在研究磁盘性能之前我们必须先了解磁盘的结构,以及工作原理。不过在这里就不再重复说明了,关系硬盘结构和工作原理的信息可以参考维基百科上面的相关词条——Hard disk drive(英文)和硬盘驱动器(中文)。
读写IO(Read/Write IO)操作
磁盘是用来给我们存取数据用的,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据时候对应的是写IO操作,取数据的时候对应的是是读IO操作。
单个IO操作
当控制磁盘的控制器接到操作系统的读IO操作指令的时候,控制器就会给磁盘发出一个读数据的指令,并同时将要读取的数据块的地址传递给磁盘,然后磁盘会将读取到的数据传给控制器,并由控制器返回给操作系统,完成一个写IO的操作;同样的,一个写IO的操作也类似,控制器接到写的IO操作的指令和要写入的数据,并将其传递给磁盘,磁盘在数据写入完成之后将操作结果传递回控制器,再由控制器返回给操作系统,完成一个写IO的操作。单个IO操作指的就是完成一个写IO或者是读IO的操作。
随机访问(Random Access)与连续访问(Sequential Access)
随机访问指的是本次IO所给出的扇区地址和上次IO给出扇区地址相差比较大,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。相反的,如果当次IO给出的扇区地址与上次IO结束的扇区地址一致或者是接近的话,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。因此尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
顺序IO模式(Queue Mode)/并发IO模式(Burst Mode)
磁盘控制器可能会一次对磁盘组发出一连串的IO命令,如果磁盘组一次只能执行一个IO命令时称为顺序IO;当磁盘组能同时执行多个IO命令时,称为并发IO。并发IO只能发生在由多个磁盘组成的磁盘组上,单块磁盘只能一次处理一个IO命令。
2单个IO的大小(IO Chunk Size)
单个IO的大小(IO Chunk Size)
熟悉数据库的人都会有这么一个概念,那就是数据库存储有个基本的块大小(Block Size),不管是SQL Server还是Oracle,默认的块大小都是8KB,就是数据库每次读写都是以8k为单位的。那么对于数据库应用发出的固定8k大小的单次读写到了写磁盘这个层面会是怎么样的呢,就是对于读写磁盘来说单个IO操作操作数据的大小是多少呢,是不是也是一个固定的值?
答案是不确定。首先操作系统为了提高 IO的性能而引入了文件系统缓存(File System Cache),系统会根据请求数据的情况将多个来自IO的请求先放在缓存里面,然后再一次性的提交给磁盘,也就是说对于数据库发出的多个8K数据块的读操作有可能放在一个磁盘读IO里就处理了。
还有对于有些存储系统也是提供了缓存(Cache)的,接收到操作系统的IO请求之后也是会将多个操作系统的 IO请求合并成一个来处理。不管是操作系统层面的缓存还是磁盘控制器层面的缓存,目的都只有一个,提高数据读写的效率。因此每次单独的IO操作大小都是不一样的,它主要取决于系统对于数据读写效率的判断。
当一次IO操作大小比较小的时候我们成为小的IO操作,比如说1K,4K,8K这样的;当一次IO操作的数据量比较的的时候称为大IO操作,比如说32K,64K甚至更大。
在我们说到块大小(Block Size)的时候通常我们会接触到多个类似的概念,像我们上面提到的那个在数据库里面的数据最小的管理单位,Oralce称之为块(Block),大小一般为8K,SQL Server称之为页(Page),一般大小也为8k。
在文件系统里面我们也能碰到一个文件系统的块,在现在很多的Linux系统中都是4K(通过 /usr/bin/time -v可以看到),它的作用其实跟数据库里面的块/页是一样的,都是为了方便数据的管理。但是说到单次IO的大小,跟这些块的大小都是没有直接关系的,在英文里单次IO大小通常被称为是IO Chunk Size,不会说成是IO Block Size的。
3IOPS(IO per Second)
IOPS(IO per Second)
IOPS,IO系统每秒所执行IO操作的次数,是一个重要的用来衡量系统IO能力的一个参数。对于单个磁盘组成的IO系统来说,计算它的IOPS不是一件很难的事情,只要我们知道了系统完成一次IO所需要的时间的话我们就能推算出系统IOPS来。
现在我们就来推算一下磁盘的IOPS,假设磁盘的转速(Rotational Speed)为15K RPM,平均寻道时间为5ms,最大传输速率为40MB/s(这里将读写速度视为一样,实际会差别比较大)。
对于磁盘来说一个完整的IO操作是这样进行的:当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带读写磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻址(Seeking),对应消耗的时间被称为寻址时间(Seek Time);但是找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正上方的之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay);接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后一次IO操作也就完成了。
在我们看硬盘厂商的宣传单的时候我们经常能看到3个参数,分别是平均寻址时间、盘片旋转速度以及最大传送速度,这三个参数就可以提供给我们计算上述三个步骤的时间。
第一个寻址时间,考虑到被读写的数据可能在磁盘的任意一个磁道,既有可能在磁盘的最内圈(寻址时间最短),也可能在磁盘的最外圈(寻址时间最长),所以在计算中我们只考虑平均寻址时间,也就是磁盘参数中标明的那个平均寻址时间,这里就采用当前最多的10krmp硬盘的5ms。
第二个旋转延时,和寻址一样,当磁头定位到磁道之后有可能正好在要读写扇区之上,这时候是不需要额外额延时就可以立刻读写到数据,但是最坏的情况确实要磁盘旋转整整一圈之后磁头才能读取到数据,所以这里我们也考虑的是平均旋转延时,对于10krpm的磁盘就是(60s/15k)*(1/2) = 2ms。
第三个传送时间,磁盘参数提供我们的最大的传输速度,当然要达到这种速度是很有难度的,但是这个速度却是磁盘纯读写磁盘的速度,因此只要给定了单次 IO的大小,我们就知道磁盘需要花费多少时间在数据传送上,这个时间就是IO Chunk Size / Max Transfer Rate。
4IOPS计算公式
IOPS计算公式
现在我们就可以得出这样的计算单次IO时间的公式:
