给出一个带边权的无向图G,设其最小生成树为T,求出图G的与T
不完全相同的边权和最小的生成树(即G的次小生成树)。一个无向图的两棵生成树不完全相同,当且仅当这两棵树中至少有一条边不同。注意,图G可能不连通,可能有平行边,但一定没有自环(其实对于自环也很好处理:直接舍弃。因为生成树中不可能出现自环)。
【具体题目】
URAL1416(注意,这一题的边数M的范围没有给出,视为124750)
【分析】
定义生成树T的一个可行变换(-E1, +E2):将T中的边E1删除后,再加入边E2(满足边E2原来不在T中但在G中),若得到的仍然是图G的一棵生成树,则该变换为可行变换,该可行变换的
代价为(E2权值 - E1权值)。这样,很容易证明,G的次小生成树就是由G的最小生成树经过一个代价最小的可行变换得到。进一步可以发现,
这个代价最小的可行变换中加入的边E2的两端点如果为V1和V2,那么E1一定是原来最小生成树中从V1到V2的路径上的权值最大的边。
这样,对于本题就有两种算法了:(以下的T全部指G的最小生成树)
(1)Prim:
设立数组F,F[x][y]表示T中从x到y路径上的最大边的权值。F数组可以在用Prim算法求最小生成树的过程中得出。每次将边(i, j)加入后(j是新加入树的边,i=c[j]),枚举树中原有的每个点k(包括i,但不包括j),则F[k][j]=max{F[k][i], (i, j)边权值},又由于F数组是对称的,可以得到F[j][k]=F[k][j]。然后千万记住将图G中的边(i, j)删除(就是将邻接矩阵中(i, j)边权值改为∞)!因为T中的边是不能被加入的。等T被求出后,所有的F值也求出了,然后,枚举点i、j,若邻接矩阵中边(i, j)权值不是无穷大(这说明i、j间存在不在T中的边),则求出{(i, j)边权值 - F[i][j]}的值,即为加入边(i, j)的代价,求最小的总代价即可。
另外注意三种特殊情况:【1】图G不连通,此时最小生成树和次小生成树均不存在。判定方法:在扩展T的过程中找不到新的可以加入的边;【2】图G本身就是一棵树,此时最小生成树存在(就是G本身)但次小生成树不存在。判定方法:在成功求出T后,发现邻接矩阵中的值全部是无穷大;【3】图G存在平行边。这种情况最麻烦,因为这时代价最小的可行变换(-E1, +E2)中,E1和E2可能是平行边!因此,只有建立两个邻接矩阵,分别存储每两点间权值最小的边和权值次小的边的权值,然后,每当一条新边(i, j)加入时,不是将邻接矩阵中边(i, j)权值改为无穷大,而是改为连接点i、j的权值次小的边的权值。
代码:
#include <iostream>
using namespace std;
#define re(i, n) for (int i=0; i<n; i++)
#define re2(i, l, r) for (int i=l; i<r; i++)
const int MAXN = 7000, INF = ~0U >> 2;
int n, s[MAXN][MAXN], s2[MAXN][MAXN], f[MAXN][MAXN], c[MAXN], v[MAXN], res1 = 0, res2 = 0;
bool vst[MAXN];
void init()
{
freopen("mst.in", "r", stdin);
scanf("%d", &n);
re(i, n) re(j, n) s[i][j] = s2[i][j] = INF;
int m, a, b, len;
scanf("%d", &m);
if (!m) {
if (n > 1) res1 = -INF; res2 = -INF;
return;
}
re(i, m) {
scanf("%d%d%d", &a, &b, &len); a--; b--;
if (len < s[a][b]) {s2[a][b] = s2[b][a] = s[a][b]; s[a][b] = s[b][a] = len;} else if (len < s2[a][b]) s2[a][b] = s2[b][a] = len;
}
fclose(stdin);
}
void solve()
{
re(i, n) {f[i][i] = c[i] = vst[i] = 0; v[i] = s[0][i];} vst[0] = 1;
int l0, l1 = INF, x, y, z;
re2(i, 1, n) {
l0 = INF; re(j, n) if (!vst[j] && v[j] < l0) {l0 = v[j]; x = j; y = c[j];}
if (l0 == INF) {res1 = res2 = -INF; return;}
vst[x] = 1; res1 += l0; s[x][y] = s[y][x] = INF; if (s2[x][y] < INF && s2[x][y] - l0 < l1) l1 = s2[x][y] - l0;
