长期以来,我们始终把GP(泛型编程)作为一种辅助技术,用于简化代码结构、提高开发效率。从某种程度上来讲,这种观念是对的。因为迄今为止,GP技术还只是一种编译期技术。只能在编译期发挥作用,一旦软件完成编译,成为可执行代码,便失去了利用GP的机会。对于现在的多数应用而言,运行时的多态能力显得尤为重要。而现有的GP无法在这个层面发挥作用,以至于我这个“GP迷”也不得不灰溜溜地声称“用OOP构建系统,用GP优化代码”。
然而,不久前,在TopLanguage group上的一次讨论,促使我们注意到runtime GP这个概念。从中,我们看到了希望——使GP runtime化的希望——使得GP有望在运行时发挥其巨大的威力,进一步为软件的设计与开发带来更高的效率和更灵活的结构。
在这个新的系列文章中,我试图运用runtime GP实现一些简单,但典型的案例,来检测runtime GP的能力和限制,同时也可以进一步探讨和展示这种技术的特性。
运行时多态
现在的应用侧重于交互式的运作形式,要求软件在用户输入下作出响应。为了在这种情况下,软件的整体结构的优化,大量使用组件技术,使得软件成为“可组装” 的系统。而接口-实现分离的结构形式很好地实现了这个目标。多态在此中起到了关键性的作用。其中,以OOP为代表的“动多态”(也称为 “subtyping多态”),构建起在运行时可调控的可组装系统。GP作为“静多态”,运用泛化的类型体系,大大简化这种系统的构建,消除重复劳动。另外还有一种鲜为人知的多态形式,被《C++ Template》的作者David Vandevoorde和Nicolai M. Josuttis称为runtime unbound多态。而原来的“动多态”,即OOP多态,被细化为runtime bound多态;“静多态”,也就是模板,则被称为static unbound多态。
不过这种称谓容易引起误解,主要就是unbound这个词上。在这里unbound和bound是指在编写代码时,一个symbol是否同一个具体的类型 bound。从这点来看,由于GP代码在编写之时,面向的是泛型,不是具体的类型,那么GP是unbound的。因为现有的GP是编译期的技术,所以是 static的。OOP的动多态则必须针对一个具体的类型编写代码,所以是bound的。但因为动多态可以在运行时确定真正的类型,所以是runtime 的。至于runtime unbound,以往只出现在动态语言中,比如SmallTalk、Python、Ruby,一种形象地称谓是“duck-typing”多态。关于多态的更完整的分类和介绍可以看
这里。
通过动态语言机制实现的runtime unbound,存在的性能和类型安全问题。但当我们将GP中的concept技术推广到runtime时会发现,rungime unbound可以拥有同OOP动多态相当的效率和类型安全性,但却具有更大的灵活性和更丰富的特性。关于这方面,我已经写过一篇
文章 ,大致描述了一种实现runtime concept的途径(本文的附录里,我也给出了这种runtime concept实现的改进)。
Runtime Concept
Runtime concept的实现并不会很复杂,基本上可以沿用OOP中的“虚表”技术,并且可以更加简单。真正复杂的部分是如何在语言层面表达出这种runtime GP,而不对已有的static GP和其他语言特性造成干扰。在这里,我首先建立一个基本的方案,然后通过一些案例对其进行检验,在发现问题后再做调整。
考虑到runtime concept本身也是concept,那么沿用static concept的定义形式是不会有问题的:
concept myconcept<T> {
T& copy(T& lhs, T const& rhs);
void T::fun();
...
}
具体的concept定义和使用规则,可以参考C++0x的
concept提案或
这篇文章 ,以及
这篇文章 。
另一方面,我们可以通过concept_map将符合一个concept的类型绑定到该concept之上:
concept_map myconcept<MyType> {}
相关内容也可参考上述文件。
有了concept之后,我们便可以用它们约束一个模板:
template<myconcept T>void myfun(T const& val); //函数模板
template<myconcept T>class X //类模板
{
...
