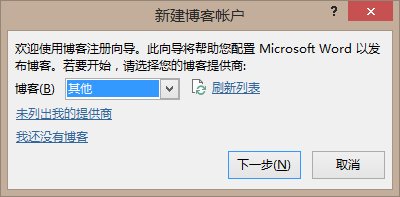
第一步:如果从未发布过博客文章的话,需要在菜单里面选这里添加博客账号

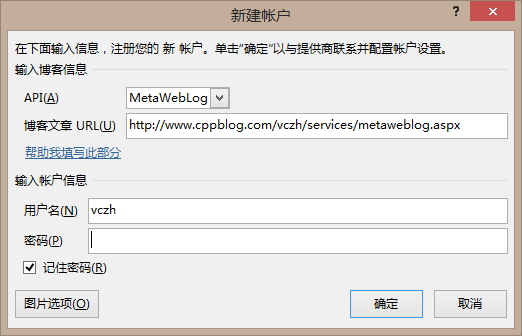
第二步:选择正确的设置
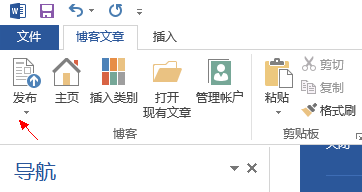
第三步:写完博客之后,按这里就可以发布了!
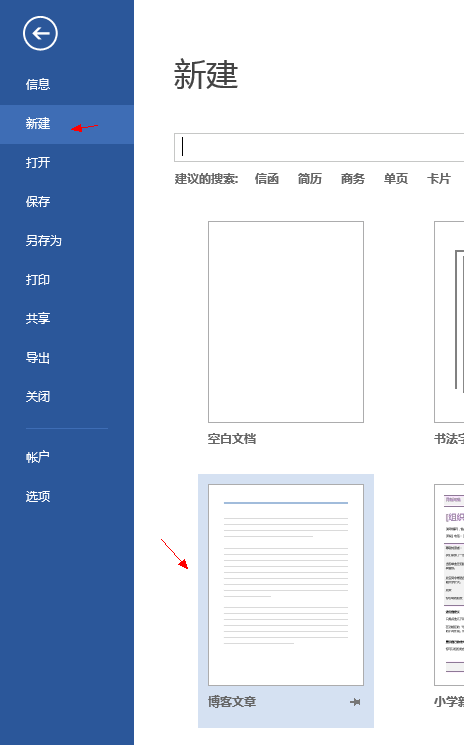
如果以后需要写新的博客的话,还可以直接点这里:
Word 2013就是简单好用啊,虽然Live Writer没有了,但是有了Word 2013,其实也是一样的。
posted @
2013-11-03 09:30 陈梓瀚(vczh) 阅读(5287) |
评论 (3) |
编辑 收藏大家看到这个标题肯定会欢呼雀跃了,以为功能少的语言就容易学。其实完全不是这样的。功能少的语言如果还适用范围广,那所有的概念必定是正交的,最后就会变得跟数学一样。数学的概念很正交吧,正交的东西都特别抽象,一点都不直观的。不信?出门转左看Haskell,还有抽象代数。因此删减语言的功能是需要高超的技巧的,这跟大家想的,还有跟go那帮人想的,可以断定完全不一样。
首先,我们要知道到底为什么需要删减功能。在这里我们首先要达成一个共识——人都是很贱的。一方面在发表言论的时候光面堂皇的表示,要以需求变更和可维护性位中心;另一方面自己写代码的时候又总是不惜“后来的维护者所支付的代价代价”进行偷懒。有些时候,人就是被语言惯坏的,所以需要对功能进行删减的同时,又不降低语言的表达能力,从而让做不好的事情变得更难(完全不让别人做不好的事情是不可能的),这样大家才会倾向于写出结构好的程序。
于是,语法糖到底是不是需要被删减的对象呢?显然不是。一个好的语言,采用的概念是正交的。尽管正交的概念可以在拼接处我们需要的概念的时候保持可维护性和解耦,但是往往这么做起来却不是那么舒服的,所以需要语法糖。那如果不是语法糖,到底需要删减什么呢?
这一集我们就来讨论面向对象的语言的事情,看看有什么是可以去掉的。
在面向对象刚刚流行起来的时候,大家就在讨论什么搭积木编程啊、is-a、has-a这些概念啊、面向接口编程啊、为什么硬件的互相插就这么容易软件就不行呢,然后就开始搞什么COM啊、SOA啊这些的确让插变得更容易,但是部署起来又很麻烦的东西。到底是什么原因造成OO没有想象中那么好用呢?
之所以会想起这个问题,其实是因为最近在我们研究院的工位上出现了一个相机的三脚架,这个太三脚架用来固定一个手机干点邪恶的事情,于是大家就围绕这个事情展开了讨论——譬如说为什么手机和三脚架是正交的,中间只要一个前凸后凹的用来插的小铁块就可以搞定,而软件就不行呢?
于是我就在想,这不就是跟所谓的面向接口编程一样,只要你全部东西都用接口,那软件组合起来就很简单了吗。这样就算刚好对不上,只要写个adaptor,就可以搞定了。其实这种做法我们现在还是很常见的。举个例子,有些时候我们需要Visual C++ 2013这款全球最碉堡的C++ IDE来开发世界上最好的复杂的软件,不过自带的那个cl.exe实在是算不上最好的。那怎么办,为了用一款更好的编译器,放弃这个IDE吗?显然不是。正确的解决方法是,买intel的icc,然后换掉cl.exe,然后一切照旧。
其实那个面向接口编程就有点这个意思。有些时候一个系统大部分是你所需要的,别人又不能满足,但是刚好这个系统的一个重要部分你手上又有更好的零件可以代替。那你是选择更好的零件,还是选择大部分你需要的周边工具呢?为什么就非得二选一呢?如果大家都是面向接口编程,那你只需要跟cl.exe换成icc一样,写个adaptor就可以上了。
好了,那接口是什么?其实这并没有什么深奥的理解,接口指的就是java和C#里面的那个interface,是很直白的。不知道为什么后来传着传着这条建议就跟一些封装偶合在一起,然后各种非面向对象语言就把自己的某些部分曲解为interface,成功地把“面向接口编程”变成了一句废话。
不过在说interface之前,有一个更简单但是可以类比的例子,就是函数和lambda expression了。如果一个语言同时存在函数和lambda expression,那么其实有一个是多余的——也就是函数了。一个函数总是可以被定义为初始化的时候给了一个lambda expression的只读变量。这里并不存在什么性能问题,因为这种典型的写法,编译器往往可以识别出来,最终把它优化成一个函数。当我们把一个函数名字当成表达式用,获得一个函数指针的时候,其实这个类型跟lambda expression并没有任何区别。一个函数就只有这两种用法,因此实际上把函数去掉,留下lambda expression,整个语言根本没有发生变化。于是函数在这种情况下就属于可以删减的功能。
那class和interface呢?跟上面的讨论类似,我主张class也是属于可以删减的功能之一,而且删减了的话,程序员会因为人类的本性而写出更好的代码。把class删掉其实并没有什么区别,我能想到的唯一的区别也就是class本身从此再也不是一个类型,而是一个函数了。这有关系吗?完全没有,你用interface就行了。
class和interface的典型区别就是,interface所有的函数都是virtual的,而且没有局部变量。class并不是所有的函数都是virtual的——java的函数默认virtual但是可以改,C++和C#则默认不virtual但是可以改。就算你把所有的class的函数都改成virtual,那你也会因此留下一些状态变量。这有什么问题呢?假设C++编译器是一个接口,而Visual C++和周边的工具则是依赖于这个class所创造出来的东西。如果你想把cl.exe替换成icc,实际上只要new一个新的icc就可以了。而如果C++编译器是一个class的话,你就不能替换了——就算class所有的函数都是virtual的,你也不可能给出一个规格相同而实现不同的icc——因为你已经被class所声明的构造函数、析构函数以及写好的一些状态变量(成员变量)所绑架了!
那我们可以想到的一个迫使大家都写出倾向于比以前更可以组合的程序,要怎么改造语言才可以呢?其实很简单,只需要不把class的名字看成一个类型,而把他看成一个函数就可以了。class本身有多个构造函数,其实也就是这个意思。这样的话,所有原本要用到class的东西,我们就会去定义一个接口了。而且这个接口往往会是最小化的,因为完全没有必要去声明一些用不到的函数。
于是跟去掉函数而留下匿名函数(也就是lambda expression)类似,我们也可以去掉class而留下匿名class的。Java有匿名class,所以我们完全不会感到这个概念有多么的陌生。于是我们可以来检查一下,这样会不会让我们丧失什么表达方法。
首先,是关于类的继承。我们有四种方法来使用类的继承。
1、类似于C#的Control继承出Button。这完全是接口规格的继承。我们继承出一个Button,不是为了让他去实现一个Control,而是因为Button比Control多出了一些新东西,而且直接体现在成员函数上面。因此在这个框架下,我们需要做的是IControl继承出IButton。
2、类似于C#的TextReader继承出StreamReader。StreamReader并不是为了给TextReader添加新功能,而是为了给TextReader指定一个来源——Stream。因此这更类似于接口和实现的区别。因此在这个框架下,我们需要的是用CreateStreamReader函数来创建一个ITextReader。
3、类似于C#的XmlNode继承出XmlElement。这纯粹是数据的继承关系。我们之所以这么做,不是因为class的用法是设计来这么用的,而是因为C++、Java或者C#并没有别的办法可以让我们来表达这些东西。在C里面我们可以用一个union加上一个enum来做,而且大家基本上都会这么做,所以我们可以看到这实际上是为了拿到一个tag来让我们知道如何解释那篇内存。但是C语言的这种做法只有大脑永远保持清醒的人可以使用,而且我们可以看到在函数式语言里面,Haskell、F#和Scala都有自己的一种独有的强类型的union。因此在这个框架下,我们需要做的是让struct可以继承,并且提供一个Nullable<T>(C#也可以写成T?)的类型——等价于指向struct的引用——来让我们表达“这里是一个关于数据的union:XmlNode,他只可能是XmlElement、XmlText、XmlCData等有限几种可能”。这完全不关class的事情。
4、在Base里面留几个纯虚函数,让Derived继承自Base并且填补他们充当回调使用——卧槽都知道是回调了为什么还要用class?设计模式帮我们准备好了Template Method Pattern,我们完全可以把这几个回调写在一个interface里面,让Base的构造函数接受这个interface,效果完全没有区别。
因此我们可以看到,干掉class留下匿名class,根本不会对语言的表达能力产生影响。而且这让我们可以把所有需要的依赖都从class转成interface。interface是很好adapt的。还是用Visual C++来举例子。我们知道cl.exe和icc都可以装,那gcc呢?cl.exe和icc是兼容的,而gcc完全是另一套。我们只需要简单地adapt一下(尽管有可能不那么简单,但总比完全不能做强多了),就可以让VC++使用gcc了。class和interface的关系也是类似的。如果class A依赖于class B,那这个依赖是绑死的。尽管class A我们很欣赏,但是由于class B实现得太傻比从而导致我们必须放弃class A这种事情简直是不能接受的。如果class A依赖于interface IB,就算他的缺省实现CreateB()函数我们不喜欢,我们可以自己实现一个CreateMyB(),从而吧我们自己的IB实现给class A,这样我们又可以提供更好的B的同时不需要放弃我们很需要的A了。
不过其实每次CreateA(CreateMyB())这种事情来得到一个IA的实现也是很蠢得,优点化神奇为腐朽的意思。不过这里就是IoC——Inverse of Control出场的地方了。这完全是另一个话题,而且Java和C#的一些类库(包括我的GacUI)已经深入的研究了IoC、正确使用了它并且发挥得淋漓尽致。这就是另一个话题了。如何用好interface,跟class是否必须是类型,没什么关系。
但是这样做还有一个小问题。假设我们在写一个UI库,定义了IControl并且有一个函数返回了一个IControl的实现,那我们在开发IButton和他的实现的时候,要如何利用IControl的实现呢?本质上来说,其实我们只需要创造一个IControl的实现x,然后把IButton里面所有原本属于IControl的函数都重定向到这个x上面去,就等价于继承了。不过这个写起来就很痛苦了,因此我们需要一个语法糖来解决它,传说中的Mixin就可以上场了。不知道Mixin?这种东西跟prototype很接近但是实际上他不是prototype,所以类似的想法经常在javascript和ruby等动态语言里面出现。相信大家也不会陌生。
上面基本上论证了把class换成匿名class的可能性(完全可能),和他对语言表达能力的影响(毫无影响),以及他对系统设计的好处(更容易通过人类的人性的弱点来引导我们写出比现在更加容易解耦的系统)。尽管这不是银弹,但显然比现在的做法要强多了。最重要的是,因为class不是一个类型,所以你没办法从IX强转成XImpl了,于是我们只能够设计出不需要知道到底谁实现了IX的算法,可靠性迅速提高。如果IY继承自IX的话,那IX可以强转成IY就类似于COM的QueryInterface一样,从“查看到底是谁实现的”升华到了“查看这个IX是否具有IY所描述的功能”,不仅B格提高了,而且会让你整个软件的质量都得到提高。
因此把class换成匿名class,让原本正确使用OO的人更容易避免无意识的偷懒,让原本不能正确使用OO的人迅速掌握如何正确使用OO,封死了一大堆因为偷懒而破坏质量的后门,具有相当的社会意义(哈哈哈哈哈哈哈哈)。
我之所以写这篇文章是为了告诉大家,通过删减语言的功能来让语言变得更好完全是可能的。但这并不意味着你能通过你自己的口味、偷懒的习惯、B格、因为智商低而学不会等各种奇怪的理由来衡量一个语言的功能是否应该被删除。只有冗余的东西在他带来危害的时候,我们应该果断删除它(譬如在有interface前提下的class)。而且通常我们为了避免正交的概念所本质上所不可避免的增加理解难度所带来的问题,我们还需要相应的往语言里面加入语法糖或者新的结构(匿名class、强类型union等)。让语言变得更简单从来不是我们的目标,让语言变得更好用才是。而且一个语言不容易学会的话,我们有各种方法可以解决——譬如说增加常见情况下可以解决问题的语法糖、免费分享知识、通过努力提高自己的智商(虽然有一部分人会因此感到绝望不过反正社会上有那么多职业何必非得跟死程死磕)等等有效做法。
于是在我自己设计的脚本里面,我打算全面实践这个想法。
posted @
2013-10-19 05:51 陈梓瀚(vczh) 阅读(9611) |
评论 (17) |
编辑 收藏几个月前就一直有博友关心DSL的问题,于是我想一想,我在gac.codeplex.com里面也创建了一些DSL,于是今天就来说一说这个事情。
创建DSL恐怕是很多人第一次设计一门语言的经历,很少有人一开始上来就设计通用语言的。我自己第一次做这种事情是在高中写这个傻逼ARPG的时候了。当时做了一个超简单的脚本语言,长的就跟汇编差不多,虽然每一个指令都写成了调用函数的形态。虽然这个游戏需要脚本在剧情里面控制一些人物的走动什么的,但是所幸并不复杂,于是还是完成了任务。一眨眼10年过去了,现在在写GacUI,为了开发的方便,我自己做了一些DSL,或者实现了别人的DSL,渐渐地也明白了一些设计DSL的手法。不过在讲这些东西之前,我们先来看一个令我们又爱(对所有人)又恨(反正我不会)的DSL——正则表达式!
