设计模式在Linux文件系统中的简单实现
注:这边文章是为了学习设计模式而写的,并不具有实际的意义。仅仅作为学习设计模式的一个参考。
Linux中的文件系统,设备驱动,和实际设备间的结构关系如下图所示:
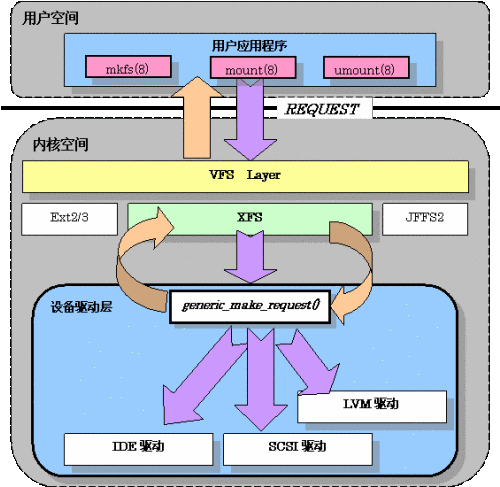
用户对设备上的数据进行I/O访问,都要先把I/O请求传递到VFS层,然后再通过实际的文件系统,最终传递到设备的驱动程序中。因为,Linux内核是由C语言和汇编语言来实现的,所以不可能像面向对象语言那样仅仅通过类的继承来就很方便的传递消息。正是由于这点,内核里仅仅使用了函数指针来达到这个目的。这里不再继续讲述文件系统间的函数指针的实现方式,因为只要看过内核源代码的人都应该了解这一点,这是学习内核的最起码的基础。
例如:


980 struct file_operations

{

981 struct module *owner;
982 loff_t (*llseek) (struct file *, loff_t, int);
983 ssize_t (*read) (struct file *, char *, size_t, loff_t *);
984 ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
985 int (*readdir) (struct file *, void *, filldir_t);
986 unsigned int (*poll) (struct file *, struct poll_table_struct *);
987 int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
988 int (*mmap) (struct file *, struct vm_area_struct *);
… …

};

对于VFS层,只提供类似于上面文件操作结构体中的函数接口,那么,这些函数的具体实现都被包含在实际的文件系统中。VFS层只是根据被访问的inode,找到实际文件系统的文件操作函数表,表中的函数指针已经指向实际文件系统中对应的操作函数。这样做的目的就是为了方便用户在日后能添加一个新类型的文件系统到linux内核的源代码,而不用去修改VFS层的代码。这一点上还有点儿面向对象设计的味道,其实我认为,C语言中的函数指针是最能贴近面向对象设计的一个技术了,只是操作起来没有像C++语言那样方面,而且可读性不是很好。
为了学习设计模式,我把linux的文件系统设计中的一些极其简单的东西用设计模式来重新组织一下,因为我工作中接触的文件系统主要是xfs,所以文中的大部分设计都是基于xfs文件系统。
文件系统的挂载(mount)
今天,我就先拿文件系统的mount操作开刀。
首先看一下mount操作的简单流程:
sys_mount //mount指定的设备
|-- copy_mount_options
|-- do_mount
// 开始进入到VFS层
//REMOUNT选项被指定的时候
|-- do_remount
|-- do_remount_sb //检查是否只读打开等
|-- fsync_super //调用s_op->write_super
|-- s_op->remount_fs //实施再mount处理
//BIND选项被指定的时候
|-- do_lookback
//REMOUNT/BIND以外的选项被指定的时候
|-- do_add_mount //mountpoint检查和读入super_block
|-- do_kernel_mount //权限检查
|-- get_sb_nodev //读入super_block
|-- fs_type->read_super //调用实际的super_block函数
// 下面进入到XFS文件系统层
|-- linvfs_read_super
|-- xfs_parseargs
|-- sb->s_op = &linvfs_sops;
|-- VFSOPS_MOUNT
|-- vfsops->vfs_mount
↓
xfs_vfsmount
↓
xfs_mount
↓
xfs_cmountfs
↓
xfs_readsb
↓
xfs_mountfs
上面的函数调用关系中的函数的意思这里不做详细说明。
在mount文件系统的关键地点就是从实际的文件系统上读取该文件系统的超级块,上面的调用关系的转折点就是fs_type->read_super函数,从这一刻开始就是开始做实际的操作。
但是,对于设计VFS层的设计人员来说,他并不知道今后,其他的开发人员会添加什么样的文件系统。也就是说,他不知道fs_type->read_super应该指向哪一个实际的读取超级块的函数。如果利用行为模式中的command模式,就可以实现这一点。
对于command模式中的主要角色是,Invoker,Command,ConcreteCommand,Receiver这四种。再利用这种设计模式时,VFS的设计人员就可以把VFS层作为命令的invoker,VFS层的一个函数操作(函数指针,例如,mount, read, write)就作为command, 而当用户想为内核再添加一个新型的文件系统时,,receiver就是该用户实际编写的文件系统,另外,用户还需要编写concrete_command作为调用实际的函数的接口。这种模式的结构如下:
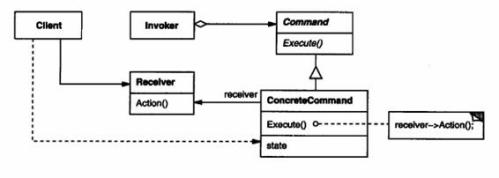
所以,对于VFS层的设计人员只需要设计Invoker(VFS类),Command类,在接受到来自用户空间的I/O请求时,只需要简单的调用Command类的Execute函数就可,而不用关心,该函数具体的是调用哪一个文件系统的实际操作函数。而设计实际文件系统的开发人员只需要从Command类派生一个具体的子类并重载Execute函数,就可以跟VFS层的接口对接。这样,就降低了VFS类和实际文件系统类的耦合,并提高VFS类和实际文件系本身的内聚,这正符合设计模式的思想。
简单的代码如下:
1
class mount
2
3
4
{
5
6
7
protected:
8
9
10


