胜率其实并不高,但是虐一般的玩家胜率是100%。同样水平的玩家,会因为随机匹配到对手的关系,胜率会40%~60%不等。
Q:你说水平差不多,为什么我觉得他们这么菜?
A:匹配系统提供的是公平的机会,而未必是你理想的结果。我们能追求系统公正,但是无法预测玩家单局内的表现。
系统100%匹配曼联对阵皇马,但是不能保证某一次曼联不会4:0碾压皇马,且在这局中,C罗表现yts,完全就在拖后腿。或者曼联也可能连胜皇马3次之类的。但是,系统只会把曼联去匹配皇马而不会出现曼联对阵中超深圳队。具体到某一局是皇马赢还是曼联赢取决于那一场的排兵布阵,临场发挥,以及战术意图。
如果这个坑爹玩家真的不在你的水平等级,他就会一直坑队友,一直输,等级一直降低,这样会让他离开你的匹配范围,让他不再可以和你匹配到。根据我们的数据,玩家的elo基本是稳定在较小范围内的。这也就是深圳队和皇马的差距,也是中国国家队能赢法国队,确永远打不进世界杯的理由。
系统没办法给你完美队友,玩家会因为很多原因发挥不好:使用不会的英雄、打了不想打的位置、玩法风格和队友不够搭配,前期不利想挂机等等。但是你和对方玩家遇到这种情况的概率是相同的,系统并不会偏袒任何一方。所以想要完美队友,请和朋友组队,不过那样你也会碰见更厉害的对手。
如果大家在如何鉴定玩家水平上有好的想法欢迎提,但是如果想要通过抱怨玩家游戏内表现来证明匹配系统不公平,就是在和风车决斗了。每个人的看法都不一样的,系统判断他和你在遇到同样的队友和对手时候,胜率差不多,这也是我们目前能做到最好的了。
以下是文章的正文。
概述:
匹配系统的目的如下,优先级从高到低:
1、 保护新手不被有经验的玩家虐;让高手局中没有新手。
2、 创造竞技和公平的游戏对局,使玩家的游戏乐趣最大化。
3、 无需等待太久就能找到对手进入游戏。
匹配系统尽其所能的匹配水平接近的玩家,玩家的水平是来自他们在此之前赢了谁以及他们对手的水平。当你战胜对手,系统会认为你更强,当你输给对手,系统会认为你更弱。虽然这对于某一局游戏并不是那么的公平,但是长期来看,对于多局游戏是相当的公平:因为好的玩家总会对游戏结果造成正面的、积极的影响。我们使用了这样一个方法测试:给水平高的玩家一个新帐号,然后看他们游戏数局后的结果。我们通过大量的测试来证明了我们的想法。
并且,匹配系统知道预先组队的玩家有一些优势,如果你是预先组队,会给你一些更强的玩家。我们用一些非常巧妙的数学方法来解决预先组队的玩家VS solo玩家的匹配公平问题。我甚至让两个数学博士来验证,他们都说给力!
匹配是怎么完成的?
首先,系统将你放进适当的匹配池里——根据游戏模式(匹配模式、排位solo/双人、排位5人、其他模式等等)
然后,系统会尝试将匹配池里的人分到更细的匹配池里——5人组队 VS 5人组队,低等级新手 vs 其他一些低等级新手,如此这般。
当你在匹配池中,系统会开始尝试找到合适的配对,目标是撮合一个双方获胜机会都为50%的游戏。
第1步:确定你的实力:
*如果你是solo,就直接使用你的个人匹配分(也就是elo值,匹配模式和排位赛有不同的匹配分)
*如果你是预先组队的,你的匹配分是你队伍的平均分,并且会根据你组队的规模稍微提高一些,这样才能保证你匹配到更强的对手来抵消你组队的优势。我和一个计算机生物学的博士(Computational Biology Ph.D)通过研究成百上千的游戏结果,计算出了预先组队到底有多大的优势。我们还在幕后做了一些其他调整,比如新手和高玩组队,比如某地图上蓝队和紫队的玩家哪个更有优势,诸如此类。
第2步:确定你合适的对手:
*首先,系统会基于你的elo值,给你匹配跟你非常相近的玩家。最终,系统会放宽匹配的条件,给你一些不是那么完美的匹配,因为你肯定也不想永远匹配不到人。
*新手会得到一些特殊的保护,通常新手只会匹配到其他新手(在成熟的服务器里,这个比例达到了99%+。除非这个新手和一个高级玩家朋友预先组队)
第3步:确定匹配:
*最终,系统会匹配10个大体上同水平、同等级的玩家,促成一个游戏。
*系统会尝试平衡这个队伍,尽量使双方的获胜机会都为50%。在绝大多数时间,误差会在3%之内——类似50/50,49/51,48/52。实际上的获胜机会会有一点点差别(会在Q&A里面回答这个问题),但是我们的研究标明,在绝大多数情况下,这实际上是一个非常精确的预测。
长期来讲,我的匹配分(Elo值)是如何被测量的?
