2013年5月27日
2009年6月2日
1、编辑MySQL(和PHP搭配之最佳组合)配置文件:
windows环境中:%MySQL(和PHP搭配之最佳组合)_installdir%\my.ini //一般在MySQL(和PHP搭配之最佳组合)安装目录下有my.ini即MySQL(和PHP搭配之最佳组合)的配置文件。
linux环境中:/etc/my.cnf
在[MySQL(和PHP搭配之最佳组合)d]配置段添加如下一行:
skip-grant-tables
保存退出编辑。
2、然后重启MySQL(和PHP搭配之最佳组合)服务
windows环境中:
net stop MySQL(和PHP搭配之最佳组合)
net start MySQL(和PHP搭配之最佳组合)
linux环境中:
/etc/init.d/MySQL(和PHP搭配之最佳组合)d restart
3、设置新的ROOT密码
然后再在命令行下执行:
MySQL(和PHP搭配之最佳组合) -uroot -p MySQL(和PHP搭配之最佳组合)
直接回车无需密码即可进入数据库了。
现在我们执行如下语句把root密码更新为 7758521:
update user set password=PASSWORD("7758521") where user='root';
quit 退出MySQL(和PHP搭配之最佳组合)。
4、还原配置文件并重启服务
然后修改MySQL(和PHP搭配之最佳组合)配置文件把刚才添加的那一行删除。
再次重起MySQL(和PHP搭配之最佳组合)服务,密码修改完毕。
修改完毕。
用新密码7758521试一下吧,又能登入MySQL(和PHP搭配之最佳组合)的感觉就是不一样吧?
2009年1月20日
关于文本的输出
在如何自己编写文本控件时,有关于如何展开Tab的具体做法:
1 void TextView::PaintLine(HDC hdc,int line_no) void TextView::PaintLine(HDC hdc,int line_no)
2
3   { {
4
5 int length = document->GetLineLength(line_no + start_line_no);
6
7 char *buffer = new char[length];
8
9 document->GetLineBuffer(buffer,line_no + start_line_no);
10
11 //容纳单行文本矩形区域
12
13 RECT line_rect;
14
15 GetClientRect(tv_hwnd,&line_rect);
16
17 line_rect.top = line_no*(font_height + font_extra);
18
19 line_rect.bottom = line_rect.top + font_height + font_extra;
20
21 line_rect.left -= start_column_no*5;
22
23 //展开Tab字符
24
25 int tab = 4*font_width;
26
27 int width = TabbedTextOut(hdc,line_rect.left,line_rect.top,buffer,length,1,&tab,line_rect.left);//输出文字
28
29 line_rect.left = LOWORD(width);
30
31 ExtTextOut(hdc,0,0,ETO_OPAQUE,&line_rect,0,0,0);
32
33 delete []buffer;
34
35 } }
36
要明白他的意思才能在以后的编写扩展功能才能得心应手。首先要明白一个函数。
TabbedTextOut
功能:
1将一个字符串写到指定位置。
2并按制表位位置数组里的值展开制表符。
函数原型:
LONG TabbedTextOut(HDC hdc, int X, int Y, LPCTSTR lpString, int nCount, int nTabPositions, LPINT lpn TabStopPositions, int nTabOrigin)
参数意义:
Hdc :设备环境句柄。
X: 字符串开始点的x坐标(逻辑单位)。
Y: 字符串开始点的y坐标(逻辑单位)。
lpString:缓冲区指针。
nCount: 字符数。
nTabPositions:指定制表位位置数组的值的个数。
lpnTabStopPositions:数组,包含制表位位置(逻辑单位)。必须按照升序保存。
nTabOrigin:指定制表符展开的开始位置的x坐标(逻辑单位)。
返回值:字符串的尺寸,高位字表示高度,低位表示宽度。
注:
【1】 如果nTabPositions值为0,且lpnTabStopPositions值位NULL,那么制表符会按平均字符宽度的8位来扩展。
【2】 如果lpnTabStopPositions数组包含一个以上的话,则制表位被设为数组里的每一个值,共为lpnTabStopPositions个。
【3】 nTabOrigin参数允许一个应用程序为一行多次调用TabbedTextOut。如果应用程序多次调用TabbedTextOut,nTabOrigin每次都设置相同的值,则此函数在相对于nTabOrigin指定的位置处展开所有的制表符。
知识补充:
TabbedTextOut(hdc,line_rect.left,line_rect.top,buffer,length,1,&tab,line_rect.left);
第六个参数为nTabPosition = 1
第七个参数为lpnTabStopPositions = tab = 4*font_width
第八个参数位nTabOrigin = line_rect.left
因为编辑器以行位模型,当然是从一行的最左端开始。制表位数组值一个等于字体宽度的4倍。
摘自《windows编程》的解释:
TabbedTextOut的前五个参数与TextOut相同,第六个参数是跳位间隔数,第七个是以图素为单位的跳位间隔数组。
【1】 如果平均字符宽度是8个图素,而您希望每5个字符加一个跳位间隔,则这个数组将包含40、80、120,按递增顺序依此类推。
【2】 如果第六个和第七个参数是0或NULL,则跳位间隔按每八个平均字符宽度设定。
【3】 如果第六个参数是1,则第七个参数指向一个整数,表示跳位间隔重复增大的倍数(例如,如果第六个参数是1,并且第七个参数指向值为30的变量,则跳位间隔设定在30、60、90…图素处)。最后一个参数给出了从跳位间隔开始测量的逻辑x坐标,它与字符串的起始位置可能相同也可能不同。
编辑器的展开tab属于【3】,增大倍数是4个字符宽度。4倍与8倍的区别如图:
2008年11月16日
继续上个版本修改了一些bug,然后美化了一下。
发现自己的审美观不咋的,俺觉得漂亮的人家觉得不漂亮。还是照着大家要求的画一个。
主要解决的问题是,这次行列都用宏表示,这样可以修改行列,窗口大小也动态改变。
另外长条旋转变成Z型问题也解决,主要是取模的时候绕回去了。
其中最重要的要算是解决了刷新闪烁问题,尽管HAM2008指点过,始终没做成,这次vczh说了一句话就点醒了我。根本不应该使用InvalidateRect函数,直接画,然后用缓冲DC就可以了。
VOID OnPaint()
{
HDC hdc = GetDC(hWnd);
