QQ在许多公司内部被禁止使用,为了能使用QQ,稍微懂点儿计算机的人都知道用代理。QQ提供了socket和http代理这两种功能,socket代理功能强大,但一般公司对外允许连接的端口号比较有限,难以利用。大多数公司是允许连接外部的80端口的,这样使用QQ的http代理是可行的。但是找到能用的QQ代理有点儿麻烦,因此下面的Python代码提供了自动进行QQ代理验证的功能。
import urllib2
import socket
import re
f = urllib2.urlopen('http://www.proxycn.com/html_proxy/http-1.html')
content = f.read()
f.close()
ipPattern = re.compile(r'(\d+\.\d+\.\d+\.\d+):80')
ipList = ipPattern.findall(content)
print ipList
requestData = "CONNECT http.tencent.com:443 HTTP/1.1\x0d\x0a"
requestData += "Accept: */*\x0d\x0aContent-Type: text/html\x0d\x0a"
requestData += "Proxy-Connection: Keep-Alive\x0d\x0a"
requestData += "Content-length: 0\x0d\x0a\x0d\x0a"
for ip in ipList:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
s.connect((ip,80))
s.send(requestData)
data = s.recv(64)
if data.find("200 Connection established")!= -1:
print ip, 'good'
# A vailable proxy is found once, then exit the program
s.close
exit(0)
else:
print ip, 'bad'
except socket.error:
print ip, 'dead'
finally:
s.close
程序在找到一个可用的QQ代理后退出,用good标识。另两种代理服务器的状态是dead,说明本地无法连接到代理服务器,或是bad,能与代理服务器建立连接,但是代理不能与QQ服务器通讯。
代码思路
通过代理中国获取到80端口的代理服务器列表,使用了urllib2模块获取页面数据,然后正则表达式解析出80端口的IP地址存入list中。接下来的几行代码简单,但是很重要,使用较为底层的socket对象,构造合适的数据包通过代理,请求与QQ服务器连接,通过读取的返回数据包来验证连接是否能建立。
这里主要涉及到了HTTP协议的CONNECT的概念,很多人可能认为http代理只是为web浏览提供服务,其实CONNECT方法允许允许用户建立TCP连接到任何端口,这意味着代理不仅可用于HTTP,还可用于FTP,QQ等其他协议。只是网上提供CONNECT方法的代理服务器比较少,我有时候扫了一大堆,也没有找到一个可用的代理。反过来说,有时候你找到的能浏览网页的http服务器,未必能用在QQ上,QQ需要的是能CONNECT的代理。网页浏览一般只使用HTTP协议的GET或POST方法,提供这两种方法的服务器就多了。
了解了代码的原理,稍做改动,就可以用于其他类型的代理的验证了,需要的是一些基本网络知识和数据报的发送和接收。
posted @
2008-07-02 22:13 len 阅读(1658) |
评论 (1) |
编辑 收藏Subversion的属性是非常好用的功能,它将一些工作自动化,实现为受版本控制的源文件添加元信息的作用。属性是外部不可见的,可以简单认为是附加上在文件上的信息,和文件大小之类的信息是一样的,只不过他是通过subversion来管理的。属性的名称和值可以是你希望的任何值,限制就是名称必须是可读的文本,并且最好的一点是这些属性也是版本化的,就像你的文本文件内容,你可以像提交文本修改一样修改、提交和恢复属性修改,当你更新时也会接收到别人的属性修改—你不必为适应属性改变你的工作流程。
Subversion保留了一组名称以svn:开头的属性,来预定义一些有用的功能。比如你常会看到一些人的源代码底部有像下面之类标识的文字:
$Id: main_window.py 68 2008-06-30 02:05:05Z Len $
这就使用了Subversion 中的 svn:keywords的自动属性,它让将发生在源代码中的一些属性的变化自动地更新到源代码中。这行字的意思是表示,main_windows.py 这个源代码文件最后被用户 len 更新于 2008-6-30 02:05:05Z,修订版本号为 68。要实现这样的自动更新,你只要对需要这样属性的文件上使用下面这行指令。
> svn propset svn:keywords "Id" main_window.py
或者使用TortoiseSVN中的Properties的操作按钮,方便地增加新的属性。接着需要在源代码文件中需要 Subversion 进行自动更新的地方插入 $Id$ 这样的 Keyword,那么在你下次进行提交更新时,该$Id$ 就会被 Subversion 自动替换为$Id: main_window.py 68 2008-06-30 02:05:05Z Len $ 这样的格式。
Subversion 中可以使用的Keyword 包括下面这些:
- Id
上面介绍过的综合的格式
- LastChangedDate
最后被修改的时间,缩写为 Date。
- LastChangedBy
最后修改该源代码文件的用户名,缩写为 Author。
- LastChangedRevision
最后修订的版本号,缩写为 Revision。
如果想每次向Subversion服务器提交文件修改时,都要设置文件的属性,则需要进行Subversion配置的修改。配置文件在你用户的主目录下,在Windows下应类似于C:\Documents and Settings\Len\Application Data\Subversion\config文件,Len是Windows用户名,注意Application Data是隐藏文件夹,需要显示全部文件才能看到。接着如下相应的修改,对你想要处理的文件做配置。
enable-auto-props = yes
[auto-props]
*.c = svn:keywords=Id
*.py = svn:keywords=Id
对于开源项目,常见其源文件头部有着版权声明的文本,这些操作大多也是通Subversion的属性功能来完成的,有关更详细的介绍和操作指南,可参见Subversion中文手册中的属性章节。
posted @
2008-06-30 12:06 len 阅读(1924) |
评论 (0) |
编辑 收藏这个类表示在单独的控制线程中运行的活动。有两种方法可以指定这种活动,给构造函数传递回调对象,或者在子类中重写run() 方法。其他方法(除了构造函数)都不应在子类中被重写。换句话说,在子类中只有__init__()和run()方法被重写。
一旦线程对象被创建,它的活动需要通过调用线程的start()方法来启动。这方法再调用控制线程中的run方法。
一旦线程被激活,则这线程被认为是'alive'(活动)。当它的run()方法终止时-正常退出或抛出未处理的异常,则活动状态停止。isAlive()方法测试线程是否是活动的。
一个线程能调用别的线程的join()方法。这将阻塞调用线程,直到拥有join()方法的线程的调用终止。
线程有名字。名字能传给构造函数,通过setName()方法设置,用getName()方法获取。
线程能被标识为'daemon thread'(守护线程).这标志的特点是当剩下的全是守护线程时,则Python程序退出。它的初始值继承于创建线程。这标志用setDaemon()方法设置,用isDaemon()获取。
存在'main thread'(主线程),它对应于Python程序的初始控制线程。它不是后台线程。
有可能存在'dummy thread objects'(哑线程对象)被创建。这些线程对应于'alien threads'(外部线程),它们在Python的线程模型之外被启动,像直接从C语言代码中启动。哑线程对象只有有限的功能,它们总是被认为是活动的,守护线程,不能使用join()方法。它们从不能被删除,既然它无法监测到外部线程的中止。
-
class Thread(group=None, target=None, name=None, args=(), kwargs={})
-
构造函数能带有关键字参数被调用。这些参数是:
group 应当为 None,为将来实现ThreadGroup类的扩展而保留。
target 是被 run()方法调用的回调对象. 默认应为None, 意味着没有对象被调用。
name 为线程名字。默认,形式为'Thread-N'的唯一的名字被创建,其中N 是比较小的十进制数。
args是目标调用参数的tuple,默认为()。
kwargs是目标调用的参数的关键字dictionary,默认为{}。
如果子线程重写了构造函数,它应保证调用基类的构造函数(Thread.__init__()),在线程中进行其他工作之前。
-
start()
- 启动线程活动。
在每个线程对象中最多被调用一次。它安排对象的run() 被调用在一单独的控制线程中。