我们使用了一个修改过的ELO系统。ELO系统的基本要点通过使用数学比较两个人的积分,来预测两人的比赛结果——类似“A和B比赛数局,A会赢掉75%的局”。
然后,比赛结果出来了。如果你赢了,你会加分,如果你输了,你会被扣分。如果你是“出人意料”的赢了(系统认为你输的可能性更大),你会赢得更多的分数。额外的,如果你是一个新玩家,你会加分减分更快,以便于你可以快速的进入到你的水平等级。长期来看,这意味着好的玩家会得到高的匹配分,因为他们总是超过系统的预期,他们会不断加分直到系统可以正确的预测他们的胜率。
我们修改这个系统给团队比赛使用,基本概念是:基于该团队的所有玩家,得到一个团队ELO值。如果你的队伍胜利,系统会假设该队伍的所有玩家都要比系统猜测的“更强”,并且加分。虽然有一些问题,但是总体上来讲是有效的,特别是玩家预先组队的时候。
举例,本人在北美的服务器上有2000的普通匹配模式elo。如果我建一个小号,就算没有天赋和符文,我打到8级的时候就已经有1800elo了。这个系统并不完美,但是确实能够让玩家快速的接近自己水平所在的位置。
当你才开始玩的时候,我们也对ELO做一些微调,让你更快的进入你水平所在的位置。
*我们有大量的,有优先级的方法来鉴定一个玩家,相比一个标准的新玩家是否更有技巧,更猛。如果发现是的,我们会在幕后提高他的elo一个档次。
*我们同样也会分辨真的菜鸟新手。
*提升等级也会极大的提高你的elo值。这个也将帮助系统将30级满级的召唤师和低等级的召唤师区分开来
如果你想知道ELO系统的理论,以及更多细节,你可以看看这:
http://en.wikipedia.org/wiki/Elo_rating_system
http://zh.wikipedia.org/wiki/ELO
呃,等等,你是怎么处理组队玩家 vs solo(单排)玩家的?
我们大多数情况下,会通过将5人组队的队伍匹配给另外一个5人组队的队伍来避免这种情况的发生(几乎是所有情况下)。
对于“部分”组队,我们进行了大量的研究,发现优势并没有想象的那么大,所以我们也会把他们混到solo(单排)的玩家里。我们发现有大量的因素会影响到组队优势的大小:从预先组队的规模(比如2、3、4、5组队),到组队玩家的水平,到高玩带菜鸟的组合,到玩家水平不同而导致的情况不同,以及其他的一些必须考虑到的微妙因素。这个要比一些我们曾见过的点对点算法-将任意的统计数据杂糅在一起猜测分数-要可靠的多
发现这些优势,我们就知道对于预先组队的队伍,需要提高多少elo值,来达成一个公平的匹配,确定一个适当的,在数学上合理的调整。结果在有些情况下非常令人惊讶(同时会校正统计数据)。
虽然我们不会给出精确的数值,因为这是商业机密,但是我们可以告诉您:
*5人组队只是比5个路人稍强。
*部分组队只是比5个路人略强。
*菜鸟5人组队并不会带来太大的优势,但是高玩组队会有很大的优势。
*团队实力方差高的队伍,会比方差低的队伍更强。(方差简单来说,是在平均值相同的情况下反应各个元素的大小差异,方差大表示差异大,高方差的队伍类似高玩带低玩,低方差的队伍各个队员实力接近。)
*这说明了大体上,高水平玩家的Carry作用(可以理解为带领或者大腿),比低水平玩家的送人头作用(feeder)要强力。
好吧…那为什么要把预先组队的玩家和非组队玩家匹配到一起?