一、正则表达式
正则表达式可读性之差我们人人都知道,而且正则表达式之难写好都值得O’reilly出一本两厘米厚的书了。根据我的经验,只要先学好编译原理,然后按照.net的规格自己撸一个自己的正则表达式,基本上这本书就不用看了。因为正则表达式之所以要用奇怪的方法去写,只是因为你手上的引擎是那么实现的,所以你需要顺着他去写而已,没什么特别的原因。而且我自己的正则表达式拥有DFA和NFA两套解析器,我的正则表达式引擎会通过检查你的正则表达式来检查是否可以用DFA,从而可以优先使用DFA来运行,省去了很多其实不是那么重要的麻烦(譬如说a**会傻逼什么的)。这个东西我自己用的特别开心,代码也放在gac.codeplex.com上面。
正则表达式作为一门DSL是当之无愧的——因为它用了一种紧凑的语法来让我们可以定义一个字符串的集合,并且取出里面的特征。大体上语法我还是很喜欢的,我唯一不喜欢的是正则表达式的括号的功能。括号作为一种指定优先级的方法,几乎是无法避免使用的。但是很多流行的正则表达式的括号竟然还带有捕获的功能,实在是令我大跌眼镜——因为大部分时候我是不需要捕获的,这个时候只会浪费时间和空间去做一些多余的事情而已。所以在我自己的正则表达式引擎里面,括号是不捕获的。如果要捕获,就得用特殊的语法,譬如说(<name>pattern)把pattern捕获到一个叫做name的组里面去。
那我们可以从正则表达式的语法里面学到什么DSL的设计原则呢?我认为,DSL的原则其实很简单,只有以下三个:
- 短的语法要分配给常用的功能
- 语法要么可读性特别好(从而比直接用C#写直接),要么很紧凑(从而比直接用C#写短很多)
- API要容易定义(从而用C#调用非常方便,还可以确保DSL的目标是明确又简单的)
很多DSL其实都满足这个定义。SQL就属于API简单而且可读性好的那一部分(想想ADO.NET),而正则表达式就属于API简单而且语法紧凑的那一部分。为什么正则表达式可以设计的那么紧凑呢?现在让我们来一一揭开它神秘的面纱。
正则表达式的基本元素是很少的,只有连接、分支和循环,还有一些简单的语法糖。连接不需要字符,分支需要一个字符“|”,循环也只需要一个字符“+”或者“*”,还有代表任意字符的“.”,还有代表多次循环的{5,},还有代表字符集合的[a-zA-Z0-9_]。对于单个字符的集合来讲,我们甚至不需要[],直接写就好了。除此之外因为我们用了一些特殊字符所以还得有转义(escaping)的过程。那让我们数数我们定义了多少字符:“|+*[]-\{},.()”。用的也不多,对吧。
尽管看起来很乱,但是正则表达式本身也有一个严谨的语法结构。关于我的正则表达式的语法树定义可以看这里:https://gac.codeplex.com/SourceControl/latest#Common/Source/Regex/RegexExpression.h。在这里我们可以整理出一个语法:
DIGIT ::= [0-9]
LITERAL ::= [^|+*\[\]\-\\{}\^,.()]
ANY_CHAR ::= LITERAL | "^" | "|" | "+" | "*" | "[" | "]" | "-" | "\" | "{" | "}" | "," | "." | "(" | ")"
CHAR
::= LITERAL
::= "\" ANY_CHAR
CHARSET_COMPONENT
::= CHAR
::= CHAR "-" CHAR
CHARSET
::= CHAR
::= "[" ["^"] { CHARSET_COMPONENT } "]"
REGEX_0
::= CHARSET
::= REGEX_0 "+"
::= REGEX_0 "*"
::= REGEX_0 "{" { DIGIT } ["," [ { DIGIT } ]] "}"
::= "(" REGEX_2 ")"
REGEX_1
::= REGEX_0
::= REGEX_1 REGEX_0
REGEX_2
::= REGEX_1
::= REGEX_2 "|" REGEX_1
REGULAR_EXPRESSION
::= REGEX_2这只是随手写出来的语法,尽管可能不是那么严谨,但是代表了正则表达式的所有结构。为什么我们要熟练掌握EBNF的阅读和编写?因为当我们用EBNF来看待我们的语言的时候,我们就不会被愈发的表面所困扰,我们会投过语法的外衣,看到语言本身的结构。脱别人衣服总是很爽的。
于是我们也要透过EBNF来看到正则表达式本身的结构。其实这是一件很简单的事情,只要把EBNF里面那些“fuck”这样的字符字面量去掉,然后规则就会分为两种:
1:规则仅由终结符构成——这是基本概念,譬如说上面的CHAR什么的。
2:规则的构成包含非终结符——这就是一个结构了。
我们甚至可以利用这种方法迅速从EBNF确定出我们需要的语法树长什么样子。具体的方法我就不说了,大家自己联系一下就会悟到这个简单粗暴的方法了。但是,我们在设计DSL的时候,是要反过来做的。首先确定语言的结构,翻译成语法树,再翻译成不带“fuck”的“骨架EBNF”,再设计具体的细节写成完整的EBNF。
看到这里大家会觉得,其实正则表达式的结构跟四则运算式子是没有区别的。正则表达式的*是后缀操作符,|是中缀操作符,连接也是中最操作符——而且操作符是隐藏的!我猜perl系正则表达式的作者当初在做这个东西的时候,肯定纠结过“隐藏的中缀操作符”应该给谁的问题。不过其实我们可以通过收集一些素材,用不同的方案写出正则表达式,最后经过统计发现——隐藏的中缀操作符给连接操作是最靠谱的。
为什么呢?我们来举个例子,如果我们把连接和分支的语法互换的话,那么原本“fuck|you”就要写成“(f|u|c|k)(y|o|u)”了。写多几个你会发现,的确连接是比分支更常用的,所以短的那个要给连接,所以连接就被分配了一个隐藏的中缀操作符了。
上面说了这么多废话,只是为了说明白一个道理——要先从结构入手然后才设计语法,并且要把最短的语法分配给最常用的功能。因为很多人设计DSL都反着来,然后做成了屎。
二、Fpmacro
第二个要讲的是Fpmacro。简单来说,Fpmacro和C++的宏是类似的,但是C++的宏是从外向内展开的,这意味着dynamic scoping和call by name。Fpmacro是从内向外展开的,这意味着lexical scoping和call by value。这些概念我在第七篇文章已经讲了,大家也知道C++的宏是一件多么不靠谱的事情。但是为什么我要设计Fpmacro呢?因为有一天我终于需要类似于Boost::Preprocessor那样子的东西了,因为我要生成类似这样的代码。但是C++的宏实在是太他妈恶心了,恶心到连我都不能驾驭它。最终我就做出了Fpmacro,于是我可以用这样的宏来生成上面提到的文件了。
我来举个例子,如果我要生成下面的代码:
int a1 = 1;
int a2 = 2;
int a3 = 3;
int a4 = 4;
cout<<a1<<a2<<a3<<a4<<endl;
就要写下面的Fpmacro代码:
$$define $COUNT 4 /*定义数量:4*/
$$define $USE_VAR($index) a$index /*定义变量名字,这样$USE_VAR(10)就会生成“a10”*/
$$define $DEFINE_VAR($index) $$begin /*定义变量声明,这样$DEFINE_VAR(10)就会生成“int a10 = 10;”*/
int $USE_VAR($index) = $index;
$( ) /*用来换行——会多出一个多余的空格不过没关系*/
$$end
$loop($COUNT,1,$DEFINE_VAR) /*首先,循环生成变量声明*/
cout<<$loopsep($COUNT,1,$USE_VAR,<<)<<endl; /*其次,循环使用这些变量*/
顺便,Fpmacro的语法在这里,FpmacroParser.h/cpp是由这个语法生成的,剩下的几个文件就是C++的源代码了。不过因为今天讲的是如何设计DSL,那我就来讲一下,我当初为什么要把Fpmacro设计成这个样子。
在设计之前,首先我们需要知道Fpmacro的目标——设计一个没有坑的宏,而且这个宏还要支持分支和循环。那如何避免坑呢?最简单的方法就是把宏看成函数,真正的函数。当我们把一个宏的名字当成参数传递给另一个宏的时候,这个名字就成为了函数指针。这一点C++的宏是不可能完全的做到的,这里的坑实在是太多了。而且Boost::Preprocessor用来实现循环的那个技巧实在是我操太他妈难受了。
于是,我们就可以把需求整理成这样:
- Fpmacro的代码由函数组成,每一个函数的唯一目的都是生成C++代码的片段。
- 函数和函数之间的空白可以用来写代码。把这些代码收集起来就可以组成“main函数”了,从而构成Fpmacro代码的主体。
- 函数可以有内部函数,在代码复杂的时候可以充当一些namespace的功能,而且内部函数都是私有的。
- Fpmacro代码可以include另一份Fpmacro代码,可以实现全局配置的功能。
- Fpmacro必须支持分支和循环,而且他们的语法和函数调用应该一致。
- 用来代表C++代码的部分需要的转义应该降到最低。
- 即使是非功能代码部分,括号也必须配对。这是为了定义出一个清晰的简单的语法,而且因为C++本身也是括号配对的,所以这个规则并没有伤害。
- C++本身对空格是有很高的容忍度的,因此Fpmacro作为一个以换行作为分隔符的语言,并不需要具备特别精确的控制空格的功能。
为什么要强调转义呢?因为如果用Fpmacro随便写点什么代码都要到处转义的话,那还怎么写得下去呀!
这个时候我们开始从结构入手。Fpmacro的结构是简单的,只有下面几种:
- 普通C++代码
- 宏名字引用
- 宏调用
- 连接
- 括号
- 表达数组字面量(最后这被证明是没有任何意义的功能)
根据上面提到的DSL三大原则,我们要给最常用的功能配置最短的语法。那最短的功能是什么呢?跟正则表达式一样,是连接。所以要给他一个隐藏的中缀运算符。其次就要考虑到转义了。如果Fpmacro大量运用的字符与C++用到的字符一样,那么我们在C++里面用这个字符的时候,就得转义了。这个是绝对不能接受的。我们来看看键盘,C++没用到的也就只有@和$了。这里我因为个人喜好,选择了$,它的功能大概跟C++的宏里面的#差不多。
那我们如何知道我们的代码片段是访问一个C++的名字,还是访问一个Fpmacro的名字呢?为了避免转义,而且也顺便可以突出Fpmacro的结构本身,我让所有的Fpmacro名字都要用$开头,无论是函数名还是参数都一样。于是定义函数就用$$define开始,而且多行的函数还要用$$begin和$$end来提示(见上面的例子)。函数调用就可以这么做:$名字(一些参数)。因为不管是参数名还是函数名都是$开头的,所以函数调用肯定也是$开头的。那写出来的代码真的需要转义怎么办呢?直接用$(字符)就行了。这个时候我们可以来检查一下这样做是不是会定义出歧义的语法,答案当然是不会。
我们定义了$作为Fpmacro的名字前缀之后,是不是一个普通的C++代码(因此没有$),直接贴上去就相当于一个Fpmacro代码呢?结论当然是成立的。仔细选择这些语法可以让我们在只想写C++的时候可以专心写C++而不会被各种转义干扰到(想想在C++里面写正则表达式的那一堆斜杠卧槽)。
到了这里,就到了最关键的一步了。那我们把一个Fpmacro的名字传递给参数的时候,究竟是什么意思呢?一个Fpmacro的名字,要么就是一个字符串,要么就是一个Fpmacro函数,不会有别的东西了(其实还可能是数组,但是最后证明没用)。这个纯洁性要一直保持下去。就跟我们在C语言里面传递一个函数指针一样,不管传递到了哪里,我们都可以随时调用它。
那Fpmacro的函数到底有没有包括上下文呢?因为Fpmacro和pascal一样有“内部函数”,所以当然是要有上下文的。但是Fpmacro的名字都是只读的,所以只用shared_ptr来记录就可以了,不需要出动GC这样的东西。关于为什么带变量的闭包就必须用GC,这个大家可以去想一想。这是Fpmacro的函数像函数式语言而不是C语言的一个地方,这也是为什么我把名字写成了Fpmacro的原因了。
不过Fpmacro是不带lambda表达式的,因为这样只会把语法搞得更糟糕。再加上Fpmacro允许定义内部函数和Fpmacro名字是只读的这两条规则,所有的lambda表达式都可以简单的写成一个内部函数然后赋予它一个名字。因此这一点没有伤害。那什么时候需要传递一个Fpmacro函数呢进另一个函数呢?当然就只有循环了。Fpmacro的内置函数有分支循环还有简单的数值计算和比较功能。
我们来做一个小实验,生成下面的代码:
void Print(int a1)
{
cout<<"1st"<<a1<<endl;
}
void Print(int a1, int a2)
{
cout<<"1st"<<a1<<", "<<"2nd"<<a2<<endl;
}
....
void Print(int a1, int a2, ... int a10)
{
cout<<...<<"10th"<<a10<<endl;
}
....我们需要两重循环,第一重是生成Print,第二重是里面的cout。cout里面还要根据数字来产生st啊、nd啊、rd啊、这些前缀。于是我们可以开始写了。Fpmacro的写法是这样的,因为没有lambda表达式,所以循环体都是一些独立的函数。于是我们来定义一些函数来生成变量名、参数定义和cout的片段:
$$define $VAR_NAME($index) a$index /*$VAR_NAME(3) -> a3*/
$$define $VAR_DEF($index) int $VAR_NAME($index) /*$VAR_DEF(3) -> int a3*/
$$define $ORDER($index) $$begin /*$ORDER(3) -> 3rd*/
$$define $LAST_DIGIT $mod($index,10)
$index$if($eq($LAST_DIGIT,1),st,$if($eq($LAST_DIGIT,2),nd,$if($eq($LAST_DIGIT,3),rd,th)))
$$end
$$define $OUTPUT($index) $(")$ORDER($index)$(")<<$VAR_NAME($index) /*$OUTPUT(3) -> "3rd"<<a3*/接下来就是实现Print函数的宏:
$$define $PRINT_FUNCTION($count) $$begin
void Print($loopsep($count,1,$VAR_DEF,$(,)))
{
cout<<$loopsep($count,1,$OUTPUT,<<)<<endl;
}
$( )
$$end最后就是生成整片代码了:
$define $COUNT 10 /*就算是20,那上面的代码的11也会生成11st,特别方便*/
$loop($COUNT,1,$PRINT_FUNCTION)
注意:注释其实是不能加的,因为如果你加了注释,这些注释最后也会被生成成C++,所以上面那个$COUNT就会变成10+空格+注释,他就不能放进$loop函数里面了。Fpmacro并没有添加“Fpmacro注释”的代码,因为我觉得没必要
为什么我们不需要C++的宏的#和##操作呢?因为在这里,A(x)##B(x)被我们处理成了$A(x)$B(x),而L#A(x)被我们处理成了L$(“)$A(x)$(“)。虽然就这么看起来好像Fpmacro长了一点点,但是实际上用起来是特别方便的。$这个前缀恰好帮我们解决了A(x)##B(x)的##的问题,写的时候只需要直接写下去就可以了,譬如说$ORDER里面的$index$if…。
那么这样做到底行不行呢?看在Fpmacro可以用这个宏来生成这么复杂的代码的份上,我认为“简单紧凑”和“C++代码几乎不需要转义”和“没有坑”这三个目标算是达到了。DSL之所以为DSL就是因为我们是用它来完成特殊的目的的,不是general purpose的,因此不需要太复杂。因此设计DSL要有一个习惯,就是时刻审视一下,我们是不是设计了多余的东西。现在我回过头来看,Fpmacro支持数组就是多余的,而且实践证明,根本没用上。
大家可能会说,代码遍地都是$看起来也很乱啊?没关系,最近我刚刚搞定了一个基于语法文件驱动的自动着色和智能提示的算法,只需要简单地写一个Fpmacro的编辑器就可以了,啊哈哈哈哈。
三、尾声
本来我是想举很多个例子的,还有语法文件啊,GUI配置啊,甚至是SQL什么的。不过其实设计一个DSL首先要求你对领域本身有着足够的理解,在长期的开发中已经在这个领域里面感受到了极大的痛苦,这样你才能真的设计出一个专门根除痛点的DSL来。
像正则表达式,我们都知道手写字符串处理程序经常要人肉做错误处理和回溯等工作,正则表达式帮我们自动完成了这个功能。
C++的宏生成复杂代码的时候,动不动就会因为dynamic scoping和call by name掉坑里而且还没有靠谱的工具来告诉我们究竟要怎么做,Fpmacro就解决了这个问题。
开发DSL需要语法分析器,而且带Visitor模式的语法树可扩展性好但是定义起来特别的麻烦,所以我定义了一个语法文件的格式,写了一个ParserGen.exe(代码在这里)来替我生成代码。Fpmacro的语法分析器就是这么生成出来的。
GUI的构造代码写起来太他妈烦了,所以还得有一个配置的文件。
查询数据特别麻烦,而且就算是只有十几个T的小型数据库也很难自己设计一个靠谱的容器,所以我们需要SQLServer。这个DSL做起来不简单,但是用起来简单。这也是一个成功的DSL。
类似的,Visual Studio为了生成代码还提供了T4这种模板文件。这个东西其实超好用的——除了用来生成C++代码,所以我还得自己撸一个Fpmacro……
用MVC的方法来写HTML,需要从数据结构里面拼HTML。用过php的人都知道这种东西很容易就写成了屎,所以Visual Studio里面又在ASP.NET MVC里面提供了razor模板。而且他的IDE支持特别号,razor模板里面可以混着HTML+CSS+Javascript+C#的代码,智能提示从不出错!
还有各种数不清的配置文件。我们都知道,一个强大的配置文件最后都会进化成为lisp,哦不,DSL的。
这些都是DSL,用来解决我们的痛点的东西,而且他本身又不足以复杂到用来完成程序所有的功能(除了连http service都能写的SQLServer我们就不说了=_=)。设计DSL的时候,首先要找到痛点,其次要理清楚DSL的结构,然后再给他设计一个要么紧凑要么可读性特别高的语法,然后再给一个简单的API,用起来别提多爽了。
posted @
2013-09-15 17:26 陈梓瀚(vczh) 阅读(8718) |
评论 (11) |
编辑 收藏类型是了解编程语言的重要一环。就算是你喜欢动态类型语言,为了想实现一个靠谱的东西,那也必须了解类型。举个简单的例子,我们都知道+和-是对称的——当然这只是我们的愿望了,在javascript里面,"1"+2和"1"-2就不是一回事。这就是由于不了解类型的操作而犯下的一些滑稽的错误。什么,你觉得因为"1"的类型是string所以"1"+2就应该是"12"?啐!"1"的类型是(string | number),这才是正确的做法。
了解编程语言的基本原理并不意味着你一定要成为一名编译器的前端,正如同学习Haskell可以让你的C++写得更好一样,如果你知道怎么设计一门语言,那遇到语言里面的坑,你十有八九可以当场看到,不会跳进去。当然了,了解编程语言的前提是你是一个优秀的程序员,至少要写程序,对吧。于是我这里推荐几门语言是在此之前要熟悉的。编程语言有好多种,每一种都有其代表作,为了开开眼界,知道编程语言可以设计成什么样子,你至少应该学会:
- C++
- C#
- F#
- Haskell
- Ruby
- Prolog
其实这一点也不多,因为只是学会而已,知道那些概念就好了,并不需要你成为一个精通xx语言的人。那为了了解类型你应该学会什么呢?没错——就是C++了!很多人可能不明白,为什么长得这么难看的C++竟然有这么重要的作用呢?其实如果详细了解了程序设计语言的基本原理之后,你会发现,C++在除了兼容那个可怜的C语言之外的那些东西,是设计的非常科学的。当然现在讲这些还太早,今天的重点是类型。
如果你们去看相关的书籍或者论文的话,你们会发现类型这个领域里面有相当多的莫名其妙的类型系统,或者说名词。对于第一次了解这个方面的人来说,熟练掌握Haskell和C++是很有用的,因为Haskell可以让你真正明白类型在程序里面的重要做哟的同时。几乎所有流行的东西都可以在C++里面找到,譬如说:
- 面向对象→class
- polymorphic type→template
- intersection type→union / 函数重载
- dependent type→带数字的模板类型
- System F→在泛型的lambda表达式里面使用decltype(看下面的例子)
- sub typing的规则→泛型lambda表达式到函数指针的隐式类型转换
等等等等,因有尽有,取之不尽,用之不竭。你先别批判C++,觉得他东西多所以糟糕。事实是,只要编译器不用你写,那一门语言是不可能通过拿掉feature来使它对你来说变得更牛逼的。不知道为什么有那么多人不了解这件事情,需要重新去念一念《形式逻辑》,早日争取做一个靠谱的人。
泛型lambda表达式是C++14(没错,是14,已经基本敲定了)的内容,应该会有很多人不知道,我在这里简单地讲一下。譬如说要写一个lambda表达式来计算一个容器里所有东西的和,但是你却不知道容器和容器里面装的东西是什么。当然这种情况也不多,但是有可能你需要把这个lambda表达使用在很多地方,对吧,特别是你#include <algorithm>用了里面超好用的函数之后,这种情况就变得常见了。于是这个东西可以这么写:
auto lambda = [](const auto& xs)
{
decltype(*xs.begin()) sum = 0;
for(auto x : xs)
{
sum += x;
}
return sum;
};于是你就可以这么用了:
vector<int> a = { ... };
list<float> b = { ... };
deque<double> c = { ... };
int sumA = lambda(a);
float sumB = lambda(b);
double sumC = lambda(c);然后还可以应用sub typing的规则把这个lambda表达式转成一个函数指针。C++里面所有中括号不写东西的lambda表达式都可以被转成一个函数指针的,因为他本来就可以当成一个普通函数,只是你为了让业务逻辑更紧凑,选择把这个东西写在了你的代码里面而已:
doube(*summer)(const vector<double>&);
summer = lambda;
只要搞明白了C++之后,那些花里胡俏的类型系统的论文的概念并不难理解。他们深入研究了各种类型系统的主要原因是要做系统验证,证明这个证明那个。其实编译器的类型检查部分也可以当成是一个系统验证的程序,他要检查你的程序是不是有问题,于是首先检查系统。不过可惜的是,除了Haskell以外的其他程序语言,就算你过了类型系统检查,也不见得你的程序就是对的。当然了,对于像javascript这种动态类型就罢了还那么多坑(ruby在这里就做得很好)的语言,得通过大量的自动化测试来保证。没有类型的帮助,要写出同等质量的程序,需要花的时间要更多。什么?你不关心质量?你不要当程序员了!是因为老板催得太紧?我们Microsoft最近有招聘了,快来吧,可以慢慢写程序!
