BLENDER架构
原文:http://www.blender.org/development/architecture/
此文并非严格的学术翻译,有错误的地方请指出,一些非技术性的东西可能被删节了。交流学习联系方式:
Kuafu:augustus4400(at)gmail(dot)com
Blog:http://www.cppblog.com/flyindark/
简介
在过去的8年Blender的代码库一直在发生变化,并且扩大了很多。(删除了本段后续部分)
在这份文档中我将目标集中在回顾当初原始的设计理念上,例如这一部分是如何实现的,或这部分实现对应代码树里哪一处。既然下面即将介绍的原始设计理念可以很好的工作到现在,那么这个信息对当前所有的开发工作都会有益处。
本文档的第二个目的是提供Hooks,以方便我们可以更深入的使用'模块化的BLENDER。
BLENDER的设计的好坏是另外一个话题!特别是(角色)动画系统的知识没有出现在最初的设计阶段,这也是为什么Armatures、约束和NLA在现在仍然有问题的原因。另一个方面是当初为赶时间,游戏引擎和逻辑编辑在后来才加入,这些地方与BLEDER也没有很完美的协调工作。
虽然这两个方面都可以在当前的设计中进行改进,但我们最好还是承认BLENDER存在一些短处。在现在这个框架上改进功能和优化结构仍然是可能的,其中最有可能的是最终的代码可以集中在完全重构的Blender3的框架和模块化中完成改进。同样这也是另外一个话题。让我们先试图将这个疯狂的野兽控制住.:)
所见即所想;所做即所得
Blender最初是在动画工作室中开发的,符合它自己的用户所需求,作为一个商业软件按照工作进度和截止日期完成开发。(意译)
它有一个严格的面向数据的设计方式,几乎像一个数据库,但也有一些面向对象的思想。它完全由纯C编写。为了设计Blender,有一种尝试是建立一个尽可能统一的数据结构,来实现3D展现的所有可能性和所有通用的工具。
这个结构是为了让用户和程序员能够迅速和灵活,这是一个非常适合开发室内3D和动画包的工作方式。
虽然有些戏称Blender为'结构可视化',但是这个名字其实是相当准确的。在第一个月的Blender的开发中,我们除了设计框架和编写包含文件确实做的不多。在随后的几年里,主要的工具和可视化的方法逐步完成。
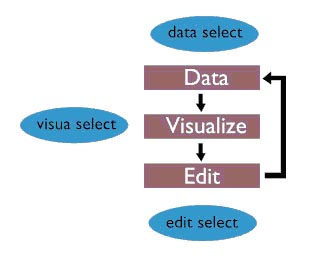
此图描述了Blender最基本的结构。“数据---可视化---编辑”这个循环周期是它的核心,并被GUI(图中蓝色处)分隔开来,GUI在3个不同的层次工作。
Data Select
一个用户选择'数据'。这意味着用户指定他希望工作的那部分三维数据库。这是一树状结构的组织。Blender的基本数据系统存在于文件上,这个数据系统直接和它加载到内存中的映射是一致的。Blender数据可以包含多个'scenes',每个场景轮流的由3D Objects,materials,动画和渲染设置组成。
Visua Select(visua or visual?)
指定的数据可以在Windows作为三维线框通过Zbuffer渲染来显示,如按钮或一个示意图。Blender有一个柔性的windows系统实现这个目标,这个窗口系统允许任何非重叠和非阻塞型的窗口布局体系。
Edit Select
根据可视化的选择,用户可以使用很多工具。编辑操作总是直接作用于数据,而不是数据的可视化。这似乎是合乎逻辑的,但这是很多软件的交互性和视觉方面的失败。一方面它是一个速度问题,在三维可视化时,它需要一定的时间后用户才看能到一个编辑命令的作用。这也是一个'反矫正的问题:用户只是了解可视化,而不是实际描述的数据结构。这可能非常痛苦,如果你试图做一些事情,结果最终被证明所做的与你想要的正好相反。
UI design decisions (本节未翻译,觉得原文更好理解)
With a 3D creation suite requiring many different but conceivable methods to make the complexity available for artists, most programs ended up with providing multiple modules, separating the workflow for artists based on tasks like 'animating' or 'material editing' or 'modeling'.
Based on our experience, as an animation studio, we didn't think this was natural nor followed the actual workflow of an art project.
Following the flow diagram as mentioned above, decided was to:
1. Base the UI on a non-overlapping non-blocking subdivision window system
2. Allow each subdivided 'window' in Blender to be hooked up with any 'editor' (= vizualization method), displaying any choosen type of data.
3. Implement a uniform usage of hotkey and mouse commands, that don't change meaning within different contexts.
4. Since it's an in-house tool, speed of usage had preference over ease of learning
The implementation of the UI was first tried with existing tools (libraries), but that failed completely because of lack of speed. The choice to create an entire new window manager, and base it all on IrisGL (predecessor of OpenGL), was one of the happy coincidences that made Blender as portable and slim as still is today.
