项目终于上线了,伴随着人数的逐步上升,最近查看日志,发现了大量连接超时的日志。项目中使用的是TCP长连接,为了保证网络资源及时有效的释放,程序中是1分钟一次心跳,3分钟无心跳即认为超时。此为本文的背景
相对于TCP连接建立时的三次握手,我想很多人对断开连接的四次招呼就不是那么熟了,这里先谈一下TCP的断开,下面给出TCP断开连接的过程图:
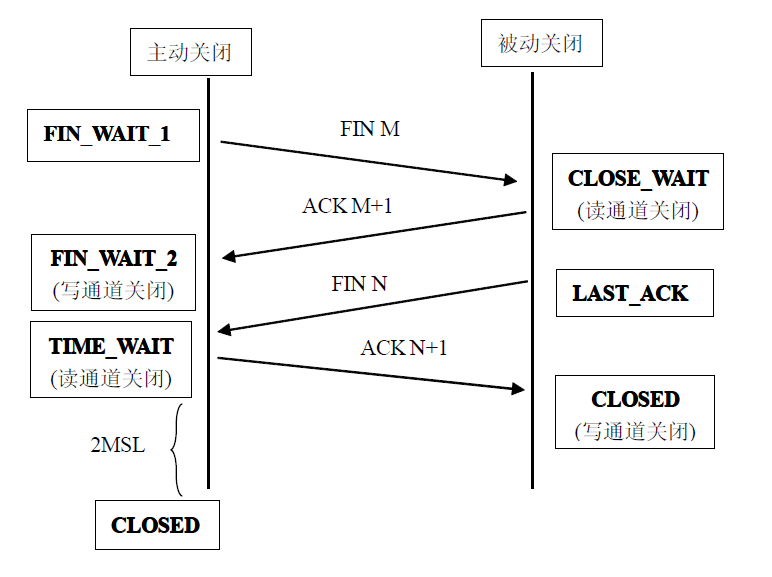
(peakflys注:TIME_WAIT状态到CLOSED状态的转变视SO_LINGER选项的设置)
从上图可以看到,在服务器不主动关闭客户端TCP连接的情况下,需要客户端发送一个FIN分节,然后服务器端OS TCP栈对这个数据包回复ACK后,服务器处理程序从TCP栈内取出此连接断开的消息,一般服务器程序的处理是:做完收尾清理工作后马上调用close或者shutdown操作来关闭相应的socket。这样双方都调用了关闭套接口的操作,经过后面的一次确认后才正常的关闭全双工工作的TCP连接。但是如果客户端出现了异常,导致FIN包发不到服务器端,那服务器端就只能一直保持这种“死连接”存在。目前解决这种问题的方法有两个:一、开启TIME_OUT选项,默认情况下TCP栈两小时后保活一次(如果要改变这个值,需要修改TCP的全局配置选项,对所有在此机器上跑的TCP程序都生效!),保活失败后则关闭连接、回收资源,但这种保活机制有很多明显或隐藏的问题,不建议使用);二、在应用层面上定义保活机制,即在应用层固定时间双方保持数据的交换即可,超出这个固定时间就认为连接已不存在,执行回收关闭的操作。
之前我对TCP超时的理解就是Client端环境(或者中间路由)发生了异常 导致TCP不优雅的断开,这种异常存在于两种情况:
①、客户端OS崩溃(peakflys注:
程序崩溃时,OS会代进程发送FIN,所以这种情况的出现时在OS负责TCP处理的内核机制失效时,这种失效可以是软件层面的,如OS自身bug,或驱动层面的故障亦或是直接硬件损坏导致的)
②、双方网络中断(peakflys注:这种中断可能是中间网络服务商的路由出现故障,或者客户端机器的网线拔掉了,断开了同最后一跳的路由器直接的连接,这种情况下就回触发TCP的重传机制,linux下是基于Berkaly的实现方法,默认重传15分次,持续时间半个小时左右)
上述情况最终表现出来的结果为“主机不可达”或“重传超时”的错误(peakflys注:如果第一种情况被最后一跳的路由器探测到,更新完路由表后就会反馈"主机不可达"的错误,探测不到或者第二种情况的重传机制规定次数还是失败的话就会反馈“重传超时”的错误),在这两种错误后,TCP栈就无能为力了。这时服务器端就出现了不优雅的“死链接”。
