近期工作上的事情太杂太琐碎,好久没有更新博客了。工作当中时有所思所感的东西,每次想记录下来时,奈何心里的那个黑天使总是跳出来说“太麻烦了”,然后就真的懒得写了,加之最近有点贪玩《炉石》,所以博客园的这一亩三分地也已荒草丛生。废话不多说,进入本篇博客正题吧。
对于服务器程序而言,尤其是云计算时代的服务器程序,三高标准(高可用、高性能、高扩展)往往是衡量一个优秀的服务器程序的重要指标。本篇文章主要聊聊服务宕机恢复(高可用的重要内容)、负载均衡(高扩展、高可用的主要内容)。以下内容均属个人工作中的见解,如有不妥之处,欢迎指正。 ----peakflys
一、服务的宕机恢复 服务根据功能定位的划分,一般可以抽象为前端服务、状态服务、各种逻辑功能服务、数据存储服务,这里给出两个常见的简单服务器架构(不含数据存储服务)
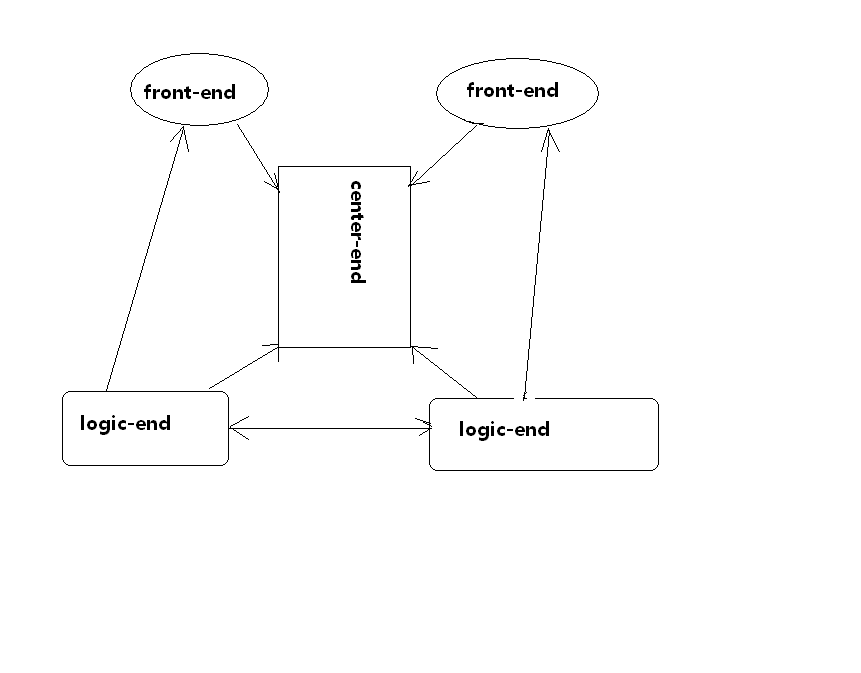
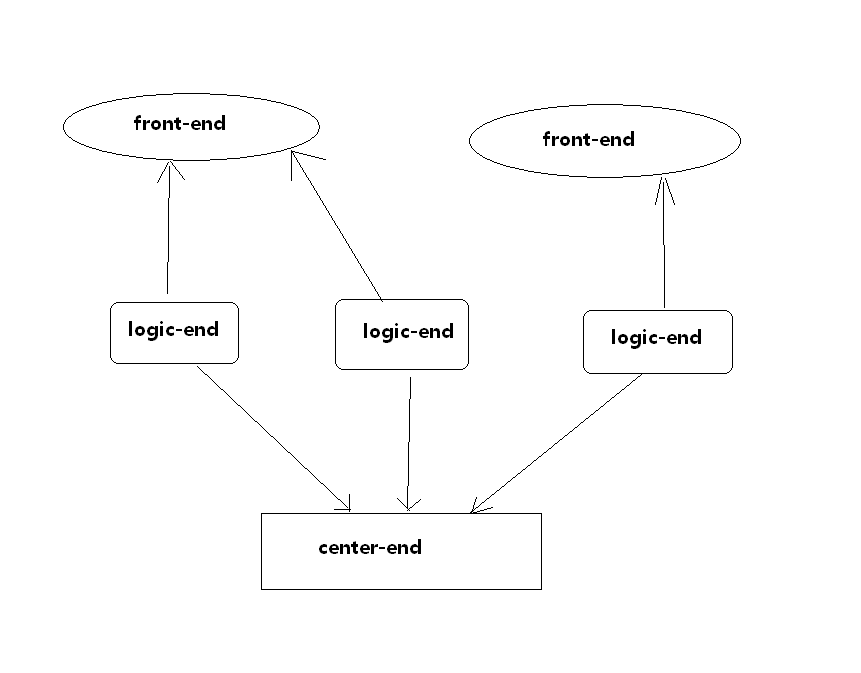
根据不同的服务类型,宕机恢复的具体操作是不同的具体的操作是不同的。
1、前端服务 前端服务一般我们又称之为网管服务,对于这种服务宕机的情况,我们除了对其他服务做用户下线的操作外,前端服务并没有其他的宕机恢复操作,重启之后,用户重新连上来并注册状态即可,对于宕机重启的间歇时间的服务,我们放在下面的高可用相关的内容来讲。
2、状态服务 如果业务量和用户量不是特别复杂的话,我们一般情况下都是把状态服务器设计成全局的单点服务器。就如上面图片中所画的那两种简易服务器架构里的center-end一样。这个服务往往存储用户所在的网关信息或者逻辑服务器的信息,这些信息往往是比较重要的。所以对于他的宕机恢复我们一般情况下使用这几种方案。
①、重新注册 如果状态服务crash重启,所存状态对应的所有服务都过来重新注册相应的状态。
优点:逻辑简单,不易出错,扩展起来方便。
缺点:如果用户量达到一定的规模,此服务重启后服务器的负载会出现瞬间飙升。
②、cache同步 使用memcache或者redis等作为所存状态的缓存(一般和状态服务器不在同一台物理机)。在状态服务更新某一状态时,同时把对应的状态数据刷到缓存服务器。 这样在状态服务宕机重启后,直接从缓存中恢复(我称之为积极恢复),或者其他服务来查询对应的状态时,如果本地内存没有,则去缓存中找,找到时,回应状态 查询请求,同时把状态恢复到本地内存中(我称之为惰性恢复)。“积极恢复”可以马上使状态服务恢复到宕机前的状态,“惰性恢复”则可以在不影响功能的情况下分散 的慢慢的恢复。
优点:逻辑较简单,不易出错,扩展性很好。
缺点:如果在状态服务crash前,cache服务重启或者关闭了,则之后状态服务宕机恢复时,会导致部分状态数据的缺失。(所以cache服务要保证稳定,最好直接 使用memcache等成熟的解决方案)。同时此类型不方便存储过于复杂的数据类型。
