前768字节,而dynamic格式下,溢出的列只存储前20字节,一旦发生了行溢出, dynamic其实就存储一个指针,数据都放在溢出页里,dynamic代表将长字段(发生行溢出)完全off-page存储。
Row_format 引发异常的一个案例:
前几天生产MYSQL遇到的一个问题,在录入数据时,整行数据完全录不进去,报以下错:
Cause:java.sql.SQLException: com.taobao.tddl.common.exception.TddlException:java.sql.SQLException: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException:Row size too large (> 8126). Changing some columns to TEXT or BLOB or usingROW_FORMAT=DYNAMIC or ROW_FORMAT=COMPRESSED may help. In current row format,BLOB prefix of 768 bytes is stored inline.; nested exception iscom.ibatis.common.jdbc.exception.NestedSQLException:
该表是一个产品介绍详情表,有20多个TEXT 字段,刚好碰到了一个产品,每个字段录入的数据都很长,
而mysql 中有了个限制,一个页(这里pagesize 是16K)必须至少存2行,也就是说每行的存储长度必须小于等于8192,而这么多 TEXT 字段,一行肯定是存不下来,也就是会发生溢出,而即例发生溢出,每个列仍然会存储前768字节(该表的row_formart 是compact),字段一多还是超过了8192,于是就报错,插不进了。
最后将表的row_format 改为 dynamic 得以解决。alter table … row_format=dynamic;
所以,如果大家遇到一些表TEXT 或 VARCHAR 大字段很多,又不好拆解时,可能需要考虑下溢出后列的长度了,如果溢出后列的长度还是太大,则要看一下表的 row_format :
show table status like '%xxx%'\G
必要时需要将其实设置为 dynamic 如:
create table test(id int,name text,...... ) row_format=dynamic; 或 alter table test row_format=dynamic;
posted @
2019-08-14 15:38 长戟十三千 阅读(1242) |
评论 (0) |
编辑 收藏记得一次面试中,面试官问我是否知道表的压缩,这个时候我才知道mysql有个表压缩这么个功能,今天试用下看看表的压缩率怎么样。
这里分两个部分说明,第一部分:官方文档说明;第二部分:具体实例测试。
【第一部分】
一、表压缩概述:
表压缩可以在创建表时开启,压缩表能够使表中的数据以压缩格式存储,压缩能够显著提高原生性能和可伸缩性。压缩意味着在硬盘和内存之间传输的数据更小且占用相对少的内存及硬盘,对于辅助索引,这种压缩带来更加明显的好处,因为索引数据也被压缩了。压缩对于硬盘是SSD的存储设备尤为重要,因为它们相对普通的HDD硬盘比较贵且容量有限。
我们都知道,CPU和内存的速度远远大于磁盘,因为对于数据库服务器,磁盘IO可能会成为紧要资源或者瓶颈。数据压缩能够让数据库变得更小,从而减少磁盘的I/O,还能提高系统吞吐量,以很小的成本(耗费较多的CPU资源)。对于读比重比较多的应用,压缩是特别有用。压缩能够让系统拥有足够的内存来存储热数据。
在创建innodb表时带上ROW_FORMAT=COMPRESSED参数能够使用比默认的16K更小的页。这样在读写时需要更少的I/O,对于SSD磁盘更有价值。
页的大小通过KEY_BLOCK_SIZE参数指定。不同大小的页意味着需要使用独立表空间,不能使用系统共享表空间,可以通过innodb_file_per_table指定。KEY_BLOCK_SIZE的值越小,你获得I/O好处就越多,但是如果因为你指定的值太小,当数据被压缩到不足够满足每页多行数据记录时,会产生额外的开销来重组页。对于一个表,KEY_BLOCK_SIZE的值有多小是有严格的限制的,一般是基于每个索引键的长度。有时指定值过小,当create table或者alter table会失败。
在缓冲池中,被压缩的数据是存储在小页中的,这个小页的实际大小就是KEY_BLOCK_SIZE的值。为了提取和更新列值,mysql也会在缓冲池中创建一个未压缩的16k页。任何更新到未压缩的页也需要重新写入到压缩的页,这时你需要估计缓冲池的大小以满足压缩和未压缩的页,尽管当缓冲空间不足时,未压缩的页会被挤出缓冲池。在下次访问时,不压缩的页还会被创建。
二、使用表的压缩
在创建一个压缩表之前,需要启用独立表空间参数innodb_file_per_table=1;也需要设置innodb_file_format=Barracuda,你可以写到my.cnf文件中不需要重启mysql服务。
SET GLOBAL innodb_file_per_table=1; SET GLOBAL innodb_file_format=Barracuda; CREATE TABLE t1 (c1 INT PRIMARY KEY) ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
- 如果你指定
ROW_FORMAT=COMPRESSED,那么可以忽略KEY_BLOCK_SIZE的值,这时使用默认innodb页的一半,即8kb; - 如果你指定了
KEY_BLOCK_SIZE的值,那么你可以忽略ROW_FORMAT=COMPRESSED,因为这时会自动启用压缩; - 为了指定最合适