IO Time = Seek Time + 60 sec/Rotational Speed/2 + IO Chunk Size/Transfer Rate
于是我们可以这样计算出IOPS
IOPS = 1/IO Time = 1/(Seek Time + 60 sec/Rotational Speed/2 + IO Chunk Size/Transfer Rate)
对于给定不同的IO大小我们可以得出下面的一系列的数据
4K (1/7.1 ms = 140 IOPS)
5ms + (60sec/15000RPM/2) + 4K/40MB = 5 + 2 + 0.1 = 7.1
8k (1/7.2 ms = 139 IOPS)
5ms + (60sec/15000RPM/2) + 8K/40MB = 5 + 2 + 0.2 = 7.2
16K (1/7.4 ms = 135 IOPS)
5ms + (60sec/15000RPM/2) + 16K/40MB = 5 + 2 + 0.4 = 7.4
32K (1/7.8 ms = 128 IOPS)
5ms + (60sec/15000RPM/2) + 32K/40MB = 5 + 2 + 0.8 = 7.8
64K (1/8.6 ms = 116 IOPS)
5ms + (60sec/15000RPM/2) + 64K/40MB = 5 + 2 + 1.6 = 8.6
从上面的数据可以看出,当单次IO越小的时候,单次IO所耗费的时间也越少,相应的IOPS也就越大。
上面我们的数据都是在一个比较理想的假设下得出来的,这里的理想的情况就是磁盘要花费平均大小的寻址时间和平均的旋转延时,这个假设其实是比较符合我们实际情况中的随机读写,在随机读写中,每次IO操作的寻址时间和旋转延时都不能忽略不计,有了这两个时间的存在也就限制了IOPS的大小。现在我们考虑一种相对极端的顺序读写操作,比如说在读取一个很大的存储连续分布在磁盘的的文件,因为文件的存储的分布是连续的,磁头在完成一个读IO操作之后,不需要从新的寻址,也不需要旋转延时,在这种情况下我们能到一个很大的IOPS值,如下
4K (1/0.1 ms = 10000 IOPS)
0ms + 0ms + 4K/40MB = 0.1
8k (1/0.2 ms = 5000 IOPS)
0ms + 0ms + 8K/40MB = 0.2
16K (1/0.4 ms = 2500 IOPS)
0ms + 0ms + 16K/40MB = 0.4
32K (1/0.8 ms = 1250 IOPS)
0ms + 0ms + 32K/40MB = 0.8
64K (1/1.6 ms = 625 IOPS)
0ms + 0ms + 64K/40MB = 1.6
相比第一组数据来说差距是非常的大的,因此当我们要用IOPS来衡量一个IO系统的系能的时候我们一定要说清楚是在什么情况的IOPS,也就是要说明读写的方式以及单次IO的大小,当然在实际当中,特别是在OLTP的系统的,随机的小IO的读写是最有说服力的。
5传输速度/吞吐率
传输速度(Transfer Rate)/吞吐率(Throughput)
现在我们要说的传输速度(另一个常见的说法是吞吐率)不是磁盘上所表明的最大传输速度或者说理想传输速度,而是磁盘在实际使用的时候从磁盘系统总线上流过的数据量。有了IOPS数据之后我们是很容易就能计算出对应的传输速度来的
Transfer Rate = IOPS * IO Chunk Size
还是那上面的第一组IOPS的数据我们可以得出相应的传输速度如下
4K: 140 * 4K = 560K / 40M = 1.36%
8K: 139 * 8K = 1112K / 40M = 2.71%
16K: 135 * 16K = 2160K / 40M = 5.27%
32K: 116 * 32K = 3712K / 40M = 9.06%
可以看出实际上的传输速度是很小的,对总线的利用率也是非常的小。
这里一定要明确一个概念,那就是尽管上面我们使用IOPS来计算传输速度,但是实际上传输速度和IOPS是没有直接关系,在没有缓存的情况下它们共同的决定因素都是对磁盘系统的访问方式以及单个IO的大小。对磁盘进行随机访问时候我们可以利用IOPS来衡量一个磁盘系统的性能,此时的传输速度不会太大;但是当对磁盘进行连续访问时,此时的IOPS已经没有了参考的价值,这个时候限制实际传输速度却是磁盘的最大传输速度。因此在实际的应用当中,只会用IOPS来衡量小IO的随机读写的性能,而当要衡量大IO连续读写的性能的时候就要采用传输速度而不能是IOPS了。
6IO响应时间
IO响应时间(IO Response Time)
最后来关注一下能直接描述IO性能的IO响应时间。IO响应时间也被称为IO延时(IO Latency),IO响应时间就是从操作系统内核发出的一个读或者写的IO命令到操作系统内核接收到IO回应的时间,注意不要和单个IO时间混淆了,单个IO时间仅仅指的是IO操作在磁盘内部处理的时间,而IO响应时间还要包括IO操作在IO等待队列中所花费的等待时间。
计算IO操作在等待队列里面消耗的时间有一个衍生于利托氏定理(Little’s Law)的排队模型M/M/1模型可以遵循,由于排队模型算法比较复杂,到现在还没有搞太明白(如果有谁对M/M/1模型比较精通的话欢迎给予指导),这里就罗列一下最后的结果,还是那上面计算的IOPS数据来说:
8K IO Chunk Size (135 IOPS, 7.2 ms)
135 => 240.0 ms
105 => 29.5 ms
75 => 15.7 ms
45 => 10.6 ms
64K IO Chunk Size(116 IOPS, 8.6 ms)
135 => 没响应了……
105 => 88.6 ms
75 => 24.6 ms
45 => 14.6 ms
从上面的数据可以看出,随着系统实际IOPS越接近理论的最大值,IO的响应时间会成非线性的增长,越是接近最大值,响应时间就变得越大,而且会比预期超出很多。一般来说在实际的应用中有一个70%的指导值,也就是说在IO读写的队列中,当队列大小小于最大IOPS的70%的时候,IO的响应时间增加会很小,相对来说让人比较能接受的,一旦超过70%,响应时间就会戏剧性的暴增,所以当一个系统的IO压力超出最大可承受压力的70%的时候就是必须要考虑调整或升级了。
另外补充说一下这个70%的指导值也适用于CPU响应时间,这也是在实践中证明过的,一旦CPU超过70%,系统将会变得受不了的慢。很有意思的东西。
posted @
2019-10-23 16:29 长戟十三千 阅读(285) |
评论 (0) |
编辑 收藏
摘要: 一、术语解释脏页:linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。内存映射:内存映射文件,是由一个文件到一块内存的映射。Win3...
