larbin分析、源码分析、结构分析
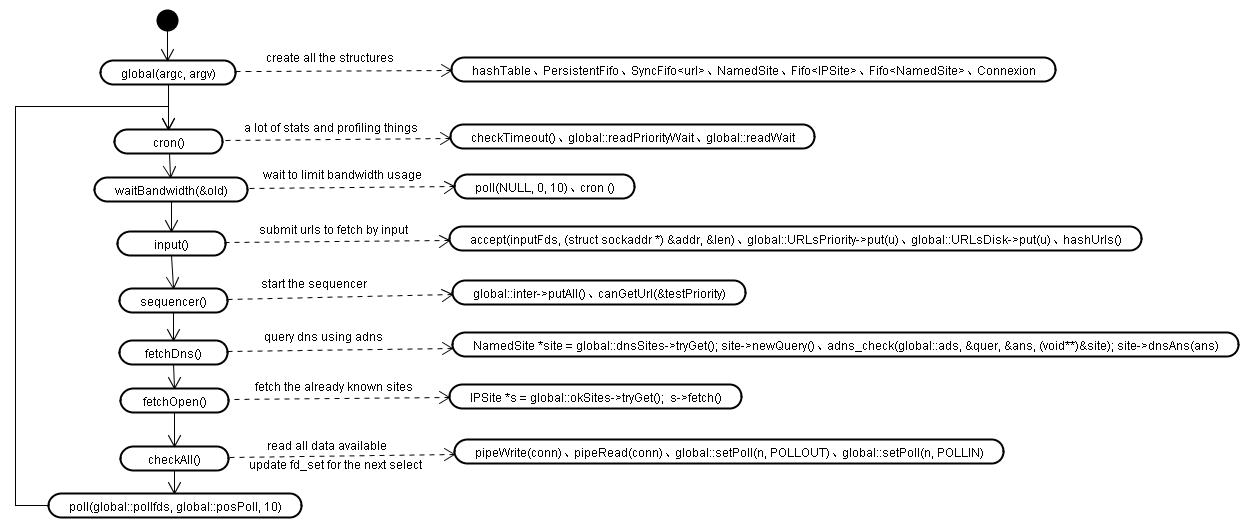
单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连接,通过poll/epoll/select对连接状态进行判断,在第一时间响应请求,不但充分利用了网络资源,同时也将本机CPU资源的消耗降至最低。这种方法需要对dns请求,连接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就需要考虑具体的设计问题了。
url肯定需要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后需要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还需要一个Document Hash表。
爬过的url需要记录下来,由于量比较大,我们将它写到磁盘上,所以还需要一个FIFO的类(记作urlsDisk)。
现在需要爬的url同样需要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取出来,写到这个FIFO里。正在运行的爬虫需要从这个FIFO里读数据出来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接读url出来,不过优先级应该比这个里面出来的url低,毕竟是已经爬过的。
爬虫一般是对多个网站进行爬取,但在同时站点内dns的请求可以只做一次,这就需要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后需要有一个解析完成的IP类与之应用,用于connect的时候使用。
HTML文档的解析类也要有一个,用来分析网页,取出里面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的连接,需要改进,另外如果对于大规模的爬虫,这仅仅实现了抓取的部分,要分布式的扩展还需要增加url的集中管理与调度以及前台spider的分布式算法。
说的简单易懂一些,网络爬虫跟你使用的〖离线阅读〗工具差不多。说离线,其实还是要跟网络联结,否则怎么抓东西下来?
那么不同的地方在哪里?
1】 网络爬虫高度可配置性。
2】 网络爬虫可以解析抓到的网页里的链接
3】 网络爬虫有简单的存储配置
4】 网络爬虫拥有智能的根据网页更新分析功能
5】 网络爬虫的效率相当的高
那么依据特征,其实也就是要求了,如何设计爬虫呢?要注意哪些步骤呢?
1】 url 的遍历和纪录
这点 larbin 做得非常的好,其实对于url的遍历是很简单的,例如:
cat [what you got]| tr " \n | gawk '{print $2}' | pcregrep ^ http://
就可以得到一个所由的 url 列表
2】多进程 VS 多线程
各有优点了,现在一台普通的PC 例如 booso.com 一天可以轻松爬下5个G的数据。大约20万网页。
3】时间更新控制
最傻的做法是没有时间更新权重,一通的爬,回头再一通的爬。
通常在下一次爬的的数据要跟上一次进行比较,如果连续5次都没有变化,那么将爬这个网页的时间间隔扩大1倍。
如果一个网页在连续5次爬取的时候都有更新,那么将设置的爬取时间缩短为原来的1/2。
注意,效率是取胜的关键之一。
4】爬的深度是多少呢?