不过正因为编译器会检查类型,所以我们其实可以把一个程序用类型武装起来,使得错误的写法会变成错误的语法被检查出来了。这种事情在C++里面做尤为方便,因为它支持dependent type——好吧,就是可以在模板类型里面放一些不是类型的东西。我来举一个正常人都熟练掌握的例子——单位。
一、类型检查(type rich programming)
我们都知道物理的三大基本单位是米、秒和千克,其它东西都可以从这些单位拼出来(大概是吧,我忘记了)。譬如说我们通过F=ma可以知道力的单位,通过W=FS可以知道功的单位,等等。然后我们发现,单位之间的关系都是乘法的关系,每个单位还带有自己的幂。只要弄清楚了这一点,那事情就很好做了。现在让我们来用C++定义单位:
template<int m, int s, int kg>
struct unit
{
double value;
unit():value(0){}
unit(double _value):value(_value){}
};好了,现在我们要通过类型系统来实现几个操作的约束。对于乘除法我们要自动计算出单位的同时,加减法必须在相同的单位上才能做。其实这样做还不够完备,因为对于任何的单位x来讲,他们的差单位Δx还有一些额外的规则,就像C#的DateTime和TimeSpan一样。不过这里先不管了,我们来做出加减乘除几个操作:
template<int m, int s, int kg>
unit<m, s, kg> operator+(unit<m, s, kg> a, unit<m, s, kg> b)
{
return a.value + b.value;
}
template<int m, int s, int kg>
unit<m, s, kg> operator-(unit<m, s, kg> a, unit<m, s, kg> b)
{
return a.value - b.value;
}
template<int m, int s, int kg>
unit<m, s, kg> operator+(unit<m, s, kg> a)
{
return a.value;
}
template<int m, int s, int kg>
unit<m, s, kg> operator-(unit<m, s, kg> a)
{
return -a.value;
}
template<int m1, int s1, int kg1, int m2, int s2, int kg2>
unit<m1+m2, s1+s2, kg1+kg2>operator*(unit<m1, s1, kg1> a, unit<m2, s2, kg2> b)
{
return a.value * b.value;
}
template<int m1, int s1, int kg1, int m2, int s2, int kg2>
unit<m1-m2, s1-s2, kg1-kg2>operator/(unit<m1, s1, kg1> a, unit<m2, s2, kg2> b)
{
return a.value / b.value;
}但是这个其实还不够,我们还需要带单位的值乘以或除以一个系数的代码。为什么不能加减呢?因为不同单位的东西本来就不能加减。系数其实是可以描写成unit<0, 0, 0>的,但是为了让代码更紧凑,于是多定义了下面的四个函数:
template<int m, int s, int kg>
unit<m, s, kg> operator*(double v, unit<m, s, kg> a)
{
return v * a.value;
}
template<int m, int s, int kg>
unit<m, s, kg> operator*(unit<m, s, kg> a, double v)
{
return a.value * v;
}
template<int m, int s, int kg>
unit<m, s, kg> operator/(double v, unit<m, s, kg> a)
{
return v / a.value;
}
template<int m, int s, int kg>
unit<m, s, kg> operator/(unit<m, s, kg> a, double v)
{
return a.value / v;
}我们已经用dependent type之间的变化来描述了带单位的量的加减乘除的规则。这看起来好像很复杂,但是一旦我们加入了下面的新的函数,一切将变得简单明了:
constexpr unit<1, 0, 0> operator""_meter(double value)
{
return value;
}
constexpr unit<0, 1, 0> operator""_second(double value)
{
return value;
}
constexpr unit<0, 0, 1> operator""_kilogram(double value)
{
return value;
}
constexpr unit<1, -2,1> operator""_N(double value) // 牛不知道怎么写-_-
{
return value;
}
constexpr unit<2, -2,1> operator""_J(double value) // 焦耳也不知道怎么写-_-
{
return value;
}然后我们就可以用来写一些神奇的代码了:
auto m = 16_kilogram; // unit<0, 0, 1>(16)
auto s = 3_meter; // unit<1, 0, 0>(3)
auto t = 2_second; // unit<0, 1, 0>(2)
auto a = s / (t*t); // unit<1, -2, 0>(3/4)
auto F = m * a; // unit<1, -2, 1>(12)
下面的代码虽然也神奇,但因为违反了物理定律,所以C++编译器决定不让他编译通过:
auto W = F * s; // unit<2, -2, 1>(36)
auto x = F + W; // bang!
这样你还怕你在物理引擎里面东西倒腾来倒腾去然后公式手抖写错了吗?类似的错误是不可能发生的!除非系数被你弄错了……如果没有unit,要用原始的方法写出来:
double m = 16;
double s = 3;
double t = 2;
double a = s / (t*t);
double F = m * a;
double W = F * s;
double x = F + W; //????
时间过得久了以后,根本不知道是什么意思了。所以为了解决这个问题,我们得用应用匈牙利命名法(这个不是那个臭名昭著的你们熟悉的傻逼(系统)匈牙利命名法)。我举个例子:
string dogName = "kula";
Person person;
person.name = dogName;
这个代码大家一看就知道不对对吧,这就是应用匈牙利命名法了。我们通过给名字一个单位——狗的——来让person.name = dogName;这句话显得很滑稽,从而避免低级错误的发生。上面的unit就更进一步了,把这个东西带进了类型系统里面,就算写出来不滑稽,编译器都会告诉你,错误的东西就是错误的。
然后大家可能会问,用unit这么写程序的性能会不会大打折扣呀?如今已经是2013年了,靠谱的C++编译器编译出来的代码,跟你直接用几个double倒腾来倒腾去的代码其实是一样的。C++比起其他语言的抽象的好处就是,就算你要用来做高性能的程序,也不怕因为抽象而丧失性能。当然如果你使用了面向对象的技术,那就另当别论了。
注,上面这段话我写完之后贴到了粉丝群里面,然后九姑娘跟我讲了很多量纲分析的故事,然后升级到航空领域的check list,最后讲到了医院把这一技术引进了之后有效地阻止了手术弄错人等严重事故。那些特别靠谱的程序还得用C++来写,譬如说洛克希德马丁的战斗机,NASA的卫星什么的。
人的精力是有限的,需要一些错误规避来防止引进低级的错误或者负担,保留精力解决最核心的问题。很多软件都是这样的。譬如说超容易配置的MSBuild、用起来巨爽无比的Visual Studio,出了问题反正用正版安装程序点一下repair就可以恢复的windows,给我们带来的好处就是——保留精力解决最核心的问题。编程语言也是如此,类型系统也是如此,人类发明出的所有东西,都是为了让你可以把更多的精力放在更加核心的问题上,更少的精力放在周边的问题上。
但是类型到处都出现其实也会让我们程序写起来很烦的,所以现代的语言都有第二个功能,就是类型推导了。
二、类型推导
这里讲的类型推导可不是Go语言那个半吊子的:=赋值操作符。真正的类型推导,就要跟C++的泛型lambda表达式、C#的linq语法糖,或者Haskell的函数一样,要可以自己计算出模板的类型参数的位置或者内容,才能全方位的实现什么类型都不写,都还能使用强类型和type rich programming带来的好处。C++的lambda表达式上面已经看到了,所以还是从Haskell一个老掉牙的demo开始讲起吧。
今天,我们用Haskell来写一个merge sort:
merge [] [] = []
merge [] xs = xs
merge xs [] = xs
merge (x:xs) (y:ys) = if x<y then x:(merge xs (y:ys)) else y:(merge (x:xs) ys)
mergeSort [] = []
mergeSort xs = merge (mergeSort a) (mergeSort b)
where
len = length xs
a = take $ len `div` 2 $ xs
b = drop $ len - len `div` 2 $ xs我们可以很清楚的看出来,merge的类型是[a] –> [a] –> [a],mergeSort的类型是[a] –> [a]。到底编译器是怎么计算出类型的呢?
- 首先,[]告诉我们,这是一个空列表,但是类型是什么不知道,所以他是forall a –> [a]。所以merge [] [] = []告诉我们,merge的类型至少是[a] –> [b] –> [c]。
- 其次,merge [] xs = xs告诉我们,merge的类型至少是[d] –> e –> e。这个类型跟[a]->[b]->[c]求一个交集就会得到merge的更准确的类型:[a] –> [b] –> [b]。
- 然后,merge xs [] = []告诉我们,merge的类型至少是f –> [g] –> f。这个类型跟[a] –> [b] –> [b]求一个交集就会得到merge的更准确的类型:[a] –> [a] –> [a]。
- 最后看到那个长长的式子,根据一番推导之后,会发现[a]->[a]->[a]就是我们要的最终类型了。
- 只要把相同的技术放在mergeSort上面,就可以得到mergeSort的类型是[a]->[a]了。
当然对于Haskell这种Hindley-Milner类型系统来说,只要我们在代码里面计算出所有类型的方程,然后一个一个去解,最后就可以收敛到一个最准确的类型上面了。倘若我们在迭代的时候发现收敛之后无解了,那这个程序就是错的。这种简单粗暴的方法很容易构造出一些只要人够蛋定就很容易使用的语言,譬如说Haskell。
Haskell看完就可以来看C#了。C#的linq真是个好东西啊,只要不把它看成SQL,那很多事情都可以表达的。譬如说是个人都知道的linq to object啦,后面还有linq to xml,linq to sql,reactive programming,甚至是parser combinator等等。一个典型的linq的程序是长这个样子的:
var w =
from x in xs
from y in ys
from z in zs
select f(x, y, z);
光看这个程序可能看不出什么来,因为xs、ys、zs和f这几个单词都是没有意义的。但是linq的魅力正在这里。如果from和select就已经强行规定了xs、ys、zs和f的意思的话。那可扩展性就全没有了。因此当我们看到一个这样的程序的时候,其实可以是下面这几种意思:
W f(X x, Y y, Z z);
var /*IEnumerable<W>*/w =
from /*X*/x in /*IEnumerable<X>*/xs
from /*Y*/y in /*IEnumerable<Y>*/ys
from /*Z*/z in /*IEnumerable<Z>*/zs
select f(x, y, z);
var /*IObservable<W>*/w =
from /*X*/x in /*IObservable<X>*/xs
from /*Y*/y in /*IObservable<Y>*/ys
from /*Z*/z in /*IObservable<Z>*/zs
select f(x, y, z);
var /*IParser<W>*/w =
from /*X*/x in /*IParser<X>*/xs
from /*Y*/y in /*IParser<Y>*/ys
from /*Z*/z in /*IParser<Z>*/zs
select f(x, y, z);var /*IQueryable<W>*/w =
from /*X*/x in /*IQueryable<X>*/xs
from /*Y*/y in /*IQueryable<Y>*/ys
from /*Z*/z in /*IQueryable<Z>*/zs
select f(x, y, z);
var /*?<W>*/w =
from /*X*/x in /*?<X>*/xs
from /*Y*/y in /*?<Y>*/ys
from /*Z*/z in /*?<Z>*/zs
select f(x, y, z);
相信大家已经看到了里面的pattern了。只要你有一个?<T>类型,而它又支持linq provider的话,你就可以把代码写成这样了。
不过我们知道,把程序写成这样并不是我们编程的目的,我们的目的是要让程序写得让具有同样知识背景的人可以很快就看懂。为什么要看懂?因为总有一天你会不维护这个程序的,这样就可以让另一个合格的人来继续维护了。一个软件是要做几十年的,那些只有一两年甚至只有半年生命周期的,只能叫垃圾了。
那现在让我们看一组有意义的linq代码。首先是linq to object的,求一个数组里面出现最多的数字是哪个:
var theNumber = (
from n in numbers
group by n into g
select g.ToArray() into gs
order by gs.Length descending
select gs[0]
).First()
其次是一个parser,这个parser用来得到一个函数调用表达式:
IParser<FunctionCallExpression> Call()
{
return
from name in PrimitiveExpression()
from _1 in Text("(")
from arguments in
many(
Expression().
Text(",")
)
from _2 in Text(")")
select new FunctionCallExpression
{
Name = name,
Arguments = arguments.ToArray(),
};
}
我们可以看到,一旦linq表达式里面的元素都有了自己的名字,就不会跟上面的xyz的例子一样莫名其妙了。那这两个例子到底为什么要用linq呢?
第一个例子很简单,因为linq to object就是设计来解决这种问题的。
第二个例子就比较复杂一点了,为什么好好地parser要写成这样呢?我们知道,parser时可能会parse失败的。一个大的parser,里面的一些小部件失败了,那么大parser就要回滚,token stream的当前光标也要回滚,等等需要类似的一系列的操作。如果我们始终都让这些逻辑都贯穿在整个parser里面,那代码根本不能看。于是我们可以写一个linq provider,让SelectMany函数来处理所有的回滚操作,然后把parser写成上面这个样子。上面这个parser的所有的in左边是临时变量,所有的in右边刚好组成了一个EBNF文法:
PrimitiveExpression "(" [Expression {"," Expression}] ")"
最后的select语句告诉我们在所有小parser都parse成功之后,如何用parse得到的临时变量来返回一颗语法树。整个parsing的代码就会非常的容易看懂。当然,前提是你必须要懂的EBNF。不过一个不懂EBNF的人,又如何能写语法分析器呢。
那这跟类型推导有什么关系呢?我们会发现上面的所有linq的例子里面,除了函数签名以外,根本没有出现任何类型的声明。而且更重要的是,这些类型尽管没有写出来,但是每一个中间变量的类型都是自明的。当然这有一部分归功于好的命名方法——也就是应用匈牙利命名法了。剩下的部分是跟业务逻辑相关的。譬如说,一个FunctionCallExpression所调用的函数当然也是一个Expression了。如果这是唯一的选择,那为什么要写出来呢?
