转载自:http://blog.sina.com.cn/s/blog_5e83fce60100pz2p.html
最初接触File Mapping是为了能够方便地处理一个几百兆的大文件,当时查了些资料大概了解了一下就匆匆动手了,因为知其然而不知其所以然,在使用过程中遇到了不少问题,今天在这里就是想把这些历史遗留问题解决掉。
问题一、Mapping有“映射”之意,那么在该语境中形成映射关系的双方是谁,也就是从哪里映射到哪里呢?
要回答这个问题,我们必须要对虚拟内存有所了解。现在操作系统中,大多都使用虚拟内存技术来对内存进行管理。通过虚拟内存,操作系统给予了每个进程一个统一的地址空间。在32位操作系统中,该地址空间的大小达到 2^32个,也就是4G了。从一个进程的角度看来,这4G的地址空间是自己独享的,也就是说,如果操作系统允许的话,我可以访问这4G地址空间中的任何一个。当然,操作系统是不可能让一个进程随心所欲地使用这些地址的。下面,我们来看看这些地址具体是怎样分配的:
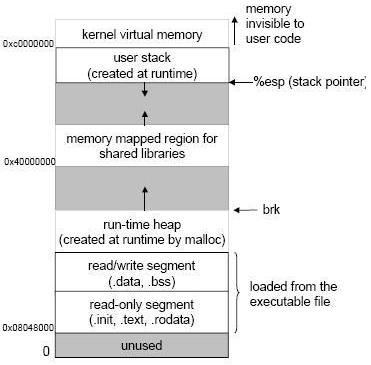
上面这个图大家应该都很熟悉,它是Linux中进程的内存映象。我们可以看到,在4G的地址空间中,我们先从下往上看, 0~0x08047ffff(大概128M左右)是系统保留的,不能使用。read-only segment和read/write segment用以存放系统加载器从可执行文件中载入的代码段以及数据段等内容。运行时堆大家应该都比较清楚,是动态分配内存的地方,我们通过malloc和free等函数动态在堆中分配和释放内存,堆的大小是往上增长的,最大可达到0x3FFFFFFF处。好,到这里我们在从上往下看,0xc0000000以上是核心虚拟内存,专门为操作系统核心的数据结构以及代码预留的,一般用户进程无权使用。然后就到了栈区了,这里是系统保存跟函数操作有关的数据,如局部变量,函数参数等内容。与堆不一样,栈是从上往下增长的,其栈顶通过寄存器esp指出。那么被堆和栈夹着的区域是干什么的呢?原来,那是用来放动态共享库的。在C/C++库文件简介中我们谈到了共享库,动态共享库是在程序被载入时或者运行过程中载入到进程内存空间中的,它存放的地方就是我们称作内存映射区的这个地方。
这样一看,原来进程开始运行时,4G的地址已经被用掉了不少,其中,光是操作系统所占用的核心虚拟内存就达到1G,加上程序的代码和数据以及动态共享库等等,我们大概就剩下2G左右的地址空间可以使用了。那么,这2G空间我们是如何使用的呢?第一,我们使用malloc函数,在堆中分配空间,使堆往上增长;第二,我们在函数中使用局部的数据,以及函数调用时现场的保留,使栈空间往下增长;第三,我们使用File Mapping,使内存映射区往上增长。
好了,终于出现File Mapping 了。现在,我们也可以知道题目中“映射”的其中一方了:内存。原来它就是在内存映射区中的一段地址空间。那么,“映射”的另一方又是什么呢?那自然是文件了。我们可以将任何类型任何大小(只要操作系统支持,现在win32支持最大的文件为16EB,就是2^64)的文件映射到内存映射区中。当然,太大的文件我们不可能一次性把它全部映射到虚拟内存中去,毕竟我们大概只有2G的地址空间,两者间是不可能构成一一对应的关系的。此时,我们可以将文件分段进行映射,每次将文件的一部分映射到内存空间中。映射完以后,我们就可以像访问内存那样直接访问文件了。
问题二、数据在哪呢?数据文件?物理内存?页面文件?
这里,我们暂且将被映射的文件称为数据文件。当我们映射好一个数据文件以后,操作系统并不会马上将文件中的内容提交到物理内存中去,数据还是原封不动地放在数据文件中。但是,当程序首次对文件中某个数据进行访问时(read /write),操作系统就会将该数据从数据文件中调入物理内存中,供CPU使用。操作完毕后,当我们解除映射时,操作系统将根据映射的属性(write/write-on-copy)决定是将更改后的数据写回到数据文件中还是将更改直接丢弃。Readonly 不存在这个问题,因为不可能被更改,因此unmap时只需将内存中的数据丢弃就可以了。
这中间还有一个问题,那就是在映射以后和解除映射之前这个时间段内,物理内存中的数据是有可能被换出的(swap out),那么,换出时这些数据是被存放在数据文件中还是像一般数据那样存放在系统的页面文件中呢?同样,这也是跟映射的属性紧密相关的:
如果映射为readonly,那么换出时只需修改相应的页表(page table)内容,标注其已被换出即可。
如果映射为write-on-copy,那么换出将存放在页面文件中,
如果映射为write,那么换出时将写会到数据文件中。
问题三、使用File Mapping为什么可以提高访问文件的速度呢?
这是因为操作系统在处理一般读写跟处理内存映射使用的方法不一样。在处理一般的读写操作时,操作系统一般使用中断的方式,先将内容拷贝到核心虚拟内存缓冲,然后再拷贝到进程空间中;但是,处理内存映射文件时,一般使用虚拟内存管理器,无需进行中间的拷贝过程,因此速度加快。此外,像Windows这样使用页式管理虚拟内存的操作系统中,数据的换入换出都是以页为单位的(通常是4k或者8k),因为程序一般都具有时间和空间的局部性(locality),因此,相当于进行了大量的缓冲操作,有利于提高性能。
问题四、什么情况适合使用 File Mapping呢?看看人家的建议:
File mapping is effective in the following situations:
-
You have a large file whose contents you want to access randomly one or more times.
-
You have a small file whose contents you want to read into memory all at once and access frequently. This technique is best for files that are no more than a few virtual memory pages in size.
-
You want to cache specific portions of a file in memory. File mapping eliminates the need to cache the data at all, which leaves more room in the system disk caches for other data.
You should not use file mapping in the following situations:
-
You want to read a file sequentially from start to finish only once.
-
The file is several hundred megabytes or more in size. (Mapping large files fills virtual memory space quickly. In addition, your program may not have the available space if it has been running for a while or its memory space is fragmented.)
问题五、为什么在操作大文件时速度变得很慢呢?
遇到这个问题,你可以首先打开Windows的任务管理器,看看你进程究竟使用了多少的内存。呵呵,通常都是个天文数字。占用了那么多的内存,系统肯定就很慢了。遇到这样的问题,我们通常都是使用内存映射文件对数据文件进行遍历操作,譬如像将A文件拷贝为B文件。上面我们提到,操作系统是在真正用到数据的时候才会把它从数据文件中提交到物理内存里面的,因此,刚做好映射不进行操作的话,进程并不会消耗多少内存。但是,一旦你开始进行遍历,那么,操作系统就马上将它们调入物理内存中(你可以看看页面错误的数量,肯定是飞速增长的),于是,内存就一路飞涨了。
怎么办呢?不要一次性把整个文件进行映射,而是分开进行,操作完一部分后,将它unmap掉,这样,操作系统就会把它们“赶回家去”了,内存就不会占用太高了。