Livespace要在明年关闭了,搭建了micolog在google app engine,方便以后自己挣腾。上次用生拙的C#写个live space到livespace的博客迁移工具,使用metaweblog接口,见 Live Spaces新旧空间迁移方法 。上次使用getRecentPosts函数依次取得最近的一篇,然后存档后发表后,删除。这次通过正则表达式分析网页内容,获取到postid后,再使有getPost接口获取文章,再进行发表,而且这次使用python写成的。
metaweblog的内容不再叙述,其实这个协议写得真不怎么样,没有检索文章的接口,要让人硬生生地从网页中分析出postid来。因此解析postid是这个迁移工具的重要内容。
#获取www.cppblog.com样式的postid列表
def getCppblogId(blog):
url='http://www.cppblog.com/'+blog['user']+'/default.html?page=1&OnlyTitle=1'
urlfile = urllib.urlopen(url)
html = urlfile.read()
#获取存档页码数
pattern = re.compile(r'http://www.cppblog.com/'+blog['user']+'/default.html\?page=(\d+)&OnlyTitle=1')
pages = [1]
pages += pattern.findall(html)
ids=[]
for p in pages:
url= 'http://www.cppblog.com/'+blog['user']+'/default.html?page='+str(p)+'&OnlyTitle=1'
urlfile = urllib.urlopen(url)
html = urlfile.read()
pattern = re.compile(r'http://www.cppblog.com/'+blog['user']+'/admin/EditPosts.aspx\?postid=(\d+)')
id = pattern.findall(html)
ids += id
return ids
利用存档页面得到总共页数(或许页数多了或有问题,未验证),然后在每页解析出postid,cppblog较简单
def getLivespaceId(blog):
ids=[]
url=blog['user']+'.spaces.live.com/blog/'
i=0
while True:
url='http://'+url
urlfile = urllib.urlopen(url)
html = urlfile.read()
#print html
pattern = re.compile(r'entrycns!'+'([a-zA-Z0-9!]*)')
id = pattern.findall(html)
ids += id
pattern = re.compile(blog['user']+'.{1,50}pagedir=Next[^"]*')
urls = pattern.findall(html)
i=i+1
if len(urls) ==0:
break
url = unescape(urls[0])
return ids
live space没有总共的页数,只能一直next下去,发现没有next按钮了就停止,在每页再解析出postid来,unescape是自定义函数,目的是将html编码转换为像!等符号。
在迁移post时出现未micolog中定义的目录(category)会出错,因此迁移工具里如果碰到未定义过的类别,会自动舍弃掉。因此在使用
时需要在micolog里定义原先blog的类别,以致不会出现目录丢失的现象。此迁移工具在python2.5下完成,只要在源码中修改中开头的
srcBlog和dstBlog定义里的用户名,密码,webapi即可使用。源码中还实现BlogXML类,用于存档为xml格式,但未用于主程序中。
迁移工具源码
posted @
2010-11-08 20:55 len 阅读(1656) |
评论 (0) |
编辑 收藏
网络书签自从del.icio.us推出后,各个网络巨头都推出了相应的服务,对于各个书签服务,我针对了自己的情况进行了一番小调查后,确定下用google bookmarks服务。虽然del.icio.us美味书签最早推出,并有些特别的工功能,有着很大的用户群,但是我感觉它更偏向社交化的web服务,如将好的书签共享等,有着好友的功能,而我更偏向于需要一种简洁的书签存储功能。再有就是美味书签改版,对于网络安全功能过于注重,导致一种不好的用户体验,比如密码要数字字母混合,并且不能与用户名有太多重合等,还有密码最多线上保存两周。这些安全措施我都知道,但比一些公司密码管理还严,这至于吗?
