
2011年5月26日
最近重读APUE2ed,为了便于源码组织其实现都包含了一个”apue.h”头文件,这样就省却了不少代码录入工作,但是这样就将一个库函数调用所需的头文件包含情况隐藏了(如果不清楚,可以阅读apue.h文件查看),本人记忆力不佳,写了一个小脚本来查询一个函数调用所需要包含的头文件,只有简单几行代码。(原来怎么没有想到呢???)
#!/bin/sh
#headcheck:check the headfiles should be included while using the function $1
usage()
{
echo "usage:`basename $0` func_name"
}
if [ $# -ne 1 ]
then
usage
exit 1
else
#这里使用eval命令不但可以置换该变量,还能够执行相应的命令
eval "man 3 $1 | grep \#include"
fi
将得到的headcheck脚本复制到bash的任何PATH路径中即可(然后将alias hc=headcheck写入.bash_profile文件(Fedora) ;这样可以少写一个字符)。
使用方法(如):headcheck readdir 输出:#include <dirent.h>
有些画蛇添足的感觉 直接man好像是更为可取的方法。既然写了,就放这里吧 以后不要做重复工作了。
posted @
2011-05-26 09:44 yibani 阅读(635) |
评论 (1) |
编辑 收藏
2011年5月16日
最近重温APUE,附源码编译指南一份:
1. 源码获取
从APUE的官网下载源码;
2. WKDIR修改
编辑源码解压生成的apue.2e文件夹下的Make.defines.linux
修改WKDIR=/home/sar/apue.2e为你的apue.2e目录,
比如我的apue源码解压在主目录下,那我就改为:
WKDIR=/home/ld/apue.2e
3.nawk
由于Fedora上没有nawk命令,所以得进入apue.2e/std 子目录,编辑linux.mk,修改里面所有的”nawk”为”awk”;(Ubuntu支持nawk命令,可略过此步)
4.stropts.h
如果出现stropts.h缺失的情况,则下载glibc-2.11,解压
cp ./glibc-2.11/streams/stropts.h /usr/include
cp ./glibc-2.11/bits/stropts.h /usr/include/bits
cp ./glibc-2.11/sysdeps/x86_64/bits/xtitypes.h /usr/include/bits
5.ARG_MAX
如果在编译时提示ARG_MAX未定义,可以修改如下:
在apue.2e/include/apue.h中添加一行:
#define ARG_MAX 4096
打开apue.2e/threadctl/getenv1.c 和apue.2e/threadctl/getenv3.c,添加一行:
#include "apue.h"
posted @
2011-05-16 13:22 yibani 阅读(786) |
评论 (0) |
编辑 收藏
2011年4月12日
对于指向同一数组arr[5]中的两个指针之差的验证:
数组如下:ptr = arr;
1: #include <stdio.h>
2: #include <stdlib.h>
3:
4: int main(int argc, char *argv[])
5: {
6: int arr[5] = {1,2,3,4,5};
7: int *ptr = arr;
8: printf("%d\n",ptr[4]-ptr[0]);
9:
10: system("PAUSE");
11: return 0;
12: }
运行输出:4
更换为字符数组,测试结果一样。
《C和指针》P110 分析如下:两个指针相减的结果的类型为ptrdiff_t,它是一种有符号整数类型。减法运算的值为两个指针在内存中的距离(以数组元素的长度为单位,而非字节),因为减法运算的结果将除以数组元素类型的长度。所以该结果与数组中存储的元素的类型无关。
类似的还有如下类型:(点击这里)
size_t是unsigned类型,用于指明数组长度或下标,它必须是一个正数,std::size_t
ptrdiff_t是signed类型,用于存放同一数组中两个指针之间的差距,它可以使负数,std::ptrdiff_t.
size_type是unsigned类型,表示容器中元素长度或者下标,vector<int>::size_type i = 0;
difference_type是signed类型,表示迭代器差距,vector<int>:: difference_type = iter1-iter2.
前二者位于标准类库std内,后二者专为STL对象所拥有。
posted @
2011-04-12 20:59 yibani 阅读(2075) |
评论 (3) |
编辑 收藏
2010年12月3日
著名的黑客站点
国外黑客安全 http://www.deadly.org/ 大量关于OpenBSD的资料文档教程
国外黑客安全 http://www.guninski.com/ 安全专家Guninski的主页,有大量由系统漏洞
国外黑客安全 http://www.sysinternals.com 有很好的windows下的工具及源代码
国外黑客安全 http://www.securityflaw.com/bible/ 入侵检测等文档整理较好的站点
国外黑客安全 http://www.secinf.net/ 网络安全方面的大量文档
国外黑客安全 http://www.incident-response.org 入侵反应,数据恢复工具等
国外黑客安全 http://www.securityfocus.com/ 安全资料整合最好的站
国外黑客安全 http://www.project.honeynet.org/ 由安全界一帮牛人组织的一个project
国外黑客安全 http://www.packetstormsecurity.com 资料全面的安全站
国外黑客安全 http://www.securityportal.com/ 还可以看看的安全站
国外黑客安全 http://www.ussrback.com/ 比较活跃的安全站
国外黑客安全 http://www.attrition.org/ 内容全面的安全站
国外黑客安全 http://www.wiretrip.net/rfp/2/index.asp rfp的安全主页,提供权威的安全信息
http://www.chen13.cn/ 陈13
列国ip地点范畴:http://soft.aidns.cn/IPS/
www.metasploit.com
http://gerix.it/
www.milw0rm.com
www.offensive-security.com/
http://www.offensive-security.com/metasploit-unleashed/
http://www.bindshell.net/tools/beef/
http://forums.remote-exploit.org
http://www.vimeo.com
http://hackersforcharity.org/
http://www.learnsecurityonline.com/
http://hakin9.org
编程网站:
http://www.tutorialspoint.com/index.htm
fast-track:
http://www.thepentest.com/
安定东西 http://sectools.org/
http://www.hackfromacave.com
http://packetstorm.securify.com
Peter Van Eeckhoutte´s Blog:http://www.corelan.be:8800/
新闻和进侵进攻的站点,随时更新进攻的数据库。为每一条进攻提供正文。可盘问进攻数据库。俺进侵的话,第一个就走查它。真的很好哦````
http://sans.org
SANS钻研院的主页,包括大量的钻研谈论和认证安定的消息。安定专家有光 该卖走瞧瞧~
http://securiteam.com
关于安定标题新闻文章的网站,列出了进攻,东西和种种百般的软件
http://securityfocus.com
BugTraq主页,提供有用的进攻消息
http://astalavista.com
一个很棒的黑客东西和进侵进攻的搜索网站
http://anticode.com
进侵进攻,拒尽办事进攻,密钥记录器,邮件,最流行的IRC客户步骤脚本,扫描器,嗅探器,口令解密器,木马等步骤。此网站更新及时,并且维护也很好
http://www.auscert.org.au/
澳大利亚电脑紧急反响小组,包括大量进侵进攻及其劳动原理的消息。
http://http://deny.de
网页包括了大量的进攻要领,文本,脚本和步骤,包括大量消息源并为初学者提供了进门学问 http://cerias.cs.purder.edu
本网站包括非常多的网络安定方面的消息和东西。
http://cert.org
Carngie Mellon大学的计算机紧急反响小组的网站。
http://ciac.llnl.gov
提供病毒消息,及时的电子雄告牌,邮件列表,安定源消息,东西和作零碎的站点。
http://elitehackers.com
为博学的黑客提供的消息雄告牌,是上了品级的黑客走的地方。可找到最新的进侵进攻及对解决要领。 http://first.org
意外事情反响小组的组织
ftp.nec.com
正在/pub/securit目录下面包括一个巨大的东西库
ftp.win.tue.nl
正在/pub/securit目录下包括巨大的安
定东西库
http://geek-speak.net
一个正在计算机安定上努力于white的站点。
http://infowar.co.uk
该网站主要包括文章,建议和东西
http://insecure.org
新闻,进侵进攻(win,linux,solaris等零碎),安定东西和whie,更新好快
http://net.tamu.edu
安定东西正在http://net.tamu.edu/network/public.html
http://wiretrip.net/rfp
Rainforest Puppy的主页,主要是针对CGI脆弱行的消息和进攻NT的消息
http://www-arc.com
可供下载的零碎和网络扫描妻,进侵雄告牌
哎先容这么多的国外黑客资源如今来一点安定材料,下面是邮件列表安定方面的,下面是更新及时的邮件列表
http://www.ntsecurity.net经过正在线签约网页假如NT列表
Alert向mailto:request-alert@iss.net发送邮件,并正在邮件的正文中写进Subscribe alert
Bug Traq向mailto:LISTERV@NETSPACE.ORG发送邮件,并正在邮件的正文中写进subscribe buy traq
Cert mailto:cert-advisory-request@cert.org并正在邮件的正文中写进subscribe
FreeBSD Hackers Digest mailto:Majordomo@FreeBSD.ORG并正在邮件的中文中写进subscribe
Happy Hacker Digest mailto:hacker@techbroker.com并正在邮件的中文中写进subscribe
Linux security mailto:linux-security-request@redhat.com并正在邮件的中文中写进subscribe
Linux Admin mailto:Majordomo@vger,rutgers.edu并正在邮件的中文中写进subscribe linux-admin
NTBuy Traq maito:LISTSERV@LISTSERV.NTBUYTRAQ.COM并正在邮件的中文中写进SUBSCRIBE NTBUYTRAQ firtnamelastname
http://www.albinoblacksheep.com/flash/dubdub.php
http://www.leejan.net/haha/hackgame/index.htm
http://www.changyl.com/cn/sc.asp?classid=85&page=1国内的http://www.tkbb.net/dir/computer_and ... er/hacker/foreignhack/
国内着名安定站点
http://www.netxeyes.com/netxeyes
http://www.chok.d2g.com/ 中国牛之一族