阅读全文
posted @
2019-10-23 15:52 长戟十三千 阅读(1313) |
评论 (0) |
编辑 收藏既前篇nodejs深入学习系列之libuv基础篇(一)学习的基本概念之后,我们在第二篇将带大家去学习为什么libuv的并发能力这么优秀?这并发后面的实现机制是什么?
3、libuv的事件循环机制
好了,了解了上述的基本概念之后,我们来扯一扯Libuv的事件循环机制,也就是event-loop。还是以[译文]libuv设计思想概述一文展示的两张图片,再结合代码来学习整个Libuv的事件循环机制。
3.1、解密第一张图片
首先是第一张图片:
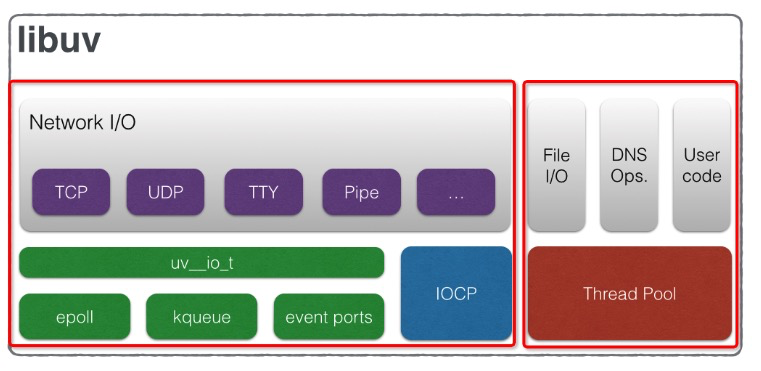
细心的童鞋会发现这张图片被我用红框分割成了两部分,为什么呢?因为Libuv处理fs I/O和网络I/O用了两套机制去实现,或者说更全面的讲应该是fs I/O和 DNS等实现的方式和网络 I/O是不一样的。为什么这么说呢?请看下图,你就会明白了:
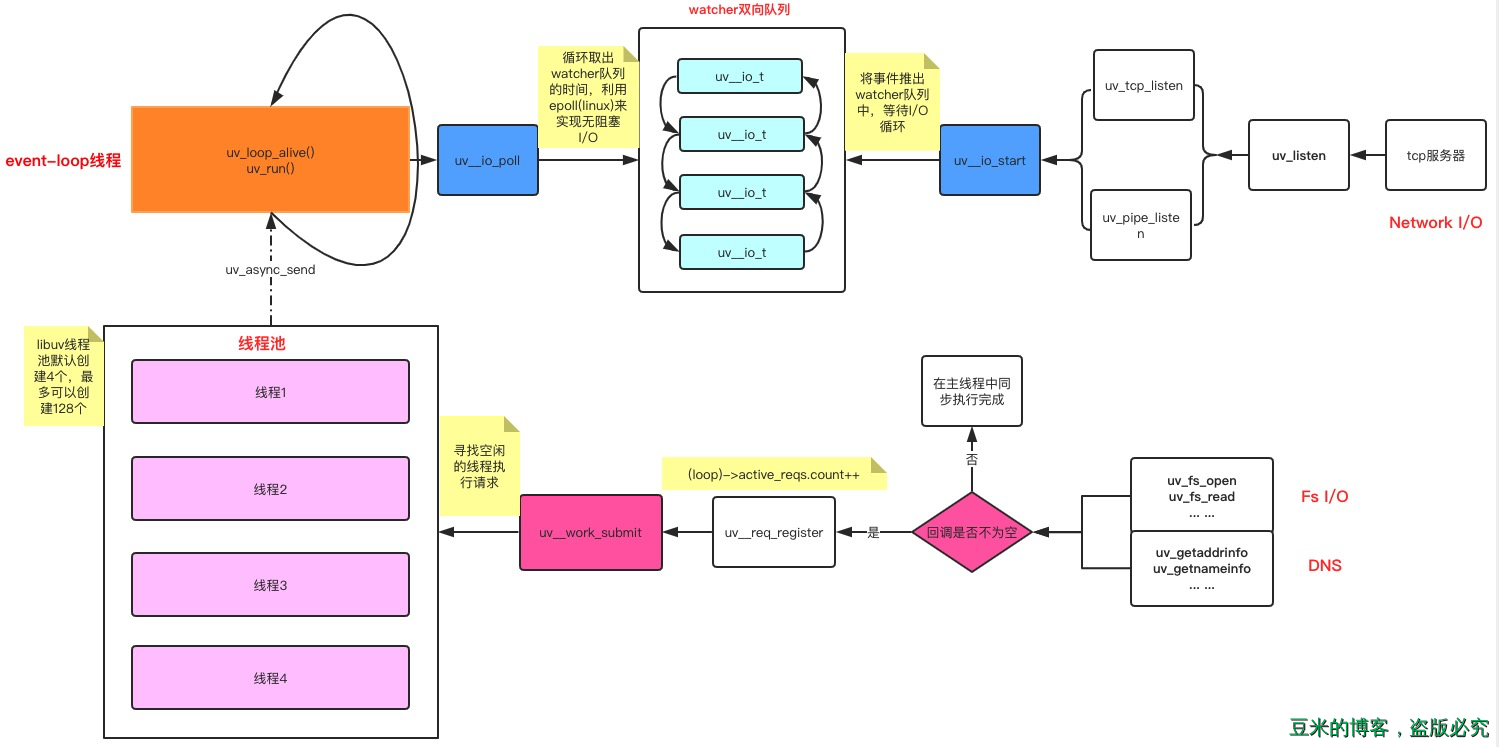
上图左侧是libuv的两大基石:event-loop线程和thread pool。而从图的右侧有两条轨迹分别连接到这两个基石,我特别用红色加粗标记,可以看到:
- Network I/O最后的调用都会归结到
uv__io_start这个函数,而该函数会将需要执行的I/O事件和回调塞到watcher队列中,之后uv_run函数执行的Poll for I/O阶段做的便是从watcher队列中取出事件调用系统的接口,这是其中一条主线 - Fs I/O和DNS的所有操作都会归结到调用
uv__work_sumit这个函数,而该函数就是执行线程池初始化并调度的终极函数。这是另外一条主线。
3.2、解密第二张图片
接着我们来看第二张图片,我们依然将该图片进行改造如下:
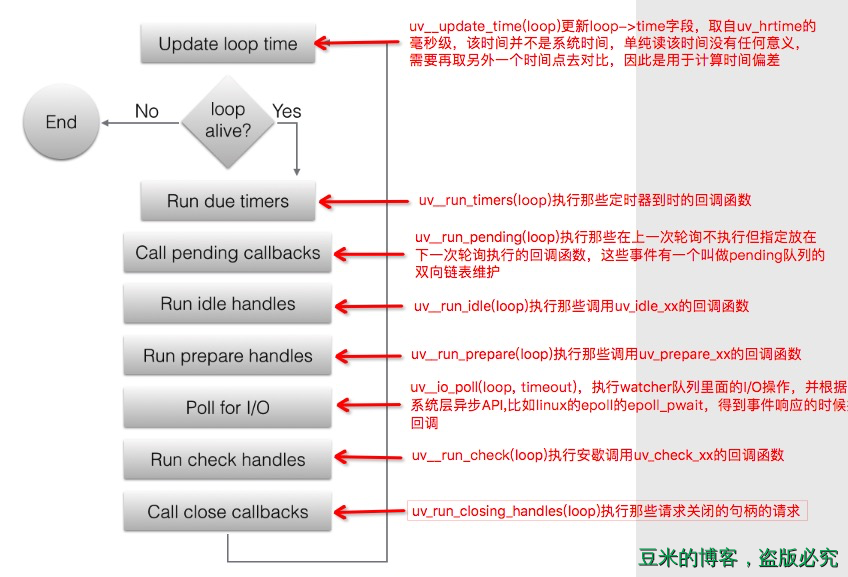
整个事件循环的执行主体是在uv_run中,每一次的循环经历的阶段对应的函数在上图中已经标注出来,有几个重点要说一下:
循环是否退出(也就是进程是否结束)取决于以下几个条件中的一个:
1.1、loop->stop_flag变为1并且uv__loop_alive返回不为0,也就是调用uv_stop函数并且loop不存在活跃的和被引用的句柄、活跃的请求或正在关闭的句柄。
1.2、事件循环运行模式等于UV_RUN_ONCE或者是UV_RUN_NOWAIT
I/O循环的超时时间的确定:
2.1、如果时间循环运行模式是UV_RUN_NOWAIT,超时为0。
2.2、如果循环将要停止(代码调用了uv_stop()),超时为0。
2.3、如果没有活跃句柄或请求,超时为0。
2.4、如果有任何Idle句柄处于活跃状态,超时为0。
2.5、如果有等待关闭的句柄,超时为0。
2.6、如果以上情况都不匹配,则采用最近的计时器的超时时间-当前时间(handle->timeout-loop->time),或者如果没有活动计时器,则为无穷大(即返回-1)。
I/O循环的实现主体uv__io_poll根据系统不同,使用方式不一样,如果对linux系统熟悉的话,epoll方式应该也会了解。更多epoll的只是可以参考该文章:Linux IO模式及 select、poll、epoll详解
4、libuv的线程池
说完时间循环的主线程,接下去我们继续揭秘libuv的线程池。
libuv提供了一个threadpool,可用来运行用户代码并在事件循环线程(event-loop)中得到通知。这个线程池在内部用于运行所有文件系统操作,以及getaddrinfo和getnameinfo请求。当然如果你想要将自己的代码放在线程池中运行也是可以的,libuv提供除了uv_queue_work的方法供开发者自己选择。
它的默认大小为4,但是可以在启动时通过将UV_THREADPOOL_SIZE环境变量设置为任意值(最大值为1024)来更改它。
