很久没有碰C++,下个项目要开始使用C++,所以很多东西需要捡起来重新看看。从今天起记录一些笔记,方便自己今后查阅。言归正传,先从构造函数的初始化列表说起。我把这个知识点细化成3个问题,1.为什么要有初始化列表,它和构造函数中初始化有什么不一样。2.初始化的顺序。3.一些注意的细节。
先说第一个问题。我们有两个东西,是必须在初始化列表里完成的,一个是const修饰的变量,一个是引用。这点我就不细说了,查阅资料的都可以找到。下面我具体说说类成员。
class Test1{
public:
Test1()
{
cout << "Test1 default constructor" << endl;
}
Test1(int i)
{
cout << "Test1 value constructor" << endl;
}
Test1(const Test1 &obj)
{
cout << "Test1 copy constructor" << endl;
}
Test1& operator = (const Test1 &obj)
{
cout << "Test1 = constructor" << endl;
return *this;
}
~Test1()
{
cout << "Test1 destructor" << endl;
}
};
class Test2
{
public:
Test2()
{
t1 = Test1(1);
}
private:
Test1 t1;
};
我们在构造函数中初始化Test1,我们看看运行结果
Test1 default constructor
Test1 value constructor
Test1 = constructor
Test1 destructor
Test1 destructor我们分析下这个输出。Test1 default constructor,这说明在进入Test1构造函数之前,已经初始化了t1成员,并且调用的是无参构造函数。Test1 value constructor这个是Test1(1)创建出来的对象。Test1 = constructor,这个表示条用了拷贝构造函数,Test1 destructor这个表示Test1(1)这个临时对象的析构,Test1 destructor这个表示是t1这个成员对象的析构。从上面的结果来看,构造函数中t1 = Test1(1);其实并不是真正意义是上的初始化,而是一次拷贝赋值。当进入构造函数内部之前,类成员会被默认构造函数初始化。如果说Test1是个很大的对象,这块会造成性能上的开销。所以,这点也是使用初始化列表的原因之一。
第二我们再来说下顺序问题。简单的原则是初始化列表里的会先于构造函数中,初始化列表里会按照变量声明的顺序。我们具体看看下面的例子。
class Test3(){
public:
Test3(int x,int y,int z):_z(z),_y(y)
{
_x = x;
}
private:
int _x,_y,_z;
};
按照上面的说法,赋值的顺序是_y,_z,_x。
第三个是注意问题,每个成员只能在初始化列表里出现一次。
class Test3{
public:
Test3(int x,int y,int z):_z(z),_y(y),_z(x)
{
_x = x;
}
private:
int _x,_y,_z;
};
比如这种就是问题的。_z被初始化了2次。
posted @
2012-08-14 10:24 梨树阳光 阅读(1541) |
评论 (3) |
编辑 收藏
写服务器的,通常会涉及到内存池的东西,自己在这方面也看了写了一些东西,有些体会,写出来跟大家分享下。
内存池基本包含以下几个东西,第一,初始化。第二,分配内存。第三,回收内存。所谓初始化,就是在服务器启动的时候,或者第一次需要内存的时候,系统分配很大的一块内存,方便之后的使用。分配内存,就是从内存池中取出需要的内存给外部使用,当然这里需要考虑的是当内存池中没有内存可分配时候的处理。回收内存,简单来说,就是外面对象生命期结束了,将分配出去的内存回收入内存池中。好了简单概念就说完了,我们先来看一种最简单的设计方式。
//为了方便描述,这里附上几个简单的链表操作宏
#define INSERT_TO_LIST( head, item, prev, next ) \
do{ \
if ( head ) \
(head)->prev = (item); \
(item)->next = (head); \
(head) = (item); \
}while(0)
#define REMOVE_FROM_LIST(head, item, prev, next) \
do{ \
if ( (head) == (item) ) \
{ \
(head) = (item)->next; \
if ( head ) \
(head)->prev = NULL; \
} \
else \
{ \
if ( (item)->prev ) \