KEY_BLOCK_SIZE的值,你可以创建表的多个副本,使用不同的值进行测试,比较他们的.ibd文件的大小; KEY_BLOCK_SIZE的值作为一种提示,如必要,Innodb也可以使用一个不同的值。0代表默认压缩页的值,Innodb页的一半。KEY_BLOCK_SIZE的值只能小于等于innodb page size。如果你指定了一个大于innodb page size的值,mysql会忽略这个值然后产生一个警告,这时KEY_BLOCK_SIZE的值是Innodb页的一半。如果设置了innodb_strict_mode=ON,那么指定一个不合法的KEY_BLOCK_SIZE的值是返回报错。
InnoDB未压缩的数据页是16K,根据选项组合值,mysql为每个表的.ibd文件使用1kb,2kb,4kb,8kb,16kb页大小,实际的压缩算法并不会受KEY_BLOCK_SIZE值影响,这个值只是决定每个压缩块有多大,从而影响多少行被压缩到每个页。设置KEY_BLOCK_SIZE值等于16k并不能有效的进行压缩,因为默认的innodb页就是16k,但是对于拥有很多BLOB,TEXT,VARCHAR类型字段的表可能会有效果的。
三、InnoDB表的压缩优化
在进行表压缩时需要考虑影响压缩性能的因素,如:
- 哪些表需要压缩
- 如何选择压缩表的页大小
- 基于运行时性能特征是否需要调整buffer pool大小,如系统在压缩和解压缩数据所花费的时间量,系统负载更像一个数据仓库还是OLTP事务性系统。
- 如果在压缩表上执行DML操作,由于数据分布的方式,可能导致压缩失败,这时你可能需要配置额外的更高级的配置选项
1、何时用压缩表
一般而言,对于读远远大于写的应用以及拥有合理数量的字符串列的表,使用压缩效果会更好。
2、数据特性及压缩率
影响数据文件压缩效率的一个关键因素是数据本身的结构,在块数据中,压缩是通过识别重复字符进行压缩的,对于完全随机的数据是一个糟糕的情况,一般而言,有重复数据的压缩更好。对于字符串的列压缩就不错,无论是string还是blob、text等类型的。另一方面,如果表中的数据是二进制类型,如整形、浮点型等或者之前别压缩过的如jpg、png类型的,压缩效果一般不好,但也不是绝对的。
为了决定是否对某个表进行压缩,你需要进行试验,可以对比未压缩与压缩后的数据文件的大小,以及监控系统对于压缩表的工作负载进行决定。具体试验请查看第二部分。
查看监控压缩表的负载,如下:
- 对于简单的测试,如一个mysql实例上没有其他的压缩表了,直接查询
INFORMATION_SCHEMA.INNODB_CMP表数据即可,该表存一些压缩表的数据状态,结构如下:
| Column name | Description |
|---|
PAGE_SIZE | 采用压缩页大小(字节数). |
COMPRESS_OPS | Number of times a B-tree page of the size PAGE_SIZE has been compressed. Pages are compressed whenever an empty page is created or the space for the uncompressed modification log runs out. |
COMPRESS_OPS_OK | Number of times a B-tree page of the size PAGE_SIZE has been successfully compressed. This count should never exceed COMPRESS_OPS. |
COMPRESS_TIME | Total time in seconds spent in attempts to compress B-tree pages of the size PAGE_SIZE. |
UNCOMPRESS_OPS | Number of times a B-tree page of the size PAGE_SIZE has been uncompressed. B-tree pages are uncompressed whenever compression fails or at first access when the uncompressed page does not exist in the buffer pool. |
UNCOMPRESS_TIME | Total time in seconds spent in uncompressing B-tree pages of the size PAGE_SIZE. |
- 对于精细的测试,如多个压缩表,查询
INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表数据,由于该表收集数据需要付出昂贵得代价,所以必须启动innodb_cmp_per_index_enabled选项才能查询。一般不要在生产环境下开启该选项。 - 还可以针对压缩运行一些测试SQL看看效率如何。
- 如果发现很多压缩失败,那么你可以调整
innodb_compression_level, innodb_compression_failure_threshold_pct, 和innodb_compression_pad_pct_max参数。
3、数据库压缩和应用程序压缩
不需要在应用端和数据库同时压缩相同的数据,那样效果并不明显而且还消耗很多CPU资源。对于数据库压缩,是在server端进行的。如果你在插入数据前通过代码进行数据压缩,然后插入数据库,这样耗费很多CPU资源,当然如果你的CPU有大量结余。你也可以结合两者,对于某些表进行应用程序压缩,而对其他数据采用数据库压缩。
4、工作负载特性和压缩率
为了选择哪些表可以使用压缩,工作负载是另一个决定因素,一般而言,如果你的系统是I/O瓶颈,那么可以使用CPU进行压缩与解压缩,以CPU换取I/O。
四、INNODB表是如何压缩的?