HDC bitmap_dc = CreateCompatibleDC(hdc);
HBITMAP bitmap = CreateCompatibleBitmap(hdc,1024,768);
SelectObject(bitmap_dc,bitmap);
  /**//******************************************** /**//********************************************
DrawBlock
 *********************************************/ *********************************************/
int x = tetris.GetX();
int y = tetris.GetY();
for(int i=0; i<4; ++i)
{
for(int j=0; j<4; ++j)
{
if(current_block[i][j] == 1)
{
DrawBlock(bitmap_dc,y+i+1,x+j+1,3,3,tetris.GetColor(),RGB(0,0,0));
}
}
}
/**//*****************************************
*DrawContainer
******************************************/
for(int i=0; i<ROWS; ++i)
{
for(int j=0; j<COLS; ++j)
{
if(Container[i][j] == 1)
{
DrawBlock(bitmap_dc,i+1,j+1,3,3,ColorTable[i][j],RGB(0,0,0));
}
}
}
BitBlt(hdc,0,0,1024,768,bitmap_dc,0,0,SRCCOPY);
DeleteDC(bitmap_dc);
DeleteObject(bitmap);
ReleaseDC(hWnd,hdc);
}
以上就是GDI缓冲的主要实现代码。
可执行文件下载代码还是等全部完善后上传吧。Redist请自行下载。 代码估计要有大的改动,感觉现在的代码没一点C++的味道。 有点简单,用陈坤的话说就是扩展性不好。
2008年11月9日
2008年10月26日
C++博客上的蚂蚁终结者的文章都写的不错,它写了个MD5的算法,我就用他的算法写了个小程序。
简单的计算文件的MD5,支持拖拽文件。现在还只是简单的计算。
目前打算改进的是
1添加进度条。
2美化界面。
3解决大文件计算时界面僵死问题。
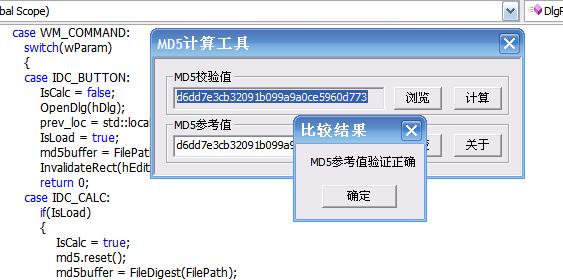
个人写程序喜欢不断改进,也就是偶然突发奇想写个程序。以后想起来就改进一下。嘎嘎。
要是忘记了,就作罢。代码可点击这里下载
2008年10月3日
脑袋里没有点API的储量,想写什么东西还是很困难的。厚积薄发才是硬道理。所以先看看别人的代码,偷学几个API的用法。
SetClipData proc lpData:LPSTR,dwSize:dword
LOCAL hMem:HANDLE ;==>内存块句柄
LOCAL pMem:dword ;==>内存块指针
mov eax,dwSize
shr eax,3
inc eax
shl eax,3 ;==>(dwSize/8 + 1)*8 不满8的倍数则补全
invoke xGlobalAlloc, GHND or GMEM_DDESHARE, eax
test eax,eax ;==>申请成功则继续否则跳转到@exit2
je @exit2
mov hMem,eax
invoke GlobalLock,eax ;hGlob ;==>锁定申请的内存块返回内存块指针
test eax,eax
je @exit1
mov pMem,eax
invoke RtlMoveMemory,eax,lpData,dwSize ;==>复制lpData的内容到申请的内存块中
mov eax,pMem
add eax,dwSize
mov byte ptr [eax],0 ;==>在内存块最后添0结束
invoke GlobalUnlock,hMem ;==>解锁,使内存块指针无效
invoke OpenClipboard,NULL
.if eax
invoke EmptyClipboard
invoke SetClipboardData,CF_TEXT,hMem ;==>将数据关联到剪贴板
invoke CloseClipboard
xor eax,eax ;0 - Ok
jmp @exit3
.endif
@exit1:
invoke GlobalFree, hMem ;==>未锁定成功则释放该内存块
xor eax, eax
@exit2:
dec eax ; -1 - error
@exit3:
ret
SetClipData endp
看完这段代码我有一个疑问,这里是将lpData的数据拷贝到一个内存块,然后与剪贴板关联,我这里解释为关联,我就认为剪贴板不应该是一个内存区域,我猜测是一个链表之类的结构,然后链表每一个节点存储一个内存区域的指针还有其他的信息,然后根据信息来管理。
否则应该可以直接将lpData来跟剪贴板关联。另一个原因是lpData是局部的随时会被释放的。如有不正确还望指正。
2008年9月7日
vector优势:1.随机访问 2.在尾部插入删除元素
#include<iostream>
#include<vector>
using namespace std;
void Print(vector<int>& vec)
{
for(int i = 0; i < vec.size(); ++i)cout<<' '<<vec[i];
cout<<endl;
}
int main()
{
vector<int> first;
vector<int> second(4, 1000);
vector<int> third(second.begin() + 2, second.end());
vector<int> forth(third);
vector<int>::iterator it;
int val[] = {1,2,3,4};
vector<int> fifth(val, val + sizeof(val) / sizeof(val[0]));
cout<<"First:";
Print(first);
cout<<"Second:";
Print(second);
cout<<"Third:";
Print(third);
cout<<"Forth:";
Print(forth);
cout<<"Fifth:";
Print(fifth);
first.swap(fifth);
cout<<"First:";
Print(first);
first.push_back(12);
cout<<"First:";
Print(first);
it = first.begin() + 2;
first.erase(it,first.end());
cout<<"First:";
Print(first);
it = first.begin();
first.insert(it,100);
cout<<"First:";
Print(first);
system("pause");
return 0;
}