threadpool是全局的,并在所有事件循环中共享。当一个特定的函数使用threadpool(即当使用uv_queue_work())时,libuv预先分配并初始化UV_THREADPOOL_SIZE所允许的最大线程数。这导致了相对较小的内存开销(128个线程大约1MB),但在运行时提高了线程的性能。
关于线程的操作,demo中的文件是:传送门
在实例中,我们用了三种方式来实现和线程相关的一些操作:
- 从线程池中调度一个线程运行回调: uv_queue_work
- 使用
uv_async_send来“唤醒” event loop主线程并执行uv_async_init当初设置好的回调 - 使用uv_thread_create手动创建一个线程来执行
我们在上一节中知道,想要创建线程池并让他们工作,唯一绕不开的函数是uv__work_submit,大家可以在libuv源码中搜寻这个,可以发现能够找到的也就这几个文件:(以unix系统为例)
threadpool.c 1. uv__work_submit实现地方 2. uv_queue_work调用 fs.c 1. 宏定义POST调用,所有的fs操作都会调用POST这个宏 getaddrinfo.c 1. uv_getaddrinfo调用 getnameinfo.c 1. uv_getnameinfo调用
细心的童鞋发现,每一处调用的地方都会传一个叫做enum uv__work_kind kind的操作,根据上面的调用,可以看出分为了3种任务类型:
- UV__WORK_CPU:CPU 密集型,UV_WORK 类型的请求被定义为这种类型。因此根据这个分类,不推荐在 uv_queue_work 中做 I/O 密集的操作。
- UV__WORK_FAST_IO:快 IO 型,UV_FS 类型的请求被定义为这种类型。
- UV__WORK_SLOW_IO:慢 IO 型,UV_GETADDRINFO 和 UV_GETNAMEINFO 类型的请求被定义为这种类型
4.2、线程池的初始化
学习线程池初始化之前,我们先得普及一下线程间的同步原语。这样后面看的代码才不会糊里糊涂
libuv提供了mutex锁、读写锁、信号量(Semaphores)、条件量(Conditions)、屏障(Barriers)五种手段来实现线程间资源竞争互斥同步等操作。接下去会简单地介绍,以便待会的初始化流程可以读懂。
4.2.1、Mutex锁
互斥锁用于对资源的互斥访问,当你访问的内存资源可能被别的线程访问到,这个时候你就可以考虑使用互斥锁,在访问的时候锁住。对应的使用流程可能是这样的:
- 初始化互斥锁:uv_mutex_init(uv_mutex_t* handle)
- 锁住互斥资源:uv_mutex_lock(uv_mutex_t* handle)
- 解锁互斥资源:uv_mutex_unlock(uv_mutex_t* handle)
在线程初始化的过程中,我们会初始化一个全局的互斥锁:
static void init_threads(void) { ... if (uv_mutex_init(&mutex)) abort() ... }
而后在每个线程的执行实体worker函数中,就使用互斥锁对下面几个公共资源进行锁住与解锁:
- 请求队列 wq:线程池收到 UVWORK_CPU 和 UVWORK_FAST_IO 类型的请求后将其插到此队列的尾部,并通过 uv_cond_signal 唤醒 worker 线程去处理,这是线程池请求的主队列。
- 慢 I/O 队列 slow_io_pending_wq:线程池收到 UV__WORK_SLOW_IO 类型的请求后将其插到此队列的尾部。
- 慢 I/O 标志位节点 run_slow_work_message:当存在慢 I/O 请求时,用来作为一个标志位放在请求队列 wq 中,表示当前有慢 I/O 请求,worker 线程处理请求时需要关注慢 I/O 队列的请求;当慢 I/O 队列的请求都处理完毕后这个标志位将从请求队列 wq 中移除。