我们可以看到,正是因为有了类型推导,我们可以在写出清晰的代码的同时,还不需要花费那么多废话来指定各种类型。程序员都是怕麻烦的,无论复杂的方法有多好,他总是会选择简单的(废话,用复杂的那个不仅要加班修bug,还没有涨工资。用简单的那个,先让他过了,bug留给下一任程序员去头疼就好了——某web程序员如是说)。类型推导让type rich programming的程序写起来简单了许多。所以我们一旦有了类型推导,就可以放心大胆的使用type rich programming了。
三、大道理
有了type rich programming,就可以让编译器帮我们检查一些模式化的手都会犯的错误。让我们重温一下这篇文章前面的一段话:
人的精力是有限的,需要一些错误规避来防止引进低级的错误或者负担,保留精力解决最核心的问题。很多软件都是这样的。譬如说超容易配置的MSBuild、用起来巨爽无比的Visual Studio,出了问题反正用正版安装程序点一下repair就可以恢复的windows,给我们带来的好处就是——保留精力解决最核心的问题。编程语言也是如此,类型系统也是如此,人类发明出的所有东西,都是为了让你可以把更多的精力放在更加核心的问题上,更少的精力放在周边的问题上。
这让我想起了一个在微博上看到的故事:NASA的员工在推一辆装了卫星的小车的时候,因为忘记看check list,没有固定号卫星,结果卫星一推倒在了地上摔坏了,一下子没了两个亿的美元。
写程序也一样。一个代表力的变量,只能跟另一个代表力的变量相加,这就是check list。但是我们知道,每一个程序都相当复杂,check list需要检查的地方遍布所有文件。那难道我们在code review的时候可以一行一行仔细看吗?这是不可能的。正因为如此,我们要把程序写成“让编译器可以检查很多我们可能会手抖犯的错误”的形式,让我们从这些琐碎的事情里面解放出来。
银弹这种东西是不存在的,所以type rich programming能解决的事情就是防止手抖而犯错误。有一些错误不是手抖可以抖出来的,譬如说错误的设计,这并不是type rich programming能很好地处理的范围。为了解决这些事情,我们就需要更多可以遵守的best practice了。
当然,其中的一个将是DSL——domain specific language,领域特定语言了。敬请关注下一篇,《如何设计一门语言(十)——DSL与建模》。
posted @
2013-08-17 00:26 陈梓瀚(vczh) 阅读(13040) |
评论 (16) |
编辑 收藏关于这个话题,其实在(六)里面已经讨论了一半了。学过Haskell的都知道,这个世界上很多东西都可以用monad和comonad来把一些复杂的代码给抽象成简单的、一看就懂的形式。他们的区别,就像用js做一个复杂的带着几层循环的动画,直接写出来和用jquery的“回调”写出来的代码一样。前者能看不能用,后者能用不能看。那有没有什么又能用又能看的呢?我目前只能在Haskell、C#和F#里面看到。至于说为什么,当然是因为他们都支持了monad和comonad。只不过C#作为一门不把“用库来改造语言”作为重要特征的语言,并没打算让你们能跟haskell和F#一样,把东西抽象成monad,然后轻松的写出来。C#只内置了yield return和async await这样的东西。
把“用库来改造语言”作为重要特征的语言其实也不多,大家熟悉的也就只有lisp和C++,不熟悉的有F#。F#除了computation expression以外,还有一个type provider的功能。就是你可以在你的当前的程序里面,写一小段代码,通知编译器在编译你的代码的时候执行以下(有点类似鸡生蛋的问题但其实不是)。这段代码可以生成新的代码(而不是跟lisp一样修改已有的代码),然后给你剩下的那部分程序使用。例子我就不举了,有兴趣的大家看这里:http://msdn.microsoft.com/en-us/library/vstudio/hh361034.aspx。里面有一个例子讲的是如何在F#里面创造一个强类型的正则表达式库,而且并不像boost的spirit或者xpress那样,正则表达式仍然使用字符串来写的。这个正则表达式在编译的时候就可以知道你有没有弄错东西了,不需要等到运行才知道。
Haskell和F#分别尝试了monad/comonad和computation expression,为的就是能用一种不会失控(lisp的macro就属于会失控的那种)方法来让用户自己表达属于自己的可以天然被continuation passing style变换处理的东西。在介绍C#的async await的强大能力之前,先来讲一下Haskell和F#的做法。为什么按照这个程序呢,因为Haskell的monad表达能力最低,其次是F#,最后是C#的那个。当然C#并不打算让你自己写一个支持CPS变换的类型。作为补充,我将在这篇文章的最后,讲一下我最近正在设计的一门语言,是如何把C#的yield return和async await都变成库,而不是编译器的功能的。
下面我将抛弃所有跟学术有关的内容,只会留下跟实际开发有关系的东西。
一、Haskell和Monad
Haskell面临的问题其实比较简单,第一是因为Haskell的程序都不能有隐式状态,第二是因为Haskell没有语句只有表达式。这意味着你所有的控制流都必须用递归或者CPS来做。从这个角度上来讲,Monad也算是CPS的一种应用了。于是我为了给大家解释一下Monad是怎么运作的,决定来炒炒冷饭,说error code的故事。这个故事已经在(七)里面讲了,但是今天用的是Haskell,别有一番异域风情。
大家用C/C++的时候都觉得处理起error code是个很烦人的事情吧。我也不知道为什么那些人放着exception不用,对error code那么喜欢,直到有一天,我听到有一个傻逼在微博上讲:“error code的意思就是我可以不理他”。我终于明白了,这个人是一个真正的傻逼。不过Haskell还是很体恤这些人的,就跟耶稣一样,凡是信他就可以的永生,傻逼也可以。可惜的是,傻逼是学不会Monad的,所以耶稣只是个传说。
由于Haskell没有“引用参数”,所以所有的结果都必须出现在返回值里面。因此,倘若要在Haskell里面做error code,就得返回一个data。data就跟C语言的union一样,区别是data是强类型的,而C的union一不小心就会傻逼了:
data Unsure a = Sure a | Error string
然后给一些必要的实现,首先是Functor:
instance Functor Unsure where
fmap f (Sure x) = Sure (f x)
fmap f (Error e) = Error e剩下的就是Monad了:
instance Monad Unsure where
return = Sure
fail = Error
(Sure s) >>= f = f s
(Error e) >>= f = Error e看起来也不多,加起来才八行,就完成了error code的声明了。当然就这么看是看不出Monad的强大威力的,所以我们还需要一个代码。譬如说,给一个数组包含了分数,然后把所有的分数都转换成“牛逼”、“一般”和“傻逼”,重新构造成一个数组。一个真正的Haskell程序员,会把这个程序分解成两半,第一半当然是一个把分数转成数字的东西:
// Tag :: integer -> Unsure string
Tag f =
if f < 0 then Error "分数必须在0-100之间" else
if f<60 then Sure "傻逼" else
if f<90 then Sure "一般" else
if f<=100 then Sure "牛逼" else
Error "分数必须在0-100之间"后面就是一个循环了:
// TagAll :: [integer] -> Unsure [string]
TagAll [] = []
TagAll (x:xs) = do
first <- Tag x
remains <- TagAll xs
return first:remainsTagAll是一个循环,把输入的东西每一个都用Tag过一遍。如果有一次Tag返回失败了,整个TagAll函数都会失败,然后返回错误。如果全部成功了,那么TagAll函数会返回整个处理后的数组。
当然一个循环写成了非尾递归不是一个真正的Haskell程序员会做的事情,真正的Haskell程序员会把事情做成这样(把>>=展开之后你们可能会觉得这个函数不是尾递归,但是因为Haskell是call by need的,所以实际上会成为一个尾递归的函数):
// TagAll :: [integer] -> Unsure [string]
TagAll xs = reverse $ TagAll_ xs [] where
TagAll [] ys = Sure ys
TagAll (x:xs) ys = do
y <- Tag x
TagAll xs (y:ys)为什么代码里面一句“检查Tag函数的返回值”的代码都没有呢?这就是Haskell的Monad的表达能力的威力所在了。Monad的使用由do关键字开始,然后这个表达式可以被这么定义:
MonadExp
::= "do" FragmentNotNull
FragmentNotNull
::= [Pattern "<-"] Expression EOL FragmentNull
FragmentNull
::= FragmentNotNull
::= ε意思就是说,do后面一定要有“东西”,然后这个“东西”是这么组成的:
1、第一样要是一个a<-e这样的东西。如果你不想给返回值命名,就省略“a<-”这部分
2、然后重复
这表达的是这样的一个意思:
1、先做e,然后把结果保存进a
2、然后做下面的事情
看到了没有,“然后做下面的事情”是一个典型的continuation passing style的表达方法。但是我们可以看到,在例子里面所有的e都是Unsure T类型的,而a相应的必须为T。那到底是谁做了这个转化呢?
聪明的,哦不,正常的读者一眼就能看出来,“<-”就是调用了我们之前在上面实现的一个叫做“>>=”的函数了。我们首先把“e”和“然后要做的事情”这两个参数传进了>>=,然后>>=去解读e,得到a,把a当成“然后要做的事情”的参数调用了一下。如果e解读失败的到了错误,“然后要做的事情”自然就不做了,于是整个函数就返回错误了。
Haskell一下就来尾递归还是略微复杂了点,我们来写一个简单点的例子,写一个函数判断一个人的三科成绩里面,有多少科是牛逼的:
// Count牛逼 :: integer -> integer -> integer –> Unsure integer
Count牛逼 chinese math english = do
a <- Tag chinese
b <- Tag math
c <- Tag english
return length [x | x <- [a, b, c], x == "牛逼"]根据上文的描述,我们已经知道,这个函数实际上会被处理成:
// Count牛逼 :: integer -> integer -> integer –> Unsure integer
Count牛逼 chinese math english
Tag chinese >>= \a->
Tag math >>= \b->
Tag english >>= \c->
return length [x | x <- [a, b, c], x == "牛逼"]>>=函数的定义是
instance Monad Unsure where
return = Sure
fail = Error
(Sure s) >>= f = f s
(Error e) >>= f = Error e这是一个运行时的pattern matching。一个对参数带pattern matching的函数用Haskell的case of写出来是很难看的,所以Haskell给了这么个语法糖。但这个时候我们要把>>=函数展开在我们的“Count牛逼”函数里面,就得老老实实地用case of了:
// Count牛逼 :: integer -> integer -> integer –> Unsure integer
Count牛逼 chinese math english
case Tag chinese of {
Sure a -> case Tag math of {
Sure b -> case Tag english of {
Sure c -> Sure $ length [x | x <- [a, b, c], x == "牛逼"]
Error e -> Error e
}
Error e -> Error e
}
Error e -> Error e
}是不是又回到了我们在C语言里面被迫做的,还有C++不喜欢用exception的人(包含一些觉得error code可以忽略的傻逼)做的,到处检查函数返回值的事情了?我觉得只要是一个正常人,都会选择这种写法的:
// Count牛逼 :: integer -> integer -> integer –> Unsure integer
Count牛逼 chinese math english
Tag chinese >>= \a->
Tag math >>= \b->
Tag english >>= \c->
return length [x | x <- [a, b, c], x == "牛逼"]于是我们用Haskell的Monad,活生生的把“每次都检查函数返回值”的代码压缩到了Monad里面,然后就可以把代码写成try-catch那样的东西了。error code跟exception本来就是一样的嘛,只是一个写起来复杂所以培养了很多觉得错误可以忽略的傻逼,而一个只需要稍微训练一下就可以把代码写的很简单罢了。
不过Haskell没有变量,那些傻逼们可能会反驳:C/C++比Haskell复杂多了,你怎么知道exception就一定没问题呢?这个时候,我们就可以看F#的computation expression了。
二、F#和computation expression
F#虽然被设计成了一门函数式语言,但是其骨子里还是跟C#一样带状态的,而且编译成MSIL代码之后,可以直接让F#和C#互相调用。一个真正的Windows程序员,从来不会拘泥于让一个工程只用一个语言来写,而是不同的大模块,用其适合的最好的语言。微软把所有的东西都设计成可以强类型地互操作的,所以在Windows上面从来不存在什么“如果我用A语言写了,B就用不了”的这些事情。这是跟Linux的一个巨大的区别。Linux是没有强类型的互操作的(字符串信仰者们再见),而Windows有。什么,Windows不能用来做Server?那Windows Azure怎么做的,bing怎么做的。什么,只有微软才知道怎么正确使用Windows Server?你们喜欢玩的EVE游戏的服务器是怎么做的呢?
在这里顺便黑一下gcc。钱(区别于财产)对于一个程序员是很重要的。VC++和clang/LLVM都是领着工资写的,gcc不知道是谁投资的(这也就意味着写得好也涨不了工资)。而且我们也都知道,gcc在windows上编译的慢出来的代码还不如VC++,gcc在linux上编译的慢还不如clang,在mac/ios上就不说了,下一个版本的xcode根本没有什么gcc了。理想主义者们醒醒,gcc再见。
为什么F#有循环?答案当然是因为F#有变量了。一个没有变量的语言是写不出循环退出条件的,只能写出递归退出条件。有了循环的话,就会有各种各样的东西,那Monad这个东西就不能很好地给“东西”建模了。于是F#本着友好的精神,既然大家都那么喜欢Monad,那他做出一个computation expression,学起来肯定就很容易了。
于是在F#下面,那个TagAll终于可以读入一个真正的列表,写出一个真正的循环了:
let TagAll xs = unsure
{
let r = Array.create xs.length ""
for i in 0 .. xs.length-1 do
let! tag = Tag xs.[i]
r.[i]<-tag
return r
}注意那个let!,其实就是Haskell里面的<-。只是因为这些东西放在了循环里,那么那个“Monad”表达出来就没有Haskell的Monad那么纯粹了。为了解决这个问题,F#引入了computation expression。所以为了让那个unsure和let!起作用,就得有下面的代码,做一个名字叫做unsure的computation expression:
type UnsureBuilder() =
member this.Bind(m, f) = match m with
| Sure a -> f a
| Error s -> Error s
member this.For(xs, body) =unsure
{
match xs with
| [] -> Sure ()
| x::xs ->
let! r = Tag x
body r
return this.For xs body
}
.... // 还有很多别的东西let unsure = new UnsureBuilder()
所以说带有副作用的语言写出来的代码又长,不带副作用的语言写出来的代码又难懂,这之间很难取得一个平衡。
如果输入的分数数组里面有一个不在0到100的范围内,那么for循环里面的“let! tag = Tag xs.[i]”这句话就会引发一个错误,导致TagAll函数失败。这是怎么做到的?
首先,Tag引发的错误是在for循环里面,也就是说,实际运行的时候是调用UnsuerBuilder类型的unsure.For函数来执行这个循环的。For函数内部使用“let! r = Tag x”,这个时候如果失败,那么let!调用的Bind函数就会返回Error s。于是unsure.Combine函数判断第一个语句失败了,那么接下来的语句“body r ; return this.For xs body”也就不执行了,直接返回错误。这个时候For函数的递归终止条件就产生作用了,由一层层的return(F#自带尾递归优化,所以那个For函数最终会被编译成一个循环)往外传递,导致最外层的For循环以Error返回值结束。TagAll里面的unsure,Combine函数看到for循环完蛋了,于是return r也不执行了,返回错误。
这个过程跟Haskell的那个版本做的事情完全是一样的,只是由于F#多了很多语句,所以Monad展开成computation expression之后,表面上看起来就会复杂很多。如果明白Haskell的Monad在干什么事情的话,F#的computation expression也是很容易就学会的。
当然,觉得“error code可以忽略”的傻逼是没有可能的。
三、C#的yield return和async await
如果大家已经明白了Haskell的>>=和F#的Bind(其实也是let!)就是一回事的话,而且也明白了我上面讲的如何把do和<-变成>>=的方法的话,大家应该对CPS在实际应用的样子心里有数了。不过,这种理解的方法实际上是相当有限的。为什么呢?让我们来看C#的两个函数:
IEnumerable<T> Concat(this IEnumerable<T> a, IEnumerable<T> b)
{
foreach(var x in a)
yield return x;
foreach(var x in b)
yield return x;
}上面那个是关于yield return和IEnumerable<T>的例子,讲的是Linq的Concat函数是怎么实现的。下面还有一个async await和Task<T>的例子:
async Task<T[]> SequencialExecute(this Task<T>[] tasks)
{
var ts = new T[tasks.Length];
for(int i=0;i<tasks.Length;i++)
ts[i]=await tasks[i];
return ts;
}这个函数讲的是,如果你有一堆Task<T>,如何构造出一个内容来自于异步地挨个执行tasks里面的每个Task<T>的Task<T[]>的方法。
大家可能会注意到,C#的yield return和await的“味道”,就跟Haskell的<-和>>=、F#的Bind和let!一样。在处理这种语言级别的事情的时候,千万不要去管代码它实际上在干什么,这其实是次要的。最重要的是形式。什么是形式呢?也就是说,同样一个任务,是如何被不同的方法表达出来的。上面说的“味道”就都在“表达”的这个事情上面了。
这里我就要提一个问题了。
- Haskell有Monad,所以我们可以给自己定义的类型实现一个Monad,从而让我们的类型可以用do和<-来操作。
- F#有computation expression,所以我们可以给自己定义的类型实现一个computation expression,从而让我们的类型可以用let!来操作。
- C#有【什么】,所以我们可以给自己定义的类型实现一个【什么】,从而让我们的类型可以用【什么】来操作?
熟悉C#的人可能很快就说出来了,答案是Linq、Linq Provider和from in了。这篇《Monadic Parser Combinator using C# 3.0》http://blogs.msdn.com/b/lukeh/archive/2007/08/19/monadic-parser-combinators-using-c-3-0.aspx 介绍了一个如何把语法分析器(也就是parser)给写成monad,并且用Linq的from in来表达的方法。
大家可能一下子不明白什么意思。Linq Provider和Monad是这么对应的:
- fmap对应于Select
- >>=对应于SelectMany
- >>= + return也对应与Select(回忆一下Monad这个代数结构的几个定理,就有这么一条)
然后诸如这样的Haskell代码:
// Count牛逼 :: integer -> integer -> integer –> Unsure integer
Count牛逼 chinese math english = do
a <- Tag chinese
b <- Tag math
c <- Tag english
return length [x | x <- [a, b, c], x == "牛逼"]就可以表达成:
Unsure<int> Count牛逼(int chinese, int math, int english)
{
return
from a in Tag(chinese)
from b in Tag(math)
from c in Tag(english)
return new int[]{a, b, c}.Where(x=>x=="牛逼").Count();
}不过Linq的这个表达方法跟yield return和async await一比,就有一种Monad和computation expression的感觉了。Monad只能一味的递归一个一个往下写,而computation expression则还能加上分支循环异常处理什么的。C#的from in也是一样,没办法表达循环异常处理等内容。
于是上面提到的那个问题
C#有【什么】,所以我们可以给自己定义的类型实现一个【什么】,从而让我们的类型可以用【什么】来操作?