};
到此为止,runtime concept同static concept还是同一个事物。它们真正的分离在于使用。对于static concept应用,我们使用一个具体的类型在实例化(特化)一个模板:
X<MyType> x1; //实例化一个类模板
MyType obj1;
myfun(obj1); //编译器推导obj1对象的类型实例化函数模板
myfun<MyType>(obj1); //函数模板的显式实例化
现在,我们将允许一种非常规的做法,以使runtime concept成为可能:
允许使用concept实例化一个模板,或定义一个对象。
X<myconcept> x2;
myconcept* obj2=new myconcept<MyType>;
myfun(obj2); //此处,编译器将会生成runtime版本的myfun
这里的含义非常明确:对于x2,接受任何符合myconcept的类型的对象。obj2是一个“
动态对象”(这里将runtime concept引入的那种不知道真实类型,但符合某个concept的对象称为“动态对象”。而类型明确已知的对象成为“静态对象”),符合myconcept要求。至于实际的类型,随便,只要符合myconcept就行。
这种情形非常类似于传统动多态的interface。但是,它们有着根本的差异。interface是一个具体的类型,并且要求类型通过继承这种形式实现这个接口。而concept则不是一种类型,而是一种“泛型”——具备某种特征的类型的抽象(或集合),不需要在类型创建时立刻与接口绑定。与 concept的绑定(concept_map)可以发生在任何时候。于是,runtime concept实际上成为了一种
非侵入的接口。相比interface这种侵入型的接口,更加灵活便捷。
通过这样一种做法,我们便可以获得一种能够在运行时工作的GP系统。
在此基础上,为了便于后续案例展开,进一步引入一些有用的特性:
- 一个concept的assosiate type被视为一个concept。一个concept的指针/引用(concept_id*/concept_id&,含义是指向一个符合concept_id的动态对象,其实际类型未知),都被视作concept。一个类模板用concept实例化后,逻辑上也是一个concept。
- 动态对象的创建。如果需要在栈上创建动态对象,那么可以使用语法:concept_id<type_id> obj_id; 这里concept_id是concept名,type_id是具体的类型名,obj_id是对象名称。这样,便在栈上创建了一个符合concept_id的动态对象,其实际类型是type_id。
如果需要在堆上创建动态对象,那么可以用语法:concept_id* obj_id=new concept_id<type_id>; 这实际上可以看作“concept指针/引用”。
- concept推导(编译期)。对于表达式concept_id obj_id=Exp,其中Exp是一个表达式,如果表达式Exp的类型是具体的类型,那么obj_id代表了一个静态对象,其类型为Exp的类型。如果表达式Exp的类型是concept,那么obj_id是一个动态对象,其类型为Exp所代表的concept。
那么如何确定Exp是具体类型还是concept?可以使用这么一个规则:如果Exp中涉及的对象,比如函数的实参、表达式的操作数等等,只要有一个是动态对象(类型是concept),那么Exp的类型就是concept;反之,如果所有涉及的对象都是静态对象(类型为具体的类型),那么Exp的类型为相应的具体类型。同样的规则适用于concept*或concept&。
- concept转换。类似在类的继承结构上执行转换。refined concept可以隐式地转换成base concept,反过来必须显式地进行,并且通过concept_cast操作符执行。兄弟concept之间也必须通过concept_cast转换。
- 基于concept的重载,也可以在runtime时执行,实现泛化的dynamic-dispatch操作。
下面,就开始第一个案例。
案例:升级的坦克
假设我们做一个游戏,主题是开坦克打仗。按游戏的惯例,消灭敌人可以得到积分,积分到一定数量,便可以升级。为了简便起见,我们只考虑对主炮升级。第一级的主炮是90mm的;第二级的主炮升级到120mm。主炮分两种,一种只能发射穿甲弹,另一种只能发射高爆弹。因此,坦克也分为两种:能打穿甲弹的和能打高爆弹的。
为了使代码容易开发和维护,我们考虑采用模块化的方式:开发一个坦克的框架,然后通过更换不同的主炮,实现不同种类的坦克和升级:
//一些基本的concept定义
//炮弹头concept
concept Warheads<typename T> {
double explode(TargetType tt); //炮弹爆炸,返回杀伤率。不同弹头,对不同类型目标杀伤率不一样。
}
//炮弹concept,我们关心的当然是弹头,所以用Warheads定义一个associate type
concept Rounds<typename T> {
Warheads WH;
...
