Linux 的虚拟内存管理有几个关键概念:
1、每个进程都有独立的虚拟地址空间,进程访问的虚拟地址并不是真正的物理地址;
2、虚拟地址可通过每个进程上的页表(在每个进程的内核虚拟地址空间)与物理地址进行映射,获得真正物理地址;
3、如果虚拟地址对应物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
基于以上认识,进行了如下分析:
一、Linux 虚拟地址空间如何分布?
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别为:
1、只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
2、数据段:保存全局变量、静态变量的空间;
3、堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
4、文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
5、栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
6、内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
下图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。
32 位系统有4G 的地址空间::
其中 0x08048000~0xbfffffff 是用户空间,0xc0000000~0xffffffff 是内核空间,包括内核代码和数据、与进程相关的数据结构(如页表、内核栈)等。另外,%esp 执行栈顶,往低地址方向变化;brk/sbrk 函数控制堆顶_edata往高地址方向变化。
64位系统结果怎样呢? 64 位系统是否拥有 2^64 的地址空间吗?
事实上, 64 位系统的虚拟地址空间划分发生了改变:
1、地址空间大小不是2^32,也不是2^64,而一般是2^48。因为并不需要 2^64 这么大的寻址空间,过大空间只会导致资源的浪费。64位Linux一般使用48位来表示虚拟地址空间,40位表示物理地址,
这可通过 /proc/cpuinfo 来查看
address sizes : 40 bits physical, 48 bits virtual
2、其中,0x0000000000000000~0x00007fffffffffff 表示用户空间, 0xFFFF800000000000~ 0xFFFFFFFFFFFFFFFF 表示内核空间,共提供 256TB(2^48) 的寻址空间。
这两个区间的特点是,第 47 位与 48~63 位相同,若这些位为 0 表示用户空间,否则表示内核空间。
3、用户空间由低地址到高地址仍然是只读段、数据段、堆、文件映射区域和栈;
二、malloc和free是如何分配和释放内存?
如何查看进程发生缺页中断的次数?
用ps -o majflt,minflt -C program命令查看。
majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
发成缺页中断后,执行了那些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
1、检查要访问的虚拟地址是否合法
2、查找/分配一个物理页
3、填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
4、建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
内存分配的原理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
下面以一个例子来说明内存分配的原理:
情况一、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
1、进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。
其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。
_edata指针(glibc里面定义)指向数据段的最高地址。
2、进程调用A=malloc(30K)以后,内存空间如图2:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
你可能会问:只要把_edata+30K就完成内存分配了?
事实是这样的,_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3、进程调用B=malloc(40K)以后,内存空间如图3。
情况二、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:
4、进程调用C=malloc(200K)以后,内存空间如图4:
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为::
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5、进程调用D=malloc(100K)以后,内存空间如图5;
6、进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。
7、进程调用free(B)以后,如图7所示:
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8、进程调用free(D)以后,如图8所示:
B和D连接起来,变成一块140K的空闲内存。
9、默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
三、既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢?
既然堆内碎片不能直接释放,导致疑似“内存泄露”问题,为什么 malloc 不全部使用 mmap 来实现呢(mmap分配的内存可以会通过 munmap 进行 free ,实现真正释放)?而是仅仅对于大于 128k 的大块内存才使用 mmap ?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。 因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, <SIZE>) 来修改这个临界值。
四、如何查看进程的缺页中断信息?
可通过以下命令查看缺页中断信息
ps -o majflt,minflt -C <program_name>
ps -o majflt,minflt -p <pid>
其中:: majflt 代表 major fault ,指大错误;
minflt 代表 minor fault ,指小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
其中 majflt 与 minflt 的不同是::
majflt 表示需要读写磁盘,可能是内存对应页面在磁盘中需要load 到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。
五、C语言的内存分配方式与malloc
C语言跟内存分配方式
(1) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(2) 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运
算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3)从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多
C语言跟内存申请相关的函数主要有 alloc,calloc,malloc,free,realloc,sbrk等.其中alloc是向栈申请内存,因此无需释放. malloc分配的内存是位于堆中的,并且没有初始化内存的内容,因此基本上malloc之后,调用函数memset来初始化这部分的内存空间.calloc则将初始化这部分的内存,设置为0. 而realloc则对malloc申请的内存进行大小的调整.申请的内存最终需要通过函数free来释放. 而sbrk则是增加数据段的大小;
malloc/calloc/free基本上都是C函数库实现的,跟OS无关.C函数库内部通过一定的结构来保存当前有多少可用内存.如果程序 malloc的大小超出了库里所留存的空间,那么将首先调用brk系统调用来增加可用空间,然后再分配空间.free时,释放的内存并不立即返回给os, 而是保留在内部结构中. 可以打个比方: brk类似于批发,一次性的向OS申请大的内存,而malloc等函数则类似于零售,满足程序运行时的要求.这套机制类似于缓冲.
使用这套机制的原因: 系统调用不能支持任意大小的内存分配(有的系统调用只支持固定大小以及其倍数的内存申请,这样的话,对于小内存的分配会造成浪费; 系统调用申请内存代价昂贵,涉及到用户态和核心态的转换.
函数malloc()和calloc()都可以用来分配动态内存空间,但两者稍有区别。
在Linux系统上,程序被载入内存时,内核为用户进程地址空间建立了代码段、数据段和堆栈段,在数据段与堆栈段之间的空闲区域用于动态内存分配。
内核数据结构mm_struct中的成员变量start_code和end_code是进程代码段的起始和终止地址,start_data和 end_data是进程数据段的起始和终止地址,start_stack是进程堆栈段起始地址,start_brk是进程动态内存分配起始地址(堆的起始 地址),还有一个 brk(堆的当前最后地址),就是动态内存分配当前的终止地址。
C语言的动态内存分配基本函数是malloc(),在Linux上的基本实现是通过内核的brk系统调用。brk()是一个非常简单的系统调用,只是简单地改变mm_struct结构的成员变量brk的值。
mmap系统调用实现了更有用的动态内存分配功能,可以将一个磁盘文件的全部或部分内容映射到用户空间中,进程读写文件的操作变成了读写内存的操作。在 linux/mm/mmap.c文件的do_mmap_pgoff()函数,是mmap系统调用实现的核心。do_mmap_pgoff()的代码,只是新建了一个vm_area_struct结构,并把file结构的参数赋值给其成员变量m_file,并没有把文件内容实际装入内存。
Linux内存管理的基本思想之一,是只有在真正访问一个地址的时候才建立这个地址的物理映射。
————————————————
版权声明:本文为CSDN博主「gfgdsg」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gfgdsg/article/details/42709943
posted @
2019-12-25 15:36 长戟十三千 阅读(493) |
评论 (0) |
编辑 收藏
摘要: brk() , sbrk() 的声明如下:#include <unistd.h>int brk(void *addr);void *sbrk(intptr_t increment);这两个函数都用来改变 "program break" (程序间断点)的位置,这个位置可参考下图:如 man 里说的:引用brk() and sbrk() chan...