这是一些原因:
*这会帮助系统更快的找到适合你的匹配分,让系统更快的给你公平的匹配。这个的工作原理是,如果你组队,会减低运气所带来的成分,如果你单排,你的队友的好坏将对你输赢的影响更大。如果你预先组队,你会和你水平差不多的玩家组成队伍,你随机遇到猛男/坑爹队友几率会更小。因为游戏的结果更多来自你和水平相近的朋友的表现,而不是随机因素,所以你的匹配分会更快的到达精确的值。
*我们希望玩家可以和自己的朋友一起玩,因为这样会让他们玩的更有乐趣。你也不可能为5v5的游戏设置单独的2人匹配池或者3人匹配池,你需要组合他们来让系统工作。我们选择包含5人组队,因为这非常有乐趣。如果我们以后有足够大的匹配池,我们可能会将5人组队和部分组队区分开来,但是数据告诉我们,这基本不会提升匹配的公平程度,两者的效果基本相同。
其他一些常见的问题:
Q:为什么不加入一些其他的细节,类似击杀数等等来确定我的匹配分?
A:因为这是有偏差的,并且因为非常难以给击杀数这个数值来评分,你使用一个gank英雄的时候(类似老鼠和易大师),要杀多少人才能算是好的呢?而且这会让好的辅助玩家非常吃亏,因为他们的目的就不是拿人头,甚至会为了自己的Carry挡死。最后,玩家会为了刷数据,故意拖长游戏时间,然后拿大量farm对方的人头,而不是为了赢得比赛。我们尽量把测量玩家水平和激励玩家的机制放到努力取胜上面,我们避免了一些不必要的周边行为,而这些行为既没乐趣,还会扰乱匹配系统。
Q:我非常愤怒,因为匹配系统老给我坑爹队友(feeders,送人头的)。为什么不阻止这种情况发生?
A:我们的确有试图阻止这种情况发生,但是如果你被匹配到一个明显很弱的玩家,这也说明匹配系统同时匹配给你了一个或者多个强力的玩家。根据我们的研究,我们发现Carry(大腿)对队伍的带领作用要比feeder(送人头,坑爹)的坑爹作用更强。原因是在LOL里,多次击杀同一个玩家的收益是会递减的,并不像其他的同类游戏。我们的分析标明,在平均elo相同的情况下,提高或者降低这个队伍的某个玩家的elo值100(其他玩家相应降低/提高以保持平均分相同),整个队伍的实力会提高约7点elo值。这也表明,LOL中Carry的作用要比feeder的作用更给力一些。确实,有时候你会因为匹配到feeder而输掉这一局比赛,但是那是因为你们队的Carry不够给力。
Q:这样的话,如果我连胜了数盘,我是不是会被匹配到一些完全不可战胜的对手?
A:不全是。连胜导致你的匹配分会提高,你会不断遇到更强的对手——但是我们并不是故意的让你的胜率保持在50%的,我们的目的只是为了系统能够正确的预测游戏结果。最终,你会达到你的极限,你将会大致保持50%的胜率。比平均水平高的玩家,往往胜率会比50%略高,因为比他们弱的玩家更多,比他们强的玩家更少。所以匹配时,往往会略微“向下匹配”。对于排位顶尖的高端玩家,他们经常会有90%的胜率。
Q:你们会如何设计固定的队伍?类似WOW的竞技场队伍?
A:这是一个非常好的想法,并且让我们有机会设计出更好的匹配系统。我们迟早会做这个,并且使用我们开发的新方法。我们需要检验并且搞清楚你大体上有多强力(例如你的个人积分),同时允许你创建/解散队伍。这是个非常大的工程,但是我们对此非常有激情~
Q:如果匹配系统真的那么公平,那为何我老遇见那种一边倒的比赛?
