接
上一篇,首先需要修正的是在DFA生成算法中的传播部分,应该需要有个循环一直传播到不能传播为止,在多次实验中表明,有些展望符是通过第2,3,4甚至更多次传播得来的。
应此,相应的make函数变成了
bool LALR1::make()
{
vector<LALR1Production> v;
v.push_back(inputProductions[begin][0]);
pStart = closure(v);
pStart->idx = Item::inc();
context.states.insert(pStart);
items.push_back(pStart);
queue<Item*> q;
q.push(pStart);
vector<Item*> changes;
bool bContinue = false;
while (!q.empty())
{
Item* pItem = q.front();
vector<Production::Item> s;
symbols(pItem, s);
select_into(s, vts, compare_production_item_is_vt, push_back_unique_vector<Production::Item>);
select_into(s, vns, compare_production_item_is_vn, push_back_unique_vector<Production::Item>);
for (vector<Production::Item>::const_iterator i = s.begin(), m = s.end(); i != m; ++i)
{
Item* pNewItem = NULL;
if (go(pItem, *i, pNewItem))
{
long n = itemIndex(pNewItem);
if (n == -1)
{
pNewItem->idx = Item::inc();
q.push(pNewItem);
items.push_back(pNewItem);
context.states.insert(pNewItem);
}
else
{
items[n]->mergeWildCards(pNewItem, bContinue);
changes.push_back_unique(items[n]);
destruct(pNewItem, has_destruct(*pNewItem));
Item_Alloc::deallocate(pNewItem);
}
edges[pItem].push_back_unique(Edge(pItem, n == -1 ? pNewItem : items[n], *i));
}
}
q.pop();
}
while (bContinue)
{
vector<Item*> v;
v.reserve(changes.size());
bContinue = false;
for (vector<Item*>::const_iterator i = changes.begin(), m = changes.end(); i != m; ++i)
{
vector<Production::Item> s;
symbols(*i, s);
for (vector<Production::Item>::const_iterator j = s.begin(), n = s.end(); j != n; ++j)
{
Item* pNewItem = NULL;
if (go(*i, *j, pNewItem))
{
long n = itemIndex(pNewItem);
if (n == -1) throw error<const char*>("unknown item", __FILE__, __LINE__);