阅读全文
posted @
2019-12-25 15:25 长戟十三千 阅读(535) |
评论 (0) |
编辑 收藏在windows平台,有一个简单的方法来追踪调用函数的堆栈,就是利用函数CaptureStackBackTrace,但是这个函数不能得到具体调用函数的名称,只能得到地址,当然我们可以通过反汇编的方式通过地址得到函数的名称,以及具体调用的反汇编代码,但是对于有的时候我们需要直接得到函数的名称,这个时候据不能使用这个方法,对于这种需求我们可以使用函数:SymInitialize、StackWalk、SymGetSymFromAddr、SymGetLineFromAddr、SymCleanup。
原理
基本上所有高级语言都有专门为函数准备的堆栈,用来存储函数中定义的变量,在C/C++中在调用函数之前会保存当前函数的相关环境,在调用函数时首先进行参数压栈,然后call指令将当前eip的值压入堆栈中,然后调用函数,函数首先会将自身堆栈的栈底地址保存在ebp中,然后抬高esp并初始化本身的堆栈,通过多次调用最终在堆栈段形成这样的布局
这里对函数的原理做简单的介绍,有兴趣的可以看我的另一篇关于C函数原理讲解的博客,点击这里跳转 VC++编译器在编译时对函数名称与地址都有详细的记录,编译出来的程序都有一个符号常量表,将符号常量与它对应的地址形成映射,在搜索时首先根据这些堆栈环境找到对应地址,然后根据地址在符号常量表中,找到具体调用的信息,这是一个很复杂的工程,需要对编译原理和汇编有很强的基础,幸运的是,如今这些工作不需要程序员自己去做,windows帮助我们分配了一组API,在编写程序时只需要调用API即可
函数说明
SymInitialize:这个函数主要用作初始化相关环境。 SymCleanup:清楚这个初始化的相关环境,在调用SymInitialize之后需要调用SymCleanup,进行释放资源的操作 StackWalk:程序的功能主要由这个函数实现,函数会从初始化时的堆栈顶开始向下查找下一个堆栈的信息,原型如下:
BOOL WINAPI StackWalk( __in DWORD MachineType, //机器类型现在一般是intel的x86系列,这个时候填入IMAGE_FILE_MACHINE_I386 __in HANDLE hProcess, //追踪的进程句柄 __in HANDLE hThread, //追踪的线程句柄 __in_out LPSTACKFRAME StackFrame, //记录的追踪到的堆栈信息 __in_out PVOID ContextRecord, //记录当前的线程环境 __in PREAD_PROCESS_MEMORY_ROUTINE ReadMemoryRoutine, __in PFUNCTION_TABLE_ACCESS_ROUTINE FunctionTableAccessRoutine, __in PGET_MODULE_BASE_ROUTINE GetModuleBaseRoutine, __in PTRANSLATE_ADDRESS_ROUTINE TranslateAddress //后面的四个参数都是回掉函数,有系统自行调用,而且这些函数都是定义好的,只需要填入相应的函数名称 );
需要注意的一点是,在首次调用该函数时需要对StackFrame中的AddrPC、AddrFrame、AddrStack这三个成员进行初始化,填入相关值,以便函数从此处线程堆栈的栈顶进行搜索,否则调用函数将失败,具体如何填写请看MSDN。
SymGetSymFromAddr:根据获取到的函数地址得到函数名称、堆栈大小等信息,这个函数的原型如下: BOOL WINAPI SymGetSymFromAddr( __in HANDLE hProcess, //进程句柄 __in DWORD Address, //函数地址 __out PDWORD Displacement, //返回该符号常量的位移或者填入NULL,不获取此值 __out PIMAGEHLP_SYMBOL Symbol//返回堆栈信息 );
SymGetLineFromAddr:根据得到的地址值,获取调用函数的相关信息。主要记录是在哪个文件,哪行调用了该函数,下面是函数原型:
BOOL WINAPI SymGetLineFromAddr( __in HANDLE hProcess, __in DWORD dwAddr, __out PDWORD pdwDisplacement, __out PIMAGEHLP_LINE Line );
它参数的含义与SymGetSymFromAddr,相同。 通过上面对函数的说明,我们可以知道,为了追踪函数调用的详细信息,大致步骤如下: 1. 首先调用函数SymInitialize进行相关的初始化工作。 2. 填充结构体StackFrame的相关信息,确定从何处开始追踪。 3. 循环调用StackWalk函数,从指定位置,向下一直追踪到最后。 4. 每次将获取的地址分别传入SymGetSymFromAddr、SymGetLineFromAddr,得到函数的详细信息 5. 调用SymCleanup,结束追踪 但是需要注意的一点是,函数StackWalk会顺着线程堆栈进行查找,如果在调用之前,某个函数已经返回了,它的堆栈被回收,那么函数StackWalk自然不会追踪到该函数的调用。
具体实现
void InitTrack() { g_hHandle = GetCurrentProcess(); SymInitialize(g_hHandle, NULL, TRUE); } void StackTrack() { g_hThread = GetCurrentThread(); STACKFRAME sf = { 0 }; sf.AddrPC.Offset = g_context.Eip; sf.AddrPC.Mode = AddrModeFlat; sf.AddrFrame.Offset = g_context.Ebp; sf.AddrFrame.Mode = AddrModeFlat; sf.AddrStack.Offset = g_context.Esp; sf.AddrStack.Mode = AddrModeFlat; typedef struct tag_SYMBOL_INFO { IMAGEHLP_SYMBOL symInfo; TCHAR szBuffer[MAX_PATH]; } SYMBOL_INFO, *LPSYMBOL_INFO; DWORD dwDisplament = 0; SYMBOL_INFO stack_info = { 0 }; PIMAGEHLP_SYMBOL pSym = (PIMAGEHLP_SYMBOL)&stack_info; pSym->SizeOfStruct = sizeof(IMAGEHLP_SYMBOL); pSym->MaxNameLength = sizeof(SYMBOL_INFO) - offsetof(SYMBOL_INFO, symInfo.Name); IMAGEHLP_LINE ImageLine = { 0 }; ImageLine.SizeOfStruct = sizeof(IMAGEHLP_LINE); while (StackWalk(IMAGE_FILE_MACHINE_I386, g_hHandle, g_hThread, &sf, &g_context, NULL, SymFunctionTableAccess, SymGetModuleBase, NULL)) { SymGetSymFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, pSym); SymGetLineFromAddr(g_hHandle, sf.AddrPC.Offset, &dwDisplament, &ImageLine); printf("当前调用函数 : %08x+%s(FILE[%s]LINE[%d])\n", pSym->Address, pSym->Name, ImageLine.FileName, ImageLine.LineNumber); } } void UninitTrack() { SymCleanup(g_hHandle); }测试程序如下:
void func1() { OPEN_STACK_TRACK; } void func2() { func1(); } void func3() { func2(); } void func4() { printf("hello\n"); } int _tmain(int argc, TCHAR* argv[]) { func4(); func3(); func3(); return 0; }OPEN_STACK_TRACK是一个宏,它的定义如下:
#define OPEN_STACK_TRACK\ HANDLE hThread = GetCurrentThread();\ GetThreadContext(hThread, &g_context);\ __asm{call $ + 5}\ __asm{pop eax}\ __asm{mov g_context.Eip, eax}\ __asm{mov g_context.Ebp, ebp}\ __asm{mov g_context.Esp, esp}\ InitTrack();\ StackTrack();\ UninitTrack();这个程序需要注意以下几点: 1. 如果想要追踪所有调用的函数,需要将这个宏放置到最后调用的位置,当然前提是此时之前被调函数的堆栈仍然存在。当然可以在调用前简单的计算,找出在哪个位置是所有函数都没有调用完成的,不过这样可能就与程序的初衷相悖,毕竟程序本身就是为了获取堆栈的调用信息。。。。 2. IMAGEHLP_SYMBOL的结构体中关于Name的成员,只有一个字节,而函数SymGetSymFromAddr在填入值时是没有关心这个实际大小,它只是简单的填充,这就造成了缓冲区溢出的情况,为了避免我们需要在Name后面额外给一定大小的缓冲区,用来接收数据,这也就是我们定义这个结构体SYMBOL_INFO的原因。另外IMAGEHLP_SYMBOL中的MaxNameLength成员是指Name的最大长度,需要根据给定的缓冲区,进行计算。 3. 从测试程序来看,在进行追踪时func4已经调用完成,而我们在获取线程的运行时环境g_context时函数GetThreadContext,也在堆栈中,最终得到的结果中必然包含GetThreadContext的调用信息,如果想去掉这个信息,只需要修改获得信息的值,既然函数StackWalk是根据堆栈进行追踪,那么只需要修改对应堆栈的信息即可,需要修改eip 、ebp、esp的值,关于esp ebp的值很好修改,可以在对应函数中esp ebp这些寄存器的值,而eip的值就不那么好获取,本生利用mov指令得到eip的值它也是指令,会改变eip的值,从而造成获取到的eip的值不准确,所以我们利用call指令,先保存当前eip的值到堆栈,然后再从堆栈中取出。call指令的实质是 push eip和jmp addr指令的组合,并不一定非要调用函数。call指令的大小为5个字节,所以call $ + 5表示先保存eip在跳转到它的下一跳指令处。这样就可以有效的避免检测到GetThreadContext中的相关函数调用
posted @
2019-12-19 12:39 长戟十三千 阅读(643) |
评论 (0) |
编辑 收藏
摘要: 文档名称:Windows NT Stack Trace文档维护:welfear创建时间:2009年6月7日更新内容:对StackWalk的分析(2009.6.17)更新内容:对x64栈的分析(2009.6.19) 在系统软件开发中有时会有得到函数调用者的信息的需要,为此WindowsNT专门提供了调用RtlGetCallerAddress为内核开发者使用,但它并没有公开所以也就不能为驱动...
阅读全文
posted @
2019-12-19 12:34 长戟十三千 阅读(461) |
评论 (0) |
编辑 收藏取模
最简单的hash算法
targetServer = serverList[hash(key) % serverList.size]
直接用key的hash值(计算key的hash值的方法可以自由选择,比如算法CRC32、MD5,甚至本地hash系统,如Java的hashcode)模上server总数来定位目标server。这种算法不仅简单,而且具有不错的随机分布特性。
但是问题也很明显,server总数不能轻易变化。因为如果增加/减少memcached server的数量,对原先存储的所有key的后续查询都将定位到别的server上,导致所有的cache都不能被命中而失效。
一致性hash
为了解决这个问题,需要采用一致性hash算法(consistent hash)
相对于取模的算法,一致性hash算法除了计算key的hash值外,还会计算每个server对应的hash值,然后将这些hash值映射到一个有限的值域上(比如0~2^32)。通过寻找hash值大于hash(key)的最小server作为存储该key数据的目标server。如果找不到,则直接把具有最小hash值的server作为目标server。
为了方便理解,可以把这个有限值域理解成一个环,值顺时针递增。

如上图所示,集群中一共有5个memcached server,已通过server的hash值分布到环中。
如果现在有一个写入cache的请求,首先计算x=hash(key),映射到环中,然后从x顺时针查找,把找到的第一个server作为目标server来存储cache,如果超过了2^32仍然找不到,则命中第一个server。比如x的值介于A~B之间,那么命中的server节点应该是B节点

可以看到,通过这种算法,对于同一个key,存储和后续的查询都会定位到同一个memcached server上。
那么它是怎么解决增/删server导致的cache不能命中的问题呢?