A:有两个原因。第一,LOL有时候“雪球效应”会非常明显。前期太差的表现会导致游戏让人感觉非常一边倒。特别是某些队伍,如果他们开始很顺风,就会一直很顺风。我们遇到过同样的队伍,第一局25-5取胜,第2局确以类似的比分输掉。第二个原因是,玩家发挥的并不好,队伍选取阵容也不好。要进行一局势均力敌的比赛,你需要平衡玩家水平和平衡阵容的选取。有时候玩家选了一个比较渣的阵容,比如5个近战dps,或者3坦克2法师之类的,或者没选打野英雄而对面有。这样的话,尽管你的队伍实力也很不错,但是情况往往惨不忍睹。
Q:为什么我作为一个高等级玩家,有时候会匹配到一些低等级玩家?他们看上去都是来送人头的。
A:当一个高等级玩家和一个低等级玩家组队,这是一个非常令人头疼的问题。我们希望玩家可以和自己的朋友一起玩,并且希望这是一种愉快的体验。但是我们并不希望将一部分人的快乐建立在另一部分人的痛苦之上,所以我们往往将这种组合评分更高,保护新玩家不会被高等级玩家虐待。非常不幸的是,不管我们怎么做,我们把这样的组合匹配到任何的游戏中,都有可能造成不愉快的体验。因此,我们计划将实施一个“不平衡组队”的队列,类似我们尽量将5人组队匹配给5人组队。
Q:我20级了,然后我被匹配到了一些10级的和一些29级的,怎么回事?
A:当不同等级的玩家组队,我们会使用他们的平均等级来作为匹配的参考。等级并不是匹配系统的主导参数——匹配系统通常是使用实力来匹配——但是我们也会尽量将等级相近的玩家匹配到一起。在预先组队的情况下,我们没法替玩家选择,所以我们尽我们所能,使用平均等级。我们会在这个计算系统里把30级的玩家看作36级,所以我们通常能让中等级玩家的游戏没有30级玩家,然而有时候呢,29级玩家能插进来。
posted @
2012-11-09 14:20 梨树阳光 阅读(1713) |
评论 (1) |
编辑 收藏
记录下这个小问题。root下可以显示路径但是切换到其他用户时没有路径显示,很不方便。在/etc/profile中加入export PS1='\u@\h:\w>',其中\u显示当前用户账号,\h显示当前主机名,\W显示当前路径。然后source一下就搞定了
posted @
2012-11-08 11:49 梨树阳光 阅读(1449) |
评论 (0) |
编辑 收藏
开门见山,我先提出几个问题,大家可以先想想,然后我再说出我的方法
1.如何判断一个数M是否为2的N次方?
2.一个数N,如何得到一个数是M,M是不小于N的最小2的K次方
先说第一个问题,我有两个思路
第一,可以通过判断M的二进制中1的个数。而判断M中1的个数可以通过下面方法获得
int GetOneCnt(int m)
{
if ( m == 0 )
return 0;
int cnt = 1;
while(m & (m-1))
{
cnt++;
m--;
}
return cnt;
}
很明显M中1的个数为1和M是2的N次方互为冲要条件
第二个思路,我们可以这样,还是利用M的二进制表示,从最高位开始,以变量high_pos表示第一个1的下标,接着从最低位开始,变量low_pos表示第一个1的下标,如果high_pos=low_pos,则M为2的N次方
int HighestBitSet(int input)
{
register int result;
if (input == 0)
{
return -1;
}
#ifdef WIN32
_asm bsr eax, input
_asm mov result, eax
#else
asm("bsr %1, %%eax;"
"movl %%eax, %0"
:"=r"(result)
:"r"(input)
:"%eax");
#endif
return result;
}
int LowestBitSet(int input)
{
register int result;
if (input == 0)
{
return -1;
}
#ifdef WIN32
_asm bsf eax, input
_asm mov result, eax
#else
asm("bsf %1, %%eax;"
"movl %%eax, %0"
:"=r"(result)
:"r"(input)
:"%eax");
#endif
return result;
}
再说第二个问题
其实有了第一个问题的思路,这个问题就更好解决了,先判断一个数是否为2^N,如果是,直接返回,否则返回2^(N+1)
代码如下
int CeilingPowerOfTwo(int iInput)
{
if (iInput <= 1)
return 1;
int32_t highestBit = HighestBitSet(iInput);
int32_t mask = iInput & ((1 << highestBit) - 1); // 相当于input对2^highestBit求余
highestBit += ( mask > 0 );
return (1<<highestBit);
}
posted @
2012-10-01 15:53 梨树阳光 阅读(1487) |
