
2013年10月9日
在沉默了数月之后,博主心血来潮想继续介绍QParserGenerator,在这里我们将不再继续介绍任何有关于LALR(1)的算法(那东西只会把你的脑子变成一团浆糊),让我们来看一下QParserGenerator的具体用法。
说到ParserGenerator不得不提的是BNF,应此QParserGenerator也有它自己的BNF,这时有人会问BNF究竟是什么呢?简单的说BNF就是用来描述一种语法的东西,比如在Basic中If后面跟表达式然后是Then中间是语句块末尾必须要有End If等等的一系列描述,更专业的解释我们可以看一下
维基百科上的解释。
好了,说完了BNF那让我们来看一下QParserGenerator的BNF到底是长啥样的
%token "%" "token" "start" "|" "-" ">" ";" "[" "]";
%start start;
strings -> strings "{String}"
| "{String}"
;
vs -> vs "{Letter}"
| vs "{String}"
| "{Letter}"
| "{String}"
;
option -> "[" vs "]"
;
oneProductionRight -> oneProductionRight option
| oneProductionRight vs
| option
| vs
;
someProductionRight -> someProductionRight "|" oneProductionRight
| oneProductionRight
;
token -> "%" "token" strings ";"
;
someTokens -> someTokens token
| token
;
production -> "{Letter}" "-" ">" someProductionRight ";"
;
someProductions -> someProductions production
| production
;
start -> someTokens "%" "start" "{Letter}" ";" someProductions
| "%" "start" "{Letter}" ";" someProductions
;
也许有人会问,不对啊根据
维基百科上的说明BNF不应该是长这样的,其实QParserGenerator是一个BNF的生成器,它可以将输入的BNF通过一系列的运算最后生成LALR(1)分析表,为了BNF文件的美观和方便处理我特地把他设计成了这个样子的而已,好了下面我们就以这个BNF文件来说明应该如何来书写BNF文件。
首先可以看到最顶上有一些以%token开头的字符串(在C语言中我们将用双引号括起来的字符序列称为字符串)以及最后的一个分号,其实这里的这些字符串正是BNF中说说的终结符,所以我们规定,所有其他没用%token声明的符号都是非终结符。终结符是用来做移进操作的,在某种特定的语言中他表现为一个token,而非终结符可以理解为一个代词,通常一个非终结符都可以展开为一条或多条规则(
产生式)。至于说为什么每条内容后面都会有分号呢,只是为了处理上的方便(消除语法上的冲突?)。
好了,我们把终结符和非终结符这两个专业术语给解释完了,接下来可以看到的是一个以%start开头后跟一个非终结符的语句,他表明了所有规则(
产生式)是从哪里开始的(有始无终的节奏-_-||杯具啊)。
最后就是我们的重头了,多空一行也不为过吧。这里有一大堆的产生式,那我们如何来阅读他呢,其实上面已经介绍了有个表明了所有规则开头的非终结符,好那让我们来找一下他所对应的产生式在哪里
start -> someTokens "%" "start" "{Letter}" ";" someProductions
| "%" "start" "{Letter}" ";" someProductions
;
可以看到所有的规则可分为左半部分和右半部分,左边总是一个非终结符来说明他应该被哪一些规则来替代,而右边则是这些规则的具体内容包含了一些终结符和非终结符序列,中间则用一个箭头符号来分割。在所有的规则中非终结符都是不带引号的,而终结符都是用引号将其括起来的,在终结符中有一些内置的变量来表达一些特定的表达式,这个会在下文中做出说明。当然对于同一个终结符来说我们可以用任意多个规则来说明他,他们都是
或的关系,由于BNF中不可能存在
且的关系,应此我们并不需要考虑他。
下面让我们来看一下预定义的终结符有哪些,从
Parser.cpp的代码中可知预定义的终结符有"{String}"、"{Digit}"、"{Real}"、"{Letter}"。
"{String}":表示正则表达式\"[^\"]*\"
"{Digit}":表示正则表达式[0-9]+
"{Real}":表示正则表达式[0-9]*.[0-9]+
"{Letter}":表示正则表达式((_[0-9]+)|([_a-zA-Z]+))[_0-9a-zA-Z]*
从这些正则表达式中可见"{String}"表示一个带双引号的字符串,"{Digit}"则表示一个数字,"{Real}"则表示一个浮点数,"{Letter}"则表示一个不带双引号的字符串。当然这些正则表达式写的并不完备,比如"{String}"中没有支持转义等等。
然后让我们来看一下每条规则支持哪些语法,首先从下面几条文法中可知,可用方括号将一些可选项括起来。
1 vs -> vs "{Letter}"
2 | vs "{String}"
3 | "{Letter}"
4 | "{String}"
5 ;
6
7 option -> "[" vs "]"
8 ;
而对于一个规则来说他可以用若干条产生式来说明他,其中每条产生式之间是
或的关系。
1 oneProductionRight -> oneProductionRight option
2 | oneProductionRight vs
3 | option
4 | vs
5 ;
6
7 someProductionRight -> someProductionRight "|" oneProductionRight
8 | oneProductionRight
9 ;
其他一些规则则说明了一些上文提到的规则,比如开头是一些token的定义等。终于把QParserGenerator的文法文件的结构给介绍完了,在接下来的一篇文章中我们将介绍如何用QParserGenerator来生成一个带括号优先级的四则混合运算计算器,其文法可见
Calculator.txt,QLanguage整个项目的代码可见
https://github.com/lwch/QLanguage/。
posted @
2013-10-09 11:17 lwch 阅读(1540) |
评论 (0) |
编辑 收藏
2013年5月30日
接
上一篇,首先需要修正的是在DFA生成算法中的传播部分,应该需要有个循环一直传播到不能传播为止,在多次实验中表明,有些展望符是通过第2,3,4甚至更多次传播得来的。
应此,相应的make函数变成了
bool LALR1::make()
{
vector<LALR1Production> v;
v.push_back(inputProductions[begin][0]);
pStart = closure(v);
pStart->idx = Item::inc();
context.states.insert(pStart);
items.push_back(pStart);
queue<Item*> q;
q.push(pStart);
vector<Item*> changes;
bool bContinue = false;
while (!q.empty())
{
Item* pItem = q.front();
vector<Production::Item> s;
symbols(pItem, s);
select_into(s, vts, compare_production_item_is_vt, push_back_unique_vector<Production::Item>);
select_into(s, vns, compare_production_item_is_vn, push_back_unique_vector<Production::Item>);
for (vector<Production::Item>::const_iterator i = s.begin(), m = s.end(); i != m; ++i)
{
Item* pNewItem = NULL;
if (go(pItem, *i, pNewItem))
{
long n = itemIndex(pNewItem);
if (n == -1)
{
pNewItem->idx = Item::inc();
q.push(pNewItem);
items.push_back(pNewItem);
context.states.insert(pNewItem);
}
else
{
items[n]->mergeWildCards(pNewItem, bContinue);
changes.push_back_unique(items[n]);
destruct(pNewItem, has_destruct(*pNewItem));
Item_Alloc::deallocate(pNewItem);
}
edges[pItem].push_back_unique(Edge(pItem, n == -1 ? pNewItem : items[n], *i));
}
}
q.pop();
}
while (bContinue)
{
vector<Item*> v;
v.reserve(changes.size());
bContinue = false;
for (vector<Item*>::const_iterator i = changes.begin(), m = changes.end(); i != m; ++i)
{
vector<Production::Item> s;
symbols(*i, s);
for (vector<Production::Item>::const_iterator j = s.begin(), n = s.end(); j != n; ++j)
{
Item* pNewItem = NULL;
if (go(*i, *j, pNewItem))
{
long n = itemIndex(pNewItem);
if (n == -1) throw error<const char*>("unknown item", __FILE__, __LINE__);
else
{
items[n]->mergeWildCards(pNewItem, bContinue);
v.push_back_unique(items[n]);
destruct(pNewItem, has_destruct(*pNewItem));
Item_Alloc::deallocate(pNewItem);
}
}
}
}
changes = v;
}
}
在merge函数中,会检测有没有新生成的展望符来决定是否继续传播下去。
一个示例
下面我们用一个例子来说明LALR1 DFA是如何生成的,首先它的文法如下
S -> L "=" R
| R "+"
| R
;
L -> "*" R
| "id"
;
R -> L
;
根据之前的算法,我们先来看自生的部分
首先我们写出这个文法的增广文法
begin -> . S (#)
求取它的闭包得到
begin -> . S
wildCards:
#
S -> . L "=" R
wildCards:
#
S -> . R "+"
wildCards:
#
S -> . R
wildCards:
#
L -> . "*" R
wildCards:
"=" "+"
L -> . "id"
wildCards:
"=" "+"
R -> . L
wildCards:
"+" #
我们观察到,其中有5个可转移的符号,分别为S、L、R、"*"和"id",我们分别用go函数对这5个转移符号求出新的状态
首先用符号S求出新状态
begin -> S
wildCards:
#
由于这个状态不在原有列表中,应此它是一个新生成的状态,我们为它添加一条通过符号S转移的边。
接下来用符号L求出新状态
S -> L . "=" R
wildCards:
#
R -> L
wildCards:
"+" #
这个状态也不在原有列表中,应此它也是一个新生成的状态,我们为它添加一条通过符号L转移的边。
然后用符号R求出新状态
S -> R . "+"
wildCards:
#
S -> R
wildCards:
#
这个状态也不在原有列表中,应此它也是一个新生成的状态,我们为它添加一条通过符号R转移的边。
然后用符号*求出新的状态
L -> "*" . R
wildCards:
"=" "+"
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
同样的它也不在原有的列表中,我们同样为其添加一条通过符号*转移的边。
然后是符号id的
L -> "id"
wildCards:
"=" "+"
同样不在列表中,我们为其添加一条通过符号id转移的边。
这样,从start状态转移出来的5条边就生成好了,下面来看看这5个新生成的状态又会生成一些什么呢
begin -> S
wildCards:
#
由第一个状态可知,它没有任何的边。
S -> L . "=" R
wildCards:
#
R -> L
wildCards:
"+" #
第二个状态则有一个=的转移,它生成了一个新状态
S -> L "=" . R
wildCards:
#
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
S -> R . "+"
wildCards:
#
S -> R
wildCards:
#
第三个状态有一个+的转移,它生成了一个新状态
S -> R "+"
wildCards:
#
L -> "*" . R
wildCards:
"=" "+"
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
第四个状态有4个转移,分别为R、L、*和id
1.通过符号R转移到新状态
L -> "*" R
wildCards:
"=" "+"
2.通过符号L转移到新状态
R -> L
wildCards:
"+" # "="
3.通过*则可转移到它自己
4.通过id转移到第5个状态
第五个状态则没有任何的转移。
S -> L "=" . R
wildCards:
#
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
第六个状态有4个转移,分别为R、L、*和id
1.通过符号R可转移到新状态
S -> L "=" R
wildCards:
#
2.通过符号L可转移到状态9
3.通过符号*可转移到状态4
4.通过符号id可转移到状态5
第6、7、8个状态都没有任何转移
然后让我们来看下changes列表里有哪些东西,根据
上一篇的算法可知,所有已存在的状态都在changes列表里,应此它里面应该会有4、5和9三个状态。
至此,整个自生的部分完成了,下面我们将其画成一张图
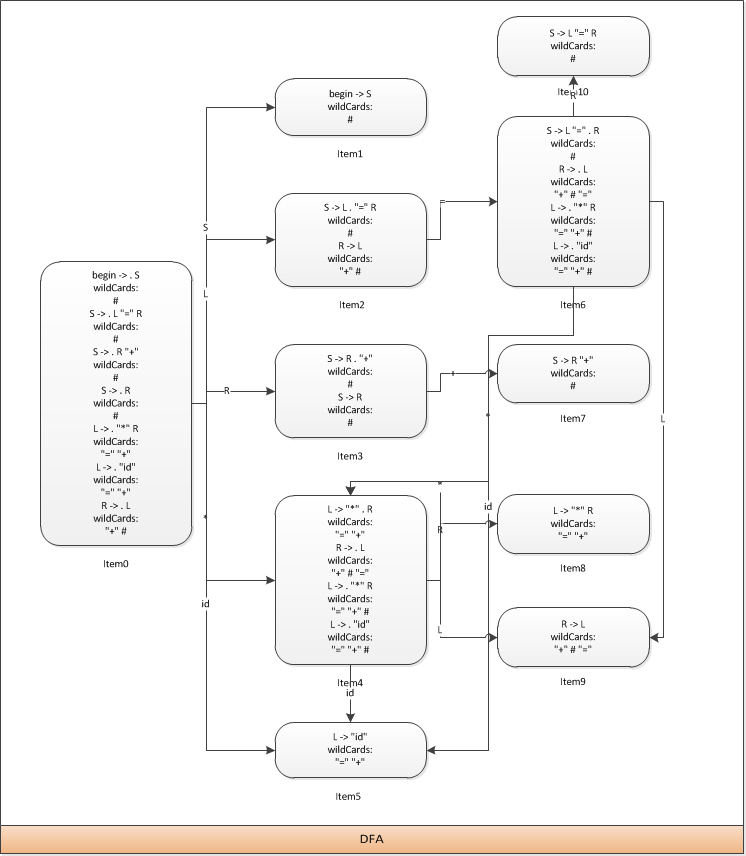 下面是传播部分
下面是传播部分
在第一次传播时changes列表里有3个状态,分别对这3个状态用go函数求出新的展望符,并把它们合并到原有的状态上。
首先看状态4,它有4个状态转移符,分别是R、L、*和id
1.通过符号R可转移到状态8,同时它的展望符如下
L -> "*" R
wildCards:
"=" "+" #
2.通过符号L可转移到状态9,同时它的展望符如下
R -> L
wildCards:
"+" # "="
3.通过符号*可转移到它自己,同时它的展望符如下
L -> "*" . R
wildCards:
"=" "+" #
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
4.通过符号id可转移到状态5,同时它的展望符如下
L -> "id"
wildCards:
"=" "+" #
然后我们来看一下状态5和9,它们没有任何状态转移符,应此它们不会传播任何展望符。
现在changes列表里有4个状态,分别为8、9、4和5,又由于第8个状态已经产生了新的展望符#应此需要继续传播
第二次传播
首先先看状态8和9,它们没有任何状态转移符,应此它们不会传播任何展望符。
然后来看状态4,同样的它有4个状态转移符,分别为R、L、*和id。
1.通过符号R可转移到状态8,同时它的展望符如下
L -> "*" R
wildCards:
"=" "+" #
