实用云计算环境简述
如今it领域没听说过云计算的绝对是out了,虽然大家都知道云计算,虽然很多高校很多专业都开设了云计算专业,虽然很多人都在讨论云计算,虽然也有少数人走在了应用云计算的前列,然而,可悲的是,大多数人对云计算的认识仅限于amazon、google、microsoft、ibm有能力架设云计算环境,其他公司都靠边,甚至唯他们的云计算才叫云计算,别的企业根本不可能做云计算,各级政府部门最搞笑了,动不动花多少钱引进某某云计算环境,填补某某空白,多少cpu多少机器每秒多少万亿次计算,最终是不是一堆浪费电力的摆设也没有人知道,也没人去过问。
略感欣慰的是,很多企业都在务实地部署自己的云计算环境,大如腾讯、淘宝、百度、小如我们这样刚成立的小公司,其实要部署一个私有云计算环境并没有那么难,以我个人的经验来看,如果有一个精干的小团队,几个人一个月部署一个私有云计算环境是完全可能可行的。在我看来,所谓云计算就是分布式存储+分布式计算,不局限于底下os是win还是*nix,也不局限于是局域网环境还是广域网环境,也不管上面跑的是c++的程序还是javascript的程序,下面简单介绍下我设计的一个即时查询价格的云计算体系:
我一直在win下开发,win用得非常熟练,所以我把云计算环境部署在windows之上,当然也考虑到windows的机器众多,tasknode可轻易找到非常多的目标机器,我部署的云计算环境主要分两类节点,jobserver和tasknode,jobserver主管任务切割、任务调度,tasknode是计算节点。另外还有一些节点,jobowner可连接jobserver并提交任务,并可查询该任务的执行情况,admin可连接jobserver查询jobserver的状态。
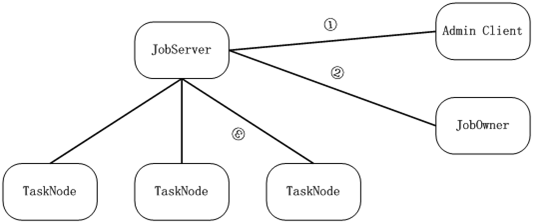
其实这些上篇博客已经写过,我再讲的详细一点,看具体的执行情况,首先jobowner给jobserver提交package,这个package是一个zip文件,包含一组文件,jobowner提交package之后jobserver会根据约定的规则管理package,并在jobserver展开该package,如下:

Jobowner连到jobserver之后,发出如下的命令到jobserver
0x49 0x0 0x0 0x0 0x2 0x0 0xb 0x0 127.0.0.1 0x0 ppsget.dll 0x0
{type:[0,1,2,3,4],rmax:5,wb:"pc",text:"诺基亚 e63"} 0x0
上面是用我设计的一种混合显示格式显示的包数据,可以看到里面带上了ppsget.dll,这就是指定包内部名,其实还可以这样ppsget.dll:getpage,如此一个dll就可支持多个IJobTask输出,getpage只是获得其中一个IJobTask接口(关于IJobTask接口参考上一篇云计算实践2的文章)。具体命令是json格式,主要是为了方便信息传输和解析。Jobserver接收到该命令之后,调用ppsget.dll的IJobTask接口中的split函数,将该任务分解,之后调度Tasknode执行,tasknode收到jobserver发过来的任务之后,检查包名称,如果缺少就会主动向jobserver要求发送相应的包,并进行部署,待部署完成之后从包获取指定的IJobTask接口,执行该接口的map函数,将结果按照约定的格式发给jobserver,最后由jobserver调用IJobTask中的reduce函数进行打包,最后将结果发给jobowner并记录相关Log。
上图中还可看到一个HashCrackCloud.dll,这是另一个云计算环境下破解md5密码的dll,这个上篇文章也写了一下,这里就不详述了。
为使得tasknode可适应各种机器环境,我把tasknode设计为一个dll,该dll内部自己管理消息及任务执行,该dll可被加载到各种容器进程(如gui进程、console进程、service进程)等执行,看下我的tasknode和它的容器进程:
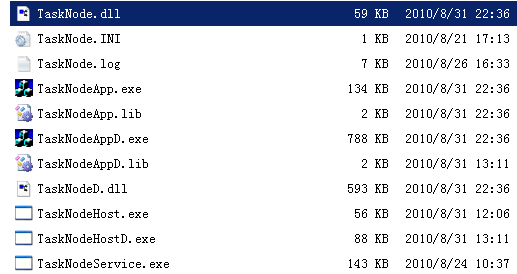
这也算是我的得意设计吧,这样设计的tasknode在windows系统下的确具有很高的灵活性。
这样的tasknode甚至可直接加载在jobserver进程,也可被任意win系列机器的任意进程加载参与运算,用主动加载或被动加载都很方便,极大的方便了云计算环境的部署,反正具体执行的任务都由package完成,tasknode只要按照约定的规则部署 package即可,所以这种云计算环境是非常轻量级又非常灵活的,开发一个新的任务只要做一个新的IJobTask即可,目前我这套体系除了没有考虑太多安全性之外,这个云计算环境的实施还是非常容易的,实际上我们这个价格查询的后台云计算环境只用了不到2周的时间就开发完成。
再看下jobserver记录的每个job的log:

从log中可很容易的分析出一个job每个task的执行情况,并可根据这些数据进行相应的优化处理。
之所以把jobserver和tasknode以及package都写出来,主要是为了表达一个看法,要实现一个简单的云计算环境其实并不难,有经验的团队很容易就能做出来,参考下google的map/reduce论文,按照自己的需要简化实现,真理在实践中,如果只是仰望google、amazon,那就真的是在云中雾里,另一个想要表达的就是云的形式是多种多样的,并不一定amazone、google的云计算环境才是标准的,对实用派来说,形式都是次要的,实用才是关键的。