1、压缩算法
mysql进行压缩是借助于zlib库,采用L777压缩算法,这种算法在减少数据大小、CPU利用方面是成熟的、健壮的、高效的。同时这种算法是无失真的,因此原生的未压缩的数据总是能够从压缩文件中重构,LZ777实现原理是查找重复数据的序列号然后进行压缩,所以数据模式决定了压缩效率,一般而言,用户的数据能够被压缩50%以上。
不同于应用程序压缩或者其他数据库系统的压缩,InnoDB压缩是同时对数据和索引进行压缩,很多情况下,索引能够占数据库总大小的40%-50%。如果压缩效果很好,一般innodb文件会减少25%-50%或者更多,而且减少I/O增加系统吞吐量,但是会增加CPU的占用,你可通过设置innodb_compression_level参数来平衡压缩级别和CPU占用。
2、InnoDB数据存储及压缩
所有数据和b-tree索引都是按页进行存储的,每行包含主键和表的其他列。辅助索引也是b-tree结构的,包含对值:索引值及指向每行记录的指针,这个指针实际上就是表的主键值。
在innodb压缩表中,每个压缩页(1,2,4,8)都对应一个未压缩的页16K,为了访问压缩页中的数据,如果该页在buffer pool中不存在,那么就从硬盘上读到这个压缩页,然后进行解压到原来的数据结构。为了最小化I/O和减少解压页的次数,有时,buffer pool中包括压缩和未压缩的页,为给其他页腾出地方,buffer pool会驱逐未压缩页,仅仅留下压缩页在内存中。或者如果一个页一段时间没有被访问,那么会被写到硬盘上。这样一来,任何时候,buffer pool中都可以包含压缩页和未压缩页,或者只有压缩页或者两者都没有。
Mysql采用LRU算法来保证哪些页应该在内存中还是被驱逐。因此热数据一般都会在内存中。
五、OLTP系统压缩负载优化
一般而言,innodb压缩对于只读或者读比重比较多的应用效果更好,SSD的出现,使得压缩更加吸引我们,尤其对于OLTP系统。对于经常update、delete、insert的应用,通过压缩表能够减少他们的存储需求和每秒I/O操作。
下面是针对写密集的应用,设置压缩表的一些有用参数:
innodb_compression_level:决定压缩程度的参数,如果你设置比较大,那么压缩比较多,耗费的CPU资源也较多;相反,如果设置较小的值,那么CPU占用少。默认值6,可以设置0-9innodb_compression_failure_threshold_pct:默认值5,范围0到100.设置中断点避免高昂的压缩失败率。innodb_compression_pad_pct_max:指定在每个压缩页面可以作为空闲空间的最大比例,该参数仅仅应用在设置了innodb_compression_failure_threshold_pct不为零情况下,并且压缩失败率通过了中断点。默认值50,可以设置范围是0到75.
【第二部分】实验:

#没有设置压缩前的数据大小 -rw-rw----. 1 mysql mysql 368M 12月 29 11:05 test.ibd #设置KEY_BLOCK_SIZE=1 (product)root@localhost [sakila]> alter table test KEY_BLOCK_SIZE=1; Query OK, 0 rows affected (14 min 49.30 sec) Records: 0 Duplicates: 0 Warnings: 0 -rw-rw----. 1 mysql mysql 204M 1月 11 21:43 test.ibd #####压缩率44.5%
#设置KEY_BLOCK_SIZE=2 (product)root@localhost [sakila]> alter table test KEY_BLOCK_SIZE=2; Query OK, 0 rows affected (9 min 55.60 sec) Records: 0 Duplicates: 0 Warnings: 0 -rw-rw----. 1 mysql mysql 180M 1月 12 13:40 test.ibd #####压缩率51% #设置KEY_BLOCK_SIZE=4 (product)root@localhost [sakila]> alter table test KEY_BLOCK_SIZE=4; Query OK, 0 rows affected (7 min 24.52 sec) Records: 0 Duplicates: 0 Warnings: 0 -rw-rw----. 1 mysql mysql 172M 1月 11 21:09 test.ibd #####压缩率53.2% #设置KEY_BLOCK_SIZE=8 (product)root@localhost [sakila]> alter table test KEY_BLOCK_SIZE=8; Query OK, 0 rows affected (5 min 16.34 sec) Records: 0 Duplicates: 0 Warnings: 0 -rw-rw----. 1 mysql mysql 172M 1月 11 21:00 test.ibd #####压缩率53.2% #设置KEY_BLOCK_SIZE=16 (product)root@localhost [sakila]> alter table test KEY_BLOCK_SIZE=16; Query OK, 0 rows affected (2 min 47.48 sec) Records: 0 Duplicates: 0 Warnings: 0 -rw-rw----. 1 mysql mysql 336M 1月 12 13:54 test.ibd #####压缩率8.6%
【总结】:通过以上测试可知,当KEY_BLOCK_SIZE的值设置为4或者8时,压缩效果最好,设置为16效果最差,因为页的默认值16K。通常我是设置为8。
posted @
2019-08-14 15:31 长戟十三千 阅读(316) |
评论 (0) |
编辑 收藏 Row_format: Compressed Rows: 0 Avg_row_length: 0 Data_length: 8192 Max_data_length: 0 Index_length: 0 Data_free: 0 Auto_increment: NULL Create_time: 2013-09-27 16:09:51 Update_time: NULL Check_time: NULL Collation: utf8_general_ci Checksum: NULL Create_options: row_format=COMPRESSED KEY_BLOCK_SIZE=8 Comment: 1 row in set (0.00 sec)
No3:
发现和innodb_file_format相关的2个参数:
+--------------------------+-----------+ | Variable_name | Value | +--------------------------+-----------+ | innodb_file_format | Barracuda | | innodb_file_format_check | ON | | innodb_file_format_max | Barracuda | +--------------------------+-----------+ 3 rows in set (0.00 sec)
官方的解释可以参考如下的链接:http://dev.mysql.com/doc/refman/5.5/en/innodb-parameters.html#sysvar_innodb_file_format
测试过程中发现,如果是innodb_file_format=barracuda而innodb_file_format_max=antelop,那么在建立压缩表的时候,max会自动变成barracuda。
localhost.test>show global variables like 'innodb_file_format%'; +--------------------------+-----------+ | Variable_name | Value | +--------------------------+-----------+ | innodb_file_format | Barracuda | | innodb_file_format_check | ON | | innodb_file_format_max | Antelope | +--------------------------+-----------+ 3 rows in set (0.00 sec) localhost.test>create table test_4(x int) ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8; Query OK, 0 rows affected (0.01 sec) localhost.test>show global variables like 'innodb_file_format%'; +--------------------------+-----------+ | Variable_name | Value | +--------------------------+-----------+ | innodb_file_format | Barracuda | | innodb_file_format_check | ON | | innodb_file_format_max | Barracuda | +--------------------------+-----------+ 3 rows in set (0.00 sec)
如果innodb_file_format_check这参数解释的,决定innodb是否会检查共享表空间中的表格式的tag,如果检查开启,那么当标记的表格式的tag高于innodb可以支撑的表格式,那么innodb会报错,并停止启动。如果支持,那么会将innodb_file_format_max的值改为这个tag的值。
posted @
2019-08-14 15:24 长戟十三千 阅读(1042) |
评论 (0) |
编辑 收藏 解决办法:
vim /etc/my.cnf,根据实际情况进行参数调整:
[mysqld]
max_allowed_packet = 1G
innodb_log_file_size = 30M
innodb_log_buffer_size = 512M
innodb_file_format='Barracuda'
alter table 'role' row_format=dynamic
修改之后,重启mysql服务。
mysql文档
https://dev.mysql.com/doc/relnotes/mysql/5.6/en/news-5-6-20.html
In MySQL 5.6.22, the redo log BLOB write limit is relaxed to 10% of the total redo log size (innodb_log_file_size * innodb_log_files_in_group).