-
run()
- 用以表示线程活动的方法。
-
你可能在子类重写这方法。标准的 run()方法调用作为target传递给对象构造函数的回调对象。如果存在参数,一系列关键字参数从args和kwargs参数相应地起作用。
-
join([timeout])
- 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
-
当timeout参数未被设置或者不是None,它应当是浮点数指明以秒计的操作超时值。因为join()总是返回None,你必须调用isAlive()来判别超时是否发生。
-
当timeout 参数没有被指定或者是None时,操作将被阻塞直至线程中止。
-
线程能被join()许多次。
-
线程不能调用自身的join(),因为这将会引起死锁。
-
在线程启动之前尝试调用join()会发生错误。
-
getName()
- 返回线程名。
-
setName(name)
- 设置线程名。
-
这名字是只用来进行标识目的的字符串。它没有其他作用。多个线程可以取同一名字。最初的名字通过构造函数设置。
-
isAlive()
- 返回线程是否活动的。
-
大致上,线程从 start()调用开始那点至它的run()方法中止返回时,都被认为是活动的。模块函数enumerate()返回活动线程的列表。
-
isDaemon()
- 返回线程的守护线程标志。
-
setDaemon(daemonic)
- 设置守护线程标志为布尔值daemonic。它必须在start()调用之前被调用。
-
初始值继承至创建线程。
-
当没有活动的非守护线程时,整个Python程序退出。
参见:Python Library Reference
posted @
2008-06-24 16:54 len 阅读(9218) |
评论 (0) |
编辑 收藏介绍
cURL是一个利用URL语法的文件传输工具,是基于libcurl的前端命令行工具。它支持很多协议:FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 以及 LDAP。 它同样支持HTTPS认证,HTTP POST方法, HTTP PUT方法, FTP上传, kerberos认证, HTTP上传, 代理服务器, cookies, 用户名/密码认证, 下载文件断点续传, 上载文件断点续传, http代理服务器管道( proxy tunneling), 甚至它还支持IPv6, socks5代理服务器,通过http代理服务器上传文件到FTP服务器等等,功能十分强大。
除了使用curl命令行直接进行相关的网络操作,你也可以自由地使用libcurl,它是用C语言编写的,可以绑定到众多的编程语言中,如C,C++,PHP,Python,Perl,Java等等。你可以很方便地利用libcurl,在程序中进行一些网络传输工作,来代替一些语言的内置,使你的知识可重用。在Unix工作环境下,你可以用curl代替wget和ftp等工具,并能将这种学习经验迁移到将来使用libcurl来完成一些自动化任务。
curl是瑞典curl组织开发的,可以通过http://curl.haxx.se/来获取更详细的信息和下载文件。
curl命令行工具使用
curl太强大了,只能对其HTTP的部分作一简单的介绍,其他选项可以参见其附带的手册。它的后端库的使用也非常方便,主要也是在选项设置上,跟命令行基本无异。
用法
curl [选项] [URL...]
URL 语法
URL语法是跟协议相关的,具体细节可参见RFC 3986
可以指定多个URLs或者部分URL地址,通过花括号{}进行分割:
http://site.{one,two,three}.com
或者用[]使用字母序:
ftp://ftp.numericals.com/file[1-100].txt
ftp://ftp.numericals.com/file[001-100].txt (有前导零)
ftp://ftp.letters.com/file[a-z]].txt
当前序列嵌套不被支持,但是还是可以使用下列的样式:
http://any.org/archive[1996-1999]/vol[1-4]/part{a,b,c}.html
可以在命令行指定任意数量的URLs,它们将以指定的顺序被取回。
从curl7.15.1开始指定可以范围步长,所以可以得到第n个数或字母:
http://www.numericals.com/file[1-100:10].txt
http://www.letters.com/file[a-z:2].txt
如果使用了protocal://前缀,curl会将尝试你想使用的协议。它默认使用HTTP,但是其他一些协议也常被用作主机名。比如说,以"ftp"打头的主机名,curl会假定你想使用ftp协议。
Curl会尝试对多文件传输使用重连接,可以使从同一服务器获取很多文件时,不会进行多次的连接。这种做法改进了速度,当然这只会在同一命令行中指定的文件启用,而不会在独立的Curl调用时使用。
进度指示器
curl通常在操作时会显示一个进度指示器,来指明当前的传输量,传输速度和预计的剩余时间等等。
但是,即然curl默认将数据显示在终端,如果你调用curl进行操作,它会将数据打印到终端上,这时它会禁用掉进度指示器,否则这些会将输出信息搞乱掉。
如果在进行HTTP的POST或PUT请求时,你想将输出重定向到文件中,可以使用shell的重定向符(>),或者类似的-o[file]选项。
但是在FTP上传并不会这样,这些操作不会将数据插入到终端中。
如果想使用进度栏,而不是常规的指示器,那么-#会非常有帮助。
常用的HTTP选项
-A/--user-agent<agent string>
(HTTP)指定用户代理字符串发送给HTTP服务器。如果这个字段没有被设为"Mozilla/4.0",某些CGIs将不会正常工作。如果在字符串中存在空白字符,需要用单引号标识。这个字段值也可用-H/--header选项进行设置。
如果这选项被多次设置,最后的设置将起作用。
-b/--cookie<name=data>
(HTTP)将data作为cookie传给HTTP服务器,这数据当然是在使用了"Set-Cookie:"后,先前从服务端接收到的。这数据应是"NAME1=VALUE1;NAME2=VALUE2"的格式。
如果没有"="字符,它将会当作先前存储cookie行的文件名,如果它能被匹配的话。使用这选项,也能激活"cookie parser",它使curl记录传入的cookies数据。将它与-L/--locaion选项组合将会更加便利。被读取cookie的文件格式应当是文本HTTP头或者Netscape/Mozilla cookie文件格式。
注意:被-b/--cookie指定的文件只能作为输入使用。没有cookie会存储在这文件中。为了存储cookie,应使用-c/--cookie-jar选项或者直接将HTTP头输出到文件中,用-D/--dump-header选项。这选项可以设置多次,但是只有最后一个起作用。
-connect-timeout<seconds>
以秒计的最大超时,用于进行服务器连接时。这只在连接阶段起作用,一旦curl连接建立,这选项将不再起作用。
-c/--cookie-jar<file name>
指定在完成一系列操作后,需要将全部的cookie信息保存到哪个文件中。Curl会将先前读取的cookie的信息和从服务器返回的信息一起保存。如果没有cookie信息,则不会进行写文件。cookie信息的文件将与Netscape cookie文件格式保存。如果文件名被设置为'-',则将cookie打印至终端。
注意:如果cookie-jar不能被创建写入,整个curl操作也不会失改,甚至不会向你报告错误.使用-v将会得到警告显示,但也只能在可能导致发生致命错误的情况才会显示。
--create-dirs
这与-o选项配合使用,curl会在需要时建立本地文件夹结构。这选项会创建在-o选项中涉及到的文件夹。如果-o选项中的文件名没有使用到文件夹,或者所需的文件夹已经存在,则不会有文件夹创建。
-D/--dump-header<file>
将协议头写到指定的文件中。当你想存储HTTP站点发给你的数据时,这选项非常有用。在协议头中的cookie将来可以用curl的另外调用来进行读取,那就是-b/--cookie选项。但是-c/--cookie-jar选项将会是更好的存储cookie信息的方法。
当使用FTP协议时,ftp服务器的应答信息将相应地当作成协议头,然后被存储。
-p/-proxytunnel
当HTTP代理被设置后(-x/--proxy),选项会使不是HTTP协议的传输试图通过代理隧道,而不是表现得HTTP类似的操作形为。代理隧道的方法是通过HTTP服务器直接使用CONNECT请求,让代理直接连接到curl隧道所请求的远程端口号的方式来实现的。
-o/--output<file>
将输出信息打印到文件中,而不是终端。可使用{}或者[]取回多个文档,可在file指定格式中的'#'跟一数字,这样这变量将会由取回的URL字符串所取代。如下:
curl http://{one,two}.site.com -o "file_#1.txt"
如果有多个变量,可以写成下面的样子:
curl http://{site.host}.host[1-5].com -o "#1_#2"
你可对任意数量的URL使用同样多的这个选项
-x/--proxy<proxyhost[:port]>
使用指定的HTTP代理,如果端口号没有被指定,默认为1080.