国内的也出现了许多对应的web 2.0的网站,但是我没试用。还有一个选择就是baidu的搜藏,除了网页快照这个功能比较吸人外,其他并无亮点。最早看中google书签是因为它的开放性,比如搜藏都没有导出功能,而google就有导出,不怕用户流失,这一点蛮赞的。但是就其本身来说,使用并不方便,后来我使用了一直比较反感的工具条后,又开始使用它的书签,除了添加方便以外,整理和查找功能都比较薄弱。比如在线上,不能直接拖拽进行标签的分类,要手工点击编辑。google对这个服务不怎么看中,自推出以后,没有什么新的功能增加,希望以后有类似网页快照的存档功能就好了。
现在使用firefox3浏览器后,找到了GMarks插件,它能直接存取google书签,包含一个边栏,工具栏,和一个书签快速查找框,可进行批量修改,删除书签,删除标签等等功能。它也可以在没有安装google工具条的情况下使用,还有定制工具栏等,最妙的是有了google工具条中没有的查找功能,不然在上千条书签找到你需要的,那是有点儿困难的。现在我将自己的收藏全都保存到google书签了,这样以后重装系统,再不用做备份了,而且在不同的机子上都可以用。
顺便说下,如何将FF3的书签导入到google书签服务中,那就使用google工具条,里面书签选项里有导入功能的,很简单。
posted @
2008-09-25 20:06 len 阅读(3957) |
评论 (7) |
编辑 收藏
微软启用了新的live域名,有许多人将hotmail之类的帐号转到新的域名,这就出现了如何将原帐号下的个人信息转移到新帐号的问题。对于live messager的联系人列表可采用其联系人选项中的导入导出功能,而最麻烦当属将live spaces的空间博客转移到新的帐号名下。最直接方法就是联系微软管理员,将你旧帐号下的空间所有权转移到新帐号名下,但是业务上是否可行不得而知。因此转而另一方法,开新的空间,将旧空间的博客转移到新空间来,本文就是采用这种思路,顺带提及下live api的简单使用。
Windows Live Spaces MetaWeblog API提供了给外部程序进行文章内容设置和读取的功能。API使用了XML—RPC协议来在客户端应用程序与Weblog服务器端进行通讯。
为了使用MetaWeblog API编辑空间中的博文内容,首先需要在空间启用E-mail发布功能,并设置密码字。
- 到你的空间中的Options->E-mail Publishing选项进行配置
- 打开E-mail发布功能,并选择 secred word的密码字。
在程序中会用到用户名和密码,如果你的空间地址为: oldname.spaces.live.com,则用户名就是oldname,而不是你的live id,密码则是上面设置的secred word,而不是live id的密码。
现在的MetaWeblogApi能进行发布新博文,编辑现有的博文,获取指定博文,获取类别列表,获取最近发布的博文,删除博文,获取用户博客信息,获取用户信息等功能。由这些功能,想迁移博客内容,首先需要获取到旧空间里的博文。我们自然想到用MetaWeblogAPI metaWeblog.getRecentPosts Method函数,指定一个较大的值,然后获取全部的博文。很可惜,对于live spaces值只能取20,也就是说只能获取最近20篇博文。顺便提下,这里的20篇包括你己发布的,和存在空间里的草稿,这些草稿有时候并不会在空间里显示出来,但是操作时会有表示。如果用MetaWeblogAPI metaWeblog.getPost Method,需要知道指定博文的id号,没有获取到全部博文id的方法作辅助,这又是一个因难。
最后我采用了将metaWeblog.getRecentPosts方法的获取值设为1,每次取最近的一篇博文,然后记录id号,将这博文用MetaWeblogAPI metaWeblog.newPost Method发表到新空间,然后用MetaWeblogAPI blogger.deletePost Method将这id号的博文从旧空间中删去,重复进行,直到无法从旧空间里获取到博文。在程序实现借用了MSDN中的示例,为了防止网络故障之类以及做了备份,先是将获取博文内容写到本地文件,再进行删除。
程序中还要说明的是,由于live spaces服务器使用非标准的时间格式,造成用DateTime.Now和获取到的博文的dateCreated都是"1/1/0001 12:00:00 AM"的格式,这需要在Invoke方法调用前加上this.NonStandard = XmlRpcNonStandard.AllowNonStandardDateTime语句。还有需要用到CookComputing.XmlRpcV2.dll,它实现了.net 2.0版本的XML-RPC协议,己包含在文末的源码中。如果是.net 1.1,需要其他相应的文件,可具体参见http://www.xmlrpc.com/metaWeblogApi。
最后要提下的是,程序只用于我自己的空间迁移,再加上不懂C#,用户名和密码之类都硬编码了,MetaWeblog之类的方法也应能用于像cppblog之类用wordpress的博客空间。这些部分加之完善,应能做个博客搬家工具的。
参考:
文中的迁移工具源码下载
MDSN Windows Live Spaces SDKs
