2013年4月14日
#
我现在是自己做,但我此前有多年在从事软件开发工作,当回过头来想一想自己,觉得特别想对那些初学JAVA/DOT。NET技术的朋友说点心里话,希望你们能从我们的体会中,多少受点启发(也许我说的不好,你不赞同但看在我真心的份上别扔砖头啊).
一。 在中国你千万不要因为学习技术就可以换来稳定的生活和高的薪水待遇,你千万更不要认为哪些从事 市场开发,跑腿的人,没有前途。
不知道你是不是知道,咱们中国有相当大的一部分软件公司,他们的软件开发团队都小的可怜,甚至只有1-3个人,连一个项目小组都算不上,而这样的团队却要承担一个软件公司所有的软件开发任务,在软件上线和开发的关键阶段需要团队的成员没日没夜的加班,还需要为测试出的BUG和不能按时提交的软件模块功能而心怀忐忑,有的时候如果你不幸加入现场开发的团队你则需要背井离乡告别你的女友,进行封闭开发,你平时除了编码之外就是吃饭和睡觉(有钱的公司甚至请个保姆为你做饭,以让你节省出更多的时间来投入到工作中,让你一直在那种累了就休息,不累就立即工作的状态)
更可怕的是,会让你接触的人际关系非常单一,除了有限的技术人员之外你几乎见不到做其他行业工作和职位的人,你的朋友圈子小且单一,甚至破坏你原有的爱情(想象一下,你在外地做现场开发2个月以上,却从没跟女友见过一面的话,你的女友是不是会对你呲牙裂嘴)。
也许你拿到了所谓的白领的工资,但你却从此失去享受生活的自由,如果你想做技术人员尤其是开发人员,我想你很快就会理解,你多么想在一个地方长期待一段时间,认识一些朋友,多一些生活时间的愿望。
比之于我们的生活和人际关系及工作,那些从事售前和市场开发的朋友,却有比我们多的多的工作之外的时间,甚至他们工作的时间有的时候是和生活的时间是可以兼顾的,他们可以通过市场开发,认识各个行业的人士,可以认识各种各样的朋友,他们比我们坦率说更有发财和发展的机会,只要他们跟我们一样勤奋。(有一种勤奋的普通人,如果给他换个地方,他马上会成为一个勤奋且出众的人。)
二。在学习技术的时候千万不要认为如果做到技术最强,就可以成为100%受尊重的人。
有一次一个人在面试项目经理的时候说了这么一段话:我只用最听话的人,按照我的要求做只要是听话就要,如果不听话不管他技术再好也不要。随后这个人得到了试用机会,如果没意外的话,他一定会是下一个项目经理的继任者。
朋友们你知道吗?不管你技术有多强,你也不可能自由的腾出时间象别人那样研究一下LINUX源码,甚至写一个LINUX样的杰作来表现你的才能。你需要做的就是按照要求写代码,写代码的含义就是都规定好,你按照规定写,你很快就会发现你昨天写的代码,跟今天写的代码有很多类似,等你写过一段时间的代码,你将领略:复制,拷贝,粘贴那样的技术对你来说是何等重要。(如果你没有做过1年以上的真正意义上的开发不要反驳我)。
如果你幸运的能够听到市场人员的谈话,或是领导们的谈话,你会隐约觉得他们都在把技术人员当作编码的机器来看,你的价值并没有你想象的那么重要。而在你所在的团队内部,你可能正在为一个技术问题的讨论再跟同事搞内耗,因为他不服你,你也不服他,你们都认为自己的对,其实你们两个都对,而争论的目的就是为了在关键场合证明一下自己比对方技术好,比对方强。(在一个项目开发中,没有人愿意长期听别人的,总想换个位置领导别人。)
三。你更不要认为,如果我技术够好,我就自己创业,自己有创业的资本,因为自己是搞技术的。
如果你那样认为,真的是大错特错了,你可以做个调查在非技术人群中,没有几个人知道C#与JAVA的,更谈不上来欣赏你的技术是好还是不好。一句话,技术仅仅是一个工具,善于运用这个工具为别人干活的人,却往往不太擅长用这个工具来为自己创业,因为这是两个概念,训练的技能也是完全不同的。
创业最开始的时候,你的人际关系,你处理人际关系的能力,你对社会潜规则的认识,还有你明白不明白别人的心,你会不会说让人喜欢的话,还有你对自己所提供的服务的策划和推销等等,也许有一万,一百万个值得我们重视的问题,但你会发现技术却很少有可能包含在这一万或一百万之内,如果你创业到了一个快成功的阶段,你会这样告诉自己:我干吗要亲自做技术,我聘一个人不就行了,这时候你才真正会理解技术的作用,和你以前做技术人员的作用。
[小结]
基于上面的讨论,我奉劝那些学习技术的朋友,千万不要拿科举考试样的心态去学习技术,对技术的学习几近的痴迷,想掌握所有所有的技术,以让自己成为技术领域的权威和专家,以在必要的时候或是心里不畅快的时候到网上对着菜鸟说自己是前辈。
技术仅仅是一个工具,是你在人生一个阶段生存的工具,你可以一辈子喜欢他,但最好不要一辈子靠它生存。
掌握技术的唯一目的就是拿它找工作(如果你不想把技术当作你第二生命的话),就是干活。所以你在学习的时候千万不要去做那些所谓的技术习题或是研究那些帽泡算法,最大数算法了,什么叫干活?
就是做一个东西让别人用,别人用了,可以提高他们的工作效率,想象吧,你做1万道技术习题有什么用?只会让人觉得酸腐,还是在学习的时候,多培养些自己务实的态度吧,比如研究一下当地市场目前有哪些软件公司用人,自己离他们的要求到底有多远,自己具体应该怎么做才可以达到他们的要求。等你分析完这些,你就会发现,找工作成功,技术的贡献率其实并没有你原来想象的那么高。
不管你是学习技术为了找工作还是创业,你都要对技术本身有个清醒的认识,在中国不会出现BILL GATES,因为,中国目前还不是十分的尊重技术人才,还仅仅的停留在把软件技术人才当作人才机器来用的尴尬境地。(如果你不理解,一种可能是你目前仅仅从事过技术工作,你的朋友圈子里技术类的朋友占了大多数,一种可能是你还没有工作,但喜欢读比尔。盖茨的传记)。
2010年9月16日
#
|
|
|
|
为了提高程序的可读性、可重用性等,逐渐出现了将程序开发中经常用到的相同的功能,比如数学函数运算、字符串操作等,独立出来编写成函数,然后按照相互关系或应用领域汇集在相同的文件里,这些文件构成了函数库。
函数库是一种对信息的封装,将常用的函数封装起来,人们不必知道如何实现它们。只需要了解如何调用它们即可。函数库可以被多个应用程序共享,在具体编程环境中,一般都有一个头文件相伴,在这个头文件中以标准的方式定义了库中每个函数的接口,根据这些接口形式可以在程序中的任何地方调用所需的函数。
由于函数、库、模块等一系列概念和技术的出现,程序设计逐渐变成如图所示的风格。程序被分解成一个个函数模块,其中既有系统函数,也有用户定义的函数。通过对函数的调用,程序的运行逐步被展开。阅读程序时,由于每一块的功能相对独立,因此对程序结构的理解相对容易,在一定程度上缓解了程序代码可读性和可重用件的矛盾,但并未彻底解决矛盾。随着计算机程序的规模越来越大,这个问题变得更加尖锐,于是出现了另一种编程风格——结构化程序设计。
在结构化程序设计中,任何程序段的编写都基于3种结构:分支结构、循环结构和顺序结构。程序具有明显的模块化特征,每个程序模块具有惟一的出口和入口语句。结构化程序的结构简单清晰,模块化强,描述方式贴近人们习惯的推理式思维方式。因此可读性强,在软件重用性、软件维护等方面都有所进步,在大型软件开发尤其是大型科学与工程运算软件的开发中发挥了重要作用。因此到目前为止,仍有许多应用程序的开发采用结构化程序设计技术和方法。即使在目前流行的面向对象软件开发中也不能完全脱离结构化程序设计。
|
|
|
面向对象的程序役计方法是程序设计的一种新方法。所有面向对象的程序设计语言一般都含有三个方面的语法机制,即对象和类、多态性、继承性。
1.对象和类
对象的概念、原理和方法是面向对象的理序设计语言晕重要的特征。对象是用户定义的类型(称为类)的变量。一个对象是既包含数据又包合操作该数据的代码(函数)的逻辑实体。对象中的这些数据和函数称为对象的成员,即成员数据和成员函数。对象中的成员分为公有的和私有的。公有成员是对象与外界的接口界面。外界只能通过调用访问一个对象的公有成员来实现该对象的功能。私有成员体现一个对象的组织形式和功能的实现细节。外界无法对私有成员进行操作。类对象按照规范进行操作,将描述客观事物的数据表达及对数据的操作处理封装在一起,成功地实现了面向对象的程序设计。当用户定义了一个类类型后,就可以在该类型的名下定义变量(即对象)了。类是结构体类型的扩充。结构体中引入成员函数并规定了其访问和继承原则后便成了类。
2.多态性
面向对象的程序设计语言支持“多态性”,把一个接口用于一类活动。即“一个接口多种算法”。具体实施时该选择哪一个算法是由特定的语法机制确定的。C++编译时和运行时都支持多态性。编译时的多态性体现在重载函数和重载运算符等方面。运行时的多态性体现在继承关系及虚函数等方面。
3.继承性
C++程序中,由一个类(称为基类)可以派生出新类(称为派生类)。这种派生的语法机制使得新类的出现轻松自然,使得一个复杂事物可以被顺理成章地归结为由逐层派生的对象描述。“派生”使得程序中定义的类呈层次结构。处于子层的对参既具有其父层对象的共性.又具有自身的特性。继承性是一个类对象获得其基类对象特性的过程。C++中严格地规定了派生类对其基类的继承原则和访问权限,使得程序中对数据和函数的访间,需在家族和朋友间严格区分。
|
|
|
事件驱动的程序设计实际上是面向对象程序设计的一个应用,但它目前仅适用于windows系列操作系统。windows环境中的应用程序与MS-DOS环境中的应用程序运行机制不同、设计程序的方式也不一样。windows程序采用事件驱动机制运行,这种事件驱动程序由事件的发生与否来控制,系统中每个对象状态副改变都是事件发生的原由或结果,设计程序时需以一种非顺序方式处理事件,与顺序的、过程驱动的传统程序设计方法迥异。
事件也称消息,含义比较广泛,常见的事件有鼠标事件(如民标移动、单击、掠过窗口边界)、键盘事件(如按键的压下与拾起)等多种。应用程序运行经过一系列必要的初始化后,将进入等待状态,等待有事件发生,一旦事件出现,程序就被激活并进行相应处理。
事件驱动程序设计是围绕着消息的产生与处理进行的.消息可来自程序中的某个对象,也可由用户、wlndow s或运行着的其他应用程序产生。每当事件发生时,Windows俘获有关事件,然后将消息分别转发到相关应用程序中的有关对象,需要对消息作出反应的对象应该提供消息处理函数,通过这个消息处理函数实现对象的一种功能或行为。所以编写事件驱动程序的大部分工作是为各个对象(类)添加各种消息的处理函数。由于一个对象可以是消息的接收者,同时也可能是消息的发送者,所发送的消息与接收到的消息也可以是相同的消息,而有些消息的发出时间是无法预知的(比如关于键盘的消息),因此应用程序的执行顺序是无法预知的。
|
|
|
逻辑式程序设计的概念来自逻辑式程序设计语言Prolog这一曾经在计算机领域引起震动的日本“第五代”计算机的基本系统语言,在这种“第五代”计算机中,Prolog的地位相当于当前计算机中的机器语言。
Prolog主要应用在人工智能领域,在自然语言处理、数据库查询、算法描述等方面都有应用,尤其适于作为专家系统的开发工具。
Prolog是一种陈述式语言,它不是一种严格的通用程序设计语言,使用Prolog编写程序不需要描述具体的解题过程、只需结出一些必要的事实和规则,这些规则是解决问题方法的规范说明,根据这些规则和事实.计算机利用渭词逻辑,通过演绎推理得到求解问题的执行序列。
|
|
|
一个有实际应用的并行算法,最终总要在并行机上实现,为此首先就要将并行算法转化为并行程序,此过程就是所谓的并行程序设计(Parallel Program)。它要求算法设计者、系统结构师和软件工作者广泛频繁的交互。因为设计并行程序涉及到的知识面较广,主要包括操作系统中的有关知识和优化编译方面的知识。操作系统内容非常丰富,并行程序中最基本的计算要素如任务、进程、线程等基本概念、同步机制和通信操作等。
目前并行程序设计的状况是:⑴并行软件的发展落后于并行硬件;⑵和串行系统与应用软件相比,现今的并行系统与应用软件甚少且不成熟;⑶并行软件的缺乏是发展并行计算的主要障碍;⑷不幸的是,这种状态似乎仍在继续着。究其原因是并行程序设计远比串行程序设计复杂:⑴并行程序设计不但包含了串行程序设计,面且还包含了更多的富有挑战性的问题;⑵串行程序设计仅有一个普遍被接受的冯·诺依曼计算模型,而并行计算模型虽有好多,但没有一个可被共同认可的像冯·诺依曼那样的优秀模型;⑶并行程序设计对环境工具(如编译、查错等)的要求远比串行程序设计先进得多;⑷串行程序设计比较适合于自然习惯,且人们在过去积累了大量的编程知识、经验和宝贵的软件财富。