这选项会覆盖环境变量中代理服务器的设置。如果环境变量中设置了代理,可将proxy设置为空字符串,来覆盖环境变量中的设置。
注意:所有通过HTTP代理的操作都会自动转化为HTTP协议。这意味着一些特定协议的操作将会变得无效。这不会有问题,如果在设置了-p/--proxytunnel选项来通过代理隧道进行操作。
简单示例
获取cppblog首页,打印至终端
>curl http://www.cppblog.com
重定向,保存到文件cppblog.html
>curl http://www.cppblog.com
作用同上,使用选项
>curl -o baidu.html http://www.baidu.com
使用http代理,可指定IP和端口
>curl -x 202.127.98.43:80 -o baidu.html http:www.baidu.com
在访问一些论坛时,常常要求启用cookie,因为这些网站需要启用cookie来记录sessioin信息,这时需要选项-D,将cookie信息保存起来
>curl -o cpp.html -c len@cppblog.com[1].txt http://www.cppblog.com
先前保存的cookie信息返回给网站,这通常会传回你的一些用户信息。
>curl -o cpp.html -c len@cppblog.com[2].txt -b len@cppblog.com[1].txt http://www.cppblog.com
posted @
2008-06-21 16:33 len 阅读(7247) |
评论 (1) |
编辑 收藏介绍
命令行接口是普遍,基础的人机交互接口,从命令行提取程序的运行时选项的方法有很多。你可以自己编写相对应的完整的解析函数,或许你有丰富的C语言编程经验,熟知getopt()函数的用法,又或许使用Python的你已经在使用optparse库来简化这一工作。大家在平时不断地谈及到“不要重复造轮子”,那就需要掌握一些顺手的库,这里介绍一种C++方式来解析命令行选项的方法,就是使用Boost.Program_options库。
program_options提供程序员一种方便的命令行和配置文件进行程序选项设置的方法。使用program_options库而不是你自己动手写相关的解析代码,因为它更简单,声明程序选项的语法简洁,并且库自身也非常小。将选项值转换为适合的类型值的工作也都能自动完成。库有着完备的错误检查机制,如果自己手写解析代码时,就可能会错过对一些出错情况的检查了。最后,选项值不仅能从命令行获取,也能从配置文件,甚至于环境变量中提取,而这些选择不会增加明显的工作量。
示例说明
以下面简单的hello程序进行说明,默认打印hello world,如果传入-p选项,就会打印出人的姓名,另外通过传入-h选项,可以打印出帮助选项。略微看一眼代码文件和相应的屏幕输入输出,然后我们再一起来看看这些是如何发生的。
//hello.cpp
#include <iostream>
#include <string>
#include <boost/program_options.hpp>
using namespace std;
int main(int argc, char* argv[])
{
using namespace boost::program_options;
//声明需要的选项
options_description desc("Allowed options");
desc.add_options()
("help,h", "produce help message")
("person,p", value<string>()->default_value("world"), "who")
;
variables_map vm;
store(parse_command_line(argc, argv, desc), vm);
notify(vm);
if (vm.count("help")) {
cout << desc;
return 0;
}
cout << "Hello " << vm["person"].as<string>() << endl;
return 0;
}
下面是在Windows命令提示符窗口上的输入输出结果,其中">"表示提示符。
>hello
Hello world
>hello -h
Allowed options:
-h [ --help ] produce help message
-p [ --person ] arg (=world) who
>hello --person len
Hello len
首先通过options_description类声明了需要的选项,add_options返回了定义了operator()的特殊的代理对象。这个调用看起来有点奇怪,其参数依次为选项名,选项值,以及选项的描述。注意到示例中的选项名为"help,h",是因为声明了具有短选项名和长选项名的选项,这跟gnu程序的命令行具有一致性。当然你可以省略短选项名,但是这样就不能用命令选项简写了。第二个选项的声明,定义了选项值为string类型,其默认值为world.
