 置顶随笔
置顶随笔
本人是Linux方面的菜鸟。给自己弄了一套练级书单。按照书单顺序,每周最少读一章,最多读二章。并以blog文的形式总结一周所学,每周最少一篇,最多二篇。
坚持两年,望学有所成。共勉 。
初级:管理
1.《鸟哥私房菜:初级篇》
2.《鸟哥私房菜:高级篇》
中级:编程
3.《Linux程序设计》
4.《Unix环境高级编程》
5.《Unix网络编程卷1:套接字联网1》
6.《Unix网络编程卷2:进程间通信》
高级:内核驱动
7.《嵌入式Linux基础教程》
8.《精通Linux设备驱动程序开发》
9.《深入理解计算机系统》
10.《深入Linux内核架构》
2012年11月22日
转载自外刊IT评论网
很多人都问我,“我想做web设计,如何入手?”或“我要开发web应用程序,需要学哪些技术?”,当然,推荐他们一摞书籍或十几篇关于55条超越竞争对手115%的技巧文章是最简单的,但问题的实际情况是,如果你想开始做某件事,你并不需要先去学会什么新知识。对你来说,最重要的却是立即着手去做。
行动起来,着手去做。如果你想学web设计,那就去做个网站。如果你想成为企业家、在网上买你的产品,那就去做个电子商务应用程序。也许你现在还不具备这些开发技能,但何必为这些担心?也许你根本不知道你究竟缺少哪些技能呢。
从你能做的开始做
如果你想在web上做点什么,不要担心着需要去学HTML,CSS,Ruby,PHP,SQL等知识。它们对于完成一个最终的产品是必要的,但开始时你并不需要它们。你可以在Keynote或Powerpoint里把你的想法的物理模型模拟出来。用方框把一个个表单域表示出来,标上说明,把一个个页面用线关联起来。你可以利用现有的软件知识制作出一个非常健壮的用户界面交互原型。根本没有任何计算机知识?那就用你的铅笔和纸和便利贴。画出一个个屏幕样式,把它们贴在墙上,试试各个界面的流程。
你也许甚至连需要什么技能都不知道,所以就不要忧虑这些了。从你已经知道的着手。
你可以用草图或幻灯片做很多事情。你可以看到你的想法形象化了,这样可以去评价它是否是一个真正具有价值的东西。到了这一步,你才可以进行下一步,去学习些HTML知识,把你的原型在浏览器里实现。此时,你要尽可能的发挥你所具有的知识和工具,把事情做的最好。
防止不自信
很多时候我们不能开始做事、无可作为的原因是缺少技术、资源、和工具。但这真正阻挡我们的却是自我挑剔和找借口。在Drawing on the Right Side of the Brain这本优秀的书中,作者贝蒂·爱德华讨论了为什么当还是孩子时喜欢写写画画而到了青春期大部分人都停止了开发这种能力。
“跟据很多成人的绘画技能来看,进入青春期标志着人们在艺术才能方面发展的突然中止。作为孩子,他们面临一个艺术危机,面临着他们对周围这世界日益增长的复杂的意识和自身艺术技能水平的冲突。”
孩子们的自我批判意识会逐渐增强,他们同样喜欢绘画,但当他们意识到画不好时,就完全放弃了绘画。
这种感觉会持续到成年。我们想起设计一个网站,或去开发一个应用程序时,如果我们拥有的资源和工具达不到我们预设的要求和水平,我们永远不会开始去做。即使互联网让我们看到了那些无数的伟大作品、天才个人和优秀的操作过程作为样板,也无济于事。人们很容易跟那些最好的比较起来发现自己的各种不充分和缺失,但从来没想过,任何人都不是天生都拥有这些技能的,如果他们不从开始做起,永远也走不到这一天。
去干——无须试
成功的人会找到一种方法让自己坚持做下去——尽管疑虑不满。艺术家文森特·梵高,只是在他的人生的后十年才称得上是艺术家。我们都因他的伟大艺术作品而认识他,但他并非一开始就是大师。对比一下Drawing on the Right Side of the Brain这本书里提供的两幅画,一副是其早期的作品,一副是两年后的作品:

文森特·梵高 木匠, 1880 和 Woman Mourning, 1882
他不是什么神童(27岁才开始学画),他通过艰苦努力练就了一身技艺。如果当他感觉到技术水平比不上保罗·高更时,他屈服了自己的疑虑和绝望,他很有可能就放弃了自己的前程。
所有的这些,都是想说一个道理,有很多本来该成的事情因为我们没有去做而没有成。如果是由于认为你自己不够好,不具备技能、知识、经验,而放弃追逐自己的梦想,那简直就是浪费。事实上,事情中存在问题正是一种驱动和鞭策。它会给你巨大的挑战同时巨大的回报。为什么要不厌其烦的做那些已经做过一百遍的事情呢,你已经从中学不到什么了。不要再担心为了完成一个任务你需要知道哪些东西,你已经拥有了开始去做所需要的任何东西了。
2012年11月17日
转载自:http://www.aqee.net/for-gods-sake-follow-your-dreams/
周末的时候我正准备和几个朋友打游戏,热身的过程中同一个不是很熟的队员发生了一次有趣的谈话。
“你是做什么的?”他问我。“哦,我给自己干,我有一个软件公司”,我回答。“真的吗!真令人羡慕!我在XXX公司工作,但我一直有个愿望去做动画设计,做独立职业人。这是我的梦想。可我现在陷入了这个错误的行业中了。”
“你还活着,不是吗?”我尽量小声的对他说。他继续说:“你不知道,我已经想这一天等了10年了,可一旦你有了家庭,你很难在干其它的事情了.”
我实在是按耐不住,于是就对他说:“那好,如果你是真的这样想,你也许应该报个动画设计培训班,或者你也可以在家里自学呀。只要你下定决心开始做。”我得到这样一句轻轻的回复:“嗨,这太难了,有了家庭,全职工作,没有时间。我很想这样做,但却不行。”
很无奈,我建议道:“你也许可以考虑几周或几个月的脱产培训,或者干脆辞职。”他看了看我,好像我是要砍掉他的右手。“你疯了吗?那我的收入从哪里来?”