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.6/en/server-configuration-defaults.html
# *** DO NOT EDIT THIS FILE. It's a template which will be copied to the
# *** default location during install, and will be replaced if you
# *** upgrade to a newer version of MySQL.
[mysqld]
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
# These are commonly set, remove the # and set as required.
# basedir = .....
# datadir = .....
# port = .....
#server_id = 1
# socket = .....
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
#sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
port=3306
basedir=/data/mysql
datadir=/data/mysql/mysqldata
log-error=/data/mysql/log
socket=/tmp/mysqld.sock
server_id=1
back_log=2048
log-bin=mysql-bin
bind-address=0.0.0.0
character-set-server=utf8
collation-server=utf8_general_ci
skip-external-locking
skip-name-resolve
query_cache_type=0
max_connections=2000
max_connect_errors=1000000
default-storage-engine=INNODB
innodb_buffer_pool_size=12884901888
innodb_concurrency_tickets=5000
innodb_flush_method=O_DIRECT
innodb_io_capacity=2000
innodb_io_capacity_max=4000
innodb_log_buffer_size=1048576
innodb_log_file_size=1048576000
innodb_log_files_in_group=2
innodb_file_format=Barracuda
innodb_file_per_table=ON
innodb_file_format_max=Antelope
innodb_max_dirty_pages_pct=75
innodb_open_files=3000
innodb_additional_mem_pool_size=20M
innodb_sort_buffer_size=8388608
join_buffer_size=262144
key_buffer_size=16777216
preload_buffer_size=32768
read_buffer_size=262144
read_rnd_buffer_size=262144
sort_buffer_size=262144
max_allowed_packet=1073741824
binlog_stmt_cache_size=32768
bulk_insert_buffer_size=4194304
key_buffer=64M
slow_query_log=1
slow_query_log_file=/data/mysql/log
long_query_time=5
sync_frm=ON
max_binlog_size=524288000
sync_binlog=1000
binlog_format=ROW
binlog_cache_size=2097152
expire_logs_days=3
tmpdir=/data/mysql/tmpdir
max_tmp_tables=32
tmp_table_size=262144
open_files_limit=65535
table_definition_cache=512
table_open_cache=100
default_storage_engine=InnoDB
default_tmp_storage_engine=InnoDB
log_queries_not_using_indexes=ON
interactive_timeout=7200
lock_wait_timeout=31536000
wait_timeout=86400
connect_timeout=120
pid_file=/data/mysql/mysqldata/mysqld.pid
slave-skip-errors=1062,1053,1146,1061
[mysql]
port=3306
socket=/tmp/mysqld.sock
default-character-set=utf8
posted @
2019-08-08 18:11 长戟十三千 阅读(2738) |
评论 (0) |
编辑 收藏
摘要: attribute是GNU C特色之一,在iOS用的比较广泛.系统中有许多地方使用到. attribute可以设置函数属性(Function Attribute )、变量属性(Variable Attribute )和类型属性(Type Attribute)等.函数属性(Function Attribute)noreturnnoinlinealways_inlinepureconstno...
阅读全文
posted @
2019-01-26 15:28 长戟十三千 阅读(1836) |
评论 (0) |
编辑 收藏
6、cmake
cd build/
CC="distcc cc" CXX="distcc g++" cmake ../cmake/
Other:
一个大型的C/C++项目的编译非常耗时。distcc和ccache这两个工具能够非常有效地压缩编译时间。它们并不是独立的编译器,而是配合 GNU GCC使用(它们的资料明确说明并不关注其他编译器)。distcc介绍中说,有人完整编译KDE项目只花费6分钟。可见其厉害!此外,它们都非常易用,保证几分钟就能上手!