|
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会 遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内 存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大 小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块 连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因 此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度, 也最灵活
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
简介
本文将讨论如何把代码注入不同的进程地址空间,然后在该进程的上下文中执行注入的代码。 我们在网上可以查到一些窗口/密码侦测的应用例子,网上的这些程序大多都依赖 Windows 钩子技术来实现。本文将讨论除了使用 Windows 钩子技术以外的其它技术来实现这个功能。如图一所示:

图一 WinSpy 密码侦测程序
为了找到解决问题的方法。首先让我们简单回顾一下问题背景。
要“读取”某个控件的内容——无论这个控件是否属于当前的应用程序——通常都是发送 WM_GETTEXT 消息来实现。这个技术也同样应用到编辑控件,但是如果该编辑控件属于另外一个进程并设置了 ES_PASSWORD 式样,那么上面讲的方法就行不通了。用 WM_GETTEXT 来获取控件的内容只适用于进程“拥有”密码控件的情况。所以我们的问题变成了如何在另外一个进程的地址空间执行:
::SendMessage( hPwdEdit, WM_GETTEXT, nMaxChars, psBuffer );
通常有三种可能性来解决这个问题。
- 将你的代码放入某个 DLL,然后通过 Windows 钩子映射该DLL到远程进程;
- 将你的代码放入某个 DLL,然后通过 CreateRemoteThread 和 LoadLibrary 技术映射该DLL到远程进程;
- 如果不写单独的 DLL,可以直接将你的代码拷贝到远程进程——通过 WriteProcessMemory——并用 CreateRemoteThread 启动它的执行。本文将在第三部分详细描述该技术实现细节;
第一部分: Windows 钩子
范例程序——参见HookSpy 和HookInjEx
Windows 钩子主要作用是监控某些线程的消息流。通常我们将钩子分为本地钩子和远程钩子以及系统级钩子,本地钩子一般监控属于本进程的线程的消息流,远程钩子是线程专用的,用于监控属于另外进程的线程消息流。系统级钩子监控运行在当前系统中的所有线程的消息流。
如果钩子作用的线程属于另外的进程,那么你的钩子过程必须驻留在某个动态链接库(DLL)中。然后系统映射包含钩子过程的DLL到钩子作用的线程的地址空间。Windows将映射整个 DLL,而不仅仅是钩子过程。这就是为什么 Windows 钩子能被用于将代码注入到别的进程地址空间的原因。
本文我不打算涉及钩子的具体细节(关于钩子的细节请参见 MSDN 库中的 SetWindowHookEx API),但我在此要给出两个很有用心得,在相关文档中你是找不到这些内容的:
- 在成功调用 SetWindowsHookEx 后,系统自动映射 DLL 到钩子作用的线程地址空间,但不必立即发生映射,因为 Windows 钩子都是消息,DLL 在消息事件发生前并没有产生实际的映射。例如:
如果你安装一个钩子监控某些线程(WH_CALLWNDPROC)的非队列消息,在消息被实际发送到(某些窗口的)钩子作用的线程之前,该DLL 是不会被映射到远程进程的。换句话说,如果 UnhookWindowsHookEx 在某个消息被发送到钩子作用的线程之前被调用,DLL 根本不会被映射到远程进程(即使 SetWindowsHookEx 本身调用成功)。为了强制进行映射,在调用 SetWindowsHookEx 之后马上发送一个事件到相关的线程。
在UnhookWindowsHookEx了之后,对于没有映射的DLL处理方法也一样。只有在足够的事件发生后,DLL才会有真正的映射。
- 当你安装钩子后,它们可能影响整个系统得性能(尤其是系统级钩子),但是你可以很容易解决这个问题,如果你使用线程专用钩子的DLL映射机制,并不截获消息。考虑使用如下代码:
BOOL APIENTRY DllMain( HANDLE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved )
{
if( ul_reason_for_call == DLL_PROCESS_ATTACH )
{
// Increase reference count via LoadLibrary
char lib_name[MAX_PATH];
::GetModuleFileName( hModule, lib_name, MAX_PATH );
::LoadLibrary( lib_name );
// Safely remove hook
::UnhookWindowsHookEx( g_hHook );
}
return TRUE;
}
那么会发生什么呢?首先我们通过Windows 钩子将DLL映射到远程进程。然后,在DLL被实际映射之后,我们解开钩子。通常当第一个消息到达钩子作用线程时,DLL此时也不会被映射。这里的处理技巧是调用LoadLibrary通过增加 DLLs的引用计数来防止映射不成功。
现在剩下的问题是如何卸载DLL,UnhookWindowsHookEx 是不会做这个事情的,因为钩子已经不作用于线程了。你可以像下面这样做:
- 就在你想要解除DLL映射前,安装另一个钩子;
- 发送一个“特殊”消息到远程线程;
- 在钩子过程中截获这个消息,响应该消息时调用 FreeLibrary 和 UnhookWindowsHookEx;
目前只使用了钩子来从处理远程进程中DLL的映射和解除映射。在此“作用于线程的”钩子对性能没有影响。
下面我们将讨论另外一种方法,这个方法与 LoadLibrary 技术的不同之处是DLL的映射机制不会干预目标进程。相对LoadLibrary 技术,这部分描述的方法适用于 WinNT和Win9x。
但是,什么时候使用这个技巧呢?答案是当DLL必须在远程进程中驻留较长时间(即如果你子类化某个属于另外一个进程的控件时)以及你想尽可能少的干涉目标进程时。我在 HookSpy 中没有使用它,因为注入DLL 的时间并不长——注入时间只要足够得到密码即可。我提供了另外一个例子程序——HookInjEx——来示范。HookInjEx 将DLL映射到资源管理器“explorer.exe”,并从中/解除影射,它子类化“开始”按钮,并交换鼠标左右键单击“开始”按钮的功能。
HookSpy 和 HookInjEx 的源代码都可以从本文的下载源代码中获得。
第二部分:CreateRemoteThread 和 LoadLibrary 技术
范例程序——LibSpy
通常,任何进程都可以通过 LoadLibrary API 动态加载DLL。但是,如何强制一个外部进程调用这个函数呢?答案是:CreateRemoteThread。
首先,让我们看一下 LoadLibrary 和FreeLibrary API 的声明:
HINSTANCE LoadLibrary(
LPCTSTR lpLibFileName // 库模块文件名的地址
);
BOOL FreeLibrary(
HMODULE hLibModule // 要加载的库模块的句柄
);
现在将它们与传递到 CreateRemoteThread 的线程例程——ThreadProc 的声明进行比较。
DWORD WINAPI ThreadProc(
LPVOID lpParameter // 线程数据
);
你可以看到,所有函数都使用相同的调用规范并都接受 32位参数,返回值的大小都相同。也就是说,我们可以传递一个指针到LoadLibrary/FreeLibrary 作为到 CreateRemoteThread 的线程例程。但这里有两个问题,请看下面对CreateRemoteThread 的描述:
- CreateRemoteThread 的 lpStartAddress 参数必须表示远程进程中线程例程的开始地址。
- 如果传递到 ThreadFunc 的参数lpParameter——被解释为常规的 32位值(FreeLibrary将它解释为一个 HMODULE),一切OK。但是,如果 lpParameter 被解释为一个指针(LoadLibraryA将它解释为一个串指针)。它必须指向远程进程的某些数据。
第一个问题实际上是由它自己解决的。LoadLibrary 和 FreeLibray 两个函数都在 kernel32.dll 中。因为必须保证kernel32存在并且在每个“常规”进程中的加载地址要相同,LoadLibrary/FreeLibray 的地址在每个进程中的地址要相同,这就保证了有效的指针被传递到远程进程。
第二个问题也很容易解决。只要通过 WriteProcessMemory 将 DLL 模块名(LoadLibrary需要的DLL模块名)拷贝到远程进程即可。
所以,为了使用CreateRemoteThread 和 LoadLibrary 技术,需要按照下列步骤来做:
- 获取远程进程(OpenProcess)的 HANDLE;
- 为远程进程中的 DLL名分配内存(VirtualAllocEx);
- 将 DLL 名,包含全路径名,写入分配的内存(WriteProcessMemory);
- 用 CreateRemoteThread 和 LoadLibrary. 将你的DLL映射到远程进程;
- 等待直到线程终止(WaitForSingleObject),也就是说直到 LoadLibrary 调用返回。另一种方法是,一旦 DllMain(用DLL_PROCESS_ATTACH调用)返回,线程就会终止;
- 获取远程线程的退出代码(GetExitCodeThread)。注意这是一个 LoadLibrary 返回的值,因此是所映射 DLL 的基地址(HMODULE)。
在第二步中释放分配的地址(VirtualFreeEx);
- 用 CreateRemoteThread 和 FreeLibrary从远程进程中卸载 DLL。传递在第六步获取的 HMODULE 句柄到 FreeLibrary(通过 CreateRemoteThread 的lpParameter参数);
- 注意:如果你注入的 DLL 产生任何新的线程,一定要在卸载DLL 之前将它们都终止掉;
- 等待直到线程终止(WaitForSingleObject);
此外,处理完成后不要忘了关闭所有句柄,包括在第四步和第八步创建的两个线程以及在第一步获取的远程线程句柄。现在让我们看一下 LibSpy 的部分代码,为了简单起见,上述步骤的实现细节中的错误处理以及 UNICODE 支持部分被略掉。
HANDLE hThread;
char szLibPath[_MAX_PATH]; // “LibSpy.dll”模块的名称 (包括全路径);
void* pLibRemote; // 远程进程中的地址,szLibPath 将被拷贝到此处;
DWORD hLibModule; // 要加载的模块的基地址(HMODULE)
HMODULE hKernel32 = ::GetModuleHandle("Kernel32");
// 初始化szLibPath
//...