http://www.nsguard.com/nsguard
http://www.haowawa.com/wawa
http://www.janker.org/ 孤单剑客
http://www.6267.net/ 广外步骤员网络
http://bigball.patching.net/olddef.htm 极品黑客
http://trojans.govell.com/ 木马帝国
http://www.westwebmaster.net/kaka/kk/kk
http://www.mayia.com/ 非常蚂蚁
http://fetag.dhs.org/ 飞鹰劳动室之零碎安定
http://badbanana.3322.net/ 〓黑客防地〓
http://www.lls268.com/ 中国鹰派华中站
http://www.vrbrothers.com/ 兄弟劳动组
http://123gz.com/dzc/index.html 猎手与蚂蚁收躲馆
国外黑客站点
http://www.thehackerschoice.com/news.phpthc-news
http://www.2600.com2600thehackerquarterly
http://www.accessdiver.com/accessdiver
http://www.insecure.org/insecure.org
http://www.peckerland.com/default.htmpeckerland
http://www.hackerslab.org/welcometohackerslab.org
国外安定站点
http://www.snort.org/snort
http://ca.com/computerassociates
http://www.foundstone.com/foundstone-knowvulnerabilities
http://www.gfisoftware.com/gfi
http://www.mysunrise.ch/users/rkistler/ ... er-snortmanagmentsystem
http://ntsecurity.nu/ntsecurity.nu
黑客社团
http://www.xfocus.net/ 安定焦点
http://www.heibai.net/ 黑白网络
http://www.sandflee.net/ 灰色轨迹
http://www.cnhacker.net/ 中国黑客同盟
http://chinesehack.org/ 小凤居
http://www.cnredhacker.org/ 中国红客安定技术大同盟
http://www.whitecell.org/index.phpwhitecellsecuritysystems
http://www.nsfocus.com/main.php 绿盟科技
http://www.board365.com/hl.html 红色同盟
http://www.20cn.net/20cn 网络安定小组
http://www.cnknife.org/ 小刀会
http://www.21road.com/hoc/index.htmh ·o·c网络安定小组
http://www.chinawill.com/ 中国鹰派同盟(ceu)
http://www.cnhonker.com/ 中国红客网络技术同盟
http://www.54hack.com/ 中国青年黑客同盟
http://www.itleague.org/ ☆☆it 社团===群英荟萃☆☆
http://www.oldhand.org/oldhand.org
http://www.patching.net/ 补天网
http://www.cnns.net/default.htm 网络安定评价核心
破解组织
http://www.pediy.com/ 瞧雪学院
不错的学习站点
http://www.ttian.net/ 天天安定网
http://cnhope.org/-- 『大学生网络科技同盟 』
几个着名的安定站点- -
着名的贸易化安定雄司
h ttp://www.iss.net( 国外领先的网络安定软件及办事提供商)
http://www.is-one.net (由IIS,软银,趋向雄司配合投资建立的安氏中国)
http://www.nai.com (国外着名的计算机病毒及网络安定软件办事提供商)
http://www.eeye.com (国外着名的安定雄司)
http://www.nsfocus.com (中联绿盟,国内最着名的安定雄司)
http://www.cnns.net (安氏科技,国内雄司)
http://www.atstake.com (@stack雄司的网站,国外)
着名的漏洞雄布站点
http://www.securityfocus.com (国外着名的漏洞雄布站点,即bugtrap)
http://ntsecurity.net (关于windows零碎安定的分析网站)
http://www.cert.org (美国计算机应急反映小组)
http://xforce.iss.net (有IIS雄司雄布的漏洞库)
http://www.bugnet.com (漏洞修补网站)
http://icat.nist.gov/icat.cfm (ICAT漏洞雄布及漏洞库搜索站点)
http://www.chinafirst.org.cn (中国消息安定论坛)
http://www.cert.org.cn/cert/index.php (中国计算机网络应急处理核心)
着名的黑客站点
http://www.phrack.com (国外着名的phrack安定杂志)
http://www.antionline.com (国外经典的黑客站点)
http://whitehats.com (白帽子网站,有最新的IDS规则库下载,关于snort等)
http://lsd-pl.net (雄布最新的exploits步骤)
http://packetstormsecurity.com (国外着名的漏洞库,有大量expolits步骤)
http://oliver.efri.hr/~crv/security/bugs/lists.html (有整理好的最新漏洞库下载)
http://astalavista.box.sk (着名的软件破解站点)
国内着名的同盟站点
http://www.chinahacker.com (中国黑客同盟)
http://www.cnhonker.net (中国红客同盟)
http://www.20cn.net (20CN网络安定小组)
http://www.chinawill.com (中国鹰派)
http://www.hackart.org (黑客技术英文站点)
http://www.hackart.org/chinaforum/forum.asp (黑客技术中文站点)
http://digitalnuke.com/main/index.php (Nuke Group)
国外安全 http://www.deadly.org/ 大量关于OpenBSD的资料文档教程
国外安全 http://www.guninski.com/ 安全专家Guninski的主页,有大量由系统漏洞
国外安全 http://www.sysinternals.com 有很好的windows下的工具及源代码
国外安全 http://www.securityflaw.com/bible/ 入侵检测等文档整理较好的站点
国外安全 http://www.secinf.net/ 网络安全方面的大量文档
国外安全 http://www.incident-response.org 入侵反应,数据恢复工具等
国外安全 http://www.securityfocus.com/ 安全资料整合最好的站
国外安全 http://www.project.honeynet.org/ 由安全界一帮牛人组织的一个project
国外安全 http://www.packetstormsecurity.com 资料全面的安全站
国外安全 http://www.securityportal.com/ 还可以看看的安全站
国外安全 http://www.ussrback.com/ 比较活跃的安全站
国外安全 http://www.attrition.org/ 内容全面的安全站
国外安全 http://www.wiretrip.net/rfp/2/index.asp rfp的安全主页,提供权威的安全信息
国外安全 http://www.antionline.com/ 有些特色栏目的安全站
国外安全 http://www.eeye.com/ eeye公司的主页,提供权威性的安全建议和工具
国外安全 http://www.insecure.org/ Fyodor的主页,nmap的老家,还有exploit
国外安全 http://www.atstake.com/ @stack公司的主页,提供权威的安全建议
国外安全 http://www.bugnet.com/ 提供漏洞修补
国外黑客 http://lsd-pl.net/ LsD的站,最新最有效的exploit
国外黑客 http://www.s0ftpj.org 提供一些水平很高的小工具
国外黑客 http://phrack.org/ Phrack的主页,经典的黑客技术电子杂志
国外黑客 http://www.w00w00.org/ w00w00组织的主页
国外黑客 http://mixter.void.ru/ Mixter的个人主页,不少有用的工具
国外黑客 http://www.thehackerschoice.com/ THC黑客组织的页面,很好的安全文档和工具
国外黑客 www.win2000mag.net Windows & .NET Magazine Network 绝对专业的站点,文章都是一流的
国外黑客 http://www.2600.com/ 2600 Magazine
国外黑客 www.experts-exchange.com 全球有名的社区
国外黑客 www.is-it-true.org 类似于FAQ的站点,资源丰富
国外黑客 www.mixter.warrior2k.com mixter security
国外黑客 www.liun.hektik.org Long Island our Underground Networks
国外黑客 www.ussrback.com ussr is back
国外黑客 www.securiteam.com 非常好的安全文章漏洞利用工具下载站点
国外黑客 www.lsd-pl.net The Last Stage of Delirium Research Group
国外黑客 www. neworder.box.sk Box Network team
国外黑客 www.sysinternals.com sysinternals
国外黑客 www.webattack.com WebAttack Inc
国外黑客 www.blackhat.com Black Hat, Inc
国外黑客 http://p.ulh.as pulhas
http://www.hack.co.za (国外著名黑客站点,较全的Exploit库)
http://www.phrack.org (经典的黑客技术电子杂志)
http://www.antionline.com (国外经典黑客站点)
http://whitehats.com (白帽子网站,有最新的规则库下载,关于Snort等)
http://lsd-pl.net (发布最新的Exploit程序)
http://packetstormsecurity.com (国外著名漏洞库,有大量exploit程序)
http://oliver.efri.hr/~crv/security/bugs/list.html (有整理好的最新漏洞库供下载)
http://astalavista.box.sk (著名的软件破解网站)
http://www.thehackerschoice.com (THC黑客组织的站点,有很多资料和工具)
http://www.insecure.org (Fyoderr的个人站点,即Nmap的老家)
http://www.ishacker.com (DigitalBrain的个人站点,国内)
http://www.sunx.org (Sunx的个人站点,国内)
http://www.docshow.net (Lyawl的个人站点,国内)
posted @
2010-12-03 09:32 yibani 阅读(3155) |
评论 (0) |
编辑 收藏
2010年10月31日
Base: 一种Acid的替代方案
本文是Ebay的架构师在2008年发表给ACM的文章,是一篇解释BASE原则,或者说最终一致性的经典文章. 文中Dan讨论了BASE与ACID原则的基本差异, 以及如何设计大型网站以满足不断增长的可伸缩性需求,期间如何对业务做调整与折衷. 以及一些具体的折衷技术的介绍.