posted @
2008-09-24 21:50 len 阅读(2223) |
评论 (2) |
编辑 收藏
py2exe是实用的python脚本工具,可以将python脚本程序转换为exe执行文件。这样你的python程序就可以没有安装python运行时环境的电脑里运行了。py2exe方便地提取出python运行时所需要的文件档案,你需要做的就是写一个两三行的安装脚本文件。
py2exe可以从http://sourceforge.net/projects/py2exe/下载,唯一需要注意的是下载与你python版本号对应的版本,简单的英文教程http://www.py2exe.org/index.cgi/Tutorial非常容易入门。
对早先写的一个代理验证脚本进行exe文件封装作为示例,这测试脚本名为HttpProxyTester.py。
首先,最好测试运行一下待封装的脚本以确定没有问题,然后在HttpProxyTester.py脚本的同级目录新建一setup.py文件。
# setup.py
from distutils.core import setup
import py2exe
setup(console=['HttpProxyTester.py'])
上面的文件首先引入了distutils模块,这模块随python安装分发的,也就是说内置的。接着导入py3exe模块,它其实对distutils做了一些功能扩展。接下来的语句说明是控制台运行。对于windows的GUI模式运行,而不出控制台窗口,则需要setup(windows=['xxx'])之类指令,这对于pyWidget程序将很有用。
在完成安装脚本后,接下来就是在控制台下运行这脚本。
>python setup.py py2exe
这时会打印出许多log信息,并在同级目录下出现两个新的文件夹:build和dist。build文件夹下是py2exe生成的一些临时文件,dist就是需要分发的文件内容,可以这文件夹打包,然后在别的机子上运行了。
总之,py2exe非常简单实用,三分钟就可以搞定。
posted @
2008-08-11 19:19 len 阅读(7942) |
评论 (0) |
编辑 收藏
Python在处理功能复用和功能颗粒度划分时采用了类、模块、包的结构。这种处理跟C++中的类和名字空间类似,但更接近于Java所采用的概念。
类
类的概念在许多语言中出现,很容易理解。它将数据和操作进行封装,以便将来的复用。
模块
模块,在Python可理解为对应于一个文件。在创建了一个脚本文件后,定义了某些函数和变量。你在其他需要这些功能的文件中,导入这模块,就可重用这些函数和变量。一般用module_name.fun_name,和module_name.var_name进行使用。这样的语义用法使模块看起来很像类或者名字空间,可将module_name 理解为名字限定符。模块名就是文件名去掉.py后缀。下面演示了一个简单的例子:
#moduel1.py
def say(word):
print word
#caller.py
import module1
print __name__
print module1.__name__
module1.say('hello')
$ python caller.py
__main__
module1
hello
例子中演示了从文件中调用模块的方法。这里还展示了一个有趣的模块属性__name__,它的值由Python解释器设定。如果脚本文件是作为主程序调用,其值就设为__main__,如果是作为模块被其他文件导入,它的值就是其文件名。这个属性非常有用,常可用来进行模块内置测试使用,你会经常在一些地方看到类似于下面的写法,这些语句只在作为主程序调用时才被执行。
if __name__ == '__main__':
app = wxapp(0)
app.MainLoop()
模块搜索路径
上面的例子中,当module1被导入后,python解释器就在当前目录下寻找module1.py的文件,然后再从环境变量PYTHONPATH寻找,如果这环境变量没有设定,也不要紧,解释器还会在安装预先设定的的一些目录寻找。这就是在导入下面这些标准模块,一切美好事情能发生的原因。
import os
import sys
import threading
...
这些搜索目录可在运行时动态改变,比如将module1.py不放在当前目录,而放在一个冷僻的角落里。这里你就需要通过某种途径,如sys.path,来告知Python了。sys.path返回的是模块搜索列表,通过前后的输出对比和代码,应能理悟到如何增加新路径的方法了吧。非常简单,就是使用list的append()或insert()增加新的目录。
#module2.py
import sys
import os
print sys.path
workpath = os.path.dirname(os.path.abspath(sys.argv[0]))
sys.path.insert(0, os.path.join(workpath, 'modules'))
print sys.path
$ python module2.py
['e:\\Project\\Python', 'C:\\WINDOWS\\system32\\python25.zip', ...]