// 1. 在远程进程中为szLibPath 分配内存
// 2. 将szLibPath 写入分配的内存
pLibRemote = ::VirtualAllocEx( hProcess, NULL, sizeof(szLibPath),
MEM_COMMIT, PAGE_READWRITE );
::WriteProcessMemory( hProcess, pLibRemote, (void*)szLibPath,
sizeof(szLibPath), NULL );
// 将"LibSpy.dll" 加载到远程进程(使用CreateRemoteThread 和 LoadLibrary)
hThread = ::CreateRemoteThread( hProcess, NULL, 0,
(LPTHREAD_START_ROUTINE) ::GetProcAddress( hKernel32,
"LoadLibraryA" ),
pLibRemote, 0, NULL );
::WaitForSingleObject( hThread, INFINITE );
// 获取所加载的模块的句柄
::GetExitCodeThread( hThread, &hLibModule );
// 清除
::CloseHandle( hThread );
::VirtualFreeEx( hProcess, pLibRemote, sizeof(szLibPath), MEM_RELEASE );
假设我们实际想要注入的代码——SendMessage ——被放在DllMain (DLL_PROCESS_ATTACH)中,现在它已经被执行。那么现在应该从目标进程中将DLL 卸载:
// 从目标进程中卸载"LibSpy.dll" (使用 CreateRemoteThread 和 FreeLibrary)
hThread = ::CreateRemoteThread( hProcess, NULL, 0,
(LPTHREAD_START_ROUTINE) ::GetProcAddress( hKernel32,
"FreeLibrary" ),
(void*)hLibModule, 0, NULL );
::WaitForSingleObject( hThread, INFINITE );
// 清除
::CloseHandle( hThread );
进程间通信 到目前为止,我们只讨论了关于如何将DLL 注入到远程进程的内容,但是,在大多数情况下,注入的 DLL 都需要与原应用程序进行某种方式的通信(回想一下,我们的DLL是被映射到某个远程进程的地址空间里了,不是在本地应用程序的地址空间中)。比如秘密侦测程序,DLL必须要知道实际包含密码的控件句柄,显然,编译时无法将这个值进行硬编码。同样,一旦DLL获得了秘密,它必须将它发送回原应用程序,以便能正确显示出来。
幸运的是,有许多方法处理这个问题,文件映射,WM_COPYDATA,剪贴板以及很简单的 #pragma data_seg 共享数据段等,本文我不打算使用这些技术,因为MSDN(“进程间通信”部分)以及其它渠道可以找到很多文档参考。不过我在 LibSpy例子中还是使用了 #pragma data_seg。细节请参考 LibSpy 源代码。
第三部分:CreateRemoteThread 和 WriteProcessMemory 技术
范例程序——WinSpy
另外一个将代码拷贝到另一个进程地址空间并在该进程上下文中执行的方法是使用远程线程和 WriteProcessMemory API。这种方法不用编写单独的DLL,而是用 WriteProcessMemory 直接将代码拷贝到远程进程——然后用 CreateRemoteThread 启动它执行。先来看看 CreateRemoteThread 的声明:
HANDLE CreateRemoteThread(
HANDLE hProcess, // 传入创建新线程的进程句柄
LPSECURITY_ATTRIBUTES lpThreadAttributes, // 安全属性指针
DWORD dwStackSize, // 字节为单位的初始线程堆栈
LPTHREAD_START_ROUTINE lpStartAddress, // 指向线程函数的指针
LPVOID lpParameter, // 新线程使用的参数
DWORD dwCreationFlags, // 创建标志
LPDWORD lpThreadId // 指向返回的线程ID
);
如果你比较它与 CreateThread(MSDN)的声明,你会注意到如下的差别:
- 在 CreateRemoteThread中,hProcess是额外的一个参数,一个进程句柄,新线程就是在这个进程中创建的;
- 在 CreateRemoteThread中,lpStartAddress 表示的是在远程进程地址空间中的线程起始地址。线程函数必须要存在于远程进程中,所以我们不能简单地传递一个指针到本地的 ThreadFunc。必须得先拷贝代码到远程进程;
- 同样,lpParameter 指向的数据也必须要存在于远程进程,所以也得将它拷贝到那。
综上所述,我们得按照如下的步骤来做:
- 获取一个远程进程的HANDLE (OpenProces) ;
- 在远程进程地址空间中为注入的数据分配内存(VirtualAllocEx);
- 将初始的 INDATA 数据结构的一个拷贝写入分配的内存中(WriteProcessMemory);
- 在远程进程地址空间中为注入的代码分配内存;
- 将 ThreadFunc 的一个拷贝写入分配的内存;
- 用 CreateRemoteThread启动远程的 ThreadFunc 拷贝;
- 等待远程线程终止(WaitForSingleObject);
- 获取远程来自远程进程的结果(ReadProcessMemory 或 GetExitCodeThread);
- 释放在第二步和第四步中分配的内存(VirtualFreeEx);
- 关闭在第六步和第一步获取的句柄(CloseHandle);
ThreadFunc 必须要遵循的原则:
- 除了kernel32.dll 和user32.dll 中的函数之外,ThreadFunc 不要调用任何其它函数,只有 kernel32.dll 和user32.dll被保证在本地和目标进程中的加载地址相同(注意,user32.dll并不是被映射到每个 Win32 的进程)。如果你需要来自其它库中的函数,将LoadLibrary 和 GetProcAddress 的地址传给注入的代码,然后放手让它自己去做。如果映射到目标进程中的DLL有冲突,你也可以用 GetModuleHandle 来代替 LoadLibrary。
同样,如果你想在 ThreadFunc 中调用自己的子例程,要单独把每个例程的代码拷贝到远程进程并用 INJDATA为 ThreadFunc 提供代码的地址。
- 不要使用静态字符串,而要用 INJDATA 来传递所有字符串。之所以要这样,是因为编译器将静态字符串放在可执行程序的“数据段”中,可是引用(指针)是保留在代码中的。那么,远程进程中ThreadFunc 的拷贝指向的内容在远程进程的地址空间中是不存在的。
- 去掉 /GZ 编译器开关,它在调试版本中是默认设置的。
- 将 ThreadFunc 和 AfterThreadFunc 声明为静态类型,或者不启用增量链接。
- ThreadFunc 中的局部变量一定不能超过一页(也就是 4KB)。
注意在调试版本中4KB的空间有大约10个字节是用于内部变量的。
- 如果你有一个开关语句块大于3个case 语句,将它们像下面这样拆分开:
switch( expression ) {
case constant1: statement1; goto END;
case constant2: statement2; goto END;
case constant3: statement2; goto END;
}
switch( expression ) {
case constant4: statement4; goto END;
case constant5: statement5; goto END;
case constant6: statement6; goto END;
}
END:
或者将它们修改成一个 if-else if 结构语句(参见附录E)。
如果你没有按照这些规则来做,目标进程很可能会崩溃。所以务必牢记。在目标进程中不要假设任何事情都会像在本地进程中那样 (参见附录F)。
GetWindowTextRemote(A/W)
要想从“远程”编辑框获得密码,你需要做的就是将所有功能都封装在GetWindowTextRemot(A/W):中。
int GetWindowTextRemoteA( HANDLE hProcess, HWND hWnd, LPSTR lpString );
int GetWindowTextRemoteW( HANDLE hProcess, HWND hWnd, LPWSTR lpString );
参数说明:
hProcess:编辑框控件所属的进程句柄;
hWnd:包含密码的编辑框控件句柄;
lpString:接收文本的缓冲指针;
返回值:返回值是拷贝的字符数;
下面让我们看看它的部分代码——尤其是注入数据的代码——以便明白 GetWindowTextRemote 的工作原理。此处为简单起见,略掉了 UNICODE 支持部分。
INJDATA
typedef LRESULT (WINAPI *SENDMESSAGE)(HWND,UINT,WPARAM,LPARAM);
typedef struct {
HWND hwnd; // 编辑框句柄
SENDMESSAGE fnSendMessage; // 指向user32.dll 中 SendMessageA 的指针
char psText[128]; // 接收密码的缓冲
} INJDATA;
INJDATA 是一个被注入到远程进程的数据结构。但在注入之前,结构中指向 SendMessageA 的指针是在本地应用程序中初始化的。因为对于每个使用user32.dll的进程来说,user32.dll总是被映射到相同的地址,因此,SendMessageA 的地址也肯定是相同的。这就保证了被传递到远程进程的是一个有效的指针。
ThreadFunc函数
static DWORD WINAPI ThreadFunc (INJDATA *pData)
{
pData->fnSendMessage( pData->hwnd, WM_GETTEXT, // Get password
sizeof(pData->psText),
(LPARAM)pData->psText );
return 0;
}
// 该函数在ThreadFunc之后标记内存地址
// int cbCodeSize = (PBYTE) AfterThreadFunc - (PBYTE) ThreadFunc.
static void AfterThreadFunc (void)
{
}
ThradFunc 是被远程线程执行的代码。
- 注释:注意AfterThreadFunc 是如何计算 ThreadFunc 大小的。通常这样做并不是一个好办法,因为链接器可以随意更改函数的顺序(也就是说ThreadFunc可能被放在 AfterThreadFunc之后)。这一点你可以在小项目中很好地保证函数的顺序是预先设想好的,比如 WinSpy 程序。在必要的情况下,你还可以使用 /ORDER 链接器选项来解决函数链接顺序问题。或者用反汇编确定 ThreadFunc 函数的大小。
如何使用该技术子类化远程控件
范例程序——InjectEx
下面我们将讨论一些更复杂的内容,如何子类化属于另一个进程的控件。
首先,你得拷贝两个函数到远程进程来完成此任务
- ThreadFunc实际上是通过 SetWindowLong子类化远程进程中的控件;
- NewProc是子类化控件的新窗口过程;
这里主要的问题是如何将数据传到远程窗口过程 NewProc,因为 NewProc 是一个回调函数,它必须遵循特定的规范和原则,我们不能简单地在参数中传递 INJDATA指针。幸运的是我找到了有两个方法来解决这个问题,只不过要借助汇编语言,所以不要忽略了汇编,关键时候它是很有用的!
方法一:
如下图所示:

在远程进程中,INJDATA 被放在NewProc 之前,这样 NewProc 在编译时便知道 INJDATA 在远程进程地址空间中的内存位置。更确切地说,它知道相对于其自身位置的 INJDATA 的地址,我们需要所有这些信息。下面是 NewProc 的代码:
static LRESULT CALLBACK NewProc(
HWND hwnd, // 窗口句柄
UINT uMsg, // 消息标示符
WPARAM wParam, // 第一个消息参数
LPARAM lParam ) // 第二个消息参数
{
INJDATA* pData = (INJDATA*) NewProc; // pData 指向 NewProc
pData--; // 现在pData 指向INJDATA;
// 回想一下INJDATA 被置于远程进程NewProc之前;
//-----------------------------
// 此处是子类化代码
// ........
//-----------------------------
// 调用原窗口过程;
// fnOldProc (由SetWindowLong 返回) 被(远程)ThreadFunc初始化
// 并被保存在(远程)INJDATA;中
return pData->fnCallWindowProc( pData->fnOldProc,
hwnd,uMsg,wParam,lParam );
}
但这里还有一个问题,见第一行代码:
INJDATA* pData = (INJDATA*) NewProc;
这种方式 pData得到的是硬编码值(在我们的进程中是原 NewProc 的内存地址)。这不是我们十分想要的。在远程进程中,NewProc “当前”拷贝的内存地址与它被移到的实际位置是无关的,换句话说,我们会需要某种类型的“this 指针”。
虽然用 C/C++ 无法解决这个问题,但借助内联汇编可以解决,下面是对 NewProc的修改:
static LRESULT CALLBACK NewProc(
HWND hwnd, // 窗口句柄
UINT uMsg, // 消息标示符
WPARAM wParam, // 第一个消息参数
LPARAM lParam ) // 第二个消息参数
{
// 计算INJDATA 结构的位置
// 在远程进程中记住这个INJDATA
// 被放在NewProc之前
INJDATA* pData;
_asm {
call dummy
dummy:
pop ecx // <- ECX 包含当前的EIP
sub ecx, 9 // <- ECX 包含NewProc的地址
mov pData, ecx
}
pData--;
//-----------------------------
// 此处是子类化代码
// ........
//-----------------------------
// 调用原来的窗口过程
return pData->fnCallWindowProc( pData->fnOldProc,
hwnd,uMsg,wParam,lParam );
}
那么,接下来该怎么办呢?事实上,每个进程都有一个特殊的寄存器,它指向下一条要执行的指令的内存位置。即所谓的指令指针,在32位 Intel 和 AMD 处理器上被表示为 EIP。因为 EIP是一个专用寄存器,你无法象操作一般常规存储器(如:EAX,EBX等)那样通过编程存取它。也就是说没有操作代码来寻址 EIP,以便直接读取或修改其内容。但是,EIP 仍然还是可以通过间接方法修改的(并且随时可以修改),通过JMP,CALL和RET这些指令实现。下面我们就通过例子来解释通过 CALL/RET 子例程调用机制在32位 Intel 和 AMD 处理器上是如何工作的。
当你调用(通过 CALL)某个子例程时,子例程的地址被加载到 EIP,但即便是在 EIP杯修改之前,其旧的那个值被自动PUSH到堆栈(被用于后面作为指令指针返回)。在子例程执行完时,RET 指令自动将堆栈顶POP到 EIP。
现在你知道了如何通过 CALL 和 RET 实现 EIP 的修改,但如何获取其当前的值呢?下面就来解决这个问题,前面讲过,CALL PUSH EIP 到堆栈,所以,为了获取其当前值,调用“哑函数”,然后再POP堆栈顶。让我们用编译后的 NewProc 来解释这个窍门。
Address OpCode/Params Decoded instruction
--------------------------------------------------
:00401000 55 push ebp ; entry point of
; NewProc
:00401001 8BEC mov ebp, esp
:00401003 51 push ecx
:00401004 E800000000 call 00401009 ; *a* call dummy
:00401009 59 pop ecx ; *b*
:0040100A 83E909 sub ecx, 00000009 ; *c*
:0040100D 894DFC mov [ebp-04], ecx ; mov pData, ECX
:00401010 8B45FC mov eax, [ebp-04]
:00401013 83E814 sub eax, 00000014 ; pData--;
.....
.....
:0040102D 8BE5 mov esp, ebp
:0040102F 5D pop ebp
:00401030 C21000 ret 0010
- 哑函数调用;就是JUMP到下一个指令并PUSH EIP到堆栈;
- 然后将堆栈顶POP到 ECX,ECX再保存EIP;这也是 POP EIP指令的真正地址;
- 注意 NewProc 的入口点和 “POP ECX”之间的“距离”是9 个字节;因此为了计算 NewProc的地址,要从 ECX 减9。
这样一来,不管 NewProc 被移到什么地方,它总能计算出其自己的地址。但是,NewProc 的入口点和 “POP ECX”之间的距离可能会随着你对编译/链接选项的改变而变化,由此造成 RELEASE和DEBUG版本之间也会有差别。但关键是你仍然确切地知道编译时的值。
- 首先,编译函数
- 用反汇编确定正确的距离
- 最后,用正确的距离值重新编译
此即为 InjecEx 中使用的解决方案,类似于 HookInjEx,交换鼠标点击“开始”左右键时的功能。
方法二:
对于我们的问题,在远程进程地址空间中将 INJDATA 放在 NewProc 前面不是唯一的解决办法。看下面 NewProc的变异版本:
static LRESULT CALLBACK NewProc(
HWND hwnd, // 窗口句柄
UINT uMsg, // 消息标示符
WPARAM wParam, // 第一个消息参数
LPARAM lParam ) // 第二个消息参数
{
INJDATA* pData = 0xA0B0C0D0; // 虚构值
//-----------------------------
// 子类化代码
// ........
//-----------------------------
// 调用原来的窗口过程
return pData->fnCallWindowProc( pData->fnOldProc,
hwnd,uMsg,wParam,lParam );
}
此处 0xA0B0C0D0 只是远程进程地址空间中真实(绝对)INJDATA地址的占位符。前面讲过,你无法在编译时知道该地址。但你可以在调用 VirtualAllocEx (为INJDATA)之后得到 INJDATA 在远程进程中的位置。编译我们的 NewProc 后,可以得到如下结果:
Address OpCode/Params Decoded instruction
--------------------------------------------------
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 C745FCD0C0B0A0 mov [ebp-04], A0B0C0D0
:0040100A ...
....
:0040102D 8BE5 mov esp, ebp
:0040102F 5D pop ebp
:00401030 C21000 ret 0010
因此,其编译的代码(十六进制)将是:
558BECC745FCD0C0B0A0......8BE55DC21000.