原文链接: BASE: An Acid Alternative
Pdf下载链接: Base
在对数据库进行分区后,为了可用性(Availability)牺牲部分一致性(Consistency)可以显著的提升系统的可伸缩性(Scalability).
By DAN PRITCHETT, EBAY ,Translated by Jametong
Web应用在过去10年变得越来越普及.无论是为最终用户还是为应用开发者构建的应用,对这个应用的希望很可能都是,此应用被最广泛的用户使用-广泛的使用会带来交易的增长.业务如果依赖于持久化,数据存储就很可能成为瓶颈.
扩展任何应用都有两种策略.第一种,也是最简单的一种,就是纵向扩展:将应用迁移到更大更强的计算机上. 目前可用的最大的机器也满足不了它的容量是它最明显的限制.纵向扩展也很昂贵,增加交易容量通常都需要购买下一个更大的机器.纵向扩展通常还会产生对供应商的依赖,从而进一步增加成本.
横向扩展(Horizontal Scaling)提供了更多的灵活性,但也会显著的增加复杂度.横向数据扩展可能沿着两个方向发展.按功能扩展(Functional Scaling)牵涉到按功能对数据进行分组,并将不同的功能组分布在多个不同的数据库上.在功能内部将数据拆分到多个数据库上,也就是进行分片(Sharding),它为横向扩展增加一个新的维度.图-1简要阐释了横向数据扩展策略.

如图-1所示,横向扩展的两种方法可以同时进行运用.用户信息(Users)、产品信息(Products)与交易信息(Transactions)可以存储在不同的数据库中.另外,每个功能区域根据其交易容量(transactional capacity)可以再拆分到多个数据库中.如图所示,功能区域可以相互独立地进行扩展.
功能分区(Functional Partitioning)
功能分区对于实现高可伸缩性相当重要.每一种好的数据库架构都会根据功能将概要(Schema)分解到多张表中.用户(Users)、产品(Products)、交易(Transactions)以及通讯都是功能分区的例子. 常用的方法是,利用诸如外键(foreign key)一类的数据库概念来维持这些功能区域之间的数据一致性.
依赖数据库的约束保证功能组之间的一致性,会导致数据库的不同概要(schema)在部署策略上高度耦合.要支持约束,表必须存在单一的数据库服务器上,当交易率(transaction rate)增长时也无法对其进行横向扩展.很多情况下, 将数据的不同功能组迁移到相互独立的数据库服务器上是最容易实现的向外扩展(Scale-out)方案.
可扩展到非常高的交易量的概要会将不同的功能的数据放置在不同的数据库服务器上.这需要将数据之间的约束从数据库迁移到应用中去. 同时这也将引入一些新的挑战,本文的后续内容会对此进行深入探讨.
CAP定理(CAP Theorem)
Eric Brewer,一位加州大学伯克利分校的教授,Inktomi公司的共同创办人以及首席科学家,作出了以下推测,Web服务无法同时满足以下3个属性(由其首字母构成缩写CAP):
- 一致性(Consistency).客户端知道一系列的操作都会同时发生(生效).
- 可用性(Availability).每个操作都必须以可预期的响应结束.
- 分区容错性(Partition tolerance).即使出现单个组件无法可用,操作依然可以完成.
具体地讲,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性.显然,任何横向扩展策略都要依赖于数据分区;因此,设计人员必须在一致性与可用性之间做出选择.
ACID解决方案
ACID数据库事务极大地简化了应用开发人员的工作.正如其缩写标识所示,ACID事务提供以下几种保证:
- 原子性(Atomicity).事务中的所有操作,要么全部成功,要么全部不做.
- 一致性(Consistency).在事务开始与结束时,数据库处于一致状态.
- 隔离性(Isolation). 事务如同只有这一个操作在被数据库所执行一样.
- 持久性(Durability). 在事务结束时,此操作将不可逆转.(也就是只要事务提交,系统将保证数据不会丢失,即使出现系统Crash,译者补充).
数据库厂商在很久以前就认识到数据库分区的必要性,并引入了一种称为2PC(两阶段提交)的技术来提供跨越多个数据库实例的ACID保证.这个协议分为以下两个阶段:
- 第一阶段,事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段,事务协调器要求每个数据库提交数据.
如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息.这样做的缺陷是什么呢? 我们可以在分区之间获得一致性.如果Brewer的猜测是对的,那么我们一定会影响到可用性,但,怎么可以这样呢?
任何系统的可用性都是执行操作的相关组件的可用性的产物.此陈述的后半段尤其重要.系统中可能会使用但又不是必需的组件,不会降低系统的可用性.在两阶段提交中涉及到两个数据库的事务,它的可用性是这两个数据库中每一个的可用性的产物.例如,如果我们假设每个数据库都有为99.9%的可用性,那么这个事务的可用性就是99.8%,或者说每月43分钟的额外停机时间.
一种ACID的替代方案
如果ACID为分区的数据库提供一致性的选择,那么你如何实现可用性呢?答案是BASE(基本上可用、软(弱)状态、最终一致性).
BASE与ACID截然相反.ACID比较悲观,在每个操作结束时都强制保持一致性,而BASE比较乐观,接受数据库的一致性处于一种动荡不定的状态.虽然,听起来很难应付,实际上这相当好管理,并且可带来ACID无法企及的更高级别的可伸缩性.
BASE的可用性是通过支持局部故障而不是系统全局故障来实现的.下面是一个简单的例子:如果用户分区在5个数据库服务器上,BASE设计鼓励类似的处理方式,这样一个用户数据库的故障只会影响这台特定主机上的那20%的用户.这里不涉及任何魔法,不过,它确实可以带来更高的可感知的系统可用性.
因此,到目前为止,你已经将数据分解到了多个功能组中,并将最繁忙的功能组分区到了多个数据库中,如何在你的应用中应用BASE原则呢?与ACID的典型应用场景相比,BASE需要对逻辑事务中的操作进行更加深入的分析.到底该如何进行分析呢?后续的内容将提供部分指导原则.
一致性模式(Consistency Patterns)
沿着Brewer的猜测,如果BASE在分区数据库中选择保留可用性(Availability), 那么,弱化一定程度的一致性就成为必然的选择.这通常难以决策,因为商业投资方与开发人员都倾向于认为一致性(Consistency)对应用的成功至关重要.哪怕是临时的不一致也瞒不过最终用户,因此,技术部门与产品部门都需要参与进来,以决定将一致性弱化到什么程度.
图-2是一个简单的概要,它阐释了BASE中一致性要考虑的事情.用户表存储用户信息,同时还包含总销售额与总购买额.这些都是运行时的统计.交易表存储每一笔交易,将买家、卖家以及交易金额关联在一起.这些是对实际使用的表进行过度简化后的结果,不过,它已经包含阐释一致性的多个方面的必要元素.
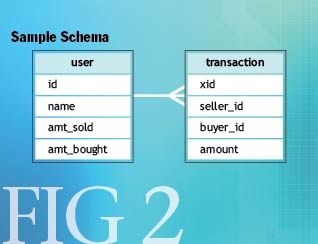
一般来说,功能组之间的一致性要比功能组内部的一致性要更加容易弱化.这个示例概要包含两个功能组:用户与交易.每当售出一个条目(的商品),交易表中就会增加一条记录,买家与卖家的计数器都会被更新.使用ACID风格的事务,SQL语句可能如图-3所示.

用户表中的总销售额的列与总购买额的列可以被认为是交易表的一份缓存(Cache).它的存在是为了提高系统的效率.有鉴于此,一致性的约束可以被弱化. 可以调整一下买家与卖家的期望设置,从而他们的运行结余(running balance)不能立即反映交易的结果.这种情况很常见,实际上,人们经常会遇到交易与运行结余之间的这种延迟(例如,ATM取款或者手机通话).
如何修改SQL语句来弱化一致性要取决于如何定义运行结余,如果它们只是简单的估计,也就是部分交易可以被错过不统计,SQL的修改非常简单,如图-4所示.

现在,我们已经将对用户表与交易表的更新做了解耦.两个表之间的一致性将再也无法保证.实际上,在第一个事务与第二个事务处理间隔发生故障,将导致用户表持久处于不一致的状态,不过,如果合同约定运行时汇总(running total)是估计值的话,这样做也足够了.