static void worker(void* arg) { ... uv_mutex_lock(&mutex); ... uv_mutex_unlock(&mutex); }
4.2.2、读写锁
读写锁没有用在线程的启动过程中,我们在demo中用来实践对某个全局变量的访问。具体使用步骤参考代码,这里就不再赘述。
4.2.3、信号量
信号量是一种专门用于提供不同进程间或线程间同步手段的原语。信号量本质上是一个非负整数计数器,代表共享资源的数目,通常是用来控制对共享资源的访问。一般使用步骤是这样的:
- 初始化信号量:int uv_sem_init(uv_sem_t* sem, unsigned int value)
- 信号量加1:void uv_sem_wait(uv_sem_t* sem)
- 信号量减1:void uv_sem_post(uv_sem_t* sem)
- 信号量销毁:void uv_sem_wait(uv_sem_t* sem)
在线程池初始化过程中,我们利用信号量来等待所有的线程初始化结束,如下代码:
static void init_threads(void) { ... for (i = 0; i < nthreads; i++) uv_sem_wait(&sem); uv_sem_destroy(&sem); } // 而每个线程的执行实体都会去将信号量-1: static void worker(void* arg) { struct uv__work* w; QUEUE* q; int is_slow_work; uv_sem_post((uv_sem_t*) arg); ... }
这样只要所有的线程没有初始化完成,uv_sem_destroy这个函数是不会执行到的,整个初始化函数也不会返回,此时的主线程也就阻塞在这里了。
4.2.4、条件变量
而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足。条件变量的内部实质上是一个等待队列,放置等待(阻塞)的线程,线程在条件变量上等待和通知,互斥锁用来保护等待队列(因为所有的线程都可以放入等待队列,所以等待队列成为了一个共享的资源,需要被上锁保护),因此条件变量通常和互斥锁一起使用。一般使用步骤是这样的:
- 初始化条件变量:int uv_cond_init(uv_cond_t* cond)
- 线程阻塞等待被唤醒:void uv_cond_wait(uv_cond_t cond, uv_mutex_t mutex)
- 别的线程唤醒阻塞的线程:void uv_cond_signal(uv_cond_t* cond)
libuv使用条件变量来阻塞线程池和唤醒线程池,使用代码如下:
static void init_threads(void) { if (uv_cond_init(&cond)) abort(); } static void worker(void* arg) { ... for (;;) { /* `mutex` should always be locked at this point. */ /* Keep waiting while either no work is present or only slow I/O and we're at the threshold for that. */ while (QUEUE_EMPTY(&wq) || (QUEUE_HEAD(&wq) == &run_slow_work_message && QUEUE_NEXT(&run_slow_work_message) == &wq && slow_io_work_running >= slow_work_thread_threshold())) { idle_threads += 1; uv_cond_wait(&cond, &mutex); idle_threads -= 1; } ... } } static void post(QUEUE* q, enum uv__work_kind kind) { ... if (idle_threads > 0) uv_cond_signal(&cond) ... }
