应用程序国际化,在开源世界里常以i18n被提及,i18n是Internationalization的简写,正好18个字母。在wxPython程序进行i18n,如果字符串是编码在源文件中时,完全可按照python程序的i18n的方法,即使用gexttext和locale模块。而wxPython程序在使用XRC文件做为界面资源时,则应使用wx.Locale模块,它封装了区域化相关的操作。i18n,或者国际化实际上涉及到语言习惯,数字格式等等类别的内容。这里只介绍语言多国化,将一个简单的英文程序转换为中文,涉及到源文件,可从这里下载。
创建PO文件
PO文件是Portable Object文件的简称,它包含需要翻译的字符串。我们需要从源文件进行提取。首先,对源文件test.py编辑,标识代码里需要翻译的字符串内容。我们使用_("xx")的方法,这种形式可能在许多开源源代码中见识过。
#加载菜单栏
menubar = rc.LoadMenuBar('IDR_MENU')
这里的IDR_MENU是资源标识ID,不需要翻译,因此不做改变,而下面的代码:
info.SetVersion('1.0')
info.SetDescription('XRC i18n Demo')
'XRC i18n Demo'是描述性的文本,需要进行翻译,将需要处理为
info.SetVersion('1.0')
info.SetDescription(_('XRC i18n Demo'))
接着需要生成.pot(Portable Object Template),这是po的模板文件。在将来程序可能配置成其他语种,其他语言的po文件都从它而来。为了创建这文件,需要用到GNU gettext工具集中的xgettext。向xgettext传入些必要的信息,来创建.pot文件。
>xgetttext --output=test.pot test.py
我们将wxPython界面以XRC文件保存了,那里同样有要翻译的字符串需要提取。用XRCed工具将XRC生成python代码,勾选上'Generate gettext strings'项即可。将源文件和XRC生成的test_xrc.py文件一起处理,生成一个test.pot。
>xgettext --output=test.pot test.py test_xrc.py
将得到的test.pot另存为test.po文件,然后进行翻译编辑,在这过程中文件需要使用utf-8编码。将对应的英文翻译成中文,将charset更改为utf-8。
"Content-Type: text/plain; charset=utf-8\n"
"Content-Transfer-Encoding: 8bit\n"
#: test.py:19
msgid "XRC i18n Demo"
msgstr "XRC 国际化示例"
...
.pot和.po这些文件都是文本文件,主要供翻译者使用。为了使程序在运行时能获取相关的翻译的内容,要进行所谓的编译过程,将文本文件转换为二进制文件.mo。这里用了gettext工具集中的另一程序msgfmt。
> msgfmt --output=test.mo test.po
因为windows下没有像linux像有公共存储.mo文件的目录,保持平台的迁移性,在应用程序本地目录下新建locale目录,用来存放编译过的.mo文件,然后将test.mo移动至locale目录。在完成这些步骤后,就转入代码方面的更改了。
wxPython代码更改
原先的代码只需要做小改动:
def OnInit(self):
wx.Locale.AddCatalogLookupPathPrefix('locale')
self.locale = wx.Locale(wx.LANGUAGE_CHINESE_SIMPLIFIED)
self.locale.AddCatalog('test')
import __builtin__
__builtin__.__dict__['_'] = wx.GetTranslation
首先,增加了新的目录文件路径,这将使wxPython搜索这个目录,寻找匹配的.mo文件。接着创建wx.Locale对象,将其初始化为简体中文,这将对应于zh_CN。最后将wx.GetTranslation做了一全局映射,这样你在其他类中,比如示例中TestFrame也能使用_('xx')调用。这样wxPython的i18n工作就完成了,下面是翻译前后的界面截图。
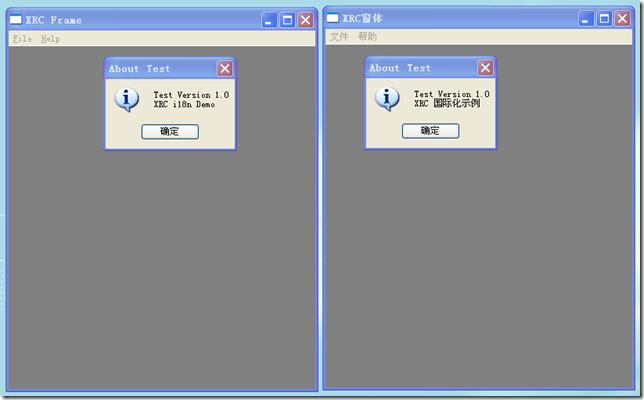
一些有益的讨论
.mo文件的查找目录
如果你将locale目录下的test.mo文件删除掉,然后将test.py中的wx.LANGUAGE_CHINESE_SIMPLIFIED改为wx.LANGUAGE_CHINESE,重新运行程序看看。发现界面变成了如下的繁体中文,但是菜单'档案'下的Exit还是英文。

因为缺失.mo文件,但又指定wx.LANGUAGE_CHINESE,wxPython运行时使用了wxstd.mo文件。wxstd.mo有许多预编译好的常见字符串的对应关系,它随wxPython发布,在wx/locale下有许多语言版本的wxstd.mo。
对于wxPython会对待查目录"DIR"来搜索.mo文件,查找它下面的这些目录,(DIR/LANG/LC_MESSAGES;DIR/LANG;DIR),对于哪些是待查目录,各个系统下又有不同,在所有的平台上,LC_PATH环境变量指定的目录将成为待查目录,在Linux下/share/locale, /usr/share/locale, /usr/lib/locale, /usr/locale /share/locale以及当前目录将是待查目录。在上面我们已经用过AddCatalogLookupPathPrefix()函数,其作用就是增加自己的待查目录。
在示例程序中,将test.mo放在locale\zh_CN\LC_MESSAGES或者locale\zh\LC_MESSAGES同样是可行的。但是如果使用wx.LANGUAGE_CHINESE指定,则zh_CN目录将不可行,因为它只是特化目录,指简体中文,而zh目录同样适用。
工具链再讨论
gettext进行国际化是开源社区的主流方案,它也提供了许多实用工具供使用。上面提到了xgettext,msgfmt,还有msginit.exe,它将根据.pot文件创建新的.po文件,然后初始化一些元信息,像作者信息,项目,以及编码等,当然也可像上面的手工编辑。msgmerge.exe将两个.po文件进行合并。除了使用GNU Gettext工具集,也可使用随python发布的tool\i18n目录下pygettext.py和msgfmt.py,它们等同于上述的两个工具。
对于编辑.po文件,可以尝试一下Poedit,它提供了图形化的编辑环境,其他功能我就不清楚了。
posted on 2008-07-15 20:21
len 阅读(2302)
评论(0) 编辑 收藏 引用 所属分类:
程序开发