如果无法接受估计值,该怎么办呢?如何继续对用户表与交易表的更新进行解耦呢?引入一个持久消息队列来解决此问题. 有多种选择可以实现持久消息.然而,实现此消息队列的最关键的因素是,确保队列的持久化支持与数据库使用同样的资源.要实现队列在不涉及2PC的情况下按事务提交,这样做很有必要 .现在的SQL操作看上看去有点不同了,如图-5所示.

这个例子中的语法有点随意,为了阐释概念对其逻辑也做了大量的简化.通过在插入语句的同一个事务中对持久消息进行排队,可以抓取更新用户运行结余所需的信息.这个事务包含在同一个数据库实例中,因此,它不会影响系统的可用性.
一个独立的消息处理组件,会从队列中取出每条消息,并将此信息应用到用户表.这个例子看似解决了所有的问题,但是,还有一个问题没有解决.为了避免排队时发生2PC,消息是持久化在交易的主机上的.如果在涉及到用户主机的事务中从队列中取出消息,我们仍将遇到2PC的情景.
消息处理组件中的2PC的一种解决方案是什么都不做.通过将更新操作解耦到一个独立的后端(back-end)组件,可以保持面向客户的组件的可用性.业务需要或许可以接受较低的消息处理器的可用性.
不过,假定你的系统完全无法接受2PC.这个问题该如何解决呢?首先,你需要理解等幂概念.如果一个操作被应用一次或多次都能取得同样的结果,就被认为是等幂的.等幂操作非常有用,因为它们允许局部故障,重复执行它们不会改变系统的最终状态.
从等幂的角度看,所选的这个例子是有问题的.更新操作通常不等幂.这个例子中有累加账户列的操作.重复应用此操作显然会导致错误的账户余额.然而,即使是仅仅设定一个值的更新操作也不是等幂的,因为它还涉及到操作执行的顺序.如果系统无法保证更新操作按照接收到的顺序被应用,系统的最终状态也将是不正确的.后面的内容会进一步讨论此问题.
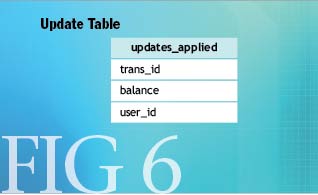
在账户更新的例子中,你需要一种方式来跟踪哪些更新已经应用成功,哪些更新仍然未解决.一种技术是,使用一个表来记录已经应用的那些交易的唯一识别号.
图-6中展示的表会记录交易ID、更新了哪个帐号以及应用此帐号的用户ID.现在,我们的样本伪代码如图-7所示.

这个例子取决于可以窥视队列中的一条消息,并在成功处理后立即删除此消息.如有必要,可以通过两个独立的事务来处理它:消息队列上一个事务,用户数据库上一个事务.数据库操作成功提交,才提交队列操作.目前的算法可以支持局部故障,而且又能提供不依赖于2PC的事务保证.
如果只是关注更新的顺序的话,还有一个更加简单的技术可以确保等幂更新.我们来稍微调整一下我们的示例概要,来阐释面临的挑战以及相应的解决方案(见图-8).
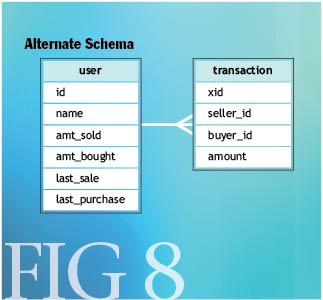
假设两笔购买交易在一个很短的时间窗口内发生,我们的消息系统无法确保顺序操作.您现在面临的情况是,取决于消息被处理的顺序,last_purchase可能出现一个不正确的值.幸运的是,可以通过对SQL语句做点简单调整来解决此类更新问题, 如图-9所描述.

仅仅通过不允许last_purchase时间做逆向调整,就可以做到更新操作顺序不相关.也可以通过这种方法来保护任何更新免遭无序更新(out-of-order update).你还可以尝试使用单调递增的事务ID来取代时间.
消息队列的顺序
关于顺序消息投递,下面这个简短地附属说明可能有用.消息系统可以提供确保消息发送的顺序与接收的顺序一致的能力.不过,支持此功能可能非常昂贵,通常也没有必要,实际上,有时它也只是给出了一种虚假的安全感.
这里提供的例子阐释了如何弱化消息的顺序,并在最终仍然能够提供一个数据库的一致性视图.弱化消息排序所需的开销是名义上的,在大部分情况下,此开销要显著的少于在消息系统中确保消息顺序的开销.
进一步讲,无论互动风格如何,Web应用在语义上都是一个事件驱动的系统.客户端请求以任意顺序达到系统.每个请求所需的处理时间要求也各不相同.整个系统的不同组件的请求调度也是不确定的,导致了消息排队的不确定.要求保持消息的顺序给出的是一种虚假的安全感.简单的事实是,不确定的输入会导致不确定的输出.
弱状态/最终一致性(Soft State/Eventually Consistent)
到此为止,重点一直是为了可用性而权衡牺牲部分一致性.硬币的另外一面是,理解软状态与最终一致性对应用设计有何影响.
由于软件工程师倾向于认为系统是闭环(closed loop)的.从预见投入产生预见的产出方面讲,我们可以这样考虑他们行为的可预测性.这对于创建正确的软件系统非常必要.好的消息是,在大部分情况下使用BASE不会改变一个闭环系统的可预测性,不过,它确实需要从整体上来进行审视.
一个简单的例子就可以帮助解释这一点.考虑这样一个系统,用户可以在此将资产转移给另一个用户.哪种类型的资产都没有关系,它可以是钱或者游戏中的装备.对于这个例子,我们假设,已经通过使用一个用于解耦的消息队列,对如下两个操作进行了解耦:从一个用户取出资产,将资产给另一个用户.
很快,系统就会感觉到有问题与不确定性.在资产离开一个用户到达另一个用户中间,有一段时间的延时. 这个时间窗口的大小由消息系统的设计所决定.无论如何,在开始状态与结束状态之间,始终会有一个时间间隔,在这段时间内, 看似任何用户都不享有这笔资产.
不过,如果我们从用户的视角来考虑这个问题,这个时间间隔可能就是无所谓的或者根本就不存在.无论是接收的用户还是发出的用户可能都不知道资产将在何时到达.如果在发送与接收之间的时间间隔是几秒钟,对于具体沟通资产转移的用户来讲,它将是隐蔽的或确实可以忍受的.在这种状况下,这种系统行为对用户来讲,就是一致并可接受的,即使,我们在实现中依赖了软状态以及最终一致性.
事件驱动架构(Event-Driven Architecture)
如果你确实需要知道,系统将在何时达到一致的状态?你可能需要一种算法,来应用到这个状态上,不过,仅仅在它达到一个与后续请求相关的一致状态时才会被应用.
继续讨论前面的例子,如果在资产到达时,需要通知用户,怎么办? 在将资产交付给接收用户的那个事务内创建一个事件,就可以提供一种机制,当达到一个事先确定的状态时,可以做进一步的处理.EDA(事件驱动架构,Event-Driven Architecture)可以显著改善可伸缩性以及架构的解耦.对于EDA应用的进一步讨论超出了本文的范畴.
结论
显著的扩展系统的交易率,需要以一种全新的方式来考虑如何对资源进行管理.当负载需要分布到大量的组件上时,传统的事务模型会漏洞百出.对操作进行解耦,并依次对它们进行处理,可能提供更好的可用性与伸缩性,不过是以牺牲一致性为代价.BASE提供了一种模型来考虑这种解耦.
References
Dan Pritchett是Ebay的一位技术人员,他过去4年一直是Ebay架构团队的成员.在此岗位上,他与Ebay市场部、Paypal以及Skype的战略、商业、产品与技术团队进行合作.他已经有20年技术公司的工作经历,他服务过的公司包含Sun,HP以及硅谷图形公司(Silicon Graphics),Pritchett具有丰富的技术经历,从网络层协议与操作系统到系统设计与软件模式.他拥有密苏里州Rolla大学的计算机科学学士学位.
posted @
2010-10-31 21:01 yibani 阅读(530) |
评论 (0) |
编辑 收藏
2010年10月20日

盖尔·拉克曼(Gayle Laakmann),Google前员工,目前在宾夕法尼亚大学沃顿商学院攻读MBA。她也是在宾州大学获得计算机科学博士学位。她现在是CareerCup和Seattle Anti-Freeze两家公司的创始人兼CEO。她也是《Cracking the Coding Interview》一书的作者。
您好,盖尔。能先自我简单介绍一下呢?
您好。我先是在微软和苹果实习,后来在Google做了三年工程师。在Google,我也是招聘委员会的成员,面试过120多位本土和国际工程师,我参与了招聘会并审查过数百份简历。我很喜欢在Google工作,但我也想尝试创业。
所以,有了这些难得的经验和见识后,我在2005年成立了CareerCup。我们通过电子书和面试论坛来帮助人们准备技术类面试。
您能否简单介绍一下像微软、Google和亚马逊这类公司的面试过程?面试有几轮?哪些地方需要重点关注?
首先是有一位工程师通过电话面试你;(通过后)再参加有4-6名求职者的群面。至于需要关注的地方,大公司追求优秀的技术能力高于一切。你能否写出合格、整洁和有条理的代码?能否解决有挑战性的问题?