这两个项目的主页:
distcc http://distcc.samba.org/
ccache http://ccache.samba.org/
这两个软件的安装没什么好说的,都是标准的"./configure;make;make install"。在Ubuntu上安装更简单:sudo apt-get install distcc ccache。
distcc工作原理:
GCC 编译C/C++构建一个execualble分为三个阶段:(1)C/C++预处理(gcc -E);(2)编译(gcc -c);(3)链接(ld)。其中第二阶段是效率瓶颈,尤其在指定“-O2”等优化选项时。distcc是一个编译器驱动器。它在"gcc -c"阶段把预处理输出分发到指定的服务器阵列(各服务器监听TCP端口3632)并收集结果。GNU Make和SCons的"-j"并行编译可以利用distcc来加速编译。
distcc用法:
(1)服务器端以普通用户执行“distccd --daemon --allow 10.0.0.0/16”。这使得distccd接受来自10.0网段的所有TCP连接。
注意:distcc文档中说"--allow 0.0.0.0"是接受所有连接--这已经过时,实际效果是拒绝所有连接!
(2)如果工程使用automake机制。
设置DISTCC_HOSTS环境变量。
在configure阶段执行"CC=distcc ./configure"。然后执行"make -j XX"。XX是并发任务数目上限。
(3)如果工程由GNU make管理。
设置DISTCC_HOSTS环境变量。
修改Makefile使得在原来C/C++编译器名称前加上"distcc ",例如设置CC="distcc arm-linux-gcc"。然后执行"make -j XX"。XX是并发任务数目上限。
(4)如果工程由SCons管理。
修改SConstruct使得在原来C/C++编译器名称前加上"distcc "。导出环境变量HOME和DISTCC_HOSTS到构建环境(注意SCons不会自动把系统环境变量导出到builder子进程):
Environment(ENV={'HOME': os.environ['HOME'],'DISTCC_HOSTS': ‘localhost 10.0.0.2’},...)
然后执行"scons -j XX"。XX是并发任务数目上限。
distcc故障处理:
运行distccmon-gnome。如果在编译期间某个distcc服务器一直不活跃,可能的原因比较多。
distcc服务器的问题可能有
(1) IP地址不可达。
(2) distccd进程没有启动。
(3) distcc客户端IP不在--allow指定的范围内。
(4) distccd监听的3632端口被防火墙屏蔽。
distccd的日志记录在/var/log/messages。必要时查看一下。
客户端的问题可能有:
(1) 一些环境变量没有设置
distcc依赖的环境变量有HOME和DISTCC_HOSTS。
distcc 日志在解决问题时尤其有用。默认的错误信息输出在console。还可以设置DISTCC_VERBOSE和DISTCC_LOG环境变量以记录详细的调试信息到一日志文件(这对理解distcc工作过程也非常有用)。参考distcc和distccd联机帮助。
ccache工作原理:
ccache也是一个编译器驱动器。第一趟编译时ccache缓存了GCC的“-E”输出、编译选项以及.o文件到$HOME/.ccache。第二次编译时尽量利用缓存,必要时更新缓存。所以即使"make clean; make"也能从中获得好处。ccache是经过仔细编写的,确保了与直接使用GCC获得完全相同的输出。
ccache用法:
很简单,就像上面distcc用法提到的那样,给所有C/C++编译器名称前加上"ccache "即可。
ccache还可以把distcc作为后台的编译器。编译器设置为"ccache distcc "+原编译器即可。
从我经历的两个项目来看,单独使用ccache或distcc(除localhost外只用1台distcc服务器)效果比较显著。但是联合使用distcc和ccache的效果就和仅使用distcc差不多。个人倾向于只使用distcc,多加几台distcc服务器。
用distcc,ccache是两年前,项目结束的空隙,自己拿来玩的。当时是在arm上做的一个很大的工程,当时的PC,只编UI部分就需要3个小时,这也是为什么后来我用分布式编译的原因。那个项目是c++加adobe的flash,仿iphone做一款很炫的手机,其中UI全部用flash做,效果很炫,速度就比较差了。后来,我也试过在arm9261(200MHz)上用gnash播放flash,效果确实比较一般。言归正传,还是来说下分布式编译,其实它的原理很简单,把c文件在本机预编译,然后发到其他主机进行编译,编译的后的o文件再传回本机,最后在本机进行链接。没有看过代码,猜测对于每个编译的c文件对应产生一个编译任务,下发到其他机器或本机,最终完成编译。
我们的环境是ADS1.2+cygwin,用tcc,tcpp进行编译。distcc,ccache本来是在cygwin上直接装的的,但后来在使用时发现会碰到一些问题。所以从源码编译了。distcc产生的中间文件是.i的格式,tcc无法识别该文件类型,需要修改源码。就一句话,网上可以搜到的。if(dcc_getenv_bool("DISTCC_KEEP_FILETYPE", 1)).然后,./configure; make; make install。ccache问题是一样的,无法识别.i文件,修改ccache.c,把中间文件i/ii改为c/cpp,一样的方式安装。
然后要对安装的东西进行配置,我当时的配置如下,10.19.5.0网段的主机都可以做协同编译的主机,当然ads的licence只有20个啦。此处目录设置至关重要,tcc无法识别cygwin环境,tcc -c /cygdriver/c/a.c, tcc无法读取文件,错误码为C3052E。利用了cygwin既可以win32的路径,又可以识别posix路径。
export DISTCC_LOG='/var/log/distcc.log'
export DISTCC_HOSTS='localhost 10.19.5.0/24'
export DISTCC_VERBOSE=1
export DISTCC_SAVE_TEMPS=1
export TMPDIR=' e:/test '
export CCACHE_DIR=e:/test
export CCACHE_PREFIX=distcc
export CCACHE_LOGFILE=e:/test/ccache.log