从上面三处代码可以看到线程启动之后就进入阻塞状态,直到有I/O请求调用uv_cond_signal来唤醒,按照uv_cond_wait调用的顺序形成一个等待队列,循环调用。
4.2.5、屏障
在多线程的时候,我们总会碰到一个需求,就是需要等待一组进程全部执行完毕后再执行某些事,由于多线程是乱序的,无法预估线程都执行到哪里了,这就要求我们有一个屏障作为同步点,在所有有屏障的地方都会阻塞等待,直到所有的线程都的代码都执行到同步点,再继续执行后续代码。使用步骤一般是:
- 初始化屏障需要达到的个数:int uv_barrier_init(uv_barrier_t* barrier, unsigned int count)
- 每当达到条件便将计数+1:int uv_barrier_wait(uv_barrier_t* barrier)
- 销毁屏障:void uv_barrier_destroy(uv_barrier_t* barrier)
只有当初始化计数的值为0,主线程才会继续执行,具体使用方法可以参考demo。
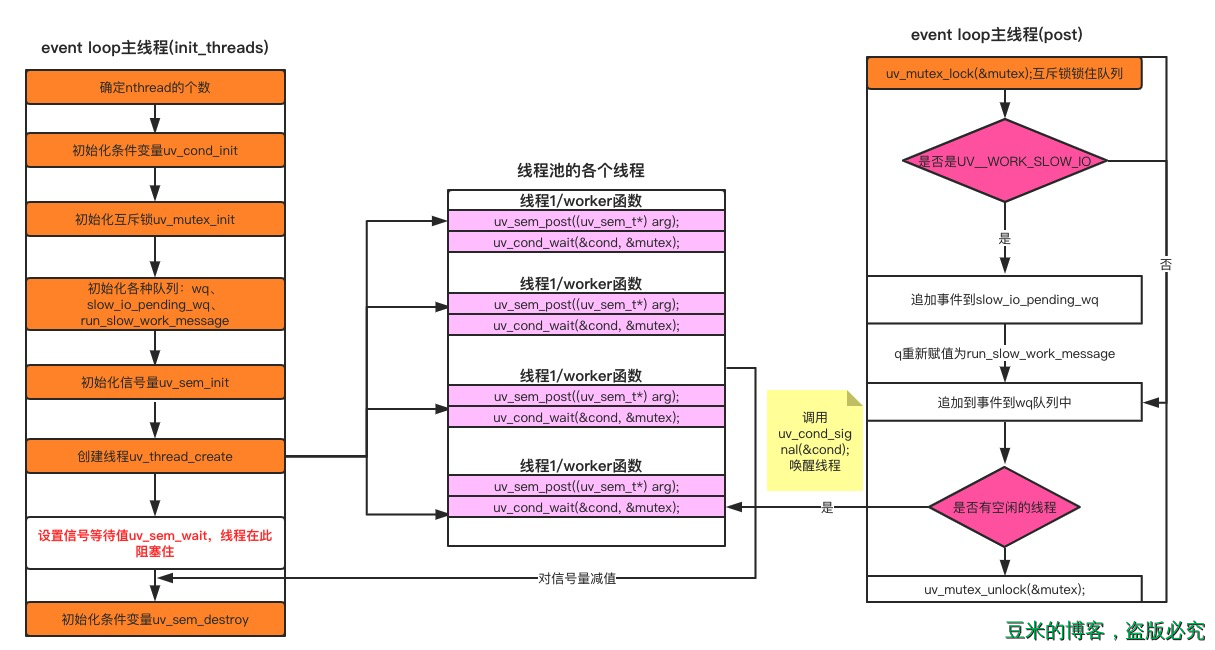
至此借助于线程间同步原语,我们就哗啦啦地把线程的初始化以及大概的工作机制讲完了,总结出了下面一张图:
4.1、线程池工作调度
线程池的工作利用的是主线程post函数和各个线程的worker函数,post函数的工作内容如下:
- 判断请求的请求类型是否是 UV__WORK_SLOW_IO:
- 如果是,将这个请求插到慢 I/O 请求队列 slow_io_pending_wq 的尾部,同时在请求队列 wq 的尾部插入一个 run_slow_work_message 节点作为标志位,告知请求队列 wq 当前存在慢 I/O 请求。
- 如果不是,将请求插到请求队列 wq 尾部。
- 如果有空闲的线程,唤醒某一个去执行请求。
并发的慢 I/O 的请求数量不会超过线程池大小的一半,这样做的好处是避免多个慢 I/O 的请求在某段时间内把所有线程都占满,导致其它能够快速执行的请求需要排队。
static unsigned int slow_work_thread_threshold(void) { return (nthreads + 1) / 2; }
而各个线程的工作内容如下:
- 等待唤醒。
- 取出请求队列 wq 或者慢 I/O 请求队列的头部请求去执行。 =>
w->work(w); - 通知 uv loop 线程完成了一个请求的处理。=>
uv_async_send - 回到最开始循环的位置。
4.2、线程间的通信
上一小节清晰地描述了libuv的主线程是如何将请求分给各个线程以及线程是如何处理请求的,那么上述过程中还有一个步骤:线程池里面的线程完成工作之后是如何通知主线程的?主线程收到通知之后又继续做了些什么?
这个过程我们称之为线程间的通信。上一小节中或者我们的demo中已经知道,完成这个事情的主要函数是uv_async_send,那么这个函数是如何实现的呢?请看下图:
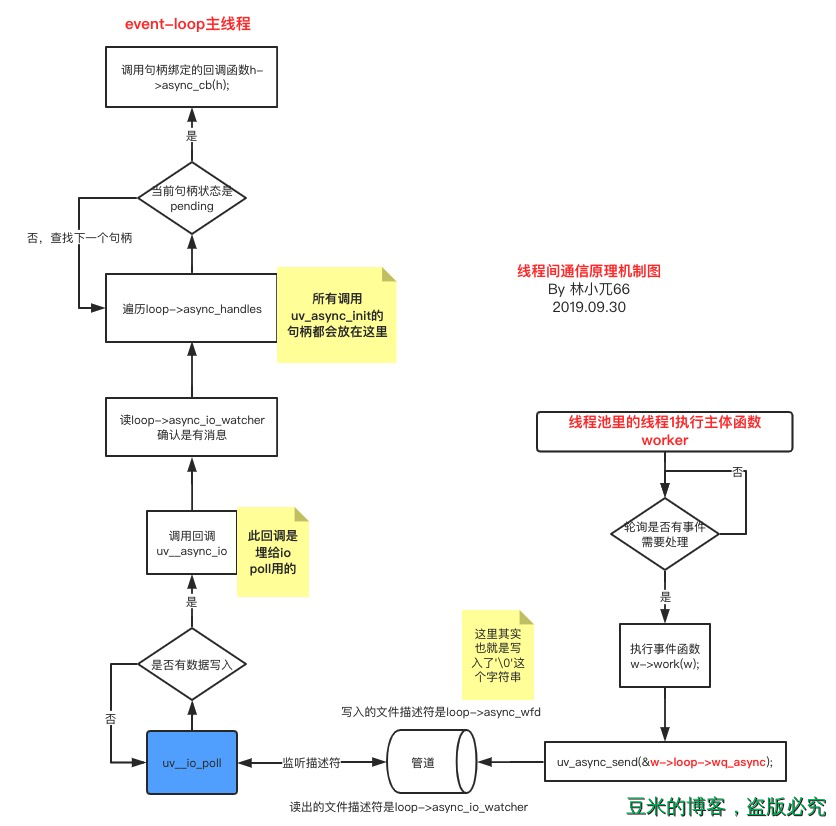
从图中我们可以看到,借助于io poll与管道,线程池的线程写入数据,被主线程轮询出来,知道有消息过来,就开始执行对应的回调函数。整个流程就是这么easy~
posted @
2019-10-17 15:30 长戟十三千 阅读(568) |
评论 (0) |
编辑 收藏
摘要: 学习完nodejs基石之一的v8基础篇(还没看过的童鞋请跳转到这里:nodejs深入学习系列之v8基础篇),我们这次将要继续学习另外一块基石:libuv。关于libuv的设计思想,我已经翻译成中文,还没看过的童鞋还是请跳转到这里: [译文]libuv设计思想概述,如果还没看完这篇文章的童鞋,下面的内容也不建议细看了,因为会有”代沟“的问题~本文的所有示例代码都可以...