假设,现在增加一个server F,如下图
此时,cache不能命中的问题仍然存在,但是只存在于B~F之间的位置(由C变成了F),其他位置(包括F~C)的cache的命中不受影响(删除server的情况类似)。尽管仍然有cache不能命中的存在,但是相对于取模的方式已经大幅减少了不能命中的cache数量。
虚拟节点
但是,这种算法相对于取模方式也有一个缺陷:当server数量很少时,很可能他们在环中的分布不是特别均匀,进而导致cache不能均匀分布到所有的server上。
posted @
2019-12-18 15:42 长戟十三千 阅读(2137) |
评论 (0) |
编辑 收藏背景
前几天,发了一条如下的微博 (关于C/C++ Volatile关键词的使用建议):

此微博,引发了朋友们的大量讨论:赞同者有之;批评者有之;当然,更多的朋友,是希望我能更详细的解读C/C++ Volatile关键词,来佐证我的微博观点。而这,正是我写这篇博文的初衷:本文,将详细分析C/C++ Volatile关键词的功能 (有多种功能)、Volatile关键词在多线程编程中存在的问题、Volatile关键词与编译器/CPU的关系、C/C++ Volatile与Java Volatile的区别,以及Volatile关键词的起源,希望对大家更好的理解、使用C/C++ Volatile,有所帮助。
Volatile,词典上的解释为:易失的;易变的;易挥发的。那么用这个关键词修饰的C/C++变量,应该也能够体现出”易变”的特征。大部分人认识Volatile,也是从这个特征出发,而这也是本文揭秘的C/C++ Volatile的第一个特征。
Volatile:易变的
在介绍C/C++ Volatile关键词的”易变”性前,先让我们看看以下的两个代码片段,以及他们对应的汇编指令 (以下用例的汇编代码,均为VS 2008编译出来的Release版本):

与测试用例一唯一的不同之处,是变量a被设置为volatile属性,一个小小的变化,带来的是汇编代码上很大的变化。a = fn(c)执行后,寄存器ecx中的a,被写回内存:mov dword ptr [esp+0Ch], ecx。然后,在执行b = a + 1;语句时,变量a有重新被从内存中读取出来:mov eax, dword ptr [esp + 0Ch],而不再直接使用寄存器ecx中的内容。
从以上的两个用例,就可以看出C/C++ Volatile关键词的第一个特性:易变性。所谓的易变性,在汇编层面反映出来,就是两条语句,下一条语句不会直接使用上一条语句对应的volatile变量的寄存器内容,而是重新从内存中读取。volatile的这个特性,相信也是大部分朋友所了解的特性。
在了解了C/C++ Volatile关键词的”易变”特性之后,再让我们接着继续来剖析Volatile的下一个特性:”不可优化”特性。
与前面介绍的”易变”性类似,关于C/C++ Volatile关键词的第二个特性:”不可优化”性,也通过两个对比的代码片段来说明:
测试用例三:非Volatile变量

在这个用例中,非volatile变量a,b,c全部被编译器优化掉了 (optimize out),因为编译器通过分析,发觉a,b,c三个变量是无用的,可以进行常量替换。最后的汇编代码相当简介,高效率。
测试用例四:Volatile变量

测试用例四,与测试用例三类似,不同之处在于,a,b,c三个变量,都是volatile变量。这个区别,反映到汇编语言中,就是三个变量仍旧存在,需要将三个变量从内存读入到寄存器之中,然后再调用printf()函数。
从测试用例三、四,可以总结出C/C++ Volatile关键词的第二个特性:“不可优化”特性。volatile告诉编译器,不要对我这个变量进行各种激进的优化,甚至将变量直接消除,保证程序员写在代码中的指令,一定会被执行。相对于前面提到的第一个特性:”易变”性,”不可优化”特性可能知晓的人会相对少一些。但是,相对于下面提到的C/C++ Volatile的第三个特性,无论是”易变”性,还是”不可优化”性,都是Volatile关键词非常流行的概念。
Volatile:顺序性
C/C++ Volatile关键词前面提到的两个特性,让Volatile经常被解读为一个为多线程而生的关键词:一个全局变量,会被多线程同时访问/修改,那么线程内部,就不能假设此变量的不变性,并且基于此假设,来做一些程序设计。当然,这样的假设,本身并没有什么问题,多线程编程,并发访问/修改的全局变量,通常都会建议加上Volatile关键词修饰,来防止C/C++编译器进行不必要的优化。但是,很多时候,C/C++ Volatile关键词,在多线程环境下,会被赋予更多的功能,从而导致问题的出现。
回到本文背景部分我的那篇微博,我的这位朋友,正好犯了一个这样的问题。其对C/C++ Volatile关键词的使用,可以抽象为下面的伪代码:

这段伪代码,声明另一个Volatile的flag变量。一个线程(Thread1)在完成一些操作后,会修改这个变量。而另外一个线程(Thread2),则不断读取这个flag变量,由于flag变量被声明了volatile属性,因此编译器在编译时,并不会每次都从寄存器中读取此变量,同时也不会通过各种激进的优化,直接将if (flag == true)改写为if (false == true)。只要flag变量在Thread1中被修改,Thread2中就会读取到这个变化,进入if条件判断,然后进入if内部进行处理。在if条件的内部,由于flag == true,那么假设Thread1中的something操作一定已经完成了,在基于这个假设的基础上,继续进行下面的other things操作。
通过将flag变量声明为volatile属性,很好的利用了本文前面提到的C/C++ Volatile的两个特性:”易变”性;”不可优化”性。按理说,这是一个对于volatile关键词的很好应用,而且看到这里的朋友,也可以去检查检查自己的代码,我相信肯定会有这样的使用存在。
但是,这个多线程下看似对于C/C++ Volatile关键词完美的应用,实际上却是有大问题的。问题的关键,就在于前面标红的文字:由于flag = true,那么假设Thread1中的something操作一定已经完成了。flag == true,为什么能够推断出Thread1中的something一定完成了?其实既然我把这作为一个错误的用例,答案是一目了然的:这个推断不能成立,你不能假设看到flag == true后,flag = true;这条语句前面的something一定已经执行完成了。这就引出了C/C++ Volatile关键词的第三个特性:顺序性。
同样,为了说明C/C++ Volatile关键词的”顺序性”特征,下面给出三个简单的用例 (注:与上面的测试用例不同,下面的三个用例,基于的是Linux系统,使用的是”GCC: (Debian 4.3.2-1.1) 4.3.2″):
测试用例五:非Volatile变量

一个简单的示例,全局变量A,B均为非volatile变量。通过gcc O2优化进行编译,你可以惊奇的发现,A,B两个变量的赋值顺序被调换了!!!在对应的汇编代码中,B = 0语句先被执行,然后才是A = B + 1语句被执行。
在这里,我先简单的介绍一下C/C++编译器最基本优化原理:保证一段程序的输出,在优化前后无变化。将此原理应用到上面,可以发现,虽然gcc优化了A,B变量的赋值顺序,但是foo()函数的执行结果,优化前后没有发生任何变化,仍旧是A = 1;B = 0。因此这么做是可行的。
测试用例六:一个Volatile变量

此测试,相对于测试用例五,最大的区别在于,变量B被声明为volatile变量。通过查看对应的汇编代码,B仍旧被提前到A之前赋值,Volatile变量B,并未阻止编译器优化的发生,编译后仍旧发生了乱序现象。
如此看来,C/C++ Volatile变量,与非Volatile变量之间的操作,是可能被编译器交换顺序的。
通过此用例,已经能够很好的说明,本章节前面,通过flag == true,来假设something一定完成是不成立的。在多线程下,如此使用volatile,会产生很严重的问题。但是,这不是终点,请继续看下面的测试用例七。
测试用例七:两个Volatile变量

同时将A,B两个变量都声明为volatile变量,再来看看对应的汇编。奇迹发生了,A,B赋值乱序的现象消失。此时的汇编代码,与用户代码顺序高度一直,先赋值变量A,然后赋值变量B。
如此看来,C/C++ Volatile变量间的操作,是不会被编译器交换顺序的。
happens-before
通过测试用例六,可以总结出:C/C++ Volatile变量与非Volatile变量间的操作顺序,有可能被编译器交换。因此,上面多线程操作的伪代码,在实际运行的过程中,就有可能变成下面的顺序:

由于Thread1中的代码执行顺序发生变化,flag = true被提前到something之前进行,那么整个Thread2的假设全部失效。由于something未执行,但是Thread2进入了if代码段,整个多线程代码逻辑出现问题,导致多线程完全错误。
细心的读者看到这里,可能要提问,根据测试用例七,C/C++ Volatile变量间,编译器是能够保证不交换顺序的,那么能不能将something中所有的变量全部设置为volatile呢?这样就阻止了编译器的乱序优化,从而也就保证了这个多线程程序的正确性。
针对此问题,很不幸,仍旧不行。将所有的变量都设置为volatile,首先能够阻止编译器的乱序优化,这一点是可以肯定的。但是,别忘了,编译器编译出来的代码,最终是要通过CPU来执行的。目前,市场上有各种不同体系架构的CPU产品,CPU本身为了提高代码运行的效率,也会对代码的执行顺序进行调整,这就是所谓的CPU Memory Model (CPU内存模型)。关于CPU的内存模型,可以参考这些资料:Memory Ordering From Wiki;Memory Barriers Are Like Source Control Operations From Jeff Preshing;CPU Cache and Memory Ordering From 何登成。下面,是截取自Wiki上的一幅图,列举了不同CPU架构,可能存在的指令乱序。

从图中可以看到,X86体系(X86,AMD64),也就是我们目前使用最广的CPU,也会存在指令乱序执行的行为:StoreLoad乱序,读操作可以提前到写操作之前进行。
因此,回到上面的例子,哪怕将所有的变量全部都声明为volatile,哪怕杜绝了编译器的乱序优化,但是针对生成的汇编代码,CPU有可能仍旧会乱序执行指令,导致程序依赖的逻辑出错,volatile对此无能为力。
其实,针对这个多线程的应用,真正正确的做法,是构建一个happens-before语义。关于happens-before语义的定义,可参考文章:The Happens-Before Relation。下面,用图的形式,来展示happens-before语义:

如图所示,所谓的happens-before语义,就是保证Thread1代码块中的所有代码,一定在Thread2代码块的第一条代码之前完成。当然,构建这样的语义有很多方法,我们常用的Mutex、Spinlock、RWLock,都能保证这个语义 (关于happens-before语义的构建,以及为什么锁能保证happens-before语义,以后专门写一篇文章进行讨论)。但是,C/C++ Volatile关键词不能保证这个语义,也就意味着C/C++ Volatile关键词,在多线程环境下,如果使用的不够细心,就会产生如同我这里提到的错误。
小结
C/C++ Volatile关键词的第三个特性:”顺序性”,能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。Volatile变量与非Volatile变量的顺序,编译器不保证顺序,可能会进行乱序优化。同时,C/C++ Volatile关键词,并不能用于构建happens-before语义,因此在进行多线程程序设计时,要小心使用volatile,不要掉入volatile变量的使用陷阱之中。