我开始明白,如果谈话继续下去的话,我会和这个还不是很熟的人在第一次见面就会争吵起来,我选择只是笑了一下,就走开了。但这事让我有所思考。为什么人们不愿意冒一点风险去追逐自己的梦想?是他们的梦想不值得这样做吗?如果不是,为什么我们要对这样的人恨恨不已呢?我们是否愧对自己没有给梦想一次公平的机会呢?
现在,我明白了,并不是每个人都愿意把全部的时间都投入到实现梦想中。但我们也不该因此就从来不向我们梦想的前方迈出一步。我的意思是,就像小孩学走路的第一步,如果你不能破釜沉舟,那也不能就此把梦想扼杀掉呀。
当还是小孩子的时候,我们都有过疯狂的主意和梦想。当人们问起 – “你长大后想干什么?”时,你不会说“我想做一份稳定的工作,我想在一家财富100强的公司里当总经理”或者“我想在政府部门里找个铁饭碗”。你希望去做一些能让你兴奋的事情,你有热情的事情 – “军人,科学家,音乐家,舞蹈家,世界小姐”等等。你根本不会考虑能从中获取多少钱,你只是想去做这些。
可是为什么长大后我们就失去了所有的热情、动力、愿望以及守住我们的梦想的力量了呢?为什么金钱就支配了我们的热情,大多数情况是扼杀了热情?为什么“一份稳定的收入”就能禁锢我们的梦想?为什么我们要停止思考我们的热爱的事情?
我们为什么会受这每月稳定工作收入的诱惑,以至于完全忽视了一个真相:追求自己的梦想永远不会太迟。我可以理解人们为什么会这样,人们是“害怕失败”。我们担心失败,这种担心导致了我们给自己编织了一个谎言:有些东西永远是不属于你的。“我没有时间,我有家庭,当我有了足够的钱后我会去做的,等等”,这些都是借口。这样我们就默认了丢掉梦想也没什么,不去做那些你热爱的事情也没什么,日复一日的做那些重复的枯燥的事情也没什么。
就像Tony Robbins说的 – “唯一你够阻挡你去获取你想要的东西的事情是你一直在告诉自己为什么它不属于你。”
我们在等待什么?当所有的星星都能按你希望的方向连成一线的时刻吗?这样就能保证你一定成功吗?这条路永远是不通的。这个光辉的时刻你永远等不到。形式环境永远都不会达到你的满意。永远都会有某方面的事情对你有所不利。你不得不横下一条心,冒一回险。一旦我们设立了一个目标,我们不可能等待各方面都完美的时机、各方面都如我所期待的那种情况。我们需要的是着手去做。我们可以在全职工作之余慢慢的进行。我很喜欢我现在所做的事情,而且我也是做完我的白天的正式工作后做这些的。这不容易,但很有意思,因为我正在实现我梦想的事情,我对我正在开发的软件充满热情。
也许只有我是这样想的,也许我是个怪人。也许我很傻,但我宁愿犯傻,宁愿活在我的梦想里拼搏,也不要找出一堆的借口。金钱的利诱不会带来真正的成功,真正的成功来自于爱和热情。你必须爱你所做的事情,你必须对你所做的事有热情。
失败并不可怕。可怕的是当你60岁时回首往事才发现“也许我应该给自己一次实现梦想的机会,也许我会成功的,也许我应该守住梦想”。但此时已经太晚了。你也许正在走向这个结局。
不要害怕去实现自己的梦想。这将是你犯的最大的错误。
在这个世界上,有数百万的人热衷于软件开发,他们有很多名字,如:软件工程师(Software Engineer),程序员(Programmer),编码人(Coder),开发人员(Developer)。经过一段时间后,这些人能够成为一个优秀的编码人员,他们非常熟悉如何用计算机语言来完成自己的工作。但是,如果你要成为一个优秀的程序员,你还可以需要有几件事你需要注意,如果你能让下面十个条目成为你的习惯,那么你才能真正算得上是优秀程序员。
1. 学无止境。就算是你有了10年以上的程序员经历,你也得要使劲地学习,因为你在计算机这个充满一创造力的领域,每天都会有很多很多的新事物出现。你需要跟上时代的步伐。你需要去了解新的程序语言,以及了解正在发展中的程序语言,以及一些编程框架。还需要去阅读一些业内的新闻,并到一些热门的社区去参与在线的讨论,这样你才能明白和了解整个软件开发的趋势。在国内,一些著名的社区例如:CSDN,ITPUB,CHINAUINX等等,在国外,建议你经常上一上digg.com去看看各种BLOG的聚合。
2. 掌握多种语言。程序语言总是有其最适合的领域。当你面对需要解决的问题时,你需要找到一个最适合的语言来解决这些问题。比如,如果你需要性能,可能C/C++是首选,如果你需要跨平台,可能Java是首选,如果你要写一个Web上的开发程序,那么 PHP,ASP,Ajax,JSP可能会是你的选择,如果你要处理一些文本并和别的应用交互,可能Perl, Python会是最好的。所以,花一些时间去探索一下其它你并熟悉的程序语言,能让你的眼界变宽,因为你被武装得更好,你思考问题也就更为全面,这对于自己和项目都会有好的帮助。
3. 理性面对不同的操作系统或技术。程序员们总是有自己心目中无可比拟的技术和操作系统,有的人喜欢Ubuntu,有的人喜欢Debian,还有的人喜欢Windows,以及FreeBSD,MacOSX或Solaris等等。看看我的BLOG(http://blog.csdn.net/haoel)中的那篇《其实Unix很简单》后的回复你就知道程序员们在维护起自己的忠爱时的那份执着了。只有一部分优秀的程序员明白不同操作系统的优势和长处和短处,这样,在系统选型的时候,才能做到真正的客观和公正,而不会让情绪影响到自己。同样,语言也是一样,有太多的程序员总是喜欢纠缠于语言的对比,如:Java和Perl。哪个刚刚出道的程序员没有争论去类似的话题呢?比如VC++和Delphi等等。争论这些东西只能表明自己的肤浅和浮燥。优秀的程序并不会执着于这些,而是能够理性的分析和理心地面对,从而才能客观地做出正确的选择。