}
//主炮concept
concept Cannons<typename T> {
Rounds R;
void T::load(R& r); //装填炮弹,load之后炮弹会存放在炮膛里,不能再load,除非把炮弹打出去
R::WH T::fire(); //开炮,返回弹头。发射后炮膛变空,可以再load
}
//类型和模板定义
//坦克类模板
template<Cannons C>
class Tank
{
...
public:
void load(typenam C::R& r) {
m_cannon.load(r);
}
typename C::R::WH fire() {
return m_cannon.fire();
}
private:
C m_cannon;
};
//主炮类模板
template<Rounds Rd>
class Cannon
{
public:
typedef Rd R;
void load(R& r) {...}
typename R::WH fire() {...}
}
template<Rounds Rd> concept_map Cannons<Cannon<Rd>>{}
//炮弹类模板
template<Warheads W>
class Round
{
public:
typedef W WH;
static const int caliber=W::caliber;
W shoot() {...}
...
};
template<Warhead W> concept_map<Round<W>>{}
//弹头类模板,通过traits把各类弹头的不同行为弹头的代码框架分离,使类型“可组装”
concept WH_Traits<T> {
return T::exploed(int, TargetType, double, Material);
}
template<WH_Traits wht, int c>
class Warhead
{
public:
const static int caliber=c;
double explode(TargetType tt) {
return wht::exploed(c, tt, ...);
}
...
};
template<WH_Traits WHT, int c> concept_map<Warhead<WHT, c>>{}
//弹头traits
struct KE_WHTraits
{
static double exploed(int caliber, TargetType tt, double weight, Material m) {...}
};
concept_map<KE_WHTraits>{}
struct HE_WHTraits
{
static double exploed(int caliber, TargetType tt, double weight, Material m) {...}
};
concept_map<HE_WHTraits>{}
//定义各类弹头
typedef Warhead<KE_WHTraits, 90> WH_KE_90;
typedef Warhead<KE_WHTraits, 120> WH_KE_120;
typedef Warhead<HE_WHTraits, 90> WH_HE_90;
typedef Warhead<HE_WHTraits, 120> WH_HE_120;
//定义各类炮弹
typedef Round<WH_KE_90> Round_KE_90;
typedef Round<WH_KE_120> Round_KE_120;
typedef Round<WH_HE_90> Round_HE_90;
typedef Round<WH_HE_120> Round_HE_120;
//定义各类主炮
typedef Cannon<Round_KE_90> Cannon_KE_90;
typedef Cannon<Round_KE_120> Cannon_KE_120;
typedef Cannon<Round_HE_90> Cannon_HE_90;
typedef Cannon<Round_HE_120> Cannon_HE_120;
//定义各类坦克
typedef Tank<Cannon_KE_90> Tank_KE_90;
typedef Tank<Cannon_KE_120> Tank_KE_120;
typedef Tank<Cannon_HE_90> Tank_HE_90;
typedef Tank<Cannon_HE_120> Tank_HE_120;
于是,当我们开始游戏时,就可以按照玩家的级别创建坦克对象,并且射击:
//第一级玩家,驾驶发射90mm高爆炮弹的坦克
Tank_HE_90 myTank;
Round_HE_90 r1;
myTank.load(r1);
myTank.fire();
//第二级玩家,驾驶发射120mm穿甲弹的坦克
Tank_KE_120 yourTank;
Round_KE_120 r2;
yourTank.load(r2);
yourTank.fire();
//如果这样,危险,炮弹不匹配,小心炸膛
myTank.load(r2); //error
到目前为止,这些代码仅仅展示了静态的GP。concept在这里也只是起到了类型参数约束的作用。但是,在这些代码中,我们可以明显地看到,在运用GP 的参数化类型特性之后,可以很容易地进行组件化。对于一组具备类似行为和结构特征的类型,我们可以通过模板的类型参数,将差异部分抽取出来,独立成所谓的 “traits”或者“policy”。并且通过traits或policy的组合构成不同的产品。在某些复杂的情况下,traits和policy还可以进一步通过traits或policy实现组件化。
接下来,很自然地应当展开runtime GP的运用了。
一个游戏者是可以升级的,为了使得这种升级变得更加灵活,我们会很自然地使用Composite模式。现在,我们可以在Runtime concept的支援下实现GP版的Composite模式:
//坦克的concept
concept tanks<T> {
typename Round;
void T::load(Round&);
Round::WH T::fire();
}
concept_map tanks<Tank_KE_90>{}
concept_map tanks<Tank_HE_90>{}
concept_map tanks<Tank_KE_120>{}
concept_map tanks<Tank_HE_120>{}
//坦克构造函数模板
template<tanks T>
T* CreateTank(WHType type, int level) { //WHType是一个枚举表明炮弹种类
switch(level)
{
case 1:
if(type==wht_KE)
return
new tanks<Tank_KE_90>;
else
return
new tanks<Tank_HE_90>;
case 2:
if(type==wht_KE)
return
new tanks<Tank_KE_120>;
else
return
new tanks<Tank_HE_120>;
default:
throw error("no such tank.");
}
}
//玩家类
class player
{
public:
void update() {
m_pTank=CreateTank(m_tankType, ++m_level);
}
...
private:
int m_level;
WHType m_tankType;
tanks* m_pTank;
};
在类player中,使用了一个concept,而不是一个类型,来定义一个对象。根据前面提到的concept推导规则,m_pTank指向一个动态对象,还是静态对象,取决于为它赋值的表达式类型是concept还是具体类型。在update()函数中,可以看到,m_pTank通过表达式
CreateTank(m_tankType, ++m_level)赋值。那么这个函数的返回类型,将决定m_pTank的类型。CreateTank()是一个模板,返回类型是模板参数,并且是符合concept tanks的类型。关键在于代码中的
return new tanks<...>语句。前文已经说过,这种形式是使用<...>中的类型创建一个符合tanks的动态对象。所以,CreateTank()返回的是动态对象。那么,m_pTank也将指向一个动态对象。在运行时,当玩家达到一定条件,便可以升级。update()成员函数将根据玩家的级别重新创建相应的坦克对象,赋值到m_pTank中。
这里,实际上是利用tanks这个concept描述,充当类型的公有接口。它所具有的特性同动多态的抽象基类是非常相似的。但是所不同的是,如同我在代码中展现的那样,concept作为接口,可以在任何时候定义,同类型绑定。而无需象抽象基类那样,必须在类型定义之前定义。于是,这种非侵入式的接口相比抽象基类拥有更加灵活自由的特性。
然而,事情还没有完。在进一步深化坦克案例后,我们还将发现runtime GP拥有更加有趣和重要的特性。
坦克开炮为的是攻击目标。对目标的毁伤情况直接关系到玩家的生存和得分。所以,我们必须对射击后,目标的损毁情况进行计算。于是编写了这样一组函数:
double LethalityEvaluate(Target& t, double hitRate, WH_KE_90& wh) {...}
double LethalityEvaluate(Target& t, double hitRate, WH_HE_90& wh) {...}
double LethalityEvaluate(Target& t, double hitRate, WH_KE_120& wh) {...}
double LethalityEvaluate(Target& t, double hitRate, WH_HE_120& wh) {...}
Target是目标;hitRate是命中率,根据坦克和目标的位置、射击参数综合计算获得(如果想要更真实,可以加上风向、风力、气温、湿度、海拔等等因素);wh就是发射出来的炮弹了。函数返回杀伤率。如此,我们便可以在射击之后进行评估了:
double l=LethalityEvaluate(house, hr, myTank.fire());
现在,游戏需要进行一些扩展,增加一个升级,允许坦克升级到第三级。到了第三极,主炮的口径就升到头了,但可以升级功能,可以发射穿甲弹和高爆弹。这样,我们就需要一个“两用”的主炮类。但是,实际上并不需要直接做这么一个类,只需要用“两用”的弹药来实例化Cannon模板:
concept Warheads120<T> : Warheads<T> { //120mm炮弹头concept
double LethalityEvaluate(Target& t, double hitRate, T& wh);
}
concept Rounds120<T> : Rounds<T> {}
concept_map Warheads120<WH_KE_120> {} //120mm的穿甲弹属于Warheads120
concept_map Warheads120<WH_HE_120> {} //120mm的高爆弹属于Warheads120
template<WH120 WH> concept_map Rounds120<Round<WH>> {} //所有弹头是Warheads120的炮弹都是属于Rounds120
typedef Canon<Rounds120> Cannon120; //用Rounds120实例化Cannon模板,得到“两用”主炮
一堆炫目的concept和concept_map之后,得到Rounds120,就是所谓的“两用”弹药。作为一个concept,它同两种类型map 在一起,实际上就成了这两个类型的接口。当我们使用Rounds120实例化Cannon<>模板时,也就创建了一个“两用的主炮”(使用 Rounds120弹药的主炮)。如果用这个Cannon120实例化Tank模板,那么就可以得到第三级坦克(装上Cannon120主炮的坦克就是第三级):
typedef Tank<Cannon120> TankL3;
于是,我们可以使用不同的120mm弹药装填主炮,并且发射相应的炮弹:
TankL3 tank_l3;
Round_KE_120 ke_round; //创建一枚穿甲弹
Round_HE_120 he_round; //创建一枚高爆弹
tank_l3.load(ke_round); //装填穿甲弹
tank_l3.fire(); //发射穿甲弹
tank_l3.load(he_round); //装填高爆弹
tank_l3.fire(); //发射高爆弹
现在,我们把注意力从消灭敌人,转移到TankL3::load()的参数类型和TankL3::fire()的返回类型上。在一级和二级坦克(类型 Tank_KE_90等)上,load()成员的参数类型是Round_KE_90等具体的类型;而fire()的返回类型亦是如此。但TankL3是用 Cannon120实例化的,而Cannon120是用Rounds120这个concept实例化的。根据Tank<>模板的定义, load()成员的参数类型实际上是模板参数上的一个associate type。而这个associate type实际上就是Rounds120。这意味着load()实例化后的签名是:void load(Rounds120& r)(这里暂且允许concept作为类型参数使用)。只要符合Rounds120的类型都可以作为实参传递给load()成员。同样,fire()成员的返回类型来自于Round120上的associate type,也是个concept。因此,fire()实例化后的签名是:Warheads120 fire()。