阅读全文
posted @
2019-10-17 15:30 长戟十三千 阅读(984) |
评论 (0) |
编辑 收藏
摘要: libuv实现了一个线程池,该线程池在用户提交了第一个任务的时候初始化,而不是系统启动的时候就初始化。入口代码如下。static void init_once(void) { #ifndef _WIN32 /* Re-initialize the threadpool after fork. * Note that this discards the global mutex and c...
阅读全文
posted @
2019-10-14 15:46 长戟十三千 阅读(936) |
评论 (0) |
编辑 收藏
摘要: 简介用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。 实用命令实例默认启动...
阅读全文
posted @
2019-09-19 15:21 长戟十三千 阅读(307) |
评论 (0) |
编辑 收藏在工作中,经常会碰到CPU占用100%的情况,那如何找到是那个线程占用了cpu呢?
1. top命令,找到cpu占用最高的进程
2. 查看该进程的线程, top -p <pid>
3. H 切换到线程模式,找到占用cpu最高的线程。并把线程号转化为十六进制,printf "%x\n" <线程ID>
4. pstack <进程号>,把线程栈打印出来。找到对应的线程号就可以分析为什么线程会占用那么高的cpu了。
posted @
2019-09-03 16:12 长戟十三千 阅读(347) |
评论 (0) |
编辑 收藏
摘要: 以下是对相关流程和socket错误码正确处理的小结。一. Socket/Epoll主要遇到的问题:(1) 非阻塞socket下,接收流程(recv/recvfrom)对错误(EINTR/EAGAIN/EWOULDBLOCK)当成Fatal错误处理,产生频繁断连.(2)EPOLLERR/EPOLLHUP事件时,直接调用socket异常处理,产生频繁断连.(3)udp socket接收到size为0数...
阅读全文
posted @
2019-08-14 19:11 长戟十三千 阅读(1559) |
评论 (0) |
编辑 收藏
摘要: 目前银联采用的方法是LT模式,如果epoll可读(大于某个边沿值),读取需要的数据长度,从epollset中del掉,处理完逻辑之后再加入epollset,如果接收缓冲区仍然有数据,因为是LT模式,会继续通知,重复上述过程(读取需要的长度...),如果不del,则其他线程可能会读取该fd接收缓冲区数据,因此存在竞争,采用的方式是在set中暂时del掉淘米框架则采用ET模式,可读(只通知一次,后面不...
阅读全文
posted @
2019-08-14 19:01 长戟十三千 阅读(414) |
评论 (0) |
编辑 收藏开发高性能网络程序时,windows开发者们言必称iocp,linux开发者们则言必称epoll。
大家都明白epoll是一种IO多路复用技术,可以非常高效的处理数以百万计的socket句柄,比起以前的select和poll效率高大发了。
我们用起epoll来都感觉挺爽,确实快,那么,它到底为什么可以高速处理这么多并发连接呢?
原理介绍
先简单回顾下如何使用C库封装的3个epoll系统调用吧。
1 int epoll_create(int size); 2 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 3 int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
使用起来很清晰,
1 首先要调用epoll_create建立一个epoll对象。参数size是内核保证能够正确处理的最大句柄数,多于这个最大数时内核可不保证效果。
2 epoll_ctl可以操作上面建立的epoll,例如,将刚建立的socket加入到epoll中让其监控,或者把 epoll正在监控的某个socket句柄移出epoll,不再监控它等等。
3 epoll_wait在调用时,在给定的timeout时间内,当在监控的所有句柄中有事件发生时,就返回用户态的进程。
从上面的调用方式就可以看到epoll比select/poll的优越之处:
因为后者每次调用时都要传递你所要监控的所有socket给select/poll系统调用,这意味着需要将用户态的socket列表copy到内核态,如果以万计的句柄会导致每次都要copy几十几百KB的内存到内核态,非常低效。
而我们调用epoll_wait时就相当于以往调用select/poll,但是这时却不用传递socket句柄给内核,因为内核已经在epoll_ctl中拿到了要监控的句柄列表。
所以,实际上在你调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
在内核里,一切皆文件。所以,epoll向内核注册了一个文件系统,用于存储上述的被监控socket。当你调用epoll_create时,就会在这个虚拟的epoll文件系统里创建一个file结点。当然这个file不是普通文件,它只服务于epoll。
epoll在被内核初始化时(操作系统启动),同时会开辟出epoll自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。
这个内核高速cache区,就是建立连续的物理内存页,然后在之上建立slab层,简单的说,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的对象。
1 static int __init eventpoll_init(void) 2 { 3 ... ... 4 5 /* Allocates slab cache used to allocate "struct epitem" items */ 6 epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem), 7 0, SLAB_HWCACHE_ALIGN|EPI_SLAB_DEBUG|SLAB_PANIC, 8 NULL, NULL); 9 10 /* Allocates slab cache used to allocate "struct eppoll_entry" */ 11 pwq_cache = kmem_cache_create("eventpoll_pwq", 12 sizeof(struct eppoll_entry), 0, 13 EPI_SLAB_DEBUG|SLAB_PANIC, NULL, NULL); 14 15 ... ...
epoll的高效在于
当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。
这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。
有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已,如何能不高效?!
