Aho-Corasick算法实践
摘要:
Aho-Corasick算法可以在文本串中识别一组关键字,所需时间和文本长度以及所有关键字的总长度成正比。该算法使用了一种称为“trie”的特殊形式的状态装换图。Trie是一个树形结构的状态装换图,从一个结点到它的各个子结点的边上有不同的标号。Trie的叶子结点表示识别到的关键字。
在这里,将着重讨论算法的实现。算法包含两个部分,一是经典的KMP算法,二是KMP的扩展算法Aho-Corasick算法。前者实现单关键字的模式匹配,后者实现多关键字的匹配。(参考龙书词法分析部分内容)
【源代码:http://www.cppblog.com/Files/yefeng/ACKMP.rar(vc9.0下测试通过)
】
一、经典KMP算法
当初,初学KMP算法时,总是通过反复的举例去理解,没有一种好的表达方式,而龙书描述这个算法使用了trie树,也就是一个单链的状态转换图。如模式b0b1...bn-1,trie树如下:

对模式串定义失效函数f:x->y,x,y in S,描述状态转移,f(s)表示在状态s处,当下一个字符不是bs时转向状态f(s)继续匹配。因此设置f(s)成为关键问题。
f(s)的存在其实主要是为了消除回溯。细节就不再多说了,这里只从原理上简单说明。
设模式串为W,用文法描述,U、V表示W的一部分,w表示一个字符:
W -> UwV,
当U识别完成后,进入状态s,识别w时,发现到来的字符不等于w,则需要转向状态f(s),f(s)到哪里去找呢?
那就要看U是什么样子了。不管什么情况,只要U非空串,总可以表示成:
U -> uXu,或 U -> u,或U-> uXx,(x != u)
可以发现,前缀u是,如果后缀也是u,意味着主串中u已经被识别,如果还从模式串头匹配u无疑是多余的,所以f(s)应该是识别前缀u后进入的状态。然后再匹配下一个字符。而满足条件的u可能会有多个,所以总是选择最长的那个。伪代码如下:
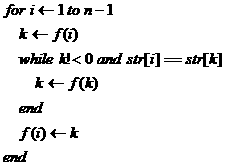
到此为止,应该算是可以结束KMP了,但实际情况下还可以对f函数进行优化。很多书本上描述的next数组就可以从f函数推导过来。
其实也显然,设状态s接收字符w,当与输入字符c不等于c时,转向状态t,倘若t状态也只接收字符w,显然再次比较w与c是多余的,之后必然再次转向状态f(t)。在运行的时候,这些状态转换时没有意义的,可以在构造f之后,直接将f(s)设置为f(t)提高运行效率(不过此时f函数的意义已经不同了)。f优化如下:
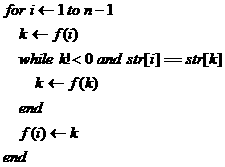
二、多关键字匹配与Aho-Corasick算法
Aho和Corasick对KMP算法进行了推广,使它可以在一个文本串识别一个关键字集合中的任何关键字。在这种情况下,trie是一棵真正的树,从其根结点开始就会出现分支。如果一个字符串是某个关键字的前缀,那么在trie中就又一个和该字符串对应的状态。如关键字集合{he,she,his,hers},trie树如下:
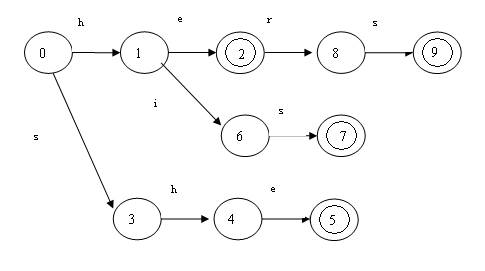
类似的,仍然构造类似KMP算法中那样的实效函数。对于上面的例子,失效函数如下:
|
s
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
|
f(s)
|
-1
|
0
|
0
|
0
|
1
|
2
|
0
|
3
|
0
|
3
|
1.构造失效函数
类似KMP算法,同样采用实效实效函数推进的方法,假设当前状态为s,s的一个孩子结点的根结点根节点t状态,如果当前的失效函数已知为f(s),则显然地,f(t)必定是f(s)的孩子结点状态,所要做的就是在状态f(s)处寻找接受字符同s->t下一个状态,如果能找到,那就是f(t),否则说明到s处匹配串的前缀长度太长,需缩减,所以需要找到更短的后缀,于是就到f(s)处继续,如果仍然找不到,则转到f(f(s))处,形成状态的递归转移。构造中需要遍历之前结点的所有孩子,所以需采用广度优先遍历,伪代码如下:
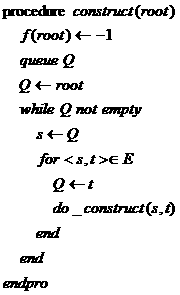
具体的构造如下:
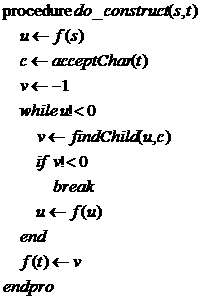
2.构造Trie树
具体实现当然需要用到树形结构了,显然采用静态链表应该是最适合的,因为树构造完就不需要改变,而且当模式串比较多的时候可以减少内存碎片。
每一个结点有5个域:接受字符,下一个兄弟结点,第一个孩子结点,失效函数值,结点状态。
但是有一种特殊情况,如上面的第二个图,在进行匹配时,hers是永远不会被匹配,因为he总是先于hers被匹配。这里就不考虑在内点状态结束,这个问题暂时无法解决。于是可以做个特殊处理,只使用4个域,因为此时匹配成功后状态就到了叶子结点,叶子结点不存在孩子域,这个域被浪费了,这里就可以借用一下,比如此域值为x,当x<0时,使用x xor 0x80000000表示识别到的模式串编号。
另一个棘手的问题是结点个数问题,这个数组到底多大?如何确定?
可以使用分值算法计算,先把模式串按字典顺序排好序,设想n个排好序的模式串第i位排在一起,相同字符的组成一组,如AiBi…Xi,再把每组下一个字符,也就是第i+1位排在一起,相同字符的组成一组,如A’iB’I…X’i,以此递归运算。伪代码如下:

3.缺点
水平有限,程序缺点很多,很多问题都没有解决。
1.如果存在两个模式串,一个是另一个的子串,那么后者将无法被匹配。
2.无法处理动态决定大小写敏感性
3.不够完整,只能向后匹配
posted on 2009-12-06 22:51
夜风 阅读(6454)
评论(1) 编辑 收藏 引用 所属分类:
C/C++技术 、
编译技术 、
算法