接下来,声明了variables_map类的对象,它主要用来存储选项值,并且能储存任意类型的值。然后,store,parse_command_line和notify函数使vm能存储在命令行中发现的选项。
最后我们就自由地使用这些选项了,variables_map类的使用就像使用std::map一样,除了它必须用as方法去获取值。如果as方法调用的指定类型与实际存储的类型不同,就会有异常抛出。
具有编程的你可能有这样的经验,使用cl或gcc对源文件进行编译时,可直接将源文件名放置在命令行中,而无需什么选项字母,如gcc a.c之类的。prgram_options也能处理这种情况,在库中被称为"positional options"(位置选项),但这需要程序员的一点儿帮助才能完成。看下面的经过对应修改的代码,我们无需传入"-p"选项,就能可指定"person"选项值
positional_options_description p;
p.add("person", -1);
store(command_line_parser(argc, argv).options(desc).positional(p).run(), vm);
>hello len
Hello len
前面新增的两行是为了说明所有的位置选项都应被解释成"person"选项,这里还采用了command_line_parser类来解析命令行,而不是用parse_command_line函数。后者只是对前者类的简单封装,但是现在我们需要传入一些额外的信息,所以要使用类本身。
选项复合来源
一般来说,在命令行上指定所有选项,对用户来说是非常烦人的。如果有些选项要应用于每次运行,那该怎么办呢。我们当然希望能创建出带有些常用设置的选项文件,跟命令行一起应用于程序中。当然这一切需要将命令行与配置文件中的值结合起来。比如,在命令行中指定的某些选项值应该能覆盖配置文件中的对应值,或者将这些值组合起来。
下面的代码段将选项通过文件读取,这文件是文本格式,可用"#"表示注释,格式如命令行中的参数一样,选项=值
ifstream ifs("config.cfg");
store(parse_config_file(ifs,config),vm);
notify(vm);
参考
Boost.prgram_options库文档
posted @
2008-06-15 21:03 len 阅读(13707) |
评论 (0) |
编辑 收藏涉及到软件:Xmanager 1.3.9 / Windows xp, ubuntu hardy
第一步,在ubuntu机器上配置好gdm,修改/etc/gdm/gdm.conf-custom,对照添加如下内容:
[security]
DisallowTCP=false
[xdmcp]
Enable=true
第二步,性能调优。这步非常关键,不然使用Xmanager登陆速度非常慢,且会报错,主要原因是gnome使用Esound进行声音数据的传送,需要使用TCP 16001端口。所以我建设在ubuntu关掉混音选项。
系统-首选项-音效-音效,将“允许软件混音”不要勾选上,
系统-首选项-字体-字体渲染,选择"单色",在“细节”的“字体渲染细节”中的平滑和微调选项,都选择"无"。
有用的参考:http://www.netsarang.com/products/xmg_faq.html
posted @
2008-06-01 21:10 len 阅读(7746) |
评论 (0) |
编辑 收藏Vim是功能强大的文本编辑器,但是每个工具都有其针对的适用群体。如果你只是偶尔做些文本编辑工作的话,那灵活而又显得繁琐的设置,以及特别的操作方式可能不适合你。但是你是跟我一样,是个平平凡凡的程序员,每天要花费大量时间在写代码,把弄着各式各样的程序语言:C\C++,Python,Tcl,Html,Xml,...,那么你可能需要像Vim这样的工具,即使你要在它上面花费些时间去熟悉和适应它。
先讲述一下,我跟Vim相处的过程,这是个从认识,到抛弃,到再认识,到再学习,到喜欢的过程。最早接触到Vim是在Solaris上,需要修改编辑一些配置文件,看着其他工程师们手指随意地在键盘上敲击,就完成内容的修改,根本没有动用到什么鼠标,那是好生羡慕。严格意义来说,那时候碰到还不是Vim,只是VI而已。在终端上工作,没有什么Notepad之类的程序,只好把指令抄在纸上,查查网上的资料,学会了h,j,k,l,w,q,e,这几个简单指类来进行简单的文本查看工作,仅此而己。后来在Windows上安装了VIM,但是挣腾了几下,没有适应过来,也就只好使用UltraEdit了。UltraEdit对一般的纯文本,按Windows习惯来说是蛮好使的。再后来,玩了会儿ruby,又装起了Vim,但是那时候的对Vim的使用也只是限于上面的简单的指令,再加上Vim的插件,来完成语法高亮,ruby中的MVC文件的方便跳转而已,还是没有习惯Vim,有时候还是不经意用UltraEdit来打开查看编辑文件。直到最近,需要编写Docbook,以及用Python,才真正花费了大量时间来学习使用Vim,才真正认识到到它的可爱。
接着说说,我为什么使用Vim,觉得值得学习它,喜欢它的理由吧,纯粹以自己的观点来叙述。
跨平台性,无论在Windows,Linux,Solaris,FreeBSD等等操作系统上,以及一些名都没有听过的系统上,你都可以找到它。这样就保证了你的学习投资的保值性,就拿UltraEdit做对比吧,即使你在UltraEdit上学会灵活运用许多功能,到了Linux上,你在这部分学习投资就没有价值了,你可能需要找其他称手的编辑器,然后再进行学习一些功能。特别在一些古老的大型机上的系统上,即使没有Vim,一般来说,还有Vi的,这样一般简单的操作命令还是可复用的。如果你确定你一直只呆在Windows上可忽略这一点。
开源免费,Vim是开源软件,意味着你可以自由使用,修改,查看它的代码。我对FreeSoftware,Open Source,Copyright,这些都是持中间立场的。对于自由查看,修改程序代的保证,有总比没有好。对于盗版软件,你有能力还是不要使用的好。正是这一特性,也是促使我放弃UE,投向Vim的重要原因。如果你对于使用盗版软件蛮不在乎,或你有财力购买正版软件,也可忽视这一条。
支持多种编程语言,Vim是程序员的编辑器,当然对程序员是非常友好的。它对C,C++,Python,Perl,Tcl,Ruby,PHP等等,以及一大堆我没有听过见过的语言,以语法着色,代码缩进等基本支持,还有一些其他特性。比如,我在编辑XML时,它能提供自动封闭标记的支持。因此如果你有对多种格式的文本编辑需要,那么你就有了一个编辑的大平台,不需用再装一大堆针对某个格式特定的编辑器了。正如跨平台性一样,你只要一次投资,多次回报。如果你专注于某一格式文件的工作,那这一点同样对于你来说是没有用的。
高效地编辑,Vim的操作方式相对于Windows上呆久了的人来说,是蛮奇特的,这一点我深有体会。但是正如很多人讲的那样,你掌握了其操作后,发现它会大大增进你的编辑速度。你的双手根本不用离开键盘,就完成了许多事情,可以让鼠标歇会儿了。如果你特别钟爱鼠标,或只偶尔打打字,那么我说的这点,同样对你没有用。
灵活的设置,Vvim可自定义的地方太多了,你可以自定义键盘映射,语法着色,缩进,格式等等。所以你在网上可以看到许多人贴着自己的vimrc配置文件,配置着自己喜欢的作业环境。如果你需要开盒即用的工具,那么这点对你的吸引力就不大了。
安装
可到VIM官网,选择Self-install executable形式的安装包下载安装。
帮助
帮助非常重要,VIM带有我认为非常好的帮助系统,可以获取你需要的任何有关VIM的详细信息。使用帮助非常简单,只需要:help安装即可。安装后程序带的是英文帮助,如果你对英文不是特别适应的话,可以去http://vimcdoc.sourceforge.net/下载安装中文帮助,或像我一样直接使用在线的中文帮助
http://vimcdoc.sourceforge.net/doc/help.html。强烈推荐你好好阅读下这一手册,然后完成其中的30分钟教程,这些内容在"初步知识"中。这比你在网上狂搜相关的教程要好得多。再次啰嗦一次,Vim的帮助非常强大,教程也非常好,是你碰到问题时的第一选择。
操作方法
对于基本操作方法,通过Vim的教程,你应该能很好的掌握了。一些常见的设置,关于特定类型的配置,因人而异,不想多述。我会列出一些认为比较好的参考文章,置于文尾供参考。但在下面,我还是在Windows下的Vim的使用做点说明,或许你现在用不上。
Vim文件夹结构
安装完Vim后,你在其安装目录下应有vim$ver($ver是版本号)和vimfiles两个文件夹。其中vim$ver是vim的程序运行时目录,在里面会看到gvim.exe(vim的GUI),vim.exe,xxd.exe等程序,一大堆的dll动态链接库,还有就是color(语法着色),doc(帮助说明),indent(缩进)等文件夹。在vimfiles内,也会看到color,doc,indent等类似的文件夹,但它们里面没有文件。vim$ver和vimfiles两者有什么区别呢,vim$ver是运行时文件目录,vimfiles相当于个人配置目录,常常有文章说在linux下将什么插件放进.vim下的plugin等等之类的,其.vim在windows下就相当于vimfiles。
标签页