现在你可以象下面这样继续:
- 将INJDATA,ThreadFunc和NewProc 拷贝到目标进程;
- 修改 NewProc 的代码,以便 pData 中保存的是 INJDATA 的真实地址。
例如,假设 INJDATA 的地址(VirtualAllocEx返回的值)在目标进程中是 0x008a0000。然后象下面这样修改NewProc的代码:
558BECC745FCD0C0B0A0......8BE55DC21000 <- 原来的NewProc (注1)
558BECC745FC00008A00......8BE55DC21000 <- 修改后的NewProc,使用的是INJDATA的实际地址。
也就是说,你用真正的 INJDATA(注2) 地址替代了虚拟值 A0B0C0D0(注2)。
- 开始执行远程的 ThreadFunc,它负责子类化远程进程中的控件。
- 注1、有人可能会问,为什么地址 A0B0C0D0 和 008a0000 在编译时顺序是相反的。因为 Intel 和 AMD 处理器使用 little-endian 符号来表示(多字节)数据。换句话说,某个数字的低位字节被存储在内存的最小地址处,而高位字节被存储在最高位地址。
假设“UNIX”这个词存储用4个字节,在 big-endian 系统中,它被存为“UNIX”,在 little-endian 系统中,它将被存为“XINU”。
- 注2、某些破解(很糟)以类似的方式修改可执行代码,但是一旦加载到内存,一个程序是无法修改自己的代码的(代码驻留在可执行程序的“.text” 区域,这个区域是写保护的)。但仍可以修改远程的 NewProc,因为它是先前以 PAGE_EXECUTE_READWRITE 许可方式被拷贝到某个内存块中的。
何时使用 CreateRemoteThread 和 WriteProcessMemory 技术
与其它方法比较,使用 CreateRemoteThread 和 WriteProcessMemory 技术进行代码注入更灵活,这种方法不需要额外的 dll,不幸的是,该方法更复杂并且风险更大,只要ThreadFunc出现哪怕一丁点错误,很容易就让(并且最大可能地会)使远程进程崩溃(参见附录 F),因为调试远程 ThreadFunc 将是一个可怕的梦魇,只有在注入的指令数很少时,你才应该考虑使用这种技术进行注入,对于大块的代码注入,最好用 I.和II 部分讨论的方法。
WinSpy 以及 InjectEx 请从这里下载源代码。
结束语
到目前为止,有几个问题是我们未提及的,现总结如下:
| 解决方案 |
OS |
进程 |
| I、Hooks |
Win9x 和 WinNT |
仅仅与 USER32.DLL (注3)链接的进程 |
| II、CreateRemoteThread & LoadLibrary |
仅 WinNT(注4) |
所有进程(注5), 包括系统服务(注6) |
III、CreateRemoteThread & WriteProcessMemory
|
仅 WinNT |
所有进程, 包括系统服务 |
- 注3:显然,你无法hook一个没有消息队列的线程,此外,SetWindowsHookEx不能与系统服务一起工作,即使它们与 USER32.DLL 进行链接;
- 注4:Win9x 中没有 CreateRemoteThread,也没有 VirtualAllocEx (实际上,在Win9x 中可以仿真,但不是本文讨论的问题了);
- 注5:所有进程 = 所有 Win32 进程 + csrss.exe
本地应用 (smss.exe, os2ss.exe, autochk.exe 等)不使用 Win32 API,所以也不会与 kernel32.dll 链接。唯一一个例外是 csrss.exe,Win32 子系统本身,它是本地应用程序,但其某些库(~winsrv.dll)需要 Win32 DLLs,包括 kernel32.dll;
- 注6:如果你想要将代码注入到系统服务中(lsass.exe, services.exe, winlogon.exe 等)或csrss.exe,在打开远程句柄(OpenProcess)之前,将你的进程优先级置为 “SeDebugPrivilege”(AdjustTokenPrivileges)。
最后,有几件事情一定要了然于心:你的注入代码很容易摧毁目标进程,尤其是注入代码本身出错的时候,所以要记住:权力带来责任!
因为本文中的许多例子是关于密码的,你也许还读过 Zhefu Zhang 写的另外一篇文章“Super Password Spy++” ,在该文中,他解释了如何获取IE 密码框中的内容,此外,他还示范了如何保护你的密码控件免受类似的攻击。
附录A:
为什么 kernel32.dll 和user32.dll 总是被映射到相同的地址。
我的假定:因为Microsoft 的程序员认为这样做有助于速度优化,为什么呢?我的解释是——通常一个可执行程序是由几个部分组成,其中包括“.reloc” 。当链接器创建 EXE 或者 DLL文件时,它对文件被映射到哪个内存地址做了一个假设。这就是所谓的首选加载/基地址。在映像文件中所有绝对地址都是基于链接器首选的加载地址,如果由于某种原因,映像文件没有被加载到该地址,那么这时“.reloc”就起作用了,它包含映像文件中的所有地址的清单,这个清单中的地址反映了链接器首选加载地址和实际加载地址的差别(无论如何,要注意编译器产生的大多数指令使用某种相对地址寻址,因此,并没有你想象的那么多地址可供重新分配),另一方面,如果加载器能够按照链接器首选地址加载映像文件,那么“.reloc”就被完全忽略掉了。
但kernel32.dll 和user32.dll 及其加载地址为何要以这种方式加载呢?因为每一个 Win32 程序都需要kernel32.dll,并且大多数Win32 程序也需要 user32.dll,那么总是将它们(kernel32.dll 和user32.dll)映射到首选地址可以改进所有可执行程序的加载时间。这样一来,加载器绝不能修改kernel32.dll and user32.dll.中的任何(绝对)地址。我们用下面的例子来说明:
将某个应用程序 App.exe 的映像基地址设置成 KERNEL32的地址(/base:"0x77e80000")或 USER32的首选基地址(/base:"0x77e10000"),如果 App.exe 不是从 USER32 导入方式来使用 USER32,而是通过LoadLibrary 加载,那么编译并运行App.exe 后,会报出错误信息("Illegal System DLL Relocation"——非法系统DLL地址重分配),App.exe 加载失败。
为什么会这样呢?当创建进程时,Win 2000、Win XP 和Win 2003系统的加载器要检查 kernel32.dll 和user32.dll 是否被映射到首选基地址(实际上,它们的名字都被硬编码进了加载器),如果没有被加载到首选基地址,将发出错误。在 WinNT4中,也会检查ole32.dll,在WinNT 3.51 和较低版本的Windows中,由于不会做这样的检查,所以kernel32.dll 和user32.dll可以被加载任何地方。只有ntdll.dll总是被加载到其基地址,加载器不进行检查,一旦ntdll.dll没有在其基地址,进程就无法创建。
总之,对于 WinNT 4 和较高的版本中
- 一定要被加载到基地址的DLLs 有:kernel32.dll、user32.dll 和ntdll.dll;
- 每个Win32 程序都要使用的 DLLs+ csrss.exe:kernel32.dll 和ntdll.dll;
- 每个进程都要使用的DLL只有一个,即使是本地应用:ntdll.dll;
附录B:
/GZ 编译器开关
在生成 Debug 版本时,/GZ 编译器特性是默认打开的。你可以用它来捕获某些错误(具体细节请参考相关文档)。但对我们的可执行程序意味着什么呢?
当打开 /GZ 开关,编译器会添加一些额外的代码到可执行程序中每个函数所在的地方,包括一个函数调用(被加到每个函数的最后)——检查已经被我们的函数修改的 ESP堆栈指针。什么!难道有一个函数调用被添加到 ThreadFunc 吗?那将导致灾难。ThreadFunc 的远程拷贝将调用一个在远程进程中不存在的函数(至少是在相同的地址空间中不存在)
附录C:
静态函数和增量链接
增量链接主要作用是在生成应用程序时缩短链接时间。常规链接和增量链接的可执行程序之间的差别是——增量链接时,每个函数调用经由一个额外的JMP指令,该指令由链接器发出(该规则的一个例外是函数声明为静态)。这些 JMP 指令允许链接器在内存中移动函数,这种移动无需修改引用函数的 CALL指令。但这些JMP指令也确实导致了一些问题:如 ThreadFunc 和 AfterThreadFunc 将指向JMP指令而不是实际的代码。所以当计算ThreadFunc 的大小时:
const int cbCodeSize = ((LPBYTE) AfterThreadFunc - (LPBYTE) ThreadFunc)
你实际上计算的是指向 ThreadFunc 的JMPs 和AfterThreadFunc之间的“距离” (通常它们会紧挨着,不用考虑距离问题)。现在假设 ThreadFunc 的地址位于004014C0 而伴随的 JMP指令位于 00401020。
:00401020 jmp 004014C0
...
:004014C0 push EBP ; ThreadFunc 的实际地址
:004014C1 mov EBP, ESP
...
那么
WriteProcessMemory( .., &ThreadFunc, cbCodeSize, ..);
将拷贝“JMP 004014C0”指令(以及随后cbCodeSize范围内的所有指令)到远程进程——不是实际的 ThreadFunc。远程进程要执行的第一件事情将是“JMP 004014C0” 。它将会在其最后几条指令当中——远程进程和所有进程均如此。但 JMP指令的这个“规则”也有例外。如果某个函数被声明为静态的,它将会被直接调用,即使增量链接也是如此。这就是为什么规则#4要将 ThreadFunc 和 AfterThreadFunc 声明为静态或禁用增量链接的缘故。(有关增量链接的其它信息参见 Matt Pietrek的文章“Remove Fatty Deposits from Your Applications Using Our 32-bit Liposuction Tools” )
附录D:
为什么 ThreadFunc的局部变量只有 4k?
局部变量总是存储在堆栈中,如果某个函数有256个字节的局部变量,当进入该函数时,堆栈指针就减少256个字节(更精确地说,在函数开始处)。例如,下面这个函数:
void Dummy(void) {
BYTE var[256];
var[0] = 0;
var[1] = 1;
var[255] = 255;
}
编译后的汇编如下:
:00401000 push ebp
:00401001 mov ebp, esp
:00401003 sub esp, 00000100 ; change ESP as storage for
; local variables is needed
:00401006 mov byte ptr [esp], 00 ; var[0] = 0;
:0040100A mov byte ptr [esp+01], 01 ; var[1] = 1;
:0040100F mov byte ptr [esp+FF], FF ; var[255] = 255;
:00401017 mov esp, ebp ; restore stack pointer
:00401019 pop ebp
:0040101A ret
注意上述例子中,堆栈指针是如何被修改的?而如果某个函数需要4KB以上局部变量内存空间又会怎么样呢?其实,堆栈指针并不是被直接修改,而是通过另一个函数调用来修改的。就是这个额外的函数调用使得我们的 ThreadFunc “被破坏”了,因为其远程拷贝会调用一个不存在的东西。
我们看看文档中对堆栈探测和 /Gs编译器选项是怎么说的:
——“/GS是一个控制堆栈探测的高级特性,堆栈探测是一系列编译器插入到每个函数调用的代码。当函数被激活时,堆栈探测需要的内存空间来存储相关函数的局部变量。
如果函数需要的空间大于为局部变量分配的堆栈空间,其堆栈探测被激活。默认的大小是一个页面(在80x86处理器上4kb)。这个值允许在Win32 应用程序和Windows NT虚拟内存管理器之间进行谨慎调整以便增加运行时承诺给程序堆栈的内存。”
我确信有人会问:文档中的“……堆栈探测到一块需要的内存空间来存储相关函数的局部变量……”那些编译器选项(它们的描述)在你完全弄明白之前有时真的让人气愤。例如,如果某个函数需要12KB的局部变量存储空间,堆栈内存将进行如下方式的分配(更精确地说是“承诺” )。
sub esp, 0x1000 ; "分配" 第一次 4 Kb
test [esp], eax ; 承诺一个新页内存(如果还没有承诺)
sub esp, 0x1000 ; "分配" 第二次4 Kb
test [esp], eax ; ...
sub esp, 0x1000
test [esp], eax
注意4KB堆栈指针是如何被修改的,更重要的是,每一步之后堆栈底是如何被“触及”(要经过检查)。这样保证在“分配”(承诺)另一页面之前,当前页面承诺的范围也包含堆栈底。
注意事项
“每一个线程到达其自己的堆栈空间,默认情况下,此空间由承诺的以及预留的内存组成,每个线程使用 1 MB预留的内存,以及一页承诺的内存,系统将根据需要从预留的堆栈内存中承诺一页内存区域” (参见 MSDN CreateThread > dwStackSize > Thread Stack Size)
还应该清楚为什么有关 /GS 的文档说在堆栈探针在 Win32 应用程序和Windows NT虚拟内存管理器之间进行谨慎调整。
现在回到我们的ThreadFunc以及 4KB 限制
虽然你可以用 /Gs 防止调用堆栈探测例程,但在文档对于这样的做法给出了警告,此外,文件描述可以用 #pragma check_stack 指令关闭或打开堆栈探测。但是这个指令好像一点作用都没有(要么这个文档是垃圾,要么我疏忽了其它一些信息?)。总之,CreateRemoteThread 和 WriteProcessMemory 技术只能用于注入小块代码,所以你的局部变量应该尽量少耗费一些内存字节,最好不要超过 4KB限制。
附录E:
为什么要将开关语句拆分成三个以上?
用下面这个例子很容易解释这个问题,假设有如下这么一个函数:
int Dummy( int arg1 )
{
int ret =0;
switch( arg1 ) {
case 1: ret = 1; break;
case 2: ret = 2; break;
case 3: ret = 3; break;
case 4: ret = 0xA0B0; break;
}
return ret;
}
编译后变成下面这个样子:
地址 操作码/参数 解释后的指令
--------------------------------------------------
; arg1 -> ECX
:00401000 8B4C2404 mov ecx, dword ptr [esp+04]
:00401004 33C0 xor eax, eax ; EAX = 0
:00401006 49 dec ecx ; ECX --
:00401007 83F903 cmp ecx, 00000003
:0040100A 771E ja 0040102A
; JMP 到表***中的地址之一
; 注意 ECX 包含的偏移
:0040100C FF248D2C104000 jmp dword ptr [4*ecx+0040102C]
:00401013 B801000000 mov eax, 00000001 ; case 1: eax = 1;
:00401018 C3 ret
:00401019 B802000000 mov eax, 00000002 ; case 2: eax = 2;
:0040101E C3 ret
:0040101F B803000000 mov eax, 00000003 ; case 3: eax = 3;
:00401024 C3 ret
:00401025 B8B0A00000 mov eax, 0000A0B0 ; case 4: eax = 0xA0B0;
:0040102A C3 ret
:0040102B 90 nop
; 地址表***
:0040102C 13104000 DWORD 00401013 ; jump to case 1
:00401030 19104000 DWORD 00401019 ; jump to case 2
:00401034 1F104000 DWORD 0040101F ; jump to case 3
:00401038 25104000 DWORD 00401025 ; jump to case 4
注意如何实现这个开关语句?