['e:\\Project\\Python\\modules', 'e:\\Project\\Python', 'C:\\WINDOWS\\system32\\python25.zip', ...]
其他的要点
模块能像包含函数定义一样,可包含一些可执行语句。这些可执行语句通常用来进行模块的初始化工作。这些语句只在模块第一次被导入时被执行。这非常重要,有些人以为这些语句会多次导入多次执行,其实不然。
模块在被导入执行时,python解释器为加快程序的启动速度,会在与模块文件同一目录下生成.pyc文件。我们知道python是解释性的脚本语言,而.pyc是经过编译后的字节码,这一工作会自动完成,而无需程序员手动执行。
包
在创建许许多多模块后,我们可能希望将某些功能相近的文件组织在同一文件夹下,这里就需要运用包的概念了。包对应于文件夹,使用包的方式跟模块也类似,唯一需要注意的是,当文件夹当作包使用时,文件夹需要包含__init__.py文件,主要是为了避免将文件夹名当作普通的字符串。__init__.py的内容可以为空,一般用来进行包的某些初始化工作或者设置__all__值,__all__是在from package-name import *这语句使用的,全部导出定义过的模块。
posted @
2008-07-24 19:42 len 阅读(20689) |
评论 (5) |
编辑 收藏
应用程序国际化,在开源世界里常以i18n被提及,i18n是Internationalization的简写,正好18个字母。在wxPython程序进行i18n,如果字符串是编码在源文件中时,完全可按照python程序的i18n的方法,即使用gexttext和locale模块。而wxPython程序在使用XRC文件做为界面资源时,则应使用wx.Locale模块,它封装了区域化相关的操作。i18n,或者国际化实际上涉及到语言习惯,数字格式等等类别的内容。这里只介绍语言多国化,将一个简单的英文程序转换为中文,涉及到源文件,可从这里下载。
创建PO文件
PO文件是Portable Object文件的简称,它包含需要翻译的字符串。我们需要从源文件进行提取。首先,对源文件test.py编辑,标识代码里需要翻译的字符串内容。我们使用_("xx")的方法,这种形式可能在许多开源源代码中见识过。
#加载菜单栏
menubar = rc.LoadMenuBar('IDR_MENU')
这里的IDR_MENU是资源标识ID,不需要翻译,因此不做改变,而下面的代码:
info.SetVersion('1.0')
info.SetDescription('XRC i18n Demo')
'XRC i18n Demo'是描述性的文本,需要进行翻译,将需要处理为
info.SetVersion('1.0')
info.SetDescription(_('XRC i18n Demo'))
接着需要生成.pot(Portable Object Template),这是po的模板文件。在将来程序可能配置成其他语种,其他语言的po文件都从它而来。为了创建这文件,需要用到GNU gettext工具集中的xgettext。向xgettext传入些必要的信息,来创建.pot文件。
>xgetttext --output=test.pot test.py
我们将wxPython界面以XRC文件保存了,那里同样有要翻译的字符串需要提取。用XRCed工具将XRC生成python代码,勾选上'Generate gettext strings'项即可。将源文件和XRC生成的test_xrc.py文件一起处理,生成一个test.pot。
>xgettext --output=test.pot test.py test_xrc.py
将得到的test.pot另存为test.po文件,然后进行翻译编辑,在这过程中文件需要使用utf-8编码。将对应的英文翻译成中文,将charset更改为utf-8。
"Content-Type: text/plain; charset=utf-8\n"
"Content-Transfer-Encoding: 8bit\n"
#: test.py:19
msgid "XRC i18n Demo"
msgstr "XRC 国际化示例"
...