评论 (4) |
编辑 收藏
如果你对能很快回答出unicode和utf-8的关系,你可以直接跳过这篇文章。下面我来说说两者的关系和转换。(本文使用符号2字代表所有的汉字,英文,数字等)
首先明确一点,UTF-8是UNICODE一种实现方式。
UNICODE:代表一种符号集合,它规定了一种符合的二进制表示,没有指明存储方式。(
http://www.unicode.org/)
UTF-8:实现了UNICODE,使用多字节的存储方式。
我们先来考虑几个问题。
第一,如果使用单字节表示符号,很明显,完全不够用
第二,如果使用多字节表示符号,那么,机器在读取的时候,它怎么知道3个字节表示一个符号,还是表示3个符号
第三,如果使用2个字节表示一个符号,首先,最多能表示65535个字符还是会不够用,就算够用,比如ASCII码这类仅需1个字节就可以表示的符号,用2个字节表示,浪费空间了。
因此,UTF-8孕育而生。
首先UTF-8使用变长表示符号,简单的说,有的时候用1个字节表示符号,有的时候用2个字节表示符号,这样解决了浪费空间的问题。那么,如何解决第二个问题的呢,我们得了解下UFT-8的编码规则。
1.对于单字节的符号,字节第一个为0,后面7为为这个符号的unicode码
2.对于N字节的符号(N>1),第一个字节前N位为1,第N+1位为0,后面字节的前两位设为10,剩下可编码的位,为该符号的UNICODE编码。
这里我从网上找了一副图
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制)0000 0000-0000 007F | 0xxxxxxx0000 0080-0000 07FF | 110xxxxx 10xxxxxx0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面我具体解释下这幅图。
首先看第一行,它的意思是00000000到0000007F的UNICODE编码,对应的UTF-8的编码方式为0XXXXXXX(X表示可编码位,不足的补0)。
第二行表示00000080到000007FF的UNICODE编码,对应的UTF-8的编码方式为110XXXXX 10XXXXXX。以此类推
那么,问题是,这个范围是怎么定的?
很简单,我们还是从第一行说起。007F,实际有效位只有7位,所以,0xxxxxxx就足矣。但是0800开始,有效位至少为8位,我们得增加一个字节,按照UTF-8的规定,2字节的表示方式为110XXXXX 10XXXXXX,我们的编码位为11位(X的个数),所以,我们最多可以表示UNICODE编码位11位的字符,也就是07FF。07FF过了就是0800,有效位至少为12位,我们得用3字节来表示,按照UTF-8的规定,1110XXXX 10XXXXXX 10XXXXXX,最大编码位为16位,也就是FFFF,最后一行我就不再解释了。
通过上面这个过程我们了解了,UNICODE转UTF-8的过程,当然,逆过来就是UTF-8转换成UNICODE。
我们通过一个例子来演示上面的过程。汉字“杨”,UNICODE的编码位0x6768,二进制形式为0110011101101000,根据上面的图,我们知道它属于第三行,因此,它应该放入1110XXXX 10XXXXXX 10XXXXXX的模板中,结果是11100110 10011101 10101000,十六进制表示为E69DA8。
另外设计编码问题,我们绕不开另一个问题,就是大端小端的问题,不过这个问题,网上资料很多,也很好实践,这里我就不多啰嗦了。
posted @
2012-09-23 22:56 梨树阳光 阅读(1878) |
评论 (1) |
编辑 收藏
进程间通信方式包括了管道,消息队列,FIFO,共享内存,而共享内存是其中效率最高的。下图解释了其效率最高的原因(图片截取自《UNIX网络编程》)
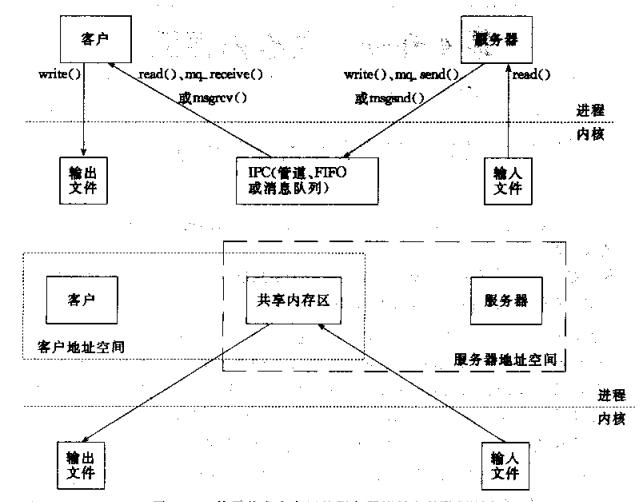
我们可以看到上面的拷贝次数是4次,下面则是2次。
接下来我们看看使用,其实网上和书上都有了很多资料,API就是那么几个。
int shmget(key_t key,size_t size,int shmflag)。
key:可以指定IPC_PRIVATE,那么系统会为你创建一个key,并且返回一个id号。也可以通过ftok函数生成一个key(不了解ftok的童鞋可以动手man一下)。那么为什么要一个IPC既要一个key又有一个ID呢。这里我觉得是为了方便其他进程访问。进程A创建了一个共享内存,内核为其分配一个ID,这个时候进程B想要访问,他怎么获取这个ID(难道需要A把ID发送给B??)。但是我们用一个key就很方便了。事先A,B进程都知道这个key,那么A创建了,B就可以通过事先知道key找到这块内存。
size:共享内存的大小。如果是获得一块内存,则该值应该为0。
shmflag:读写权限的组合,可以与IPC_CREAT和IPC_EXCL按位或。当指定一个key时,IPC_CREAT和IPC_EXCL配合使用可以在存在该key的共享内存时返回-1。