其实并没有回答完整。我们可以换一个角度来体味。假设IEnumerable<T>和Task<T>都是我们自己写的,而不是.net framework里面的内容,那么C#究竟要加上一个什么样的(类似于Linq Provider的)功能,从而让我们可以写出接近yield return和async await的效果的代码呢?如果大家对我的那篇《时隔多年我又再一次体验了一把跟大神聊天的感觉》还有点印象的话,其实我当时也对我自己提出了这么个问题。
我那个时候一直觉得,F#的computation expression才是正确的方向,但是我怎么搞都搞不出来,所以我自己就有点动摇了。于是我跑去问了Don Syme,他很斩钉截铁的告诉我说,computation expression是做不到那个事情的,但是需要怎么做他也没想过,让我自己research。后来我就得到了一个结论。
四、Koncept(我正在设计的语言)的yield return和async await(问题)
Koncept主要的特征是concept mapping和interface。这两种东西的关系就像函数和lambda表达式、instance和class一样,是定义和闭包的关系,所以相处起来特别自然。首先我让函数只能输入一个参数,不过这个参数可以是一个tuple,于是f(a, b, c)实际上是f.Invoke(Tuple.Create(a, b, c))的语法糖。然后所有的overloading都用类似C++的偏特化来做,于是C++11的不定模板参数(variadic template argument)在我这里就成为一个“推论”了,根本不是什么需要特殊支持就自然拥有的东西。这也是concept mapping的常用手法。最后一个跟普通语言巨大的变化是我删掉了class,只留下interface。反正你们写lambda表达时也不会给每个闭包命名字(没有C++11的C++除外),那为什么写interface就得给每一个闭包(class)命名字呢?所以我给删去了。剩下的就是我用类似mixin的机制可以把函数和interface什么的给mixin到普通的类型里面去,这样你也可以实现class的东西,就是写起特别来麻烦,于是我在语法上就鼓励你不要暴露class,改为全部暴露function、concept和interface。
不过这些都不是重点,因为除了这些差异以外,其他的还是有浓郁的C#精神在里面的,所以下面在讲Koncept的CPS变换的时候,我还是把它写成C#的样子,Koncept长什么样子以后我再告诉你们,因为Koncept的大部分设计都跟CPS变换是没关系的。
回归正题。之前我考虑了许久,觉得F#的computation expression又特别像是一个正确的解答,但是我怎么样都找不到一个可以把它加入Koncept地方法。这个问题我从NativeX(这里、这里、这里和这里)的时候就一直在想了,中间兜了一个大圈,整个就是试图山寨F#结果失败的过程。为什么F#的computation expression模型不能用呢,归根结底是因为,F#的循环没有break和continue。C#的跳转是自由的,不仅有break和continue,你还可以从循环里面return,甚至goto。因此一个for循环无论如何都表达不成F#的那个函数:M<U> For(IEnumerable<T> container, Func<T, M<U>> body);。break、continue、return和goto没办法表达在类型上。
伟大的先知Eric Meijer告诉我们:“一个函数的类型表达了关于函数的业务的一切”。为什么我们还要写函数体,是因为编译器还没有聪明到看着那个类型就可以帮我们把代码填充完整。所以其实当初看着F#的computation expression的For的定义的时候,是因为我脑筋短路,没有想起Eric Meijer的这句话,导致我浪费了几个月时间。当然我到了后面也渐渐察觉到了这个事情,产生了动摇,自己却无法确定,所以去问了Don Syme。于是,我就得到了关于这个问题的结论的一半:在C#(其实Koncept也是)支持用户可以自由添加的CPS变换(譬如说用户添加IEnumerable<T>的时候添加yield return和yield break,用户添加Task<T>的时候添加await和return)的话,使用CPS变换的那段代码,必须用控制流图(control flow graph)处理完之后生成一个状态机来做,而不能跟Haskell和F#一样拆成一个一个的小lambda表达式。
其实C#的yield return和async await,从一开始就是编译成状态机的。只是C#没有开放那个功能,所以我一直以为这并不是必须的。想来微软里面做语言的那帮牛逼的人还是有牛逼的道理的,一下子就可以找到问题的正确方向,跟搞go的二流语言专家(尽管他也牛逼但是跟语言一点关系也没有)是完全不同的。连Mozilla的Rust的设计都比go强一百倍。
那另一半的问题是什么呢?为了把问题看得更加清楚,我们来看两个长得很像的yield return和async await的例子。为了把本质的问题暴露出来,我决定修改yield return的语法:
- 首先把yield return修改成yield
- 其次吧yield break修改成return
- 然后再给函数打上一个叫做seq的东西,跟async对称,就当他是个关键字
- 给所有CPS operator加上一个感叹号,让他变得更清楚(这里有yield、await和return)。为什么return也要加上感叹号呢?因为如果我们吧seq和aysnc摘掉的话,我们会发现return的类型是不匹配的。所以这不是一个真的return。
然后就可以来描述一个类似Linq的TakeWhile的事情了:
seq IEnumerable<T> TakeWhile(this IEnumerable<T> source, Predicate<T> predicate)
{
foreach(var x in source)
{
if(!predicate(x))
return!;
yield! x
}
}
async Task<T[]> TakeWhile(this Task<T>[] source, Predicate<T> predicate)
{
List<T> result=new List<T>();
foreach(var t in source)
{
var x = await! t;
if(!predicate(x))
return! result.ToArray();
result.Add(x);
}
return! result.ToArray();
}于是问题就很清楚了。如果我们想让用户自己通过类库的方法来实现这些东西,那么yield和await肯定是两个函数,因为这是C#里面唯一可以用来写代码的东西,就算看起来再奇怪,也不可能是别的。
- seq和async到底是什么?
- seq下面的yield和return的类型分别是什么?
- async下面的await和return的类型分别是什么?
其实这里还有一个谜团。其实seq返回的东西应该是一个IEnumerator<T>,只是因为C#觉得IEnumerable<T>是更好地,所以你两个都可以返回。那么,是什么机制使得,函数可以构造出一个IEnumerable<T>,而整个状态机是在IEnumerator<T>的MoveNext函数里面驱动的呢?而async和Task<T>就没有这种情况了。
首先解答第一个问题。因为yield、return和await都是函数,是函数就得有个namespace,那我们可以拿seq和async做namespace。所以seq和async,设计成两个static class也是没有问题的。
其次,seq的yield和return修改了某个IEnumerator<T>的状态,而async的await和return修改了某个Task<T>的状态。而seq和async的返回值分别是IEnumerable<T>和Task<T>。因此对于一个CPS变换来说,一共需要两个类型,第一个是返回值,第二个是实际运行状态机的类。
第三,CPS变换还需要有一个启动函数。IEnumerator<T>的第一次MoveNext调用了那个启动函数。而Task<T>的Start调用了那个启动函数。启动函数自己维护着所有状态机的内容,而状态机本身是CPS operator们看不见的。为什么呢?因为一个状态机也是一个类,这些状态机类是没有任何公共的contract的,也就是说无法抽象他们。因此CPS operator必须不能知道状态机类。
而且yield、return和await都叫CPS operator,那么他们不管是什么类型,本身肯定看起来像一个CPS的函数。之前已经讲过了,CPS函数就是把普通函数的返回值去掉,转而添加一个lambda表达式,用来代表“拿到返回之后的下一步计算”。
因此总的来说,我们拿到了这四个方程,就可以得出一个解了。解可以有很多,我们选择最简单的部分。
那现在就开始来解答上面两个TakeWhile最终会被编译成什么东西了。
五、Koncept(我正在设计的语言)的yield return和async await(seq答案)
首先来看seq和yield的部分。上面讲到了,yield和return都是在修改某个IEnumerator<T>的状态,但是编译器自己肯定不能知道一个合适的IEnumerator<T>是如何被创建出来的。所以这个类型必须由用户来创建。而为了第一次调用yield的时候就已经有IEnumerator<T>可以用,所以CPS的启动函数就必须看得到那个IEnumerator<T>。但是CPS的启动函数又不可能去创建他,所以,这个IEnumerator<T>对象肯定是一个continuation的参数了。
看,其实写程序都是在做推理的。尽管我们现在还不知道整个CPS要怎么运作,但是随着这些线索,我们就可以先把类型搞出来。搞出了类型之后,就可以来填代码了。
- 对于yield,yield接受了一个T,没有返回值。一个没有返回值的函数的continuation是什么呢?当然就是一个没有参数的函数了。
- return则连输入都没有。
- 而且yield和return都需要看到IEnumerator<T>。所以他们肯定有一个参数包含这个东西。
那么这三个函数的类型就都确定下来了:
public static class seq
{
public static IEnumerator<T> CreateCps<T>(Action<seq_Enumerator<T>>);
public static void yield<T>(seq_Enumerator<T> state, T value, Action continuation);
public static void exit<T>(seq_Enumerator<T> state /*没有输入*/ /*exit代表return,函数结束的意思就是不会有一个continuation*/);
}什么是seq_Enumerator<T>呢?当然是我们那个“某个IEnumerator<T>”的真是类型了。
于是看着类型,唯一可能的有意义又简单的实现如下:
public class seq_Enumerable<T> : IEnumerable<T>
{
public Action<seq_Enumerator<T>> startContinuation;
public IEnumerator<T> CreateEnumerator()
{
return new seq_Enumerator<T>
{
startContinuation=this.startContinuation)
};
}
}
public class seq_Enumerator<T> : IEnumerator<T>
{
public T current;
bool available;
Action<seq_Enumerator<T>> startContinuation;
Action continuation;
public T Current
{
get
{
return this.current;
}
}
public bool MoveNext()
{
this.available=false;
if(this.continuation==null)
{
this.startContinuation(this);
}
else
{
this.continuation();
}
return this.available;
}
}
public static class seq
{
public static IEnumerable<T> CreateCps<T>(Action<seq_Enumerator<T>> startContinuation)
{
return new seq_Enumerable
{
startContinuation=startContinuation
};
}
public static void yield<T>(seq_Enumeartor<T> state, T value, Action continuation)
{
state.current=value;
state.available=true;
state.continuation=continuation;
}
public static void exit<T>(seq_Enumeartor<T> state)
{
}
}那么那个TakeWhile函数最终会变成:
public class _TakeWhile<T>
{
seq_Enumerator<T> _controller;
Action _output_continuation_0= this.RunStateMachine;
int _state;
IEnumerable<T> _source;
IEnumerator<T> _source_enumerator;
Predicate<T> _predicate;
T x;
public void RunStateMachine()
{
while(true)
{
switch(this.state)
{
case 0:
{
this._source_enumerator = this._source.CreateEnumerator();
this._state=1;
}
break;
case 1:
{
if(this._state_enumerator.MoveNext())
{
this.x=this._state_enumerator.Current;
if(this._predicate(this.x))
{
this._state=2;
var input=this.x;
seq.yield(this._controller. input, this._output_continuation_0);
return;
}
else
{
seq.exit(this._controller);
}
}
else
{
state._state=3;
}
}
break;
case 2:
{
this.state=1;
}
break;
case 3:
{
seq.exit(this._controller);
}
break;
}
}
}
}但是TakeWhile这个函数是真实存在的,所以他也要被改写:
IEnumerable<T> TakeWhile(this IEnumerable<T> source, Predicate<T> predicate)
{
return seq.CreateCps(controller=>
{
var sm = new _Where<T>
{
_controller=controller,
_source=source,
_predicate=predicate,
};
sm.RunStateMachine();
});
}最终生成的TakeWhile会调用哪个CreateCps函数,然后把原来的函数体经过CFG的处理之后,得到一个状态机。在状态机内所有调用CPS operator的地方(就是yield!和return!),都把“接下来的事情”当成一个参数,连同那个原本写上去的CPS operator的参数,还有controller(在这里是seq_Enumeartor<T>)一起传递过去。而return是带有特殊的寓意的,所以它调用一次exit之后,就没有“然后——也就是continuation”了。
现在回过头来看seq类型的声明
public static class seq
{
public static IEnumerator<T> CreateCps<T>(Action<seq_Enumerator<T>>);
public static void yield<T>(seq_Enumerator<T> state, T value, Action continuation);
public static void exit<T>(seq_Enumerator<T> state /*没有输入*/ /*exit代表return,函数结束的意思就是不会有一个continuation*/);
}其实想一想,CPS的自然属性决定了,基本上就只能这么定义它们的类型。而他们的类型唯一定义了一个最简单有效的函数体。再次感叹一下,写程序就跟在做推理完全是一摸一样的。
六、Koncept(我正在设计的语言)的yield return和async await(async答案)
因为CPS operator都是一样的,所以在这里我给出async类型的声明,然后假设Task<T>的样子长的就跟C#的System.Tasks.Task<T>一摸一样,看看大家能不能得到async下面的几个函数的实现,以及上面那个针对Task<T>的TakeWhile函数最终会被编译成什么:
public static class async
{
public static Task<T> CreateCps<T>(Action<FuturePromiseTask<T>> startContinuation);
{
/*请自行填补*/
}
public static void await<T>(FuturePromiseTask<T> task, Task<T> source, Action<T> continuation);
{
/*请自行填补*/
}
public static void exit<T>(FuturePromiseTask<T> task, T source); /*在这里async的return是有参数的,所以跟seq的exit不一样*/
{
/*请自行填补*/
}
}
public class FuturePromiseTask<T> : Task<T>
{
/*请自行填补*/
}posted @
2013-07-26 19:12 陈梓瀚(vczh) 阅读(14891) |
评论 (15) |
编辑 收藏人们都很喜欢讨论闭包这个概念。其实这个概念对于写代码来讲一点用都没有,写代码只需要掌握好lambda表达式和class+interface的语义就行了。基本上只有在写编译器和虚拟机的时候才需要管什么是闭包。不过因为系列文章主题的缘故,在这里我就跟大家讲一下闭包是什么东西。在理解闭包之前,我们得先理解一些常见的argument passing和symbol resolving的规则。
首先第一个就是call by value了。这个规则我们大家都很熟悉,因为流行的语言都是这么做的。大家还记得刚开始学编程的时候,书上总是有一道题目,说的是:
void Swap(int a, int b)
{
int t = a;
a = b;
b = t;
}
int main()
{
int a=0;
int b=1;
Swap(a, b);
printf("%d, %d", a, b);
}
然后问程序会输出什么。当然我们现在都知道,a和b仍然是0和1,没有受到变化。这就是call by value。如果我们修改一下规则,让参数总是通过引用传递进来,因此Swap会导致main函数最后会输出1和0的话,那这个就是call by reference了。
除此之外,一个不太常见的例子就是call by need了。call by need这个东西在某些著名的实用的函数式语言(譬如Haskell)是一个重要的规则,说的就是如果一个参数没被用上,那传进去的时候就不会执行。听起来好像有点玄,我仍然用C语言来举个例子。
int Add(int a, int b)
{
return a + b;
}
int Choose(bool first, int a, int b)
{
return first ? a : b;
}
int main()
{
int r = Choose(false, Add(1, 2), Add(3, 4));
printf("%d", r);
}
这个程序Add会被调用多少次呢?大家都知道是两次。但是在Haskell里面这么写的话,就只会被调用一次。为什么呢?因为Choose的第一个参数是false,所以函数的返回值只依赖与b,而不依赖与a。所以在main函数里面它感觉到了这一点,于是只算Add(3, 4),不算Add(1, 2)。不过大家别以为这是因为编译器优化的时候内联了这个函数才这么干的,Haskell的这个机制是在运行时起作用的。所以如果我们写了个快速排序的算法,然后把一个数组排序后只输出第一个数字,那么整个程序是O(n)时间复杂度的。因为快速排序的average case在把第一个元素确定下来的时候,只花了O(n)的时间。再加上整个程序只输出第一个数字,所以后面的他就不算了,于是整个程序也是O(n)。
于是大家知道call by name、call by reference和call by need了。现在来给大家讲一个call by name的神奇的规则。这个规则神奇到,我觉得根本没办法驾驭它来写出一个正确的程序。我来举个例子:
int Set(int a, int b, int c, int d)
{
a += b;
a += c;
a += d;
}
int main()
{
int i = 0;
int x[3] = {1, 2, 3};
Set(x[i++], 10, 100, 1000);
printf("%d, %d, %d, %d", x[0], x[1], x[2], i);
}
学过C语言的都知道这个程序其实什么都没做。如果把C语言的call by value改成了call by reference的话,那么x和i的值分别是{1111, 2, 3}和1。但是我们知道,人类的想象力是很丰富的,于是发明了一种叫做call by name的规则。call by name也是call by reference的,但是区别在于你每一次使用一个参数的时候,程序都会把计算这个参数的表达式执行一遍。因此,如果把C语言的call by value换成call by name,那么上面的程序做的事情实际上就是:
x[i++] += 10;
x[i++] += 100;
x[i++] += 1000;
程序执行完之后x和i的值就是{11, 102, 1003}和3了。
很神奇对吧,稍微不注意就会中招,是个大坑,基本没法用对吧。那你们还整天用C语言的宏来代替函数干什么呢。我依稀记得Ada(有网友指出这是Algol 60)还是什么语言就是用这个规则的,印象比较模糊。
讲完了argument passing的事情,在理解lambda表达式之前,我们还需要知道两个流行的symbol resolving的规则。所谓的symbol resolving讲的就是解决程序在看到一个名字的时候,如何知道这个名字到底指向的是谁的问题。于是我又可以举一个简单粗暴的例子了:
Action<int> SetX()
{
int x = 0;
return (int n)=>
{
x = n;
};
}
void Main()
{
int x = 10;
var setX = SetX();
setX(20);
Console.WriteLine(x);
}
弱智都知道这个程序其实什么都没做,就输出10。这是因为C#用的symbol resolving地方法是lexical scoping。对于SetX里面那个lambda表达式来讲,那个x是SetX的x而不是Main的x,因为lexical scoping的含义就是,在定义的地方向上查找名字。那为什么不能在运行的时候向上查找名字从而让SetX里面的lambda表达式实际上访问的是Main函数里面的x呢?其实是有人这么干的。这种做法叫dynamic scoping。我们知道,著名的javascript语言的eval函数,字符串参数里面的所有名字就是在运行的时候查找的。
=======================我是背景知识的分割线=======================
想必大家都觉得,如果一个语言的lambda表达式在定义和执行的时候采用的是lexical scoping和call by value那该有多好呀。流行的语言都是这么做的。就算规定到这么细,那还是有一个分歧。到底一个lambda表达式抓下来的外面的符号是只读的还是可读写的呢?python告诉我们,这是只读的。C#和javascript告诉我们,这是可读写的。C++告诉我们,你们自己来决定每一个符号的规则。作为一个对语言了解得很深刻,知道自己每一行代码到底在做什么,而且还很有自制力的程序员来说,我还是比较喜欢C#那种做法。因为其实C++就算你把一个值抓了下来,大部分情况下还是不能优化的,那何苦每个变量都要我自己说明我到底是想只读呢,还是要读写都可以呢?函数体我怎么用这个变量不是已经很清楚的表达出来了嘛。
那说到底闭包是什么呢?闭包其实就是那个被lambda表达式抓下来的“上下文”加上函数本身了。像上面的SetX函数里面的lambda表达式的闭包,就是x变量。一个语言有了带闭包的lambda表达式,意味着什么呢?我下面给大家展示一小段代码。现在要从动态类型的的lambda表达式开始讲,就凑合着用那个无聊的javascript吧:
function pair(a, b) {
return function(c) {
return c(a, b);
};
}
function first(a, b) {
return a;
}
function second(a, b) {
return b;
}
var p = pair(1, pair(2, 3));
var a = p(first);
var b = p(second)(first);
var c = p(second)(second);
print(a, b, c);
这个程序的a、b和c到底是什么值呢?当然就算看不懂这个程序的人也可以很快猜出来他们是1、2和3了,因为变量名实在是定义的太清楚了。那么程序的运行过程到底是怎么样的呢?大家可以看到这个程序的任何一个值在创建之后都没有被第二次赋值过,于是这种程序就是没有副作用的,那就代表其实在这里call by value和call by need是没有区别的。call by need意味着函数的参数的求值顺序也是无所谓的。在这种情况下,程序就变得跟数学公式一样,可以推导了。那我们现在就来推导一下:
var p = pair(1, pair(2, 3));
var a = p(first);
// ↓↓↓↓↓
var p = function(c) {
return c(1, pair(2, 3));
};
var a = p(first);
// ↓↓↓↓↓
var a = first(1, pair(2, 3));
// ↓↓↓↓↓
var a = 1;
这也算是个老掉牙的例子了啊。闭包在这里体现了他强大的作用,把参数保留了起来,我们可以在这之后进行访问。仿佛我们写的就是下面这样的代码:
var p = {
first : 1,
second : {
first : 1,
second : 2,
}
};
var a = p.first;
var b = p.second.first;
var c = p.second.second;
于是我们得到了一个结论,(带闭包的)lambda表达式可以代替一个成员为只读的struct了。那么,成员可以读写的struct要怎么做呢?做法当然跟上面的不一样。究其原因,就是因为javascript使用了call by value的规则,使得pair里面的return c(a, b);没办法将a和b的引用传递给c,这样就没有人可以修改a和b的值了。虽然a和b在那些c里面是改不了的,但是pair函数内部是可以修改的。如果我们要坚持只是用lambda表达式的话,就得要求c把修改后的所有“这个struct的成员变量”都拿出来。于是就有了下面的代码:
// 在这里我们继续使用上面的pair、first和second函数
function mutable_pair(a, b) {
return function(c) {
var x = c(a, b);
// 这里我们把pair当链表用,一个(1, 2, 3)的链表会被储存为pair(1, pair(2, pair(3, null)))
a = x(second)(first);
b = x(second)(second)(first);
return x(first);
};
}
function get_first(a, b) {
return pair(a, pair(a, pair(b, null)));
}
function get_second(a, b) {
return pair(b, pair(a, pair(b, null)));
}
function set_first(value) {
return function(a, b) {
return pair(undefined, pair(value, pair(b, null)));
};
}
function set_second(value) {
return function(a, b) {
return pair(undefined, pair(a, pair(value, null)));
};
}
var p = mutable_pair(1, 2);
var a = p(get_first);
var b = p(get_second);
print(a, b);
p(set_first(3));
p(set_second(4));
var c = p(get_first);
var d = p(get_second);
print(c, d);
我们可以看到,因为get_first和get_second做了一个只读的事情,所以返回的链表的第二个值(代表新的a)和第三个值(代表新的b)都是旧的a和b。但是set_first和set_second就不一样了。因此在执行到第二个print的时候,我们可以看到p的两个值已经被更改成了3和4。
虽然这里已经涉及到了“绑定过的变量重新赋值”的事情,不过我们还是可以尝试推导一下,究竟p(set_first(3));的时候究竟干了什么事情:
var p = mutable_pair(1, 2);
p(set_first(3));
// ↓↓↓↓↓
p = return function(c) {
var x = c(1, 2);
a = x(second)(first);
b = x(second)(second)(first);
return x(first);
};
p(set_first(3));
// ↓↓↓↓↓
var x = set_first(3)(1, 2);
p.a = x(second)(first); // 这里的a和b是p的闭包内包含的上下文的变量了,所以这么写会清楚一点
p.b = x(second)(second)(first);
// return x(first);出来的值没人要,所以省略掉。
// ↓↓↓↓↓
var x = (function(a, b) {
return pair(undefined, pair(3, pair(b, null)));
})(1, 2);
p.a = x(second)(first);
p.b = x(second)(second)(first);
// ↓↓↓↓↓
x = pair(undefined, pair(3, pair(2, null)));
p.a = x(second)(first);
p.b = x(second)(second)(first);
// ↓↓↓↓↓
p.a = 3;
p.b = 2;
由于涉及到了上下文的修改,这个推导严格上来说已经不能叫推导了,只能叫解说了。不过我们可以发现,仅仅使用可以捕捉可读写的上下文的lambda表达式,已经可以实现可读写的struct的效果了。而且这个struct的读写是通过getter和setter来实现的,于是只要我们写的复杂一点,我们就得到了一个interface。于是那个mutable_pair,就可以看成是一个构造函数了。
大括号不能换行的代码真他妈的难读啊,远远望去就像一坨屎!go语言还把javascript自动补全分号的算法给抄去了,真是没品位。
所以,interface其实跟lambda表达是一样,也可以看成是一个闭包。只是interface的入口比较多,lambda表达式的入口只有一个(类似于C++的operator())。大家可能会问,class是什么呢?class当然是interface内部不可告人的实现细节的。我们知道,依赖实现细节来编程是不对的,所以我们要依赖接口编程。
当然,即使是仓促设计出javascript的那个人,大概也是知道构造函数也是一个函数的,而且类的成员跟函数的上下文链表的节点对象其实没什么区别。于是我们会看到,javascript里面是这么做面向对象的事情的:
function rectangle(a, b) {
this.width = a;
this.height = height;
}
rectangle.prototype.get_area = function() {
return this.width * this.height;
};
var r = new rectangle(3, 4);
print(r.get_area());
然后我们就拿到了一个3×4的长方形的面积12了。不过javascript给我们带来的一点点小困惑是,函数的this参数其实是dynamic scoping的,也就是说,这个this到底是什么,要看你在哪如何调用这个函数。于是其实
整个东西是一个语法,它代表method的this参数是obj,剩下的参数是args。可惜的是,这个语法并不是由“obj.member”和“func(args)”组成的。那么在上面的例子中,如果我们把代码改为:
var x = r.get_area;
print(x());
结果是什么呢?反正不是12。如果你在C#里面做这个事情,效果就跟javascript不一样了。如果我们有下面的代码:
class Rectangle
{
public int width;
public int height;
public int GetArea()
{
return width * height;
}
};
那么下面两段代码的意思是一样的:
var r = new Rectangle
{
width = 3;
height = 4;
};
// 第一段代码
Console.WriteLine(r.GetArea());
// 第二段代码
Func<int> x = r.GetArea;
Console.WriteLine(x());
究其原因,是因为javascript把obj.method(a, b)解释成了GetMember(obj, “method”).Invoke(a, b, this = r);了。所以你做r.get_area的时候,你拿到的其实是定义在rectangle.prototype里面的那个东西。但是C#做的事情不一样,C#的第二段代码其实相当于:
Func<int> x = ()=>
{
return r.GetArea();
};
Console.WriteLine(x());
所以说C#这个做法比较符合直觉啊,为什么dynamic scoping(譬如javascript的this参数)和call by name(譬如C语言的宏)看起来都那么屌丝,总是让人掉坑里,就是因为违反了直觉。不过javascript那么做还是情有可原的。估计第一次设计这个东西的时候,收到了静态类型语言太多的影响,于是把obj.method(args)整个当成了一个整体来看。因为在C++里面,this的确就是一个参数,只是她不能让你obj.method,得写&TObj::method,然后还有一个专门填this参数的语法——没错,就是.*和->*操作符了。
假如说,javascript的this参数要做成lexical scoping,而不是dynamic scoping,那么能不能用lambda表达式来模拟interface呢?这当然是可以,只是如果不用prototype的话,那我们就会丧失javascript爱好者们千方百计绞尽脑汁用尽奇技淫巧锁模拟出来的“继承”效果了:
function mutable_pair(a, b) {
_this = {
get_first = function() { return a; },
get_second = function() { return b; },
set_first = function(value) { a = value; },
set_second = function(value) { b = value; }
};
return _this;
}
var p = new mutable_pair(1, 2);
var a = p.get_first();
var b = p.get_second();
print(a, b);
var c = p.set_first(3);
var d = p.set_second(4);
print(c, d);
这个时候,即使你写
var x = p.set_first;
var y = p.set_second;
x(3);
y(4);
代码也会跟我们所期望的一样正常工作了。而且创造出来的r,所有的成员变量都屏蔽掉了,只留下了几个函数给你。与此同时,函数里面访问_this也会得到创建出来的那个interface了。
大家到这里大概已经明白闭包、lambda表达式和interface之间的关系了吧。我看了一下之前写过的六篇文章,加上今天这篇,内容已经覆盖了有:
- 阅读C语言的复杂的声明语法
- 什么是语法噪音
- 什么是语法的一致性
- C++的const的意思
- C#的struct和property的问题
- C++的多重继承
- 封装到底意味着什么
- 为什么exception要比error code写起来干净、容易维护而且不需要太多的沟通
- 为什么C#的有些interface应该表达为concept
- 模板和模板元编程
- 协变和逆变
- type rich programming
- OO的消息发送的含义
- 虚函数表是如何实现的
- 什么是OO里面的类型扩展开放/封闭与逻辑扩展开放/封闭
- visitor模式如何逆转类型和逻辑的扩展和封闭
- CPS(continuation passing style)变换与异步调用的异常处理的关系
- CPS如何让exception变成error code
- argument passing和symbol resolving
- 如何用lambda实现mutable struct和immutable struct
- 如何用lambda实现interface
想了想,大概通俗易懂的可以自学成才的那些东西大概都讲完了。当然,系列是不会在这里就结束的,只是后面的东西,大概就需要大家多一点思考了。
写程序讲究行云流水。只有自己勤于思考,勤于做实验,勤于造轮子,才能让编程的学习事半功倍。
posted @
2013-07-05 06:31 陈梓瀚(vczh) 阅读(9583) |
评论 (12) |
编辑 收藏代码可以在这里直接下载到:http://www.cppblog.com/Files/vczh/Cppblog备份工具.rar
这是一个C#写的命令行程序,在资源管理器双击运行之后输入你的用户名和密码,然后就可以把目录、博客内容、图片和文件下载到当前目录下的一个叫做CppblogPosts的文件夹下面了。在此需要注意,我只会下载在博客里面引用了的、上传到了cppblog的图片和文件。下载的文件格式如下:
Posts.xml:记录了所有博客文章的一些元数据,还有每一个博客的id。
Post[博客id].txt:每一篇博客的内容。
Images.xml:保存了所有图片的“url”到“文件名”的映射。
Image[GUID]文件名.xxx:文件名。一个文件名究竟对应什么url可以再Images.xml里面查到。
Files.xml:保存了所有文件的“url”到“文件名”的映射。
File[GUID]文件名.xxx:文件名。一个文件名究竟对应什么url可以再Files.xml里面查到。
之所以安排成这样的格式是因为,下载完之后你们就可以自己写程序随便你们怎么处理了。
================无耻的分割线================
在做这个程序之前,我发现cppblog支持metaweblog的api,但是发现这个api没办法遍历帖子的id。我为此还发信给了博客园的管理员,最终让他们加上了这个功能,于是就有了现在这个程序了。在这个程序的代码里面,你们还能看到我用C#写的一个简单的XmlRpc的轮子。之所以不找别人的是因为,自己写比上网找然后学习怎么用快多了,啊哈哈哈哈。
这个轮子可是很漂亮的哦!
posted @
2013-06-29 05:57 陈梓瀚(vczh) 阅读(13089) |
评论 (5) |
编辑 收藏跟大神聊天是很开心的。这不是因为我激动,而是因为大神说出来的每一个字都是有价值的,一针见血,毫无废话。至于为什么说又,当然是这种事情以前发生过。
第一次是在高中认识了龚敏敏。那个时候我刚做完那个傻逼的2D ARPG不久,龚敏敏已经是M$RA的实习生了,图形学上的造诣肯定要比我高许多,其中的差距构成了大神跟菜鸟的关系。当然现在我尽管中心已经放在了程序设计语言(programming language,以下简称PL)上,但是还知道一些图形学的内容,跟龚敏敏的差距自然也已经缩小到了不构成大神和菜鸟的关系的程度了。尽管他还是比我多知道很多东西。
第二次是在大学的时候认识了g9yuayon。g9菊苣是做形式化和证明的,自然也知道很多PL的事情。那应该是我大二的时候,在CSDN上偶然发现了g9菊苣的博客,觉得文章写的很好,就顺便把博客上面的email“密码”给破了之后发email给他。后来g9菊苣告诉了我很多诸如在哪里可以获得知识的事情,于是我也就做了PL。尽管现在已经很少跟g9菊苣联系了,不过我感觉目前我跟g9的差距应该还属于大神跟菜鸟的关系,因为他很久以前写的博客我都还不能完全搞明白。
第三次就是今天的事情了。大家都知道最近我在写一个《如何设计一门语言》的系列文章。这个系列文章肯定是会继续写下去的,因为我的语言都还没做出来。所以可以很明显地看出来,我现在也在做一个语言。这跟王垠的那个one当然是不一样的,因为我从一开始就没打算代替所有东西,而且目标也很明确,就是把它做成跟C++/C#一样,菜鸟可以很容易上手写出清晰易懂的代码,大神也可以在里面挖掘出很多奇技淫巧。于是我不可避免的就遇到了CPS的问题。
大家都知道C#有yield和await两个关键字,F#也有computation expression。于是我就在想,如果yield和await不是关键字,而是一个函数,会发生什么事情。展开来讲,就是如果要让程序员自己实现一个为特定目的服务的CPS变换,那我的语法要怎么做。对于没有怎么设计过程序语言的人来说,“设计一个语法”这种事情其实是很容易被误解的。语法并不是说要在这里放一个括号,在那里放一个关键字,在别的地方还能省略一个什么东西(瞧瞧go抄了javascript那个屎一样的分号省略策略)。这些都属于品味的问题。品味是不需要设计的,那是靠感觉的,是一种艺术。只要你拿出来觉得漂亮,那就是好的。真正需要思考的东西是什么,那自然是围绕早上面的类型系统了。
我用通俗易懂的方法来解释一下,什么是类型系统,或者说在我们这些做PL的人看来,眼中的程序大概是什么样子的。我们拿一个C#的异步程序来说,其实也就是上一篇文章讲的那个例子了。
async void button4_Click(object sender, EventArgs e)
{
try
{
string a=await Http.DownloadAsync(url1);
string b=await Http.DownloadAsync(url2);
textBox1.Text=a+b;
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
}大家都很熟悉吧。如果这个这么简单的程序还看不懂的话,那肯定是没有认真阅读我的《如何》系列。好了,现在开始来讲,做PL的人到底是如何看待这个程序的呢:
async void button4_Click(Object, EventArgs)
{
try
{
String=await (String -> Task<String>) (String);
String=await (String -> Task<String>) (String);
(TextBox -> String -> Void#TextBox.Text) (TextBox, String + String);
}
catch(Exception)
{
(TextBox -> String -> Void#TextBox.Text) (TextBox, (Exception -> String#Exception.Message) (Exception));
}
}嗯,差不多就是这个样子。这个函数究竟是下载一个盗版小说,还是下载一个带节操的日本电影,究竟是同步下载,还是异步下载,是下载到一个文件夹,还是下载到skydrive——关我屁事!我只看这里关于类型的部分。
所以,如果await是一个函数的话,那他应该是什么类型?如果yield也是一个函数,那他应该是什么类型?如果这门语言让程序员来创建属于自己的await和yield甚至是他自己的想要的计算,那我应该如何做一个框架让他往里面套,或者他写出来的这个函数究竟要在什么上下文里面满足什么样的一个类型的关系呢?我最近就一直在想这个问题。
一开始我就把目光投向了F#的computation expression,因为F#的这个东西就具有我想要的一切功能。后来我想把这个功能搬进来的时候,发现怎样都套不上。当然我很快就发现了,这其实是因为F#归根结底还是一个函数是语言,他是不能在一个for循环里面写break、continue或者return的。F#的一个for循环,永远是一个完美的for循环。但是我的语言是可以的,于是这样在类型上就不完美了——不过这是小事,牺牲一点点完美换来易用性是值得的。当然,牺牲很多完美来满足易用性,我觉得是不值得的。
既然for循环里面可以带break/continue/return,那么“我的computation expression”的For函数,就不能是类似于IEnumerable<T>->(T->M<U>)->M<U>这种纯粹的东西了。那我应该怎么做呢?
