首先描述一下三个相关函数strcpy/strncpy、memcpy和memmove的意义。
众所周知的,strcpy/strncpy和memcpy都是用于从一块内存复制一段连续的数据到另一块内存,区别是终结标识不同。strcpy会比较每个字符是否为'\0'以判定是否继续复制,而memcpy就不管内存数据内容,确定复制指定的长度(不讨论源串有错误或者目的空间不够等出错的情况)。所以这两者在作用上是可以共通的,我想这两个函数最大的区别只能说是语义上的区别。而用法上,strcpy只能针对字符串,memcpy却没有这个限制,用memcpy(char*pDest,char*pSource,strlen(pSource))完全能替代strcpy的功能。
而后面两个mem系列函数,主要区别在memcpy对于重叠内存的复制支持不太好。例如对char a[10]操作的话,memcpy(a, a + 3, 5)这样的,源数据是a+3到a+7,目标位置是a到a+5,操作区域有重复,则应该用memmove。
好了,说明了这三个函数的作用,就进入本文讨论的正题:用memcpy替代strcpy/strncpy!
首先,从功能上来说,上文已经讨论过了,用memcpy(char*pDest,char*pSource,strlen(pSource))完全能替代strcpy的功能。之所以倡导这种用法,在于用memcpy函数不仅功能上比strcpy/strncpy更强大,关键在于前者效率要高很多!尽管没有这两个函数的源代码,但是单从分析上,strcpy\strncpy需要在每一步操作时都要比较字符是否为'\0',而memcpy完全不需要,甚至有更快的指令来优化块复制,所以效率肯定高很多。事实上,测试结果也是这样,测试程序如下:
 #include <string.h>
#include <string.h>
#include <windows.h>
int main(void)


 {
{
 char * pch = "常常有人问:我想学习内核,需要什么基础吗?LinusTorvalds本人是这样回答的:你必须使用过Linux。这个……还是有点太泛了吧,我想下面几个基础可能还是需要的,尽管不一定必需:1,关于操作系统理论的最初级的知识。不需要通读并理解《操作系统概念》《现代操作系统》等巨著,但总要知道分时(time-shared)和实时(real-time)的区别是什么,进程是个什么东西,CPU和系统总线、内存的关系(很粗略即可),等等。2,关于C语言。不需要已经很精通C语言,只要能熟练编写C程序,能看懂链表、散列表等数据结构的C实现,用过gcc编译器,就可以了。当然,如果已经精通C语言显然是大占便宜的。3,关于CPU的知识。这块儿可以在学习内核过程中补,但这样的话你就需要看讲解很详细的书,比方后面将会提到的《情景分析》。你是否熟悉Intel80386CPU?尝试着回答这几个问题来判断一下:1)说出80386的中断门和陷阱门的区别;2)说出保护模式与实模式的区别;3)多处理器机器上,普通的读-改-写回一块内存这样的动作,为什么需要特殊的手段来保护。等等。讲解基于其它CPU的Linux内核的书,目前好象只有一本《IA64Linux内核:设计与实现》──也还是Intel的,其它都是讲解基于IA32的。以上算是知识方面吧,如果还要再补充一条,我想就是:动手编译过内核。好了,我们接下来走。好多人装上Linux之后,第一件事找到内核源码所在的路径,打开一个C程序文件,开始哗哗哗翻页,看看大名鼎鼎的Linux内核代码到底长啥模样──然后关闭。这是可理解的,但却不是学习的方法。刚开始,必须从读书入手。[color=red:8c0c3b6f46]至少要对内核有一个Overview之后,才有可能带着问题去试图阅读源代码本身。[/color:8c0c3b6f46]下面就讲一下我读过的几本书:1,《Linux内核设计与实现》,英文名LinuxKernelDevelopment(所以有人叫它LKD),机械工业出版社,¥35,美国RobertLove著,陈莉君译者。评说:此书是当今首屈一指的入门最佳图书。作者是为2.6内核加入了抢占的人,对调度部分非常精通,而调度是整个系统的核心,因此本书是很权威的。这本书讲解浅显易懂,全书没有列举一条汇编语句,但是给出了整个Linux操作系统2.6内核的概观,使你能通过阅读迅速获得一个overview。而且对内核中较为混乱的部分(如下半部),它的讲解是最透彻的。对没怎么深入内核的人来说,这是强烈推荐的一本书。翻译:翻译水平、负责任程度都不错,但是印刷存在一些错误。买了此书的朋友可以参考我在Linux高级应用版的《Linux内核设计与实现中文版勘误》:\