.pot和.po这些文件都是文本文件,主要供翻译者使用。为了使程序在运行时能获取相关的翻译的内容,要进行所谓的编译过程,将文本文件转换为二进制文件.mo。这里用了gettext工具集中的另一程序msgfmt。
> msgfmt --output=test.mo test.po
因为windows下没有像linux像有公共存储.mo文件的目录,保持平台的迁移性,在应用程序本地目录下新建locale目录,用来存放编译过的.mo文件,然后将test.mo移动至locale目录。在完成这些步骤后,就转入代码方面的更改了。
wxPython代码更改
原先的代码只需要做小改动:
def OnInit(self):
wx.Locale.AddCatalogLookupPathPrefix('locale')
self.locale = wx.Locale(wx.LANGUAGE_CHINESE_SIMPLIFIED)
self.locale.AddCatalog('test')
import __builtin__
__builtin__.__dict__['_'] = wx.GetTranslation
首先,增加了新的目录文件路径,这将使wxPython搜索这个目录,寻找匹配的.mo文件。接着创建wx.Locale对象,将其初始化为简体中文,这将对应于zh_CN。最后将wx.GetTranslation做了一全局映射,这样你在其他类中,比如示例中TestFrame也能使用_('xx')调用。这样wxPython的i18n工作就完成了,下面是翻译前后的界面截图。
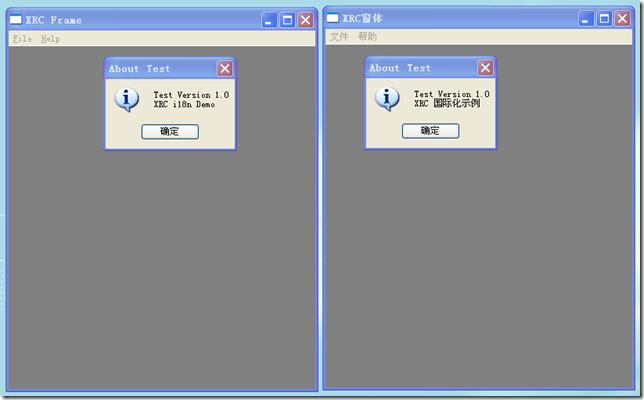
一些有益的讨论
.mo文件的查找目录
如果你将locale目录下的test.mo文件删除掉,然后将test.py中的wx.LANGUAGE_CHINESE_SIMPLIFIED改为wx.LANGUAGE_CHINESE,重新运行程序看看。发现界面变成了如下的繁体中文,但是菜单'档案'下的Exit还是英文。

因为缺失.mo文件,但又指定wx.LANGUAGE_CHINESE,wxPython运行时使用了wxstd.mo文件。wxstd.mo有许多预编译好的常见字符串的对应关系,它随wxPython发布,在wx/locale下有许多语言版本的wxstd.mo。
对于wxPython会对待查目录"DIR"来搜索.mo文件,查找它下面的这些目录,(DIR/LANG/LC_MESSAGES;DIR/LANG;DIR),对于哪些是待查目录,各个系统下又有不同,在所有的平台上,LC_PATH环境变量指定的目录将成为待查目录,在Linux下/share/locale, /usr/share/locale, /usr/lib/locale, /usr/locale /share/locale以及当前目录将是待查目录。在上面我们已经用过AddCatalogLookupPathPrefix()函数,其作用就是增加自己的待查目录。
在示例程序中,将test.mo放在locale\zh_CN\LC_MESSAGES或者locale\zh\LC_MESSAGES同样是可行的。但是如果使用wx.LANGUAGE_CHINESE指定,则zh_CN目录将不可行,因为它只是特化目录,指简体中文,而zh目录同样适用。
工具链再讨论
gettext进行国际化是开源社区的主流方案,它也提供了许多实用工具供使用。上面提到了xgettext,msgfmt,还有msginit.exe,它将根据.pot文件创建新的.po文件,然后初始化一些元信息,像作者信息,项目,以及编码等,当然也可像上面的手工编辑。msgmerge.exe将两个.po文件进行合并。除了使用GNU Gettext工具集,也可使用随python发布的tool\i18n目录下pygettext.py和msgfmt.py,它们等同于上述的两个工具。
对于编辑.po文件,可以尝试一下Poedit,它提供了图形化的编辑环境,其他功能我就不清楚了。