与其单独检查每个CASE语句,不如创建一个地址表,然后通过简单地计算地址表的偏移量而跳转到正确的CASE语句。这实际上是一种改进。假设你有50个CASE语句。如果不使用上述的技巧,你得执行50次 CMP和JMP指令来达到最后一个CASE。相反,有了地址表后,你可以通过表查询跳转到任何CASE语句,从计算机算法角度和时间复杂度看,我们用O(5)代替了O(2n)算法。其中:
- O表示最坏的时间复杂度;
- 我们假设需要5条指令来进行表查询计算偏移量,最终跳到相应的地址;
现在,你也许认为出现上述情况只是因为CASE常量被有意选择为连续的(1,2,3,4)。幸运的是,它的这个方案可以应用于大多数现实例子中,只有偏移量的计算稍微有些复杂。但有两个例外:
- 如果CASE语句少于等于三个;
- 如果CASE 常量完全互不相关(如:“"case 1” ,“case 13” ,“case 50” , 和“case 1000” );
显然,单独判断每个的CASE常量的话,结果代码繁琐耗时,但使用CMP和JMP指令则使得结果代码的执行就像普通的if-else 语句。
有趣的地方:如果你不明白CASE语句使用常量表达式的理由,那么现在应该弄明白了吧。为了创建地址表,显然在编译时就应该知道相关地址。
现在回到问题!
注意到地址 0040100C 处的JMP指令了吗?我们来看看Intel关于十六进制操作码 FF 的文档是怎么说的:
操作码 指令 描述
FF /4 JMP r/m32 Jump near, absolute indirect,
address given in r/m32
原来JMP 使用了一种绝对寻址方式,也就是说,它的操作数(CASE语句中的 0040102C)表示一个绝对地址。还用我说什么吗?远程 ThreadFunc 会盲目地认为地址表中开关地址是 0040102C,JMP到一个错误的地方,造成远程进程崩溃。
附录F:
为什么远程进程会崩溃呢?
当远程进程崩溃时,它总是会因为下面这些原因:
- 在ThreadFunc 中引用了一个不存在的串;
- 在在ThreadFunc 中 中一个或多个指令使用绝对寻址(参见附录E);
- ThreadFunc 调用某个不存在的函数(该调用可能是编译器或链接器添加的)。你在反汇编器中可以看到这样的情形:
:004014C0 push EBP ; ThreadFunc 的入口点
:004014C1 mov EBP, ESP
...
:004014C5 call 0041550 ; 这里将使远程进程崩溃
...
:00401502 ret
如果 CALL 是由编译器添加的指令(因为某些“禁忌” 开关如/GZ是打开的),它将被定位在 ThreadFunc 的开始的某个地方或者结尾处。
不管哪种情况,你都要小心翼翼地使用 CreateRemoteThread 和 WriteProcessMemory 技术。尤其要注意你的编译器/链接器选项,一不小心它们就会在 ThreadFunc 添加内容。
CreateRemoteThread提供了一个在远程进程中执行代码的方法,就像代码长出翅膀飞到别处运行。本文将做一个入门介绍,希望对广大编程爱好者有所帮助。
先解释一下远程进程,其实就是要植入你的代码的进程,相对于你的工作进程(如果叫本地进程的话)它就叫远程进程,可理解为宿主。
首先介绍一下我们的主要工具CreateRemoteThread,这里先将函数原型简单介绍以下。
CreateRemoteThread可将线程创建在远程进程中。
函数原型
HANDLE CreateRemoteThread(
HANDLE hProcess, // handle to process
LPSECURITY_ATTRIBUTES lpThreadAttributes, // SD
SIZE_T dwStackSize, // initial stack size
LPTHREAD_START_ROUTINE lpStartAddress, // thread function
LPVOID lpParameter, // thread argument
DWORD dwCreationFlags, // creation option
LPDWORD lpThreadId // thread identifier
);
参数说明:
hProcess
[输入] 进程句柄
lpThreadAttributes
[输入] 线程安全描述字,指向SECURITY_ATTRIBUTES结构的指针
dwStackSize
[输入] 线程栈大小,以字节表示
lpStartAddress
[输入] 一个LPTHREAD_START_ROUTINE类型的指针,指向在远程进程中执行的函数地址
lpParameter
[输入] 传入参数
dwCreationFlags
[输入] 创建线程的其它标志
lpThreadId
[输出] 线程身份标志,如果为NULL,则不返回
返回值
成功返回新线程句柄,失败返回NULL,并且可调用GetLastError获得错误值。
接下来我们将以两种方式使用CreateRemoteThread,大家可以领略到CreateRemoteThread的神通,它使你的代码可以脱离你的进程,植入到别的进程中运行。
第一种方式
第一种方式,我们使用函数的形式。即我们将自己程序中的一个函数植入到远程进程中。
步骤1:首先在你的进程中创建函数MyFunc,我们将把它放在另一个进程中运行,这里以windows
计算器为目标进程。
static DWORD WINAPI MyFunc (LPVOID pData)
{
//do something
//...
//pData输入项可以是任何类型值
//这里我们会传入一个DWORD的值做示例,并且简单返回
return *(DWORD*)pData;
}
static void AfterMyFunc (void) {
}
这里有个小技巧,定义了一个static void AfterMyFunc (void);为了下面确定我们的代码大小
步骤2:定位目标进程,这里是一个计算器
HWND hStart = ::FindWindow (TEXT("SciCalc"),NULL);
步骤3:获得目标进程句柄,这里用到两个不太常用的函数(当然如果经常做线程/进程等方面的 项目的话,就很面熟了),但及有用
DWORD PID, TID;
TID = ::GetWindowThreadProcessId (hStart, &PID);
HANDLE hProcess;
hProcess = OpenProcess(PROCESS_ALL_ACCESS,false,PID);
步骤4:在目标进程中配变量地址空间,这里我们分配10个字节,并且设定为可以读
写PAGE_READWRITE,当然也可设为只读等其它标志,这里就不一一说明了。
char szBuffer[10];
*(DWORD*)szBuffer=1000;//for test
void *pDataRemote =(char*) VirtualAllocEx( hProcess, 0, sizeof(szBuffer), MEM_COMMIT,
PAGE_READWRITE );
步骤5:写内容到目标进程中分配的变量空间
::WriteProcessMemory( hProcess, pDataRemote, szBuffer,(sizeof(szBuffer),NULL);
步骤6:在目标进程中分配代码地址空间
计算代码大小
DWORD cbCodeSize=((LPBYTE) AfterMyFunc - (LPBYTE) MyFunc);
分配代码地址空间
PDWORD pCodeRemote = (PDWORD) VirtualAllocEx( hProcess, 0, cbCodeSize, MEM_COMMIT,
PAGE_EXECUTE_READWRITE );
步骤7:写内容到目标进程中分配的代码地址空间
WriteProcessMemory( hProcess, pCodeRemote, &MyFunc, cbCodeSize, NULL);
步骤8:在目标进程中执行代码
HANDLE hThread = CreateRemoteThread(hProcess, NULL, 0,
(LPTHREAD_START_ROUTINE) pCodeRemote,
pDataRemote, 0 , NULL);
DWORD h;
if (hThread)
{
::WaitForSingleObject( hThread, INFINITE );
::GetExitCodeThread( hThread, &h );
TRACE("run and return %d\n",h);
::CloseHandle( hThread );
}
这里有几个值得说明的地方:
使用WaitForSingleObject等待线程结束;
使用GetExitCodeThread获得返回值;
最后关闭句柄CloseHandle。
步骤9:清理现场
释放空间
::VirtualFreeEx( hProcess, pCodeRemote,
cbCodeSize,MEM_RELEASE );
::VirtualFreeEx( hProcess, pDataRemote,
cbParamSize,MEM_RELEASE );
关闭进程句柄
::CloseHandle( hProcess );
第二种方式
第二种方式,我们使用动态库的形式。即我们将自己一个动态库植入到远程进程中。
这里不再重复上面相同的步骤,只写出其中关键的地方.
关键1:
在步骤5中将动态库的路径作为变量传入变量空间.
关键2:
在步骤8中,将GetProcAddress作为目标执行函数.
hThread = ::CreateRemoteThread( hProcess, NULL, 0,
(LPTHREAD_START_ROUTINE )::GetProcAddress(
hModule, "LoadLibraryA"),
pDataRemote, 0, NULL );
另外在步骤9,清理现场中首先要先进行释放我们的动态库.也即类似步骤8执行函数FreeLibrary
hThread = ::CreateRemoteThread( hProcess, NULL, 0,
(LPTHREAD_START_ROUTINE )::GetProcAddress(
hModule, "FreeLibrary"),
(void*)hLibModule, 0, NULL );
好了,限于篇幅不能够介绍的很细,在使用过程中如有疑问可向作者咨询.(开发环境:windows2000/vc6.0)
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/fangchao918628/archive/2008/08/30/2852744.aspx
#pragma data_seg("flag_data")
int count=0;
#pragma data_seg()
#pragma comment(linker,"/SECTION:flag_data,RWS")
这种方法只能在没有def文件时使用,如果通过def文件进行导出的话,那么设置就要在def文件内设置而不能
在代码里设置了。
SETCTIONS
flag_data READ WRITE SHARED
在主文件中,用#pragma data_seg建立一
个新的数据段并定义共享数据,其具体格式为:
#pragma data_seg ("shareddata") //名称可以
//自己定义,但必须与下面的一致。
HWND sharedwnd=NULL;//共享数据
#pragma data_seg()
仅定义一个数据段还不能达到共享数据的目的,还要告诉编译器该段的属性,有两种方法可以实现该目的 (其效果是相同的),一种方法是在.DEF文件中加入如下语句: SETCTIONS shareddata READ WRITE SHARED 另一种方法是在项目设置链接选项(Project Setting --〉Link)中加入如下语句: /SECTION:shareddata,rws
第一点:什么是共享数据段?为什么要用共享数据段??它有什么用途??
在Win16环境中,DLL的全局数据对每个载入它的进程来说都是相同的;而在Win32环境中,情况却发生了变化,DLL函数中的代码所创建的任何对象(包括变量)都归调用它的线程或进程所有。当进程在载入DLL时,操作系统自动把DLL地址映射到该进程的私有空间,也就是进程的虚拟地址空间,而且也复制该DLL的全局数据的一份拷贝到该进程空间。也就是说每个进程所拥有的相同的DLL的全局数据,它们的名称相同,但其值却并不一定是相同的,而且是互不干涉的。
因此,在Win32环境下要想在多个进程中共享数据,就必须进行必要的设置。在访问同一个Dll的各进程之间共享存储器是通过存储器映射文件技术实现的。也可以把这些需要共享的数据分离出来,放置在一个独立的数据段里,并把该段的属性设置为共享。必须给这些变量赋初值,否则编译器会把没有赋初始值的变量放在一个叫未被初始化的数据段中。
#pragma data_seg预处理指令用于设置共享数据段。例如:
#pragma data_seg("SharedDataName") HHOOK hHook=NULL; //必须在定义的同时进行初始化!!!!#pragma data_seg()
在#pragma data_seg("SharedDataName")和#pragma data_seg()之间的所有变量将被访问该Dll的所有进程看到和共享。再加上一条指令#pragma comment(linker,"/section:.SharedDataName,rws"),[注意:数据节的名称is case sensitive]那么这个数据节中的数据可以在所有DLL的实例之间共享。所有对这些数据的操作都针对同一个实例的,而不是在每个进程的地址空间中都有一份。
当进程隐式或显式调用一个动态库里的函数时,系统都要把这个动态库映射到这个进程的虚拟地址空间里(以下简称"地址空间")。这使得DLL成为进程的一部分,以这个进程的身份执行,使用这个进程的堆栈。(这项技术又叫code Injection技术,被广泛地应用在了病毒、黑客领域!呵呵^_^)
第二点:在具体使用共享数据段时需要注意的一些问题!
Win32 DLLs are mapped into the address space of the calling process. By default, each process using a DLL has its own instance of all the DLLs global and static variables. (注意: 即使是全局变量和静态变量也都不是共享的!) If your DLL needs to share data with other instances of it loaded by other applications, you can use either of the following approaches:
· Create named data sections using the data_seg pragma.
· Use memory mapped files. See the Win32 documentation about memory mapped files.
Here is an example of using the data_seg pragma:
#pragma data_seg (".myseg")
int i = 0;
char a[32] = "hello world";
#pragma data_seg()
data_seg can be used to create a new named section (.myseg in this example). The most typical usage is to call the data segment .shared for clarity. You then must specify the correct sharing attributes for this new named data section in your .def file or with the linker option /SECTION:.MYSEC,RWS. (这个编译参数既可以使用pragma指令来指定,也可以在VC的IDE中指定!)
There are restrictions to consider before using a shared data segment:
· Any variables in a shared data segment must be statically initialized. In the above example, i is initialized to 0 and a is 32 characters initialized to hello world.
· All shared variables are placed in the compiled DLL in the specified data segment. Very large arrays can result in very large DLLs. This is true of all initialized global variables.
