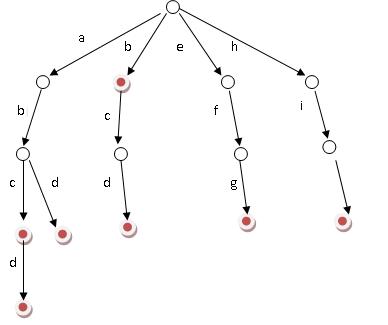
Trie,又称字典树、单词查找树,是一种树形结构,用于保存大量的字符串。它的优点是:利用字符串的公共前缀来节约存储空间。
相对来说,Trie树是一种比较简单的数据结构.理解起来比较简单,正所谓简单的东西也得付出代价.故Trie树也有它的缺点,Trie树的内存消耗非常大.当然,或许用左儿子右兄弟的方法建树的话,可能会好点.
其基本性质可以归纳为:
1. 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3. 每个节点的所有子节点包含的字符都不相同。
其基本操作有:查找 插入和删除,当然删除操作比较少见.我在这里只是实现了对整个树的删除操作,至于单个word的删除操作也很简单.
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
其他操作类似处理.

 /**//*
/**//*
 Name: Trie树的基本实现
Name: Trie树的基本实现
Author: MaiK
 Description: Trie树的基本实现 ,包括查找 插入和删除操作*/
Description: Trie树的基本实现 ,包括查找 插入和删除操作*/
 #include<algorithm>
#include<algorithm>
#include<iostream>
using namespace std;
const int sonnum=26,base='a';
struct Trie
 {
{
int num;//to remember how many word can reach here,that is to say,prefix
bool terminal;//If terminal==true ,the current point has no following point
struct Trie *son[sonnum];//the following point
};
Trie *NewTrie()// create a new node
{
Trie *temp=new Trie;
temp->num=1;temp->terminal=false;
for(int i=0;i<sonnum;++i)temp->son[i]=NULL;
return temp;
}
void Insert(Trie *pnt,char *s,int len)// insert a new word to Trie tree
{
Trie *temp=pnt;
for(int i=0;i<len;++i)

 {
{
if(temp->son[s[i]-base]==NULL)temp->son[s[i]-base]=NewTrie();
else temp->son[s[i]-base]->num++;
temp=temp->son[s[i]-base];
 }
}
temp->terminal=true;
}
void Delete(Trie *pnt)// delete the whole tree
{
if(pnt!=NULL)
{
for(int i=0;i<sonnum;++i)if(pnt->son[i]!=NULL)Delete(pnt->son[i]);
delete pnt;
pnt=NULL;
}
}
Trie* Find(Trie *pnt,char *s,int len)//trie to find the current word
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
if(temp->son[s[i]-base]!=NULL)temp=temp->son[s[i]-base];
else return NULL;
return temp;
}
转自:http://hi.baidu.com/luyade1987/blog/item/2667811631106657f2de320a.html