2.通过符号L可转移到状态9,同时它的展望符如下
R -> L
wildCards:
"+" # "="
3.通过符号*可转移到它自己,同时它的展望符如下
L -> "*" . R
wildCards:
"=" "+" #
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
4.通过符号id可转移到状态5,同时它的展望符如下
L -> "id"
wildCards:
"=" "+" #
最后我们来看状态5,它没有任何状态转移符,应此它不会传播任何展望符。
现在changes列表里同样有4个状态,分别为8、9、4和5,由于没有一个状态产生了新的展望符,应此它将不会继续传播下去了。
现在整个文法的DFA就生成完毕了,让我们来修改一下原先的那张图来看看最终的DFA是什么样的。
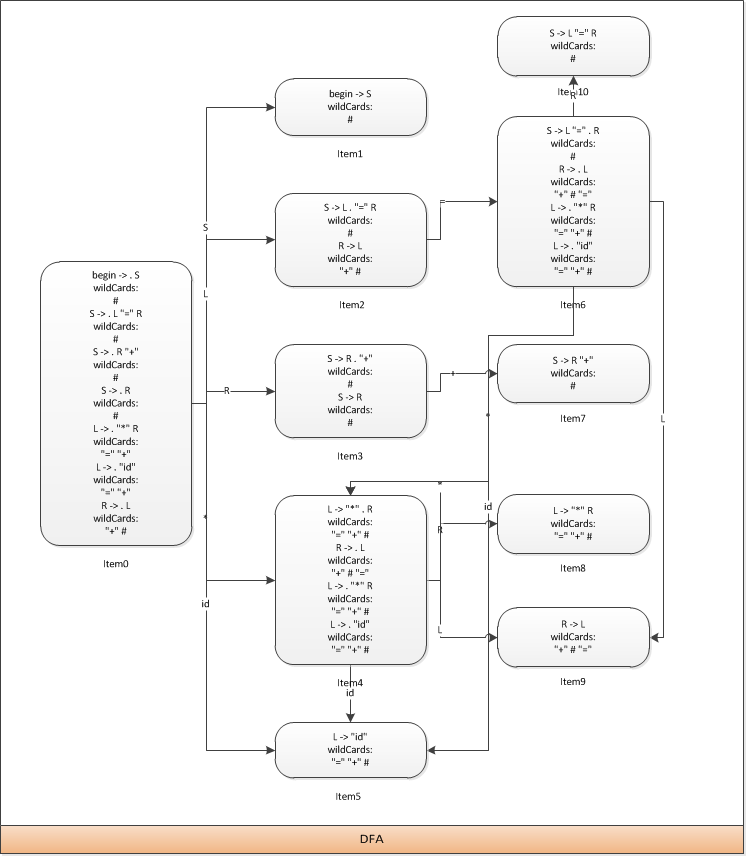
整个示例就先介绍到这里,在接下来的一篇文章中将会通过几个示例来介绍closure和go函数的原理,希望这种由粗到细的讲解顺序能够被读者所接受。最后完整的代码可到
http://code.google.com/p/qlanguage下载。
posted @
2013-05-30 23:04 lwch 阅读(1635) |
评论 (2) |
编辑 收藏
2013年5月12日
摘要: 以下所说的文法文件均为QParserGenerator的文法文件
产生式
我们将文法文件中形如
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->strings &n...
阅读全文
posted @
2013-05-12 22:32 lwch 阅读(2662) |
评论 (1) |
编辑 收藏
2013年4月30日
QCore/Library说明文档
李文超
前言
QCore/Library是一套类STL的类库,它在标准库的范围内删去了不常用的heap、deque等结构(至少我是不常用的)。并为一些容器提供了一些特殊的接口,比如vector中的push_back_unique、add和add_unique等。
Library主要分为六部分,内存调试相关、容器、算法、正则、IO和Graphic,每个模块都有各自的分工,他们之间的耦合度极低,几乎每个模块都可以拆出来独立使用,下面来分别介绍各个模块。
内存调试
我们知道,在C/C++中内存相关的东西是极难控制的,在使用不当时可能造成各种错误,轻则内存泄漏,重则程序崩溃。所以,在生产环境中我们必须通过一个有效的手段来管理好内存。当然,在小块内存频繁new、delete的过程中也会产生大量的内存碎片,从而导致可用内存数量越来越少。应此我们设计了一个内存池来控制小块内存的频繁new、delete,以及做到对内存泄漏的检测。
在内存池的设计之初,我只是简单的设计出了可以使用的MemoryPool的最简版本,它包含一个大块内存的free_list和每个小块内存的chunk_list,当时足以应付大部分的需求,而且最初用的是Visual Leak Detector来检测内存泄漏。但随着时间的推移,想要自己检测内存泄漏的欲望越来越强烈,之后便有了一个use_list来保存内存块的释放情况。当时完成了这个patch之后,兴奋的跑了一下TestCase,然后的结果我想大家应该知道了,一路的飘红,到处是内存泄漏。
经过一天的调试,实在无法容忍的情况下,我翻阅了MSDN,查到了dbghelp.dll中可以通过许多函数来获取调用堆栈,于是在此之下便生产出了CallStack模块。有了它之后你就可以在任意地方保存当前的调用堆栈了,真是十分方便。当然直到现在,它还只支持在Windows下调用堆栈的获取(稍后我会翻阅资料,实现一个like unix的版本,如果可能的话)。
这里不过多的描述实现的细节,具体可以看http://www.cppblog.com/lwch/archive/2012/07/14/183420.html和http://www.cppblog.com/lwch/archive/2013/01/19/197415.html两篇文章。
最后来看allocator,这里只是简单的为其包装了一层。
template <typename T>
class allocator
{
public:
allocator()
{
}
allocator(const allocator<T>&)
{
}
static T* allocate()
{
MemoryPool* pool = getPool();
return reinterpret_cast<T*>(pool->allocate(sizeof(T), free_handler));
}
static T* allocate(size_t n)
{
MemoryPool* pool = getPool();
return reinterpret_cast<T*>(pool->allocate(n * sizeof(T), free_handler));
}
static void deallocate(T* p)
{
MemoryPool* pool = getPool();
pool->deallocate(p, sizeof(T));
}
static void deallocate(T* p, size_t n)
{
MemoryPool* pool = getPool();
pool->deallocate(p, n * sizeof(T));
}
static void deallocateWithSize(T* p, size_t n)
{
MemoryPool* pool = getPool();
pool->deallocate(p, n);
}
static T* reallocate(T* p, size_t old_size, size_t n)
{
MemoryPool* pool = getPool();
return pool->reallocate(p, old_size, n * sizeof(T), free_handler);
}
public:
static void(*free_handler)(size_t);
static void set_handler(void(*h)(size_t))
{
free_handler = h;
}
protected:
static MemoryPool* getPool()
{
static MemoryPool pool;
return &pool;
}
};
template <typename T>
void (*allocator<T>::free_handler)(size_t) = 0;
容器
容器占了Library的大部分,容器的作用是用来存储对象的,容器分为线性和非线性两种。线性的容器有vector、list、string以及用它们作为容器实现的queue、stack四种,非线性的则有rbtree、hashtable以及用它们作为容器实现的set、map、hashset、hashmap六种。对于每种容器,都必须定义出它的value_type、pointer、reference、const_reference、size_type、distance_type、const_iterator、const_reverse_iterator、iterator、reverse_iterator的类型。
所有容器必须包含以下几个接口:size(获取容器内元素个数)、clear(清空容器)、begin(获取[first,last)区间中的first迭代器)、end(获取[first,last)区间中的last迭代器)、rbegin(获取反向的first迭代器)、rend(获取反向的last迭代器)。
traits
traits是一种萃取技术,通过它你可以获取某种类型的一些特性,比如是否含有默认构造函数、拷贝构造函数等。
__type_traits
__type_traits用于萃取出某种类型的一些特性,它的原型如下
template <typename T>
struct __type_traits
{
typedef __true_type has_default_construct;
typedef __true_type has_copy_construct;
typedef __true_type has_assign_operator;
typedef __true_type has_destruct;
typedef __false_type is_POD;
};
通过特例化,可以定义出所有类型的这些属性,比如char
template <>
struct __type_traits<char>
{
typedef __true_type has_default_construct;
typedef __true_type has_copy_construct;
typedef __true_type has_assign_operator;
typedef __false_type has_destruct;
typedef __true_type is_POD;
};
__container_traits
__container_traits用于萃取出容器的特性,如上文所说的value_type等特性,它的代码很简单
template <typename T>
struct __container_traits
{
typedef typename T::value_type value_type;
typedef typename T::pointer pointer;
typedef typename T::reference reference;
typedef typename T::const_reference const_reference;
typedef typename T::size_type size_type;
typedef typename T::distance_type distance_type;
typedef typename T::const_iterator const_iterator;
typedef typename T::const_reverse_iterator const_reverse_iterator;
typedef typename T::iterator iterator;
typedef typename T::reverse_iterator reverse_iterator;
};
char_traits
char_traits定义了一些对于Char的操作,包括assign(赋值)、eq(相等)、lt(小于)、compare(比较两个字符串的大小)、length(获取字符串的长度)、move(移动)、copy(拷贝)、assign(字符串赋值)、eof(结束符),它的代码比较简洁,这里不做说明。
type_compare
type_compare用于对两种类型做运行时的匹配,判断所给定的两种类型是否相同。同样通过特例化技术可以很轻松的实现它的代码。
迭代器
迭代器类是一种类似于smart pointer的东西,一般的它都会支持前置和后置的++和--操作,有一些特殊的迭代器同样支持+=和-=操作。当然作为一种smart pointer少不了的是->和*操作,而对于比较操作,则比较的是迭代器所保存的值。
迭代器分为bidirectional_iterator和random_access_iterator两种类型,前者只支持++和--操作而后者支持+和-运算符,之所以会定义出这两种类型是为了提高算法的速度。对于一个迭代器来说同样需要定义value_type、distance_type、pointer、reference、const_pointer、const_reference的类型。
反向迭代器
反向迭代器与正向的正好相反,应此我们可以类似的定义它的++为正向迭代器的--等运算符
iterator_traits
iterator_traits用于萃取出迭代器的所有特性,应此它比较简单
template <typename Iterator>
struct iterator_traits
{
typedef typename Iterator::value_type value_type;
typedef typename Iterator::distance_type distance_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
typedef typename Iterator::const_pointer const_pointer;
typedef typename Iterator::const_reference const_reference;
};
vector
vector是一种比较常用的容器,它的内部是一个连续的内存块,应此它有两个接口分别用于获取内存块已使用的大小和容器的大小,它们是size和capacity,同样它也有一个reserve接口来调整它的容量。由于vector的内部是连续的,应此它只允许从后面插入元素,所以它有push_back、push_back_unique和pop_back方法。当然为了作为queue的容器,我还为其增加了pop_front方法用于删除前端的元素。insert和erase用于在某个地方插入和删除元素,add和add_unique用于插入另一个vector里的内容,而unique则会将容器内重复的元素删除。
当然vector可以像数组一样的使用,它支持方括号的运算符与at接口来获取某个位置上的元素值。
vector容器就先介绍到这里,它的代码你可以在QCore/Library/vector.h中找到。
list
list的内部则是一个双向的链表,应此它在删除前端的元素时会比vector快很多,它的接口基本跟vector相同,这里就不做过多的介绍了。由于vector是内存连续的,所以它可以直接通过索引来访问某个元素,而list是一个双向的链表,应此通过制定索引去访问某个元素时会先看这个索引的值是否小于list长度的一半来决定是从list的头部遍历还是从list的尾部遍历,它的代码你可以在QCore/Library/list.h中找到。
queue和stack
queue是一种FIFO(先进先出)的结构,应此我们建议使用list作为它的容器,通过list的push_back和pop_front可以使代码变的高效。它拥有front和back方法来获取队列中队头和队尾的元素值,同样在插入队列时,你可以不加选择的直接插入或是插入一个不重复的值。
stack是一种FILO(先进后出)的结构,同样它拥有push、push_unique和pop方法以及top和bottom方法用于获取栈顶端和底部的元素值。
对于这两种结构的代码,你可以在QCore/Library/queue.h和QCore/Library/stack.h中找到。
rbtree
rbtree(红黑树)是一棵自平衡的二叉查找树,应此它拥有较高的查找效率,红黑树有以下5条性质
性质1. 节点是红色或黑色。
性质2. 根节点是黑色。
性质3 每个叶节点是黑色的。
性质4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
以上摘自百度百科
对于红黑树的每个节点,它都拥有它的key和value,当然我们是按照节点的key来排序的(废话)。红黑树拥有insert_equal和insert_unique方法分别用于插入一个节点,前者允许待插入节点的key已存在于这棵树中,而后者在插入时并不允许这个节点的key已存在于这棵树中,应此它的返回值则是一个二元的。erase方法则提供了对于树中某个节点的删除操作,可以通过迭代器或某个key值来删除其中的节点。
由于红黑树是一棵二叉查找树,应此它应该具备find方法,用于在树中查找某个节点,它返回的则是指向这个节点的一个迭代器。由于红黑树是有序的,应此可以通过maximum和minimum方法得到其中的最大和最小值。通过lower_bound和upper_bound可以得到属于某个key的[first,last]区间,equal_range就是干这个活的,count方法可以得到某个key所对应的节点数。
rbtree就先介绍到这里,稍后我会在博客中继续更新提供更完整的实现方法,它的代码你可以在QCore/Library/rbtree.h中找到。
set和map
set是一种集合的结构,应此在集合中是不允许有重复的元素的,set是以rbtree作为容器的。应此它的insert方法对应于rbtree的insert_unique方法,同样rbtree所具备的接口set也同样拥有,set的key_type与value_type相同,都是给定的类型。