4. 别把自己框在单一的开发环境中。 再一次,正如上面所述,每个程序员都有自己忠爱的工具和技术,有的喜欢老的(比如我就喜欢Vi编辑程序),而有的喜欢新的比如gedit或是Emacs 等。有的喜欢使用像VC++一样的调试器,而我更喜欢GDB命令行方面的调式器。等等等等。程序员在使用什么样的工具上的争论还少吗?到处都是啊。使用什么样的工具本来无所谓,只要你能更好更快地达到你的目的。但是有一点是优秀程序员都应该了解的——那就是应该去尝试一下别的工作环境。没有比较,你永远不知道谁好谁不好,你也永远不知道你所不知道的。
5. 使用版本管理工具管理你的代码。千万不要告诉我你不知道源码的版本管理,如果你的团队开发的源代码并没有版本管理系统,那么我要告诉你,你的软件开发还处于石器时代。赶快使用一个版式本管理工具吧。CVS 是一个看上去平淡无奇的版本工具,但它是被使用最广的版本管理系统,Subversion 是CVS的一个升级版,其正在开始接管CVS的领地。Git 又是一个不同的版本管理工具。还有Visual SourceSafe等。使用什么样的版本管理工具依赖于你的团队的大小和地理分布,你也许正在使用最有效率或最没有效率的工具来管理你的源代码。但一个优秀的程序员总是会使用一款源码版本管理工具来管理自己的代码。如果你要我推荐一个,我推荐你使用开源的Subversion。
6. 是一个优秀的团队成员。 除非你喜欢独奏,除非你是孤胆英雄。但我想告诉你,今天,可能没有一个成熟的软件是你一个人能做的到的,你可能是你团队中最牛的大拿,但这并不意味着你就是好的团队成员。你的能力只有放到一个团队中才能施展开来。你在和你的团队成员交流中有礼貌吗?你是否经常和他们沟通,并且大家都喜欢和你在一起讨论问题?想一想一个足球队吧,你是这个队中好的成员吗?当别人看到你在场上的跑动,当别人看到你的传球和接球和抢断,能受到鼓舞吗?
7. 把你的工作变成文档。 这一条目当然包括了在代码中写注释,但那还仅仅不够,你还需要做得更多。有良好的注释风格的代码是一个文档的基础,他能够让你和你的团队容易的明白你的意图和想法。写下文档,并不仅仅是怕我们忘了当时的想法,而且还是一种团队的离线交流的方法,更是一种知识传递的方法。记录下你所知道的一切会是一个好的习惯。因为,我相信你不希望别人总是在你最忙的时候来打断你问问题,或是你在休假的时候接到公司的电话来询问你问题。而你自己如果老是守着自己的东西,其结果只可能是让你自己长时间地深陷在这块东西内,而你就更本不可以去做更多的事情。包括向上的晋升。你可能以为“教会徒弟能饿死师父”,但我告诉你,你的保守会让你失去更多更好的东西,请你相信我,我绝不是在这里耸人听闻。
8. 注意备份和安全。 可能你觉得这是一个“废话”,你已明白了备份的重要性。但是,我还是要在这里提出,丢失东西是我们人生中的一部份,你总是会丢东西,这点你永远无法避免。比如:你的笔记本电脑被人偷了,你的硬盘损坏了,你的电脑中病毒了,你的系统被人入侵了,甚至整个大楼被烧了,等等,等等。所以,做好备份工作是非常非常重要的事情,硬盘是不可信的,所以定期的刻录光盘或是磁带可能会是一个好的方法,网络也是不可信的,所以小心病毒和黑客,不但使用软件方面的安全策略,你更需要一个健全的管理制度。此外,尽量的让你的数据放在不同的地方,并做好定期(每日,每周,每月)的备份策略。
9. 设计要足够灵活。 可能你的需求只会要求你实现一个死的东西,但是,你作为一个优秀的程序,你应该随时在思考这个死的东西是否可以有灵活的一面,比如把一些参数变成可以配置的,把一些公用的东西形成你的函数库以便以后重用,是否提供插件方面的功能?你的模块是否要以像积木一样随意组合?如果要有修改的话,你的设计是否能够马上应付?当然,灵活的设计可能并不是要你去重新发明轮子,你应该尽可能是使用标准化的东西。所谓灵话的设计就是要让让考虑更多需求之外的东西,把需求中这一类的问题都考虑到,而不是只处理需求中所说的那一特定的东西。比如说,需要需要的屏幕分辨率是800×600,那么你的设计能否灵活于其他的分辨率?程序设计总是需要我们去处理不同的环境,以及未来的趋势。我们需要用动态的眼光去思考问题,而不是刻舟求剑。也许有一天,你今天写的程序就要移植到别的环境中去,那个时候你就能真正明白什么是灵活的设计了。
10. 不要搬起石头砸自己的脚。程序员总是有一种不好的习惯,那就是总是想赶快地完成自己手上的工作。但情况却往往事已愿违。越是想做得快,就越是容易出问题,越是想做得快,就越是容易遗漏问题,最终,程序改过来改过去,按下葫芦起了瓢,最后花费的时间和精力反而更多。欲速而不达。优秀程序员的习惯是前面多花一些时间多作一些调查,试验一下不网的解决方案,如果时间允许,一个好的习惯是,每4个小时的编程,需要一个小时的休息,然后又是4个小时的编码。当然,这因人而异,但其目的就是让你时常回头看看,让你想一想这样三个问题:1)是否这么做是对的?2)是否这么做考虑到了所有的情况?3)是否有更好的方法?想好了再说,时常回头看看走过的路,时常总结一下过去事,会对你有很大的帮助。
以上是十条优秀程序员的习惯或行为规范,希望其可以对你有所帮助。
本文来源于网上phil的BLOG,但我在写作过程中使用了自己的语言和方法重新描述了一下这十条,所以,我希望你在转载的时候能够注明作者和出处以表示对我的尊重。谢谢!