其实这两种错误很容易理解,这就像两个打电话的人约定如果要挂电话必须要让对方知道,第二种情况对应的场景是:一方突然被绑架,嘴上被绑上胶带,然后使劲在心里喊我要挂电话了,我要挂电话了,但是对方听不到,只能一直傻傻的等着。第一种情况对应的场景是:一方直接被爆头了,连遗言都没来得及说就挂了,对方没听到他说挂电话,所以也只能傻傻的等到花儿也落了……
言归正传,重新回到本次事件的描述上。看到大量的连接超时的日志(一天有四百多条记录,当时用户量才3000人左右),首先基本排除网络问题,因为通过对超时的连接IP分析,发现并没有明显的区域性,美国很多州的IP都有。那么最有可能的就是客户端问题了,因为客户端如果出现死循环或者进程死锁之类的问题时,因为进程未崩溃,OS的TCP栈不会管你的,这时候客户端也无力处理服务器发送过来的保活信息,导致服务器端程序认为此链接已不存在。但是客户端的同事说应该不会出现这么多客户端异常的情况吧,因为测试了很久,最近也没放出特别的代码,内部QA人员也从没有反馈有这种情况。
没办法,继续搜集日志,找找规律。当时的思维就停留在这里了,非优雅连接产生除了客户端问题,还可能有什么情况? 不同地方这么多用户的OS一天内都崩溃?概率应该很小啊,而且前后连续的几天都是这样的情况,从概率上讲应该是0了吧? 难道是不同地方的这么多用户网络一天内都出现问题?倒是可能出现,但是美国那边的产品经理和运维人员都说没有听过这种情况……
直到第二天和QA的经理在聊起时他说了一句话:如果对方电脑休眠会出现这种情况吗?我才柯南一般的灵光一闪,电脑休眠或者待机时应该会出现这种情况吧。马上去微软官网帮助信息里查找关于待机、休眠的描述:
“休眠”将保存一份桌面及所有打开文件和文档的映像,然后关闭计算机电源。打开电源时,文件和文档就会按原来离开时的样子在桌面上打开。“待机”功能则切断所用硬件组件的电源,从而减少计算机的电源消耗。“待机”可切断外围设备、显示器甚至硬盘驱动器的电源,但会保留计算机内存的电源,以不至于丢失工作数据。
从上面可以看到休眠直接关闭了计算机的电源,就算是待机也是关闭了外围设备,因为网络功能的处理肯定都是最终通过网卡来实现的,如果它关闭了,自然一切的网络功能都失效了,而且OS还无耻的自己直接“睡”了,导致在服务器程序不知情的情况下,客户端程序直接被“雪藏”了……
在自己电脑上模拟了一下,日志表现出来的状况也证实了应该是个答案。至于为什么这种情况每天有上百个,因为外网环境复杂,使用者的习惯更难以捉摸,但持续观察了很多天,都没有人反馈客户端有什么异常,所以基本可以肯定是因windows电源管理策略的待机和休眠导致的。
其实这种情况可以归为第一种情况:客户端OS“崩溃”,认真想一下应该可以想到休眠这种情况的,但是当时思维愣是没往那方面想,一直认为可能是客户端程序出了问题,导致浪费了将近一天的时间,虚惊一场。很多事情都是这样,结果出来后再去倒推感觉每个过程都是顺理成章的,但是正推时如果有一层窗户纸没捅开,就很可能跑到迷宫的另一个方向了……
--peakflys 16:42:04 Monday, May 27, 2013