结果: 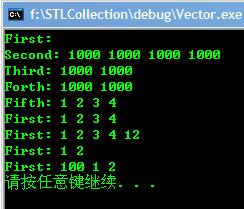 Deque操作代码类似。 优势:比之Vector在头部插入删除元素也有很高效率。也支持迭代器随机访问。不过元素在内存中不连续。 List操作基本相同不过多了一些功能 优势:高效遍历元素,常量时间插入删除任意位置元素。
#include<iostream>
#include<list>
using namespace std;
void Print(list<int>& ls)
{
list<int>::iterator it = ls.begin();
for(; it != ls.end(); ++it)cout<<' '<<*it;
cout<<endl;
}
void Print(list<double>& ls)
{
list<double>::iterator it = ls.begin();
for(; it != ls.end(); ++it)cout<<' '<<*it;
cout<<endl;
}
int main()
{
list<int> first;
list<int> second(4, 1000);
list<int>::iterator it;
double first_val[] = {1.0,3.0,2.0,4.0};
list<double> third(first_val, first_val + sizeof(first_val) / sizeof(first_val[0]));
double sencond_val[] = {1.1,4.3,1.4,2.9};
list<double> fourth(sencond_val, sencond_val + sizeof(sencond_val)/sizeof(sencond_val[0]));
it = first.begin();
first.insert(it,100);
cout<<"First:";
Print(first);
it = first.begin();
first.splice(it,second);//splice四个参数,第一个参数是插入的位置,第二个是插入源,第三四个参数指定范围
cout<<"First:";
Print(first);
first.remove(100);
cout<<"First:";
Print(first);
third.sort();
fourth.sort();
cout<<"Third:";
Print(third);
cout<<"Fourth:";
Print(fourth);
third.merge(fourth);
cout<<"Third:";
Print(third);
system("pause");
return 0;
}
结果: 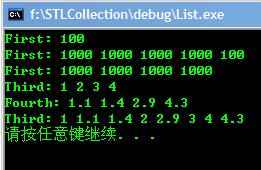 splice在代码中已经说明,merge函数合并两个list而且是按照从小到大的顺序,merge有另一个版本包含两个参数,另一个是一个 返回bool类型的函数,说明了比较规则。用法相同。另外一些函数使用比较简单。 该类笔记均参考: www.cplusplus.com
2008年8月31日
1)运行时库就是 C run-time library,是 C 而非 C++ 语言世界的概念:取这个名字就是因为你的 C 程序运行时需要这些库中的函数.
2)C 语言是所谓的“小内核”语言,就其语言本身来说很小(不多的关键字,程序流程控制,数据类型等);所以,C 语言内核开发出来之后,Dennis Ritchie 和 Brian Kernighan 就用 C 本身重写了 90% 以上的 UNIX 系统函数,并且把其中最常用的部分独立出来,形成头文件和对应的 LIBRARY,C run-time library 就是这样形成的。
3)随后,随着 C 语言的流行,各个 C 编译器的生产商/个体/团体都遵循老的传统,在不同平台上都有相对应的 Standard Library,但大部分实现都是与各个平台有关的。由于各个 C 编译器对 C 的支持和理解有很多分歧和微妙的差别,所以就有了 ANSI C;ANSI C (主观意图上)详细的规定了 C 语言各个要素的具体含义和编译器实现要求,引进了新的函数声明方式,同时订立了 Standard Library 的标准形式。所以C运行时库由编译器生产商提供。至于由其他厂商/个人/团体提供的头文件和库函数,应当称为第三方 C 运行库(Third party C run-time libraries)。
4)C run-time library里面含有初始化代码,还有错误处理代码(例如divide by zero处理)。你写的程序可以没有math库,程序照样运行,只是不能处理复杂的数学运算,不过如果没有了C run-time库,main()就不会被调用,exit()也不能被响应。因为C run-time library包含了C程序运行的最基本和最常用的函数。
5)到了 C++ 世界里,有另外一个概念:Standard C++ Library,它包括了上面所说的 C run-time library 和 STL。包含 C run-time library 的原因很明显,C++ 是 C 的超集,没有理由再重新来一个 C++ run-time library. VC针对C++ 加入的Standard C++ Library主要包括:LIBCP.LIB, LIBCPMT.LIB和 MSVCPRT.LIB
6)Windows环境下,VC提供的 C run-time library又分为动态运行时库和静态运行时库。
动态运行时库主要是DLL库文件msvcrt.dll(or MSVCRTD.DLL for debug build),对应的Import library文件是MSVCRT.LIB(MSVCRTD.LIB for debug build)
静态运行时库(release版)对应的主要文件是:
LIBC.LIB (Single thread static library, retail version)
LIBCMT.LIB (Multithread static library, retail version)
msvcrt.dll提供几千个C函数,即使是像printf这么低级的函数都在msvcrt.dll里。其实你的程序运行时,很大一部分时间时在这些运行库里运行。在你的程序(release版)被编译时,VC会根据你的编译选项(单线程、多线程或DLL)自动将相应的运行时库文件(libc.lib,libcmt.lib或Import library msvcrt.lib)链接进来。
编译时到底哪个C run-time library联入你的程序取决于编译选项:
/MD, /ML, /MT, /LD (Use Run-Time Library)
你可以VC中通过以下方法设置选择哪个C run-time library联入你的程序:
To find these options in the development environment, click Settings on the Project menu. Then click the C/C++ tab, and click Code Generation in the Category box. See the Use Run-Time Library drop-down box.