当该函数调用成功后,返回一个系统分配的共享内存,并且size大小的字节被初始化为0
void *shmat(int shmid, const void *shmaddr, int shmflg)
有了一块共享内存后,进程需要映射该内存到进程的地址空间。这个函数就是作用。
shmid就是之前获得ID,shmaddr如果指定了,就会配合shmflg确定映射地址,不过一般都不这么干的。返回值就是获得的地址,你可以往里面写你或者读你需要的数据了。同时调用了该函数,系统会修改shmid_ds数据。
int shmdt(const void *shmaddr)
解除绑定关系,参数就是我们之前获取的那个返回地址。(其实我觉得这里参数如果为ID貌似更统一些吧)
int shmctl(int shmid, int cmd, struct shmid_ds *buf)
这个函数主要做一些修改和查询。比如设置锁,解锁,移除一块共享内存。
简单介绍了API,还要说一下一些注意的东西
1.共享内存不会把数据写入磁盘文件中,这个区别于mmap
2.即使没有进程绑定在共享内存,共享内存也不会消失的。必须通过shmctl或者ipcrm删除(或者更暴力的方式关掉电脑)
另外我们可能会考虑,系统最多创建多少个共享内存,一个进程最多可以绑定多少个内存,一个共享内存创建的size最大最小值是多少。其实这些设置在/proc/sys/kernel下面,我们也可以自己写程序来读取。贴一段代码用来获取上面的信息
#define MAX_SHMIDS 8196
int main(int argc,char *argv[])
{
int i,j;
int shmid[MAX_SHMIDS] = {0};
void *addr[MAX_SHMIDS] = {0};
//测试可以创建多少个共享内存
for ( i = 0;i < MAX_SHMIDS;++i )
{
shmid[i] = shmget(IPC_PRIVATE,1024,0666|IPC_CREAT);
if ( shmid[i] == -1 )
{
printf("create shared memory failed,max create num[%d],%s\r\n",i,strerror(errno));
break;
}
}
for ( int j = 0;j < i;++j )
{
shmctl(shmid[j],IPC_RMID,NULL);
}
//测试每个进程可以attach的最大数
for ( i = 0;i < MAX_SHMIDS;++i )
{
shmid[i] = shmget(IPC_PRIVATE,1024,0666|IPC_CREAT);
if ( shmid[i] != -1 )
{
addr[i] = shmat(shmid[i],0,0);
if ( addr[i] == (void *)-1 )
{
printf("process attach shared memory failed,max num[%d],%s\r\n",i,strerror(errno));
shmctl(shmid[i],IPC_RMID,NULL);
break;
}
}
else
{
printf("max num of process attach shared memory is[%d]\r\n",i-1);
break;
}
}
for ( j = 0;j < i;++j )
{
shmdt(addr[j]);
shmctl(shmid[j],IPC_RMID,NULL);
}
//测试一个共享内存创建最小的size
size_t size = 0;
for ( ;;size++ )
{
shmid[0] = shmget(IPC_PRIVATE,size,0666|IPC_CREAT);
if ( shmid[0] != -1 )
{
printf("create shared memory succeed,min size[%d]\r\n",size);
shmctl(shmid[0],IPC_RMID,NULL);
break;
}
}
//测试共享内存创建最大的size
for ( size = 65536;;size += 1024 )
{
shmid[0] = shmget(IPC_PRIVATE,size,0666|IPC_CREAT);
if ( shmid[0] == -1 )
{
printf("create shared memory failed,max size[%ld],%s\r\n",size,strerror(errno));
break;
}
shmctl(shmid[0],IPC_RMID,NULL);
}
exit(0);
}
好了,下篇开始介绍如何控制读写。
posted @
2012-09-06 19:26 梨树阳光 阅读(2317) |
评论 (0) |
编辑 收藏
1.拷贝构造函数的形式
对于类X,如果它的函数形式如下
a) X&
b) const X&
c) volatile X&