posted @
2019-12-02 18:25 长戟十三千 阅读(214) |
评论 (0) |
编辑 收藏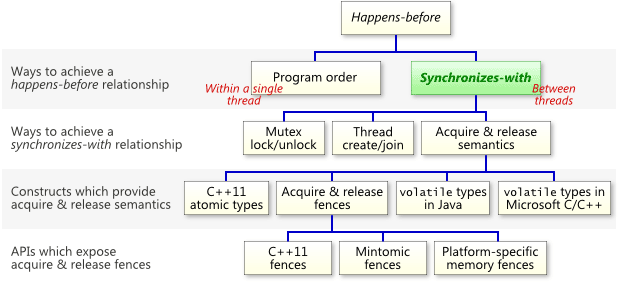
一. 内存屏障 Memory Barrior
1.1 重排序
同步的目的是保证不同执行流对共享数据并发操作的一致性。在单核时代,使用原子变量就很容易达成这一目的。甚至因为CPU的一些访存特性,对某些内存对齐数据的读或写也具有原子的特性。但在多核架构下即使操作是原子的,仍然会因为其他原因导致同步失效。
首先是现代编译器的代码优化和编译器指令重排可能会影响到代码的执行顺序。
其次还有指令执行级别的乱序优化,流水线、乱序执行、分支预测都可能导致处理器次序(Process Ordering,机器指令在CPU实际执行时的顺序)和程序次序(Program Ordering,程序代码的逻辑执行顺序)不一致。可惜不影响语义依旧只能是保证单核指令序列间,单核时代CPU的Self-Consistent特性在多核时代已不存在(Self-Consistent即重排原则:有数据依赖不会进行重排,单核最终结果肯定一致)。
除此还有硬件级别Cache一致性(Cache Coherence)带来的问题:CPU架构中传统的MESI协议中有两个行为的执行成本比较大。一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。如图:
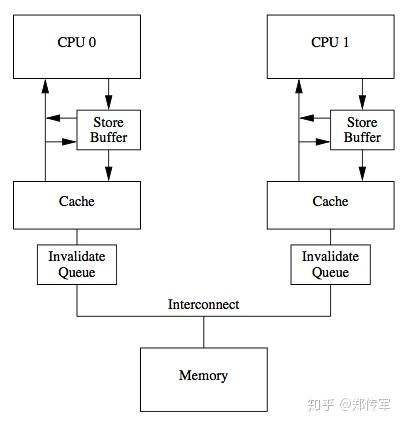
当一个核心在Invalid状态进行写入时,首先会给其它CPU核发送Invalid消息,然后把当前写入的数据写入到Store Buffer中。然后异步在某个时刻真正的写入到Cache Line中。当前CPU核如果要读Cache Line中的数据,需要先扫描Store Buffer之后再读取Cache Line(Store-Buffer Forwarding)。但是此时其它CPU核是看不到当前核的Store Buffer中的数据的,要等到Store Buffer中的数据被刷到了Cache Line之后才会触发失效操作。
而当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态。和Store Buffer不同的是,当前CPU核心使用Cache时并不扫描Invalidate Queue部分,所以可能会有极短时间的脏读问题。这里的Store Buffer和Invalidate Queue的说法是针对一般的SMP架构来说的,不涉及具体架构。
内存对于缓存更新策略,要区分Write-Through和Write-Back两种策略。前者更新内容直接写内存并不同时更新Cache,但要置Cache失效,后者先更新Cache,随后异步更新内存。通常X86 CPU更新内存都使用Write-Back策略。
1.2 编译器屏障 Compiler Barrior
/* The "volatile" is due to gcc bugs */ #define barrier() __asm__ __volatile__("": : :"memory")
阻止编译器重排,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
1.3 CPU屏障 CPU Barrior
CPU级别内存屏障其作用有两个:
- 防止指令之间的重排序
- 保证数据的可见性
指令重排中Load和Store两种操作会有Load-Store、Store-Load、Load-Load、Store-Store这四种可能的乱序结果。
Intel为此提供三种内存屏障指令:
- sfence ,实现Store Barrior 会将store buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
- lfence ,实现Load Barrior 会将invalidate queue失效,强制读取入L1 cache中,而且lfence之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
- mfence ,实现Full Barrior 同时刷新store buffer和invalidate queue,保证了mfence前后的读写操作的顺序,同时要求mfence之后写操作结果全局可见之前,mfence之前写操作结果全局可见;
- lock 用来修饰当前指令操作的内存只能由当前CPU使用,若指令不操作内存仍然由用,因为这个修饰会让指令操作本身原子化,而且自带Full Barrior效果;还有指令比如IO操作的指令、exch等原子交换的指令,任何带有lock前缀的指令以及CPUID等指令都有内存屏障的作用。
X86-64下仅支持一种指令重排:Store-Load ,即读操作可能会重排到写操作前面,同时不同线程的写操作并没有保证全局可见,例子见《Intel® 64 and IA-32 Architectures Software Developer’s Manual》手册8.6.1、8.2.3.7节。要注意的是这个问题只能用mfence解决,不能靠组合sfence和lfence解决。(用sfence+lfence组合仅可以解决重排问题,但不能解决全局可见性问题,简单理解不如视为sfence和lfence本身也能乱序重拍)
X86-64一般情况根本不会需要使用lfence与sfence这两个指令,除非操作Write-Through内存或使用 non-temporal 指令(NT指令,属于SSE指令集),比如movntdq, movnti, maskmovq,这些指令也使用Write-Through内存策略,通常使用在图形学或视频处理,Linux编程里就需要使用GNC提供的专门的函数(例子见参考资料13:Memory part 5: What programmers can do)。
下面是GNU中的三种内存屏障定义方法,结合了编译器屏障和三种CPU屏障指令
#define lfence() __asm__ __volatile__("lfence": : :"memory") #define sfence() __asm__ __volatile__("sfence": : :"memory") #define mfence() __asm__ __volatile__("mfence": : :"memory")
代码中仍然使用lfence()与sfence()这两个内存屏障应该也是一种长远的考虑。按照Interface写代码是最保险的,万一Intel以后出一个采用弱一致模型的CPU,遗留代码出问题就不好了。目前在X86下面视为编译器屏障即可。
GCC 4以后的版本也提供了Built-in的屏障函数__sync_synchronize(),这个屏障函数既是编译屏障又是内存屏障,代码插入这个函数的地方会被安插一条mfence指令。
C++11为内存屏障提供了专门的函数std::atomic_thread_fence,方便移植统一行为而且可以配合内存模型进行设置,比如实现Acquire-release语义:
#include <atomic> std::atomic_thread_fence(std::memory_order_acquire); std::atomic_thread_fence(std::memory_order_release);
二、内存模型
2.1 Acquire与Release语义
- 对于Acquire来说,保证Acquire后的读写操作不会发生在Acquire动作之前
- 对于Release来说,保证Release前的读写操作不会发生在Release动作之后
Acquire & Release 语义保证内存操作仅在acquire和release屏障之间发生
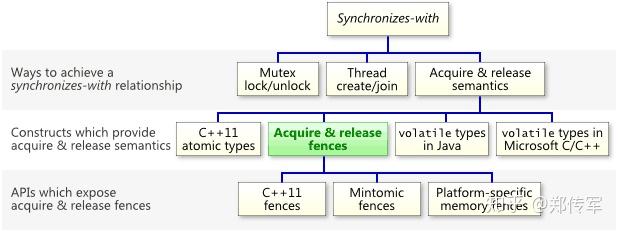
X86-64中Load读操作本身满足Acquire语义,Store写操作本身也是满足Release语义。但Store-Load操作间等于没有保护,因此仍需要靠mfence或lock等指令才可以满足到Synchronizes-with规则。
2.2 happens-before规则
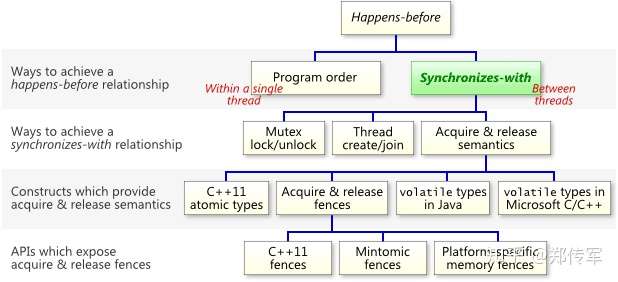
相对于Synchronizes-with规则更宽松,happens-before规则定义指令执行顺序与变量的可见性,类似偏序关系,具有可传递性,因此可以运用于并行逻辑分析。
2.3 内存一致性模型 Memory Model
内存一致性模型从程序员视角,由内存序Memory Ordering和写操作原子性Store Atomicity来定义,针对不同线程中原子操作的全局顺序:
- Strong Consistency / Sequential consistency 顺序一致性
- Release Consistency / release-acquire / release-consume
- Relaxed Consistency
C++11相应定义了6种内存模型:
- std::memory_order_seq_cst 所有读写操作不能跨过,写顺序全线程可见
- std::memory_order_acq_rel 所有读写操作不能跨过,写顺序仅同步线程间可见、std::memory_order_release 所有读写操作不能往后乱序、std::memory_order_acquire 所有读写操作不能向前乱序、std::memory_order_consume 依赖该读操作的后续读写操作不能向前乱序
- std::memory_order_relaxed 无特殊要求
三. volatile 关键字
voldatile关键字首先具有“易变性”,声明为volatile变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取。
其次具有”不可优化”性,volatile告诉编译器,不要对这个变量进行各种激进的优化,甚至将变量直接消除,保证代码中的指令一定会被执行。
最后具有“顺序性”,能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。不过要注意与非volatile变量之间的操作,还是可能被编译器重排序的。
需要注意的是其含义跟原子操作无关,比如:volatile int a; a++; 其中a++操作实际对应三条汇编指令实现”读-改-写“操作(RMW),并非原子的。
思考:bool类型是不是适合使用,不会出问题。
不同编程语言中voldatile含义与实现并不完全相同,Java语言中voldatile变量可以被看作是一种轻量级的同步,因其还附带了acuire和release语义。实际上也是从JDK5以后才通过这个措施进行完善,其volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。Java语言中有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个lock指令,就是增加一个完全的内存屏障指令,这点与C++实现并不一样。volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
Java实践中仅满足下面这些条件才应该使用volatile关键字:
- 变量写入操作不依赖变量当前值,或确保只有一个线程更新变量的值(Java可以,C++仍然不能)
- 该变量不会与其他变量一起纳入
- 变量并未被锁保护