本人是Linux方面的菜鸟。给自己弄了一套练级书单。按照书单顺序,每周最少读一章,最多读二章。并以blog文的形式总结一周所学,每周最少一篇,最多二篇。
坚持两年,望学有所成。共勉 。
初级:管理
1.《鸟哥私房菜:初级篇》
2.《鸟哥私房菜:高级篇》
中级:编程
3.《Linux程序设计》
4.《Unix环境高级编程》
5.《Unix网络编程卷1:套接字联网1》
6.《Unix网络编程卷2:进程间通信》
高级:内核驱动
7.《嵌入式Linux基础教程》
8.《精通Linux设备驱动程序开发》
9.《深入理解计算机系统》
10.《深入Linux内核架构》
2012年8月29日
声明:本文涉及的源代码及文章请点击这里下载,本文版权归IronOxide所有。博客地址:http://www.cppblog.com/IronOxide/
这篇文章讨论的是序列中第K大或第K小元素,由于第K大元素可以转化为求第N-K+1小元素(N为序列的长度),所以,本文专注于讨论第K小元素。
本文讨论的几个问题:
1. 对给定整数序列,求该序列中第K小的元素。
2. 对某一整数序列,允许动态更改序列中的数。动态查询序列中第K小元素。
3. 给定一个整数序列和若干个区间,回答该区间内第K小元素。
4. 对某一整数序列,允许动态更改序列中的数。动态查询序列中的第K小元素。
【关键字】
第K小元素 树状数组 线段树 平衡二叉树 归并树 划分树 单调队列 堆 块状表
【问题一】
问题描述:
给出一个乱序整数序列a[1…n] ,求该序列中的第K小元素。(1<=K<=N)。
算法分析:
用基于快速排序的分治算法,期望复杂度为O(N)。
代码:
int qs(int *a , int l , int r , int k){
if(l == r) return a[l] ;
int i = l , j = r , x = a[(l+r)>>1] , temp ;
do{
while(a[i] < x) ++ i ;
while(a[j] > x) -- j ;
if(i <= j){
temp = a[i] ; a[i] = a[j] , a[j] = temp ;
i++ ; j-- ;
}
}while(i<=j) ;
if(k <= j) return qs(a , l , j , k);
if(k >= i) return qs(a , i , r , k);
return x ;
}
练习
RQNOJ 350 这题数据量比较小1≤N≤10000,1≤M≤2000 。所以计算量不会超过10^7。当然用到后面的归并树或划分树,能将复杂度降低。
【问题二】
问题描述:
给出一个乱序整数序列a[1...n] ,有3种操作:
操作一:ADD NUM 往序列添加一个数NUM。
操作二:DEL NUM 从序列中删除一个数NUM(若有多个,只删除一个)。
操作三:QUERY K 询问当前序列中第K小的数。
输出每次询问的数。假设操作的次数为M。
算法分析:
这题实际上就是一边动态增删点,一边查询第K小数。这类题有两种思维方法:一是二分答案,对当前测试值mid,查询mid在当前序列中的排名rank , 然后根据rank决定向左边还是右边继续二分。另一种是直接求第K小元素。
这个题可以用各种类型的数据结构解决,其时间复杂度和编程复杂度稍有区别:
线段树:运用第一种思维,当添加(删除)一个数x时,相当于往线段树上添加(删除)一条(x , maxlen)(注意是闭区间)长度的线段。这样询问时,覆盖[mid , mid]区间的线段数就是比mid小的数,加上1就是rank。二分次数为log(maxlen) ,查一次mid的rank , 复杂度为O(logN) 。所以总复杂度上界为O(M*logN*logN) 。为方便比较,这里认为log(maxlen)等于logN。
树状数组:
第一种思维:这个相对简单,因为树状数组求比mid小的数就一个getsum(mid-1)就搞定。
复杂度同线段树一样。只是常数很小,代码量也很小。
第二种思维:我只能说很巧妙。回顾树状数组求和时的操作:
代码
int getsum(int x ){
int res = 0 ;
for( ; x>0 ; x-=lowbit(x) ) res += arr[x] ;
return res ;
}
对二进制数10100010 是依次累加arr[10100010] , arr[10100000] , arr[10000000] 。从而得到小于x的数的个数。当反过来看的时候,就有了这种方法:从高位到低位依次确定答案的当前为是0还是1,首先假设是1,判断累计结果是否会超过K,超过K则假设不成立,应为0,否则继续确定下一位。看程序就明白了。
代码
int getkth(int k){
int ans = 0 , cnt = 0 , i ;
for(i = 20 ; i>=0 ; --i){
ans += 1<<i ;
if(ans>=maxn||cnt+c[ans]>=k) ans-=1<<i ;
else cnt +=c[ans] ;
}
return ans+1 ;
}
复杂度:自然就比第一种少了一个阶。O(M*logN)。
平衡二叉树:
各种平衡二叉树都可以解决这个问题:Size Balance Tree ,Spaly ,Treap ,红黑树等等。 不得不说,Size Balance Tree解这个问题是比较方便的。因为SBT本身就有一个Select操作,直接调用一下,就出来了。
代码
复杂度:用的是第二种思维。O(M*logN)。
总结:
其实,综合起来,各种数据结构,各种算法 ,各种纠结。平衡树太复杂,线段树又高了点(一般情况不会有问题的)。最好的方法还是树状数组的二进制算法,时间复杂度和编程复杂度达到双赢。
但是,总结起来,发现线段树或者树状数组所消耗的空间跟数据的范围有关,当序列元素是浮点数或者范围很大时,就有点力不从心了(当然,离线的情况可以离散化,在线的某些情况可以离散化),而用平衡二叉树就不存在这样的问题。原来平衡二叉树才是王道。