posted @
2008-07-15 20:21 len 阅读(2298) |
评论 (0) |
编辑 收藏
在Windows下,许多网络程序的连接依赖于IE浏览器中的代理服务器的设置,IE浏览器的代理设置很可能设定了注册表中的全局网络连接配置。
我在IE浏览器中设置了代理,而使用Maxthon浏览网页。在写Python时,用了urllib2库,后来出现了下面的错误:
urllib2.URLError: <urlopen error (10061, 'Connection refused')>
先前这个程序是运行正确的,又直接用浏览器访问需要的网址,正常。通过排查,发现IE浏览器中设置了代理,而代理无效,而urllib2库使用其网络配置,因此无法连接。通过取消代理,程序连接正常。
还有一例是,刚才用Windows Live Writer检索日志,和发布日志时出错,分别显示如下的错误:
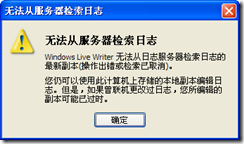
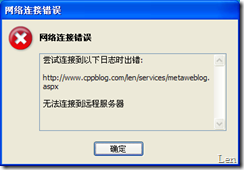
这也是因为WLW使用IE的网络设置,造成的网络错误而显示的错误提示。
因此在设置了IE代理,并使用其他与网络相关的程序,要特别注意其是否对IE代理设置有依赖。像Maxthon等就可选择不使用IE代理配置的选项。
posted @
2008-07-08 13:27 len 阅读(1004) |
评论 (0) |
编辑 收藏
Windows Live Writer是写博客的利器,非常好用。只是对一些常见的html标签支持不足,比如没有预排文本标签<pre>之类的。在插入示例代码时,我不喜欢使用网上的那些高亮插件,它们增加了一些我感觉不友好的标签元素。我在写文章时,代码放在<pre>标签,然后使用自定义的code类,如果是一些屏幕输入输入文本,会用一个console类来进行说明。如果直接从源代码拷贝文本至html源文件时,xml文件的的<>"之类标签需要进行转义才可以。在这之前,我都需要手工将WLW切换到HTML模式进行创作,然后修改这些标签,非常麻烦。这样干了几次后,昨天决定自己写个WLW插件用。在搜索引擎的帮助下,找到Dflying Chen的 为Windows Live Writer开发插件——InsertSearchPageLink这篇文章,并在其参照完成了插件编写。
但在找到这篇文章之前,和编写插件的过程中,还是费了很多功夫。最早我认为写插件是需要下载SDK之类的软件,所以在Live Writer官方开发网站,Live Writer网,MSDN之类的找了个遍,看见是有SDK之类字样的下载,但弄不下来只有文档,根本不见其什么头文件,DLL之类的。在这花费了很多时间,最后才发现WLW插件的SDK是随WLW一起分发了,也就是WindowsLive.Writer.Api.dll之类的,这些dll 都随WLW主程序在一个目录中。还有一点是,现在WLW在中国是随Live套件一起发布的,因此路径由原来的C:\Program Files\Windows Live Writer变成了C:\Program Files\Windows Live\Writer,插件目录为Plugin。如果在网上发现有好用的插件,只需要将其发布的插件dll扔到这个目录就行了。
在开发中碰到图标资源不能成功加载,在Dflying Chen的文章中特意提到了图标资源需要是嵌入形式,我也按照其操作的,总以为是这里出现问题。后来花了一些时间,才找到总是的根源:自己在开发中更改了工程名,导致最后生成的程序集的名称与后来的命名空间名称不一致,图标路径就出错了。C#也只是这次用一下,这些都没有接触到。
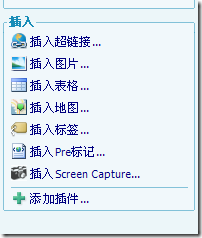