map则是一种key-value的directory结构,应此它的key是不允许重复的,map同样是以rbtree作为容器的。应此它的insert方法同样对应于rbtree的insert_unique方法,在map中除了rbtree的maximum、minimum、lower_bound、upper_bound、equal_range和count没有之外其他接口基本全都拥有,map的key_type是给定的类型,而value_type则是一个以Key和T组成的二元组。
对于这两种结构的代码,你可以在QCore/Library/set.h和QCore/Library/map.h中找到。
hashtable
hashtable是一种哈希结构,应此它的元素查找和插入是非常快的。在这里我用的是吊桶法来处理元素插入时的冲突,当吊桶长度过长(默认是11个元素)时,会将桶的大小翻一倍然后重建整个hashtable以提高hashtable中元素的查找速度。
同样的在hashtable中有insert_equal和insert_unique来分别插入允许相同和不同的元素,当遇到一个已有的元素时会将这个元素插入到第一个与它值相同的节点后面,这样做的好处是可以简单的实现equal_range方法。同时hashtable拥有value方法用于通过一个指定的key来查找到它对应的值,find方法则是用来查找一个key所对应的迭代器的。同样的hashtable也拥有count方法来获取某个key所对应的值的个数,maximum和minimum则是用来获取最大值和最小值的。
hashtable的代码,你可以在QCore/Library/hashtable.h中找到。
hashset和hashmap
hashset和hashmap基本与set和map相同,这里不过多做介绍,关于它们的代码,你可以在QCore/Library/hashset.h和QCore/Library/hashmap.h中找到。
basic_string
basic_string的实现方式基本和vector差不多,为了提高效率,在所有的插入操作中若新的长度的一倍小于一个定长(默认是512)字节时会申请新长度的一倍作为容器的容量。
与vector不同的是basic_string拥有c_str和data方法用于获取字符指针,append方法往字符串尾部链接另一个字符串,assign方法给字符串赋值,find方法查找到第一个指定的字符串的位置,substr则用来获取字符串中一部分的内容。
在basic_string中也有format的静态方法来生成一个指定形式的字符串,其他用法基本与vecotr相同。它的代码,你可以在QCore/Library/string.h中找到。
本章小结
上面介绍了所有的容器的接口和使用方法,以及在实现方式上的一些技巧。希望通过上面的介绍,读者们能够体会到STL为什么需要这么去设计、这么设计的好处是什么。
在我后来做regex的过程中,我深刻的体会到,选用一个合适的数据结构可以给代码的运行效率带来非常大的提升。比如给定NFA某个状态,需要找出所有从这个状态出发的边,之前使用的是map结构来保存从某个状态出发边的vector,之后发现遍历的速度非常缓慢,在换成hashmap之后,速度有显著的提升。应此在实际编程过程中,选用一个合适的数据结构显得尤为重要。
在使用线性结构时,一般在小数据量或不平凡插入或删除数据的情况下,选用vector作为容器会更快一些。而在需要平凡插入或删除数据的场合下,选用list作为容器会有更优异的结果。需要保持元素唯一性的情况下,我会优先选用set作为容器,而在数据量非常大的情况下,就会使用hashset来代替set。map则如它的名字那样,适用于key-value的场合,而hashmap在数据量非常大的情况下使用。
算法
min和max函数分别用于求取最小值和最大值,fill_n用来填充若干个对象的值。copy_backward用来从后往前拷贝值。distance用来求给定区间[first, last)的长度。search用于在给定范围[first1, last1)内查找符合序列[first2, last2)集合的值。swap和iterator_swap分别用于交换两个值和两个迭代器指向的值。sort用于将指定范围[first, last)内的值排序,find用于在指定范围[first, last)内查找指定的值。toArray用于将指定范围[first, last)内的值转换为内存连续的数组,compareArray则用于比较两个数组内的值的个数和值是否相同。
具体的实现代码,你可以在QCore/Library/algo.h中找到。
正则
通过重载+(相加)、-、|、+(前置)、*(前置)、!以及opt函数来生成正则表达式的ε-NFA,然后通过buildDFA函数生成DFA。通过parse和match可分析给定的字符串是否符合这个正则表达式,parse从头开始跑DFA看这个字符串的开头是否有符合这个正则表达式的字符串,而match则会找[first, last)区间内符合这个正则表达式的第一个字符串的相关结果。
具体的实现方法,你可以看http://www.cppblog.com/lwch/archive/2013/02/15/197848.html和http://www.cppblog.com/lwch/archive/2013/02/23/198043.html两篇文章,而代码则可在QCore/Library/regex/regex.h中找到。
IO
IO模块包含文件IO和标准输入输出IO,首先有两个基类分别是basic_istream和basic_ostream分别作为输入和输出stream的基类,其中分别定义了运算符>>和<<,通过这两个运算符可以直观的看到是从stream输出到变量或是从变量输入到stream中。之后有stdstream_basic和fstream_basic都继承自basic_istream和basic_ostream分别作为basic_stdstream和basic_fstream的基类,它们都有open、size、tell、seek、read、write和flush方法,它们都是对底层C函数的一些封装。而在下一层的basic_stdstream和basic_fstream中则实现了运算符>>和<<的所有重载,这样做的好处是可以使代码更有条理性,并方便阅读。
对于标准输入输出流来说,实际上是对stdin、stdout、stderr的一些封装,当然里面也有一些比较特殊的接口,比如setColor(用于设置输入输出流的字体颜色)以及一些颜色相关的函数。
对于fstream来说它是针对所有文件的,应此它会多一个readAll接口用于一次性的读出这个文件的所有内容,为了节省频繁读写磁盘所造成的性能损耗,我们给它定义了两个buffer用来做cache,当你要写入文件时,它并不是马上就直接往磁盘里写的,而会加到buffer当中,当达到一个预值时才真正的写入到磁盘。
那么IO模块就先介绍到这里了,它们的代码你可以在QCore/Library/ios.h、QCore/Library/istream.h、QCore/Library/ostream.h、QCore/Library/fstream.h、QCore/Library/stdstream.h、QCore/Library/iostream.h和QCore/Library/iostream.cpp中找到。
结束
上文介绍了大部分模块的实现过程与实现过程中的心得,让我们来按照顺序回顾一下。
首先介绍了内存池的实现过程,以及在实现过程中遇到的一些问题,比如如何检测内存泄漏、如何获取调用堆栈等。
然后介绍了traits技术,它是用来萃取出一些特性用的,通过traits技术你可以得到一个类型是否为POD是否有默认构造函数等特性。而__container_traits则萃取出了容器的一些特性,比如值类型等等。通过char_traits我们得到了一些关于字符串的操作,比如求字符串的长度等。
之后又通过特例化,我们实现了一种比较两个变量类型是否相同的手段。
接下来我们介绍了迭代器和反向迭代器,它们是一种类似于smart pointer的东西,我们可以通过一个[first, last]前闭后开区间来表示一个容器内的所有元素。然后我们通过iterator_traits萃取出了迭代器的一些特性,比如值类型等。
最后我们介绍了所有比较常用的容器,以及在某些场合下应该使用哪种容器来达到高效的目的。比如在数据量较大时使用hashset要比使用set在插入和查找速度要更快一些,而且时间负责度更稳定一些。
之后我们又介绍了一些常用算法,通过这些算法足以解决一些简单的问题。比如排序和求取一个范围[first, last]的长度等。
在正则这一章中,介绍了我们是如何通过一些运算符的重载来构造出某个正则表达式的状态机的,以及如何通过运行这些状态机来分析给定的字符串。
最后介绍了IO模块,其中分为标准输入输出流和文件流,通过重载<<和>>运算符,可以直观的看到是从流中讲内容输入到一个变量或是从一个变量中讲内容输入到流中。
希望通过本文可使读者体会到作者在设计这个库的时候所考虑的问题,以及对这个库有一个大概的认识,稍后我会在我的博客中补齐所有没有介绍过的模块是如何实现的。
修改记录
2013.4.23第一次编写
2013.4.24添加容器的说明
2013.4.25添加hashtable、hashset、hashmap和basic_string结构的说明
2013.4.28添加算法和正则的说明
2013.4.30添加IO的说明,完结此文
posted @
2013-04-30 20:24 lwch 阅读(2229) |
评论 (1) |
编辑 收藏
2013年2月23日
接上一篇我们已经得到了一个完整的ε-NFA,下面来说说如何将ε-NFA转换为DFA(确定有限自动机)。
DFA的状态
在DFA中,某个状态对应到ε-NFA中的若干状态,应此我们将会得到下面这样的一个结构。
struct DFA_State
{
set<EpsilonNFA_State*> content;
bool bFlag;
#ifdef _DEBUG
uint idx;
#endif
DFA_State(const set<EpsilonNFA_State*>& x) : content(x), bFlag(false)
{
#ifdef _DEBUG
idx = inc();
#endif
}
inline const bool operator==(const DFA_State& x)const
{
if (&x == this) return true;
return content == x.content;
}
#ifdef _DEBUG
inline uint inc()
{
static uint i = 0;
return i++;
}
#endif
};
可以看到,为了调试方便我们在结构中定义了状态的唯一ID以及对应到ε-NFA状态的集合和一个标记位。
DFA的边
根据上一篇的经验,不难想到DFA的边应该是什么样的,下面直接给出代码,不做说明。
struct DFA_Edge
{
struct
{
Char_Type char_value;
String_Type string_value;
}data;
enum Edge_Type
{
TUnknown = 0,
TNot = 1,
TChar = 2,
TString = 4
};
uchar edge_type;
DFA_State* pFrom;
DFA_State* pTo;
DFA_Edge(const Char_Type& x, bool bNot, DFA_State* pFrom, DFA_State* pTo) : pFrom(pFrom), pTo(pTo)
{
data.char_value = x;
edge_type = bNot ? (TChar | TNot) : TChar;
}
DFA_Edge(const String_Type& x, bool bNot, DFA_State* pFrom, DFA_State* pTo) : pFrom(pFrom), pTo(pTo)
{
data.string_value = x;
edge_type = bNot ? (TString | TNot) : TString;
}
inline const bool isNot()const
{
return (edge_type & TNot) == TNot;
}
inline const bool isChar()const
{
return (edge_type & TChar) == TChar;
}
inline const bool isString()const
{
return (edge_type & TString) == TString;
}
const Edge_Type edgeType()const
{
if (isChar()) return TChar;
else if (isString()) return TString;
else return TUnknown;
}
const bool operator<(const DFA_Edge& x)const
{
return (ulong)pFrom + pTo < (ulong)x.pFrom + x.pTo;
}
const bool operator==(const DFA_Edge& x)const
{
return pFrom == x.pFrom && pTo == x.pTo;
}
};
由于DFA中不存在ε边,应此DFA将会存在若干个结束状态,但他只有一个开始状态
DFA_State* pDFAStart;
set<DFA_State*> pDFAEnds;
set<DFA_Edge> dfa_Edges;
为了下一步分析的高效,以后可能会将这里的dfa_Edges同样修改为hashmap。
至此DFA所要用到的两个结构迅速的介绍完了。
子集构造算法
通过各种资料,我们不难发现,从ε-NFA转换到DFA的过程中,最常用就是子集构造算法。子集构造算法的主要思想是让DFA的每个状态对应NFA的一个状态集。这个DFA用它的状态去记住NFA在读输入符号后达到的所有状态。(引自编译原理)其算法如下
输入:一个NFA N。
输出:一个接受同样语言的DFA D。
方法:
1.求取ε-NFA初始状态的ε闭包作为DFA的起始状态,并将这个状态加入集合C中,且它是未标记的。同时记录它的向后字符集。
2.从集合C中取出一个未被标记的子集T和其对应的字符集,标记子集T。
3.使用上一步取出的字符集通过状态转移函数求出转移后的状态集M。
4.求取上一步得到的状态集M的ε闭包U
5.如果U不在集合C中则将U作为未被标记的子集加入C中,同时记录它的向后字符集。检查状态U中是否存在NFA中的终结状态,若存在则将状态U加入到pDFAEnds中。
重复2,3,4,5部直至集合C中不存在未被标记的状态。
ε闭包
ε闭包是指从某个状态起只经过ε边达到的其他状态的集合,同时这个状态也属于这个集合中。其算法如下
输入:状态集k。
输出:状态集U和其所对应的向后字符集。
方法:
1.遍历状态集k中的每个状态k'。
2.若k'不存在于结果状态集U中,将k'插入U中。
3.建立一个临时集合tmp,并将k'插入其中。
4.从临时集合tmp中取出一个状态p。
5.取出所有从p出发的边,若这条边是ε边,且抵达状态不在结果状态集U中,将抵达的状态分别插入结果状态集U和临时集合tmp中。若这条边是字符集的边且这条边所对应的字符不在向后字符集中,则将向后字符插入向后字符集中。
6.将状态p从临时集合tmp中删除。
循环4,5,6部直至tmp中不存在任何状态为止。
由于在生成ε-NFA时不存在只有ε边的循环,应此这里不会产生死循环。下面给出具体的代码
void epsilonClosure(const set<EpsilonNFA_State*>& k, EpsilonClosureInfo& info)
{
for (typename set<EpsilonNFA_State*>::const_iterator i = k.begin(), m = k.end(); i != m; ++i)
{
info.states.insert(*i);
set<EpsilonNFA_State*> tmp;
tmp.insert(*i);
while (!tmp.empty())
{
EpsilonNFA_State* pState = *tmp.begin();
for (typename vector<EpsilonNFA_Edge>::const_iterator j = epsilonNFA_Edges[pState].begin(), n = epsilonNFA_Edges[pState].end(); j != n; ++j)
{
if (j->isEpsilon())
{
if (info.states.insert(j->pTo).second) tmp.insert(j->pTo);
}
