一直比较好奇,调试器是如何生成堆栈的调用过程的,比如如下代码:
int add(int a, int b)
{
return a + b;
}
int main()
{
int c = add(1, 2);
system("pause");
return 0;
}
调用Add时的堆栈截图如下:

调试器究竟是如何生成这个堆栈过程的呢?
我最初的理解调试器是根据EBP来生成该堆栈的,原理如下:
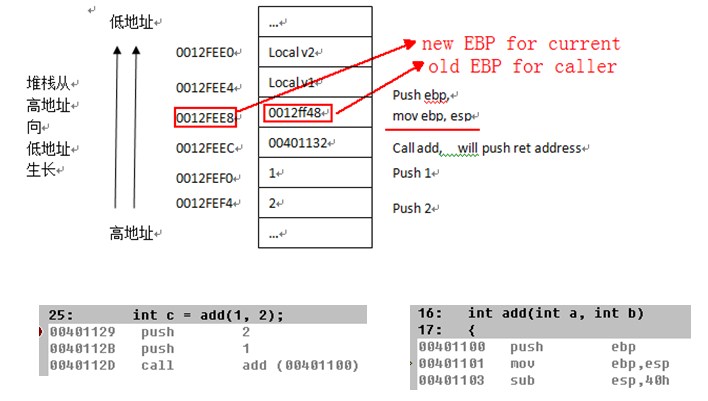
可以看到按照上面的原理, 每次EBP里存放的都是当前函数的堆栈桢基址,所以我们只要一直递推,就可以得到完整的Call Stack.
但是我们很快会发现, 并不是每个函数都是以
push ebp
mov ebp, esp
开头的,我们可以写一些裸(naked)函数,
比如
int __declspec(naked) add(int x,int y) 来手动控制函数头,而且很多编译器优化过的函数代码也是没有该标准函数头的。
那么调试器在这种情况下又是如何生成完整的call stack的呢?
和群里的朋友讨论的结果是调试器很可能是在调用call指令时保存了调用现场,
这样只要在调试器下运行,它就一直可以知道正确而完整的call stack.
这也解释了为什么我们在分析Crash的Dump文件时很多时候得不到正确的堆栈过程?
有可能是堆栈本身被我们的异常代码破坏了;
更有可能是因为我们的代码在直接运行时没有调试器的参与, 所以堆栈过程没有被保存,所以windbg分析dump时只能根据堆栈里内容自己分析和推理堆栈调用过程,所以很多时候得不到正确的堆栈过程。
那么Windbg分析dump时,会如何倒推堆栈过程呢?
如果每个函数都是有标准的push ebp, 那么按照ebp递推就可以了;
否这就只能用其他方法分析,比如看看堆栈里某个地址是不是函数返回地址(该地址属于某个模块的代码段),这样就可以确定该地址是某个函数堆栈桢的起始地址。
上面关于生成call stack的原理只是一些非专业人士的个人看法,如果有不正确的地方,欢迎指正。
注: 和开发过调试器的朋友讨论,上面 关于callstack产生原理的推论,实际上是不正确的, 调试器实际上是通过查询PDB文件的方式获取的callstack.
posted on 2012-07-20 14:00
Richard Wei 阅读(5473)
评论(3) 编辑 收藏 引用 所属分类:
汇编