else
{
items[n]->mergeWildCards(pNewItem, bContinue);
v.push_back_unique(items[n]);
destruct(pNewItem, has_destruct(*pNewItem));
Item_Alloc::deallocate(pNewItem);
}
}
}
}
changes = v;
}
}
在merge函数中,会检测有没有新生成的展望符来决定是否继续传播下去。
一个示例
下面我们用一个例子来说明LALR1 DFA是如何生成的,首先它的文法如下
S -> L "=" R
| R "+"
| R
;
L -> "*" R
| "id"
;
R -> L
;
根据之前的算法,我们先来看自生的部分
首先我们写出这个文法的增广文法
begin -> . S (#)
求取它的闭包得到
begin -> . S
wildCards:
#
S -> . L "=" R
wildCards:
#
S -> . R "+"
wildCards:
#
S -> . R
wildCards:
#
L -> . "*" R
wildCards:
"=" "+"
L -> . "id"
wildCards:
"=" "+"
R -> . L
wildCards:
"+" #
我们观察到,其中有5个可转移的符号,分别为S、L、R、"*"和"id",我们分别用go函数对这5个转移符号求出新的状态
首先用符号S求出新状态
begin -> S
wildCards:
#
由于这个状态不在原有列表中,应此它是一个新生成的状态,我们为它添加一条通过符号S转移的边。
接下来用符号L求出新状态
S -> L . "=" R
wildCards:
#
R -> L
wildCards:
"+" #
这个状态也不在原有列表中,应此它也是一个新生成的状态,我们为它添加一条通过符号L转移的边。
然后用符号R求出新状态
S -> R . "+"
wildCards:
#
S -> R
wildCards:
#
这个状态也不在原有列表中,应此它也是一个新生成的状态,我们为它添加一条通过符号R转移的边。
然后用符号*求出新的状态
L -> "*" . R
wildCards:
"=" "+"
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
同样的它也不在原有的列表中,我们同样为其添加一条通过符号*转移的边。
然后是符号id的
L -> "id"
wildCards:
"=" "+"
同样不在列表中,我们为其添加一条通过符号id转移的边。
这样,从start状态转移出来的5条边就生成好了,下面来看看这5个新生成的状态又会生成一些什么呢
begin -> S
wildCards:
#
由第一个状态可知,它没有任何的边。
S -> L . "=" R
wildCards:
#
R -> L
wildCards:
"+" #
第二个状态则有一个=的转移,它生成了一个新状态
S -> L "=" . R
wildCards:
#
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
S -> R . "+"
wildCards:
#
S -> R
wildCards:
#
第三个状态有一个+的转移,它生成了一个新状态
S -> R "+"
wildCards:
#
L -> "*" . R
wildCards:
"=" "+"
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
第四个状态有4个转移,分别为R、L、*和id
1.通过符号R转移到新状态
L -> "*" R
wildCards:
"=" "+"
2.通过符号L转移到新状态
R -> L
wildCards:
"+" # "="
3.通过*则可转移到它自己
4.通过id转移到第5个状态
第五个状态则没有任何的转移。
S -> L "=" . R
wildCards:
#
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
第六个状态有4个转移,分别为R、L、*和id
1.通过符号R可转移到新状态
S -> L "=" R
wildCards:
#
2.通过符号L可转移到状态9
3.通过符号*可转移到状态4
4.通过符号id可转移到状态5
第6、7、8个状态都没有任何转移
然后让我们来看下changes列表里有哪些东西,根据
上一篇的算法可知,所有已存在的状态都在changes列表里,应此它里面应该会有4、5和9三个状态。
至此,整个自生的部分完成了,下面我们将其画成一张图
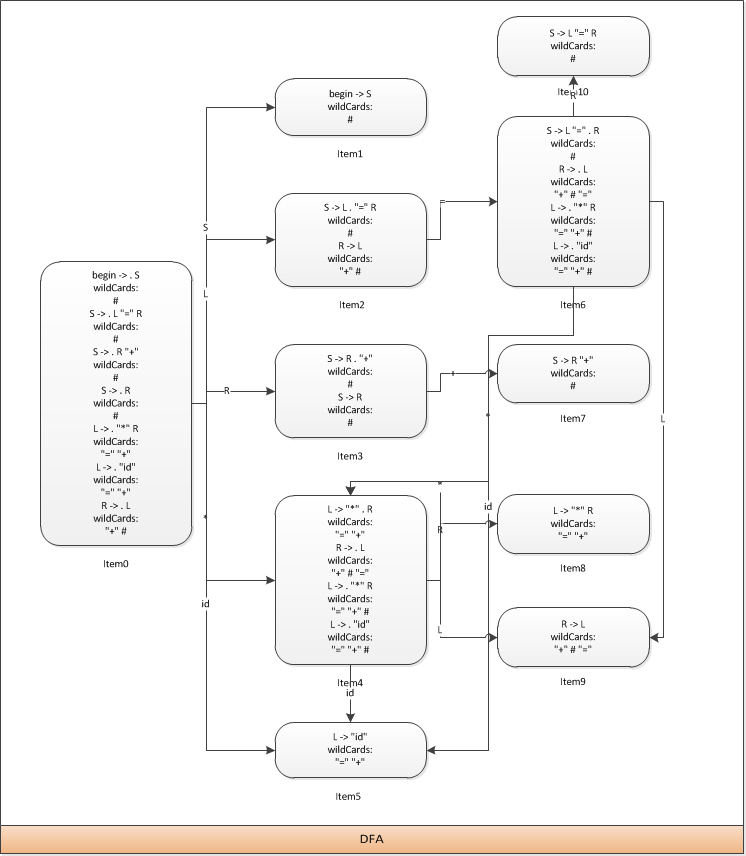 下面是传播部分
下面是传播部分
在第一次传播时changes列表里有3个状态,分别对这3个状态用go函数求出新的展望符,并把它们合并到原有的状态上。
首先看状态4,它有4个状态转移符,分别是R、L、*和id
1.通过符号R可转移到状态8,同时它的展望符如下
L -> "*" R
wildCards:
"=" "+" #
2.通过符号L可转移到状态9,同时它的展望符如下
R -> L
wildCards:
"+" # "="
3.通过符号*可转移到它自己,同时它的展望符如下
L -> "*" . R
wildCards:
"=" "+" #
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
4.通过符号id可转移到状态5,同时它的展望符如下
L -> "id"
wildCards:
"=" "+" #
然后我们来看一下状态5和9,它们没有任何状态转移符,应此它们不会传播任何展望符。
现在changes列表里有4个状态,分别为8、9、4和5,又由于第8个状态已经产生了新的展望符#应此需要继续传播
第二次传播
首先先看状态8和9,它们没有任何状态转移符,应此它们不会传播任何展望符。
然后来看状态4,同样的它有4个状态转移符,分别为R、L、*和id。
1.通过符号R可转移到状态8,同时它的展望符如下
L -> "*" R
wildCards:
"=" "+" #
2.通过符号L可转移到状态9,同时它的展望符如下
R -> L
wildCards:
"+" # "="
3.通过符号*可转移到它自己,同时它的展望符如下
L -> "*" . R
wildCards:
"=" "+" #
R -> . L
wildCards:
"+" # "="
L -> . "*" R
wildCards:
"=" "+" #
L -> . "id"
wildCards:
"=" "+" #
4.通过符号id可转移到状态5,同时它的展望符如下
L -> "id"
wildCards:
"=" "+" #
最后我们来看状态5,它没有任何状态转移符,应此它不会传播任何展望符。
现在changes列表里同样有4个状态,分别为8、9、4和5,由于没有一个状态产生了新的展望符,应此它将不会继续传播下去了。
现在整个文法的DFA就生成完毕了,让我们来修改一下原先的那张图来看看最终的DFA是什么样的。
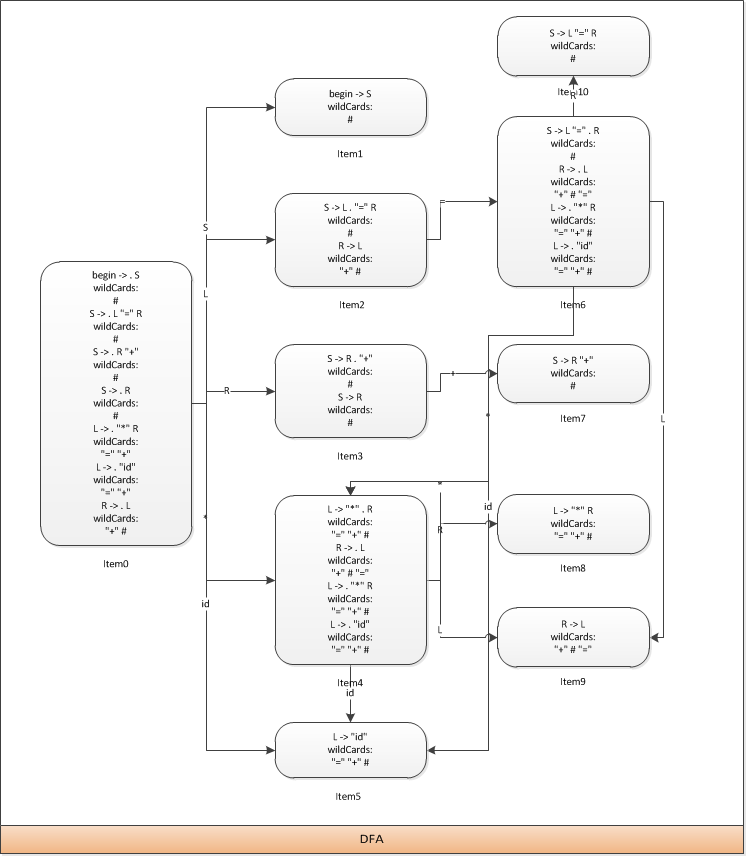
整个示例就先介绍到这里,在接下来的一篇文章中将会通过几个示例来介绍closure和go函数的原理,希望这种由粗到细的讲解顺序能够被读者所接受。最后完整的代码可到
http://code.google.com/p/qlanguage下载。
posted on 2013-05-30 23:04
lwch 阅读(1643)
评论(2) 编辑 收藏 引用 所属分类:
QLanguage