(item)->prev->next = (item)->next; \
\
if ( (item)->next ) \
(item)->next->prev = (item)->prev; \
} \
}while(0)
struct student
{
char name[32];
byte sex;
struct student *prev,*next;
};
static struct mem_pool
{
//该指针用来记录空闲节点
struct student *free;
//该变量记录分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存“块”的函数
bool mem_pool_resize(size_t size)
{
//该函数创建size个不连续的对象,把他们通过链表的方式加入到s_mem_pool.free中
for ( size_t i = 0;i < size;++i )
{
struct student *p = (struct student *)malloc(sizeof(struct student));
if ( !p )
return false;
p->prev = p->next = NULL;
INSERT_TO_LIST(s_mem_pool.free,p,prev,next);
}
s_mem_pool.alloc_cnt += size;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == NULL )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.free;
REMOVE_FROM_LIST(s_mem_pool.free,ret,prev,next)
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
memset(p,0,sizeof(struct student));
INSERT_TO_LIST(s_mem_pool.free,p,prev,next)
}
好了最简单的内存池的大致框架就是这样。我们先来看下他的过程。首先,在mem_pool_init()函数中,他先分配512个不连续的student对象。每分配出来一个就把它加入到free链表中,初始化完成后内存池大概是这样的
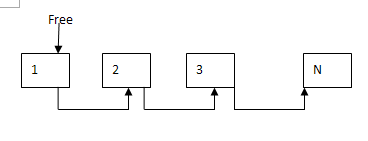
接下来就是从内存池中取出一个对象get_data()。函数先去判断是否有空闲的对象,有则直接分配,否则再向系统获取一"块"大的内存。调用一次后的内存池大概是这样的
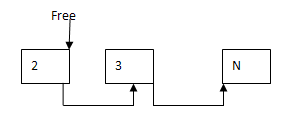
释放对象,再把对象加入到Free链表中。
以上就是过程的简单分析,下面我们来看看他的缺点。
第一,内存不是连续的,容易产生碎片
第二,一个类型就得写一个这样的内存池,很麻烦
第三,为了构建这个内存池,每个没对象必须加上一个prev,next指针
好了,我们来优化一下它。我们重新定义下我们的结构体
union student
{
int index;
struct
{
char name[32];
byte sex;
}s;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
union student *mem;
//已分配结点个数
size_t alloc_cnt;
}s_mem_pool;
//分配内存块的函数
bool mem_pool_resize(size_t size)
{
size_t new_size = s_mem_pool.alloc_cnt+size;
union student *tmp = (union student *)realloc(s_mem_pool.mem,new_size*sizeof(union student));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.alloc_cnt,0,size*sizeof(union student));
size_t i = s_mem_pool.alloc_cnt;
for ( ;i < new_size - 1;++i )
{
tmp[i].index = i + 1;
}
tmp[i].index = -1;
s_mem_pool.free = s_mem_pool.alloc_cnt;
s_mem_pool.mem = tmp;
s_mem_pool.alloc_cnt = new_size;
return true;
}
#define MEM_INIT_SIZE 512
#define MEM_INC_SIZE 256
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
union student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