distccd在没有设置DISTCCD_PATH时,使用系统的PATH作为搜索,和makefile里指定的不一致。设置了DISTCCD_PATH,很莫名其妙,当时是为什么。然后distccd --daemon --allow0.0.0.0/0,任何ip都可以接入,比较简单。
修改makefile,在CC,ARMCC,ARMCPP,TCPP原来的设置前,添加ccache。需要说明的是,distcc仅为编译器前端,编译器的指定需要distcc 。distcc支持的编译器必须可以预编译,也就是常用的gcc -E这样的选项。
最后的测试很简单,自己写makefile,只做".c.o:" ,然后把.o文件链接到工程中就可以了。在手机上还是可以很好的run起来的。当然验证的工作不是那么简单了,看了下反汇编的代码。一台主机编译的和分布式编译的,没有什么太大的差别,汇编稍有不同,但功能一致。
项目结束后自己玩的东西,虽然没有用于实际来提高效率,但还是学到了一些东西。
posted @
2018-09-08 20:56 长戟十三千 阅读(4885) |
评论 (0) |
编辑 收藏TcMalloc(Thread-CachingMalloc)是google-perftools工具中的一个内存管理库,与标准的glibc库中malloc相比,TcMalloc在内存分配的效率和速度上要高很多,可以提升高并发情况下的性能,降低系统的负载。
Google-perftools项目的网址为:http://code.google.com/p/google-perftools/,该项目包括TcMalloc、heap-checker、heap-profiler和cpu-profiler共4个组件。在只使用TcMalloc情况下可以不编译其他三个组件。
注:使用线程内存池的方法,在小对象是在内存池中进行分配,使用分配较多的内存空间来优化分配时间。
实现原理请参考网址http://goog-perftools.sourceforge.net/doc/tcmalloc.html。
简介
TcMalloc是一个由Google开发的,比glibc的malloc更快的内存管理库。通常情况下ptmalloc2能在300ns执行一个malloc和free对,而TcMalloc能在50ns内执行一个malloc和free对。
TcMalloc可以减少多线程程序之间的锁争用问题,在小对象上能达到零争用。
TcMalloc为每个线程单独分配一个线程本地的Cache,少量的地址分配就直接从Cache中分配,并且定期做垃圾回收,将线程本地Cache中的空闲内存返回给全局控制堆。
TcMalloc认为小于(<=)32K为小对象,大对象直接从全局控制堆上以页(4K)为单位进行分配,也就是说大对象总是页对齐的。
TcMalloc中一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存堆中分配。
安装
Linux下tcmalloc的安装过程如下:
1) 从Google源代码网址上下载源代码包,现在最新版本为2.0;
2) 解压缩源代码包
# unzip gperftools-2.0.zip 或
# tar zxvf gperftools-2.0.tar.gz
3) 编译动态库
# cd gperftools-2.0
# ./ configure --disable-cpu-profiler --disable-heap-profiler--disable-heap-checker
--disable-debugalloc--enable-minimal
加入上面的参数是为了只生成tcmalloc_minimal动态库,如果需要所有组件,命令如下:
# ./configure
# ./configure -h 用于查看编译选项。
编译和安装:
# make&& make install
使用最小安装时把tcmalloc_minimal的动态库拷贝到系统目录中:
# cplib/tcmalloc_minimal.so.0.0.0 /usr/local/lib
创建软连接指向tcmalloc:
# ls –s /usr/local/lib/libtcmalloc_minimal.so.0.0.0/usr/local/lib/libtcmalloc.so
启动程序之前,预先加载tcmalloc动态库的环境变量设置:
# exportLD_PRELOAD=”/usr/local/lib/libtcmalloc.so
使用losf检查程序是否已经加载tcmalloc库:
# lsof -n | greptcmalloc
在Linux下使用的tcmalloc安装完成,在Windows下使用VS(2003以上版本)打开工程项目gperftools.sln进行编译。
使用
将libtcmalloc.so/libtcmalloc.a链接到程序中,或者设置LD_PRELOAD=libtcmalloc.so。这样就可以使用tcmalloc库中的函数替换掉操作系统的malloc、free、realloc、strdup内存管理函数。可以设置环境变量设置如下:
TCMALLOC_DEBUG=<level> 调试级别,取值为1-2
MALLOCSTATS=<level> 设置显示内存使用状态级别,取值为1-2
HEAPPROFILE=<pre> 指定内存泄露检查的数据导出文件
HEAPCHECK=<type> 堆检查类型,type=normal/strict/draconian
TcMalloc库还可以进行内存泄露的检查,使用这个功能有两种方法:
1)将tcmalloc库链接到程序中,注意应该将tcmalloc库最后链接到程序中;
2)设置LD_PRELOAD=”libtcmalloc.so”/HEAPCHECK=normal,这样就不需重新编译程序
打开检查功能,有两种方式可以开启泄露检查功能:
1) 使用环境变量,对整个程序进行检查: HEAPCHECK=normal /bin/ls
2) 在源代码中插入检查点,这样可以控制只检查程序的某些部分,代码如下:
HeapProfileLeakCheckerchecker("foo"); // 开始检查Foo(); // 需要检查的部分
assert(checker.NoLeaks()); // 结束检查
调用checker建立一个内存快照,在调用checker.NoLeaks建立另一个快照,然后进行比较,如果内存有增长或者任意变化,NoLeaks函数返回false,并输出一个信息告诉你如何使用pprof工具来分析具体的内存泄露。
执行内存检查:
#LD_PRELOAD=libtcmalloc.so HEAPCHECK=strict HEAPPROFILE=memtm ./a.out