mount()
{}
11
12
13
public:
14
15
16
virtual ~mount()
{}
17
18
19
virtual void execute() = 0;
20
21
22
};
23
24
25
class vfs
{
26
27
28
public:
29
30
31
vfs()
{}
32
33
34
void vfs_mount()
{
35
36
37
mount* mnt = new xfs_mount(new xfs());
38
39
40
mnt->execute();
41
42
43

}
44
45
46
};
47
48
49
50
51
class xfs
52
53
54
{
55
56
57
public:
58
59
60
xfs()
{}
61
62
63
void do_mount()
{
64
65
66
cout << “mounted a XFS filesystem for device.” << endl;
67
68
69
}
70
71
72
};
73
74
75
76
77
class xfs_mount : public mount
78
79
80
{
81
82
83
public:
84
85
86
xfs_mount(xfs* filesystem)
{
87
88
89
_xfs = filesystem;
90
91
92
}
93
94
95
96
97
98
void execute()
{
99
100
101
_xfs->do_mount();
102
103
104
}
105
106
107
private:
108
109
110
xfs* _xfs;
111
112
113
114
115
};
116
117
但是,上述的代码中,vfs类的设计有一个很大的问题,
1
class vfs
{
2
3
4
public:
5
6
7
vfs()
{}
8
9
10
void vfs_mount()
{
11
12
13
mount* mnt = new xfs_mount(new xfs());
14
15
16
mnt->execute();
17
18
19
}
20
21
22
};
23
在vfs_mount函数的设计里,设计人员根据不知道mount的子类的名字,而且,实际的文件系统类的名字他就更不知道了,而且,这两个类的实例化应该由实际文件系统设计者来创建。所以,这里不能这样实现。那么,VFS层怎么能得到已经创建xfs_mount和xfs类的实例呢?这个也并不难,我们可以个把xfs_mount和xfs类看作是一个具体的产品(product),只需要在VFS层设计一个抽象的工厂类和一些抽象的产品类,这样就可以利用工厂方法把xfs_mount和xfs类的实例化延迟到,实际文件系统设计者编写的具体的工厂类中。所以,在vfs_mount()中,只需要得到一个具体的工厂类,就可以很轻松的创建了xfs_mount和xfs类了。而具体的工厂类是在内核初始化是被创建的,VFS层设计者只需要根据特定的参数来查找这个具体的工厂类的实例。那么在上述代码中加入工厂方法后的简单代码如下:
首先为xfs类设计抽象产品类,
因为要把xfs作为具体的产品,所以,它需要从fs类派生。
而mount类则作为xfs_mount类的抽象产品,这里就不用重复设计了。接下来,为设计抽象工厂类。
vfs类的改写后的例子如下:
而具体的xfs工厂类,则是在内核启动时,由模块初始化程序来创建具体的实例。这个实例应该被记录在内核的一个工厂列表中,这样在VFS层根据要挂载文件系统的类型(fstype)来从这个列表中搜索该实例。
那么,xfs文件系统设计者应该编写的具体工厂如下:
到此为止,文件系统的mount操作的基本框架都搭好了,umount操作的设计跟这个也差不多。
设计模式在Linux文件系统中的简单实现(源代码实现1)
设计模式在Linux文件系统中的简单实现(源代码实现2)
设计模式在Linux文件系统中的简单实现(源代码实现3)
编译方法和执行结果:
lymons@d3 ~/kernel
$ g++ mount.cpp -o mount
lymons@d3 ~/kernel
$ ./mount.exe xfs
booting BASE kernel, please waiting ...
with video=vesafb:ywrap,mtrr splash=silent vga=0x317
create VFS layer ... [OK]
create XFS filesystem ... [OK]
register XFS filesystem ... [OK]
mounted a XFS filesystem for device[8,1].
lymons@d3 ~/kernel
$ ./mount.exe cxfs
booting BASE kernel, please waiting ...
with video=vesafb:ywrap,mtrr splash=silent vga=0x317
create VFS layer ... [OK]
create XFS filesystem ... [OK]
register XFS filesystem ... [OK]
ERR: kernel not supporting filesystem type "cxfs"