从程序可移植性考虑,如果两函数都可完成一种功能,选运行时库函数好,因为各个 C 编译器的生产商对标准C Run-time library提供了统一的支持.
2008年8月20日
最早时候就曾经哪里看到过说所有控件都是窗口(window),更有甚者说都是对象,这个就不扯了。自己做好的控件是做成Lib还是Dll那是后话,MFC我是不熟悉了,Win32还是看了几天的。大致把制作的整个流程简要的记录一下。
自己做的控件最主要的功能就是接受你发给他的命令,也就是要给外部调用的接口。控件有自己的消息处理函数比如
LRESULT CALLBACK PETextViewWndProc(HWND hWnd,UINT Message,WPARAM wParam,LPARAM lParam)
{
PETextView *View = (PETextView*)GetWindowLong(hWnd,0);
switch(Message)
{
case WM_NCCREATE:
if((View = new PETextView(hWnd)) == 0)
return false;
SetWindowLong(hWnd,0,(LONG)View);
return true;
case WM_NCDESTROY:
if(View)delete View;
return 0;
case WM_PAINT:
return View->OnPaint();
case WM_SIZE:
return View->OnSize(wParam, LOWORD(lParam), HIWORD(lParam));
case PEM_OPENFILE:
return View->OpenFile((TCHAR*)lParam);
case PEM_CLEAR:
return View->ClearFile();
default:
break;
}
return DefWindowProc(hWnd,Message,wParam,lParam);
}
这里有两类消息,一类是系统定义的以WM开头,一类是自己定义的,当然随便你自己定义啦。对应的消息看到是调用相应的函数完成的,这也就是说控件的行为就可以另外编写逻辑部分,然后提供接口给这里调用即可。
之所以说控件就是窗口是因为他有自己的窗口类,以及初始化函数,同时也有创建的函数。窗口类的定义和注册也做成提供给外部的接口,在外部必要的时候调用。而控制控件是通过发送消息来实现的,为了更加好看,可以定义一个宏,比如
#define PE_OpenFile(hWnd, Path) SendMessage((hWnd), PEM_OPENFILE, 0, (LPARAM)(Path))
那么创建窗口和控件唯一不同的地方就是,内部的创建和销毁消息是WM_NCCREATE和WM_NCDESTROY,先不管这两个消息。我们看到WM_NCCREATE之前有个GetWindowLong,其内有个SetWindowLong。这两个是关键的,这样就设置了这个控件的属性,使其关联起来,第二个参数msdn上是没有说明设置为0是什么意思的,其实这两个函数的第二个参数设置0表示读取的意思,第一个是读取该控件的属性,然后第二个函数在增加第三个参数的属性的同时读取赋予给这个控件。
一切都OK了!那么控件创建可在外部的WM_CREATE之时调用,当然也可以在使用其功能前调用即可。
一切提供给外部的调用都Port在一个头文件中,这样使用的时候包含这个头文件就好了。
接下来解释那两个消息,这两个消息是因为我们创建了子窗口,也就是我们自己的控件。
这两个消息与WM_CREATE,WM_DESTROY之间的顺序关系是这样的,只看销毁吧。
hwnd = parent, uMsg = WM_DESTROY
hwnd = child, uMsg = WM_DESTROY
hwnd = child, uMsg = WM_NCDESTROY
hwnd = parent, uMsg = WM_NCDESTROY
WM_DESTROY是通知子窗口销毁,然后子窗口通过接受WM_NCDESTROY进行销毁,并发送给父窗口,进行销毁。
细节部分介绍的差不多,总体思路就是和创建窗口差不多,但是要搞个头文件,把一些个常量和功能的函数另外一个窗口类的初始化和创建的接口搞进去。
2008年8月6日
摘要: 第一次写俄罗斯方块,完全是按照自己的想法做的。做完了很奇怪。估计是按照相对坐标来算,好多的分支语句把自己都搞晕了。所以决定放弃了,贴出来以祭奠。设计的草稿是这样的
棋子记录状态
棋盘根据棋子状态进行判断和绘制
主要检测:
越界检测:每次左移或者右移时检测(在边界内则移动否则不动)OK
触底检测:每次下降时检测OK,也就是在时钟记录一次时探测。
消行检测:触底触发时检测
旋转检测:... 阅读全文
2008年8月4日
以前曾经推荐过大家一个MasmPlus是用于编写汇编程序的IDE,简洁轻巧。 可以到 这里下载 然而文本编辑器始终没有遇到一个简洁的,偶然机会看到这个还算符合要求,叫E-texteditor  同样小巧精悍。可惜不是免费的,不过crack倒是一搜一大堆。 VistualStudio一装我的硬盘就几乎没空间了。这回可以用他来编辑了. 编译器使用mingw,以前都是整个都下载下来,这回就把必要的部分下载下来,顺带make和gdb打了个包 这里可以下载。make和gdb手生的很,记得一些如codeblocks他们会自动生成makefile文件,不知道这个什么原理。
2008年7月29日