C++中voldatile等于插入编译器级别屏障,因此并不能阻止CPU硬件级别导致的重排。C++11 中volatile语义没有任何变化,不过提供了std::atomic工具可以真正实现原子操作,而且默认加入了内存屏障(可以通过在store与load操作时设置内存模型参数进行调整,默认为std::memory_order_seq_cst)。
C++实践中推荐涉及并发问题都使用std::atomic,只有涉及特殊内存操作的时候才使用volatile关键字。这些情况通常IO相关,防止相关操作被编译器优化,也是volatile关键字发明的本意。
四、使用经验
内存屏障相关并行逻辑使用的分析顺序:线程安全、操作原子性、存储器操作顺序
C++ 使用对齐变量与mfence
C++11 使用std::atomic与std::atomic_thread_fence,先使用默认std::memory_order_seq_cst模型再进行相关优化
Java 使用volatile或atomic
一个经典的例子就是DCL双重检查加锁实现单例模式,本意是想要实现延迟初始化
@NotThreadSafe public class DoubleCheckedLock { private static Resource resoure; public static Resource getInstance() { if (resource == null) { synchronized (DoubleCheckedLock.class) { if (resource == null) resource = new Resource(); } } return resource; } }
问题在于未同步状态下读共享变量,可能获取的是中间值,比如这里获取的resource对象可能还未完全构造好。尽管JDK5以后声明为volatile可以避免这个问题,但DCL已经没有必要,因为Java可以利用JVM内部静态类装载的特点实现“延迟初始化占位类模式”来达到同样的效果。C++下面可以使用pthread_once实现。
后续:同步原语使用(锁、信号量等)、Lockfree与非阻塞操作
posted @
2019-12-02 16:49 长戟十三千 阅读(1393) |
评论 (0) |
编辑 收藏posted @
2019-12-02 16:13 长戟十三千 阅读(708) |
评论 (0) |
编辑 收藏以War3为例,启动魔兽后,首先是如何看见主机的问题:
魔兽是通过TCP/UDP协议进行数据发送的,那如何实现看到对方?我们这样:每个机器监听一个固定的UDP端口(比如6112),一旦任何机器建立主机,它就向整个局域网所有的机器的6112端口广播“我建立了主机”的信息,这样,其他机器接收到这个信息,就知道有主机建立了(广播只存在于UDP协议,使用UDP.sendto向地址255.255.255.255实现)。
来看看HF和VS平台怎么实现的:
1.挂钩UDP.Sendto,将所有广播信息(即发向地址255.255.255.255)的消息截获,然后把消息重新打包(比如{本机虚拟IP+消息数据}的形式),然后使用真正的UDP.sendto把消息转到平台服务器,服务器查看有哪些玩家是跟此玩家在同一房间,把消息传给那些玩家;平台再挂钩住接收消息用的UDP.recv From,把UDP.recvFrom的发送方地址修改为消息中的对方虚拟IP,再把数据传给真正的UDP.recvFr om。
问:万一广播信息不是建立主机而是其他的,被误截了怎么办?
答:大部分游戏包括War3的广播信息唯一的作用就是传播“建立主机”这一类需要传给所有局域网的机器的信息,就是说只有“建立主机”这一类信息会通过地址255.255.255,因此一般不会有误截发生。
实际上通过广播的信息还有主机是否人满,地图,主机是否取消建立,等信息。
其次,如何加入游戏:
魔兽在加入游戏后使用TCP协议,每个玩家对应一个连接。
在真正的局域网中,一个玩家看到和选择一个主机后点击加入,他的机器会使用TCP请求和对方连接,(地址从UDP中获得,端口是固定的6112),如果没有人满,被主机关闭等意外发生,主机就会答应此连接(使用TCP.accept),发送些数据(地图信息,其他玩家信息等),此玩家就加入了游戏,此后两机器就使用这个TCP连接通讯。
回到平台,在平台中,魔兽从UDP中获得的地址是服务器的地址啊(因为UDP信息是服务器转过来的),这样发起的TCP只能链接到服务器,怎么可能连接得上真正的玩家呢?别忘了,上面说过平台挂钩了UDP.sendTo(会把本机虚拟IP加入);挂钩了UDP.recvFrom(会把服务器这个发送方的IP改为对方虚拟IP);
接着魔兽向对方虚拟IP发起TCP.connect,可能成功吗?当然不可能,因为实际的局域网中根本没这个IP,那怎么请求连接和接受连接呢?
平台采用了这样的办法:TCP连接是靠TCP.connect发起的,平台挂钩住这个函数,把连接向服务器的地址修改为自己(即127.0.0.1或实际IP,一般用前者),然后再挂钩TCP.accept函数(此函数用来接受TCP连接),然后发送同样的连接请求由服务器转到另一台机器(即主机),根据那台机器的做法决定是否答应127.0.0.1的那个TCP.connect,(注意这个TCP.accept返回的新连接是挂钩代码创建的,挂钩的代码拥有它收到的所有数据),如果答应连接的话,是不是魔兽所有的数据就会发送到这个挂钩代码创建的连接这里了?
接着,挂钩代码把这些数据重新打包(例如{接收方机器的虚拟IP+发送数据+发送方的虚拟IP}的形式),使用UDP.sendto发到服务器,服务器从信息中获得接收方机器的虚拟IP,查找其真正的IP,并把数据发送过去,跨网的TCP发送就完成了。
(另外一台机器也按以上方法同样处理)
魔兽是游戏数据传输时基于TCP连接,此时主机作为TCP的服务端,非主机是客户端。但是没办法在Internet上实现两个非服务器主机之间的直接TCP连接(这个可以看P2P的实现原理)。那对战平台是怎么实现在Internet上通过War3的局域网模式连接对战的呢?
简单来说是如果A建了一个主机,B要进A的主机,A通过平台转发过来的消息知道B要连接主机,就在自己本地创建一个TCP的客户端,让这个客户端与war进程的服务端连接,在魔兽中就相当于有玩家B连接进A主机建立的游戏,同时B主机在自己本地创建一个TCP服务端,让War进程的TCP客户端连接到自己本地的服务端。既然都是在本地建立的TCP连接,那么怎么实现主机和非主机的游戏数据交换的呢??

从上面的图可以看出,War3主机和非主机的数据交换,其实是在两个本地模拟创建的TCPsever和TCPClient之间进行的,当主机有数据要发给非主机,先会将数据发给主机本地的TCPClient,然后对战平台会从TCPClient数据缓冲池中取出数据,通过UDP的方式,发给非主机,非主机会将UDP数据放入TCPServer的发送数据缓冲池,由它发给魔兽进程中的TCPClient,反过来一样,这样就实现了魔兽数据的完成传输,Internet上的联网对战也就实现了。
另外说一下T人挂的原理,为什么主机可以T人呢?为什么主机只是关闭本机的TCP连接就可以把远程的非主机玩家T出游戏呢?从上图我们应该可以获得答案。如果主机关闭了本地用来接受远程非主机传输的UDP信息的那个TCPClient,那么很显然,主机将不能获得这个非主机信息,远程的那个非主机也不能收到主机转发的游戏数据包了,这个时候这个非主机War3进程理所当然的认为自己与主机失去了连接,T人挂的目的也达到了。
posted @
2019-11-19 17:16 长戟十三千 阅读(672) |
评论 (0) |
编辑 收藏 转载请注明出处: http://blog.csdn.net/luotuo44/article/details/38403241
上一篇博客说到了TAILQ_QUEUE队列,它可以把多个event结构体连在一起。是一种归类方式。本文也将讲解一种将event归类、连在一起的结构:哈希结构。
哈希结构体:
哈希结构由下面几个结构体一起配合工作:
struct event_list
{
struct event *tqh_first;
struct event **tqh_last;
};
struct evmap_io {
//TAILQ_HEAD (event_list, event);
struct event_list events;
ev_uint16_t nread;
ev_uint16_t nwrite;
};
struct event_map_entry {
HT_ENTRY(event_map_entry) map_node; //next指针
evutil_socket_t fd;
union { /* This is a union in case we need to make more things that can
be in the hashtable. */
struct evmap_io evmap_io;
} ent;
};
struct event_io_map
{
//哈希表
struct event_map_entry **hth_table;
//哈希表的长度
unsigned hth_table_length;
//哈希的元素个数
unsigned hth_n_entries;
//resize 之前可以存多少个元素
//在event_io_map_HT_GROW函数中可以看到其值为hth_table_length的
//一半。但hth_n_entries>=hth_load_limit时,就会发生增长哈希表的长度
unsigned hth_load_limit;
//后面素数表中的下标值。主要是指明用到了哪个素数
int hth_prime_idx;
};
结构体event_io_map指明了哈希表的存储位置、哈希表的长度、元素个数等数据。该哈希表是使用链地址法解决冲突问题的,这一点可以从hth_talbe成员变量看到。它是一个二级指针,因为哈希表的元素是event_map_entry指针。
除了怎么解决哈希冲突外,哈希表还有一个问题要解决,那就是哈希函数。这里的哈希函数就是模(%)。用event_map_entry结构体中的fd成员值模 event_io_map结构体中的hth_table_length。
由上面那些结构体配合得到的哈希表结构如下图所示:
从上图可以看到,两个发生了冲突的哈希表元素event_map_entry用一个next指向连在一起了(链地址解决冲突)。
另外,从图或者从前面关于event_map_entry结构体的定义可以看到,它有一个evmap_io结构体。而这个evmap_io结构体又有一个struct event_list 类型的成员,而struct event_list类型就是一个TAILQ_HEAD。这正是前一篇博客说到的TAILQ_QUEUE队列的队列头。从这一点可以看到,这个哈希结构还是比较复杂的。
为什么在哈希表的元素里面,还会有一个TAILQ_QUEUE队列呢?这得由Libevent的一个特征说起。Libevent允许用同一个文件描述符fd或者信号值,调用event_new、event_add多次。所以,同一个fd或者信号值就可以对应多个event结构体了。所以这个TAILQ_QUEUE队列就是将这些具有相同fd或者信号值的多个event结构体连一起。
什么情况会使用哈希表:
有一点需要说明,那就是Libevent中的哈希表只会用于Windows系统,像遵循POSIX标准的OS是不会用到哈希表的。从下面的定义可以看到这一点。
//event-internal.h文件
#ifdef WIN32
/* If we're on win32, then file descriptors are not nice low densely packed
integers. Instead, they are pointer-like windows handles, and we want to
use a hashtable instead of an array to map fds to events.