昨天弄完自己的“插入Pre标记”插件后,想到自己写博客常需要截图,遂想再开发一个截图工具的。最早搜到了别人调用SnagIt搜件,不好用,因为SnagIt是商业软件,需要注册的。后来找到了picpick,小巧免费,非常实用。我想调用picpick的,但是在参照Insert SnagIt Screen Capture发现是用COM接口,而无奈picpick没有这样供开发使用的接口考虑,最终不可行。后来经过一些其他的尝试,都告失败。最后还是搜索帮了忙,找到了Screen Capture这个插件,原来有别人已完工了。
最后附上,我用这个新插件截的图,非常好用,只需一步:
posted @
2008-07-05 21:43 len 阅读(1218) |
评论 (0) |
编辑 收藏
安装Cygwin
在cgywin官方主页下载安装文件setup.exe,这只是一个网络安装包,体积很小。cgywin包含了许多GNU下的应用程序,真正安装时会根据你选择的组件,会自动去网上下载安装的。在国内最好使用镜像服务,这样速度会提高很多,建议去http://www.cygwin.net.cn/或http://www.cygwin.cn/下载上述的安装包,并在安装进行到Choose A Download Site这个步骤时,选择合理的镜像。由于中国南北网速的差异,上述两个地址都尝试一下,看看哪个对你而言速度更快一些。
在进行到Select Packages这个步骤时,选择你需要包,建议如下:
- Shells -> rxvt-unicode-x 强大的X终端,可用它替换windows下的cmd.exe
- Net-> openssh ssh客户端,可作putty的替换
- Net-> inetutils 可选,包含一些基本的网络工具,如telnet,否则在cygwin下无法使用windows的telnet
cygwin安装时会自动进行包关联,在安装rxvt时,已自动将X server安装上了。
配置调整
启动cygwin,实际上是运行cgywin.bat批处理,它又调用了cmd.exe。我们将安装的rxvt作为默认终端,需要修改cygwin.bat。下面是我机子上的配置修改,请对应修改相应的路径。
@echo off
d:
chdir d:\Cygwin\bin
rxvt -e bash --login -i
调整rxvt观感,需要修改你用户主目录下的.Xdefaults文件,此文件在你选择的安装目录下的home\usrname下,在我的机子上是D:\Cgywin\home\len。若不存在,可在此目录下新建一个,修改内容如下:
Rxvt*background: black
Rxvt*foreground: #E2E6C7
Rxvt*font: 9x16
Rxvt*boldFont: 9x16
Rxvt*scrollBar_right: True
Rxvt*saveLines: 1024
Rxvt*geometry: 80x30
Rxvt*color0: black
Rxvt*color1: red
Rxvt*color2: green
Rxvt*color3: yellow
Rxvt*color4: blue
Rxvt*color5: magenta
Rxvt*color6: cyan
Rxvt*color7: white
Rxvt*color8: burlywood1
Rxvt*color9: sienna1
Rxvt*color10: PaleVioletRed1
Rxvt*color11: LightSkyBlue
Rxvt*color12: white
Rxvt*color13: white
Rxvt*color14: white
Rxvt*color15: white
在cygwin下也是可以访问Windows下其他盘符的,如cd /cygdrive/c/windows,就转到了C盘windows目录下。这样对于在linux下工作的人说有点儿别扭,更希望是以cd /mnt/c/windows的mount方式来访问其他盘符。这需要修改注册表的选项,将HKLM\software\Cygnus Solutions\Cgywin\mounts v2下的子项cygdrive prefix更改为/mnt即可。