本文转自 Azure博客自己总是用VC平台来开发东西,但是有时候总是出这样那样的问题,呵呵,总是需要上网查资料来解决,在这里把自己用到上网查的一些技巧摘录如下,希望对大家有用,省去大家再去搜索的烦恼。 1.如何在Release状态下进行调试Project->Setting=>ProjectSetting对话框,选择Release状态。C/C++标签中的Category选General,Optimizations选Disable(Debug),Debut info选Program Database。在Link标签中选中Generate debug info复选框。 注:只是一个介乎Debug和Release的中间状态,所有的ASSERT、VERIFY都不起作用,函数调用方式已经是真正的调用,而不查表,但是这种状态下QuickWatch、调用队列跟踪功能仍然有效,和Debug版一样。 2. Release和Debug有什么不同Release版称为发行版,Debug版称为调试版。 Debug中可以单步执行、跟踪等功能,但生成的可执行文件比较大,代码运行速度较慢。Release版运行速度较快,可执行文件较小,但在其编译条件下无法执行调试功能。 Release的exe文件链接的是标准的MFC DLL(Use MFC in a shared or static dll)。这些DLL在安装Windows的时候,已经配置,所以这些程序能够在没有安装Visual C++ 6.0的机器上运行。而Debug版本的exe链接了调试版本的MFC DLL文件,在没有安装Visual C++6.0的机器上不能运行,因为缺相应的DLL,除非选择use static dll when link。 3. ASSERT和VERIFY有什么区别ASSERT里面的内容在Release版本中不编译,VERIFY里面的内容仍然翻译,但不再判断真假。所以后者更安全一点。 例如ASSERT(file.Open(strFileName))。 一旦到了Release版本中,这一行就忽略了,file根本就不Open()了,而且没有任何出错的信息。如果用VERIFY()就不会有这个问题。 4.Workspace和Project之间是什么样的关系每个Workspace可以包括几个project,但只有一个处于Active状态,各个project之间可以有依赖关系,在project的Setting..中可以设定,比如那个Active状态的project可以依赖于其他的提供其函数调用的静态库。 5. 如何在非MFC程序中使用ClassWizard在工程目录下新建一个空的.RC文件,然后加入到工程中就可以了。 6.如何设置断点按F9在当前光标处增加一个断点和取消一个断点。 另外,在编辑状态下,按Ctrl+B组合键,弹出断点设置对话框。然后单击【Condition…】按钮弹出设置断点条件的对话框进行设置。 7.在编辑状态下发现成员变量或函数不能显示提示是如何打开显示功能这似乎是目前这个Visual C++ 6.0版本的一个bug,可按如下步骤使其正常,如再出现,可如法炮制: (1)关闭Project (2)删除“工程名.ncb”文件 (3)重新打开工程 8.如何将一个通过ClassWizard生成的类彻底删除首先在工作区的FileView中选中该类的.h和.cpp文件,按delete删除,然后在文件管理器中将这两个文件删除,再运行ClassWizard,这时出现是否移走该类的提示,选择remove就可以了。 9. 如何将在workspace中消失的类找出来打开该类对应的头文件,然后将其类名随便改一下,这个时候工作区就会出现新的类,再将这个类改回原来的名字就可以了。 10. 如何清除所有的断点菜单【Edit】->【Breakpoints…】,打开“Breakpoints”对话框,单击【Remove All】按钮即可。快捷键是“Ctrl + Shift + F8”。 11. 如何再ClassWizard中选择未列出的信息打开“ClassWizard”对话框,然后切换到“Class Info”页面。改变“Message filter”,如选择“Window”,“Message”页面就会出现Window的信息。 12. 如何检测程序中的括号是否匹配把光标移动到需要检测的括号前面,按快捷键“Ctrl + ]”。如果括号匹配正确,光标就跳到匹配的括号处,否则光标不移动,并且机箱喇叭还会发出一声警告。 13. 如何查看一个宏(或变量、函数)的定义把光标移动到要查看的一个宏上,就比如说最常见的DECLARE_MAP_MESSAGE上按一下F12(或右键菜单中的相关菜单),如果没有建立浏览文件,就会出现提示对话框,按【确定】按钮,然后就会跳到该宏(或变量、函数)定义的地方。 14. 如何添加Lib文件到当前工程单击菜单【Project】->【Settings…】弹出“Project Setting”对话框,切换到“Link”标签页,在“Object/library modules”处输入Lib文件名称,不同的Lib之间用空格格开。 15. 如何快速删除项目下的Debug文件夹中临时文件在工作区的FileView视图中选中对应的项目,单击右键弹出菜单,选择【Clean(selection only)】菜单即可。 16. 如何快速生成一个现有工程除了工程名外完全相同的新工程在新建工程的“New”对话框中选择“Custom Appwizard”项,输入新工程的名字,单击【OK】按钮。出现“Custom AppWizard”项,输入新工程的名字,单击【OK】按钮。出现“Custom AppWizard-Step 1 of 2”对话框,选择“An existing Project”项,单击【Next】按钮。出现“Custom AppWizard-Step 2 of 2”对话框,选择现有工程的工程文件名,最后单击【Finish】按钮。编译后就生成一个与现有工程相同但可以重新取名的工程AppWizard。 现在就可以项用MFC AppWizard一样用这个定制的向导。如果不想用了,可以在Visual C++ 6.0安装目录下Common\MSDev98\Template目录中删除该Wizard对应的.awx和.pdb文件。 17. 如何解决Visual C++ 6.0不正确连接的问题情景:明明改动了一个文件,却要把整个项目全部重新编译链接一次。