re(j, n) if (!vst[j] && s[x][j] < v[j]) {v[j] = s[x][j]; c[j] = x;}
re(j, n) if (vst[j] && j != x) f[j][x] = f[x][j] = max(f[j][y], l0);
}
re(i, n-1) re2(j, i+1, n) if (s[i][j] < INF) {
z = s[i][j] - f[i][j];
if (z < l1) l1 = z;
}
if (l1 == INF) res2 = -INF; else res2 = res1 + l1;
}
void pri()
{
freopen("mst.out", "w", stdout);
printf("Cost: %d\nCost: %d\n", res1 == -INF ? -1 : res1, res2 == -INF ? -1 : res2);
fclose(stdout);
}
int main()
{
init();
if (!res2) solve();
pri();
return 0;
}
效率分析:Prim算法求次小生成树的时空复杂度均为O(N2)。(2)Kruskal:Kruskal算法也可以用来求次小生成树。在准备加入一条新边(a, b)(该边加入后不会出现环)时,选择原来a所在连通块(设为S1)与b所在连通块(设为S2)中,点的个数少的那个(如果随便选一个,最坏情况下可能每次都碰到点数多的那个,时间复杂度可能增至O(NM)),找到该连通块中的每个点i,并遍历所有与i相关联的边,若发现某条边的另一端点j在未选择的那个连通块中(也就是该边(i, j)跨越了S1和S2)时,就说明最终在T中"删除边(a, b)并加入该边"一定是一个可行变换,且由于加边是按照权值递增顺序的,(a, b)也一定是T中从i到j路径上权值最大的边,故这个可行变换可能成为代价最小的可行变换,计算其代价为[(i, j)边权值 - (a, b)边权值],取最小代价即可。注意,在遍历时需要排除一条边,就是(a, b)本身(具体实现时由于用DL边表,可以将边(a, b)的编号代入)。另外还有一个难搞的地方:如何快速找出某连通块内的所有点?方法:由于使用并查集,连通块是用树的方式存储的,可以直接建一棵树(准确来说是一个森林),用“最左子结点+相邻结点”表示,则找出树根后遍历这棵树就行了,另外注意在合并连通块时也要同时合并树。
对于三种特殊情况:【1】图G不连通。判定方法:遍历完所有的边后,实际加入T的边数小于(N-1);【2】图G本身就是一棵树。判定方法:找不到这样的边(i, j);【3】图G存在平行边。这个对于Kruskal来说完全可以无视,因为Kruskal中两条边只要编号不同就视为不同的边。
其实Kruskal算法求次小生成树还有一个优化:每次找到边(i, j)后,一处理完这条边就把它从图中删掉,因为当S1和S2合并后,(i, j)就永远不可能再是可行变换中的E2了。
代码:
#include <iostream>
#include <stdlib.h>
using namespace std;
#define re(i, n) for (int i=0; i<n; i++)
#define re3(i, l, r) for (int i=l; i<=r; i++)
const int MAXN = 7000, MAXM = 130000, INF = ~0U >> 2;
struct edge {
int a, b, len, pre, next;
} ed[MAXM + MAXM];
struct edge2 {
int a, b, len, No;
} ed2[MAXM];
int n, m = 0, m2, u[MAXN], ch[MAXN], nx[MAXN], q[MAXN], res1 = 0, res2 = INF;
void init_d()
{
re(i, n) ed[i].a = ed[i].pre = ed[i].next = i;
if (n % 2) m = n + 1; else m = n;
}
void add_edge(int a, int b, int l)
{
ed[m].a = a; ed[m].b = b; ed[m].len = l; ed[m].pre = ed[a].pre; ed[m].next = a; ed[a].pre = m; ed[ed[m].pre].next = m++;
ed[m].a = b; ed[m].b = a; ed[m].len = l; ed[m].pre = ed[b].pre; ed[m].next = b; ed[b].pre = m; ed[ed[m].pre].next = m++;
}
void del_edge(int No)