*/
#define EVMAP_USE_HT
#endif
#ifdef EVMAP_USE_HT
#include "ht-internal.h"
struct event_map_entry;
HT_HEAD(event_io_map, event_map_entry);
#else
#define event_io_map event_signal_map
#endif
可以看到,如果是非Windows系统,那么event_io_map就会被定义成event_signal_map(这是一个很简单的结构)。而在Windows系统,那么就由HT_HEAD这个宏定义event_io_map。最后得到的event_io_map就是本文最前面所示的那样。
为什么只有在Windows系统才会使用这个哈希表呢?代码里面的注释给出了一些解释。因为在Windows系统里面,文件描述符是一个比较大的值,不适合放到event_signal_map结构中。而通过哈希(模上一个小的值),就可以变得比较小,这样就可以放到哈希表的数组中了。而遵循POSIX标准的文件描述符是从0开始递增的,一般都不会太大,适用于event_signal_map。
哈希函数:
前面说到哈希函数是 用文件描述符fd 模 哈希表的长度。实际上,并不是直接用fd,而是用一个叫hashsocket的函数将这个fd进行一些处理后,才去模 哈希表的长度。下面是hashsocket函数的实现:
//evmap.c文件
/* Helper used by the event_io_map hashtable code; tries to return a good hash
* of the fd in e->fd. */
static inline unsigned
hashsocket(struct event_map_entry *e)
{
/* On win32, in practice, the low 2-3 bits of a SOCKET seem not to
* matter. Our hashtable implementation really likes low-order bits,
* though, so let's do the rotate-and-add trick. */
unsigned h = (unsigned) e->fd;
h += (h >> 2) | (h << 30);
return h;
}
前面的event_map_entry结构体中,还有一个HT_ENTRY的宏。从名字来看,它是一个哈希表的表项。它是一个条件宏,定义如下:
//ht-internal.h文件
#ifdef HT_CACHE_HASH_VALUES
#define HT_ENTRY(type) \
struct { \
struct type *hte_next; \
unsigned hte_hash; \
}
#else
#define HT_ENTRY(type) \
struct { \
struct type *hte_next; \
}
#endif
可以看到,如果定义了HT_CACHE_HASH_VALUES宏,那么就会多一个hte_hash变量。从宏的名字来看,这是一个cache。不错,变量hte_hash就是用来存储前面的hashsocket的返回值。当第一次计算得到后,就存放到hte_hash变量中。以后需要用到(会经常用到),就直接向这个变量要即可,无需再次计算hashsocket函数。如果没有这个变量,那么需要用到这个值,都要调用hashsocket函数计算一次。这一点从后面的代码可以看到。
哈希表操作函数:
ht-internal.h文件里面定义了一系列的哈希函数的操作函数。下来就列出这些函数。如果打开ht-internal.h文件,就发现,它是宏的天下。该文件的函数都是由宏定义生成的。下面就贴出宏定义展开后的函数。同前一篇博文那样,是用gcc的-E选项展开的。下面的代码比较长,要有心理准备。
struct event_list
{
struct event *tqh_first;
struct event **tqh_last;
};
struct evmap_io
{
struct event_list events;
ev_uint16_t nread;
ev_uint16_t nwrite;
};
struct event_map_entry
{
struct
{
struct event_map_entry *hte_next;
#ifdef HT_CACHE_HASH_VALUES
unsigned hte_hash;
#endif
}map_node;
evutil_socket_t fd;
union
{
struct evmap_io evmap_io;
}ent;
};
struct event_io_map
{
//哈希表
struct event_map_entry **hth_table;
//哈希表的长度
unsigned hth_table_length;
//哈希的元素个数
unsigned hth_n_entries;
//resize 之前可以存多少个元素
//在event_io_map_HT_GROW函数中可以看到其值为hth_table_length的
//一半。但hth_n_entries>=hth_load_limit时,就会发生增长哈希表的长度
unsigned hth_load_limit;
//后面素数表中的下标值。主要是指明用到了哪个素数
int hth_prime_idx;
};
int event_io_map_HT_GROW(struct event_io_map *ht, unsigned min_capacity);
void event_io_map_HT_CLEAR(struct event_io_map *ht);
int _event_io_map_HT_REP_IS_BAD(const struct event_io_map *ht);
//初始化event_io_map
static inline void event_io_map_HT_INIT(struct event_io_map *head)
{
head->hth_table_length = 0;
head->hth_table = NULL;
head->hth_n_entries = 0;
head->hth_load_limit = 0;
head->hth_prime_idx = -1;
}
//在event_io_map这个哈希表中,找个表项elm
//在下面还有一个相似的函数,函数名少了最后的_P。那个函数的返回值
//是event_map_entry *。从查找来说,后面那个函数更适合。之所以
//有这个函数,是因为哈希表还有replace、remove这些操作。对于
//A->B->C这样的链表。此时,要replace或者remove节点B。
//如果只有后面那个查找函数,那么只能查找并返回一个指向B的指针。
//此时将无法修改A的next指针了。所以本函数有存在的必要。
//在本文件中,很多函数都使用了event_map_entry **。
//因为event_map_entry **类型变量,既可以修改本元素的hte_next变量
//也能指向下一个元素。
//该函数返回的是查找节点的前驱节点的hte_next成员变量的地址。
//所以返回值肯定不会为NULL,但是对返回值取*就可能为NULL
static inline struct event_map_entry **
_event_io_map_HT_FIND_P(struct event_io_map *head,
struct event_map_entry *elm)
{
struct event_map_entry **p;
if (!head->hth_table)
return NULL;
#ifdef HT_CACHE_HASH_VALUES
p = &((head)->hth_table[((elm)->map_node.hte_hash)
% head->hth_table_length]);
#else
p = &((head)->hth_table[(hashsocket(*elm))%head->hth_table_length]);
#endif
//这里的哈希表是用链地址法解决哈希冲突的。
//上面的 % 只是找到了冲突链的头。现在是在冲突链中查找。
while (*p)
{
//判断是否相等。在实现上,只是简单地根据fd来判断是否相等
if (eqsocket(*p, elm))
return p;
//p存放的是hte_next成员变量的地址
p = &(*p)->map_node.hte_next;
}
return p;
}
/* Return a pointer to the element in the table 'head' matching 'elm',
* or NULL if no such element exists */
//在event_io_map这个哈希表中,找个表项elm
static inline struct event_map_entry *
event_io_map_HT_FIND(const struct event_io_map *head,
struct event_map_entry *elm)
{
struct event_map_entry **p;
struct event_io_map *h = (struct event_io_map *) head;
#ifdef HT_CACHE_HASH_VALUES
do
{ //计算哈希值
(elm)->map_node.hte_hash = hashsocket(elm);
} while(0);
#endif
p = _event_io_map_HT_FIND_P(h, elm);
return p ? *p : NULL;
}
/* Insert the element 'elm' into the table 'head'. Do not call this
* function if the table might already contain a matching element. */
static inline void
event_io_map_HT_INSERT(struct event_io_map *head,
struct event_map_entry *elm)
{
struct event_map_entry **p;
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit)
event_io_map_HT_GROW(head, head->hth_n_entries+1);
++head->hth_n_entries;
#ifdef HT_CACHE_HASH_VALUES
do
{ //计算哈希值.此哈希不同于用%计算的简单哈希。
//存放到hte_hash变量中,作为cache
(elm)->map_node.hte_hash = hashsocket(elm);
} while (0);
p = &((head)->hth_table[((elm)->map_node.hte_hash)
% head->hth_table_length]);
#else
p = &((head)->hth_table[(hashsocket(*elm))%head->hth_table_length]);
#endif
//使用头插法,即后面才插入的链表,反而会在链表头。
elm->map_node.hte_next = *p;
*p = elm;
}
/* Insert the element 'elm' into the table 'head'. If there already
* a matching element in the table, replace that element and return
* it. */
static inline struct event_map_entry *
event_io_map_HT_REPLACE(struct event_io_map *head,
struct event_map_entry *elm)
{
struct event_map_entry **p, *r;
if (!head->hth_table || head->hth_n_entries >= head->hth_load_limit)
event_io_map_HT_GROW(head, head->hth_n_entries+1);
#ifdef HT_CACHE_HASH_VALUES
do
{
(elm)->map_node.hte_hash = hashsocket(elm);
} while(0);
#endif
p = _event_io_map_HT_FIND_P(head, elm);
//由前面的英文注释可知,这个函数是替换插入一起进行的。如果哈希表
//中有和elm相同的元素(指的是event_map_entry的fd成员变量值相等)
//那么就发生替代(其他成员变量值不同,所以不是完全相同,有替换意义)
//如果哈希表中没有和elm相同的元素,那么就进行插入操作
//指针p存放的是hte_next成员变量的地址
//这里的p存放的是被替换元素的前驱元素的hte_next变量地址
r = *p; //r指向了要替换的元素。有可能为NULL
*p = elm; //hte_next变量被赋予新值elm
//找到了要被替换的元素r(不为NULL)
//而且要插入的元素地址不等于要被替换的元素地址
if (r && (r!=elm))
{
elm->map_node.hte_next = r->map_node.hte_next;
r->map_node.hte_next = NULL;
return r; //返回被替换掉的元素
}
else //进行插入操作