写到这里,我觉得在微软工作就是好啊。关于编程语言领域的很多改进其实都是从微软这里做出来的。通俗的部分,看看完美的C#,看看ASP.NET MVC的razor模板在Visual Studio里面的智能提示的功能——这可是一个可以混合HTML+CSS+Javascript+C#的代码,写的时候丝般顺滑,行云流水,俨然这四门语言就是一门语言一样。在学术上,微软的各个研究院也贡献了相当多的东西——不过我觉得你们对这些应该是不感兴趣的,尽管你们在linux上面也用了很多微软的成果。
那这能说明什么问题呢?这就意味着,我可以随时access到微软做编程语言的大神们,抓他们来问问题。不过他们是很忙的,经常不在线(我们也有一个类似QQ这样子的东西)。不过今天我随手打开了一下,展开了我积累的几个大神的组,发现F#他爹竟然是绿的,于是我随手就发了一句hi,看看人家在不在。人家回了我,于是我就开始问这个问题了。
什么,你不知道F#他爹是谁?他当然是Don Syme了。写函数式语言不认识Don Syme,就犹如读物理不认识牛顿,读数学不认识柯西,写C++不知道Bjarne Stroustrup,用操作系统不知道Dave Cutler一样,要跪着爬回自己学校里重新读书。
Don Syme是微软的Principle Researcher,翻译过来大概就是“顶级科学家”的意思吧,很少有更牛逼的东西了。
于是故事到这里就结束了,因为Don Syme大神他很快就回复我说,如果for循环支持break/continue/return,那我就不应该从F#的computation expression里面获取灵感。至于我的问题要怎么办,这还是个open question。于是我们愉快的聊天就用下面的一句话结束了:
Don Syme: Research 
posted @
2013-06-25 09:17 陈梓瀚(vczh) 阅读(12670) |
评论 (15) |
编辑 收藏我一直以来对于exception的态度都是很明确的。首先exception是好的,否则就不会有绝大多数的语言都支持他了。其次,error code也没什么问题,只是需要一个前提——你的语言得跟Haskell一样有monad和comonad。你看Haskell就没有exception,大家也写的很开心。为什么呢?因为只要把返回带error code结果的函数给做成一个monad/comonad,那么就可以用CPS变换把它变成exception了。所以说CPS作为跟goto同样基本的控制流语句真是当之无愧呀,只是CPS是type rich的,goto是type poor的。
其实很多人对于exception的恐惧心理在于你不知道一个函数会抛什么exception出来,然后程序一crash你就傻逼了。对于server来讲情况还好,出了问题只要杀掉快速重启就行了,如今没个replication和fault tolerance还有脸说你在写后端(所以不知道那些做web的人究竟在反对什么)?这主要的问题还是在于client。只要client上面的东西还没保存,那你一crash数据就完蛋了是不是——当然这只是你的想象啦,其实根本不是这样子的。
我们的程序抛了一个access violation出来,和抛了其它exception出来,究竟有什么区别呢?access violation是一个很奇妙的东西,一旦抛了出来就告诉你你的程序没救了,继续执行下去说不定还会有破坏作用。特别是对于C/C++/Delphi这类语言来说,你不小心把错误的东西写进了什么乱七八糟的指针里面去,那会儿什么事情都没发生,结果程序跑着跑着就错了。因为你那个算错了得到的野指针,说不定是隔壁的不知道什么object的成员变量,说不定是heap里面的数据结构,或者说别的什么东西,就这么给你写了。如果你写了别的object的成员变量那封装肯定就不管用了,这个类的不变量就给你破坏了。既然你的成员函数都是基于不变量来写的,那这个时候出错时必须的。如果你写到了heap的数据结构那就更加呵呵呵了,说不定下次一new就崩了,而且你还不知道为什么。
出了access violation以外的exception基本是没什么危害的,最严重的大概也就是网线被拔了,另一块不是装OS的硬盘突然坏了什么的这种反正你也没办法但是好歹还可以处理的事情。如果这些exception是你自己抛出来的那就更可靠了——那都是计划内的。只要程序未来不会进入access violation的状态,那证明你现在所能拿到的所有变量,还有指针指向的memory,基本上都还是靠谱的。出了你救不了的错误,至少你还可以吧数据安全的保存下来,然后让自己重启——就跟word一样。但是你有可能会说,拿出了access violation怎么就不能保存数据了呢?因为这个时候内存都毁了,指不定你保存数据的代码new点东西然后挂了,这基本上是没准的。
所以无论你喜欢exception还是喜欢error code,你所希望达到的效果本质上就是避免程序未来会进入access violation的状态。想做到这一点,方法也是很简单粗暴的——只要你在函数里面把运行前该对函数做的检查都查一遍就好了。这个无论你用exception还是用error code,写起来都是一样的。区别在于调用你的函数的那个人会怎么样。那么我来举个例子,譬如说你觉得STL的map实在是太傻比了,于是你自己写了一个,然后有了一个这样子的函数:
// exception版本
Symbol* SymbolMap::Lookup(const wstring& name);
// error code版本
int SymbolMap::Lookup(const wstring& name, Symbol*& result);
// 其实COM就是你们最喜欢的error code风格了,写起来应该很开心才对呀,你们的双重标准真严重
HRESULT ISymbolMap::Lookup(BSTR name, ISymbol** result);
于是拿到了Lookup函数之后,我们就要开始来完成一个任务了,譬如说拿两个key得到两个symbol然后组合出一个新的symbol。函数的错误处理逻辑是这样的,如果key失败了,因为业务的原因,我们要告诉函数外面说key不存在的。调用了一个ComposeSymbol的函数丢出什么IndexOutOfRangeException显然是不合理的。但是合并的那一步,因为业务都在同一个领域内,所以suppose里面的异常外面是可以接受的。如果出现了计划外的异常,那我们是处理不了的,只能丢给上面了,外面的代码对于不认识的异常只需要报告任务失败了就可以了。于是我们的函数就会这么写:
Symbol* ComposeSymbol(const wstring& a, const wstring& b, SymbolMap* map)
{
Symbol* sa=0;
Symbol* sb=0;
try
{
sa=map->Lookup(a);
sa=map->Lookup(b);
}
catch(const IndexOutOfRangeException& ex)
{
throw SymbolKeyException(ex.GetIndex());
}
return CreatePairSymbol(sa, sb);
}看起来还挺不错。现在我们可以开始考虑error code的版本了。于是我们需要思考几个问题。首先第一个就是Lookup失败的时候要怎么报告?直接报告key的内容是不可能的,因为error code是个int。
题外话,error code当然可以是别的什么东西,如果需要返回丰富内容的错误的话,那怎样都得是一个指针了,这个时候你们就会面临下面的问题——这已经他妈不满足谁构造谁释放的原则了呀,而且我这个指针究竟直接返回出去外面理不理呢,如果只要有一个环节不理了,那内存岂不是泄露了?如果我要求把错误返回在参数里面的话,我每次调用函数都要创建出那么个结构来保存异常,不仅有if的复杂度,还有创建空间的复杂度,整个代码都变成了屎。所以还是老老实实用int吧……
那我们要如何把key的信息给编码在一个int里面呢?因为key要么是来自于a,要么是来自于b,所以其实我们就需要两个code了。那Lookup的其他错误怎么办呢?CreatePairSymbol的错误怎么办呢?万一Lookup除了ERROR_KEY_NOT_FOUND以外,或者是CreatePairSymbol的错误刚好跟a或者b的code重合了怎么办?对于这个问题,我只能说:
要不你们team的人先开会讨论一下最后记录在文档里面备查以免后面的人看了傻眼了……
好了,现在假设说会议取得了圆满成功,会议双方加深了互相的理解,促进了沟通,最后还写了一个白皮书出来,有效的落实了对a和b的code的指导,于是我们终于可以写出下面的代码了:
#define SUCCESS 0 // global error code for success
#define ERROR_COMPOSE_SYMBOL_WRONG_A 1
#define ERROR_COMPOSE_SYMBOL_WRONG_B 2
int ComposeSymbol(const wstring& a, const wstring& b, SymbolMap* map, Symbol*& result)
{
int code=SUCCESS;
Symbol* sa=0;
Symbol* sb=0;
switch(code=map->Lookup(a, sa))
{
case SUCCESS:
break;
case ERROR_SYMBOL_MAP_KEY_NOT_FOUND:
return ERROR_COMPOSE_SYMBOL_WRONG_A;
default:
return code;
}
switch(code=map->Lookup(b, sb))
{
case SUCCESS:
break;
case ERROR_SYMBOL_MAP_KEY_NOT_FOUND:
return ERROR_COMPOSE_SYMBOL_WRONG_B;
default:
return code;
}
return CreatePairSymbol(sa, sb, result);
}啊,好像太长,干脆我还是不负责任一点吧,反正代码写的好也涨不了工资,干脆不认识的错误都返回ERROR_COMPOSE_SYMBOL_UNKNOWN_ERROR好了,于是就可以把代码变成下面这样……都到这份上了不要叫自己程序员了,叫程序狗吧……
#define SUCCESS 0 // global error code for success
#define ERROR_COMPOSE_SYMBOL_WRONG_A 1
#define ERROR_COMPOSE_SYMBOL_WRONG_B 2
#define ERROR_COMPOSE_SYMBOL_UNKNOWN_ERROR 3
int ComposeSymbol(const wstring& a, const wstring& b, SymbolMap* map, Symbol*& result)
{
Symbol* sa=0;
Symbol* sb=0;
if(map->Lookup(a, sa)!=SUCCESS)
return ERROR_COMPOSE_SYMBOL_UNKNOWN_ERROR;
if(map->Lookup(b, sb)!=SUCCESS)
return ERROR_COMPOSE_SYMBOL_UNKNOWN_ERROR;
if(CreatePairSymbol(sa, sb, result)!=SUCCESS)
return ERROR_COMPOSE_SYMBOL_UNKNOWN_ERROR;
return SUCCESS;
}当然,如果大家都一样不负责任的话,还是exception完爆error code:
Symbol* ComposeSymbol(const wstring& a, const wstring& b, SymbolMap* map)
{
return CreatePairSymbol(map->Lookup(a), map->Lookup(b));
}
大部分人人只会用在当前条件下最容易写的方法来设计软件,而不是先设计出软件然后再看看怎样写比较容易,这就是为什么我说,只要你一个月给程序员还给不到一狗半,还是老老实实在政策上落实exception吧。至少exception写起来还不会让人那么心烦,可以把程序写得坚固一点。
好了,单线程下面至少你还可以争吵说究竟exception好还是error code好,但是到了异步程序里面就完全不一样了。现在的异步程序都很多,譬如说有良心的手机app啦,譬如说javascript啦,metro程序等等。一个try根本没办法跨线程使用所以一个这样子的函数(下面开始用C#,C++11的future/promise我用的还不熟):
class Normal
{
public string Do(string args);
}
最后就会变成这样:
class Async
{
// before .NET 4.0
IAsyncResult BeginDo(string args, Action<IAsyncResult> continuation);
string EndDo(IAsyncResult ar);
// after .NET 4.0
Task<string> DoAsync(string args);
}
当你使用BeginDo的时候,你可以在continuation里面调用EndDo,然后得到一个string,或者得到一个exception。但是因为EndDo的exception不是在BeginDo里面throw出来的,所以无论你EndDo返回string也好,返回Tuple<string, Exception>也好,对于BeginDo和EndDo的实现来说其实都一样,没有上文所说的exception和error code的区别。
不过.NET从BeginDo/EndDo到DoAsync经历了一个巨大的进步。虽然形式上都一样,但是由于C#并不像Haskell那样可以完美的操作函数,C#还是面向对象做得更好,于是如果我们吧Task<T>看成下面的样子,那其实两种写法是没有区别的:
class Task<T>
{
public IAsyncResult BeginRun(Action<IAsyncResult> continuation);
public T EndRun(IAsyncResult ar);
}
不过如果还是用BeginRun/EndRun这种方法来调用的话,使用起来还是很不方便,而且也很难把更多的Task组合在一起。所以最后.NET给出的Task是下面这个样子的(Comonad!):
class Task<T>
{
public Task<U> ContinueWith<U>(Func<Task<T>, U> continuation);
}
尽管真实的Task<T>要比上面那个复杂得多,但是总的来说其实就是围绕着基本简单的函数建立起来的一大堆helper function。到这里C#终于把CPS变换在异步处理上的应用的这一部分给抽象出来了。在看CPS的效果之前,我们先来看一个同步函数:
void button1_Clicked(object sender, EventArgs e)
{
// 假设我们有string Http.Download(string url);
try
{
string a = Http.Download(url1);
string b = Http.Download(url2);
textBox1.Text=a+b;
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
}
这段代码显然是一个GUI里面的代码。我们如果在一个GUI程序里面这么写,就会把程序写得跟QQ一样卡了。所以实际上这么做是不对的。不过为了表达程序需要做的所有事情,就有了这么一个同步的版本。那么我们尝试吧这个东西修改成异步的把!
void button2_Clicked(object sender, EventArgs e)
{
// 假设我们有Task<string> Http.DownloadAsync(string url);
// 需要MethodInvoker是因为,对textBox1.Text的修改只能在GUI线程里面做
Http.DownloadAsync(url1).ContinueWith(ta=>new MethodInvoker(()=>
{
try
{
// 这个时候ta已经运行完了,所以对ta.Result的取值不会造成GUI线程等待IO。
// 而且如果DownloadAsync内部出了错,异常会在这里抛出来。
string a=ta.Result;
Http.DownloadAsync(url2).ContinueWith(tb=>new MethodInvoker(()=>
{
try
{
string b=tb.Result;
textBox1.Text=a+b;
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
})));
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
})));
}
我们发现,异步操作发生的异常,把优越的exception拉低到了丑陋的error code的同一个情况上面——我们需要不断地对每一个操作重复同样的错误处理过程!而且在这种地方我们连“不负责任”的选项都没有了,如果你不try-catch(或者不检查error code),那到时候程序就会发生一些莫名其妙的问题,在GUI那一层你什么事情都不知道,整个程序就变成了傻逼。
现在可以开始解释一下什么是CPS变换了。CPS变换就是把所有g(f(x))都给改写成f(x, r=>g(r))的过程。通俗一点讲,CPS变换就是帮你把那个同步的button1_Click给改写成异步的button2_Click的这个过程。尽管这么说可能不太严谨,因为button1_Click跟button2_Click所做的事情是不一样的,一个会让GUI卡成qq,另一个不会。但是我们讨论CPS变换的时候,我们讨论的是对代码结构的变换,而不是别的什么东西。
现在就是激动人心的一步了。既然CPS可以把返回值变换成lambda表达式,那反过来我们也可以把所有的以这种形式存在的lambda表达式都改写成返回值嘛。现在我们滚回去看一看button2_Click,会发现这个程序其实充满了下面的pattern:
// lambda的参数名字故意起了跟前面的变量一样的名字(previousTask)因为其实他们就是同一个东西
previousTask.ContinueWith(previousTask=>new MethodInvoker(()=>
{
try
{
continuation(previousTask.Result);
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
})));我们可以“发明”一个语法来代表这个过程。C#用的是await关键字,那我们也来用await关键字。假设说上面的代码永远等价于下面的这个代码:
try
{
var result=await previousTask;
continuation(result);
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
两段代码的关系就跟i++;和i=i+1;一样是可以互相替换的,只是不同的写法而已。那我们就可以用相同的方法来把button2_Click给替换成下面的button3_Click了:
void button3_Click(object sender, EventArgs e)
{
try
{
var a=await Http.DownloadAsync(url1);
try
{
var b=await Http.DownloadAsync(url2);
textBox1.Text=a+b;
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
}
聪明的读者立刻就想到了,两个try其实是重复的,那为什么不把他们合并成一个呢!当然我想告诉大家的是,异常是在不同的线程里面抛出来的,只是我们用CPS变换把代码“改写”成这种形式而已。理论上两个try是不能合并的。但是!我们的C#编译器君是很聪明的。正所谓语言的抽象高级了一点,那么编译器对你的代码也就理解得更多了一点。如果编译器发现你在try里面写了两个await,马上就明白了过来他需要帮你复制catch的部分——或者说他可以帮你自动的复制catch的部分,那情况就完全不同了,最后就可以写成:
// C#要求函数前面要加一个async来允许你在函数内使用await
// 当然同时你的函数也就返回Task而不是void了
// 不过没关系,C#的event也可以接受一个标记了async的函数,尽管返回值不一样
// 设计语言这种事情就是牵一发而动全身呀,加个await连event都要改
async void button4_Click(object sender, EventArgs e)
{
try
{
string a=await Http.DownloadAsync(url1);
string b=await Http.DownloadAsync(url2);
textBox1.Text=a+b;
}
catch(Exception ex)
{
textBox1.Text=ex.Message;
}
}
把两个await换成回调已经让我们写的够辛苦了,那么如果我们把await写在了循环里面,事情就不那么简单了。CPS需要把循环翻译成递归,那你就得把lambda表达时拿出来写成一个普通的函数——这样他就可以有名字了——然后才能递归(写出一个用于CPS的Y-combinator是一件很困难的事情,尽管并没有比Y-combinator本身困难多少)。这个例子就复杂到爆炸了,我在这里就不演示了。
总而言之,C#因为有了CPS变换(await),就可以把button4_Click帮你写成button3_Click然后再帮你写成button2_Click,最后把整个函数变成异步和回调的形式(真正的做法要更聪明一点,大家可以反编译去看)在异步回调的写法里面,exception和error code其实是一样的。但是CPS+exception和CPS+error code就跟单线程下面的exception和error code一样,有着重大的区别。这就是为什么文章一开始会说,我只会在带CPS变换的语言(Haskell/F#/etc)里面使用error code。
在这类语言里面利用相同的技巧,就可以不是异步的东西也用CPS包装起来,譬如说monadic parser combinator。至于你要选择monad还是comonad,基本上就是取决于你要自动提供错误处理还是要手动提供错误处理。像上面的Task.ContinueWith,是要求你手动提供错误处理的(因为你catch了之后可以干别的事情,Task无法自动替你选择最好的措施),所以他就把Task.ContinueWith写成了comonad的那个样子。
写到这里,不禁要同情写前端的那帮javascript和自以为可以写后端的node.js爱好者们,你们因为小小的eval的问题,不用老赵的windjs(windjs给javascript加上了await但是它不是一个altjs所以得显式调用eval),是一个多大的损失……
posted @
2013-06-09 23:01 陈梓瀚(vczh) 阅读(14111) |
评论 (8) |
编辑 收藏面向对象这个抽象的特例总是有说不完的话题,更糟糕的是很多语言都错误地实现了面向对象——class居然可以当一个变量类型什么的这只是让人们写代码写的更糟糕而已。当然这个话题第三篇文章已经说过了,现在来谈谈人们喜欢拿来装逼的另一个话题——消息发送。
按照惯例先来点题外话。说到消息发送,有些人喜欢跳出来说,objective-c的消息做得多优雅啊,代码都可以写成一句话[golang screw:you you:suck]之类的。其实这个还做得不够彻底。在几年前易语言曾经火了一阵,但是为什么大家这么讨厌他呢?其实显然不是因为每个token都是汉字,而是因为他做的一点都不像中文,谁会说话的时候带那么多符号呀。其实objective-c也一样,没人会因为想在一句英语里面用冒号来分割短语的。
当我还在读大三的时候,我由于受到了Apple Script(也是苹果做的)的启发,试图发明一门语言,让他可以尽量写起来像自然语言——当然他仍然是严格的编程语言。但是这门语言因为其奇特的语法结构,我只好自己想出了一个两遍parse地方法。第一遍parse出所有函数头,让后用这些函数头临时组成一个parser,用它来parse语句的部分。后面整个也实现出来了,然后我就去做了一下调查,发现大家不喜欢,原因是要输入的东西太多了。不过我这里还是贴一下当初是怎么设计的:
phrase print(content) is
external function "writeln"
end phrase
phrase first (count) items of fibonacci sequence is
if count equals to 1 then
result is [1]
else if count equals to 2 then
result is [1,1]
else
let list be [1,1]
repeat with i from 3 to count
let list be list joins with item length of list - 1 of list + item length of list - 2 of list
end
result is list
end
end phrase
phrase (number) is odd is
result is number mod 2 is 0
end phrase alias odd number
phrase append (item) after (list) is
let 0 element of list from length of list be [item]
end phrase
phrase ((item) is validated) in (list) is
let filtered list be []
repeat with item in list
append item after filtered list if item is validated
end
result is filtered list
end phrase
phrase main is
print odd number in first 10 items of fibonacci sequence
end phrase倒数第二个函数声明甚至连函数指针的声明也如此的优雅(我自己认为的),整个程序组织起来,我们要输出斐波那契数列里面前10个数字中间的奇数,于是就写成了
print odd number in first 10 items of fibonacci sequence
看起来比objective-c要漂亮把。其实如果想把所有的东西换成中文,算法也不需要变化。现在用空格来分割一个一个的词,中文直接用字符就好了,剩下的都一样。要parse这个程序根本没办法用流行的那些方法来parse。当然我知道大家也不会关心这些特别复杂的问题,于是题外话就到这里结束了,这个语言的实现的代码你们大概也永远都不会看到的,啊哈哈哈哈。
为什么要提这件事情呢?我主要是想告诉大家,就算你在用面向对象语言,想在程序里面给一个对象发送一条消息,这个对象并不是非得写在最前面的。为什么呢?有的时候对象不止一个——这个东西叫multiple dispatching,著名的问题就是如何给一堆面向对象的几何体类做他们的求交函数——用面向对象的惯用做法做起来会特别的难受。不过现在我们先来看一下普通的消息发送是什么样子的。
对于一个我们知道他是什么类型的对象来说,发送一个消息就跟直接调用一个函数一样,因为你不需要去resolve一下这个函数到底是谁。譬如说下面的代码:
class Language
{
public:
void YouSuck(){ ... }
};
Language golang;
golang.YouSuck();最终翻译出来的结果会近似于
struct Language
{
};
void Language_YouSuck(Language* const this)
{
...