union student *ret = s_mem_pool.mem+s_mem_pool.free;
s_mem_pool.free = ret->index;
return ret;
}
void free_data(union student *p)
{
if ( !p )
return;
p->index = s_mem_pool.free;
s_mem_pool.free = p - s_mem_pool.mem;
}
我们来看看改进了些什么。第一student改成了联合体,这主要是为了不占用额外的内存,也就是我们上面所说的第三个缺点,第二,我们使用了realloc函数,这样我们可以使我们分配出来的内存是连续的。我们初始化的时候多了一个for循环,这是为了记录空闲对象的下标,当我们取出一个对象时,free可以立刻知道下一个空闲对象的位置,释放的时候,对象先记录free此时的值,接着再把free赋值成该对象在数组的下标,这样就完成了回收工作。
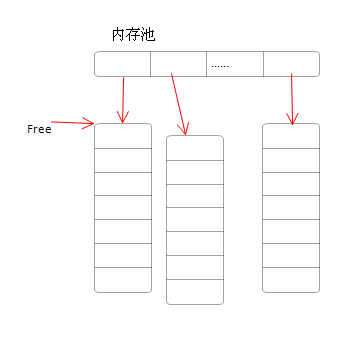
我们继续分析这段代码,问题在realloc函数上,如果我们的s_mem_pool.mem已经很大了,在realloc的时候我们都知道,先要把原来的数据做一次拷贝,所以如果数据量很大的情况下做一次拷贝,是会消耗性能的。那这里有没有好的办法呢,我们进一步优化
思路大概是这样
初始化
再次分配的时候,我们只需要重新分配新的内存单元,而不需要拷贝之前的内存单元。
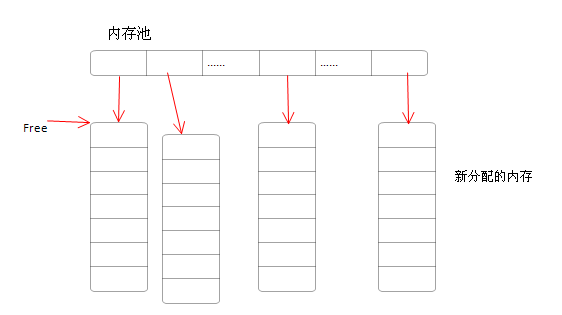
因此基于此思路,我们修改我们的代码
#include <stdio.h>
#include <stdlib.h>
struct student
{
int index;
char name[32];
byte sex;
};
static struct mem_pool
{
//该下标用来记录空闲节点
int free;
//内存池
struct student **mem;
//已分配块个数
size_t block_cnt;
}s_mem_pool;
#define BLOCK_SIZE 256 //每块的大小
//分配内存块的函数
bool mem_pool_resize(size_t block_size)
{
size_t new_cnt = s_mem_pool.block_cnt + block_size;
struct student **tmp = (struct student **)realloc(s_mem_pool.mem,new_size*sizeof(struct student *));
if ( !tmp )
return false;
memset(tmp+s_mem_pool.block_cnt,0,size*sizeof(struct student*));
for ( size_t i = s_mem_pool.block_cnt;i < new_cnt;++i )
{
tmp[i] = (struct student *)calloc(BLOCK_SIZE,sizeof(struct student));
if ( !tmp[i] )
return false;
size_t j = 0;
for(;j < BLOCK_SIZE - 1;++j )
{
tmp[i][j].index = i*BLOCK_SIZE+j+1;
}
if ( i != new_cnt-1 )
tmp[i][j].index = (i+1)*BLOCK_SIZE;
else
tmp[i][j].index = -1;
}
s_mem_pool.free = s_mem_pool.alloc_cnt*BLOCK_SIZE;
s_mem_pool.mem = tmp;
s_mem_pool.block_cnt = new_cnt;
return true;
}
#define MEM_INC_SIZE 10
//初始化函数
bool mem_pool_init()
{
if ( !mem_pool_resize(MEM_INIT_SIZE) )
return false;
return true;
}
struct student *get_data()
{
if ( s_mem_pool.free == -1 )
{
if ( !mem_pool_resize(MEM_INC_SIZE) )
return NULL;
}
struct student *ret = s_mem_pool.mem[s_mem_pool.free/BLOCK_SIZE]+s_mem_pool.free%BLOCK_SIZE;
int pos = s_mem_pool.free;
s_mem_pool.free = ret->index;
ret->index = pos;
return ret;
}