{
//这里貌似有一个bug。如果前一个判断中,r 不为 NULL,而且r == elm
//对于同一个元素,多次调用本函数。就会出现这样情况。
//此时,将会来到这个else里面
//实际上没有增加元素,但元素的个数却被++了。因为r 的地址等于 elm
//所以 r = *p; *p = elm; 等于什么也没有做。(r == elm)
//当然,因为这些函数都是Libevent内部使用的。如果它保证不会同于同
//一个元素调用本函数,那么就不会出现bug
++head->hth_n_entries;
return NULL; //插入操作返回NULL,表示没有替换到元素
}
}
/* Remove any element matching 'elm' from the table 'head'. If such
* an element is found, return it; otherwise return NULL. */
static inline struct event_map_entry *
event_io_map_HT_REMOVE(struct event_io_map *head,
struct event_map_entry *elm)
{
struct event_map_entry **p, *r;
#ifdef HT_CACHE_HASH_VALUES
do
{
(elm)->map_node.hte_hash = hashsocket(elm);
} while (0);
#endif
p = _event_io_map_HT_FIND_P(head,elm);
if (!p || !*p)//没有找到
return NULL;
//指针p存放的是hte_next成员变量的地址
//这里的p存放的是被替换元素的前驱元素的hte_next变量地址
r = *p; //r现在指向要被删除的元素
*p = r->map_node.hte_next;
r->map_node.hte_next = NULL;
--head->hth_n_entries;
return r;
}
/* Invoke the function 'fn' on every element of the table 'head',
using 'data' as its second argument. If the function returns
nonzero, remove the most recently examined element before invoking
the function again. */
static inline void
event_io_map_HT_FOREACH_FN(struct event_io_map *head,
int (*fn)(struct event_map_entry *, void *),
void *data)
{
unsigned idx;
struct event_map_entry **p, **nextp, *next;
if (!head->hth_table)
return;
for (idx=0; idx < head->hth_table_length; ++idx)
{
p = &head->hth_table[idx];
while (*p)
{
//像A->B->C链表。p存放了A元素中hte_next变量的地址
//*p则指向B元素。nextp存放B的hte_next变量的地址
//next指向C元素。
nextp = &(*p)->map_node.hte_next;
next = *nextp;
//对B元素进行检查
if (fn(*p, data))
{
--head->hth_n_entries;
//p存放了A元素中hte_next变量的地址
//所以*p = next使得A元素的hte_next变量值被赋值为
//next。此时链表变成A->C。即使抛弃了B元素。不知道
//调用方是否能释放B元素的内存。
*p = next;
}
else
{
p = nextp;
}
}
}
}
/* Return a pointer to the first element in the table 'head', under
* an arbitrary order. This order is stable under remove operations,
* but not under others. If the table is empty, return NULL. */
//获取第一条冲突链的第一个元素
static inline struct event_map_entry **
event_io_map_HT_START(struct event_io_map *head)
{
unsigned b = 0;
while (b < head->hth_table_length)
{
//返回哈希表中,第一个不为NULL的节点
//即有event_map_entry元素的节点。
//找到链。因为是哈希。所以不一定哈希表中的每一个节点都存有元素
if (head->hth_table[b])
return &head->hth_table[b];
++b;
}
return NULL;
}
/* Return the next element in 'head' after 'elm', under the arbitrary
* order used by HT_START. If there are no more elements, return
* NULL. If 'elm' is to be removed from the table, you must call
* this function for the next value before you remove it.
*/
static inline struct event_map_entry **
event_io_map_HT_NEXT(struct event_io_map *head,
struct event_map_entry **elm)
{
//本哈希解决冲突的方式是链地址
//如果参数elm所在的链地址中,elm还有下一个节点,就直接返回下一个节点
if ((*elm)->map_node.hte_next)
{
return &(*elm)->map_node.hte_next;
}
else //否则取哈希表中的下一条链中第一个元素
{
#ifdef HT_CACHE_HASH_VALUES
unsigned b = (((*elm)->map_node.hte_hash)
% head->hth_table_length) + 1;
#else
unsigned b = ( (hashsocket(*elm)) % head->hth_table_length) + 1;
#endif
while (b < head->hth_table_length)
{
//找到链。因为是哈希。所以不一定哈希表中的每一个节点都存有元素
if (head->hth_table[b])
return &head->hth_table[b];
++b;
}
return NULL;
}
}
//功能同上一个函数。只是参数不同,另外本函数还会使得--hth_n_entries
//该函数主要是返回elm的下一个元素。并且哈希表的总元素个数减一。
//主调函数会负责释放*elm指向的元素。无需在这里动手
//在evmap_io_clear函数中,会调用本函数。
static inline struct event_map_entry **
event_io_map_HT_NEXT_RMV(struct event_io_map *head,
struct event_map_entry **elm)
{
#ifdef HT_CACHE_HASH_VALUES
unsigned h = ((*elm)->map_node.hte_hash);
#else
unsigned h = (hashsocket(*elm));
#endif
//elm变量变成存放下一个元素的hte_next的地址
*elm = (*elm)->map_node.hte_next;
--head->hth_n_entries;
if (*elm)
{
return elm;
}
else
{
unsigned b = (h % head->hth_table_length)+1;
while (b < head->hth_table_length)
{
if (head->hth_table[b])
return &head->hth_table[b];
++b;
}
return NULL;
}
}
//素数表。之所以去素数,是因为在取模的时候,素数比合数更有优势。
//听说是更散,更均匀
static unsigned event_io_map_PRIMES[] =
{
//素数表的元素具有差不多2倍的关系。
//这使得扩容操作不会经常发生。每次扩容都预留比较大的空间
53, 97, 193, 389, 769, 1543, 3079,
6151, 12289, 24593, 49157, 98317,
196613, 393241, 786433, 1572869, 3145739,
6291469, 12582917, 25165843, 50331653, 100663319,
201326611, 402653189, 805306457, 1610612741
};
//素数表中,元素的个数。
static unsigned event_io_map_N_PRIMES =
(unsigned)(sizeof(event_io_map_PRIMES)
/sizeof(event_io_map_PRIMES[0]));
/* Expand the internal table of 'head' until it is large enough to
* hold 'size' elements. Return 0 on success, -1 on allocation
* failure. */
int event_io_map_HT_GROW(struct event_io_map *head, unsigned size)
{
unsigned new_len, new_load_limit;
int prime_idx;
struct event_map_entry **new_table;
//已经用到了素数表中最后一个素数,不能再扩容了。
if (head->hth_prime_idx == (int)event_io_map_N_PRIMES - 1)
return 0;
//哈希表中还够容量,无需扩容
if (head->hth_load_limit > size)
return 0;
prime_idx = head->hth_prime_idx;
do {
new_len = event_io_map_PRIMES[++prime_idx];
//从素数表中的数值可以看到,后一个差不多是前一个的2倍。
//从0.5和后的new_load_limit <= size,可以得知此次扩容
//至少得是所需大小(size)的2倍以上。免得经常要进行扩容
new_load_limit = (unsigned)(0.5*new_len);
} while (new_load_limit <= size
&& prime_idx < (int)event_io_map_N_PRIMES);
if ((new_table = mm_malloc(new_len*sizeof(struct event_map_entry*))))
{
unsigned b;
memset(new_table, 0, new_len*sizeof(struct event_map_entry*));
for (b = 0; b < head->hth_table_length; ++b)
{
struct event_map_entry *elm, *next;
unsigned b2;
elm = head->hth_table[b];
while (elm) //该节点有冲突链。遍历冲突链中所有的元素
{
next = elm->map_node.hte_next;
//冲突链中的元素,相对于前一个素数同余(即模素数后,结果相当)
//但对于现在的新素数就不一定同余了,即它们不一定还会冲突
//所以要对冲突链中的所有元素都再次哈希,并放到它们应该在的地方
//b2存放了再次哈希后,元素应该存放的节点下标。
#ifdef HT_CACHE_HASH_VALUES
b2 = (elm)->map_node.hte_hash % new_len;
#else
b2 = (hashsocket(*elm)) % new_len;
#endif
//用头插法插入数据
elm->map_node.hte_next = new_table[b2];
new_table[b2] = elm;
elm = next;
}
}
if (head->hth_table)
mm_free(head->hth_table);
head->hth_table = new_table;
}
else
{
unsigned b, b2;
//刚才mm_malloc失败,可能是内存不够。现在用更省内存的
//mm_realloc方式。当然其代价就是更耗时(下面的代码可以看到)。
//前面的mm_malloc会同时有hth_table和new_table两个数组。
//而mm_realloc则只有一个数组,所以省内存,省了一个hth_table数组
//的内存。此时,new_table数组的前head->hth_table_length个
//元素存放了原来的冲突链的头部。也正是这个原因导致后面代码更耗时。
//其实,只有在很特殊的情况下,这个函数才会比mm_malloc省内存.