看情况了。如果你比较牛,有几万台服务器做网络爬虫,我劝您跳过这一点。
如果你同我一样只有一台服务器做网络爬虫,那么这样一个统计您应该知道:
网页深度:网页个数:网页重要程度
0 : 1 : : 10
1 :20 : :8
2: :600: :5
3: :2000: :2
4 above: 6000: 一般无法计算
好了,爬到三级就差不多了,再深入一是数据量扩大了3/4倍,二是重要度确下降了许多,这叫做“种下的是龙种,收获的是跳蚤。”
5】爬虫一般不直接爬对方的网页,一般是通过一个Proxy出去,这个proxy有缓解压力的功能,因为当对方的网页没有更新的时候,只要拿到 header 的 tag就可以了,没有必要全部传输一次了,可以大大节约网络带宽。
apache webserver里面纪录的 304 一般就是被cache的了。
6】请有空的时候照看一下robots.txt
7】存储结构。
这个人人见智,google 用 gfs 系统,如果你有7/8台服务器,我劝你用NFS系统,要是你有70/80个服务器的话我建议你用afs 系统,要是你只有一台服务器,那么随便。
给一个代码片断,是我写的新闻搜索引擎是如何进行数据存储的:
NAME=`echo $URL |perl -p -e 's/([^w-.@])/$1 eq " " ? " ":sprintf("%%%2.2x",ord($1))/eg'`
mkdir -p $AUTHOR
newscrawl.pl $URL --user-agent="news.booso.com+(+ http://booso.com)" -outfile=$AUTHOR/$NAME
larbin官方地址:http://larbin.sourceforge.net/index-eng.html
larbin,a input system。
定制larbin: http://larbin.sourceforge.net/custom-eng.html
1、对爬来的网页定制自己的输出。
目前系统已经定义了4中输出,参见src/interf/useroutput.cc。自己的输出可以参考它们写。
2、修改larbin.conf,options.h进行简单定制。
Labin、OpenSpider、天网 三款爬虫对比分析
Labin、OpenSpider、天网 是三款比较著名的网络爬虫,其中天网现在已经做成了分布式爬虫,据称天网在ftp搜索方面水平比较高。这三款爬虫本人都接触过,对于Labin和天网的源代码也研究过一段时间。
Larbin:
首先,Labin采用的socket方式是 单线程非阻塞式的爬取。具体的技术实现采用 linux/unix的poll轮询接口。当Larbin读取种子网站以后,会解析出网页中的url.从源代码中来看,Larbin提取url的技术水平并不高,只是采取简单的字符串操作。然而url是各种各样的,字符串操作能否提取90%以上html网页中的url,还值得怀疑。
当被urls被提取以后,Labin建立了四个队列存取之:两个优先权队列、两个普通队列。为什么要这么做呢?我想做着可能这样想:优先权队列用作采集优先权高的url,而这个优先权怎么计算?这个要根据系统的实际情况了!如果是垂直搜索引擎,可能会根据倾向性、内容相关性来打分,分数高则优先级高。甚至会用分类、聚类或者各种评判手段,甚至pagerank/hits 算法来预先计算url的权重。如果是普通搜索引擎,那么可以这样计算打分:要不根据爬取的网页深度,要不根据是否location字段等等。Larbin中优先权是根据什么来计算的,我想读了上面的东西已经不重要了。
既然提取了urls,就要对url进行域名解析。Larbin自建立了一个DNS服务器。关于DNS服务器的运作,鲜有说明。我自己是这样认为的:首先,本地(Larbin)的dns与外网的DNS进行交互,将外网的DNS的相关内容读取进来。然后,就可以响应larbin的解析请求了。所以当开启DNS服务器的时候,应该会有一个大量读取外网DNS内容的过程。
Larbin似乎是将解析完毕的DNS存入一个管道之中,一头进,一头出。出的一头就是继续重复爬取了。另外Larbin的url消重算法是采用的是普通的bloom filter算法。不在累赘了。
总结:从上面看来,Larbin只是一个小型架构的爬虫,并不适合大型分布式爬取。其架构针对小型爬虫来说,轻装上阵,非常合理。但是对于大型爬虫则是非常的不合理了。
OpenSpider:
OpenSpider我并没细看,大体上也就是那么个流程。不过值得一提的是,OpenSpider提取urls采用的是正则表达式的方法。这个是值得大书特书的。
关于正则表达式的具体设计,需要丰富的工程项目经验。其设计非常复杂。
天网:
天网的初期版本在这三个爬虫之中是最差劲的。几乎毫无架构可言。不过凡事都是从低级做起,还是要大书一番。勇气可嘉么。
看得出来,天网模仿了很多开源系统。譬如一个http的简单读取器,还有Larbin似乎也看到了模仿的影子。低等科技国家只能够从模仿开始。一味鼓吹创新只能是自欺欺人。
天网开了几个线程,并行进行爬取。爬取流程大约如下:
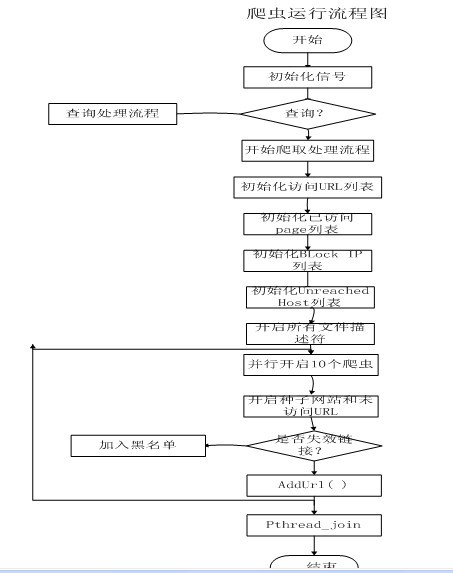
足见,天网将爬来的并解析的url直接放在了map,vector等容器中,消重也是简单的MD5匹配。同时也设置了一个已爬取的容器。socket采用的是非阻塞的select。但是我怀疑他们的select没有起作用。用法等于没有用。
以上是我对三款爬虫的简要分析。因为没有必要进行非常细致的抠,所以很多地方都是一笔带过。谬误之处肯定很多的,希望大家多指教。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/liwenjia1981/archive/2009/11/21/4846668.aspx