刚刚链接好,一运行,又提示重新编译链接一次。 这是因为出现了未来文件(修改时间和创建时间比系统时间晚)的缘故。可以这样处理:找到工程文件夹下的debug目录,将创建和修改时间都比系统时间的文件全部删除,然后再从新“Rebuild All”一次。 18. 引起LNK2001的常见错误都有哪些遇到的LNK2001错误主要为:unresolved external symbol “symbol” 如果链接程序不能在所有的库和目标文件内找到所引用的函数、变量或标签,将产生此错误信息。 一般来说,发生错误的原因有两个:一是所引用的函数、变量不存在,拼写不正确或者使用错误;其次可能使用了不同版本的链接库。以下是可能产生LNK2001错误的原因: <1>由于编码错误导致的LNK2001错误 (1)不相匹配的程序代码或模块定义(.DEF)文件导致LNK2001。例如,如果在C++源文件了内声明了一变量“var1”,却试图在另一个文件内以变量“var1”访问改变量。 (2)如果使用的内联函数是在.cpp文件内定义的,而不是在头文件内定义将导致LNK2001错误。 (3)调用函数时如果所用的参数类型和头函数声明时的类型不符将会产生LNK2001错误。 (4)试图从基类的构造函数或析构函数中调用虚拟函数时将会导致LNK2001错误。 (5)要注意函数和变量的可公用性,只有全局变量、函数是可公用的。静态函数和静态变量具有相同的使用范围限制。当试图从文件外部方位任何没有在该文件内声明的静态变量时将导致编译错误或LNK2001错误。 <2>由于编译和联机的设置而造成的LNK2001错误 (1)如果编译时使用的是/NOD(/NODERAULTLIB)选项,程序所需要的运行库和MFC时将得到又编译器写入目标文件模块,但除非在文件中明确包含这些库名,否则这些库不会被链接进工程文件。这种情况下使用/NOD将导致LNK2001错误 (2)如果没有为wWinMainCRTStartup设定程序入口,在使用Unicode和MFC时将出现“unresolved external on _WinMain@16”的LNK2001错误信息。 (3)使用/MD选项编译时,既然所有的运行库都被保留在动态链接库之内,源文件中对“func”的引用,在目标文件里即对“__imp__func”的引用。如果试图使用静态库LIBC.LIB或LIBCMT.LIB进行链接,将在__imp__func上发生LNK2001错误。如果不使用/MD选项编译,在使用MSVCxx.LIB链接时也会发生LNK2001错误。 (4)使用/ML选项编译时,如用LIBCMT.LIB链接会在_errno上发生LNK2001错误。 (5)当编译调试版的应用程序时,如果采用发行版模态库进行链接也会产生LNK2001错误;同样,使用调试版模态库链接发行版应用程序时也会产生相同的错误。 (6)不同版本的库和编译器的混合使用也能产生问题,因为新版的库里可能包含早先的版本没有的符号和说明。 (7)在不同的模块中使用内联和非内联的编译选项能够导致LNK2001错误。如果创建C++库时打开了函数内联(/Ob1或/Ob2),但是在描述该函数的相应头文件里却关闭了函数内联(没有inline关键字),只是将得到错误信息。为避免该问题的发生,应该在相应的头文件中用inline关键字标志为内联函数。 (8)不正确的/SUBSYSTEM或ENTRY设置也能导致LNK2001错误。 19. 如何调试一个没有源码的exe文件调用的dll在Visual C++ 6.0中,进入“Project Setting”对话框然后选择Debug标签页。通常Visual Studio默认“executable for debug session”为可执行文件名,但可以将他改成任何你想要的程序。甚至可以指定不同的工作目录以及传递参数到你的程序。这个技术常用来调试Dlls、名字空间扩展、COM对象和其他从某些EXE以及从第三方的EXE中调用的plug-in程序。 20. Visual C++ 6.0工程中的项目文件都表示什么.opt:工程关于开发环境的参数文件。如工具条位置等信息。 .aps(AppStudio File)资源辅助文件,二进制格式,一般不用去管它。 .clw:ClassWizard信息文件,实际上是INI文件格式,有兴趣可以研究一下。有时候ClassWizard出了问题,手工修改CLW文件可以解决。如果此文件不存在的话,每次用ClassWizard的时候回提示是否重建。 .dsp(DevelopStudio Project):项目文件,文本格式,不过不熟悉的不要手工修改。 .dsw(DevelopStudio Workspace):是工作区文件,其他特点和.dsp差不多。 .plg:是编译信息文件,编译时的error和warning信息文件(实际上是一个html文件),一般用处不大。在单击菜单【Tool】->【Option】弹出的对话框里面有个选项可以控制这个文件的生成。 .hpj(Help Project):是生成帮助文件的工程,用microsoft Help Compiler可以处理。 .mdp(Microsoft DevStudio Project):是旧版本的项目文件,如果要打开此文件的话,会提示你是否转换成新的.dsp格式。 .bsc:是用于浏览项目信息的,如果用Source Brower的话就必须有这个文件。如果不用这个功能的话,可以在Project Options里面去掉Generate Browse Info File,这样可以加快编译速度。 .map是执行文件的映象信息记录文件,除非对系统底层,这个文件一般用不着。 .pch(Pre-Compiled File):是与编译文件,可以加快编译速度,但是文件非常大。 .pdb(Program Database):记录了程序有关的一些数据和调试信息,在调试的时候可能有用。 .exp:只有在编译DLL的时候才会生成,记录了DLL文件的一些信息,一般也没有用。 .ncb:无编译浏览文件(no compile browser)。当自动完成功能出问题时可以删除此文件。编译工程后会自动生成。