· Never store process-specific information in a shared data segment. Most Win32 data structures or values (such as HANDLEs) are really valid only within the context of a single process.
· Each process gets its own address space. It is very important that pointers are never stored in a variable contained in a shared data segment. A pointer might be perfectly valid in one application but not in another.
· It is possible that the DLL itself could get loaded at a different address in the virtual address spaces of each process. It is not safe to have pointers to functions in the DLL or to other shared variables.
在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C ++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。
其格式一般为: #Pragma Para
其中Para 为参数,下面来看一些常用的参数。
(1)message 参数。
Message 参数是我最喜欢的一个参数,它能够在编译信息输出窗口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为:
#Pragma message(“消息文本”)
当编译器遇到这条指令时就在编译输出窗口中将消息文本打印出来。
当我们在程序中定义了许多宏来控制源代码版本的时候,我们自己有可能都会忘记有没有正确的设置这些宏,此时我们可以用这条指令在编译的时候就进行检查。
假设我们希望判断自己有没有在源代码的什么地方定义了_X86这个宏可以用下面的方法
#ifdef _X86
#Pragma message(“_X86 macro activated!”)
#endif
当我们定义了_X86这个宏以后,应用程序在编译时就会在编译输出窗口里显示“_
X86 macro activated!”。我们就不会因为不记得自己定义的一些特定的宏而抓耳挠腮了。
(2)另一个使用得比较多的pragma参数是code_seg。
格式如:
#pragma code_seg( ["section-name"[,"section-class"] ] )
它能够设置程序中函数代码存放的代码段,当我们开发驱动程序的时候就会使用到它。
(3)#pragma once (比较常用)
只要在头文件的最开始加入这条指令就能够保证头文件被编译一次,这条指令实际上在VC6中就已经有了,但是考虑到兼容性并没有太多的使用它。
(4)#pragma hdrstop
表示预编译头文件到此为止,后面的头文件不进行预编译。BCB可以预编译头文件以加快链接的速度,但如果所有头文件都进行预编译又可能占太多磁盘空间,所以使用这个选项排除一些头文件。
有时单元之间有依赖关系,比如单元A依赖单元B,所以单元B要先于单元A编译。你可以用#pragma startup指定编译优先级,如果使用了#pragma package(smart_init) ,BCB就会根据优先级的大小先后编译。
(5)#pragma resource
#pragma resource "*.dfm"表示把*.dfm文件中的资源加入工程。*.dfm中包括窗体外观的定义。
(6)#pragma warning
#pragma warning( disable : 4507 34; once : 4385; error : 164 )
等价于:
#pragma warning(disable:4507 34) // 不显示4507和34号警告信息
#pragma warning(once:4385) // 4385号警告信息仅报告一次
#pragma warning(error:164) // 把164号警告信息作为一个错误。
同时这个pragma warning 也支持如下格式:
#pragma warning( push [ ,n ] )
#pragma warning( pop )
这里n代表一个警告等级(1---4)。
#pragma warning( push )保存所有警告信息的现有的警告状态。
#pragma warning( push, n)保存所有警告信息的现有的警告状态,并且把全局警告等级设定为n。
#pragma warning( pop )向栈中弹出最后一个警告信息,在入栈和出栈之间所作的一切改动取消。例如:
#pragma warning( push )
#pragma warning( disable : 4705 )
#pragma warning( disable : 4706 )
#pragma warning( disable : 4707 )
//.......
#pragma warning( pop )
在这段代码的最后,重新保存所有的警告信息(包括4705,4706和4707)。
(7)pragma comment(...)
该指令将一个注释记录放入一个对象文件或可执行文件中。
常用的lib关键字,可以帮我们连入一个库文件。
(8)progma data_seg
有的时候我们可能想让一个应用程序只启动一次,就像单件模式(singleton)一样,实现的方法可能有多种,这里说说用#pragma data_seg来实现的方法,很是简洁便利。
应用程序的入口文件前面加上
#pragma data_seg("flag_data")
int app_count = 0;
#pragma data_seg()
#pragma comment(linker,"/SECTION:flag_data,RWS")
然后程序启动的地方加上
if(app_count>0) // 如果计数大于0,则退出应用程序。
{
//MessageBox(NULL, "已经启动一个应用程序", "Warning", MB_OK);
//printf("no%d application", app_count);
return FALSE;
}
app_count++;
Windows 在一个Win32程序的地址空间周围筑了一道墙。通常,一个程序的地址空间中的数据是私有的,对别的程序而言是不可见的。但是执行STRPROG的多个执行实体表示了STRLIB在程序的所有执行实体之间共享数据是毫无问题的。当您在一个STRPROG窗口中增加或者删除一个字符串时,这种改变将立即反映在其它的窗口中。
在全部例程之间,STRLIB共享两个变量:一个字符数组和一个整数(记录已储存的有效字符串的个数)。STRLIB将这两个变量储存在共享的一个特殊内存区段中:
#pragma data_seg ("shared")
int iTotal = 0 ;
WCHAR szStrings [MAX_STRINGS][MAX_LENGTH + 1] = { '\0' } ;
#pragma data_seg ()
第一个#pragma叙述建立数据段,这里命名为shared。您可以将这段命名为任何一个您喜欢的名字。在这里的#pragma叙述之后的所有初始化了的变量都放在shared数据段中。第二个#pragma叙述标示段的结束。对变量进行专门的初始化是很重要的,否则编译器将把它们放在普通的未初始化数据段中而不是放在shared中。
连结器必须知道有一个「shared」共享数据段。在「Project Settings」对话框选择「Link」页面卷标。选中「STRLIB」时在「Project Options」字段(在Release和Debug设定中均可),包含下面的连结叙述:
字母RWS表示段具有读、写和共享属性。或者,您也可以直接用DLL原始码指定连结选项,就像我们在STRLIB.C那样:
#pragma comment(linker,"/SECTION:shared,RWS")
共享的内存段允许iTotal变量和szStrings字符串数组在STRLIB的所有例程之间共享。因为MAX_STRINGS等于256,而 MAX_LENGTH等于63,所以,共享内存段的长度为32,772字节-iTotal变量需要4字节,256个指针中的每一个都需要128字节。
2010年8月10日
#
RTTI、虚函数和虚基类的实现方式、开销分析及使用指导
白杨
http://baiy.cn
“在正确的场合使用恰当的特性” 对称职的C++程序员来说是一个基本标准。想要做到这点,首先要了解语言中每个特性的实现方式及其开销。本文主要讨论相对于传统 C 而言,对效率有影响的几个C++新特性。
相对于传统的 C 语言,C++ 引入的额外开销体现在以下两个方面:
编译时开销

| 模板、类层次结构、强类型检查等新特性,以及大量使用了这些新特性的 STL 标准库都增加了编译器负担。但是应当看到,这些新机能在不降低,甚至(由于模板的内联能力)提升了程序执行效率的前提下,明显减轻了广大 C++ 程序员的工作量。
用几秒钟的CPU时间换取几人日的辛勤劳动,附带节省了日后调试和维护代码的时间,这点开销当算超值。
当然,在使用这些特性的时候,也有不少优化技巧。比如:编译一个 广泛依赖模板库的大型软件时,几条显式实例化指令就可能使编译速度提高几十倍;恰当地组合使用部分专门化和完全专门化,不但可以最优化程序的执行效率,还可以让同时使用多种不同参数实例化一套模板的程序体积显著减小……
|
运行时开销
运行时开销恐怕是程序员最关心的问题之一了。相对与传统C程序而言,C++中有可能引入额外运行时开销的新特性包括:
- 虚基类
- 虚函数
- RTTI(dynamic_cast和typeid)
- 异常
- 对象的构造和析构
关于其中第四点:异常,对于大多数现代编译器来说,在正常情况(未抛出异常)下,try块中的代码执行效率和普通代码一样高,而且由于不再需要使用传统上通过返回值或函数调用来判断错误的方式,代码的实际执行效率还可能进一步提高。抛出和捕捉异常的效率也只是在某些情况下才会稍低于函数正常返回的效率,何况对于一个编写良好的程序,抛出和捕捉异常的机会应该不多。关于异常使用的详细讨论,参见:C++编码规范正文中的相关部分和C++异常机制的实现方式和开销分析一节。
而第五点,对象的构造和析构开销也不总是存在。对于不需要初始化/销毁的类型,并没有构造和析构的开销,相反对于那些需要初始化/销毁的类型来说,即使用传统的C方式实现,也至少需要与之相当的开销。这里要注意的一点是尽量不要让构造和析构函数过于臃肿,特别是在一个类层次结构中更要注意。时刻保持你的构造、析构函数中只有最必要的初始化和销毁操作,把那些并不是每个(子)对象都需要执行的操作留给其他方法和派生类去解决。
其实对一个优秀的编译器而言,C++的各种特性本身就是使用C/汇编加以千锤百炼而最优化实现的。可以说,想用C甚至汇编比编译器更高效地实现某个C++特性几乎是不可能的。要是真能做到这一点的话,大侠就应该去写个编译器造福广大程序员才对~
C++之所以 被广泛认为比C“低效”,其根本原因在于:由于程序员对某些特性的实现方式及其产生的开销不够了解,致使他们在错误的场合使用了错误的特性。而这些错误基本都集中在:
- 把异常当作另一种流控机制,而不是仅将其用于错误处理中
- 一个类和/或其基类的构造、析构函数过于臃肿,包含了很多非初始化/销毁范畴的代码
- 滥用或不正确地使用RTTI、虚函数和虚基类机制
其中前两点上文已经讲过,下面讨论第三点。
为了说明RTTI、虚函数和虚基类的实现方式,这里首先给出一个经典的菱形继承实例,及其具体实现(为了便于理解,这里故意忽略了一些无关紧要的优化):
|
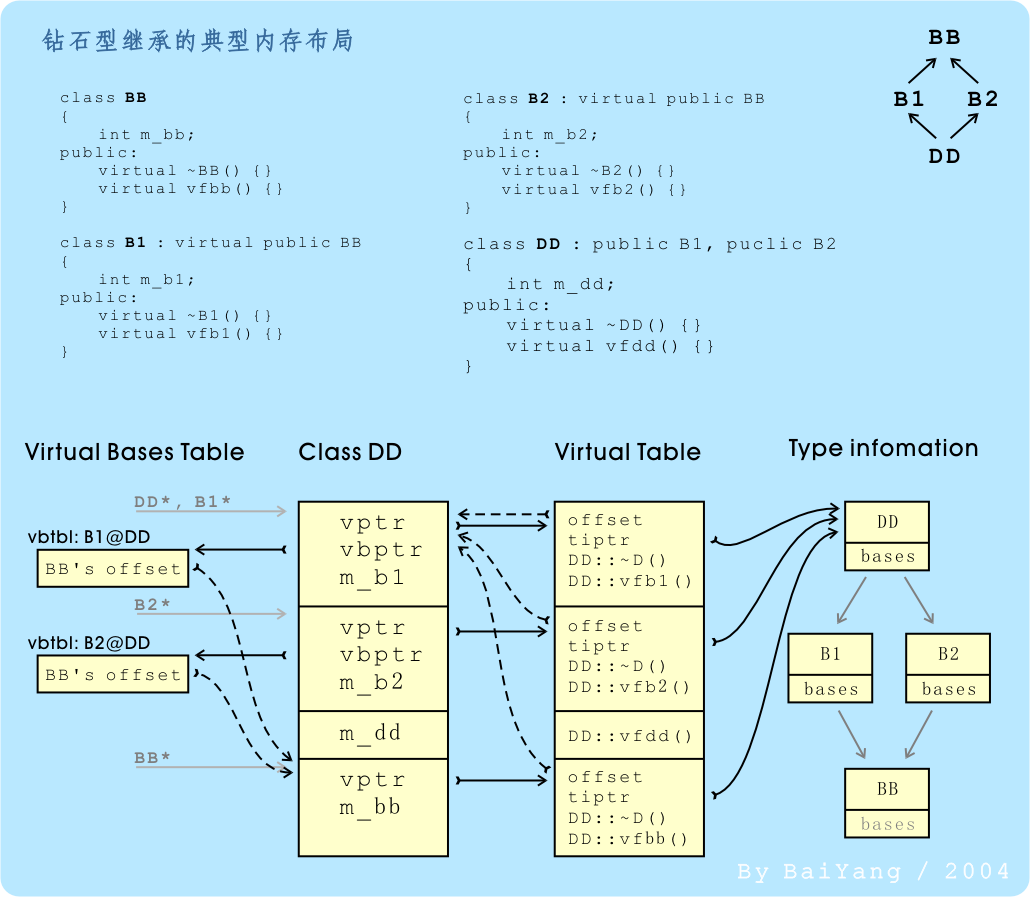
图中虚箭头代表偏移,实箭头代表指针
由上图得到每种特性的运行时开销如下:
| 特性 |
时间开销 |
空间开销 |
| RTTI |
几次整形比较和一次取址操作(可能还会有1、2次整形加法) |
每类型一个type_info对象(包括类型ID和类名称),典型情况下小于32字节
|
| 虚函数 |
一次整形加法和一次指针间接引用 |
每类型一个虚表,典型情况下小于128字节
每对象若干个(大部分情况下是一个)虚表指针,典型情况下小于8字节
|
| 虚基类 |
从虚继承的子类中访问虚基类的数据成员或其虚函数时,将增加两次指针间接引用和一次整形加法(部分情况下可以优化为一次指针间接引用)。 |
每类型一个虚基类表,典型情况下小于32字节
每对象若干虚基类表指针,典型情况下小于8字节
在同时使用了虚函数的时候,虚基类表可以合并到虚表(virtual table)中,每对象的虚基类表指针(vbptr)也可以省略(只需vptr即可)。实际上, 很多实现都是这么做的。
|
| * 其中“每类型”或“每对象”是指用到该特性的类型/对象。对于未用到这些功能的类型及其对象,则不会增加上述开销 |
可见,关于老天“饿时掉馅饼、睡时掉老婆”等美好传说纯属谣言。但凡人工制品必不完美,总有设计上的取舍,有其适应的场合也有其不适用的地方。
C++中的每个特性,都是从程序员平时的生产生活中逐渐精化而来的。在不正确的场合使用它们必然会引起逻辑、行为和性能上的问题。对于上述特性,应该只在必要、合理的前提下才使用。
"dynamic_cast" 用于在类层次结构中漫游,对指针或引用进行自由的向上、向下或交叉强制。"typeid" 则用于获取一个对象或引用的确切类型,与 "dynamic_cast" 不同,将 "typeid" 作用于指针通常是一个错误,要得到一个指针指向之对象的type_info,应当先将其解引用(例如:"typeid(*p);")。
一般地讲,能用虚函数解决的问题就不要用 "dynamic_cast",能够用 "dynamic_cast" 解决的就不要用 "typeid"。比如:

void
rotate(IN const CShape& iS)
{
if (typeid(iS) == typeid(CCircle))
{
// ...