那么,这个准备就绪list链表是怎么维护的呢?
当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。
所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。
执行epoll_create时,创建了红黑树和就绪链表,执行epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行epoll_wait时立刻返回准备就绪链表里的数据即可。
最后看看epoll独有的两种模式LT和ET。无论是LT和ET模式,都适用于以上所说的流程。区别是,LT模式下,只要一个句柄上的事件一次没有处理完,会在以后调用epoll_wait时次次返回这个句柄,而ET模式仅在第一次返回。
这件事怎么做到的呢?
当一个socket句柄上有事件时,内核会把该句柄插入上面所说的准备就绪list链表,这时我们调用epoll_wait,会把准备就绪的socket拷贝到用户态内存,然后清空准备就绪list链表,
最后,epoll_wait干了件事,就是检查这些socket,如果不是ET模式(就是LT模式的句柄了),并且这些socket上确实有未处理的事件时,又把该句柄放回到刚刚清空的准备就绪链表了。
所以,非ET的句柄,只要它上面还有事件,epoll_wait每次都会返回。而ET模式的句柄,除非有新中断到,即使socket上的事件没有处理完,也是不会次次从epoll_wait返回的。
1 /* 2 * Each file descriptor added to the eventpoll interface will 3 * have an entry of this type linked to the hash. 4 */ 5 struct epitem { 6 /* RB-Tree node used to link this structure to the eventpoll rb-tree */ 7 struct rb_node rbn; 8 //红黑树,用来保存eventpoll 9 10 /* List header used to link this structure to the eventpoll ready list */ 11 struct list_head rdllink; 12 //双向链表,用来保存已经完成的eventpoll 13 14 /* The file descriptor information this item refers to */ 15 struct epoll_filefd ffd; 16 //这个结构体对应的被监听的文件描述符信息 17 18 /* Number of active wait queue attached to poll operations */ 19 int nwait; 20 //poll操作中事件的个数 21 22 /* List containing poll wait queues */ 23 struct list_head pwqlist; 24 //双向链表,保存着被监视文件的等待队列,功能类似于select/poll中的poll_table 25 26 /* The "container" of this item */ 27 struct eventpoll *ep; 28 //指向eventpoll,多个epitem对应一个eventpoll 29 30 /* The structure that describe the interested events and the source fd */ 31 struct epoll_event event; 32 //记录发生的事件和对应的fd 33 34 /* 35 * Used to keep track of the usage count of the structure. This avoids 36 * that the structure will desappear from underneath our processing. 37 */ 38 atomic_t usecnt; 39 //引用计数 40 41 /* List header used to link this item to the "struct file" items list */ 42 struct list_head fllink; 43 双向链表,用来链接被监视的文件描述符对应的struct file。因为file里有f_ep_link,用来保存所有监视这个文件的epoll节点 44 45 /* List header used to link the item to the transfer list */ 46 struct list_head txlink; 47 双向链表,用来保存传输队列 48 49 /* 50 * This is used during the collection/transfer of events to userspace 51 * to pin items empty events set. 52 */ 53 unsigned int revents; 54 //文件描述符的状态,在收集和传输时用来锁住空的事件集合 55 }; 56 57 //该结构体用来保存与epoll节点关联的多个文件描述符,保存的方式是使用红黑树实现的hash表. 58 //至于为什么要保存,下文有详细解释。它与被监听的文件描述符一一对应. 59 struct eventpoll { 60 /* Protect the this structure access */ 61 rwlock_t lock; 62 //读写锁 63 64 /* 65 * This semaphore is used to ensure that files are not removed 66 * while epoll is using them. This is read-held during the event 67 * collection loop and it is write-held during the file cleanup 68 * path, the epoll file exit code and the ctl operations. 69 */ 70 struct rw_semaphore sem; 71 //读写信号量 72 73 /* Wait queue used by sys_epoll_wait() */ 74 wait_queue_head_t wq; 75 /* Wait queue used by file->poll() */ 76 77 wait_queue_head_t poll_wait; 78 /* List of ready file descriptors */ 79 80 struct list_head rdllist; 81 //已经完成的操作事件的队列。 82 83 /* RB-Tree root used to store monitored fd structs */ 84 struct rb_root rbr; 85 //保存epoll监视的文件描述符 86 }; 87 88 //这个结构体保存了epoll文件描述符的扩展信息,它被保存在file结构体的private_data 89 //中。它与epoll文件节点一一对应。通常一个epoll文件节点对应多个被监视的文件描述符。 90 //所以一个eventpoll结构体会对应多个epitem结构体。那么,epoll中的等待事件放在哪里呢?见下面 91 /* Wait structure used by the poll hooks */ 92 struct eppoll_entry { 93 /* List header used to link this structure to the "struct epitem" */ 94 struct list_head llink; 95 /* The "base" pointer is set to the container "struct epitem" */ 96 void *base; 97 /* 98 * Wait queue item that will be linked to the target file wait 99 * queue head. 100 */ 101 wait_queue_t wait; 102 /* The wait queue head that linked the "wait" wait queue item */ 103 wait_queue_head_t *whead; 104 }; 105 106 //与select/poll的struct poll_table_entry相比,epoll的表示等待队列节点的结 107 //构体只是稍有不同,与struct poll_table_entry比较一下。 108 struct poll_table_entry { 109 struct file * filp; 110 wait_queue_t wait; 111 wait_queue_head_t * wait_address; 112 };
posted @
2019-08-14 18:41 长戟十三千 阅读(777) |
评论 (0) |
编辑 收藏