2008年7月17日
主要类
|
CellBuffer
|
保存文本,样式信息,恢复堆栈,标签,代码叠起结构等信息
|
|
ContractionState
|
|
|
Document
|
包含CellBuffer和一些高度抽象操作,管理样式处理。
|
|
Editor
|
使用ContractionState, Indicator, LineMarker, Style, ViewStyle来显示文档KeyMap和ContractionState同样在这里使用。
|
|
Indicator
|
|
|
LineMarker
|
|
|
Style
|
|
|
ViewStyle
|
|
|
KeyMap
|
|
|
ScintillaBase
|
Editor的子类,增加了调用提示和自动完成等功能,使用类CallTip和AutoComplete
|
|
CallTip
|
|
|
AutoComplete
|
|
Scintilla文档的每个字符都紧跟关联的样式信息。一个字节的字符信息和一个字节的样式信息作为一个单位。样式信息高3位是指示器,低5位是索引号。索引号索引一个存放样式的数组。这样就可以表示32种基础样式,几乎包含所有语言的样式。三个无关指示器可以一次显示语法错误,非法命名,和缩进错误。关于样式的位可以通过SCI_SETSTYLEBITS来改变最多其中7位,剩下的位用于指示器。
字符位置信息以0开始计数,至nLen-1,中文的字符是两个字符为一个文字,这样计数就有误了(DBCS)
Scintilla的消息都是以SCI_GETxxx或者SCI_SETxxx来命名的
一.文本取回与修改
主要消息有:
SCI_GETTEXT(int length, char *text)
SCI_SETTEXT(<unused>, const char *text)
SCI_SETSAVEPOINT
SCI_GETLINE(int line, char *text)
SCI_REPLACESEL(<unused>, const char*text)
SCI_SETREADONLY(bool readOnly)
SCI_GETREADONLY
SCI_GETTEXTRANGE(<unused>, TextRange*tr)
SCI_ALLOCATE(int bytes, <unused>)
SCI_ADDTEXT(int length, const char *s)
SCI_ADDSTYLEDTEXT(int length, cell *s)
SCI_APPENDTEXT(int length, const char*s)
SCI_INSERTTEXT(int pos, const char*text)
SCI_CLEARALL
SCI_CLEARDOCUMENTSTYLE
SCI_GETCHARAT(int position)
SCI_GETSTYLEAT(int position)
SCI_GETSTYLEDTEXT(<unused>, TextRange*tr)
SCI_SETSTYLEBITS(int bits)
SCI_GETSTYLEBITS
SCI_TARGETASUTF8(<unused>, char *s)
SCI_ENCODEDFROMUTF8(const char *utf8,char *encoded)
SCI_SETLENGTHFORENCODE(int bytes)
1)SCI_GETTEXT(int length, char *text)
此函数可以取得控件中的字符串存到一个缓冲区,这样就可以保存文档了。流程是使用SCI_GETLENGTH获得字符串的长度然后根据取得的长度申请一个缓冲区,再利用该消息取得文本,然后就可以保存文本了,同时需要利用SCI_SETSAVEPOINT标记文本已保存了。
做了例子果然是可以运行的,不知道作者是如何制作这样一个控件的。我对他的内部运行机制很感兴趣,想仔细看一些具体的代码,而不是仅仅使用它。另外发现API使用的字符是宽字符,这一点很令人讨厌。
另外获取处理函数的过程用了上次写的typedef的用法,改一下看上去就清晰多了
typedef int (*EditorSendFun)(void*,int,int,int);
void* ptr;
EditorSendFun editsendmessage;
2008年7月14日
2008年7月13日
最近看Scintillia的源代码,总看到typedef的身影,朋友也说autodesk的面试官曾说过不懂typedef很差劲。于是查了网上的资料,看了几种比较
容易出错的常用用法,做了一些整理。
一.起别名的两种用法
1. typedef (int *) pInt;
2. typedef pInt (int *)
比如pInt a,b;
第一种表示: int*a;int*b;
第二种表示: int*a,b;
所以第一种更像一个类型,第二种更像宏。
二.旧式代码中声明对象
typedef struct tagPoint
{
Int x;
Int y;
}POINT;
POINT a,b;
三.代码简化
为复杂的声明定义一个新的简单的别名
方法:在原来的声明里逐步用别名替换一部分复杂声明,如此循环,把带变量名的部分留到最后替换,得到的就是原声明的最简化版
typedef int (*PF) (const char *, const char *);
这个声明引入了 PF 类型作为函数指针的同义字,该函数有两个 const char * 类型的参数以及一个 int 类型的返回值。
如果要使用下列形式的函数声明,那么上述这个 typedef 是不可或缺的:
PF Register(PF pf);