}
else if (typeid(iS) == typeid(CTriangle))
{
// ...
}
else if (typeid(iS) == typeid(CSqucre))
{
// ...
}
// ...
} |
以上代码用 "dynamic_cast" 写会稍好一点,当然最好的方式还是在CShape里定义名为 "rotate" 的虚函数。
虚函数是C++众多运行时多态特性中开销最小,也最常用的机制。虚函数的好处和作用这里不再多说,应当注意在对性能有苛刻要求的场合,或者需要频繁调用,对性能影响较大的地方(比如每秒钟要调用成千上万次,而自身内容又很简单的事件处理函数)要慎用虚函数。
需要特别说明的一点是:虚函数的调用开销与通过函数指针的间接函数调用(例如:经典C程序中常见的,通过指向结构中的一个函数指针成员调用;以及调用DLL/SO中的函数等常见情况)是相当的。比起函数调用本身的开销(保存现场->传递参数->传递返回值->恢复现场)来说,一次指针间接引用是微不足道的。这就使得在绝大部分可以使用函数的场合中都能够负担得起虚方法的些微额外开销。
作为一种支持多继承的面向对象语言,虚基类有时是保证类层次结构正确一致的一种必不可少的手段。但在需要频繁使用基类提供的服务,又对性能要求较高的场合,应该尽量避免使用它。在基类中没有数据成员的场合,也可以解除使用虚基类。例如,在上图中,如果类 "BB" 中不存在数据成员,那么 "BB" 就可以作为一个普通基类分别被 "B1" 和 "B2" 继承。这样的优化在达到相同效果的前提下,解除了虚基类引起的开销。不过这种优化也会带来一些问题:从 "DD" 向上强制到 "BB" 时会引起歧义,破坏了类层次结构的逻辑关系。
上述特性的空间开销一般都是可以接受的,当然也存在一些特例,比如:在存储布局需要和传统C结构兼容的场合、在考虑对齐的场合、在需要为一个本来尺寸很小的类同时实例化许多对象的场合等等。
|
2009年11月21日
#
Debug版本包括调试信息,所以要比Release版本大很多(可能大数百K至数M)。至于是否需要DLL支持,主要看你采用的编译选项。如果是基于ATL的,则Debug和Release版本对DLL的要求差不多。如果采用的编译选项为使用MFC动态库,则需要MFC42D.DLL等库支持,而Release版本需要MFC42.DLL支持。Release Build不对源代码进行调试,不考虑MFC的诊断宏,使用的是MFC Release库,编译十对应用程序的速度进行优化,而Debug Build则正好相反,它允许对源代码进行调试,可以定义和使用MFC的诊断宏,采用MFC Debug库,对速度没有优化。
一、Debug 和 Release 编译方式的本质区别
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
Debug 和 Release 的真正秘密,在于一组编译选项。下面列出了分别针对二者的选项(当然除此之外还有其他一些,如/Fd /Fo,但区别并不重要,通常他们也不会引起 Release 版错误,在此不讨论)
Debug 版本:
/MDd /MLd 或 /MTd 使用 Debug runtime library(调试版本的运行时刻函数库)
/Od 关闭优化开关
/D "_DEBUG" 相当于 #define _DEBUG,打开编译调试代码开关(主要针对
assert函数)
/ZI 创建 Edit and continue(编辑继续)数据库,这样在调试过
程中如果修改了源代码不需重新编译
/GZ 可以帮助捕获内存错误
/Gm 打开最小化重链接开关,减少链接时间
Release 版本:
/MD /ML 或 /MT 使用发布版本的运行时刻函数库
/O1 或 /O2 优化开关,使程序最小或最快
/D "NDEBUG" 关闭条件编译调试代码开关(即不编译assert函数)
/GF 合并重复的字符串,并将字符串常量放到只读内存,防止
被修改
实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
二、哪些情况下 Release 版会出错
有了上面的介绍,我们再来逐个对照这些选项看看 Release 版错误是怎样产生的
1. Runtime Library:链接哪种运行时刻函数库通常只对程序的性能产生影响。调试版本的 Runtime Library 包含了调试信息,并采用了一些保护机制以帮助发现错误,因此性能不如发布版本。编译器提供的 Runtime Library 通常很稳定,不会造成 Release 版错误;倒是由于 Debug 的 Runtime Library 加强了对错误的检测,如堆内存分配,有时会出现 Debug 有错但 Release 正常的现象。应当指出的是,如果 Debug 有错,即使 Release 正常,程序肯定是有 Bug 的,只不过可能是 Release 版的某次运行没有表现出来而已。
2. 优化:这是造成错误的主要原因,因为关闭优化时源程序基本上是直接翻译的,而打开优化后编译器会作出一系列假设。这类错误主要有以下几种:
(1) 帧指针(Frame Pointer)省略(简称 FPO ):在函数调用过程中,所有调用信息(返回地址、参数)以及自动变量都是放在栈中的。若函数的声明与实现不同(参数、返回值、调用方式),就会产生错误————但 Debug 方式下,栈的访问通过 EBP 寄存器保存的地址实现,如果没有发生数组越界之类的错误(或是越界“不多”),函数通常能正常执行;Release 方式下,优化会省略 EBP 栈基址指针,这样通过一个全局指针访问栈就会造成返回地址错误是程序崩溃。C++ 的强类型特性能检查出大多数这样的错误,但如果用了强制类型转换,就不行了。你可以在 Release 版本中强制加入 /Oy- 编译选项来关掉帧指针省略,以确定是否此类错误。此类错误通常有:
● MFC 消息响应函数书写错误。正确的应为
afx_msg LRESULT OnMessageOwn(WPARAM wparam, LPARAM lparam);
ON_MESSAGE 宏包含强制类型转换。防止这种错误的方法之一是重定义 ON_MESSAGE 宏,把下列代码加到 stdafx.h 中(在#include "afxwin.h"之后),函数原形错误时编译会报错
#undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn) \
{ message, 0, 0, 0, AfxSig_lwl, \
(AFX_PMSG)(AFX_PMSGW)(static_cast< LRESULT (AFX_MSG_CALL \
CWnd::*)(WPARAM, LPARAM) > (&memberFxn) },
(2) volatile 型变量:volatile 告诉编译器该变量可能被程序之外的未知方式修改(如系统、其他进程和线程)。优化程序为了使程序性能提高,常把一些变量放在寄存器中(类似于 register 关键字),而其他进程只能对该变量所在的内存进行修改,而寄存器中的值没变。如果你的程序是多线程的,或者你发现某个变量的值与预期的不符而你确信已正确的设置了,则很可能遇到这样的问题。这种错误有时会表现为程序在最快优化出错而最小优化正常。把你认为可疑的变量加上 volatile 试试。
(3) 变量优化:优化程序会根据变量的使用情况优化变量。例如,函数中有一个未被使用的变量,在 Debug 版中它有可能掩盖一个数组越界,而在 Release 版中,这个变量很可能被优化调,此时数组越界会破坏栈中有用的数据。当然,实际的情况会比这复杂得多。与此有关的错误有:
● 非法访问,包括数组越界、指针错误等。例如
void fn(void)
{
int i;
i = 1;
int a[4];
{
int j;
j = 1;
}
a[-1] = 1;//当然错误不会这么明显,例如下标是变量
a[4] = 1;
}
j 虽然在数组越界时已出了作用域,但其空间并未收回,因而 i 和 j 就会掩盖越界。而 Release 版由于 i、j 并未其很大作用可能会被优化掉,从而使栈被破坏。
3. _DEBUG 与 NDEBUG :当定义了 _DEBUG 时,assert() 函数会被编译,而 NDEBUG 时不被编译。除此之外,VC++中还有一系列断言宏。这包括:
ANSI C 断言 void assert(int expression );
C Runtime Lib 断言 _ASSERT( booleanExpression );
_ASSERTE( booleanExpression );
MFC 断言 ASSERT( booleanExpression );
VERIFY( booleanExpression );
ASSERT_VALID( pObject );
ASSERT_KINDOF( classname, pobject );
ATL 断言 ATLASSERT( booleanExpression );
此外,TRACE() 宏的编译也受 _DEBUG 控制。
所有这些断言都只在 Debug版中才被编译,而在 Release 版中被忽略。唯一的例外是 VERIFY() 。事实上,这些宏都是调用了 assert() 函数,只不过附加了一些与库有关的调试代码。如果你在这些宏中加入了任何程序代码,而不只是布尔表达式(例如赋值、能改变变量值的函数调用 等),那么 Release 版都不会执行这些操作,从而造成错误。初学者很容易犯这类错误,查找的方法也很简单,因为这些宏都已在上面列出,只要利用 VC++ 的 Find in Files 功能在工程所有文件中找到用这些宏的地方再一一检查即可。另外,有些高手可能还会加入 #ifdef _DEBUG 之类的条件编译,也要注意一下。
顺便值得一提的是 VERIFY() 宏,这个宏允许你将程序代码放在布尔表达式里。这个宏通常用来检查 Windows API 的返回值。有些人可能为这个原因而滥用 VERIFY() ,事实上这是危险的,因为 VERIFY() 违反了断言的思想,不能使程序代码和调试代码完全分离,最终可能会带来很多麻烦。因此,专家们建议尽量少用这个宏。
4. /GZ 选项:这个选项会做以下这些事
(1) 初始化内存和变量。包括用 0xCC 初始化所有自动变量,0xCD ( Cleared Data ) 初始化堆中分配的内存(即动态分配的内存,例如 new ),0xDD ( Dead Data ) 填充已被释放的堆内存(例如 delete ),0xFD( deFencde Data ) 初始化受保护的内存(debug 版在动态分配内存的前后加入保护内存以防止越界访问),其中括号中的词是微软建议的助记词。这样做的好处是这些值都很大,作为指针是不可能的(而且 32 位系统中指针很少是奇数值,在有些系统中奇数的指针会产生运行时错误),作为数值也很少遇到,而且这些值也很容易辨认,因此这很有利于在 Debug 版中发现 Release 版才会遇到的错误。要特别注意的是,很多人认为编译器会用 0 来初始化变量,这是错误的(而且这样很不利于查找错误)。
(2) 通过函数指针调用函数时,会通过检查栈指针验证函数调用的匹配性。(防止原形不匹配)
(3) 函数返回前检查栈指针,确认未被修改。(防止越界访问和原形不匹配,与第二项合在一起可大致模拟帧指针省略 FPO )
通常 /GZ 选项会造成 Debug 版出错而 Release 版正常的现象,因为 Release 版中未初始化的变量是随机的,这有可能使指针指向一个有效地址而掩盖了非法访问。
除此之外,/Gm /GF 等选项造成错误的情况比较少,而且他们的效果显而易见,比较容易发现。
--------------------------------------------------------------
Release是发行版本,比Debug版本有一些优化,文件比Debug文件小
Debug是调试版本,包括的程序信息更多
Release方法:
build->batch build->build就OK.