③、master-slave 每次启动两台状态服务,先启动的作为master服务,后启动为slave服务,每次master服务更新某一状态时,会同时把对应的信息同步到slave服务器(或者两者 直接使用共享内存等方式)。当master服务宕机时,通过一些方案(例如virtual IP漂移等),使slave服务转变为master服务,同时master服务重启后变为 slave服务。
优点:可用性更强,服务的宕机恢复能力也比较强。所存数据的安全性和一致性都比较高,而且存储的数据类型不受限制。
缺点:逻辑比较复杂,要做的处理比较多,而且容易出错。
④、master-master(or more) 每次启动两台(或者多台)状态服务,两台服务之间使用共享内存等方式共享状态信息,这样任何一台服务的宕机重启均不影响状态的查询服务,而且重启之后不 需要恢复做什么额外的恢复操作。
优点:服务本身不存储状态,服务的高可用性更强,宕机恢复速度也比较快。
缺点:状态存储的一致性需要保证,而且使用的共享内存等存储带来了另外的单点隐患,一旦宕机,影响重大。
这几种方案各有优缺点,在项目早期,用户量不大,而且项目进度很赶的情况下,第一种方案,无疑是最适合的方案;如果所存储的状态是天然的key-value形式, 则第二种方案很适合;如果项目时间充裕,而且存储的状态很多或者很复杂的话,可以优先考虑第三或者第四种。
3、数据存储服务 这个服务是大家讨论最多,解决方案也比较成熟的话题,目前我了解到的很多都是使用master-master或者master+多slave(memcache或redis集群)的方案,另外一些数据库提供商本身就提供了很多高可用方案(例如SQL Server的AlwaysOn,Mysql最新存储引擎的宕机恢复机制等),开发者本身不用太过关注。反倒是开发者最为关注的应该是数据库读写性能的优化。
4、逻辑功能服务
这一项是最为复杂的,需要结合具体的逻辑功能来说。一般情况下,我认为有以下几种方案:
①、用户重登陆处理 主要的逻辑服务宕机后,直接使用户在其他服务做下线处理,然后客户端程序自动做重连接,重新注册到其他的逻辑功能服务器,恢复对应的服务。
优点:逻辑处理简单,用户状态的维持不易出错。
缺点:如果逻辑功能服务会保存一些用户状态,则这种方案用户感受度不好。而且如果登陆过程比较复杂时,其他服务器的负载也会比较高(例如账号验证一般放 在前端服务器来做,如果认证过程过多等,前端服务的负载和出错率都会升高)。
②、前端服务重新选择 在用户不断开和前端服务器(即gateway服务器)连接的情况下,直接由前端服务器重新为用户选择新的逻辑功能服务。
优点:仅作前端服务和逻辑服务之间的重连,响应速度比较快。
缺点:如果逻辑功能服务会保存一些用户状态,则这种方案用户感受度不好。
其他逻辑更为复杂的,只能结合着具体业务来定制方案,在此不作过多的分析。
上面的服务举例仅仅是一个便于讲述的精简版,如果要做高强度的高可用,尤其是在云时代的大数据量的高可用,服务器架构里必然要消除单点服务!
时间不早了,负载均衡相关的东西放在下一篇博客讨论,待续……