远程登陆Linux桌面
其实这里介绍的不仅仅适用于Linux,而是针对X Window的。X Widonw的介绍不进行赘述,但需要明确其中的服务器端和客户端的区别,在X Window的概念中服务器端是指你进行显示,输入输出的机器,也是接下来示例中的本机len-computer,IP为10.3.164.70,而客户端指的是进行远程登陆的机器auto-desktop,IP为10.3.164.74。
在局域网内最简单的方法是使用XDMCP连接,这时远程的机器启用xdmcp。那台机器运行着ubuntu-8.04,用gdm进行窗口管理,编辑/etc/gdm/gdm.conf-custom如下,其他版本的linux需找到对应的窗口管理的配置文件。
[security]
DisallowTCP=false
[xdmcp]
Enale=true
修改完后,在远程机器上重启服务,$sudo /etc/init.d/gdm restart。接下来本机启动cgywin,转到X目录下,运行Xwin.exe,使用 -query指定远程的linux机器的ip即可。
Len@len-computer /usr/X11R6/bin
$ cd /usr/X11R6/bin
Len@len-computer /usr/X11R6/bin
$ Xwin -query 10.3.164.74
这里会出现如下面图示的窗口,提示输入用户名和密码。另再附一张在登陆成功后,我在本地执行远程操作的截图。

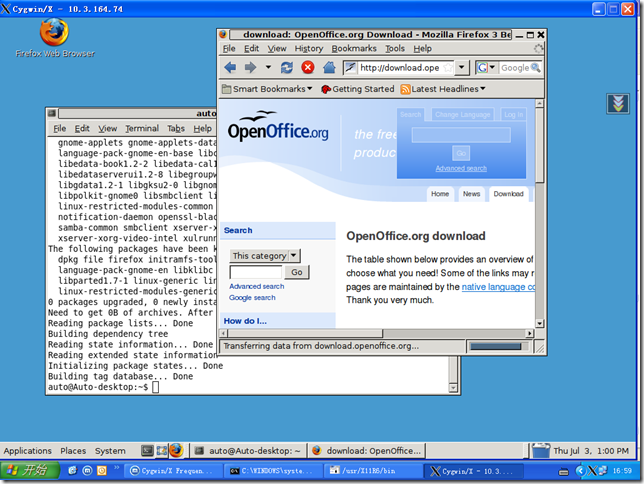
如果你需要连接的远程机器比较固定,可以修改本地机器d:\cgygin\usrX11R6\bin\startxdmcp.bat中的REMOTE_HOST值为你需要连接机器的IP,这个批处理设置了一些有用的环境变量值。或许你需要创建一个桌面的快键方式,这样每次点击,就直接连接到远程机器了。
不引入桌面环境
可能有时候只需要将某个需要X服务的远程应用程序引入到本地桌面显示,而不需要启动像上面的GNOME或者KDE等庞大的桌面环境。这样做比较适合喜欢终端操作的人,我就常常终端敲命令,然后将gvim,openoffice这些从远程导入到本地操作。
找到d:\cgywin\usr\X11R6\bin\startwin.bat,将%RUN% xterm -e /usr/bin/bash -l注释掉,因为我们己经有了rxvt,不需要一个新的xterm终端了,执行该批处理文件,就会在本机运行X server。启动cgywin,用ssh登陆到远程机器上,执行如下命令,导出DISPLAY环境变量和运行你感兴趣的程序。
auto@Auto-desktop:~$ export DISPLAY=10.3.164.70:0.0
auto@Auto-desktop:~$ gvim&
[1] 22652
auto@Auto-desktop:~$ oowriter&
其中环境变量DISPLAY中的:0.0部分表示X server的display和screen。display指运行着X server实例。如果使用TCP/IP连接,表示的是端口6000+display号做为连接。screen代表X server上的不同输出设备。我在例子中执行gvim和openoffice.org-writer,运行的效果可看下面的截图。在ubuntu上运行着的gvim和openoffice都在我本机10.3.164.70上显示了,并且可操作。
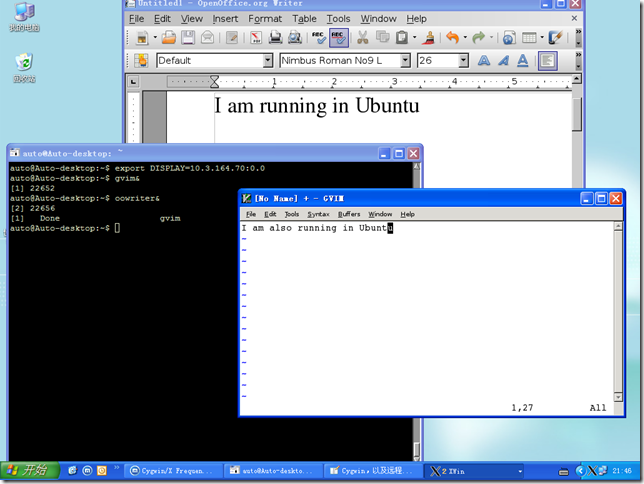
有用的链接
Cgywin/X FAQ 在碰到一些操作问题时,不妨先看看这份FAQ
使用cygwin X server实现Linux远程桌面 easwy介绍了KDE环境下的配置,部分受此启发
使用rxvt做为cygwin终端 碰到rxvt中文显示问题时,或许有帮助
posted @
2008-07-03 21:55 len 阅读(5474) |
评论 (0) |
编辑 收藏