那学生/求职者该怎么掌握这些呢?
一定要实践!熟能生巧虽是老生常谈,但它的确有用。在纸上练习编程,然后照原样输入到电脑上。你会发现错误比你想象的要多的多!
你看到什么样的求职者才会说“哇!这就是我要找的人。”
我希望求职者是:
- 1. 聪明的
- 2. 能写合格的代码
- 3. 关注编写整洁的代码
最后一条是最难的。作为一个面试官,我选人时主要看:当求职者拿到一个问题时,他们是仅在纸上写代码么?或者他们会定义相关的数据结构么?
求职者并不知道面试中所有问题的答案吧?他们怎么回答那些没有提示的问题呢?
一位优秀的面试官,会问那些难度非常高以致于你甚至都不会知道答案的问题。回答这类问题的最好办法是,先简化问题,做假设(比如:假设数组中只有整数);然后,解决简化后的问题;最后,归纳答案。
此外,面试官想知道你的想法,所以尽力说出你的方法,并解释你的操作过程。这将给他们留下对你技术和技能的良好印象。
在求职过程中,您认为GPA有什么样的作用?或者在面试中,纯粹看GPA么?
这个真的取决于公司。一般来说,想要得到初步面试机会,除了诸如经验和兴趣等其他东西之外,GPA也重要。
在他们面试你后,并且正决定是否用你时,GPA不应是阻碍。(否则,他们就没必要面试你了。)
我接触过一些非常聪明的人,但由于各种原因他们的GPA不好,我相信您也应该遇到过吧。您对他们有什么建议呢?你认为什么样的技能才能打动顶级公司?
这些公司真的不关心你的分数。他们看重的是:你是否聪明,你是否有强硬的技术和你是否能努力工作。
你要用其他途径来证明自己。比如:引用你做过的项目,或在开源项目中解决的问题。列举说明你在某一特别困难课程中的分数或班级排名。
在简历中列举你的奖项和参与的项目,保持更简历更新。如果你没有项目经验,竭尽全力去获取经验!这才是那些公司最最看重的东西。如何增加项目经验,请参考伯乐在线的这篇《程序员:增加编程经验的3种途径》。
在求职者去应聘Google这类公司前,请您给他们分享一些建议或注意事项。
练习诸如我们网站上的问题;先在纸上练习算法,然后按原样再输入到电脑中。
还有一件事要注意,关于你简历上的每个工作或项目,你必须能解释其中最艰难的挑战,你最喜欢它的哪部分?你最不喜欢哪部分?你学到了什么?
感谢盖尔接受采访。
编者推荐
除了盖尔·拉克曼有谈论程序员如何面试之外,Google前工程经理王忻曾在2006年6月份也写过一篇文章《如何准备软件工程师的面试 》。
转自:伯乐在线http://www.jobbole.com/entry.php/277
posted @
2010-10-20 16:59 yibani 阅读(403) |
评论 (0) |
编辑 收藏
2010年10月18日
为什么Lisp语言如此先进?(译文)
作者: 阮一峰
日期: 2010年10月14日
上周,《黑客与画家》总算翻译完成,已经交给出版社了。
翻译完这本书,累得像生了一场大病。把书稿交出去的时候,心里空荡荡的,也不知道自己得到了什么,失去了什么。
希望这个中译本和我的努力,能得到读者认同和肯定。
下面是此书中非常棒的一篇文章,原文写于八年前,至今仍然具有启发性,作者眼光之超前令人佩服。由于我不懂Lisp语言,所以田春同学帮忙校读了一遍,纠正了一些翻译不当之处,在此表示衷心感谢。
============================
为什么Lisp语言如此先进?
作者:Paul Graham
译者:阮一峰
英文原文:Revenge of the Nerds
(节选自即将出版的《黑客与画家》中译本)
一、
如果我们把流行的编程语言,以这样的顺序排列:Java、Perl、Python、Ruby。你会发现,排在越后面的语言,越像Lisp。
Python模仿Lisp,甚至把许多Lisp黑客认为属于设计错误的功能,也一起模仿了。至于Ruby,如果回到1975年,你声称它是一种Lisp方言,没有人会反对。
编程语言现在的发展,不过刚刚赶上1958年Lisp语言的水平。
二、
1958年,John McCarthy设计了Lisp语言。我认为,当前最新潮的编程语言,只是实现了他在1958年的设想而已。
这怎么可能呢?计算机技术的发展,不是日新月异吗?1958年的技术,怎么可能超过今天的水平呢?
让我告诉你原因。
这是因为John McCarthy本来没打算把Lisp设计成编程语言,至少不是我们现在意义上的编程语言。他的原意只是想做一种理论演算,用更简洁的方式定义图灵机。
所以,为什么上个世纪50年代的编程语言,到现在还没有过时?简单说,因为这种语言本质上不是一种技术,而是数学。数学是不会过时的。你不应该把Lisp语言与50年代的硬件联系在一起,而是应该把它与快速排序(Quicksort)算法进行类比。这种算法是1960年提出的,至今仍然是最快的通用排序方法。
三、
Fortran语言也是上个世纪50年代出现的,并且一直使用至今。它代表了语言设计的一种完全不同的方向。Lisp是无意中从纯理论发展为编程语言,而Fortran从一开始就是作为编程语言设计出来的。但是,今天我们把Lisp看成高级语言,而把Fortran看成一种相当低层次的语言。
1956年,Fortran刚诞生的时候,叫做Fortran I,与今天的Fortran语言差别极大。Fortran I实际上是汇编语言加上数学,在某些方面,还不如今天的汇编语言强大。比如,它不支持子程序,只有分支跳转结构(branch)。
Lisp和Fortran代表了编程语言发展的两大方向。前者的基础是数学,后者的基础是硬件架构。从那时起,这两大方向一直在互相靠拢。Lisp刚设计出来的时候,就很强大,接下来的二十年,它提高了自己的运行速度。而那些所谓的主流语言,把更快的运行速度作为设计的出发点,然后再用超过四十年的时间,一步步变得更强大。
直到今天,最高级的主流语言,也只是刚刚接近Lisp的水平。虽然已经很接近了,但还是没有Lisp那样强大。
四、
Lisp语言诞生的时候,就包含了9种新思想。其中一些我们今天已经习以为常,另一些则刚刚在其他高级语言中出现,至今还有2种是Lisp独有的。按照被大众接受的程度,这9种思想依次是:
1. 条件结构(即"if-then-else"结构)。现在大家都觉得这是理所当然的,但是Fortran I就没有这个结构,它只有基于底层机器指令的goto结构。
2. 函数也是一种数据类型。在Lisp语言中,函数与整数或字符串一样,也属于数据类型的一种。它有自己的字面表示形式(literal representation),能够储存在变量中,也能当作参数传递。一种数据类型应该有的功能,它都有。
3. 递归。Lisp是第一种支持递归函数的高级语言。
4. 变量的动态类型。在Lisp语言中,所有变量实际上都是指针,所指向的值有类型之分,而变量本身没有。复制变量就相当于复制指针,而不是复制它们指向的数据。
5. 垃圾回收机制。
6. 程序由表达式(expression)组成。Lisp程序是一些表达式区块的集合,每个表达式都返回一个值。这与Fortran和大多数后来的语言都截然不同,它们的程序由表达式和语句(statement)组成。
区分表达式和语句,在Fortran I中是很自然的,因为它不支持语句嵌套。所以,如果你需要用数学式子计算一个值,那就只有用表达式返回这个值,没有其他语法结构可用,因为否则就无法处理这个值。
后来,新的编程语言支持区块结构(block),这种限制当然也就不存在了。但是为时已晚,表达式和语句的区分已经根深蒂固。它从Fortran扩散到Algol语言,接着又扩散到它们两者的后继语言。
7. 符号(symbol)类型。符号实际上是一种指针,指向储存在哈希表中的字符串。所以,比较两个符号是否相等,只要看它们的指针是否一样就行了,不用逐个字符地比较。
8. 代码使用符号和常量组成的树形表示法(notation)。
9. 无论什么时候,整个语言都是可用的。Lisp并不真正区分读取期、编译期和运行期。你可以在读取期编译或运行代码;也可以在编译期读取或运行代码;还可以在运行期读取或者编译代码。
在读取期运行代码,使得用户可以重新调整(reprogram)Lisp的语法;在编译期运行代码,则是Lisp宏的工作基础;在运行期编译代码,使得Lisp可以在Emacs这样的程序中,充当扩展语言(extension language);在运行期读取代码,使得程序之间可以用S-表达式(S-expression)通信,近来XML格式的出现使得这个概念被重新"发明"出来了。
五、
Lisp语言刚出现的时候,它的思想与其他编程语言大相径庭。后者的设计思想主要由50年代后期的硬件决定。随着时间流逝,流行的编程语言不断更新换代,语言设计思想逐渐向Lisp靠拢。
思想1到思想5已经被广泛接受,思想6开始在主流编程语言中出现,思想7在Python语言中有所实现,不过似乎没有专用的语法。
思想8可能是最有意思的一点。它与思想9只是由于偶然原因,才成为Lisp语言的一部分,因为它们不属于John McCarthy的原始构想,是由他的学生Steve Russell自行添加的。它们从此使得Lisp看上去很古怪,但也成为了这种语言最独一无二的特点。Lisp古怪的形式,倒不是因为它的语法很古怪,而是因为它根本没有语法,程序直接以解析树(parse tree)的形式表达出来。在其他语言中,这种形式只是经过解析在后台产生,但是Lisp直接采用它作为表达形式。它由列表构成,而列表则是Lisp的基本数据结构。
用一门语言自己的数据结构来表达该语言,这被证明是非常强大的功能。思想8和思想9,意味着你可以写出一种能够自己编程的程序。这可能听起来很怪异,但是对于Lisp语言却是再普通不过。最常用的做法就是使用宏。
术语"宏"在Lisp语言中,与其他语言中的意思不一样。Lisp宏无所不包,它既可能是某样表达式的缩略形式,也可能是一种新语言的编译器。如果你想真正地理解Lisp语言,或者想拓宽你的编程视野,那么你必须学习宏。
就我所知,宏(采用Lisp语言的定义)目前仍然是Lisp独有的。一个原因是为了使用宏,你大概不得不让你的语言看上去像Lisp一样古怪。另一个可能的原因是,如果你想为自己的语言添上这种终极武器,你从此就不能声称自己发明了新语言,只能说发明了一种Lisp的新方言。
我把这件事当作笑话说出来,但是事实就是如此。如果你创造了一种新语言,其中有car、cdr、cons、quote、cond、atom、eq这样的功能,还有一种把函数写成列表的表示方法,那么在它们的基础上,你完全可以推导出Lisp语言的所有其他部分。事实上,Lisp语言就是这样定义的,John McCarthy把语言设计成这个样子,就是为了让这种推导成为可能。
六、
就算Lisp确实代表了目前主流编程语言不断靠近的一个方向,这是否意味着你就应该用它编程呢?