else if (j->isChar()) info.chars.insert(pair<Char_Type, bool>(j->data.char_value, j->isNot()));
else if (j->isString()) info.strings.insert(pair<String_Type, bool>(j->data.string_value, j->isNot()));
}
tmp.erase(pState);
}
}
}
其中用到的EpsilonClosureInfo结构为
struct EpsilonClosureInfo
{
set<EpsilonNFA_State*> states;
set<pair<Char_Type, bool> > chars;
set<pair<String_Type, bool> > strings;
EpsilonClosureInfo() {}
EpsilonClosureInfo(const set<EpsilonNFA_State*>& states,
const set<pair<Char_Type, bool> >& chars,
const set<pair<String_Type, bool> >& strings)
: states(states)
, chars(chars)
, strings(strings) {}
EpsilonClosureInfo(const EpsilonClosureInfo& x)
{
states = x.states;
chars = x.chars;
strings = x.strings;
}
};
需要保存的是状态集和向后字符集。
状态转移函数
通过状态转移函数,输入一个集合T和一个字符a将可得到所有通过T中的每一个状态和a边所能达到的状态的集合。应此代码如下
set<EpsilonNFA_State*> move(const DFA_State& t, const Char_Type& c, bool bNot)
{
set<EpsilonNFA_State*> result;
for (typename set<EpsilonNFA_State*>::const_iterator i = t.content.begin(), m = t.content.end(); i != m; ++i)
{
for (typename vector<EpsilonNFA_Edge>::const_iterator j = epsilonNFA_Edges[*i].begin(), n = epsilonNFA_Edges[*i].end(); j != n; ++j)
{
if (j->isChar() && j->data.char_value == c && j->isNot() == bNot) result.insert(j->pTo);
}
}
return result;
}
set<EpsilonNFA_State*> move(const DFA_State& t, const String_Type& s, bool bNot)
{
set<EpsilonNFA_State*> result;
for (typename set<EpsilonNFA_State*>::const_iterator i = t.content.begin(), m = t.content.end(); i != m; ++i)
{
for (typename vector<EpsilonNFA_Edge>::const_iterator j = epsilonNFA_Edges[*i].begin(), n = epsilonNFA_Edges[*i].end(); j != n; ++j)
{
if (j->isString() && j->data.string_value == s && j->isNot() == bNot) result.insert(j->pTo);
}
}
return result;
}
为了分别支持Char_Type和String_Type的字符我们定义了两个move函数。
最后我们给出子集构造算法的代码
void buildDFA()
{
set<EpsilonNFA_State*> start;
start.insert(pEpsilonStart);
typedef pair<DFA_State*, EpsilonClosureInfo> c_type;
map<size_t, list<c_type> > c;
queue<c_type> c2;
pDFAStart = DFA_State_Alloc::allocate();
EpsilonClosureInfo info;
epsilonClosure(start, info);
construct(pDFAStart, info.states);
c_type ct(pDFAStart, info);
c[info.states.size()].push_back(ct);
c2.push(ct);
if (isEndDFAStatus(pDFAStart)) pDFAEnds.insert(pDFAStart);
context.dfa_States.insert(pDFAStart);
while (!c2.empty())
{
DFA_State* t = c2.front().first;
set<pair<Char_Type, bool> > chars = c2.front().second.chars;
set<pair<String_Type, bool> > strings = c2.front().second.strings;
t->bFlag = true;
for (typename set<pair<Char_Type, bool> >::const_iterator i = chars.begin(), m = chars.end(); i != m; ++i)
{
EpsilonClosureInfo info;
epsilonClosure(move(*t, i->first, i->second), info);
DFA_State* p = getDFAState(info.states, c);
if (p) // 如果这个状态已存在
{
dfa_Edges.insert(DFA_Edge(i->first, i->second, t, p));
}
else
{
DFA_State* pState = DFA_State_Alloc::allocate();
construct(pState, info.states);
context.dfa_States.insert(pState);
if (isEndDFAStatus(pState)) pDFAEnds.insert(pState);
c_type ct(pState, info);
c[info.states.size()].push_back(ct);
c2.push(ct);
dfa_Edges.insert(DFA_Edge(i->first, i->second, t, pState));
}
}
for (typename set<pair<String_Type, bool> >::const_iterator i = strings.begin(), m = strings.end(); i != m; ++i)
{
EpsilonClosureInfo info;
epsilonClosure(move(*t, i->first, i->second), info);
DFA_State* p = getDFAState(info.states, c);
if (p) // 如果这个状态已存在
{
dfa_Edges.insert(DFA_Edge(i->first, i->second, t, p));
}
else
{
DFA_State* pState = DFA_State_Alloc::allocate();
construct(pState, info.states);
context.dfa_States.insert(pState);
if (isEndDFAStatus(pState)) pDFAEnds.insert(pState);
c_type ct(pState, info);
c[info.states.size()].push_back(ct);
c2.push(ct);
dfa_Edges.insert(DFA_Edge(i->first, i->second, t, pState));
}
}
c2.pop();
}
}
尾声
同样我们来编写一个函数来打印出DFA。
void printDFA()
{
printf("---------- DFA Start ----------\n");
set<DFA_State*> tmp;
for (typename set<DFA_Edge>::const_iterator i = dfa_Edges.begin(), m = dfa_Edges.end(); i != m; ++i)
{
printf("%03d -> %03d", i->pFrom->idx, i->pTo->idx);
switch (i->edgeType())
{
case DFA_Edge::TChar:
printf("(%c)", i->data.char_value);
break;
case DFA_Edge::TString:
printf("(%s)", i->data.string_value.c_str());
break;
default:
break;
}
if (i->isNot()) printf("(not)");
printf("\n");
tmp.insert(i->pFrom);
tmp.insert(i->pTo);
}
printf("start: %03d -> ends: ", pDFAStart->idx);
for (typename set<DFA_State*>::const_iterator i = pDFAEnds.begin(), m = pDFAEnds.end(); i != m; ++i)
{
printf("%03d ", (*i)->idx);
}
printf("\n");
#if DEBUG_LEVEL == 3
printf("-------------------------------\n");
for (typename set<DFA_State*>::const_iterator i = tmp.begin(), m = tmp.end(); i != m; ++i)
{
printf("State: %03d\n", (*i)->idx);
for (typename set<EpsilonNFA_State*>::const_iterator j = (*i)->content.begin(), n = (*i)->content.end(); j != n; ++j)
{
printf("%03d ", (*j)->idx);
}
printf("\n");
}
#endif
printf("----------- DFA End -----------\n");
}
最后我们加入测试代码
Rule_Type::Context context;
Rule_Type a('a', context), b('b', context), d('d', context);
Rule_Type result = (a - d).opt() + (+b | !(a + b));
result.buildDFA();
#ifdef _DEBUG
result.printEpsilonNFA();
result.printDFA();
#endif
可打印出如下内容

画成图如下

完整的代码可到http://code.google.com/p/qlanguage下载
posted @
2013-02-23 23:30 lwch 阅读(2946) |
评论 (0) |
编辑 收藏
2013年2月15日
自动机
关于自动机的说明,这里不不再复述,请到http://zh.wikipedia.org/wiki/自动机查看。
表达式
首先,我们规定表达式中只允许输入Char_Type和String_Type类型的字符。
template <typename Char_Type, typename String_Type>
class Rule
{
};
ε-NFA的状态
对于一个状态来说,我们并不需要知道他的任何信息
在上面的代码中,为了调试方便,我为其加入了idx域,并为每个状态分配了一个唯一的ID。
struct EpsilonNFA_State
{
#ifdef _DEBUG
uint idx;
EpsilonNFA_State()
{
idx = inc();
}
static uint inc()
{
static uint i = 0;
return i++;
}
#else
EpsilonNFA_State() {}
#endif
};
ε-NFA的边
ε-NFA中的边都是有向的。对于任意一条边来说,最重要的是他的两个端点是谁以及这条边所对应的字符集(若这条边不是ε边)。
struct EpsilonNFA_Edge
{
struct
{
Char_Type char_value;
String_Type string_value;
}data;
enum Edge_Type
{
TUnknown = 0,
TNot = 1,
TChar = 2,
TString = 4,
TEpsilon = 8
};
uchar edge_type;
EpsilonNFA_State* pFrom;
EpsilonNFA_State* pTo;
EpsilonNFA_Edge(EpsilonNFA_State* pFrom, EpsilonNFA_State* pTo) : edge_type(TEpsilon), pFrom(pFrom), pTo(pTo) {}
EpsilonNFA_Edge(const Char_Type& x, EpsilonNFA_State* pFrom, EpsilonNFA_State* pTo) : edge_type(TChar), pFrom(pFrom), pTo(pTo)
{
data.char_value = x;
}
EpsilonNFA_Edge(const String_Type& x, EpsilonNFA_State* pFrom, EpsilonNFA_State* pTo) : edge_type(TString), pFrom(pFrom), pTo(pTo)
{
data.string_value = x;
}
inline void negate()
{
edge_type ^= TNot;
}
inline const bool isNot()const
{
return (edge_type & TNot) == TNot;
}
inline const bool isEpsilon()const
{
return (edge_type & TEpsilon) == TEpsilon;
}
inline const bool isChar()const
{
return (edge_type & TChar) == TChar;
}
inline const bool isString()const
{
return (edge_type & TString) == TString;
}
const Edge_Type edgeType()const
{
if (isEpsilon()) return TEpsilon;
else if (isChar()) return TChar;
else if (isString()) return TString;
else return TUnknown;
}
};
有了以上两个结构之后,我们为Rule添加三个成员变量
EpsilonNFA_State *pEpsilonStart, *pEpsilonEnd;
hashmap<EpsilonNFA_State*, vector<EpsilonNFA_Edge>, _hash> epsilonNFA_Edges;
pEpsilonStart和pEpsilonEnd分别表示这条表达式所对应状态机的start和end状态,epsilonNFA_Edges则是以某个状态作为key,从这个状态到达另一个状态所经过的边作为value的hash表。
生成状态机
终于到了正题,首先,我们把所有的关系分为串联关系、并联关系、可选关系、0次及以上的重复关系、至少1次以上的重复关系和取反关系。下面分别介绍每种关系的ε-NFA如何来生成。(下文中若没有指出连接边的类型则是ε边)
字符集