接下来值得注意的是fire()成员。它返回类型是一个concept,那么返回的将是一个动态对象。在运行时,它可能返回WH_KE_120的实例,也可能返回WH_HE_120的实例,取决于运行时load()函数所装填的炮弹类型。当我们采用LethalityEvaluate()函数对该炮弹的杀伤情况进行评估将会出现比较微妙的情况:
double x=LethalityEvaluate(hisTank, hr, tank_l3.fire());
这时候,编译器应当选择哪个LethalityEvaluate()?由于tank_l3.fire()返回的是一个动态对象,具体的类型编译时不知道。实际上,在正宗的静态语言中,这样的调用根本无法通过编译。当然,编译器可以通过runtime reflect获得类型信息,然后在LethalityEvaluate()的重载中匹配正确的函数。然而,这种动态语言做法会造成性能上的问题,为静态语言所不屑。
但是,在这里,在runtime concept的作用下,我们可以使这种调用成为静态的、合法的,并且是高效的。请注意我在concept Warhead120的定义中加入了一个associate function:double LethalityEvaluate(Target& t, double hitRate, T& wh);。runtime concept会很忠实地将concept定义中的associate function构造到一个函数指针表(我称之为ctable)中。(详细情况请看本文附录和
这篇文章的附录)。因此,与tank_l3.fire()返回的动态对象实际类型对应的LethalityEvaluate()函数版本的指针正老老实实地躺在相应的ctable里。所以,我们可以直接从动态对象上获得指向ctable的指针,并且找出相应的LethalityEvaluate()函数指针,然后直接调用即可。比如:
tank_l3.load(ke_round);
double x=LethalityEvaluate(hisTank, hr, tank_l3.fire());
在这些代码的背后,ke_round通过load()装填入主炮后,便摇身变成了一个动态对象。编译器会为它附加上指向ctable的指针,然后在调用 fire()的时候返回指向这个动态对象的引用。此时,编译器发现这个动态对象所对应的Warhead120 concept上已经定义了一个名为LethalityEvaluate()的associate function,并且签名与当前调用相符。于是,便可以直接找到ctable中LethalityEvaluate()对应的那个函数指针,无所顾忌的调用。由于一个concept的associate function肯定是同实际类型匹配的函数版本。比如,对于WH_HE_120而言,它的associate function LethalityEvaluate()是版本:double LethalityEvaluate(Target& t, double hitRate, WH_HE_120& wh) {...}。其他版本的LethalityEvaluate()都无法满足concept Warhead120施加在类型WH_HE_120上的约束。
这个特性就使得runtime concept作为接口,相比动多态的抽象接口,具有更大的灵活性。抽象接口只表达了类的成员,以及类本身的行为,无法表达类型同其他类型的互动关系,或者说类型间的交互。而concept同时描述了成员函数和相关的自由函数(包括操作符),使得类型间的关系也可以通过接口直接获得,无需再通过 reflect等间接的动态手段。
这一点在处理内置类型(如int、float)、预置类型(某些库中的类型)、第三方类型等不易或无法修改的类型有至关重要的作用。在OOP下,我们无法输出一个“整数”,或许是short、或许是long,甚至是unsinged longlong。为此,我们要么把它们转换成一个“最基础类型”(C/C++的void*,或C#的Object*),然后运用rtti信息进行类型转换,再做处理;要么使用variant这种类型包装(就像COM中的那样),然后为他们全面定义一套计算库。但runtime concept不仅仅允许输出“整数”这样一个动态对象,而且还将相关的各种操作附在动态对象之上,使之无需借助rtti或者辅助类型也可进行各类处理,就如同处理具体类型的对象那样。
但是,在这里我仅仅考察了针对一个类型的concept(暂且称之为一元concept),还未涉及两个和两个以上类型的concept(暂且称为多元 concept,或n-元concept)。在实际开发中,多数操作都会涉及多个对象,比如两个数相加、一种类型转换成另一种。此时,我们将会面对多元的 concept。但是多元的runtime concept的特性还不清楚,还需要进一步研究分析。