-----------------------------------------------------
一、"Debug是调试版本,包括的程序信息更多"
补充:只有DEBUG版的程序才能设置断点、单步执行、使用TRACE/ASSERT等调试输出语句。REALEASE不包含任何调试信息,所以体积小、运行速度快。
二、一般发布release的方法除了hzh_shat(水) 所说的之外,还可以project->Set Active Config,选中release版本。此后,按F5或F7编译所得的结果就是release版本
2009年10月26日
#
1.概览
.构造DLL
(1)仅导出函数
DLL可以导出全局变量和类,但我们不建议这么做,建议导出函数。
(2).lib
每个DLL都有与之相对应的.lib文件,该文件中列出了DLL中导出的函数和变量的符号名
(3)指定要导出的函数名
因为不同编译器的Name mangle规则不同,这就导致DLL不能跨编译器使用。
有以下两种方法可以解决这个问题:
1.在.def文件中指定要导出的函数名
2.在编译指中指定要导出的函数名:
#pragma comment(linker, "/export:MyFunc=_MyFunc@8")
.DLL加载路径
当需要加载一个DLL时,系统会依照下面的顺序去寻找所需DLL直到找到为止,然后加载,否则加载失败。
(1)当前可执行文件路径
(2)GetWindowsDirectory返回的Windows系统路径
(3)16位系统的路径 windows"system
(4)GetSystemDirectory返回的Windows系统路径
(5)当前进程所在路径
(6)PATH环境中所指定的路径
.创建\使用动态链接库
首先必须创建一个包含需要导出的符号的头文件,以便其他程序链接到该dll上:
// dllexample.h
#ifdef DLLEXAMPLE_EXPORTS // 在编译命令中已定义,所以实际用的是 __declspec(dllexport)
#define DLLEXAMPLE_API __declspec(dllexport)
#else
#define DLLEXAMPLE_API __declspec(dllimport)
#endif
DLLEXAMPLE_API int fnDllexample(void);
当其他应用包含该头文件,意图使用该dll的导出符号时,因为没有定义DLLEXAMPLE_EXPORTS,所以使用的是__declspec(dllimport),这样编译器编译时便知道这是从外部引入的函数。在链接时,链接程序将生成导入表(ImportAddressTable),该表罗列了所有调用到的函数,以及一个空白的对应地址。在程序执行时,加载器将动态的填入每个函数符号在本进程中的地址,使得程序能正确的调用到dll中的函数上。
这种通过dll提供的.h和.lib文件进行链接dll的使用方式,称为隐式链接。用vc开发程序时,几乎所有的系统API调用都用了隐式链接。
.显式链接
在exe创建时不引用.lib文件中的符号,当然也不必包含.h头文件,而是由程序调用LoadLibrary(Ex)以及GetProcAddress函数来获取每个需要使用的函数地址,从而进行dll中的函数调用,这种dll使用方法称为显式链接。显式链接时不生成对应dll的IAT.
当决定不再使用该dll时,通过调用FreeLibrary来卸载。需要注意的是,同一个进程中共计调用LoadLibrary的次数要和调用FreeLibrary的次数相等,因为系统维护了一个使用计数,当计数为0时,才会真正的卸载该dll.
如果想确认一个dll是否已经被映射到进程空间中,尽量使用GetModuleHandle,最好不要冒然使用LoadLibrary(Ex).
GetProcAddress可以传递函数名或者序号(通过MAKEINTRESOURCE(2)来"制作"序号).
1.1动态加载DLL文件 LoadLibraryEx
HMODULE LoadLibraryEx( //返回DLL加载到进程空间原首地址。
PCTSTR pszDLLPathName,
HANDLE hFile,
DWORD dwFlags);
dwFlags 可以有以下几个值
(1) DONT_RESOLVE_DLL_REFERENCES
建议永远不要使有这个值,它的存在仅仅是为了向后兼容、
(2) LOAD_LIBRARY_AS_DATAFILE
把要加载的DLL文件以数据文件的形式加载到进程中。
GetModuleHandle和GetProcAddress返回NULL
(3) LOAD_LIBRARY_AS_DATAFILE_EXCLUSIVE
与前者相同,不同的时独占打开,禁止其它进程访问和修改该DLL中的内容。
(4) LOAD_LIBRARY_AS_IMAGE_RESOURCE
不修改DLL中的RVA,以image的形式加载到进程中。常与LOAD_LIBRARY_AS_DATAFILE_EXCLUSIVE一起使用。
(5) LOAD_WITH_ALTERED_SEARCH_PATH
修改DLL的加载路径
1.2 DLL的加载与卸载
(1)加载
不要在同一进程中,同时使用LoadLIbrary和LoadLibraryEx加载同一DLL文件。
DLL的引用计数是以进程为单位的。LoadLibrary会把DLL文件加载到内存,然后映射到进程空间中。
多次加载同一DLL只会增加引用计数而不会多次映射。当所有进程对DLL的引用计数都为0时,系统会在内存中释放该DLL。
(2)卸载
FreeLibrary,FreeLibraryAndExitThread对当前进程的DLL的引用计数减1
(3) GetProcAddress
取得函数地址。它只接受ANSI字符串。
2.DLL的入口函数
2.1 DllMain
BOOL WINAPI DllMain(
HINSTANCE hInstDll, ""加载后在进程中的虚拟地址
DWORD fdwReason, ""系统因何而调用该函数
PVOID fImpLoad ""查看是隐工还是动态加载该DLL
DLLs用DllMain方法来初始化他们自已。DllMain中的代码应尽量简单,只做一些简单的初始化工作。
不要在DllMain中调用LoadLibrary,FreeLibrary及Shell, ODBC, COM, RPC, 和 socket 函数,从而避免不可预期的错误。
2.2 fdwReason的值
(1)DLL_PROCESS_ATTACH
系统在为每个进程第一次加载该DLL时会,执行DLL_PROCESS_ATTACH后面的语句来初始化DLL,DllMain的返回值仅由它决定。
系统会忽略DLL_THREAD_ATTACH等执行后DllMain的返回值。
如果DllMain返回FALSE,系统会自动调用DLL_PROCESS_DETACH的代码并解除DLL文件中进程中的内存映射。
(2)DLL_PROCESS_DETACH
如果DLL是因进程终止而卸载其在进程中的映射,那么负责调用ExitProcess的线程会调用DllMain中DLL_PROCESS_DETACH所对应的代码。
如果DLL是因FreeLibrary或FreeLibraryAndExitThread,而卸载其在进程中的映射, 那么FreeLibrary或FreeLibraryAndExitThread会负责调用DllMain中DLL_PROCESS_DETACH所对应的代码。
如果DLL是因TerminateProcess而卸载其在进程中的映射,系统不会调用DllMain中DLL_PROCESS_DETACH所对应的代码。
(3) DLL_THREAD_ATTACH
若进程是先加载的DLL,后创建的线程
那么在进程中创建新线程时(主线程除外),系统会执行该进程已载的所有DLL的DllMain中DLL_THREAD_ATTACH对应的代码。
若进程是先创建的线程,后加载的DLL
那么系统不会调用DLL的DllMain中的代码。
(4) DLL_THREAD_DETACH
进程中的线程退出时,会先执行所有已加载DLL的DllMain中DLL_THREAD_DETACH所对应的代码。若该代码中有死循环,线程不会退出。
2.3 同步化DllMain的调用
同一时间只能有一个线程调用DllMain中的代码,所以下面的代码会导致死循环
BOOL WINAPI DllMain(HINSTANCE hInstDll, DWORD fdwReason, PVOID fImpLoad) {
HANDLE hThread;
DWORD dwThreadId;
switch (fdwReason) {
case DLL_PROCESS_ATTACH:
// The DLL is being mapped into the process' address space.
// Create a thread to do some stuff.
hThread = CreateThread(NULL, 0, SomeFunction, NULL,
0, &dwThreadId);// CreateThread会DLL_THREAD_ATTACH中的代码,但是由于当前线程并未执行完毕,
//所以DLL_THREAD_ATTACH 中的代码不会被执行,且CreateThread永无不会返回。
// Suspend our thread until the new thread terminates.
WaitForSingleObject(hThread, INFINITE);
// We no longer need access to the new thread.
CloseHandle(hThread);
break;
case DLL_THREAD_ATTACH:
// A thread is being created.
break;
case DLL_THREAD_DETACH:
// A thread is exiting cleanly.
break;
case DLL_PROCESS_DETACH:
// The DLL is being unmapped from the process' address space.
break;
}
return(TRUE);
}
3.延时加载DLL
(1)延时加载DLL的限制
延迟加载的D L L是个隐含链接的D L L,它实际上要等到你的代码试图引用D L L中包含的一个符号时才进行加载,它与动态加载不同。
4.已知的DLL (Known DLLs)
位置:HKEY_LOCAL_MACHINE"SYSTEM"CurrentControlSet"Control"Session Manager"KnownDLLs
LoadLibrary在查找DLL会先去该位置查找有无相应的键值与DLL要对应,若有则根据链值去%SystemRoot%"System32加载键值对应的DLL
若无则根据默认规去寻找DLL
5.Bind and Rebase Module
它可以程序启动的速度。ReBaseImage
DLL 注入和API钩(DLL Injection and API Hooking)
1.概览
每个进程都有自已独立的地址空间,一个进程不可能创建一个指向其它进程地址空间的指针。
然而如果我们把自已的DLL注射到另一个进程的地址空间去,我们就可以在那个被注入的进程里为所欲为了。
2.用注册表注入DLL
该方法适用于给GUI的程序注入DLL
所有的GUI应用程序在启动时都会加载User32.dll,而在User32.dll的DLL_PROCESS_ATTACH代码根据注册表中的信息
来注入用户指定的DLL
注册表项 HKEY_LOCAL_MACHINE"Software"Microsoft"Windows NT"CurrentVersion"Windows"
中有两个值:
LoadAppInit_Dlls:键值中指定要注入的DLL 如:c:"inject.dll
AppInit_Dlls:若其键值为1,则注入LoadAppInit_Dlls中指定的DLL,否则若为0则不注入。
注:
(1)LoadAppInit_Dlls中的值是以空格或分号分隔的,所以DLL的路径中最好不要有空格,最后不指定路径,直接将DLL放到windows系统目录中。
(2) 用注册表注入DLL的方式有很大的局限性,Kernel32.dll和Ntdll.dll中有的函数才能调用
一.注入dll
1.通过注册表项 HKEY_LOCAL_MACHINE\Software\Microsoft\Windows NT\CurrentVersion\Windows\AppInit_DLLs 来指定你的dll的路径,那么当一个GUI程序启动时就要加载User32.dll,而User32.dll将会检查这个值,如果有的话就LoadLibrary该Dll。这个方法不好,因为大多数情况我们只需要针对性的注入,并且没办法注入到不使用User32.dll的进程中;
2.用SetWindowsHookEx函数,并传递目标线程ID、需要挂载的Dll在本进程中的映射地址(hInstance)、替换函数在本进程中的地址。这样,当被挂载进程的这个线程要执行相应的操作时(GETMESSAGE、键盘消息之类的),就会发现已经安装了WH_XX,The system checks to see whether the DLL containing the GetMsgProc function is mapped into Process B's address space,如果还未映射该Dll,则强制LoadLibrary。然后系统调用hThisInstance + (GetMsgProc - hInstance),从而实现了事件的通知。这种方法的好处是可以针对某个进程安装Hook,缺点是容易被目标进程发现、同样只适用于GUI进程。如果不再想使用挂钩了,那么需要调用UnhookWindowsHookEx,卸载Hook。
3.使用远程线程注入Dll(Injecting a DLL Using Remote Threads)
这个方法比较好。流程是这样的:
?调用VirtualAllocEx,在目标进程保留一块内存,并提交,其长度是你要注入Dll的全路径长度nLen + 1,返回地址pv;
?调用WriteProcessMemory,在目标进程的pv处写入Dll的全路径,注意要添加\0结束符;
?获取本进程的LoadLibrary函数的地址,方法是调用pfn = GetProcAddress(GetModuleHandle(TEXT("Kernel32")), "LoadLibraryA")——之所以获取本进程的地址,是因为kernel32.dll在每个进程的映射地址都相同,倘若不同,那么此方法则无效;
?调用HANDLE hThread = CreateRemoteThread(hProcessRemote, NULL, 0, pfn, pv, 0, NULL)来创建远程线程,其实这个线程函数就是LoadLibrary函数,因此将执行映射Dll到目标进程的操作;
?调用VirtuallFreeEx(hProcessRemote, pv)释放提交的内存;
这便完成了dll注入。
缺点是不能用在windows98上。但是对于xp都要被微软抛弃的年代,windows98地影响不大了。
4.披着羊皮的狼:使用特洛伊Dll来注入Dll(Injecting a DLL with a Trojan DLL)
其实就是替换某个目标进程要加载的a.dll,并把a.dll的所有引出函数用函数转发器在自己的dll引出。
5.用调试函数插入Dll
ReadProcessMemory和WriteProcessMemory是windows提供的调试函数。如果在方法3中调用WriteProcessMemory写入的不是字串而是精心编排好的机器指令,并且写在目标进程特定的地址空间,那么这段机器指令就有机会执行——而这段机器指令恰好完成了LoadLibrary功能;
6.其他方法(略)
二.挂接API(API Hooking)
其实,这是许多注入的Dll都愿意做的事情。
所谓挂接API就是在目标进程调用windows API之前,先执行我们的仿API函数,从而控制系统API的行为,达到特殊的目的。
我们的仿造函数必须与要替换的系统API有相同的型参表以及相同的返回值类型.
1.改写系统API代码的前几个字节,通过写入jmp指令来跳转到我们的函数。在我们的函数里执行操作,可以直接返回一个值,也可以将系统API的前几个字节复原,调用系统API,并返回系统API的值——随便你想怎么做。
此方法的缺点是对于抢占式多线程的系统不太管用。
2.通过改写目标进程IAT中要调用的函数地址来达到目的。具体操作见书中示例
线程本地存储(Thread-Local Storage)
例子C / C + +运行期库要使用线程本地存储器( T L S)。由于运行期库是在多线程应用程序出现前的许多年设计的,因此运行期库中的大多数函数是用于单线程应用程序的。函数s t r t o k就是个很好的例子。
尽可能避免使用全局变量和静态变量
1.动态TLS
图21-1 用于管理T L S的内部数据结构
在创建线程时,进程会为当前创建的线程分配一个void *的数组作为TLS用。它用于存储只限当前线程可见的全局变量。
从而使进程中的每个线程都可以有自已的(不能其它线程访问的)全局变量。
TlsAlloc在返回时会先把槽中的值置为0。每个线程至少有64个槽。
2.静态TLS
__declspec(thread)关键字用于声明,线程本地的全局变量。
要求声明的变量必须是全局变量或静态变量。
3.Common API:
TlsAlloc TlsFree
TlsSetValue TlsGetValue
__declspec(thread)