正如上文所说,字符集包括Char_Type和String_Type类型的字符,应此生成字符集的状态机就比较简单了,只需创建出两个状态,然后通过一条经过这个字符集的边将这两个状态按照某个方向连接,最后将一个状态标记为start状态,另一个状态标记为end状态即可。
Rule(const Char_Type& x, Context& context) : pDFAStart(NULL), context(context)
{
pEpsilonStart = EpsilonNFA_State_Alloc::allocate();
construct(pEpsilonStart);
pEpsilonEnd = EpsilonNFA_State_Alloc::allocate();
construct(pEpsilonEnd);
epsilonNFA_Edges[pEpsilonStart].push_back(EpsilonNFA_Edge(x, pEpsilonStart, pEpsilonEnd));
context.epsilonNFA_States.insert(pEpsilonStart);
context.epsilonNFA_States.insert(pEpsilonEnd);
}
Rule(const String_Type& x, Context& context) : pDFAStart(NULL), context(context)
{
pEpsilonStart = EpsilonNFA_State_Alloc::allocate();
construct(pEpsilonStart);
pEpsilonEnd = EpsilonNFA_State_Alloc::allocate();
construct(pEpsilonEnd);
epsilonNFA_Edges[pEpsilonStart].push_back(EpsilonNFA_Edge(x, pEpsilonStart, pEpsilonEnd));
context.epsilonNFA_States.insert(pEpsilonStart);
context.epsilonNFA_States.insert(pEpsilonEnd);
}
串联关系
串联关系中,只需要将前一个状态机的end状态通过ε边连接到另一个状态机的start状态,最后将前一个状态的start状态标记为新状态机的start状态,后一个状态机的end状态标记为新状态机的end状态即可。
self operator+(const self& x)
{
self a = cloneEpsilonNFA(*this), b = cloneEpsilonNFA(x);
copyEpsilonNFA_Edges(b, a);
a.epsilonNFA_Edges[a.pEpsilonEnd].push_back(EpsilonNFA_Edge(a.pEpsilonEnd, b.pEpsilonStart));
a.pEpsilonEnd = b.pEpsilonEnd;
return a;
}
并联关系
并联关系中,需要分别新建一个start和end状态做为新状态机的start和end状态,然后将新生成的start状态分别连接到原状态机的start状态,原状态机的end状态连接到新生成的end状态即可。
self operator|(const self& x)
{
self a = cloneEpsilonNFA(*this), b = cloneEpsilonNFA(x);
copyEpsilonNFA_Edges(b, a);
EpsilonNFA_State* _pStart = EpsilonNFA_State_Alloc::allocate();
construct(_pStart);
EpsilonNFA_State* _pEnd = EpsilonNFA_State_Alloc::allocate();
construct(_pEnd);
context.epsilonNFA_States.insert(_pStart);
context.epsilonNFA_States.insert(_pEnd);
a.epsilonNFA_Edges[_pStart].push_back(EpsilonNFA_Edge(_pStart, a.pEpsilonStart));
a.epsilonNFA_Edges[_pStart].push_back(EpsilonNFA_Edge(_pStart, b.pEpsilonStart));
a.epsilonNFA_Edges[a.pEpsilonEnd].push_back(EpsilonNFA_Edge(a.pEpsilonEnd, _pEnd));
a.epsilonNFA_Edges[b.pEpsilonEnd].push_back(EpsilonNFA_Edge(b.pEpsilonEnd, _pEnd));
a.pEpsilonStart = _pStart;
a.pEpsilonEnd = _pEnd;
return a;
}
重复关系
在正则表达式中存在形如(a)+和(a)*的两种重复关系,对于这两种重复关系,生成的状态机的区别仅在于end状态对于一次以上的重复,只需要给原状态机添加一条从end状态到start状态的ε边即可。而对于零次以上的重复,不光需要添加ε边,同时需要将新状态机的end状态标记为start状态,因为零次重复时不需要经过任意边既可被接受。
self operator*()
{
self a = cloneEpsilonNFA(*this);
a.epsilonNFA_Edges.insert(EpsilonNFA_Edge(a.pEpsilonEnd, a.pEpsilonStart));
a.pEpsilonEnd = a.pEpsilonStart;
return a;
}
self operator+()
{
self a = cloneEpsilonNFA(*this);
a.epsilonNFA_Edges[a.pEpsilonEnd].push_back(EpsilonNFA_Edge(a.pEpsilonEnd, a.pEpsilonStart));
return a;
}
上面这三种是最基本的生成方法,通过以上这三种生成方法已足够应付多数的表达式。
一些拓展
下面来看看一些拓展形式的状态机是如何生成的。
可选关系
在可选关系中,只需要给原状态机添加一条从start状态到end状态的ε边即可。由于ε-NFA只允许有一个start和end状态的关系,应此当条件不成立时从start状态就可直接通过ε边到达end状态。
inline self opt()
{
self a = cloneEpsilonNFA(*this);
a.epsilonNFA_Edges[a.pEpsilonStart].push_back(EpsilonNFA_Edge(a.pEpsilonStart, a.pEpsilonEnd));
return a;
}
取反关系
由于我们只处理Char_Type和String_Type类型的字符集,应此对于取反我们只需要将当前状态机内所有类型为TChar或TString类型的边取一下反即可(需要注意的是可能存在负负得正的情况,既取偶数次反等于没取反)
self operator!()
{
self a = cloneEpsilonNFA(*this);
for (typename hashmap<EpsilonNFA_State*, vector<EpsilonNFA_Edge>, _hash>::iterator i = a.epsilonNFA_Edges.begin(), m = a.epsilonNFA_Edges.end(); i != m; ++i)
{
for (typename vector<EpsilonNFA_Edge>::iterator j = i->second.begin(), n = i->second.end(); j != n; ++j)
{
if (j->isChar() || j->isString()) j->negate();
}
}
return a;
}
Char-Char关系
所谓的char-char关系就是正则表达式中的[a-z]表达式。其实这是一种并联关系的拓展,由两个原始状态机拓展到了N个,生成方法也类似。
self operator-(const self& x)
{
self a = cloneEpsilonNFA(*this);
if (epsilonNFA_Edges.size() == 1 && x.epsilonNFA_Edges.size() == 1 &&
epsilonNFA_Edges.begin()->second.size() == 1 && x.epsilonNFA_Edges.begin()->second.size() == 1 &&
epsilonNFA_Edges.begin()->second.begin()->edge_type == EpsilonNFA_Edge::TChar && x.epsilonNFA_Edges.begin()->second.begin()->edge_type == EpsilonNFA_Edge::TChar)
{
EpsilonNFA_State* _pStart = EpsilonNFA_State_Alloc::allocate();
construct(_pStart);
EpsilonNFA_State* _pEnd = EpsilonNFA_State_Alloc::allocate();
construct(_pEnd);
context.epsilonNFA_States.insert(_pStart);
context.epsilonNFA_States.insert(_pEnd);
a.epsilonNFA_Edges[_pStart].push_back(EpsilonNFA_Edge(_pStart, a.pEpsilonStart));
a.epsilonNFA_Edges[a.pEpsilonEnd].push_back(EpsilonNFA_Edge(a.pEpsilonEnd, _pEnd));
const Char_Type chStart = epsilonNFA_Edges.begin()->second.begin()->data.char_value;
const Char_Type chEnd = x.epsilonNFA_Edges.begin()->second.begin()->data.char_value;
for (Char_Type ch = chStart + 1; ch < chEnd; ++ch)
{
self y(ch, context);
copyEpsilonNFA_Edges(y, a);
a.epsilonNFA_Edges[_pStart].push_back(EpsilonNFA_Edge(_pStart, y.pEpsilonStart));
a.epsilonNFA_Edges[y.pEpsilonEnd].push_back(EpsilonNFA_Edge(y.pEpsilonEnd, _pEnd));
}
self b = cloneEpsilonNFA(x);
copyEpsilonNFA_Edges(b, a);
a.epsilonNFA_Edges[_pStart].push_back(EpsilonNFA_Edge(_pStart, b.pEpsilonStart));
a.epsilonNFA_Edges[b.pEpsilonEnd].push_back(EpsilonNFA_Edge(b.pEpsilonEnd, _pEnd));
a.pEpsilonStart = _pStart;
a.pEpsilonEnd = _pEnd;
}
else
{
throw error<string>("doesn't support", __FILE__, __LINE__);
}
return a;
}
尾声
让我们来编写一个函数来打印出整个生成后的状态机。
void printEpsilonNFA()
{
printf("-------- ε- NFA Start --------\n");
for (typename hashmap<EpsilonNFA_State*, vector<EpsilonNFA_Edge>, _hash>::const_iterator i = epsilonNFA_Edges.begin(), m = epsilonNFA_Edges.end(); i != m; ++i)
{
for (typename vector<EpsilonNFA_Edge>::const_iterator j = i->second.begin(), n = i->second.end(); j != n; ++j)
{
printf("%03d -> %03d", j->pFrom->idx, j->pTo->idx);
switch (j->edgeType())
{
case EpsilonNFA_Edge::TEpsilon:
printf("(ε)");
break;
case EpsilonNFA_Edge::TChar:
printf("(%c)", j->data.char_value);
break;
case EpsilonNFA_Edge::TString:
printf("(%s)", j->data.string_value.c_str());
break;
default:
break;
}
if (j->isNot()) printf("(not)");
printf("\n");
}
}
printf("start: %03d -> end: %03d\n", pEpsilonStart->idx, pEpsilonEnd->idx);
printf("--------- ε- NFA End ---------\n");
}
最后我们来编写一些测试代码来试试生成效果如何
Rule_Type::Context context;
Rule_Type a('a', context), b('b', context), d('d', context);
Rule_Type result = (a - d).opt() + (+b | !(a + b));
#ifdef _DEBUG
result.printEpsilonNFA();
#endif
可打印出如下内容

最后形成形如下图的状态机

完整的代码可到http://code.google.com/p/qlanguage下载。
posted @
2013-02-15 20:29 lwch 阅读(3016) |
评论 (3) |
编辑 收藏
2013年1月19日
在
上一篇中我们已经实现了一个简单的内存池,可以申请更大块的内存块来减少申请小块内存块时产生的内存碎片。
在本篇中,我们需要为其加入内存泄漏的检测代码,以此来检测代码编写过程中的疏忽带来的内存泄漏。(callstack的显示暂时仅支持Windows)
一、内存泄漏检测
首先,改写obj和block结构,在obj中加入一个域released表示这个chunk是否被释放
1 struct obj
2 {
3 #ifdef _DEBUG
4 bool released;
5
6 #if defined(WIN32) && !defined(__MINGW32__) && !defined(__CYGWIN__) // Only windows can get callstack
7 #define CALLSTACK_MAX_DEPTH 30
8 UINT_PTR callStack[CALLSTACK_MAX_DEPTH];
9 DWORD dwCallStackDepth; // Real depth
10 #endif
11
12 #endif
13 obj* next;
14 };
15
16 struct block
17 {
18 block* next;
19 void* data;
20 #ifdef _DEBUG
21 size_type size;
22 #if defined(WIN32) && !defined(__MINGW32__) && !defined(__CYGWIN__)
23 UINT_PTR callStack[CALLSTACK_MAX_DEPTH];
24 DWORD dwCallStackDepth;
25 #endif
26 #endif
27 };
其中的callstack部分将在下一节中介绍
然后,我们增加一个结构
1 #ifdef _DEBUG
2 struct use
3 {
4 obj* data;
5 use* next;
6 };
7 #endif
其中data域指向了一块分配出去的小内存块,next域形成了一张链表。