char * pch = "常常有人问:我想学习内核,需要什么基础吗?LinusTorvalds本人是这样回答的:你必须使用过Linux。这个……还是有点太泛了吧,我想下面几个基础可能还是需要的,尽管不一定必需:1,关于操作系统理论的最初级的知识。不需要通读并理解《操作系统概念》《现代操作系统》等巨著,但总要知道分时(time-shared)和实时(real-time)的区别是什么,进程是个什么东西,CPU和系统总线、内存的关系(很粗略即可),等等。2,关于C语言。不需要已经很精通C语言,只要能熟练编写C程序,能看懂链表、散列表等数据结构的C实现,用过gcc编译器,就可以了。当然,如果已经精通C语言显然是大占便宜的。3,关于CPU的知识。这块儿可以在学习内核过程中补,但这样的话你就需要看讲解很详细的书,比方后面将会提到的《情景分析》。你是否熟悉Intel80386CPU?尝试着回答这几个问题来判断一下:1)说出80386的中断门和陷阱门的区别;2)说出保护模式与实模式的区别;3)多处理器机器上,普通的读-改-写回一块内存这样的动作,为什么需要特殊的手段来保护。等等。讲解基于其它CPU的Linux内核的书,目前好象只有一本《IA64Linux内核:设计与实现》──也还是Intel的,其它都是讲解基于IA32的。以上算是知识方面吧,如果还要再补充一条,我想就是:动手编译过内核。好了,我们接下来走。好多人装上Linux之后,第一件事找到内核源码所在的路径,打开一个C程序文件,开始哗哗哗翻页,看看大名鼎鼎的Linux内核代码到底长啥模样──然后关闭。这是可理解的,但却不是学习的方法。刚开始,必须从读书入手。[color=red:8c0c3b6f46]至少要对内核有一个Overview之后,才有可能带着问题去试图阅读源代码本身。[/color:8c0c3b6f46]下面就讲一下我读过的几本书:1,《Linux内核设计与实现》,英文名LinuxKernelDevelopment(所以有人叫它LKD),机械工业出版社,¥35,美国RobertLove著,陈莉君译者。评说:此书是当今首屈一指的入门最佳图书。作者是为2.6内核加入了抢占的人,对调度部分非常精通,而调度是整个系统的核心,因此本书是很权威的。这本书讲解浅显易懂,全书没有列举一条汇编语句,但是给出了整个Linux操作系统2.6内核的概观,使你能通过阅读迅速获得一个overview。而且对内核中较为混乱的部分(如下半部),它的讲解是最透彻的。对没怎么深入内核的人来说,这是强烈推荐的一本书。翻译:翻译水平、负责任程度都不错,但是印刷存在一些错误。买了此书的朋友可以参考我在Linux高级应用版的《Linux内核设计与实现中文版勘误》:\
另外,此书2005年有了第二版,目前尚无中译本面世。我就是对照着2nd-en勘误1st-cn的。2,《Linux内核源代码情景分析》上、下。毛德操、胡希明著,浙江大学出版社,上册¥80,下册¥70.评说:本书是基于2.4.0内核的,比较早,也没听说会出第二版。上册讲解内存管理、中断、异常与系统调用、进程控制、文件系统与传统UnixIPC;下册讲解socket、设备驱动、SMP和引导。关于这套书的评价褒贬不一,我个人认为其深度是同类著作中最优秀的。本书基于IntelIA32体系,由于厚度大,很多体系上的知识都捎带讲解了,所以如果你想深入了解内核的工作机制而又不非常熟悉IntelCPU的体系构造,本书是最合适的。缺点是:版本较老,没有TCP/IP协议栈部分(它讲的socket只是Unix域协议的),图表太少,不适合初学者入门。还有就是对学生朋友来说,可能书价偏高,这样的话可以考虑先买上册,因为上册是核心部分,下册一大部分都在讲具体PCI/ISA/USB设备的驱动。翻译:没什么翻译,作者是国人,而且行文流畅。本人书桌上诸多计算机经典图书当中,这套是唯一又经典又无阅读障碍的。www.linuxforum.net内核版好多朋友已经把这书读到六七遍了,我很惭愧,上册差不多读熟了,下册就SMP部分还看过──但这就花费了整整1年的时间,还有好多弄不懂的。这里顺便说明另外一个研究内核常见的误区:目标太庞大。要知道Linux内核(最新的2.6.13)bzip2压缩之后37M,解压缩之后244M,根本不是哪个人能够吃透的。即使是内核的核心开发团队中,恐怕也只LinusTorvalds、AlanCox、DavidMiller、IngoMolnar寥寥数人会有比较全面的了解,其它人都是做自己专门的部分。我自己来说,目前已经决定放弃内存管理的全部(slab层、LRU、rbtree等)、文件系统部分、外设驱动部分,暂时也没打算弄IA32以外的其它体系的部分。3,《深入理解Linux内核》第二版。中国电力出版社。也是陈莉君译。此书是Linux内核黑客在推荐图书时的首眩评说:此书C版的converse兄送了我一本第一版,因此就没买第二版,比较后悔。因此只就第一版说一说,第一版基于2.2,第二版2.4。我见O'Reilly官方主页上说第三版的英文版将于2005年11月出版,也不知咱们何时才能见到。此书图表很多,形象地给出了关键数据结构的定义,与《情景分析》相比,本书内容紧凑,不会一个问题讲解动辄上百页,有提纲挈领的功用,但是深度上要逊于《情景分析》。