如果使用一种不那么强大的语言,你又会有多少损失呢?有时不采用最尖端的技术,不也是一种明智的选择吗?这么多人使用主流编程语言,这本身不也说明那些语言有可取之处吗?
另一方面,选择哪一种编程语言,许多项目是无所谓的,反正不同的语言都能完成工作。一般来说,条件越苛刻的项目,强大的编程语言就越能发挥作用。但是,无数的项目根本没有苛刻条件的限制。大多数的编程任务,可能只要写一些很小的程序,然后用胶水语言把这些小程序连起来就行了。你可以用自己熟悉的编程语言,或者用对于特定项目来说有着最强大函数库的语言,来写这些小程序。如果你只是需要在Windows应用程序之间传递数据,使用Visual Basic照样能达到目的。
那么,Lisp的编程优势体现在哪里呢?
七、
语言的编程能力越强大,写出来的程序就越短(当然不是指字符数量,而是指独立的语法单位)。
代码的数量很重要,因为开发一个程序耗费的时间,主要取决于程序的长度。如果同一个软件,一种语言写出来的代码比另一种语言长三倍,这意味着你开发它耗费的时间也会多三倍。而且即使你多雇佣人手,也无助于减少开发时间,因为当团队规模超过某个门槛时,再增加人手只会带来净损失。Fred Brooks在他的名著《人月神话》(The Mythical Man-Month)中,描述了这种现象,我的所见所闻印证了他的说法。
如果使用Lisp语言,能让程序变得多短?以Lisp和C的比较为例,我听到的大多数说法是C代码的长度是Lisp的7倍到10倍。但是最近,New Architect杂志上有一篇介绍ITA软件公司的文章,里面说"一行Lisp代码相当于20行C代码",因为此文都是引用ITA总裁的话,所以我想这个数字来自ITA的编程实践。 如果真是这样,那么我们可以相信这句话。ITA的软件,不仅使用Lisp语言,还同时大量使用C和C++,所以这是他们的经验谈。
根据上面的这个数字,如果你与ITA竞争,而且你使用C语言开发软件,那么ITA的开发速度将比你快20倍。如果你需要一年时间实现某个功能,它只需要不到三星期。反过来说,如果某个新功能,它开发了三个月,那么你需要五年才能做出来。
你知道吗?上面的对比,还只是考虑到最好的情况。当我们只比较代码数量的时候,言下之意就是假设使用功能较弱的语言,也能开发出同样的软件。但是事实上,程序员使用某种语言能做到的事情,是有极限的。如果你想用一种低层次的语言,解决一个很难的问题,那么你将会面临各种情况极其复杂、乃至想不清楚的窘境。
所以,当我说假定你与ITA竞争,你用五年时间做出的东西,ITA在Lisp语言的帮助下只用三个月就完成了,我指的五年还是一切顺利、没有犯错误、也没有遇到太大麻烦的五年。事实上,按照大多数公司的实际情况,计划中五年完成的项目,很可能永远都不会完成。
我承认,上面的例子太极端。ITA似乎有一批非常聪明的黑客,而C语言又是一种很低层次的语言。但是,在一个高度竞争的市场中,即使开发速度只相差两三倍,也足以使得你永远处在落后的位置。
附录:编程能力
为了解释我所说的语言编程能力不一样,请考虑下面的问题。我们需要写一个函数,它能够生成累加器,即这个函数接受一个参数n,然后返回另一个函数,后者接受参数i,然后返回n增加(increment)了i后的值。
Common Lisp的写法如下:
(defun foo (n)
(lambda (i) (incf n i)))
Ruby的写法几乎完全相同:
def foo (n)
lambda {|i| n += i } end
Perl 5的写法则是:
sub foo {
my ($n) = @_;
sub {$n += shift}
}
这比Lisp和Ruby的版本,有更多的语法元素,因为在Perl语言中,你不得不手工提取参数。
Smalltalk的写法稍微比Lisp和Ruby的长一点:
foo: n
|s|
s := n.
^[:i| s := s+i. ]
因为在Smalltalk中,局部变量(lexical variable)是有效的,但是你无法给一个参数赋值,因此不得不设置了一个新变量,接受累加后的值。
Javascript的写法也比Lisp和Ruby稍微长一点,因为Javascript依然区分语句和表达式,所以你需要明确指定return语句,来返回一个值:
function foo (n) {
return function (i) {
return n += i } }
(实事求是地说,Perl也保留了语句和表达式的区别,但是使用了典型的Perl方式处理,使你可以省略return。)
如果想把Lisp/Ruby/Perl/Smalltalk/Javascript的版本改成Python,你会遇到一些限制。因为Python并不完全支持局部变量,你不得不创造一种数据结构,来接受n的值。而且尽管Python确实支持函数数据类型,但是没有一种字面量的表示方式(literal representation)可以生成函数(除非函数体只有一个表达式),所以你需要创造一个命名函数,把它返回。最后的写法如下:
def foo (n):
s = [n]
def bar (i):
s[0] += i
return s[0]
return bar
Python用户完全可以合理地质疑,为什么不能写成下面这样:
def foo (n):
return lambda i: return n += i
或者:
def foo (n):
lambda i: n += i
我猜想,Python有一天会支持这样的写法。(如果你不想等到Python慢慢进化到更像Lisp,你总是可以直接......)