练习:
最近发现,基于这种思想的题目还真是不少啊~ ~ POJ Double Queue
[NOI2004]郁闷的出纳员 工资反过来看,职员工资不变,而是工资下界在变而已。当降低工资下界时,为了知道哪些职员走人了,我还用了个二叉堆。。。。。
POJ 2761 Feed the dogs 首先该题用接下来问题3的一个特例。但其特殊性在于任意两个区间不包含,导致把区间按左端点(不会存在相同左端点滴,否则必包含)排序之后,依次扫描每个区间,当前区间和前一个区间相交的部分不动,前一区间有而当前区间没有的部分删除,前一区间没有而当前区间有的部分添加。这能保证每个元素正好添删各一次。
POJ 2823 Sliding Window 太特殊了,最大值就是第K 小 , 最小值就是第1小(这是一个很重要的启示:树状数组也可以动态求最值)。单调队列可以弄成线性算法。
HUNNU 10571 Counting Girls 第四届华中南邀请赛 但数据与题目稍有不符 但可以确定每个数大于等于0且不超过200000 。关键是求第X th 到第 Y th 个MM的rating 和要注意下。
KiKi's K-Number 这题就没什么好说的了。求[a+1,MaxnInt]的第K 小的数,先求出[0,a]有多少个数,设为cnt,只要求第K+cnt小的数就可以了。哦,题目说是求第K大的,实际是求第K小的,这有点意思~
【问题三】
问题描述
给定一个序列a[1...n] , 有m 个询问 , 每次询问a[i...j]之间第K小的数。
(引用一句英文:You can assume that n<100001 and m<50001)
算法分析
块状表
如果这道题能够想到用块状表的话,思维复杂度和编程复杂度都不高~,考虑这样操作:
首先预处理,将序列划分成sqrt(N)个小段,每段长[sqrt(N)] ,划分时,将每小段排好序。
然后就是查询了,对区间[i,j]的查询,同样采用二分求比测试值mid小的个数。i和j所在的零散的两小段直接枚举求,中间完整的小段则二分查找求。
这样一次查询时间复杂度为
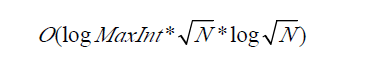
于是总复杂度为:

当然,这里计算量是比较大的,实际写了个程序也是超时的。但当M
比较小时,也未尝不是一种好的选择(或者当开阔思路吧,但对问题四却正好打个擦边球)。
划分树
划分树应该是解决这道题复杂度最低的方法,复杂度为

思想其实很简答,用线段树把整个序列分成若干区间。建树时,对区间[l,r]划分:选择该区间的中位数value(注意:可以先用快速排序对原来序列排个序,于是可以速度得到中位数),将小于等于value的不超过mid-l+1个数划分到[l,mid]区间,其余划分到[mid+1,r]区间,用一个数组把每层划分后的序列保存起来。
然后,查找的时候,Find(x , l , r , k)表示超找x节点内区间[l,r]第K小的数。将该节点区间分成三个区间[seg_left , l-1] , [l , r ] , [r+1 , seg_right]来讨论问题,他们在划分过程中分到[l,mid]区间的个数依次为ls , ms , rs 。若ms<=K自然查左边区间, Find(2*x , l+ls , l+ls+ms-1,K)。否则自然查右边,计算下标很烦啊。有代码在~
代码
void build(lld d ,lld l , lld r ){
if(l == r) return ;
lld i , mid = (l+r)>>1 , j=l , k=mid+1 ;
for(i = l ; i <= r ; ++ i){
s[d][i] = s[d][i-1] ;
if(tr[d][i] <= mid){
s[d][i]++ ;
tr[d+1][j++] = tr[d][i];
}else{
tr[d+1][k++] = tr[d][i];
}
}
build(d+1 ,l , mid);
build(d+1 , mid+1 , r);
}
lld getkth(lld d ,lld lp ,lld rp , lld l , lld r , lld k){
if(lp == rp ) return tr[d][lp] ;
lld mid = (lp + rp)>>1 ;
if(k<=s[d][r]-s[d][l-1])
return getkth(d+1 ,lp , mid ,
lp+s[d][l-1]-s[d][lp-1] , lp+s[d][r]-s[d][lp-1]-1 , k );
else
return getkth(d+1 ,mid+1 , rp , mid+1+(l-lp)-(s[d][l-1]-s[d][lp-1]) ,
mid+(r-lp+1)-(s[d][r]-s[d][lp-1]) , k-(s[d][r]-s[d][l-1]) );
}
归并树
归并树思想就跟简单了,说白了就是线段树每个区间[l,r]内的数都排好序然后保存起来, 从两个儿子到父亲节点,其实就是两个有序序列归并成一个有序序列,所以就称归并树了。
用前面说的二分答案,对测试值mid求rank。查找的时候,将查找区间划分成线段树中若干子区间之并,很明显各个子区间小于mid的个数加起来,就是该区间小于mid的个数。而每个子区间又是有序的,所有二分可以很快找到小区间小于mid的个数。
总结起来,有三次二分:
1.二分答案;
2.查找区间[a,b]划分成不超过log(b - a)个小区间;
3.对每个子区间,二分查找小于mid的个数;
于是,整个算法复杂度为:
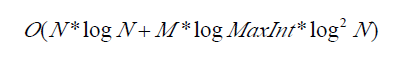
总结:
对本问题,提供了三种算法,其中基于快排的划分算法是最快的;块状表思维和编程都比较简单,但是复杂度比较高;归并树算法思想很好,二分答案,求rank , 后面问题四的算法就是根据这种思维设计出来的。
练习
POJ 2761 Feed the dogs
POJ 2104 K-th Number