Register() 的参数是一个 PF 类型的回调函数,返回某个函数的地址,其署名与先前注册的名字相同。如果不用 typedef,那么代码是这样的:
int (*Register (int (*pf)(const char *, const char *)))(const char *, const char *);
摘自Scintilla文档
一.如何在窗口中建立Scintilla编辑控件
1. 载入动态链接库
1hmod = LoadLibrary("SciLexer.DLL");
2if (hmod==NULL)
3{
4 MessageBox(hwndParent,
5 "The Scintilla DLL could not be loaded.",
6 "Error loading Scintilla",
7 MB_OK | MB_ICONERROR);
8}
9
2. 创建窗口(已经注册)
hwndScintilla = CreateWindowEx(0,
"Scintilla","", WS_CHILD | WS_VISIBLE | WS_TABSTOP | WS_CLIPCHILDREN,
10,10,500,400,hwndParent,(HMENU)GuiID, hInstance,NULL);
二.如何控制窗口类控件
方法一:给控件发送消息和接受来自控件的响应
SendMessage(hwndScintilla,sci_command,wparam,lparam);
方法二:首先通过SCI_GETDIRECTFUNCTION 和 SCI_GETDIRECTPOINTER消息获取编辑控件回调函数的指针和第一个参数,接下来就可以直接使用编辑控件的消息处理函数了。
int (*fn)(void*,int,int,int);
void * ptr;
fn = (int (__cdecl *)(void *,int,int,int))SendMessage(hwndScintilla,SCI_GETDIRECTFUNCTION,0,0);
ptr = (void *)SendMessage(hwndScintilla,SCI_GETDIRECTPOINTER,0,0);
然后使用该回调函数:
fn(ptr,sci_command,wparam,lparam);
三.如何接受响应
只要在父窗口消息处理函数中对WM_NOTIFY消息做相应处理
NMHDR *lpnmhdr;
[]
case WM_NOTIFY:
lpnmhdr = (LPNMHDR) lParam;
if(lpnmhdr->hwndFrom==hwndScintilla)
{
switch(lpnmhdr->code)
{
case SCN_CHARADDED:
[…]
break;
}}
break;
整个过程没有任何问题,做好后是这个样子的Download。
此时你会发现该控件你没有发送任何消息就已经具备了一定的功能,有redo undo操作,还有复制黏贴。
2008年6月14日
两本需要看的书
C++程序设计语言 经常看看思考思考习题认真对待。
算法导论 需要琢磨,更需要创造性的应用。
一些需要玩玩的小程序
简单文本编辑器 先把界面搞出来再实现功能
计算器
2008年5月18日
 图0  图1.1  图1.2  图2.1
 图2.2 图0是原图,经过一次小波变换后变成图1.1,逆变换回来后是图1.2 看图1.2发现有些像素与原图不同 然后对图1.2经过一次小波变换变成图2.1,逆变换回来时图2.2 图2.2与原图十分相似 算法并没有不同 为什么会有这样的现象? 大家帮帮我哈。 ps:小波变换是有损的
2008年4月23日
2008年4月22日
2008年3月15日
2008年1月22日
摘要: 由于屏幕不够显示,滚动条成为必备品。我们也习以为常了,如果没有滚动条,我们的电脑生活就没那么轻松了^_^。要添加滚动条,我们必须知道客户区的信息,客户区是不断变化的,但是变化是就就有WM_SIZE消息,此时的lparam的高字节保存高度,低字节保存宽度。获取办法如下
caseWM_SIZE: &nb... 阅读全文
2008年1月21日
摘要:
显示器是由许多应用程序填充的,所以如何合理使用这一资源是至关重要的。有两种极端情况,一种是你的显示区域不够显示,一种是够显示但非常的多余,资源浪费。Windows程序只能对显示区域大小甚至字符的大小做很少的假定,必须使用Windows提供的功能来取得关于程序执行环境的信息。关于重新绘制在书中讲了许多,那是讲给从dos时代走过来的人的,我用惯了xp的人,很容易明白,显示区域是充满... 阅读全文
2008年1月19日
摘要: 窗口是屏幕上的矩形区域,消息窗口功能有限,因为我们不能添加四个以上的按钮以及菜单等,而且添加的按钮必须是windows提供的按钮,不能自定义。所以我们有必要自己创建一个多功能可自定义的窗口。
自己的窗口
创建窗口最重要的函数是CreateWindow,它可以创建重叠式窗口,弹出式窗口,子窗口等。而且可以自定义各种功能。
... 阅读全文
2008年1月18日
2008年1月1日
2007年11月12日
|
|
|
CALENDER
| | 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|
| 28 | 29 | 30 | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | 30 | 31 | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|
公告
常用链接
随笔分类(54)
随笔档案(53)
文章分类
相册
C++名库
Friend
GUI和设计方法
Mathematics
Problem
STL网站
工具
精品网站
其他
语言
最新随笔
最新评论

Powered By: 博客园
模板提供:沪江博客
|