单链表的快速排序
单链表的快速排序跟数组的排序原理上一致,有一个分区(区分)的函数在一个区间中针对某个标杆值进行区分,比它大的放它后面,比它小的放它前面,并返回它的地址,好对它前面的以及它后面的递归。
单链表的快速排序跟数组有个明显的区别,就是指示起始和终止的元素,在一轮之后它们在链表中的位子会发生改变,所以需要返回一个新的起始的位置(终止的位置)
我的算法中总是拿后一个的节点作为终止位置,所以它在链表中的位子其实是不改变的,所以我只修改了起始位置指向新的起始位置即可。
我的算法是,用2个链表,一个放比它大的一个放比它小的,最后接起来,它的位置就是mid,而其实位置就是当初起始的前一个节点在新链表中的next。有点拗口,就是说a->start->...->nullptr,这一轮传进来的是start,那么经过这轮的分区之后,start的位置肯定改变了,对吧?但是a->next的地址没有改变,即&(a->next),因为start之前的都会原封不动的放在那里。我觉得用指针的地址来处理是这里的关键之处吧。
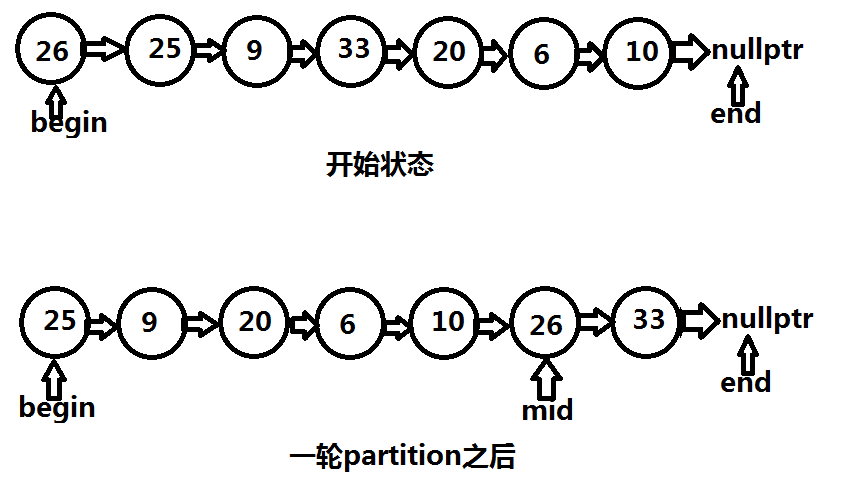
这是一轮partition之前和之后的图示,之后就对于(begin, mid)和(mid->next, end)进行快速排序即可。
1 // Problem: sort a singly link list by Quick Sort
2 node *partition(list &l, node *&begin, node *end = nullptr) {
3 // if end is the next node, that means it's only one node to sort
4 if (begin == nullptr || end == begin->next) {
5 return nullptr;
6 }
7
8 list small_list, big_list;
9 node *current = l.root;
10 node *pivot = begin;
11 node **pbegin; // points to the address of begin
12 node **s_current = &small_list.root, **b_current = &big_list.root;
13
14 // move previous nodes before 'begin' to small list
15 while (current != begin) {
16 *s_current = current;
17 s_current = &(*s_current)->next;
18 current = current->next;
19 }
20
21 // pbegin presents the location(address) of begin item, e.g. if (a->next == begin) then pbegin = &a->next;
22 pbegin = s_current;
23
24 while (begin != end) {
25 if (begin->data < pivot->data) {
26 *s_current = begin;
27 s_current = &(*s_current)->next;
28 }
29 else {
30 *b_current = begin;
31 b_current = &(*b_current)->next;
32 }
33
34 begin = begin->next;
35 }
36
37 // pass begin back to quick_sort for next sort action
38 begin = *pbegin;
39
40 *b_current= end;
41 *s_current = big_list.root;
42 l = small_list;
43 l.print();
44
45 // current pivot would be the end node for smaller set sorting
46 return big_list.root;
47 }
48
49 void quick_sort(list &l, node *begin, node *end = nullptr) {
50 if (begin == end) {
51 return;
52 }
53 // mid represents the pivot node which is the next node of the end of the small list
54 node *mid = partition(l, begin, end);
55
56 if (mid != nullptr){
57 quick_sort(l, begin, mid);
58 }
59
60 if (mid != nullptr &&
61 mid->next != nullptr) {
62 quick_sort(l, mid->next, end);
63 }
64 }
代码