执行完成后会输出检查的结果,如果有泄露,pprof会输出泄露多少个字节,有多少次分配,也会输出详细的列表指出在什么地方分配和分配多少次。
比较两个快照:
#pprof --base=profile.0001.heap 程序名 profile.0002.heap
已知内存泄漏时,关闭内存泄露检查的代码:
void *mark =HeapLeakChecker::GetDisableChecksStart();
<leaky code> //不做泄漏检查的部分
HeapLeakChecker::DisableChecksToHereFrom(mark);
注:在某些libc中程序可能要关闭检查才能正常工作。
注:不能检查数组删除的内存泄露,比如:char *str = new char[100]; delete str;。
=================================安装缺少库============================
libunwind库为基于64位CPU和操作系统的程序提供了基本的堆栈辗转开解功能,其中包括用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API。
64位操作系统一定要先装libunwind这个库。
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-1.1.tar.gz
tar zxvf libunwind-1.1.tar.gz
cd libunwind-1.1
CFLAGS=-fPIC ./configure
make CFLAGS=-fPIC
make CFLAGS=-fPIC install
posted @
2018-08-24 11:22 长戟十三千 阅读(4855) |
评论 (0) |
编辑 收藏LINUX samba配置共享文件目录
1.使用rpm -qa|grep samba 查看是否安装samba
samba-winbind-clients-3.5.4-68.el6.x86_64
samba-3.5.4-68.el6.x86_64
samba-client-3.5.4-68.el6.x86_64
samba-common-3.5.4-68.el6.x86_64
已安装
2.更改/etc/samba/smb.conf配置
- [global]
- dos charset = cp936
- display charset = UTF-8
- workgroup = MYGROUP
- server string = Samba Server Version %v
- log file = /var/log/samba/log.%m
- max log size = 50
- cups options = raw
-
- [homes]
- comment = Home Directories
- read only = No
- browseable = No
-
- [printers]
- comment = All Printers
- path = /var/spool/samba
- printable = Yes
- browseable = No
-
- [tools]
- comment = tools
- path = /tools
- read only = No
- guest ok = Yes
-
- [home]
- comment = User Directory
- path = /home/%U
- read only = No
[global] dos charset = cp936 display charset = UTF-8 workgroup = MYGROUP server string = Samba Server Version %v log file = /var/log/samba/log.%m max log size = 50 cups options = raw [homes] comment = Home Directories read only = No browseable = No [printers] comment = All Printers path = /var/spool/samba printable = Yes browseable = No [tools] comment = tools path = /tools read only = No guest ok = Yes [home] comment = User Directory path = /home/%U read only = No
添加smb访问用户smbpasswd -a root
3.重启service smb restart
4.如果windows下登录samba服务器后无法访问linux下共享目录,提示没有权限。
则检查
a、确保linux下防火墙关闭或者是开放共享目录权限
b、确保samba服务器配置文件smb.conf设置没有问题,可网上查阅资料看配置办法
c、确保setlinux关闭,可以用setenforce 0命令执行。 默认的,SELinux禁止网络上对Samba服务器上的共享目录进行写操作,即使你在smb.conf中允许了这项操作。 /usr/bin/setenforce 修改SELinux的实时运行模式
setenforce 1 设置SELinux 成为enforcing模式
setenforce 0 设置SELinux 成为permissive模式
如果要彻底禁用SELinux 需要在/etc/sysconfig/selinux中设置参数selinux=0 ,或者在/etc/grub.conf中添加这个参数
/usr/bin/setstatus -v
posted @
2018-08-16 17:09 长戟十三千 阅读(1196) |
评论 (0) |
编辑 收藏gperftools是Google提供的一套工具,其中的一个功能是CPU profiler,用于分析程序性能,找到程序的性能瓶颈。
Graphviz是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形,gperftools依靠此工具生成图形分析结果。
安装命令:yum install graphviz
编译google-perftools
因为我们只需要tcmalloc功能,因此不编译google-perftools中的其他工具。
wget http://gperftools.googlecode.com/files/google-perftools-1.9.1.tar.gz
tar -xvzf google-perftools-1.9.1.tar.gz
cd google-perftools-1.9.1