void free_data(struct student *p)
{
if ( !p )
return;
int pos = p->index;
p->index = s_mem_pool.free;
s_mem_pool.free = pos;
}
这里不一样的地方主要在mem_pool_resize函数中,mem变成了2级指针,每次realloc的时候只需要分配指针数组的大小,无须拷贝对象,这样可以提高效率,但是为了在释放的时候把对象放回该放的位置,我们这里在结构体里加入了index变量,记录它的下标。在内存池里,它表示下个空闲对象的下标,在内存池外,它表示在内存池中的下标。总的来说满足了一个需求,却又带来了新的问题,有没有更好的方法呢,答案是肯定,不过今天先写到这里,明天继续。
posted @
2012-07-19 11:41 梨树阳光 阅读(3608) |
评论 (2) |
编辑 收藏
从存储方式来说,文件在磁盘上的存储方式都是二进制形式,所以,文本文件其实也应该算二进制文件。那么他们的区别呢,各自的优缺点呢?不急,我慢慢道来。
先从他们的区别来说,虽然都是二进制文件,但是二进制代表的意思不一样。打个比方,一个人,我们可以叫他的大名,可以叫他的小名,但其实都是代表这个人。二进制读写是将内存里面的数据直接读写入文本中,而文本呢,则是将数据先转换成了字符串,再写入到文本中。下面我用个例子来说明。
我们定义了一个结构体,表示一个学生信息,我们打算把学生的信息分别用二进制和文本的方式写入到文件中。
struct Student
{
int num;
char name[20];
float score;
};
我们定义两个方法,分别表示内存写入和文本写入
//使用二进制写入
void write_to_binary_file()
{
struct Student stdu;
stdu.num = 111;
sprintf_s(stdu.name,20,"%s","shine");
stdu.score = 80.0f;
fstream binary_file("test1.dat",ios::out|ios::binary|ios::app); //此处省略文件是否打开失败的判断
binary_file.write((char *)&stdu,sizeof(struct Student));//二进制写入的方式
binary_file.close();
}
//文本格式写入
void write_to_text_file()
{
struct Student stdu;
stdu.num = 111;
sprintf_s(stdu.name,20,"%s","shine");
stdu.score = 80.0f;
FILE *fp = fopen("test2.dat","a+"); //此处省略文件是否打开失败的判断
fprintf(fp,"%d%s%f",stdu.num,stdu.name,stdu.score); //将数据转换成字符串(字符串的格式可以自己定义)
fclose(fp);
}
//MAIN函数调用前面两个方法
int _tmain(int argc, _TCHAR* argv[])
{
write_to_binary_file();
write_to_text_file();
return 0;
}
我们来看下,文件里面的格式
2进制文件
 文本文件
文本文件 2进制文件里面将111编码成6F,1个字节,这刚好是111的16进制表示,而文本文件中则写成31,31,31用了3个字节,表示111。73 68 69 6E 65 表示shine,之后2进制文件里是几个连续的FE,而文本文件中是38 30......文本文件将浮点数80.000000用了38(表示8) 30(表示0) 2E(表示.) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0),二进制文件用了4个字节表示浮点数00 00 A0 42
2进制文件里面将111编码成6F,1个字节,这刚好是111的16进制表示,而文本文件中则写成31,31,31用了3个字节,表示111。73 68 69 6E 65 表示shine,之后2进制文件里是几个连续的FE,而文本文件中是38 30......文本文件将浮点数80.000000用了38(表示8) 30(表示0) 2E(表示.) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0),二进制文件用了4个字节表示浮点数00 00 A0 42
通过这里我们可以初见端倪了,二进制将数据在内存中的样子原封不动的搬到文件中,文本格式则是将每一个数据转换成字符写入到文件中,他们在大小上,布局上都有着区别。由此可以看出,2进制文件可以从读出来直接用,但是文本文件还多一个“翻译”的过程,因此2进制文件的可移植性好。
posted @
2012-07-12 09:59 梨树阳光 阅读(13136) |
评论 (5) |
编辑 收藏先看一个简单的使用例子