4,其它的几本书。市面上能见到的其它的Linux内核的图书,象《Linux设备驱动程序》、《Linux内核源代码完全注释》以及新出的《Linux内核分析及编程》等。《Linux设备驱动程序》第二版是基于2.4的,中文翻译不错,中国电力出版。这书强调动手实践,但它是讲解“设备驱动”的,不是最核心的东西,而且有些东西没硬件的话无法实践,可能更适合驱动开发的程序员吧,不太适合那些Forfunandprofit的人。此书有第三版英文版,东南大学出版社影印,讲解2.6的,行文流畅,讲解的面也比第二版更广泛,我读过其中关于同步与互斥、内存分配的部分,感觉很不错。《Linux内核源代码完全注释》(机械工业出版社)是同济大学的博士生赵炯的著作,讲解0.1Linux内核,我没买也没看,有看过的朋友说一说。《Linux内核分析及编程》(电子工业出版社)是刚刚出版的,国人写的,讲解2.6.11。很多人说好,但有人说不够系统,我没买,不敢评说。还有一本清华出的《Linux内核编程指南(第三版)》,原书应该是好书,但是翻译、排版十分糟烂,脱字跳行,根本没法看,我买了一本又扔掉了。5,其它资源。TLDP(TheLinuxDocumentationProject)有大量文档,其中不少是关于内核的,有些是在国外出版过的,象《LinuxKernelInterls》《TheLinuxKernel》《LinuxKernelModuleProgrammingGuide》等,作者都是亲身参加开发的人,著作较为可信。该版是研究内核的中文Linux社区中水平最高的,有很多专家级别的牛人,强烈推荐去学习一下(但建议不要问太过分简单的问题,人家脾气再好也会烦的^_^),它的置顶贴简直是一个包罗万象的FAQ,精华区也有很多资料。只可惜太过曲高和寡,人气不是很旺。6,一本不是讲解Linux的书:《现代体系结构上的Unix系统:内核程序员的SMP和Caching技术》,人民邮电出版社2003版,定价¥39.本书虽然不是讲解Linux,但是对所有Unix内核都是适用的,适合对SMP和CPU的Cache这些组成原理知识不是很熟的朋友,而且是很多国外牛人推荐的书。中文版翻译非常负责。还有个很重要的问题:怎样浏览内核源代码。有的朋友喜欢在Windows上工作,用SourceInsight;有的在Linux,用SourceNavigator;还有专门浏览源代码的软件,象lxr(LinuxCrossReference);还有用ctags/ectags/cscope等,这些都是很优秀的软件。我个人用Vim+ctags浏览(参考了www.linuxforum.net内核版wheelz大侠的文档,)。此外,前边已经提到的一个重要的问题是:你研究内核的目的是什么,开发?乐趣?如果是开发,而且是国内做开发,把kernelAPI熟悉一下就差不太多了(你也知道国内的水平有多差),比方说copy_from_user()、kmalloc()函数等,kernelAPI在Internet上找得到,编译内核时也可以用DocBook生成(具体请参考内核源代码包下的README文件);如果是研究,那就差别很大了,需要下很大的苦功:会用kmalloc()绝不说明你懂得Linux内核的虚存管理子系统,正如同会讲汉语不说明你懂中国文化一样";
int len = strlen(pch);
char * pDest = new char[len+1];
int number = 1000000;
printf("源字符串长度:%d;运行次数:%d次\n", len,number);
DWORD take = GetTickCount();
for (int i=0;i < number;++i)

 {
{
strcpy(pDest,pch);
 }
}
printf("strcpy消耗时间:%ldms\n", GetTickCount() - take);
take = GetTickCount();
for (int i=0;i < number;++i)
{
memcpy(pDest,pch,strlen(pch));
}
printf("memcpy算len消耗时间:%ldms\n", GetTickCount() - take);
take = GetTickCount();
for (int i=0;i < number;++i)
{
memcpy(pDest,pch,len);
}
printf("memcpy消耗时间:%ldms\n", GetTickCount() - take);
while(1);
return 0;
 }
}
运行结果如下:
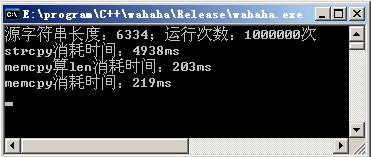
注:我的机器是Inter Core2 4G内存。编译器是Visual Studio2010。
由此可见,strcpy消耗的时间是memcpy消耗时间的24倍!
结论:倡导用memcpy替代strcpy/strncpy!