{
ed[ed[No].pre].next = ed[No].next; ed[ed[No].next].pre = ed[No].pre;
ed[ed[No ^ 1].pre].next = ed[No ^ 1].next; ed[ed[No ^ 1].next].pre = ed[No ^ 1].pre;
}
void init()
{
freopen("mst.in", "r", stdin);
scanf("%d%d", &n, &m2);
if (!m2) {
if (n > 1) res1 = -INF;
res2 = -INF; return;
}
init_d();
int a, b, len;
re(i, m2) {
scanf("%d%d%d", &a, &b, &len);
ed2[i].No = m; add_edge(--a, --b, len);
ed2[i].a = a; ed2[i].b = b; ed2[i].len = len;
}
fclose(stdin);
}
int cmp(const void *s1, const void *s2)
{
return ((edge2 *)s1)->len - ((edge2 *)s2)->len;
}
void prepare()
{
re(i, n) u[i] = ch[i] = nx[i] = -1;
qsort(ed2, m2, 16, cmp);
}
int find(int x)
{
int r = x, r0 = x, tmp;
while (u[r] >= 0) r = u[r];
while (u[r0] >= 0) {tmp = u[r0]; u[r0] = r; r0 = tmp;}
return r;
}
void uni(int r1, int r2, int No, int l0)
{
q[0] = r1;
int j, k, l1, front, rear;
for (front=0, rear=0; front<=rear; front++) {
j = ch[q[front]];
while (j != -1) {
q[++rear] = j;
j = nx[j];
}
}
re3(i, 0, rear) {
j = q[i];
for (int p=ed[j].next; p != j; p=ed[p].next) {
k = ed[p].b;
if (p != No && find(k) == r2) {
l1 = ed[p].len - l0;
if (l1 < res2) res2 = l1;
del_edge(p);
}
}
}
u[r2] += u[r1]; u[r1] = r2; nx[r1] = ch[r2]; ch[r2] = r1;
}
void solve()
{
int r1, r2, l0, num = 0;
re(i, m2) {
r1 = find(ed2[i].a); r2 = find(ed2[i].b);
if (r1 != r2) {
l0 = ed2[i].len; res1 += l0; num++;
if (u[r1] >= u[r2]) uni(r1, r2, ed2[i].No, l0); else uni(r2, r1, ed2[i].No ^ 1, l0);
}
}
if (num < n - 1) {res1 = res2 = -INF; return;}
if (res2 == INF) res2 = -INF; else res2 += res1;
}
void pri()
{
freopen("mst.out", "w", stdout);
printf("Cost: %d\nCost: %d\n", res1 == -INF ? -1 : res1, res2 == -INF ? -1 : res2);
fclose(stdout);
}
int main()
{
init();
if (!res1 && res2 == INF) {
prepare();
solve();
}
pri();
return 0;
}
效率分析:可以证明,如果每次都选取点少的连通块,Kruskal算法求次小生成树的时间复杂度为O(M*(logN+logM)),空间复杂度为O(M)。
总结:显然Prim适用于稠密图,而Kruskal适用于稀疏图。
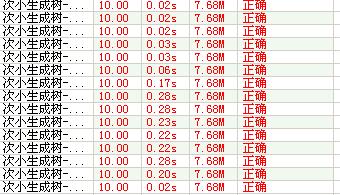
下面是对于一些数据的测试结果(数据说明:第1~9个点和第15个点为稠密图或一般图,第10~14个点为稀疏图)
Prim:
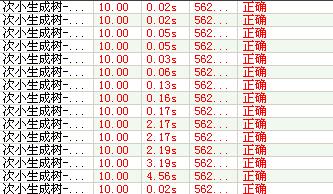
Kruskal(加入删边优化):
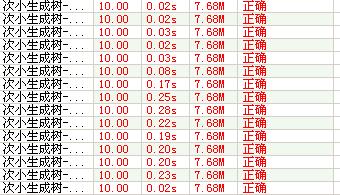
Kruskal(未加删边优化):