//就是堆内存head->hth_table区域的后面刚好有一段可以用的内存。
//具体的,可以搜一下realloc这个函数。
new_table = mm_realloc(head->hth_table,
new_len*sizeof(struct event_map_entry*));
if (!new_table)
return -1;
memset(new_table + head->hth_table_length, 0,
(new_len - head->hth_table_length)*sizeof(struct event_map_entry*)
);
for (b=0; b < head->hth_table_length; ++b)
{
struct event_map_entry *e, **pE;
for (pE = &new_table[b], e = *pE; e != NULL; e = *pE)
{
#ifdef HT_CACHE_HASH_VALUES
b2 = (e)->map_node.hte_hash % new_len;
#else
b2 = (hashsocket(*elm)) % new_len;
#endif
//对于冲突链A->B->C.
//pE是二级指针,存放的是A元素的hte_next指针的地址值
//e指向B元素。
//对新的素数进行哈希,刚好又在原来的位置
if (b2 == b)
{
//此时,无需修改。接着处理冲突链中的下一个元素即可
//pE向前移动,存放B元素的hte_next指针的地址值
pE = &e->map_node.hte_next;
}
else//这个元素会去到其他位置上。
{
//此时冲突链修改成A->C。
//所以pE无需修改,还是存放A元素的hte_next指针的地址值
//但A元素的hte_next指针要指向C元素。用*pE去修改即可
*pE = e->map_node.hte_next;
//将这个元素放到正确的位置上。
e->map_node.hte_next = new_table[b2];
new_table[b2] = e;
}
//这种再次哈希的方式,很有可能会对某些元素操作两次。
//当某个元素第一次在else中处理,那么它就会被哈希到正确的节点
//的冲突链上。随着外循环的进行,处理到正确的节点时。在遍历该节点
//的冲突链时,又会再次处理该元素。此时,就会在if中处理。而不会
//进入到else中。
}
}
head->hth_table = new_table;
}
//一般是当hth_n_entries >= hth_load_limit时,就会调用
//本函数。hth_n_entries表示的是哈希表中节点的个数。而hth_load_limit
//是hth_table_length的一半。hth_table_length则是哈希表中
//哈希函数被模的数字。所以,当哈希表中的节点个数到达哈希表长度的一半时
//就会发生增长,本函数被调用。这样的结果是:平均来说,哈希表应该比较少发生
//冲突。即使有,冲突链也不会太长。这样就能有比较快的查找速度。
head->hth_table_length = new_len;
head->hth_prime_idx = prime_idx;
head->hth_load_limit = new_load_limit;
return 0;
}
/* Free all storage held by 'head'. Does not free 'head' itself,
* or individual elements. 并不需要释放独立的元素*/
//在evmap_io_clear函数会调用该函数。其是在删除所有哈希表中的元素后
//才调用该函数的。
void event_io_map_HT_CLEAR(struct event_io_map *head)
{
if (head->hth_table)
mm_free(head->hth_table);
head->hth_table_length = 0;
event_io_map_HT_INIT(head);
}
/* Debugging helper: return false iff the representation of 'head' is
* internally consistent. */
int _event_io_map_HT_REP_IS_BAD(const struct event_io_map *head)
{
unsigned n, i;
struct event_map_entry *elm;
if (!head->hth_table_length)
{
//刚被初始化,还没申请任何空间
if (!head->hth_table && !head->hth_n_entries
&& !head->hth_load_limit && head->hth_prime_idx == -1
)
return 0;
else
return 1;
}
if (!head->hth_table || head->hth_prime_idx < 0
|| !head->hth_load_limit
)
return 2;
if (head->hth_n_entries > head->hth_load_limit)
return 3;
if (head->hth_table_length != event_io_map_PRIMES[head->hth_prime_idx])
return 4;
if (head->hth_load_limit != (unsigned)(0.5*head->hth_table_length))
return 5;
for (n = i = 0; i < head->hth_table_length; ++i)
{
for (elm = head->hth_table[i]; elm; elm = elm->map_node.hte_next)
{
#ifdef HT_CACHE_HASH_VALUES
if (elm->map_node.hte_hash != hashsocket(elm))
return 1000 + i;
if( (elm->map_node.hte_hash % head->hth_table_length) != i)
return 10000 + i;
#else
if ( (hashsocket(*elm)) != hashsocket(elm))
return 1000 + i;
if( ( (hashsocket(*elm)) % head->hth_table_length) != i)
return 10000 + i;
#endif
++n;
}
}
if (n != head->hth_n_entries)
return 6;
return 0;
}
代码中的注释已经对这个哈希表的一些特征进行了描述,这里就不多说了。
哈希表在Libevent的使用:
现在来讲一下event_io_map的应用。
在event_base这个结构体中有一个event_io_map类型的成员变量io。它就是一个哈希表。当一个监听读或者写操作的event,调用event_add函数插入到event_base中时,就会调用evmap_io_add函数。evmap_io_add函数应用到这个event_io_map结构体。该函数的定义如下,其中使用到了一个宏定义,我已经展开了。
int
evmap_io_add(struct event_base *base, evutil_socket_t fd, struct event *ev)
{
const struct eventop *evsel = base->evsel;
struct event_io_map *io = &base->io;
struct evmap_io *ctx = NULL;
int nread, nwrite, retval = 0;
short res = 0, old = 0;
struct event *old_ev;
EVUTIL_ASSERT(fd == ev->ev_fd);
if (fd < 0)
return 0;
//GET_IO_SLOT_AND_CTOR(ctx, io, fd, evmap_io, evmap_io_init,
// evsel->fdinfo_len);SLOT指的是fd
//GET_IO_SLOT_AND_CTOR宏将展开成下面这个do{}while(0);
do
{
struct event_map_entry _key, *_ent;
_key.fd = fd;
struct event_io_map *_ptr_head = io;
struct event_map_entry **ptr;
//哈希表扩容,减少冲突的可能性
if (!_ptr_head->hth_table
|| _ptr_head->hth_n_entries >= _ptr_head->hth_load_limit)
{
event_io_map_HT_GROW(_ptr_head,
_ptr_head->hth_n_entries + 1);
}
#ifdef HT_CACHE_HASH_VALUES
do{
(&_key)->map_node.hte_hash = hashsocket((&_key));
} while(0);
#endif
//返回值ptr,是要查找节点的前驱节点的hte_next成员变量的地址.
//所以返回值肯定不会为NULL,而*ptr就可能为NULL。说明hte_next
//不指向任何节点。也正由于这个原因,所以即使*ptr 为NULL,但是可以
//给*ptr赋值。此时,是修改前驱节点的hte_next成员变量的值,使之
//指向另外一个节点。
//这里调用_event_io_map_HT_FIND_P原因有二:1.查看该fd是否已经
//插入过这个哈希表中。2.得到这个fd计算哈希位置。
ptr = _event_io_map_HT_FIND_P(_ptr_head, (&_key));
//在event_io_map这个哈希表中查找是否已经存在该fd的event_map_entry了
//因为同一个fd可以调用event_new多次,然后event_add多次的。
if (*ptr)
{
_ent = *ptr;
}
else
{
_ent = mm_calloc(1, sizeof(struct event_map_entry) + evsel->fdinfo_len);
if (EVUTIL_UNLIKELY(_ent == NULL))
return (-1);
_ent->fd = fd;
//调用初始化函数初始化这个evmap_io
(evmap_io_init)(&_ent->ent.evmap_io);
#ifdef HT_CACHE_HASH_VALUES
do
{
ent->map_node.hte_hash = (&_key)->map_node.hte_hash;
}while(0);
#endif
_ent->map_node.hte_next = NULL;
//把这个新建的节点插入到哈希表中。ptr已经包含了哈希位置
*ptr = _ent;
++(io->hth_n_entries);
}
//这里是获取该event_map_entry的next和prev指针。因为
//evmap_io含有next、prev变量。这样在之后就可以把这个
//event_map_entry连起来。这个外do{}while(0)的功能是
//为这个fd分配一个event_map_entry,并且插入到现有的哈希
//表中。同时,这个fd还是结构体event的一部分。而event必须
//插入到event队列中。
(ctx) = &_ent->ent.evmap_io;
} while (0);
....
//ctx->events是一个TAILQ_HEAD。结合之前讲到的TAILQ_QUEUE队列,
//就可以知道:同一个fd,可能有多个event结构体。这里就把这些结构体连
//起来。依靠的链表是,event结构体中的ev_io_next。ev_io_next是
//一个TAILQ_ENTRY,具有前驱和后驱指针。队列头部为event_map_entry
//结构体中的evmap_io成员的events成员。
TAILQ_INSERT_TAIL(&ctx->events, ev, ev_io_next);
return (retval);
}
GET_IO_SLOT_AND_CTOR宏的作用就是让ctx指向struct event_map_entry结构体中的TAILQ_HEAD。这样就可以使用TAILQ_INSERT_TAIL宏,把ev变量插入到队列中。如果有现成的event_map_entry就直接使用,没有的话就新建一个。
————————————————
版权声明:本文为CSDN博主「luotuo44」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/luotuo44/article/details/38403241
posted @
2019-11-12 17:26 长戟十三千 阅读(345) |
评论 (0) |
编辑 收藏