NOI 2010 超级刚琴 这题还真有点难度。
思路:划分树+堆+单调队列
对每个区间,起点为i+1,终点在区间[i+L,i+R]。计s[i]=a[0]+a[1]+...+a[i] (规定a[0]=0), 设opt[i,k]表示第k大的s[j] (i+L<=j<=i+R),即opt[i,k] = Max_k { s[j] | i+L<=j<=i+R} (Max_k表示第k大)。
先进行两个预处理工作:
1.将s[1] , s[2] , s[3] , .. s[n] 建成一颗静态划分树。
2.用单调队列预处理出所有opt[i,1]的值,并将所有opt[i,1]-s[i]用一个堆维护起来。当然也可以直接通过查询[i+L,i+R]区间第1大的值来预处理opt[i,1]。
下面开始取值,并更新:依次从堆中取出最大值,设是opt[i,j]-s[i],把它累加至答案,再查询划分树中[i+L , i+R]区间第j+1大的值opt[i,j+1] , 将opt[i,j+1]-s[i]后入堆。直到累加次数为K停止。
【问题四】
问题描述
给定一个原始序列a[1...n] , 有两种操作:
操作一: QUERY i j k 询问当前序列中,a[i...j]之间第k小的数是多少
操作二: CHANG I T 将a[i]改为T ;
输出每次询问的结果。N<=50000 , 操作次数M<=10000
算法分析
块状表
将a[1...n]分成sqrt(N)段,每段长[sqrt(N)],为方便二分查找每段,将每段排好序,对操作二,先删去a[i] , 在插入T , 维护该块得有序性,复杂度为O(sqrt(N))。
对操作一,二分答案,设当前测试值为mid , 先统计两端零散块,O(2*sqrt(N)) 。对中间完整块,每块二分查找,总复杂度为:
线段树+平衡二叉树
序列被线段树划分为区间节点,而每个节点又是一颗平衡二叉树,平衡二叉树放的是该区间段的所有数。
对操作二,依次更新从跟区间到叶子节点区间的平衡树即可(先删除a[i],在插入T),考虑复杂度,第一层规模为N,第二层规模为N/2,第k层规模为 N/2^k 。进行依次操作二的复杂度为:
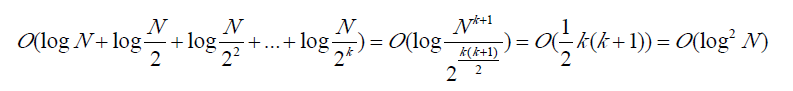
这里 K = [logN]
对操作一:询问区间被划分为不超过[logN]个线段树节点之并,每次区间查找上界为logN 。所以,对每个测试值mid , 耗时(logN)^2 , 故查询一次的复杂度为:
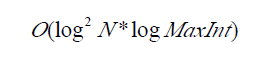
总复杂度为
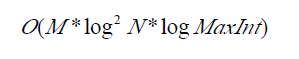
练习
ZOJ 2112 Dynamic Rankings
声明:本文版权归IronOxide所有,博客地址:http://www.cppblog.com/IronOxide/
第一部分 数据结构与算法
1. 设数组中初始状态是递增的,分别用堆排序,快速排序,冒泡排序和归并排序方法对其进行排序(按递增顺序),【冒泡排序】最省时间,【快速排序】最费时间。
2. 红黑树中已经有n个数据,寻找某个key是否存在的时间复杂度为【O(logn)】。
3. 7个相同的球放到4个不同的盒子里的,每个盒子至少放一个,方法有【20】种。
4. 两个无环点链表L1,L2,其长度分别为m和n(m>n),判定L1,L2是否相交的时间复杂度是【O(m+n)】,空间复杂度是(不包括原始链表L1,L2)【O(1)】。
5. 平面上有两个n条直线两两相交,但没有三条直线交与一点,问这n条直线把平面划分成【(n*n+n+2)/2】个区域。
第二部分 软件工程与数据库
在京东商城的商品展示页面下方,总会有一些关于本商品的客户评论信息。模仿该评论模块,有如下三个表:price(商品表),userinfo(用户表),threads(评论主题表)
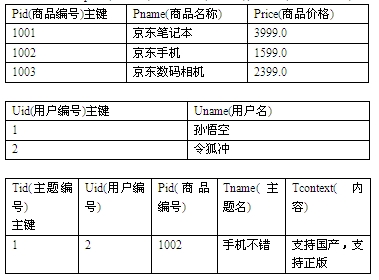
1.请画出以上三张表对应实体的ER图(实体字段标明主键外键即可,用箭头表示)
2.在product表中加入一条新纪录(1004,'京东空调',3000).请写出对应的SQL语句。
INSERT INTO product(Pid,Pname,Price) VALUES(1004,'京东空调',3000);
3.更新product表中pid为1001的商品的价格为3666。请写出对应的SQL语句。
UPDATE product SET Price=3666 WHERE pid=1001;
4.在product表中查询pname中带有"京"的商品。请写出对应的SQL语句。
SELECT * FROM product WHERE pname LIKE '%京%';
5.查询product表中price在1000.0与3000.0之间的所有商品并按照价格降序排序。
SELECT * FROM product WHERE price<3000.0 AND price>1000.0 ORDER BY price DESC;
第三部分 数字与逻辑
1.数字与逻辑
A. 0 2 6 14 【30】 62
B. 11 22 33 45 【57】 71
C. 1 7 10 【不知道】 3 4 -1
2.逻辑推理
A.你让工人为你工作7天,给工人的回报是1根金条。金条平分成相连的7段,你必须在每天结束时给他们1段金条,如果只许你两次把金条弄断,你如何给你的工人付费。
解:假设金条长度为7,将金条分成7=1+2+4(实际上就是2的幂)。
第一天,把长度为1的小段给工人。
第二天,把长度为2的小段给工人,并收回长度为1的小段。
第三天,把长度为1的小段给工人。
第四天,把长度为4的小段给工人,并收回长度为1和长度为2的小段。
第五天,把长度为1的小段给工人。
第六天,把长度为2的小段给工人,并收回长度为1的小段。
第七天,把长度为1的小段给工人。
B.有7克,2克砝码各一个,天平一只,如何只用这些物品3次将140的盐分为50,,90克各一份?