}
Language golang;
Language_YouSuck(&golang);很多人其实并不能在学习面向对象语言的时候就直接意识到这一点。其实我也是在高中的时候玩delphi突然就在网上看见了这么一篇文章,然后我才明白的。看起来这个过渡并不是特别的自然是不是。
当你要写一个独立的class,不继承自任何东西的时候,这个class的作用只有两个。第一个是封装,这个第三篇文章已经提到过了。第二个作用就是给里面的那些函数做一个匿名的namespace。这是什么意思呢?就像上面的代码一样,你写golang.YouSuck(),编译器会知道golang是一个Language,然后去调用Language::YouSuck()。如果你调用lisp.YouSuck()的时候,说不定lisp是另一个叫做BetterThanGolangLanguage的类型,然后他就去里面找了YouSuck。这里并不会因为两个YouSuck的名字一样,编译器就把它搞混了。这个东西这跟重载也差不多,我就曾经在Microsoft Research里面看见过一个人做了一个语言(主要是用来验证语言本身的正确性的),其中a.b(c, d)是b(a, c, d)的语法糖,这个“.”毫无特别之处。
有一天,情况变了。专门开发蹩脚编译器的AMD公司看见golang很符合他们的口味,于是也写了一个golang的实现。那这个事情应该怎么建模呢?因为golang本身是一套标准,你可也可以称呼他为协议,然后下面有若干个实现。所以Language本身作为一个category也只好跟着golang变成interface了。为了程序简单我们只看其中的一个小片段:
class IGolang
{
public:
virtual void YouSuck()=0;
};
class GoogleGolang : public IGolang
{
public:
void YouSuck()override{ /*1*/ }
};
class AmdGolang : public IGolang
{
public:
void YouSuck()override{ /*2*/ }
};
IGolang* golang = new GoogleGolang;
golang->YouSuck();我很喜欢VC++的专有关键字override,他可以在我想override但是不小心写错了一点的时候提示我,避免了我大量的错误的发生。当然这个东西别的编译器不支持,所以我在我的代码的靠前的地方写了一个宏,发现不是VC++再编译,我就把override给#define成空的。反正我的程序里面不会用关键字来当变量名的。
看着这个程序,已经不能单纯的用GoogleGolang_YouSuck(golang)来代替这个消息发送了,因为类型是IGolang的话说不定下面是一个AmdGolang。所以在这里我们就要引入虚函数表了。一旦引入了虚函数表,代码就会瞬间变得复杂起来。我见过很多人问,虚函数表那么大,要是每一个类的实例都带一个表的话岂不是很浪费内存?这种人就应该先去看《Inside the C++ Object Model》,然后再反省一下自己的问题有多么的——呃——先看带有虚函数表的程序长什么样子好了:
struct vtable_IGolang
{
void (*YouSuck)(IGolang* const this);
};
struct IGolang
{
vtable_IGolang* vtable;
};
//---------------------------------------------------
vtable_IGolang vtable_GoogleGolang;
vtable_GoogleGolang.YouSuck = &vtable_GoogleGolang_YouSuck;
struct GoogleGolang
{
IGolang parent;
};
void vtable_GoogleGolang_YouSuck(IGolang* const this)
{
int offset=(int)(&((GoogleGolang*)0)->parent);
GoogleGolang_YouSuck((GoogleGolang*)((char*)this-offset));
}
void GoogleGolang_YouSuck(GoogleGolang* const this)
{
/*1*/
}
void GoogleGolang_ctor(GoogleGolang* const this)
{
this->parent->vtable = &vtable_GoogleGolang;
}
//---------------------------------------------------
// AmdGolang略,长得都一样
//---------------------------------------------------
GoogleGolang* tmp = (GoogleGolang*)malloc(sizeof(GoogleGolang));
GoogleGolang_ctor(tmp);
IGolang* golang = &tmp->parent;
golang->vtable->YouSuck(golang);基本上已经面目全非了。当然实际上C++生成的代码比这个要复杂得多。我这里只是不想把那些细节牵引进来,针对我们的那个例子写了个可能的实现。面向对象的语法糖多么的重要啊,尽管你也可以在需要的时候用C语言把这些东西写出来(就跟那个愚蠢的某著名linux GUI框架一样),但是可读性已经完全丧失了吧。明明那么几行就可以表达出来的东西,我们为了达到同样的性能,用C写要把代码写成屎。东西一多,名字用完了,都只好对着代码发呆了,决定把C扔了,完全用C++来写。万一哪天用到了virtual继承——在某些情况下其实是相当好用的,譬如说第三篇文章讲的,在C++里面用interface,而且也很常见——那用C就只能呵呵呵了,写出来的代码再也没法读了,没法再把OOP实践下去了。
好了,消息发送的简单的实现大概也就讲到这里了。只要不是C++,其他语言譬如说只有单根继承的Delphi,实现OOP大概也就是上面这个样子。于是我们围绕着消息发送的语法糖玩了很久,终于遇到了两大终极问题。这两个问题说白了都是开放和封闭的矛盾。我们用基类和一大堆子类的结构来写程序的时候,需要把逻辑都封装在虚函数里面,不然的话你就得cast了,cast是将程序最终导向失控的根源之一。这个时候我们对类型扩展是开放的,而对逻辑扩展是封闭的。这是什么意思呢?让我们来看下面这个例子:
class Shape
{
public:
virtual double GetArea()=0;
virtual bool HitTest(Point p)=0;
};
class Circle : public Shape ...;
class Rectangle : public Shape ... ;我们每当添加一个新形状的时候,只要实现GetArea和HitTest,那么事情就做完了。所以你可以无限的添加新形状——所以类型扩展是开放的。但是你却永远只能做GetArea和HitTest——对逻辑扩展是封闭的。你如果想做除了GetArea和HitTest以外的更多的事情的话,这个时候你就被迫做cast了。那么在类型相对稳定的情况下有没有别的方法呢?设计模式告诉我们,我们可以用Visitor来把情况扭转过来——做成对类型扩展封闭,而对逻辑扩展开放的:
class IShapeVisitor
{
public:
virtual void Visit(Circle* shape)=0;
virtual void Visit(Rectangle* shape)=0;
};
class Shape
{
public:
virtual void Accept(IShapeVisitor* visitor)=0;
};
class Circle : public Shape
{
public:
...
void Accept(IShapeVIsitor* visitor)override
{
visitor->Visit(this); // 因为重载的关系,会调用到第一个Visit函数
}
};
class Rectangle : public Shape
{
public:
...
void Accept(IShapeVIsitor* visitor)override
{
visitor->Visit(this); // 因为重载的关系,会调用到第二个Visit函数
}
};
//------------------------------------------
class GetAreaVisitor : public IShapeVisitor
{
public:
double result;
void Visit(Circle* shape)
{
result = ...;
}
void Visit(Rectangle* shape)
{
result = ...;
}
};
class HitTestVisitor : public IShapeVisitor ...;这个时候GetArea可能调用起来就不是那么方便了,不过我们总是可以把它写成一个函数:
double GetArea(Shape* shape)
{
GetAreaVisitor visitor;
shape->Accept(&visitor);
return visitor.result;
}这个时候你可以随意的做新的事情了,但是一旦需要添加新类型的时候,你需要改动很多东西,首先是Visitor的接口,其实是让所有的逻辑都支持新类型,这样你就不能仅仅通过添加新代码来扩展新类型了。所以这就是对逻辑扩展开放,而对类型扩展封闭了。
所以第一个问题就是:能不能做成类型扩展也开放,逻辑扩展也开放呢?在回答这个问题之前,我们先来看下一个问题。我们要对两个Shape进行求交,看看他们是不是有重叠在一起的部分。但是每一个具体的Shape,譬如Circle啊Rectangle啊,定义都是不一样的,没办法有通用的处理办法,所以我们只能写3个函数了(RR, CC, CR)。如果有3各类型,那么我们就需要6个函数。如果有4个类型,那我们就需要有10个函数——才能处理所有情况。公式倒是可以一下子看出来,函数数量就等于1+2+ … +n,n等于类型的数量。
这看起来好像是一个类型扩展开放的问题是吧,但是实际上他只能用逻辑扩展的方法来做。为什么呢?你看我们的一个visitor其实很像是我们对一个一个的具体类型都试一下看看shape是不是这个类型,从而做出正确的处理。不过这跟我们直接用if地方法相比有两个优点:1、快;2、编译器替你查错有保证。
那实际上应该怎么做呢?想想,我们这里有两次“if type”。第一次针对第一个参数,第二次针对第二个参数。所以我们一共需要n+1=3个visitor。写的方法倒是不复杂,首先我们得准备好RR,CC,CR三个逻辑,然后用visitor去识别类型然后调用它们:
bool IntersectCC(Circle* s1, Circle* s2){ ... }
bool IntersectCR(Circle* s1, Rectangle* s2){ ... }
bool IntersectRR(Rectangle* s1, Rectangle* s2){ ... }
// RC和CR是一样的
class IntersectWithCircleVisitor : public IShapeVisitor
{
public:
Circle* s1;
bool result;
void Visit(Circle* shape)
{
result=IntersectCC(s1, shape);
}
void Visit(Rectangle* shape)
{
result=IntersectCR(s1, shape);
}
};
class IntersectWithRectangleVisitor : public IShapeVisitor
{
public:
Rectangle* s1;
bool result;
void Visit(Circle* shape)
{
result=IntersectCR(shape, s1);
}
void Visit(Rectangle* shape)
{
result=IntersectRR(s1, shape);
}
};
class IntersectVisitor : public IShapeVisitor
{
public:
bool result;
IShape* s2;
void Visit(Circle* shape)
{
IntersectWithCircleVisitor visitor;
visitor.s1=shape;
s2->Accept(&visitor);
result=visitor.result;
}
void Visit(Rectangle* shape)
{
IntersectWithRectangleVisitor visitor;
visitor.s1=shape;
s2->Accept(&visitor);
result=visitor.result;
}
};
bool Intersect(Shape* s1, Shape* s2)
{
IntersectVisitor visitor;
visitor.s2=s2;
s1->Accept(&visitor);
return visitor.result;
}我觉得你们现在心里的想法肯定是:“我屮艸芔茻。”嗯,这种事情在物理引擎里面是经常要碰到的。然后当你需要添加一个新的形状的时候,呵呵呵呵呵呵呵呵。不过这也是没办法的,谁让现在的要求运行时性能的面向对象语言都这么做呢?
当然,如果在不要求性能的情况下,我们可以用ruby和它的mixin来做。至于说怎么办,其实你们应该发现了,添加一个Visitor和添加一个虚函数的感觉是差不多的。所以只要把Visitor当成虚函数的样子,让Ruby给mixin一堆新的函数进各种类型就好了。不过只有支持运行时mixin的语言才能做到这一点。强类型语言我觉得是别想了。
Mixin地方法倒是很直接,我们只要把每一个Visitor里面的Visit函数都给加进去就好了,大概感觉上就类似于:
class Shape
{
public:
// Mixin的时候等价于给每一个具体的Shape类都添加下面三个虚函数的重写
virtual bool Intersect(Shape* s2)=0;
virtual bool IntersectWithCircle(Circle* s1)=0;
virtual bool IntersectWithRectangle(Rectangle* s1)=0;
};
//--------------------------------------------
bool Circle::Intersect(Shape* s2)
{
return s2->IntersectWithCircle(this);
}
bool Rectangle::Intersect(Shape* s2)
{
return s2->IntersectWithRectangle(this);
}
//--------------------------------------------
bool Circle::IntersectWithCircle(Circle* s1)
{
return IntersectCC(s1, this);
}
bool Rectangle::IntersectWithCircle(Circle* s1)
{
return IntersectCR(s1, this);
}
//--------------------------------------------
bool Circle::IntersectWithRectangle(Rectangle* s1)
{
return IntersectCR(this, s1);
}
bool Rectangle::IntersectWithRectangle(Rectangle* s1)
{
return IntersectRR(s1, this);
}这下子应该看出来为什么我说这种方法只能用Visitor了吧,否则就要把所有类型都写进Shape,就会很奇怪了。如果这样的逻辑一多,类型也有四五个的话,那每加一个逻辑就得添加一批虚函数,Shape类很快就会被玩坏了。而代表逻辑的Visitor是可以放在不同的地方的,互相之间是隔离的,维护起来就会比较容易。
那现在我们就要有第二个问题了:在拥有两个“this”的情况下,我们要如何做才能把逻辑做成类型扩展也开放,逻辑扩展也开放呢?然后参考我们的第一个问题:能不能做成类型扩展也开放,逻辑扩展也开放呢?你应该心里有数了吧,答案当然是——不能做。
这就是语言的极限了。面向对象才用的single dispatch的方法,能做到的东西是很有限的。情况稍微复杂那么一点点——就像上面对两个形状求交这种正常的问题——写起来都这么难受。
那呼应一下标题,如果我们要设计一门语言,来支持上面这种multiple dispatch,那可以怎么修改语法呢?这里面分为两种,第一种是像C++这样运行时load dll不增加符号的,第二种是像C#这样运行时load dll会增加符号的。对于前一种,其实我们可以简单的修改一下语法:
bool Intersect(switch Shape* s1, switch Shape* s2);
bool Intersect(case Circle* s1, case Circle* s2){ ... }
bool Intersect(case Circle* s1, case Rectangle* s2){ ... }
bool Intersect(case Rectangle* s1, case Circle* s2){ ... }
bool Intersect(case Rectangle* s1, case Rectangle* s2){ ... }然后修改一下编译器,把这些东西翻译成虚函数塞回原来的Shape类里面就行了。对于第二种嘛,其实就相当于Intersect的根节点、Circle和CC写在dll1,Rectangle和CR、RC、RR写在dll2,然后dll1运行时把dll2给动态地load了进来,再之后调用Intersect的时候就好像“虚函数已经进去了”一样。至于要怎么做,这个大家回去慢慢思考一下吧,啊哈哈哈。
posted @
2013-05-24 19:08 陈梓瀚(vczh) 阅读(11580) |
评论 (5) |
编辑 收藏