然后,我们添加一个成员变量来保存这张链表,以及一个函数来将一个chunk插入这张链表
#ifdef _DEBUG
use* use_list;
#endif
#ifdef _DEBUG
inline void MemoryPool::addUseInfo(obj* ptr)
{
use* p = (use*)malloc(sizeof(use));
p->data = ptr;
p->next = use_list;
use_list = p;
}
#endif
然后,我们来改写refill函数使其在分配内存块时打上released标记,并将每个分配的内存块记录下来
1 void* MemoryPool::refill(int i, void(*h)(size_type))
2 {
3 const int count = 20;
4 const int preSize = (i + 1) * ALIGN + headerSize;
5 char* p = (char*)malloc(preSize * count);
6 while(p == 0)
7 {
8 h(preSize * count);
9 p = (char*)malloc(preSize * count);
10 }
11 block* pBlock = (block*)malloc(sizeof(block));
12 while(pBlock == 0)
13 {
14 h(sizeof(block));
15 pBlock = (block*)malloc(sizeof(block));
16 }
17 pBlock->data = p;
18 pBlock->next = free_list;
19 free_list = pBlock;
20
21 obj* current = (obj*)p;
22 #ifdef _DEBUG
23 addUseInfo(current);
24 current->released = false;
25 #endif
26 current = (obj*)((char*)current + preSize);
27 for(int j = 0; j < count - 1; ++j)
28 {
29 #ifdef _DEBUG
30 addUseInfo(current);
31 current->released = true;
32 #endif
33 current->next = chunk_list[i];
34 chunk_list[i] = current;
35 current = (obj*)((char*)current + preSize);
36 }
37 return (char*)p + headerSize;
38 }
其中的headerSize跟callstack有关,将在下一节中介绍。
当然,在deallocate时要将此内存块的released标记打为true
1 void MemoryPool::deallocate(void* p, size_type n)
2 {
3 if(p == 0) return;
4 if(n > MAX_BYTES)
5 {
6 free(p);
7 return;
8 }
9 const int i = INDEX(ROUND_UP(n));
10 #ifdef _DEBUG
11 p = (char*)p - (int)headerSize;
12 obj* ptr = reinterpret_cast<obj*>(p);
13 if (ptr->released) throw error<char*>("chunk has already released", __FILE__, __LINE__);
14 ptr->released = true;
15 #endif
16 reinterpret_cast<obj*>(p)->next = chunk_list[i];
17 chunk_list[i] = reinterpret_cast<obj*>(p);
18 }
OK,现在已经有模有样了,可以松口气了。接下来是最重要的部分,在MemoryPool析构时检测这个Pool内的use_list中是否有chunk的released标记为true(内存泄漏了)
1 MemoryPool::~MemoryPool()
2 {
3 #ifdef _DEBUG
4 while (use_list)
5 {
6 use *ptr = use_list, *next = use_list->next;
7 if (!ptr->data->released)
8 {
9 obj* pObj = ptr->data;
10 Console::SetColor(true, false, false, true);
11 throw error<char*>("chunk leaked", __FILE__, __LINE__);
12 }
13 free(ptr);
14 use_list = next;
15 }
16 #endif
17 clear();
18 }
其实说来也容易,只需要检测每个chunk的released标记是否为true就行了,而最后的clear函数是以前析构函数的代码,用来释放所有申请的block和大块的chunk。
OK,现在我们已经可以检测出没有被deallocate的chunk了。
二、callstack
首先,我们先来看一个Windows API,“
CaptureStackBackTrace”这个API通过传入的一个数组来得到一组地址。当然有这个API并不够,我们还需要知道是哪个文件的第几行。“
SymGetSymFromAddr64”这个API用来获取某个地址对应的函数名,“
SymGetLineFromAddr64”这个API则是用来获取某个地址对应的文件名和行号的,这两个函数的32位版本则是不带64的。有了这些Windows API,我们就可以很轻松的获取到当前函数的调用堆栈了,主要的功劳还是要归功于Windows强大的dbghelp。
最后,完整的代码你可以在
http://code.google.com/p/qlanguage/中找到。
posted @
2013-01-19 20:09 lwch 阅读(2024) |
评论 (0) |
编辑 收藏
2012年8月25日
template <typename T1, typename T2>
inline const bool compare_type(T1, T2)
{
return false;
}
template <>
inline const bool compare_type(int, int)
{
return true;
}
template <>
inline const bool compare_type(float, float)
{
return true;
}
template <>
inline const bool compare_type(double, double)
{
return true;
}
template <>
inline const bool compare_type(char, char)
{
return true;
}
template <>
inline const bool compare_type(wchar_t, wchar_t)
{
return true;
}
template <typename T1, typename T2>
inline const bool compare_type(T1*, T2*)
{
return compare_type(T1(), T2());
}
template <typename T1, typename T2>
inline const bool compare_type(const T1*, const T2*)
{
return compare_type(T1(), T2());
}
template <typename T1, typename T2>
inline const bool compare_type(const T1*, T2*)
{
return false;
}
template <typename T1, typename T2>
inline const bool compare_type(T1*, const T2*)
{
return false;
}
通过特例化,我们可以很轻松的查看两个变量的类型是否相同。
posted @
2012-08-25 16:13 lwch 阅读(1218) |
评论 (0) |
编辑 收藏
2012年8月9日
在STL中list是以双向链表的方式来存储的,应此使用给定的下标值来找到对应的节点所需的时间复杂度为O(n),相比vector直接使用原生指针会慢一些。
因为是双向链表的关系,那么必然有一种结构来表示链表中的节点。
template <typename T>
struct __list_node
{
__list_node<T>* prev;
__list_node<T>* next;
T data;
__list_node() : prev(NULL), next(NULL)
{
}
__list_node(const T& x) : prev(NULL), next(NULL), data(x)
{
}
};
然后我们定义出其iterator和const_iterator的结构
template <typename T>
struct __list_iterator
{
typedef __list_iterator<T> iterator;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
typedef const T* const_pointer;
typedef const T& const_reference;
typedef __list_node<T>* link_type;
typedef void* void_pointer;
link_type node;
__list_iterator(link_type x) : node(x)
{
}
__list_iterator(const __list_const_iterator<T>& x) : node(x.node)
{
}
__list_iterator() : node(NULL)
{
}
inline iterator& operator++()
{
node = ((link_type)node)->next;
return *this;
}
inline iterator operator++(int)
{
iterator tmp = *this;
++*this;
return tmp;
}
inline iterator& operator--()
{
node = ((link_type)node)->prev;
return *this;
}
inline iterator operator--(int)
{
iterator tmp = *this;
--*this;
return tmp;
}
inline reference operator*()const
{
return node->data;
}
inline bool operator==(const iterator& x)const
{
return node == x.node;
}
inline bool operator!=(const iterator& x)const
{
return node != x.node;
}
};
由于const_iterator与iterator的结构类似,这里不再贴出。其中重载了++与--运算符,实际上就是节点的前后移动。
然后看一下list的定义
template <typename T>
class list
{
}
让我们来看看list中的别名
public:
typedef T value_type;
typedef T* pointer;
typedef __list_iterator<T> iterator;
typedef __list_const_iterator<T> const_iterator;
typedef T& reference;
typedef const T& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef reverse_iterator<const_iterator, value_type, size_type, difference_type> const_reverse_iterator;
typedef reverse_iterator<iterator, value_type, size_type, difference_type> reverse_iterator;
下面是其内部的成员变量
protected:
typedef __list_node<T>* link_type;
typedef list<T> self;
typedef allocator<__list_node<T> > Node_Alloc;
link_type node;
size_type length;
在STL中从begin到end总是以一个前闭后开的形式来表示的,应此我们给出一个node节点来表示end所指位置,而node节点的前驱则是这个list的起始节点,而length则存储了这个list的元素数量。
下面来看看list中最基本的构造函数和析构函数
list() : length(0)
{
node = Node_Alloc::allocate();
node->next = node;
node->prev = node;
}
~list()
{
clear();
Node_Alloc::deallocate(node);
}
在list对象构造之初,首先构造出node节点,使其的前驱和后继都指向其本身,应此通过begin和end拿出的迭代器为同一个。在list对象析构时,首先将这个list清空,然后将构造出的node节点释放掉。
然后是其begin和end方法,用来获取第一个元素和最后一个元素的后一个元素的迭代器
inline iterator begin()
{
return node->next;
}
inline const_iterator begin()const
{
return node->next;
}
inline iterator end()
{
return node;
}
inline const_iterator end()const
{
return node;
}
front和back分别被用来获取第一个元素和最后一个元素
inline reference front()
{
return *begin();
}
inline const_reference front()const
{
return *begin();
}
inline reference back()
{
return *end();
}
inline const_reference back()const
{
return *end();
}
empty、size分别被用来判别容器是否为空、获取容器内元素的个数
inline bool empty()const
{
return length == 0;
}
inline size_type size()const
{
return length;
}
list与vector不同的是list是双向的,应此它允许从头尾两个方向来插入和删除元素
inline void push_front(const T& x)
{
insert(begin(), x);
}
inline void push_back(const T& x)
{
insert(end(), x);
}
inline void pop_front()
{
erase(begin());
}
inline void pop_back()
{
erase(--end());
}
然后我们来看一下push的本质,insert函数
iterator insert(const iterator& position, const T& x)
{
if(!inRange(position)) throw "out of range";
link_type tmp = Node_Alloc::allocate();
construct(tmp, x);
tmp->prev = position.node->prev;
tmp->next = position.node;
position.node->prev->next = tmp;
position.node->prev = tmp;
++length;
return tmp;
}
这里首先会检查这个迭代器是否属于这个list,然后构造出一个新节点,并把它插入到这个迭代器的前面,最后将节点数+1。
