以静态表为例,原理如下图,也就是多个单链表存储在同一个数组中。勉强算开地址哈希表吧,但跟一般开地址哈希表原理
不太一样。存储在同一个数组的目的是节省一个表头指针,有表头指针的哈希表见本主页"
双数组哈希unordered_xxx"相
对于传统的拉链哈希表,这个哈希表的原理不太好理解(传统的好理解,但耗费内存多且速度慢~~)
看上图。使用默认值覆盖的原因是我们原本用它计算陆地坐标,(0,0,0)这个点在海里,我们根本用不上。如果想存入
默认值的话,需要小改一下代码,节点snode增加一个计数器跟指针组成union,默认值放在slot最高端做特殊处理。
显然他比双数组哈希表节约内存,这不必说了,速度当然也要比双数组哈希表稍慢一点,但慢不了太多,不过还是比
常见的数组+链表的拉链哈希表快,当然仅局限于处理整数,处理长字符窜的话,可以改为处理字符窜指针理论上会
好一些。顺便说一句,最适合处理字符窜的数据结构显然不是哈希表,而是trie,如果内存不充裕则应该用有向无环图。
这个表用于PC机上意义不大,用于内存相对紧张,硬件计算能力十分有限的嵌入式则意义非凡。
PC机上我用64位的g++4.8.2和VC++11.0编译OK,别的编译器不知道能否通过。分别在Windows7 X64和
Debian 7.2 X64系统上用g++编译做了测试,仅仅测试了64位伪随机数,跟系统的std::unordered_map做个简
单的比较,结果如下。
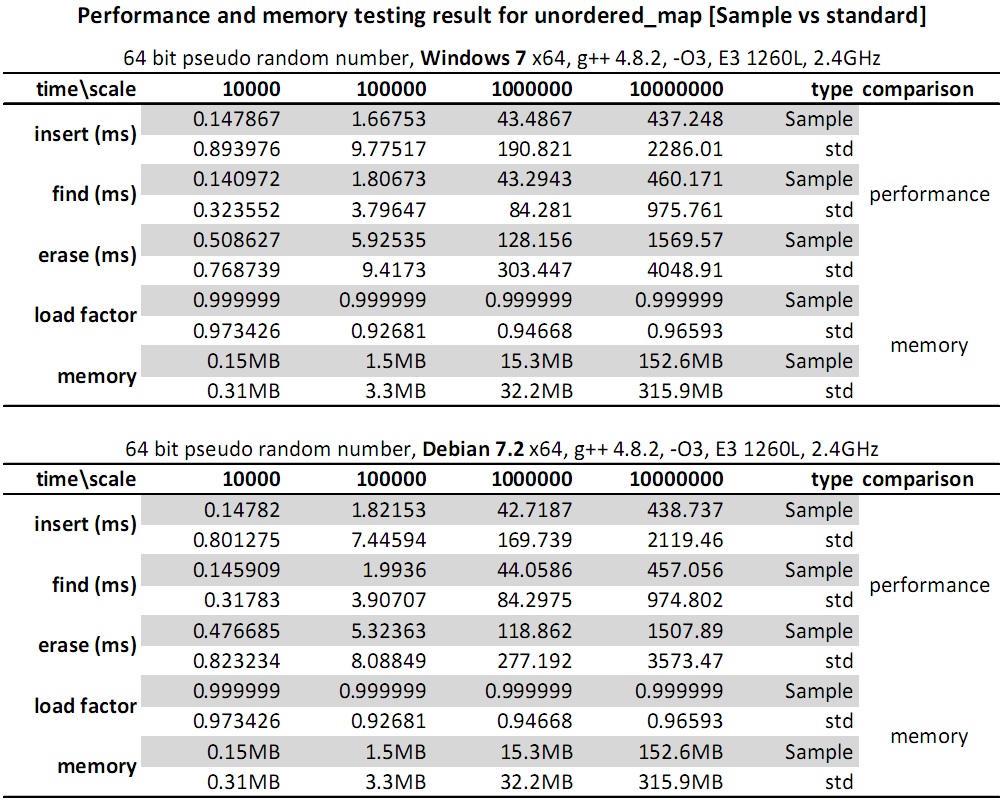
Sample::unordered_map的erase操作比find和insert显著慢的原因是减肥了,当空间利用率50%的时候自动
减肥,释放用不到的空间。实时性要求高且内存碎片敏感的嵌入式里应该禁止resize,减少碎片且提升速度。
上表仅仅是静态表的测试结果,在PC上模拟的。在Linux和Windows都用的g++4.8.2编译器。
源代码
https://github.com/chipsethan/HashTable.git