Tabpage是Vim后增的功能,类似于UltraEdit的标签页。也想在Windows下使用Untraledit一样,在同一个VIM实例中打开多个文件的话,需要做些小修改。在注册表中删除"HKCR\*\shellex\ContextMenuHandlers\gvim\"主键,然后在Shell下新项"Vim 编辑",再在其下新建command项,然后修改其值为$vimruntime\gvim.exe -p --remote-tab-silent "%1",其中$vimruntime修改为你系统中VIM实际运行目录。如果你不知道$vimruntime的值,可以打开gvim,输入:echo $vimruntime。你想双击关联文件,也在同一实例打开的话,查找注册表中gvim相关项,将$vimruntime\gvim.exe改为上述的值即可,主要是HKLM\software\classes\application\gvim.exe\shell\edit\command下的值。
文件编码
具体可参见"Vim实用技术:实用技巧"。我推荐内部编码使用utf-8,以支持国际化,即encoding=utf-8。这需要在_vimrc中进行设置,网上常有人启用这一选项后Vim菜单和消息出现乱码。据我的经验,需要将这encoding=utf-8写在_vimrc最开头,然后设置language message,可参见我的_vimrc文件。
vimrc文件
Vim使用中,配置文件vimrc是非常重要的,用:echo $myvimrc,来查看你的vimrc在哪里。
如果这为空的话,你可以在$vim目录,建一新的_vimrc文件。
我的vimrc文件
set encoding=utf-8
set termencoding=gbk
set nocompatible " We're running Vim
set nobackup "We don't need the backup file
set showmatch "Show where the bracket match
set showcmd
set ruler "Show the line and column number
set hlsearch "Highlight the search key
set backspace=indent,eol,start
set fileencodings=ucs-bom,utf-8,chinese
set guifont=courier_new:h10
set autoindent
syntax on " Enable syntax highlighting
filetype plugin indent on " Enable filetype-specific indenting and plugins
language message zh_CN.utf-8 " Use chinese message
color zellner " Color theme
其中termencoding=gbk是因为windows中的“命令提示符”窗口只能使用gbk编码,不能像Gnome中的Console那样用utf-8。不设置的情况下,使用“命令提示符”下的vim,而不是gvim时,会出乱码。在设置文件中的色彩和字体,可以先在gvim菜单中设置,然后将你所喜好的,添加到_vimrc文件中。看到我的vimrc文件,你是不是感觉特别短。因为我把许多跟文件类型的相关设置放在其对应的脚本里,扔在vimfiles文件夹了。在vimrc里,例如常见的空格,制表符,缩进都没有在这配置。
杂项
Vim中一些内置的变量,你都可以通过:echo varname来查看值,比如::echo $myvimrc
这些变量,注意大小写,常用的有
$VIM Vim的安装目录
$vimruntime Vim运行时目录
$myvimrc 用户的_vimrc文件
$home 用户的主目录
我常常使用:e $myvimrc来编辑我的vimrc文件,非常方便。
对一些带值的配置选项,你可以用:set optionname来查看其当前值,或用:set optionname=val来更改其值.比如:set fileformat查看文件格式,因为dos,unix,mac对于换行是不一样的。:set filemat=unix的话,换行将用LF,而不是dox\windows下的CR,LF。
参考链接
IBM开发中心非常实在的Vim实用技术系列:
Vim实用技术(1)-实用技巧
Vim实用技术(2)-常用插件
Vim实用技术(3)-定制Vim
Easwy的博客,里面有用的信息,更多的Vim资源链接
Vim专栏
posted @
2008-05-25 20:19 len 阅读(6290) |
评论 (13) |
编辑 收藏Boost.Lambda是什么?
Boost Lambda库是C++模板库,以C++语言实现了lambda抽象.Lambda这个术语来自函数编程语言和lambda闭包理论,lambda抽象实际上定义了匿名函数.了解过C#新引入的匿数函数特性或Lisp编程的人,对这些概念理解会有很大帮助.Lambda库设计的主要动机是为STL算法提供灵活方便的定义匿名函数对象的机制.这个Lambda库究竟是有什么用呢?代码胜千言!看下面将STL容器中的元素打印到标准输出上的代码.
for_each(a.begin(), a.end(), std::cout << _1 << ' ');
表达式std::cout << _1 << ' '定义了一元函数对象.变量_1是函数的形参,是实参的占位符.每次for_each的迭代中,函数带着实际的参数被调用,实际参数取代了占位符,然后函数体里的内容被执行.Lambda库的核心就是让你能像上面所展示的那样,在STL算法的调用点,定义小的匿名函数对象.
Lambda库的安装
Lambda库只由头文件组成,这就意味着你不需要进行任何编译,连接,生成二进制库的动作,只需要boost库头文件路径包含进你的工程中即可使用.
与现代的C++语言一样,在使用时你需要声明用到的名字空间,把下列的代码包含在你的源文件头:
using namespace boost::lambda;
Boost Lambda库的动机
在标准模板库STL成为标准C++的一部分后,典型的STL算法对容器中元素的操作大都是通过函数对象(function objects)完成的.这些函数作为实参传入STL算法.
任何C++中以函数调用语法被调用的对象都是函数对象.STL对某些常见情况预置了些函数对象.比如:
plus,less,not1下面就是标准
plus模板的一种可能实现:
template <class T>
struct plus : public binary_function <T, T, T> {
T operator()(const T& i, const T& j) const {
return i + j;
}
};
基类binary_function<T, T, T>包含了参数和函数对象返回类型的类型定义,这样可使得函数对象可配接.
除了上面提到的基本的函数对象外,STL还包含了
binder模板,将可配接的二元函数中的某个实参固定为常量值,来创建一个一元函数对象.比如:
class plus_1 {
int _i;
public:
plus_1(const int& i) : _i(i) {}
int operator()(const int& j) { return _i + j; }
};
上面的代码显性地创建了一个函数对象,将其参数加1.这样的功能可用plus模板与binder模板(bind1st来等效地实现.举例来说,下面的两行表达式创建了一个函数对象,当它被调用时,将返回1与调用参数的和.
plus_1(1)
bind1st(plus<int>(), 1)
plus<int>就是计算两个数之和的函数对象.bind1st使被调用的函数对象的第一个参数绑定到常量1.作为上面函数对象的使用示例,下面的代码就是将容器a中的元素加1后,输出到标准输出设备:
transform(a.begin(), a.end(), ostream_iterator<int>(cout),
bind1st(plus<int>(), 1));
为了使binder更加通用,STL包含了适配器
(adaptors)用于函数引用与指针,以及成员函数的配接.
所有这些工具都有一个目标,就是为了能在STL算法的调用点有可能指定一个匿名的函数,换句说,就是能够使部分代码片断作为参数传给调用算法函数.但是,标准库在这方面只做了部分工作.上面的例子说明用标准库工具进行匿名函数的定义还是很麻烦的.复杂的函数调用表达式,适配器,函数组合符都使理解变得困难.另外,在运用标准库这些方法时还有明显的限束.比如,标准C++98中的binder只允许二元函数的一个参数被绑定,而没有对3参数,4参数的绑定.这种情况在TR1实施后,引进了通用的binder后可能改善,对于使用MSVC的程序员,有兴趣还可以查看下微软针对VS2008发布的TR1增强包.
但是不管怎样,Lambda库提供了针对这些问题比较优雅的解决方法:
对匿名函数以直观的语义进行创建,上面的例子可改写成:
transform(a.begin(), a.end(), ostream_iterator<int>(cout),
1 + _1);
更直观点:
for_each(a.begin(), a.end(), cout << (1 + _1));
绝大部分对函数参数绑定的限制被去除,在实际C++代码中可以绑定任意的参数
分离的函数组合操作不再需要了,函数组合被隐性地支持.