然后是其删除节点函数erase
void erase(const iterator& position)
{
if(!inRange(position)) throw "out of range";
position.node->prev->next = position.node->next;
position.node->next->prev = position.node->prev;
destruct(&position.node->data, has_destruct(position.node->data));
Node_Alloc::deallocate(position.node);
--length;
}
这里同样会检查这个迭代器是否属于这个list,然后将这个节点移除,最后析构并释放内存空间。
最后让我们来看一下list中重载的运算符
self& operator=(const self& x)
{
if(this == &x) return *this;
iterator first1 = begin();
iterator last1 = end();
const_iterator first2 = x.begin();
const_iterator last2 = x.end();
while (first1 != last1 && first2 != last2) *first1++ = *first2++;
if (first2 == last2) erase(first1, last1);
else insert(last1, first2, last2);
return *this;
}
reference operator[](size_type n)
{
if(n < 0 || n >= length) throw "out of range";
link_type current = NULL;
if(n < length / 2)
{
current = node->next;
for(size_type i = 0; i < n; i++, current = current->next);
}
else
{
n = length - n - 1;
current = node->prev;
for(size_type i = 0; i < n; i++, current = current->prev);
}
return current->data;
}
inline value_type at(size_type n)
{
return operator[](n);
}
因为其内部使用的是双向链表,应此通过指定下标来获取这个元素是可分别从两头进行移动指针。
至此,list的讲解已完成,完整代码请到
http://qlanguage.codeplex.com下载
posted @
2012-08-09 21:17 lwch 阅读(1938) |
评论 (0) |
编辑 收藏
2012年7月14日
内存池的作用:
减少内存碎片,提高性能。
首先不得不提的是Win32和x64中对于指针的长度是不同的,
在Win32中一个指针占4字节,而在x64中一个指针占8字节。也正是不清楚这一点,当我在x64中将指针作为4字节修改造成其他数据异常。
首先我们先来定义三个宏
#define ALIGN sizeof(void*)
#define MAX_BYTES 128
#define MAX_COUNT (MAX_BYTES / ALIGN)
正如前面所说的,为了兼容Win32与x64应此我们将要申请的内存按void*的大小来对齐。正如前面所说的,我们认为小于128字节的内存为小内存,会产生内存碎片,应此在申请时应该劲量申请一块较大的内存而将其中的一小块分配给他。
然后让我们来看一下内存池中的成员变量
struct obj
{
obj* next;
};
struct block
{
block* next;
void* data;
};
obj* chunk_list[MAX_COUNT];
size_t chunk_count;
block* free_list;
这里使用obj结构来存储已释放内存的列表,这样做的好处是可以更节省内存。在Win32中使用这块内存的前4字节来指向下一个节点,而在x64中使用这块内存的前8字节来指向下一个节点。
chunk_list:保存通过deallocate或refill中释放或是新申请的内存块列表,deallocate和refill将会在下文中介绍。
chunk_count:内存块列表中已有的内存块数量。
free_list:保存了通过malloc申请内存块的链表。
下面我们来看一下内存池的构造函数与析构函数
MemoryPool() : free_list(0), chunk_count(0)
{
for(int i = 0; i < MAX_COUNT; ++i) chunk_list[i] = 0;
}
~MemoryPool()
{
block* current = free_list;
while(current)
{
block* next = current->next;
free(current->data);
free(current);
current = next;
}
}
构造函数中初始化free_list和chunk_count为0,并初始化chunk_list为一个空列表。而在析构函数中我们必须释放每一块通过malloc申请的大内存块。
接下来是内存的申请
template <typename T>
T* allocate(size_t n, void(*h)(size_t))
{
if(n == 0) return 0;
if(n > MAX_BYTES)
{
T* p = (T*)malloc(n);
while(p == 0)
{
h(n);
p = (T*)malloc(n);
}
return p;
}
const int i = INDEX(ROUND_UP(n));
obj* p = chunk_list[i];
if(p == 0)
{
return refill<T>(i, h);
}
chunk_list[i] = p->next;
return reinterpret_cast<T*>(p);
}
值得注意的是,在调用时必须传入一个函数指针作为参数,当malloc申请内存失败时会去调用这个函数来释放出足够多的内存空间。当要申请的内存大小超过128字节时,调用默认的malloc为其申请内存。否则先查找列表中是否还有足够的空间分配给它,若已没有足够的空间分配给它,则调用refill申请一块大内存。
然后是内存释放函数deallocate
template <typename T>
void deallocate(T* p, size_t n)
{
if(p == 0) return;
if(n > MAX_BYTES)
{
free(p);
return;
}
const int i = INDEX(ROUND_UP(n));
reinterpret_cast<obj*>(p)->next = chunk_list[i];
chunk_list[i] = reinterpret_cast<obj*>(p);
}
值得注意的是在释放时必须给出这块内存块的大小。若这块内存大于128字节时,调用默认的free函数释放掉这块内存。否则将其加到对应的chunk_list列表内。
然后是调整内存块大小函数reallocate
template <typename T>
T* reallocate(T* p, size_t old_size, size_t new_size, void(*h)(size_t))
{
if(old_size > MAX_BYTES && new_size > MAX_BYTES)
{
return realloc(p, new_size);
}
if(ROUND_UP(old_size) == ROUND_UP(new_size)) return p;
T* result = allocate<T>(new_size, h);
const size_t copy_size = new_size > old_size ? old_size : new_size;
memcpy(result, p, copy_size);
deallocate<T>(p, old_size);
return result;
}
参数中必须给出这块内存的原始大小和要调整后的大小,同时也必须给出当内存不足时的释放函数的指针。若旧内存块和新内存块的大小都大于128字节时,调用默认的realloc函数重新分配内存。否则先按调整后的大小申请一块内存,并把原来的内容拷贝过来,最后释放掉原来的内存块。这里并不建议使用这个函数,而是手动的去重新申请内存并拷贝释放。
然后来看4个非常简单的计算函数
inline size_t ROUND_UP(size_t bytes)const
{
return (bytes + ALIGN - 1) & ~(ALIGN - 1);
}
inline size_t ROUND_DOWN(size_t bytes)const
{
return bytes & ~(ALIGN - 1);
}
inline int INDEX(size_t bytes)const
{
return (bytes + ALIGN - 1) / ALIGN - 1;
}
inline size_t obj_count(int i)const
{
size_t result = 0;
obj* current = chunk_list[i];
while(current)
{
++result;
current = current->next;
}
return result;
}
前3个用于内存对齐和计算索引,最后一个用于获取一在空闲列表内一个内存块的数量。
然后是refill函数,用于在没有空闲内存块时申请一块大内存块
template <typename T>
T* refill(int i, void(*h)(size_t))
{
const int count = 20;
const int preSize = (i + 1) * ALIGN;
char* p = (char*)malloc(preSize * count);
while(p == 0)
{
h(preSize * count);
p = (char*)malloc(preSize * count);
}
block* pBlock = (block*)malloc(sizeof(block));
while(pBlock == 0)
{
h(sizeof(block));
pBlock = (block*)malloc(sizeof(block));
}
pBlock->data = p;
pBlock->next = free_list;
free_list = pBlock;
obj* current = (obj*)(p + preSize);
for(int j = 0; j < count - 1; ++j)
{
current->next = chunk_list[i];
chunk_list[i] = current;
current = (obj*)((char*)current + preSize);
}
chunk_count += count - 1;
rebalance();
return reinterpret_cast<T*>(p);
}
首先申请一个大内存块,然后将这块申请到的内存块放入free_list链表内,最后组织起chunk_list中对应内存卡块的链表,然后重新调整chunk_list列表,最后将申请到的内存块返回。
最后来看一下调整函数rebalance
void rebalance()
{
for(int i = MAX_COUNT - 1; i > 0; --i)
{
const size_t avge = chunk_count / MAX_COUNT;
size_t count = obj_count(i);
if(count > avge)
{
const int preSize = ROUND_DOWN((i + 1) * ALIGN / 2);
const int j = INDEX(preSize);
for(int k = count; k > avge; --k)
{
obj* chunk = chunk_list[i];
chunk_list[i] = chunk_list[i]->next;
if(i % 2 == 1)
{
chunk->next = (obj*)((char*)chunk + preSize);
chunk->next->next = chunk_list[j];
chunk_list[j] = chunk;
}
else
{
chunk->next = chunk_list[j];
chunk_list[j] = chunk;
obj* next = (obj*)((char*)chunk + preSize);
next->next = chunk_list[j + 1];
chunk_list[j + 1] = next;
}
++chunk_count;
}
}
}
}
这里从后至前查看对应内存块空闲链表的长度,若超过平均数量,则将其切分为2块较小的内存块放入对应的链表内。这样做的好处是可以形成一个金字塔形的分布状况,既越小的内存块大小拥有的节点数量越多,正如本文开头所说,使用内存池是为了解决在申请小块内存时造成的内存碎片。
至此,内存池的讲解已完成,完整的代码请到
http://qlanguage.codeplex.com下载
posted @
2012-07-14 18:40 lwch 阅读(2490) |
评论 (1) |
编辑 收藏
2012年6月17日
首先是vector的定义
template <typename T>
class vector
{
};
让我们先来看看vector中的一些别名
public:
typedef T value_type;
typedef T* pointer;
typedef T& reference;
typedef const T& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef const T* const_iterator;
typedef reverse_iterator<const_iterator, value_type, size_type, difference_type> const_reverse_iterator;
typedef T* iterator;
typedef reverse_iterator<iterator, value_type, size_type, difference_type> reverse_iterator;
由上可见,正如
上一篇所说,vector的迭代器是由原生的指针来实现的。
下面是其内部的成员变量
protected:
typedef vector<T> self;
typedef allocator<T> Alloc;
iterator start;
iterator finish;
iterator end_of_element;
start:指向vector的起始地址
finish:指向最后一个元素的后一个元素的地址
end_of_element:指向已申请内存块的结束位置(finish总是小于或等于end_of_element)
在STL中从begin到end总是以一个前闭后开的形式来表示的,形如[begin,end),这样做的好处是可以使代码写的更简洁:
template <typename Iterator, typename T>
Iterator find(Iterator first, Iterator last, const T& value)
{
while(first != last && *first != value) ++first;
return first;
}
下面来看看vector中最基本的构造函数和析构函数
vector() : start(0), finish(0), end_of_element(0)
{
}
~vector()
{
destruct(start, end_of_element);
if (start != 0) Alloc::deallocate(start, end_of_element - start);
}
这里将其中的3个成员变量都填充为0。
如
上一篇所说,在STL中是将内存分配与对象初始化分开的,同样对象析构与内存释放也是被分开的。
然后是其begin和end方法,用来获取第一个元素和最后一个元素的后一个元素的迭代器。
inline iterator begin()
{
return start;