解:答案有多解:
步骤一:把2克的砝码放到天平一段,然后把140克盐往天平两端加,直到平衡。这样就把所有的盐分成69克和71克两部分。
步骤二:把7克砝码和2克砝码放到天平左端,把71克盐网天平两端加,直到平衡。这样左端的盐重31克,右端的盐重40克。
步骤三:把31克盐和69克盐合成一堆,往天平上加,直到平衡。这样就把100克盐分成了两个50克,把上面称出的40克和一个50克合并就得90克,剩余的就是50克了。
第四部分 其他
1. 线程是【进程】中某个单一顺序的控制流。
参考资料:http://baike.baidu.com/view/1053.htm
多线程可以让同一个【进程】的不同部分【并发】执行,从而实现加速。
参考资料:http://baike.baidu.com/view/65706.htm
2.死锁是指【两个或两个以上的进程 】在执行过程中,因争夺资源二造成的一种【互相等待 】现象,若无外力作用,它们将无法推进下去。内存中造成死锁的原因有【可剥夺资源和不可剥夺资源】,【竞争不可剥夺资源】,【竞争临时资源】。
参考资料:http://baike.baidu.com/view/121723.htm
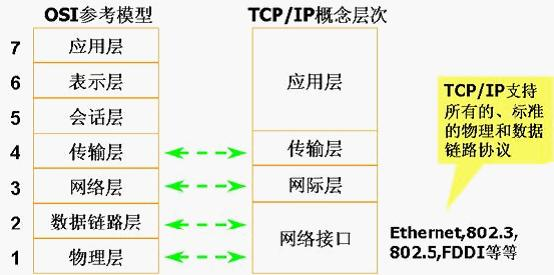
3.ISO网络模型图与TCP/IP网络模型图对应关系为
【应用层】,【表示层】,【会话层】对应【应用层】
【传输层】对应【传输层】
【网络层】对应【网际层】
【数据链路层】【物理层】对应【网络接口】
参考网址http://blog.csdn.net/yuliu0552/article/details/6711659
4.你所见过的最大影子是【月亮的影子】。
5.京东商城的商品搜索功能是整个网站架构中非常重要的一个模块。当用户在搜索栏中写入他们想要搜索的关键字时,往往会有一些热门的关键词出现在提示框中。对于这一功能的实现,你认为需要:
1.用户输入一些关键字查询时,将用户的相关信息(ip,cookie,keyword,username etc.),暂时存储。(临时对象,临时文件等等)。
2.定时从暂时缓存处,一次行读取,写入到数据库中。
3.记录下来关键字后,需要定时从数据库中提取出来。
4.数据库存储建议采用Oracle,因为这个数据量会增加很快,且很大。最好采用分表处理。
5.定时生成相关关键字页面,可以与定时关键字写入数据库放在一起。
由于关键词的存储量非常大,在你看来这么关键词该:
需要将用户关键字记录表分解处理.即每个月的第一天的零点生成一个新的数据库表,名字(user_key_200604),名字后面的数字是年月(六位数字)。用户每次查询时,记录到当月的记录表中,(以后提供的用户的查询日志,默认只提供当月的查询记录)。
参考资料:http://blog.sina.com.cn/s/blog_53fc0ac20100pr7j.html
第五部分 选答题(任选一题作答,使用JAVA,C#,C++等主流语言编写)
1.求给定数组中最大的K个数function array[] findK(array[] a , int k)
解:http://blog.csdn.net/v_JULY_v/article/details/6370650
2.求给定数组中存在的和为最大的子数组,子数组中各元素要求是在原数组中连续的部分
(3,-2,3,4,5,-8)
解:http://blog.csdn.net/v_july_v/article/details/6444021
/*
dp[i] = max(dp[i-1]+a[i] ,a[i]);
Time O(n)
Space O(n)
*/
void MaxSubSeq(int a[] , int n , int &left , int &right , int &answer){
// the start position is left and the end position is right. sum[leftrgiht] = answer
int previous , current , preBegin , preEnd , curBegin , curEnd;
previous = answer = a[0] ;
preBegin = preEnd = 0 ;
left = right = 0 ;
for(int i = 1 ; i < n ; ++ i){
if(previous < 0 ){
current = a[i] ; curBegin = curEnd = i ;
}else{
current = previous + a[i] ;
curBegin = preBegin ; curEnd = i ;
}
previous = current ;
preBegin = curBegin ;
preEnd = curEnd ;
if(answer < current ){
answer = current ;
left = curBegin ; right = curEnd ;
}
}
}
声明:本文版权归IronOxide所有,博客地址:http://www.cppblog.com/IronOxide/ Hash表(Hash Table)
hash表实际上由size个的桶组成一个桶数组table[0...size-1] 。当一个对象经过哈希之后,得到一个相应的value , 于是我们把这个对象放到桶table[ value ]中。当一个桶中有多个对象时,我们把桶中的对象组织成为一个链表。这在冲突处理上称之为拉链法。
负载因子(load factor)
假设一个hash表中桶的个数为 size , 存储的元素个数为used .则我们称 used / size 为负载因子loadFactor . 一般的情况下,当loadFactor<=1时,hash表查找的期望复杂度为O(1). 因此,每次往hash表中添加元素时,我们必须保证是在loadFactor <1的情况下,才能够添加。
容量扩张(Expand)& 分摊转移
当我们添加一个新元素时,一旦loadFactor大于等于1了,我们不能单纯的往hash表里边添加元素。因为添加完之后,loadFactor将大于1,这样也就不能保证查找的期望时间复杂度为常数级了。这时,我们应该对桶数组进行一次容量扩张,让size增大 。这样就能保证添加元素后 used / size 仍然小于等于1 , 从而保证查找的期望时间复杂度为O(1).但是,如何进行容量扩张呢? C++中的vector的容量扩张是一种好方法。于是有了如下思路 : Hash表中每次发现loadFactor==1时,就开辟一个原来桶数组的两倍空间(称为新桶数组),然后把原来的桶数组中元素全部转移过来到新的桶数组中。注意这里转移是需要元素一个个重新哈希到新桶中的,原因后面会讲到。
这种方法的缺点是,容量扩张是一次完成的,期间要花很长时间一次转移hash表中的所有元素。这样在hash表中loadFactor==1时,往里边插入一个元素将会等候很长的时间。
redis中的dict.c中的设计思路是用两个hash表来进行进行扩容和转移的工作:当从第一个hash表的loadFactor=1时,如果要往字典里插入一个元素,首先为第二个hash表开辟2倍第一个hash表的容量,同时将第一个hash表的一个非空桶中元素全部转移到第二个hash表中,然后把待插入元素存储到第二个hash表里。继续往字典里插入第二个元素,又会将第一个hash表的一个非空桶中元素全部转移到第二个hash表中,然后把元素存储到第二个hash表里……直到第一个hash表为空。