d) const volatile X&
且没有其他参数或其他参数都有默认值,那么这个函数是拷贝构造函数
X::X(const X&);是拷贝构造函数
X::X(const X&,int val = 10);是拷贝构造函数
2.一个类中可以存在超过一个拷贝构造函数
class X {
public:
X(const X&);
X(X&); // OK
};
编译器根据实际情况调用const拷贝构造函数或非const的拷贝构造函数
3.默认的拷贝构造函数行为
a)先调用父类的拷贝构造函数
b)如果数据成员为一个类的实例,则调用该类的拷贝构造函数
c)其他成员按位拷贝
4.默认的赋值构造函数行为
a)先调用父类的赋值构造函数
b)如果数据成员为一个类的实例,则调用该类的赋值构造函数
c)其他成员按位拷贝
5.提供显示的拷贝和赋值构造函数
基本的原则是子类一定要调用父类的相应函数,参考方式
Derive(const Derive& obj):Base(obj)
{
…...
}
Derive& operator =(const Derive &obj)
{
if ( this == &obj )
return *this;
//方式一
Base::operator =(obj);
//方式二
static_cast<Base&>(*this) = obj;
return *this;
}
另外当你的成员变量有const或者引用,系统无法为你提供默认的拷贝和赋值构造函数,我们必须自己处理这些特殊的情况
posted @
2012-08-31 17:13 梨树阳光 阅读(1795) |
评论 (0) |
编辑 收藏
我们在类里面会定义成员函数,同时我们也希望定义成员函数指针。因此需要解决3个问题,第一怎么定义类的函数指针,第二赋值,第三使用。
我定义一个类,
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
};
int A::add(int a,int b)
{
return a + b;
}
int A::mul(int a,int b)
{
return a * b;
}
int A::div(int a,int b)
{
return (b !=0 ? a/b : a);
}
我现在想要定义一个指针,指向A类型中返回值为int,参数为两个int的函数指针。熟悉C的同学马上会写出typedef int (*oper)(int,int)。但是这个用到C++里就有问题了,
因为我们知道,类的非static成员方法实际上还有this指针的参数。比如add方法,它实际的定义可能会这样int add(A* this,int a,int b);因此,我们不能简单把C语言里的那套东西搬过来,我们需要重新定义这种类型的指针。正确做法是加上类型,typedef int (A::*Action)(int,int)
typedef int (A::* Action)(int,int);
int main()
{
A a;
Action p = &A::add;
cout << (a.*p)(1,2) << endl;
return 0;
}
Action p = &A::add;这个就是赋值语句
调用的时候注意,直接这样(*p)(1,2)是不行的,它必须绑定到一个对象上(a.*p)(1,2);我们也可以把类的函数指针定义在类的声明里。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
int (A::*oper)(int,int);
};
上面这种方式是针对非static成员函数的,那么static成员函数的函数指针应该怎么定义呢,还能用上面这种方式吗?我们知道static成员函数是没有this指针的,所以不会加上的类的限定,它的函数指针定义方式和C里面的函数指针定义方式一样的。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
static int sub(int,int);
};
int A::sub(int a,int b)
{
return a - b;
}
int main()
{
int (*pp)(int,int) = &A::sub;
cout << (*pp)(10,5) << endl;
return 0;
}
总结起来,非static成员函数的函数指针需要加上类名,而static的成员函数的函数指针和普通的函数指针一样,没有什么区别。
另外注意一点的是
如果函数指针定义在类中,调用的时候有点区别。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
int (A::*pfunc)(int,int);
};
int main()
{
A a;
a.pfunc = &A::add;
cout << (a.*(a.pfunc))(1,2) << endl;
return 0;
}
posted @
2012-08-14 17:17 梨树阳光 阅读(1476) |
评论 (0) |
编辑 收藏