Lambda表达式介绍
Lambda表达在函数式编程语言中很常见.在不同语言中,它们的语法有着很大不同,但是lambda表达式的基本形式是:
lambda x1...xn.e
lambda表达式定义了匿名函数,并由下列的元素组成
- 函数的参数:x1...xn
- 表达式e,以参数x1...xn的形式计算函数的值
一个简单的lambda表达式的例子是:
(lambda x y.x+y) 2 3 = 2 + 3 = 5
在lambda表达式的C++版本中,表达式中x1...xn不需要,已预定义形式化的参数.在现在Boost.Lambda库中,存在三个这样的预定义的参数,叫做占位符:_1,_2,和_3.它们分别指代在lambda表达式中的第一,二,三个参数.比如,下面这样的lambda表达式:
lambda x y.x+y
C++定义的形式将会是这样:
_1 + _2
因此在C++中的lambda表达式没有语义上所谓的关键字.占位符作为运算符使用时就隐性地意味着运算符调用是个lambda表达式.但是只有在作为运算符调用才是这样.当Lambda表达式包含函数调用,控制结构,转换时就需要特殊的语法调用了.更为重要的是,作为函数调用是需封装成binder函数的形式.比如,下面这个lambda表达式:
lambda x y.foo(x,y)
不应写成foo(_1,_2),对应的C++结构应如下:
bind(foo, _1, _2)
对于这种表达式,更倾向于作为绑定表达式bind expressions
lambda表达式定义了C++的函数对象,因此,对于函数调用的形式跟其他的函数对象一样,比如:(_1 + _2)(i, j).
性能
性能,运行效率,总是C++程序员关心的话题.理论上,相对于手写循环代码,使用STL算法和Lambda函数对象的所有运行开销,可以通过编译优化消除掉.这种优化取决于编译器,实际中的编译器大都能做到.测试表明,性能会有下降,但是影响不大,对于代码的效率和简洁之间的权衡,只能由程序员自己做出判断了.
Lambda库的设计与实现中大量运用了模板技术,造成对于同一模板需要大量的递归实例化.这一因素可能使构建复杂逻辑的lambda表达式,不是一个非常理想的做法.因为编译这些表达式需要大量的内存,从而使编译时间变得非常慢,这在一些大型项目中会更加突出.还有在发生编误错误时,引发的大量错误信息,不能有效地指出真正错误之处.最后点,C++标准建议模板的嵌套层次不要超过17层来防止导致无限递归,而复杂的Lambda表达式模板会很容易超过这一限制.虽然大多数编译器允许更深层次的模板嵌套,但是通常需要显性地传入一个命令行参数才能做到.
参考
大多数内容是从Boost.Lambday库在线文档参考翻译而成
posted @
2008-05-18 16:03 len 阅读(8731) |
评论 (5) |
编辑 收藏
"Designing Qt-Style C++ APIs" by Matthias Ettrich
http://doc.trolltech.com/qq/qq13-apis.html
翻译这篇文章的目的不是让人了解Qt,而是让人试着学习点C++编程的软技能。我从原文中得到的一些风格上的体会,也希望你能从中有所收获.(译者注)
我们在Trolltech做了大量研究来改进Qt开发体验.在这篇文章中,我将分享我们的一些成果,呈现我们在进行Qt 4设计时所使遵循的原现,并向你展示如何将它们应用到你的代码中.
设计应用程序接口(APIs)是有难度的.它是像跟设计编程语言一样困难的艺术.要遵循许多不同的的原则,这些原则中的许多还彼此冲突.
现今的计算机教育过多关注于算法和数据结构,很少去关注隐藏在程序设计语言和程序框架后面的那些设计原则.这使得程序员们面对日益重要的任务,创建可复用的组件,毫无准备.
在面向对象语言出现前,通用的可复用的代码大都由库提供者而不是应用程序开发者来编写.在Qt世界中,这种情况已发生了很大的变化.在用Qt编程其实就是在写新的组件.典型的Qt应用程序都存在某些自定义的组件,在整个应用程序中被复用.相同的组件常常作为其他程序的一部分被开发出来.KDE,K桌面环境,甚至使用许多附加库,来进一步扩展Qt,实现许多额外的类.
但是一个优秀,高效的C++ API究竟是怎样子呢?它的好坏取决于许多因素,比如说,手头上的任务和特定目标群体.优秀的API具有很多特性,它们的一些是普遍所要期望的,另一些是针对特定问题域的.
优秀API的六个特性
API对于程序员就相当于GUI对于最终用户.API中'P'代表程序员(Programmer),而不是程序(Program),强调这一点是为了说明API是让程序员使用的,程序员是人而不机器.
我们认为APIs应当精简而完备,具有清晰简单的语义,直观,易记且应使代码具有可读性.
-
精简性:精简的API具有尽可能少的类和公共成员.这使得理解,记忆,调试,更改API更加容易.
-
完备性:完备的API意味着拥有应具有的期望功能.这可能使与API保持精简性相冲突.还有,如果成员函数放在不相匹配的类中,那么许多使用这个功能函数的潜在用户会找不到它.
-
清晰简单的语义:正如与其他设计工作一样,你应该准守最小惊议原则.让通常的任务简单,罕见的任务应尽可能简单,但它不应成为重点.解决特定的问题.不要使解决方法具有普适作用,当它们不需要的时候.
-
直观性:与计算机有关的其他事情一样,API应具有直观性.不同经历和背景会导致对哪些是直观,哪些不是直观的不同看法.如果对非专业的用户在不需要阅读文档下能立即使用API,或对这个API不了解的程序员能理解使用了API的代码,那么这API就是具有直观性.
-
易记:为了使API容易记忆,使用一致且精准的命名规范.使用容易识别的模式和概念,避免使用缩写.
-
能生成可读生代码:代码只写一遍,却要阅读许多遍(调试或更改).可读性的代码有时候可能需要多敲些字,但是从产品生命周期中可节省很多时间.
最后,请记住:不同的用户使用API的不同部分.当简单地使用Qt类的实例可能有直观性,但这有可能使用户在阅读完有关文档后,才能尝试使用其中部分功能.
方便性陷阱
通常的误读是越少的代码越能使你达到编写更好的API这一目的.请记住,代码只写一遍,却要一遍又一遍地去理解阅读它.比如:
QSlider *slider = new QSlider(12, 18, 3, 13, Qt::Vertical,
0, "volume");
可以会比下面的代码更难阅读(甚至于编写)
QSlider *slider = new QSlider(Qt::Vertical);
slider->setRange(12, 18);
slider->setPageStep(3);
slider->setValue(13);
slider->setObjectName("volume");
布尔参数陷阱
布尔参数常常导致难以阅读的代码.特别地,增加某个bool参数到现存的函数一般都会是个错误的决定.在Qt中,传统的例子是repaint(),它带有一个可选的布尔参数,来指定背景是否删除(默认是删除).这就导致了代码会像这样子:
widget->repaint(false);
初学者可能会按字面义理解为,"不要重绘!"