在面向对象编程的语言中,你能够在有限程度上模拟一个闭包(即一个函数,通过它可以引用由包含这个函数的代码所定义的变量)。你定义一个类(class),里面有一个方法和一个属性,用于替换封闭作用域(enclosing scope)中的所有变量。这有点类似于让程序员自己做代码分析,本来这应该是由支持局部作用域的编译器完成的。如果有多个函数,同时指向相同的变量,那么这种方法就会失效,但是在这个简单的例子中,它已经足够了。
Python高手看来也同意,这是解决这个问题的比较好的方法,写法如下:
def foo (n):
class acc:
def _ _init_ _ (self, s):
self.s = s
def inc (self, i):
self.s += i
return self.s
return acc (n).inc
或者
class foo:
def _ _init_ _ (self, n):
self.n = n
def _ _call_ _ (self, i):
self.n += i
return self.n
我添加这一段,原因是想避免Python爱好者说我误解这种语言。但是,在我看来,这两种写法好像都比第一个版本更复杂。你实际上就是在做同样的事,只不过划出了一个独立的区域,保存累加器函数,区别只是保存在对象的一个属性中,而不是保存在列表(list)的头(head)中。使用这些特殊的内部属性名(尤其是__call__),看上去并不像常规的解法,更像是一种破解。
在Perl和Python的较量中,Python黑客的观点似乎是认为Python比Perl更优雅,但是这个例子表明,最终来说,编程能力决定了优雅。Perl的写法更简单(包含更少的语法元素),尽管它的语法有一点丑陋。
其他语言怎么样?前文曾经提到过Fortran、C、C++、Java和Visual Basic,看上去使用它们,根本无法解决这个问题。Ken Anderson说,Java只能写出一个近似的解法:
public interface Inttoint {
public int call (int i);
}
public static Inttoint foo (final int n) {
return new Inttoint () {
int s = n;
public int call (int i) {
s = s + i;
return s;
}};
}
这种写法不符合题目要求,因为它只对整数有效。
当然,我说使用其他语言无法解决这个问题,这句话并不完全正确。所有这些语言都是图灵等价的,这意味着严格地说,你能使用它们之中的任何一种语言,写出任何一个程序。那么,怎样才能做到这一点呢?就这个小小的例子而言,你可以使用这些不那么强大的语言,写一个Lisp解释器就行了。
这样做听上去好像开玩笑,但是在大型编程项目中,却不同程度地广泛存在。因此,有人把它总结出来,起名为"格林斯潘第十定律"(Greenspun's Tenth Rule):
"任何C或Fortran程序复杂到一定程度之后,都会包含一个临时开发的、只有一半功能的、不完全符合规格的、到处都是bug的、运行速度很慢的Common Lisp实现。"
如果你想解决一个困难的问题,关键不是你使用的语言是否强大,而是好几个因素同时发挥作用(a)使用一种强大的语言,(b)为这个难题写一个事实上的解释器,或者(c)你自己变成这个难题的人肉编译器。在Python的例子中,这样的处理方法已经开始出现了,我们实际上就是自己写代码,模拟出编译器实现局部变量的功能。
这种实践不仅很普遍,而且已经制度化了。举例来说,在面向对象编程的世界中,我们大量听到"模式"(pattern)这个词,我觉得那些"模式"就是现实中的因素(c),也就是人肉编译器。 当我在自己的程序中,发现用到了模式,我觉得这就表明某个地方出错了。程序的形式,应该仅仅反映它所要解决的问题。代码中其他任何外加的形式,都是一个信号,(至少对我来说)表明我对问题的抽象还不够深,也经常提醒我,自己正在手工完成的事情,本应该写代码,通过宏的扩展自动实现。
(完)
文档信息
posted @
2010-10-18 00:07 yibani 阅读(419) |
评论 (0) |
编辑 收藏
2010年10月14日
结对编程
目录
- 简介
- 结对编程的优势
编辑本段
简介
结对编程技术是一个非常简单和直观的概念:两位程序员肩并肩地坐在同一台电脑前合作完成同一个设计。同一个算法、同一段代码或同一组测试、与两位程序员各自独立工作相比.结对编程往往只需花费大约一半的时间就能编写出质量更高的代码, 但是,人与人之间的合作不是一件简单的事情——尤其当人们都早已习惯了独自工作的时候、实施结对编程技术将给软件项目的开发工作带来好处.只是这些好处必须经过缜密的思考和计划才能真正体现出来。而另一方面,两个有经验的人可能会发现配对编程里没有什么技能的转移,但是让他们在不同的抽象层次解决同一个问题会让他们更快地找到解决方案,而且错误更少。
结对编程还有其他多种好处:
1、直接的、连续的代码回顾。
2、与别人工作会增加责任和纪律性。
3、同时理解一个问题。
4、在有人盯着的时候去偷懒要困难得多!
两个程序员具有相同的缺点和盲点的可能性很小,所以我们当我们采用结对编程的时候会获得一个强大的解决方案。而这个解决方案恰恰是其它软件工程方法学中所没有的。
在我们平时的编程当中,如果遇到一个非常难解决的问题(困难到对该项目产生厌烦的态度),那么你势必会希望录求帮助,无论是从信息量庞大的Internet网络里,还是从身边的技术大师里,你都会拼了老命去解决(前提是你有对计算机知识的势爱)。这个时候不妨采用结对编程试一下,其它的不说,可能感觉就不同。
编辑本段
结对编程的优势
其实结对编程坐起来很简单也很有趣,找个水平差的不太远的程序员和自己配成一对。只用一台计算机,大家选一个人坐在键盘前面负责输入,另一个人坐在后面口述。两个人要不断的交流,频率不应低于一分钟一次。整个的设计思想由后面只动口不动手的人主导,而由操键盘的人做实现。由于人的思维速度是快于输入代码的速度的。那么观看的人可以有空闲的时间做额外的思考,观察代码写的有没有问题,结构有没有问题。
如果程序员的经验积累足够,是很容易看出存在潜在问题的代码的,即表面上实现了功能,但实际上是一种糟糕的做法。这在XP中被称为代码坏味道,在 Martin Fowler的《重构》一书中有详细的介绍。两个有经验的程序员同时在一起工作,看起来好像浪费了一个人的时间:但实际上的效果确实完成了更高质量的代码。程序编的不那么容易出BUG,而且代码页写得更为优雅和紧凑.
关于结对编程,发现了一些新的受益之处。首先,它可以促进参与项目的程序员自身的提高,一对程序员工作的时候,水平较低的一方会潜移默化地受水平略高的程序员影响,学到一些新的东西。而水平高的一方同样因为不断地把自己的想法说出来而整理了自己的思路。
其次,一定时间周期地打乱配对,让参与项目的人员相互转换位置,使得维护繁杂的文档变得不那么重要。大家分组打乱后,口头的交流很容易让所有人都熟悉每个模块,这样对于公司也很有好处,项目中万一有人离开,也不至于影响到整个项目。最后,开发过程变得更为有趣,任何人的交流变得很多,大家关系更为融洽。
另外想补充一点的是,讲解XP的书籍上都没有提到,但是实际上却存在的一点:结对编程使得程序员被迫提高了工作效率。如果单独工作,在遇到困难的时候,并不是所有人都立刻积极地去解决问题,这时或许会上网和网友聊聊天,看看无关的网站等等。有可能因为工作的打断,大半天的时间都浪费了。看起来,程序员每天都在加班,实际有效工作时间往往还打不到6个小时。而结对编程有一种相互督促的作用,在一边工作疲惫状态不好使,另一边会起一个鼓励和激发斗志的作用。
而且两个人共用一台电脑,略带私人性质的聊天活动都会很自觉地不去进行了。结果一天下来,新实验结对编程的程序员都会喊累,神经紧绷8个小时的工作不累才怪。
从这个角度看,严格限制结对编程的程序员不准加班是合理的,实际上,开始每天甚至不必限制8小时工作,每天这样工作6小时队项目同样是非常高效的。
当两个人不断的互换角色,以至于最后谁也记不清哪行代码是谁敲的;团队内循环的分组以至于分不清到底那个模块该谁负责;反而大家的感觉会不错。整个项目的代码是团队共有,而不再是个人作品了。
- 扩展阅读:
posted @
2010-10-14 17:10 yibani 阅读(406) |
评论 (0) |
编辑 收藏
2010年9月17日
在31年前(1979年),一名刚获得博士学位的研究员,为了开发一个软件项目发明了一门新编程语言,该研究员名为Bjarne Stroustrup,该门语言则命名为——C with classes,四年后改称为C++。C++是一门通用编程语言,支持多种编程范式,包括过程式、面向对象(object-oriented programming, OP)、泛型(generic programming, GP),后来为泛型而设计的模版,被发现及证明是图灵完备的,因此使C++亦可支持模版元编程范式(template metaprogramming, TMP)。C++继承了C的特色,既为高级语言,又含低级语言功能,可同时作为系统和应用编程语言。
C++广泛应用在不同领域,使用者以数百万计。根据近十年的调查,C++的流行程度约稳定排行第3位(于C/Java之后)。 C++经历长期的实践和演化,才成为今日的样貌。1998年,C++标准委员会排除万难,使C++成为ISO标准(俗称C++98),当中含非常强大的标准模版库(standard template library, STL)。之后委员会在2005年提交了有关标准库的第一个技术报告(简称TR1),并为下一个标准C++0x而努力。可惜C++0x并不能在200x年完成,各界希望新标准能于2011年内出台。
流行的C++编译器中,微软Visual C++ 2010已实现部分C++0x语法并加入TR1扩充库,而gcc对C++0x语法和库的支持比VC2010更多。
应否选择C++
哪些程序适宜使用C++?
C++并非万能丹,我按经验举出一些C++的适用时机。
- C++适合构造程序中需求较稳定的部分,需求变化较大的部分可使用脚本语言;
- 程序须尽量发挥硬件的最高性能,且性能瓶颈在于CPU和内存;
- 程序须频繁地与操作系统或硬件沟通;
- 程序必须使用C++框架/库,如大部分游戏引擎(如Unreal/Source)及中间件(如Havok/FMOD),虽然有些C++库提供其他语言的绑定,但通常原生的API性能最好、最新;
- 项目中某个目标平台只提供C++编译器的支持。
按应用领域来说,C++适用于开发服务器软件、桌面应用、游戏、实时系统、高性能计算、嵌入式系统等。
使用C++还是C?