这种策略就把第一个hash表所有元素的转移分摊为多次转移,而且每次转移的期望时间复杂度为O(1)。这样就不会出现某一次往字典中插入元素要等候很长时间的情况了。
为了更深入的理解这个过程,先看看在dict.h中的两个结构体:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
dictht指的就是上面说的桶数组,size用来表示容量,一般为2^n ,sizemask(一般为2^n-1,二进制表示为n个1)用来对哈希值取模 , used表示hash表中存储了多少个元素。
dict表示字典,由两个桶数组组成,type是一些函数指针(哈希函数及key,value的一些处理函数)。
d->rehashidx
这个变量的理解很关键:
d->rehashidx 表明了新元素到底是存储到桶数组0中,还是桶数组1中,同时指明了d->h[0]中到底是哪一个桶转移到d->h[1]中。
当d->rehashidx==-1时,这时新添加的元素应该存储在桶数组0里边。
当d->rehashidx!=-1 时,表示应该将桶数组0中的第一个非空桶元素全部转移到桶数组1中来(不妨称这个过程为桶转移,或者称为rehash)。这个过程必须将非空桶中的元素一个个重新哈希放到桶数组1中,因为d->h[1]->sizemask已经不同于d->h[0]->sizemask了。这时新添加的元素应该存储在桶数组1里边,因为此刻的桶数组0的loadFactor为1 ,而桶数组1的loadFactor小于1 。
当发现桶数组0中的元素全部都转移到桶数组1中,即桶数组0为空时。释放桶数组0的空间,把桶数组0的指针指向桶数组1。将d->rehashidx赋值为-1 , 这样桶数组1就空了,下次添加元素时,仍然添加到桶数组0中。直到桶数组0的元素个数超过桶的个数,我们又重新开辟桶数组0的2倍空间给桶数组1 , 同时修改d->rehashidx=0,这样下次添加元素是就添加到桶数组1中去了。
值得注意的是,在每次删除、查找、替换操作进行之前,根据d->rehashidx的状态来判断是否需要进行桶转移。这可以加快转移速度。
下面是一份精简的伪代码,通过依次插入element[1..n]这n个元素到dict来详细描述容量扩张及转移的过程:
//初始化两个hash表
d->h[0].size = 4 ; d->h[1].used = 0 ; //分配四个空桶
d->h[1].size = 0 ; d->h[1].used = 0 ; //初始化一个空表
for(i = 1 ; i <= n ; ++ i){
if( d->rehashidx !=-1 ){
if(d->h[0]->used != 0){
把 d->h[0]中一个非空桶元素转移(重新hash)到 d->h[1]中 ;
// 上一步会使得:
// d->h[0]->used -= 转移的元素个数
// d->h[1]->used += 转移的元素个数 ;
把 element[i] 哈希到 d->h[1]中 ; // d->h[1]->used ++
}else{
//用桶数组1覆盖桶数组0; 赋值前要释放d->h[0]的空间,赋值后重置d->h[1])
d->h[0] = d->h[1] ;
d->rehashidx = -1 ;
把element[i]哈希到d->h[0]中;// d->h[0]->used ++ ;
}
}else if( d->h[0]->used >= d->h[0]->size )
d->h[1] = new bucket[2*d->h[0]->size ];
// d->h[0]->size 等于d->h[0]->size的2倍
把element[i]哈希到d->h[1]中 ; // d->h[1]->used ++
d->rehashidx = 0 ;
}else{
把element[i]哈希到d->h[0]中; // d->h[0]->used ++
}
}
字典的迭代器(Iterator)
分为安全迭代器( safe Iterator )和非安全迭代器 。
安全迭代器能够保证在迭代器未释放之前,字典两个hash表之间不会进行桶转移。
桶转移对迭代器的影响是非常大的,假设一个迭代器指向d->h[0]的某个桶中的元素实体,在一次桶转移后,这个实体被rehash到d->h[1]中。而在d->h[1]中根本不知道哪些元素被迭代器放过过,哪些没有被访问过,这样有可能让迭代器重复访问或者缺失访问字典中的一些元素。所以安全迭代器能够保证不多不少不重复的访问到所有的元素(当然在迭代过程中,不能涉及插入新元素和删除新元素的操作)。
2012年2月21日
#include<iostream>
#include<cstdlib>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<ctime>
#include<algorithm>
#include<set>
#include<map>
#include<queue>
#include<stack>
using namespace std ;
void QuickSort(int a[] , int l , int r){
if(l >= r ) return ;
int x = a[(l+r)>>1] , i = l , j = r ;
do{
while(a[i] < x) ++i ;
while(a[j] > x) --j ;
if(i <= j ) swap(a[i++],a[j--]);
}while(i<=j);
QuickSort(a , i , r) ;
QuickSort(a , l , j) ;
}
int main(){
int a[] = { 0 , -10 , 1 , 23 , 100 , 2340 , -9 , 124 } ;
QuickSort(a , 0 , 7) ;
for(int i = 0 ; i < 8 ; ++ i )
cout << a[i] << endl ;
system("pause");
return 0 ;
}
2011年9月9日
比赛网址:
http://acm.hunnu.edu.cn/online/?action=problem&type=list&courseid=68A.树遍历题。本来以为是个树形动态规划,结果确定了比例,每次只要选择前K个儿子节点就可以了。
B.
C.
D.贪心算法,先优先人进去,让他们呆的时间尽量的长,再出来。
E.写出用电数x和付价f(x)的函数关系。发现这是一个增函数。假设你用电x,邻居用电为y.则f(x+y)=A.f(y)-f(x)=B.
二分求出x+y=C,化简f(y)-f(C-y)=B.发现g(y)=f(y)-f(C-y)也是个增函数。同样二分得出x和y值。
F.后缀数组
G.
H.
I.算出i点到其他所有点的距离,然后计算每个距离出线的次数,得出以i为顶点的等腰三角形个数,累加即可。复杂度为O(N^2logN)。
J.简单的水题啊……
K.把每个区域的学生排序,然后枚举T值。二分计算出T对应的值,取最小值即可。
2010年12月19日
摘要:
Problem A : Network Wars
提交网址:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2676
参考程序:
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeH...
阅读全文