总结
本文初步展示了在引入runtime concept之后,GP的动态化特性。归纳起来有以下几点:
- static GP和runtime GP之间在形式上完全统一,两者可以看作同一种抽象机制的不同表现。因此,我们在构造类型、函数等代码实体的时候,并不需要考虑它们将来需要作为static使用,还是runtime使用。static和runtime的控制完全取决于这些代码实体的使用方式。这就很好地减少了软件项目早期设计,以及库设计的前瞻性方面压力。
- runtime concept作为非侵入式的接口,可以非常灵活地使用。我们无需在代码编写的一开始就精确地定义好接口,可以先直接编写功能类型,逐步构建软件结构。需要时再定义接口(concept),并可以在任何时候与类型绑定。接口的定制可以成为一个逐步推进的过程,早期的接口设计不足产生的不良影响相应地弱化了。
- runtime concept相比动多态的抽象接口更加自由。concept可以对类型的成员函数、自由函数、类型特征等等方面的特性作出描述。在runtime化之后,相关自由函数成为了接口的一部分。更进一步规约了类型在整体软件的代码环境中的行为特征。同时,也为动态对象的访问提供更多的信息和手段。
- concept不仅实现类型描述,还可以进一步描述类型之间的关系。这大大完善了抽象体系。特别在runtime情况下,这种更宽泛的类型描述能力可以起到两个作用:其一,进一步约束了动态对象的行为;其二,为外界操作和使用类型提供更多的信息,消除或减少了类型匹配方面的抽象惩罚。这个方面的更多特性尚不清楚,还需要更进一步地深入研究。
综上所述,我们可以看到runtime GP在不损失性能的情况下,具备相比动多态更灵活、更丰富的手段。从根本上而言,以concept为核心的GP提供了更基础的抽象体系(关于这方面探讨,请看我的
这篇文章中关于concept对类型划分的作用部分)。或者说,concept的类型描述和约束作用体现了类型抽象的本质,而在此基础上进一步衍生出static和runtime两种具体的使用方式。这也就是所谓:道生一,一生二。:)
附录
Runtime Concept实现方案二
我在
这篇文章附录里,给出了一种实现runtime concept的可能方案。这里,我进一步对这个方案做了一些改进,使其更加精简、高效。
假设我们有一个concept:
concept Shape<T>
{
void T::load(xml);
void T::draw(device);
void move(T&);
}
另外,还有一个代表圆的concept:
concept Cycles<T> :
CopyConstructable<T>,
Assignable<T>,
Swappable<T>,
Shape<T>
{
T::T(double, double, double);
double T::getX();
double T::getY();
double T::getR();
void T::setX(double);
void T::setY(double);
void T::setR(double);
}
现在有类型Cycle:
class Cycle
{
public:
Cycle(double x, double y, double r);
Cycle(Cycle const& c);
Cycle& operator=(Cycle const& c);
void swap(Cycle const& c);
void load(xml init);
void draw(device dev);
double getX();
double getY();
double getR();
void setX(double x);
void setY(double y);
void setR(double r);
private:
...
};
我们将类型Cycle map到concept Cycles上:
concept_map Cycles<Cycle>{}
当我们创建对象时,将会得到如下图的结构:
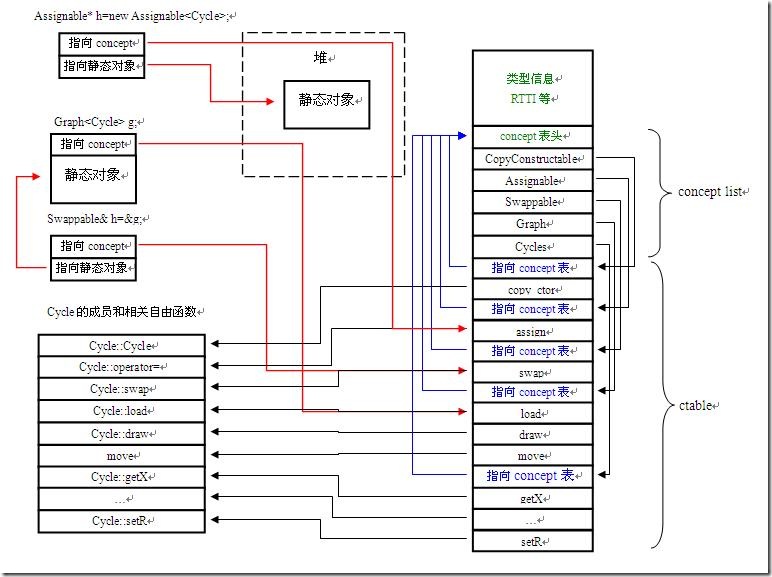
concept表(concept list)不再同对象放在一起,而是同一个类型的类型信息放在一起。一同放置的还有ctable。ctable中每个对应的concept项都有一个指向 concept表的指针(也可以指向类型信息头),用以找到concept list,执行concept cast。动态对象,或动态对象的引用/指针上只需附加一个指向相应的concept的指针即可。相比前一个方案,内存利用率更高。