求任意个自然数的平方和:
int SqSum(int n,)
{
va_list arg_ptr;
int sum = 0,_n = n;
arg_ptr = va_start(arg_ptr,n);
while(_n != 0)
{
sum += (_n*_n);
_n = va_arg(arg_ptr,int);
}
va_end(arg_ptr);
return sum;
}
首先解释下函数参数入栈情况
在VC等绝大多数C编译器中,默认情况下,参数进栈的顺序是由右向左的,因此,参数进栈以后的内存模型如下图所示:
最后一个固定参数的地址位于第一个可变参数之下,并且是连续存储的。
| 最后一个可变参数(高内存地址处) | 第N个可变参数 | 第一个可变参数 | 最后一个固定参数 | 第一个固定参数(低内存地址处)
明白上面那个顺序,就知道其实可变参数就是玩弄参数的地址,已达到“不定”的目的
下面我摘自VC中的源码来解释
va_list,va_start,va_arg,va_end宏
1.其实va_list就是我们平时经常用的char*
typedef char * va_list;
2.va_start该宏的目的就是将指针指向最后一个固定参数的后面,即第一个不定参数的起始地址
#define va_start(ap,v)( ap = (va_list)&v + _INTSIZEOF(v) )
v即表示最后一个固定参数,&v表示v的地址,
#define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
该宏其实是一个内存对齐的操作。即表示大于sizeof(n)且为sizeof(int)倍数的最小整数。这句话有点绕,其实举几个例子就简单了。比如1--4,则返回4,5--8则返回8
3.va_arg 该宏的目的是将ap指针继续后移,读取后面的参数,t表示参数类型。该宏首先将ap指针移动到下一个参数的起始地址ap += _INTSIZEOF(t),然后将本参数的值返回
#define va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
4.va_end将指针赋空
#define va_end(ap) ap = (va_list)0
有了这个分析我们可以把上例中的代码重新翻译下
int SqSum(int n,)
{
char *arg_ptr;
int sum = 0,_n = n;
arg_ptr = (char *)&n + 4;//本机上sizeof(int) = 4
while(_n != 0)
{
sum += (_n*_n);
arg_ptr += 4;
_n = *(int *)(arg_ptr-4);
}
arg_ptr = (void*)0;
}
这样我们也可以写出我们自己的printf了
posted @
2012-07-12 09:51 梨树阳光 阅读(1115) |
评论 (1) |
编辑 收藏1.制作自己的动态库和静态库
linux下动态库以.so结尾,静态库以.a结尾,它们都以lib开头,比如一个库名为net,那么它的全名应该是libnet.so或者libnet.a。
我们有两个文件,hello.c和test.c,下面是两个文件的内容
//hello.c
#include <stdio.h>
void my_lib_func()
{
printf("Library routine called\r\n");
}
//test.c
#include <stdio.h>
int main()
{
my_lib_func();
return 1;
}
test.c调用了hello.c的方法,我们把hello.c封装成库文件。无论是静态库还是动态库,都是由.o文件组成,我们先把gcc -c hello.c生成.o文件
制作静态库
ar crv libmyhello.a hello.o,ar是生成静态库的命令,libmyhello.a是我的静态库名。下一步就是在我的程序中使用静态库
可以看到已经有了Library routine called的结果,说明调用成功了。
下面我们删除libmyhello.a,看看程序是否还是运行正常

我们发现程序依然运行正常,说明静态库已经连接进入我们的程序中
制作动态库

我们看见动态库libmyhello.so已经生成,下面继续使用

找不到库文件,这个时候我们把so文件拷贝到/usr/lib下面

运行成功
2.动态库和静态库同时存在的调用规则
我们可以发现,不论是动态库还是静态库,程序编译连接的时候都是加的参数-l,那么当他们同时存在的时候,程序会选择动态库还是静态库呢。我们做个尝试。

我们同时存在libmyhello.a和libmyhello.so,我们发现运行的时候,出现找不到动态库的错误,由此,我们可以得出结论,同时存在动态库和静态库的时候,gcc会优先选择动态库
posted @
2012-07-11 15:15 梨树阳光 阅读(1563) |
评论 (0) |
编辑 收藏