自然的想法是bool参数节省了一个函数,因此减少了代码的臃肿.事实上,这增加了代码的臃肿,有多少Qt用户真正知道下面这三行代码在做什么呢?
widget->repaint();
widget->repaint(true);
widget->repaint(false);
好一点的API代码可能看起来像这样:
widget->repaint();
widget->repaintWithoutErasing();
在Qt 4中,我们解决这个问题的办法是,简单地去除掉不删除widget而进行重绘的可能性.Qt 4对双重缓冲的原生支持,会使这功能被废弃掉.
这里有些例子:
widget->setSizePolicy(QSizePolicy::Fixed,
QSizePolicy::Expanding, true);
textEdit->insert("Where's Waldo?", true, true, false);
QRegExp rx("moc_*.c??", false, true);
显然的解决办法就是将bool 参数用枚举类型来替换.这就是我们在Qt 4中Qstring中的大小写敏感所做的,比较下面两个例子:
str.replace("%USER%", user, false); // Qt 3
str.replace("%USER%", user, Qt::CaseInsensitive); // Qt 4
静态多态
相似的类应该有相似的API.在某种程度上,这能用继承来实现,也就是运用运行时多态机制.但是多态也能发生在设计时.比如,你将QListBox与QComboBox交换,QSlider与QSpinBox交换,你会发现API的相似性会使这种替换变得比较容易.这就是我们所谓的"静态多态".
静态多态也能使记忆API和编程模式更加容易.因而,对一组相关类的相似API有时候比为每个类设计独特完美的API会更好.
命名艺术
命名有时候是设计API中最重要的事情了.某个类应叫什么名字,某个成员函数又应叫什么名字,都需要好好思考.
通常的命名规则
有少许规则对所有类型的命名都适应.首先,正如我早先所提到的,不要用缩写.甚至对用"prev"代表"previous"这样明显的缩写也不会在长期中受益,因为用户必须记住哪些名字是缩写.
如果连API自身都不能保持统一,事情自然会变得更坏.比如,Qt 3中有activatePreviousWindow()函数,也有fetchPrev()函数.坚持"没有缩写"这条规则,会使创建一致的API更加简单.
在设计类中,另一重要但是不明显的规则是尽量保持子类中名字的简洁易懂.在Qt 3中,这个原则并不总是被遵守.为了说明这一点,我们举下QToolButton的例子.如果你在Qt 3中对QToolButton调用call name(), caption(), text(), 或 textLabel()成员函数时,你希望会发生什么?那就在Qt设计器中试试QToolButton吧.
-
name 属性继承自QObject,用来在调试和测试中指代对象的内部名称.
-
caption 属性继承自QWidget,指代窗体的标题.对于QToolButton没有什么意思,既然它们都是由父窗体创建的.
-
text 属性继承自QButton,通常用于按钮中,除非useTextLabel为真.
-
textLabel 属性 在QToolButton中声明,如果useTextLabel为真,则显示在按钮上.
为了可读性的关系,在Qt4中name 被称为objectName ,caption被称为windowTitle,在QToolButton中为了使text明晰,不再有textLabel属性.
命名类
不应为每个不同的类寻求完美的名字,而是将类进行分给.比如,在Qt 4中所有跟模型有关的视类的部件都用View后缀(QlistView,QTableView,QTreeView),相应的基于部件的类用Widget后缀代替(QListWidget,QTableWidget,QTreeWidge).
枚举类型和值类型命名
当设计枚举时,我们应当记住C++中(不像Java或C#),枚举值在使用时不带类型名.下面的例子说明了对枚举值取太一般化的名字的危害:
namespace Qt
{
enum Corner { TopLeft, BottomRight, ... };
enum CaseSensitivity { Insensitive, Sensitive };
...
};
tabWidget->setCornerWidget(widget, Qt::TopLeft);
str.indexOf("$(QTDIR)", Qt::Insensitive);
在上面这行中,Insensitive这个名字什么意思呢?为枚举类型命名具有指导的原则是最好在每个枚举值中重复枚举类型的名字.
namespace Qt
{
enum Corner { TopLeftCorner, BottomRightCorner, ... };
enum CaseSensitivity { CaseInsensitive,
CaseSensitive };
...
};
tabWidget->setCornerWidget(widget, Qt::TopLeftCorner);
str.indexOf("$(QTDIR)", Qt::CaseInsensitive);
但枚举值之间是一种"或"关系和被用作标志位时,传统的解决方法是将"或"结果存为int,这样做是类型不安全的.Qt 4提供了一模板类QFlags<T>,其中T是枚举类型.Qt为标志类型名称提供了便利,你能用Qt::Alignment 来代替QFlags<Qt::AlignmentFlag>.
为了方便,我们给枚举类型单数形式的名称(只有当只含一个标志位时),给"flags"类型复数形式的名称,比如:
enum RectangleEdge { LeftEdge, RightEdge, ... };
typedef QFlags<RectangleEdge> RectangleEdges;
在某些情况下,"flags"类型有单数形式的名称.在这种情况下,枚举类型以Flag后缀标识:
enum AlignmentFlag { AlignLeft, AlignTop, ... };
typedef QFlags<AlignmentFlag> Alignment;
函数和参数的命名
函数命名中的一条规则就是应能从它的名字清楚地看出函数是否着副作用.在Qt 3中,常函数QString::simplifyWhiteSpace()就违反了这规则.即然它返回QString,而不是像它的名字所表述的那样修改字符串. 在Qt 4中,这个函数被重命名为QString::simplified().
参数名对于程序员来说是重要的信息来源,即使它们不出现在调用API的代码中.既然现代的IDE会在程序员编码时显示这些参数,所以非常值得在头文件中给这些参数取恰当的名字,在文档中同样使用相同的名字
给布尔型的getter,setter,属性的命名
给布尔型的getter,setter,属性取个恰当的名字总是特别困难.getter应该叫checked() 或者还是叫isChecked(),取scrollBarsEnabled()还是areScrollBarEnabled()
在Qt 4中,我们对于getter的函数使用下面的指导原则
- 形容词就使用is-前缀.比如:
- isChecked()
- isDown()
- isEmpty()
- isMovingEnabled()
但是形容词应用到复数形式的名词没有前缀:
- scrollBarsEnabled(), not areScrollBarsEnabled()
- 动词没有前缀,也不使用第三人称的(-s):
- acceptDrops(), not acceptsDrops()
- allColumnsShowFocus()
- 名词性的通常没有前缀:
- 用autoCompletion(), 不用isAutoCompletion()
- boundaryChecking()
有时候没有前缀会产生误导,在这种情就加上前缀is-:
- isOpenGLAvailable(), not openGL()
- isDialog(), not dialog()
(如果函数叫做dialog(),我们通常会认定它会返回QDialog*类型)
setter的命名可以从这推知,只要去掉is前缀,在名字前面加set前缀就可以了.比如setDown()和setScrollBarsEnabled().属性的名字跟getter一样,就是没有is前缀
指针或引用?
对于向外传参,是使用指针,还是引用更好呢?
void getHsv(int *h, int *s, int *v) const
void getHsv(int &h, int &s, int &v) const
绝大多数C++书籍都推荐无论何时都尽可能使用引用,因为从大多数情况来说,引用比指针有着所谓的"安全和优雅".相比而方,在Trolltech,我们更趋向于指针,因为它使用户代码更具可读性.比较下面的代码:
color.getHsv(&h, &s, &v);
color.getHsv(h, s, v);
只有第一行代码能更清楚地说明h,s,v在函数被调用后,其值极有可能被修改.