}
inline const_iterator begin()const
{
return start;
}
inline iterator end()
{
return finish;
}
inline const_iterator end()const
{
return finish;
}
front和back分别被用来获取第一个元素和最后一个元素
inline reference front()
{
return *begin();
}
inline const_reference front()const
{
return *begin();
}
inline reference back()
{
return *(end() - 1);
}
inline const_reference back()const
{
return *(end() - 1);
}
empty、size、capacity分别被用来判别容器是否为空、容器内元素的个数和容器的大小
inline bool empty()const
{
return begin() == end();
}
inline const size_type size()const
{
return size_type(end() - begin());
}
inline const size_type capacity()const
{
return size_type(end_of_element - begin());
}
由于在vector的头部插入元素会使所有元素后移,应此它被设计为单向的,只能由尾部插入或移除数据
void push_back(const T& x)
{
if (end_of_element != finish)
{
construct(&*finish, x);
++finish;
}
else
{
insert_aux(end(), x);
}
}
inline void pop_back()
{
--finish;
destruct<T>(finish, has_destruct(*finish));
}
当然从头部移除数据也并非不可以,可以使用erase方法来移除头部的数据,erase方法将会在后面的部分作出说明。
我们先来看一下insert_aux这个方法,在插入元素时几乎都使用到了这个方法。
void insert_aux(const iterator position, const T& x)
{
if(finish != end_of_element)
{
construct(&*finish, *(finish - 1));
T x_copy = x;
copy_backward(position, finish - 1, finish);
*position = x_copy;
++finish;
}
else
{
const size_type old_size = size();
const size_type new_size = old_size == 0 ? 2 : old_size * 2;
iterator tmp = Alloc::allocate(new_size);
uninitialized_copy(begin(), position, tmp);
iterator new_position = tmp + (position - begin());
construct(&*new_position, x);
uninitialized_copy(position, end(), new_position + 1);
destruct(begin(), end());
Alloc::deallocate(begin(), old_size);
end_of_element = tmp + new_size;
finish = tmp + old_size + 1;
start = tmp;
}
}
在容器还有足够的空间时,首先将从position位置到finish位置的元素整体后移一个位置,最后将要被插入的元素写入到原position的位置同时改变finish指针的值。
若空间不足时,首先根据原有空间的大小的一倍来申请内存,然后将元素从原有位置的begin到position拷贝到新申请的内存中,然后在新申请内存的指定位置插入要插入的元素值,最后将余下的部分也拷贝过来。然后将原有元素析构掉并把内存释放掉。
为何不使用reallocate?
reallocate的本意并不是在原有内存的位置增加或减少内存,reallocate首先会试图在原有的内存位置增加或减少内存,
若失败则会重新申请一块新的内存并把原有的数据拷贝过去,这种操作本质上等价于重新申请一块内存,应此这里使用的是allocate而并非reallocate。
然后让我们来看一下insert和erase方法
inline iterator insert(iterator position, const T& x)
{
const size_type pos = position - begin();
if(finish != end_of_element && position == end())
{
construct(&*finish, x);
++finish;
}
else insert_aux(position, x);
return begin() + pos;
}
iterator erase(iterator position)
{
destruct(position, has_destruct(*position));
if (position + 1 != end())
{
copy(position + 1, end(), position);
}
--finish;
return position;
}
若是要在最后插入一个元素且容器的剩余空间还足够的话,直接将元素插入到finish的位置,并将finish指针后移一位即可。若容器空间不够或不是插在最后一个的位置,则调用insert_aux重新分配内存或插入。
删除时首先析构掉原有元素,若被删元素不是最后一个元素,则将后面的所有元素拷贝过来,最后将finish指针前移一个位置。
最后让我们来看一下其中重载的运算符
self& operator=(const self& x)
{
if(&x == this) return *this;
size_type const other_size = x.size();
if(other_size > capacity())
{
destruct(start, finish);
Alloc::deallocate(start, capacity());
start = Alloc::allocate(other_size);
finish = uninitialized_copy(x.begin(), x.end(), start);
end_of_element = start + other_size;
}
else
{
finish = uninitialized_copy(x.begin(), x.end(), start);
}
return *this;
}
inline reference operator[](size_type n)
{
return *(begin() + n);
}
inline value_type at(size_type n)
{
return *(begin() + n);
}
由于vector内部用的是原生的指针,应此这些运算符的使用方式和原生指针的并无差异。
值得注意的是在做赋值操作时会产生内存的重新分配与拷贝操作。
至此,vector的讲解已完成,完整的代码请到
http://qlanguage.codeplex.com下载
posted @
2012-06-17 17:08 lwch 阅读(3675) |
评论 (3) |
编辑 收藏
2012年6月2日
traits技术被广泛应用于STL中,通过它您可以轻松的萃取出一个对象的特性。在STL中也是通过它来实现性能的最优化,比如一个对象是个POD对象(Plain Old Data),则在拷贝过程中直接可以通过memcpy等函数拷贝,而无需调用拷贝构造函数或operator=。
先来看看STL中最基本的对象iterator
template <typename T, typename Size = size_t, typename Difference = ptrdiff_t>
struct iterator
{
typedef T value_type;
typedef Difference difference_type;
typedef T* pointer;
typedef T& reference;
typedef const T* const_pointer;
typedef const T& const_reference;
typedef iterator<T, Size, Difference> self;
};
template <typename T, typename Size = size_t, typename Difference = ptrdiff_t>
struct const_iterator : public iterator<T>
{
};
由以上代码可知,对于每一个iterator必须定义其value_type,size_type,difference_type,pointer,reference,const_pointer,const_reference和self类型。
一、value_type
value_type指示了该迭代器所保存的值类型
二、difference_type
difference_type用来指示两个迭代器之间的距离类型
三、pointer,reference,const_pointer,const_reference
分别是所指之物的指针,引用,指针常量和引用常量的类型
四、self
self为该迭代器自身的类型
下面来看一下iterator_traits,iterator_traits主要用来萃取迭代器iterator的值类型等
template <typename Iterator>
struct iterator_traits
{
typedef typename Iterator::value_type value_type;
typedef typename Iterator::difference_type difference_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
typedef typename Iterator::const_pointer const_pointer;
typedef typename Iterator::const_reference const_reference;
typedef typename Iterator::self self_type;
};
这里有一点可以提前预告一下,vector作为一个容器,其内部是使用指针作为迭代器的,那么我们如何萃取出它的值类型等呢?
答案很简单,特例化,那么我们就来为iterator_traits分别做两种T*和const T*的特例化
template <typename T>
struct iterator_traits<T*>
{
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
typedef const T* const_pointer;
typedef const T& const_reference;
typedef T* self_type;
};
template <typename T>
struct iterator_traits<const T*>
{
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
typedef const T* const_pointer;
typedef const T& const_reference;
typedef const T* self_type;
};
至此,我们可以用iterator_traits萃取出每种iterator的值类型等内容了。
之前已经说到了,通过traits可以萃取出一些对象的特性,从而提高代码的效率。事实确实如此,通过traits可萃取出一个对象是否是一个POD对象,对于一个POD对象,我们在拷贝时,不应该使用其拷贝构造函数或是operator=,而用memcpy则效率更高。
下面我们来看一下__type_traits
struct __true_type
{
};
struct __false_type
{
};
template <typename I>
struct __type_traits
{
typedef __false_type has_default_construct;
typedef __false_type has_copy_construct;
typedef __false_type has_assign_operator;
typedef __false_type has_destruct;
typedef __false_type is_POD;
};
不得不提的是其中分别用__true_type和__false_type来表示是否存在这个特性。
那么我们如何萃取出基础类型诸如int,char等的特性呢?
答案依然是特例化,这里代码不再贴出,文末会给出完整代码的详细地址。
最后我们使用一个hash_destruct的函数来获取出这个类型是否有析构函数。
template <typename T>
inline auto has_destruct(const T&)->decltype(static_cast<__type_traits<T>::has_destruct*>(0))
{
return static_cast<typename __type_traits<T>::has_destruct*>(0);
}
template <typename T>
inline auto has_destruct(T*)->decltype(static_cast<__type_traits<T>::has_destruct*>(0))
{
static_assert(false, "Please use const T& not T*");
return static_cast<typename __type_traits<T>::has_destruct*>(0);
}
template <typename T>
inline auto has_destruct(const T*)->decltype(static_cast<__type_traits<T>::has_destruct*>(0))
{
static_assert(false, "Please use const T& not const T*");
return static_cast<typename __type_traits<T>::has_destruct*>(0);
}
不得不提的是C++0x的确很强大,可以通过形参来确定返回值的类型,这样我们就可以萃取出这个类型的has_destruct域是__true_type或是__false_type了。
最后来看看construct和destruct的代码,在STL中对象的内存分配和构造是被分开的,对于基础对象int,char等,在析构时我们无需调用其析构函数。
下面来看construct和destruct的实现
template <typename T1, typename T2>
inline void construct(T1* p, const T2& value)
{
new (p) T1(value);
}
template <typename T>
inline void destruct(T* p, __true_type*)
{
p->~T();
}
template <typename T>
inline void destruct(T*, __false_type*)
{
}
template <typename ForwardIterator>
inline void destruct(ForwardIterator first, ForwardIterator last)
{
while(first != last)
{
destruct(first, has_destruct(*first));
++first;
}
}
至此,关于traits技术和construct及destruct的讲解已完成,完整的代码请到
http://qlanguage.codeplex.com/下载
posted @
2012-06-02 22:39 lwch 阅读(2689) |
评论 (3) |
编辑 收藏