C++和C的设计哲学并不一样,两者取舍不同,所以不同的程序员和软件项目会有不同选择,难以一概而论。与C++相比,C具备编译速度快、容易学习、显式描述程序细节、较少更新标准(后两者也可同时视为缺点)等优点。在语言层面上,C++包含绝大部分C语言的功能(例外之一,C++没有C99的变长数组VLA),且提供OOP和GP的特性。但其实用C也可实现OOP思想,亦可利用宏去实现某程度的GP,只不过C++的语法能较简洁、自动地实现OOP/GP。C++的RAII(resource acquisition is initialization,资源获取就是初始化)特性比较独特,C/C#/Java没有相应功能。回顾历史,Stroustrup开发的早期C++编译器Cpre/Cfront是把C++源代码翻译为C,再用C编译器编译的。由此可知,C++编写的程序,都能用等效的C程序代替,但C++在语言层面上提供了OOP/GP语法、更严格的类型检查系统、大量额外的语言特性(如异常、RTTI等),并且C++标准库也较丰富。有时候C++的语法可使程序更简洁,如运算符重载、隐式转换。但另一方面,C语言的API通常比C++简洁,能较容易供其他语言程序调用。因此,一些C++库会提供C的API封装,同时也可供C程序调用。相反,有时候也会把C的API封装成C++形式,以支持RAII和其他C++库整合等。
为何C++性能可优于其他语言?
相对运行于虚拟机语言(如C#/Java),C/C++直接以静态形式把源程序编译为目标平台的机器码。一般而言,C/C++程序在编译及链接时可进行的优化最丰富,启动时的速度最快,运行时的额外内存开销最少。而C/C++相对动态语言(如Python/Lua)也减少了运行时的动态类型检测。此外,C/C++的运行行为是确定的,且不会有额外行为(例如C#/Java必然会初始化变量),也不会有如垃圾收集(GC)而造成的不确定性延迟,而且C/C++的数据结构在内存中的布局也是确定的。有时C++的一些功能会使程序性能优于C,当中以内联和模版最为突出,这两项功能使C++标准库的sort()通常比C标准库的qsort()快多倍(C可用宏或人手编码去解决此问题)。另一方面,C/C++能直接映射机器码,之间没有另一层中间语言,因此可以做底层优化,例如使用内部(intrinsic)函数和嵌入汇编语言。然而,许多C++的性能优点并非免费午餐,代价包括较长的编译链接时间和较易出错,因而增加开发时间和成本,这点稍后补充。
我进行了一个简单全局渲染性能测试(512x512像素,每像素10000个采样),C++ 1小时36分、Java 3小时18分、Python约18天、Ruby约351天。评测方式和其他语言的结果详见博文。
C++常见问题
C++源代码跨平台吗?
C++有不错的跨平台能力,但由于直接映射硬件,因性能优化的关系,跨平台能力不及Java及多数脚本语言。然而,实践跨平台的C++软件还是可行的,但须注意以下问题:
- C++标准没有规定原始数据类型(如int)的大小,需要特定大小的类型时,可自订类型(如int32_t),同时对任何类型使用sizeof()而不假设其大小;
- 字节序(byte order)按CPU有所不同,特别要注意二进制输入输出、reinterpret_cast法;
- 原始数据和结构类型的地址对齐有差异;
- 编译器提供的一些编译器或平台专用扩充指令;
- 避免作应用二进制接口(application binary interface, ABI)的假设,例如调用函数时参数的取值顺序在C/C++中没定义,在C++中也不可随便假设RTTI/虚表等实现方式。
总括而言,跨平台C++软件可在头文件中用宏检测编译器和平台,再用宏、typedef、自定平台相关实现等方法去实践跨平台,C++标准不会提供这类帮助。
C++程序容易崩溃?
和许多语言相比,C/C++提供不安全的功能以最优化性能,有可能造成崩溃。但要注意,很多运行时错误,如向空指针/引用解引用、数组越界、堆栈溢出等,其他语言也会报错或抛出异常,这些都是程序问题,而不是语言本身的问题。有些意见认为,出现这类运行时错误,应该尽量写入日志并立即崩溃,不该让程序继续运行,以免造成更大的影响(例如程序继续把内存中错误的数据覆写文件)。若要容错,可按业务把程序分割为多进程,像Chrome或使用fork()的形式。然而,C++有许多机制可以减少错误,例如以string代替C字符串;以vector或array(TR1)代替原始数组(有些实现可在调试模式检测越界);使用智能指针也能减少一些原始指针的问题。另外,我最常遇到的Bug,就是没有初始化成员变量,有时会导致崩溃,而且调试版和发行版的行为可能不同。
C++要手动做内存管理?
C++同时提供在堆栈上的自动局部变量,以及从自由存储(free store)分配的对象。对于后者,程序员需手动释放,或使用不同的容器和智能指针。 C++程序员经常进一步优化内存,自定义内存分配策略以提升效能,例如使用对象池、自定义的单向/双向堆栈区等。虽然C++0x还没加入GC功能,但也可以自行编写或使用现成库。此外,C/C++也可以直接使用操作系统提供的内存相关功能,例如内存映射文件、共享内存等。
使用C++常要重造轮子?
我曾参与的C++项目,都会重造不少标准库已提供的功能,此情况在其他语言中较少出现。我试图分析个中原因。首先,C++标准库相对很多语言来说是贫乏的,各开发者便会重复地制造自订库。从另一个角度看,C++标准库是用C++编写的(很多其他语言不用自身而是用C/C++去编写库),在能力和性能上,自订库和标准库并无本质差别;另外,标准库为通用而设,对不同平台及多种使用需求作取舍,性能上有所影响,例如EA公司就曾发表自制的EASTL规格,描述游戏开发方面对STL的性能及功能需求的特点;此外,多个C++库一起使用,经常会因规范不同而引起冲突,又或功能重叠,所以项目可能须自行开发,或引入其他库的概念或实现(如Boost/TR1/Loki),改写以符合项目规范。
C++编译速度很慢?
错,是非常慢。我认为C++可能是实用程序语言中编译速度最慢的。此问题涉及C++沿用C的编译链接方式,又加入了复杂的类/泛型声明和内联机制,使编译时间倍增。在C++对编译方法改革之前(如module提案),可使用以下技巧改善:第一,使用pimpl手法,因性能损耗应用于调用次数不多的类;第二,仅包含必要头文件,并尽量使用及提供前置声明版本的头文件(如iosfwd);第三采用基于接口的设计,但须注意虚函数调用成本;第四,采用unity build,即把多个cpp文件结合在一个编译单元进行编译;第五,采用分布式生成系统如IncrediBuild。
C++缺乏什么功能?
虽然C++已经非常复杂,但仍缺少很多常见功能。 C++0x作出了不少改善,例如语言方面加入Lambda函数、闭包、类型推导声明等,而库方面则加入正则表达式、采用哈希表的unordered_set/unordered_map、引用计数智能指针shared_ptr/weak_ptr等。但最值得留意的是C++0x引入多线程的语法和库功能,这是C++演进的一大步。然而,模组、GC、反射机制等功能虽有提案,却未加进C++0x。
C++使用建议
为应用挑选特性集
我同意Stroustrup关于使用C++各种技术的回应:“你可以做,不意味着你必须这么做。(Just because you can do it, doesn't mean that you have to.)” C++充满丰富的特性,但同时带来不同问题,例如过分复杂、编译及运行性能的损耗。一般可考虑是否使用多重继承、异常、RTTI,并调节使用模版及模版元编程的程度。使用过分复杂的设计和功能,可能会令部分团队成员更难理解和维护。
为团队建立编程规范
C++的编码自由度很高,容易编写风格迥异的代码,C++本身也没有定义一些标准规范。而且,C++的源文件物理构成,较许多语言复杂。因此,除了决定特性集,每个团队应建立一套编程规范,包括源文件格式(可使用文件模版)、花括号风格。
尽量使用C++风格而非C风格
由于C++有对C兼容的包袱,一些功能可以使用C风格实现,但最好使用C++提供的新功能。最基本的是尽量以具名常量、内联函数和泛型取代宏,只把宏用在条件式编译及特殊情况。旧式的C要求局部变量声明在作用域开端,C++则无此限制,应把变量声明尽量置于邻近其使用的地方,for()的循环变量声明可置于for的括号内。 C++中能加强类型安全的功能应尽量使用,例如避免“万能”指针void *,而使用个别或泛型类型;用bool而非int表示布尔值;选用4种C++ cast关键字代替简单的强制转换。
结合其他语言
如前文所述,C++并非适合所有应用情境,有时可以混合其他语言使用,包括用C++扩展其他语言,或在C++程序中嵌入脚本语言引擎。对于后者,除了使用各种脚本语言的专门API,还可使用Boost或SWIG作整合。
C++学习建议
C++缺点之一,是相对许多语言复杂,而且难学难精。许多人说学习C语言只需一本K&R《C程序设计语言》即可,但C++书籍却是多不胜数。我是从C进入C++,皆是靠阅读自学。在此分享一点学习心得。个人认为,学习C++可分为4个层次:
由于我主要是应用C++,大约只停留于第二、三个层次。然而,C++只是软件开发的一环而已,单凭语言并不能应付业务和工程上的问题。建议读者不要强求几年内“彻底学会C++的知识”,到达第二层左右便从工作实战中汲取经验,有兴趣才慢慢继续学习更高层次的知识。虽然学习C++有难度,但也是相当有趣且有满足感的。
数十年来,C++虽有起伏,但她依靠其使用者而不断得到顽强的生命力,相信在我退休之前都不会与她分离,也希望更进一步了解她,与她走进未来。
本文原于《程序员》2010年8月刊揭载。
posted @
2010-09-17 22:08 yibani 阅读(280) |
评论 (0) |
编辑 收藏