案例分析:QProgressBar
为了在实际代码中说明这些概念,我们以QProgressBar在Qt3和Qt4中的比较进行研究.在Qt 3中:
class QProgressBar : public QWidget
{
...
public:
int totalSteps() const;
int progress() const;
const QString &progressString() const;
bool percentageVisible() const;
void setPercentageVisible(bool);
void setCenterIndicator(bool on);
bool centerIndicator() const;
void setIndicatorFollowsStyle(bool);
bool indicatorFollowsStyle() const;
public slots:
void reset();
virtual void setTotalSteps(int totalSteps);
virtual void setProgress(int progress);
void setProgress(int progress, int totalSteps);
protected:
virtual bool setIndicator(QString &progressStr,
int progress,
int totalSteps);
...
};
对这个API进行改进的关键之处就是需要观察到Qt 4中QProgressBar与QAbstractSpinBox,以及它的子类,QSpinBox,QSlider,和QDial有着相似性.解决的办法呢?将其中的progress和totalSteps用minimun,maximum和value替换.
增加valueChanged()的信号量.增加setRange()这一方便的函数.
接下来需要到progressString, percentage 和indicator实际上都指代同一东西:显示在进度栏上的文本.通常这一文本是一百分数,但是它能被setIndicator()设置成任何值.这里是新的API:
virtual QString text() const;
void setTextVisible(bool visible);
bool isTextVisible() const;
默认,这文本是百分比指示器.这可以用重新实现的text()进行改变.
在Qt 3中,setCenterIndicator() 和 setIndicatorFollowsStyle()是两个影响对齐方式的函数.它们现在都被一个高级的函数所取代,setAlignment().
void setAlignment(Qt::Alignment alignment);
如果程序员没有调用 setAlignment(),对齐是基于的样式决定的.对于Motif样式,文本显示在中间,而对于其他样式,文本是右对齐的.
这里是改进过的QProgressBar:
class QProgressBar : public QWidget32
{
...
public:
void setMinimum(int minimum);
int minimum() const;
void setMaximum(int maximum);
int maximum() const;
void setRange(int minimum, int maximum);
int value() const;
virtual QString text() const;
void setTextVisible(bool visible);
bool isTextVisible() const;
Qt::Alignment alignment() const;
void setAlignment(Qt::Alignment alignment);
public slots:
void reset();
void setValue(int value);
signals:
void valueChanged(int value);
...
};
怎样写出正确的APIs
APIs需要质量保证.最早的版本一般都不是很好的,你必须测试它.通过调用这个API的代码作为测试事例,来验证代码具有可读性.
另外的技巧包括让人在没有文档和类文档化(类的概述和函数说明)的情况下能够使用这个API.
当你陷入麻烦中时,文档化也是好的办法找出一个合适的命名:试着为这些类,函数,枚举值标住文档,然后使用浮现在你脑中的第一个词汇.如果你找不到精准的名字去表述,那很有可能这个东西就不应存在.如果任何办法都失败了,而且你确信这个概念是有用的,那就发明一个新的名字吧.最后,不管怎么说,"widget", "event", "focus", and "buddy"这些词总会能用上一个.
posted @
2008-05-11 20:07 len 阅读(7933) |
评论 (6) |
编辑 收藏Glade是针对GTK+工具箱与GNOME桌面开发环境的快速图形界面开发工具.用Glade设计的用户接口以XML的文件形式保存,然后根据需要由程序通过libglade库文件来动态加载.因为使用了libglade库,Glade XML文件能够被C,C++,Java,Perl,Python,C#等等语言所支持.针对其他未涉及的语言的支持也是方便的.
在网上可以见到某些关于Glade的教程,大都是关于Linux平台和Glade 2的,因为原先Glade作为快速开发工具,集成代码生成功能,生成C文件.所以常常有初学者对网上某些教程所提及的"generate"(生成代码)功能表示迷惑,在新版本的Glade-3上找不到对应的功能.
新版本的Glade-3是对原先Glade代码的完全重写.一个显著的变化就是去除了代码生成功能.这样做是有原因的,即然代码生成功能不被提倡使用,而是更鼓励使用libglade功能.但是如果你真需要代码生成功能的话,它还是可以做为插件来提供的.另一个显著的不同是glade-3设计用来最大化使用GObject的自省机制(GObject introspection),来使外部工具箱和部件的控制,信号和属性的集成更加容易.
如果看过Say Hello to GTK+的话,可能感觉那样的窗体程序太简单了.那么现在让我们借助Glade弄点儿复杂一点儿的界面吧.首先来瞧瞧Glade长什么样,下图就是Glade在windows下的界面.左边的窗体的小部件选择器,相当于调色板.中间是主菜单,右边的是属性窗体.
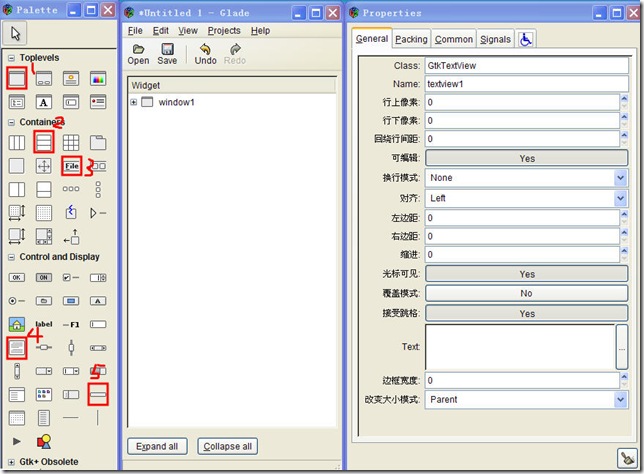
现在开始创建一个类似于文本编辑器的图形界面.按照上图标注的顺序,依次添加window部件,vertical box部件,menu bar部件,text view部件和Status部件.vertical box设置三行,它是用来进行界面布局,分割空间用,这是gtk+设计与传统的windows UI设计很不同的地方.后三个部件是放置vertical box中的,最后设计完成图形如下.保存取名为win.glade.如果你感兴趣的话,可以用文件编辑器打开这个文件看看,正如所说的那样,它是一个xml格式的文本文件.
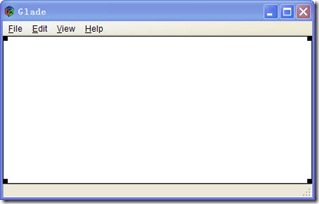
现在我们设置相关的头文件和库文件,编辑一个glade.c文件,添加进以下的代码,运行看看,会出现如上图的对话框.虽然这个对话框什么都不干,但是通过Glade,我们能较为容易地设计界面,而不用通过gtk函数,一个一个将控件实现.
#include <gtk/gtk.h>
#include <glade/glade.h>
int main(int argc, char* argv[])
{
GladeXML *gxml;
GtkWidget *window;
gtk_init (&argc, &argv);
gxml = glade_xml_new ("win.glade", NULL, NULL);
window = glade_xml_get_widget (gxml, "hello");
g_object_unref (G_OBJECT (gxml));
gtk_widget_show (window);
gtk_main ();
return 0;
}
posted @
2008-03-27 20:49 len 阅读(10306) |
评论 (8) |
编辑 收藏