./configure –disable-cpu-profiler –disable-heap-profiler –disable-heap-checker –enable-minimal–disable-dependency-tracking
make
makeinstall
/sbin/ldconfig
用法
1.目标程序中引入头文件
示例:
#include <google/profiler.h> #include <iostream> using namespace std; void func1() { int i = 0; while (i < 100000) { ++i; } } void func2() { int i = 0; while (i < 200000) { ++i; } } void func3() { for (int i = 0; i < 1000; ++i) { func1(); func2(); } } int main(){ ProfilerStart("my.prof"); // 指定所生成的profile文件名 func3(); ProfilerStop(); // 结束profiling return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
然后编译链接运行,使用pprof生成分析结果
g++-o demo demo.cpp -lprofiler
运行demo,生成my.prof文件,然后用pprof命令对该文件解析,生成结果txt或pdf等。
pprof–text ./demo my.prof > output.txt
pprof–pdf ./demo my.prof > output.pdf
pdf格式的比较直观
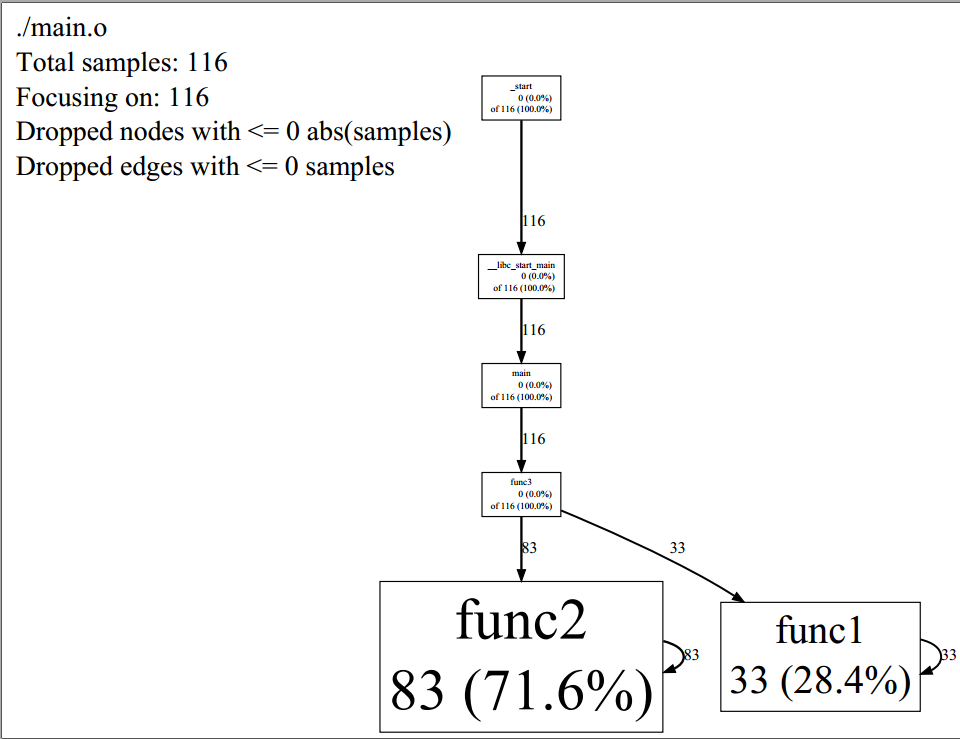
图形风格的结果由节点和有向边组成,
每个节点代表一个函数,节点数据格式:
Class Name
Method Name
local (percentage)
of cumulative (percentage)
local时间是函数直接执行的指令所消耗的CPU时间(包括内联函数)。性能分析通过抽样方法完成,默认是1秒100个样本,一个样本是10毫秒,即时间单位是10毫秒;cumulative时间是local时间与其他函数调用的总和;如果cumulative时间与local时间相同,则不打印cumulative时间项。
有向边:调用者指向被调用者,有向边上的时间表示被调用者所消耗的CPU时间
如果生成pdf时报错:ps2pdf command not found,那么要安装Ghostscript。
下载地址:
http://www.linuxfromscratch.org/blfs/view/cvs/pst/gs.html
百度地址:
http://pan.baidu.com/s/1hsP2N56#list/path=%2F
安装的时间会很长,要耐心等待。
文本风格输出结果
Total: 116 samples
83 71.6% 71.6% 83 71.6% func2
33 28.4% 100.0% 33 28.4% func1
0 0.0% 100.0% 116 100.0% __libc_start_main
0 0.0% 100.0% 116 100.0% _start
0 0.0% 100.0% 116 100.0% func3
0 0.0% 100.0% 116 100.0% main
一共6列,分别代表的意思是:
分析样本数量(不包含其他函数调用)
分析样本百分比(不包含其他函数调用)
目前为止的分析样本百分比(不包含其他函数调用)
分析样本数量(包含其他函数调用)
分析样本百分比(包含其他函数调用)
函数名
注意:
gperftools需要程序正常退出才能向prof文件打印数据,所以当程序无法退出时,得要发送信号给进程,在接到信号后,调用ProfilerStop();函数,才能打印出数据。如下所示:
void signal_handler(int signo) { signal(signo, signal_handler); INFO_LOG("recv signal[%d]", signo); switch(signo) { case SIGTERM: //程序自己退出,或shell里调用kill缺省该进程。该信号可以被阻塞,或被处理 //可以在这里做一些程序退出前的最后处理工作 ProfilerStop(); INFO_LOG("Process recieve SIGTERM"); break; } exit(0); } //主函数 signal(SIGTERM, &signal_handler);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
用valgrind的callgrind工具也可以进行分析程序性能。
分享一个教程:http://www.tuicool.com/articles/nUZJBb2
posted @
2018-07-13 13:47 长戟十三千 阅读(1307) |
评论 (0) |
编辑 收藏linux登录后有时候会出现-bash-4.1$
造成这样的原因:
与这个用户有关环境变量没了,有关的文件被删除。也就是用户的家目录下面 .bash_profile .bashrc 被删除。
解决办法:
##首先切换到故障用户 su - test ##复制对应的文件(不要用root直接复制,否则复制过去的东西属主,数组都是root的) -bash-4.1$ cp /etc/skel/.bash* ~ ##(/etc/skel 新用户老家的样子,所以从这里复制) -bash-4.1$ ls -la total 24 drwx------ 2 test test 4096 Nov 5 14:51 . drwxr-xr-x. 6 root root 4096 Nov 5 14:44 .. -rw------- 1 test test 21 Nov 5 14:45 .bash_history -rw-r--r-- 1 test test 18 Nov 5 14:51 .bash_logout -rw-r--r-- 1 test test 176 Nov 5 14:51 .bash_profile -rw-r--r-- 1 test test 124 Nov 5 14:51 .bashrc -bash-4.1$ logout [root@xxxx ~]# su - test [test@xxxx ~]$
搞定了
posted @
2018-07-06 20:00 长戟十三千 阅读(260) |
评论 (0) |
编辑 收藏