数据结构
Blender设计的大部分时间用于决定哪些类型的数据类型要定义在一起,以及如何定义数据之间的关系。在时刻记住“'实现遵循设计”的理念的前提下,任何设计决策既有效又尽可能功能约束是很好理解的。
根据我们如何需要3D来实现我们的项目,做出了数据设计的决策,实现了一个高度抽象的数据层:
- 允许多人协同工作
- 让复杂的动画项目建立在1个项目(或文件)的基础上
- 允许高效的重复使用的数据
- 允许模板(或背景)
这导致设计一个非标'数据库',不像传统的'场景图'(这在当时基于的概念/显示),而是基于创建通用的3D的数据世界,在那里你可以创建你想要的足够多的场景图(显示,图像,动画等)。
顺便说一句:认识这个数据结构的概念一直是新用户进入Blender的瓶颈:)
在Blender数据块是用户的积木:它们可以随心所欲的被复制,修改和与另一块建立链接。
创建一个链接实际上和指明关系是一样的。这会导致一个块'被使用'。这可能会产生一个块的实例,或者得到一个特定的特征(类似C++中特化的概率?)。

For example, the block type 'Object' makes a 'Mesh' block appear in the 3d scene. The Object here determines the exact location, rotation and size of the Mesh. The Mesh then only stores information on vertex locations and faces. Also, more than one Object can have a link to the same Mesh (use, create an instance). Other block types, e.g. Materials, can be linked to Meshes to obtain the block type's features.
在Blender中每一个这样的块都带有一个ID结构,其中包含块的唯一名称,并在某些情况下,包含一个指明该块来自何处的库。ID结构允许Blender的数据被一个统一的方式操纵,而不需要了解实际的数据类型。
这些ID也让Blender来内部组织文件作为一个文件结构,仿佛它是一个包含文件的目录的集合。
这样的组织方式对当需要组合blender文件或将他们作为一个库使用的情形也很重要。
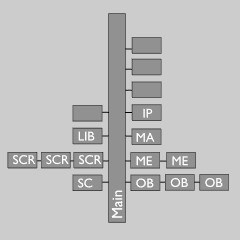
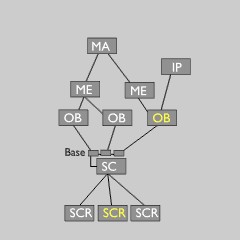
Data tree as in memory and file Scene graph
Blender中所有的数据都存储在一个主树上,这实际上只是一个块的列表。这里的数据始终驻留,独立于无论用户如何将他们连接在一起。在图片上面你可以看到一个'场景图'是如何从主树中可用的数据来构造出来的。
真实的数据仍然在主树上,这是在场景块(Scene block)中的进一步可视化。它内部有一个基本结构的清单,允许一个场景去连接许多对象而不从主结构中删除他们。
(一个基础还允许一些本地属性,例如层和选择集(selection),使一个对象可以被多个场景使用而且附带这些不同的属性。)
当使用Blender,Library blocks通常不解放自己(not freed themselves),而只是没有被连接。他们留在主块列表中。只有当用户计数是零的时候,这样的块才不写入文件中。
注意上图中黄色处,这里有两个主要的全局变量:当前屏幕(也表示活动场景)和活动对象。
数据块类型(Data block types)
所有存储在主树中的块都被称为Library blocks(有时也称为Libdata)。Library blocks启始的ID结构:
1 <ccode>
2
3 typedef struct ID {
4
5 void *next, *prev; /* for inserting in lists */
6
7 struct ID *newid; /* temporal data for finding new links when copying */
8
9 struct Library *lib; /* pointer to the optional Library */
10
11 char name[24]; /* unique name, starting with 2 bytes identifier */
12
13 short us; /* amount of users of the block */
14
15 short flag; /* bitwise flags to indicate special types */
16
17 } ID;
18
19 </ccode>
20
21
让我们来仔细看看Library blocks的其中之一,那个Mesh。当然,这样一个块其实是许多块的集合,不论是在数组中还是在列表中。在这里我们存储顶点,面,UV纹理坐标,等等(蓝色图片部分)。这些块被称为直接数据(Direct Data)。这些数据意味着是该网格的直接组成部分,并且总是和一个网格写在一起或从文件中读取回来。
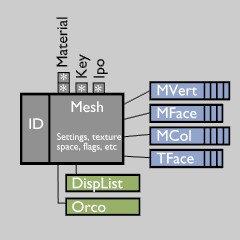
除了这些永久数据,另外还有一些临时数据可能会被连接到这个网格,例如显示列表,可以链接到网格。这些数据总是在匆忙中产生,不写入文件,并且在从文件中读回的时候被设置为清空。由于所有的库和Direct Data都保留在文件中,所以将他们设计紧凑并将临时数据分隔开来很重要。
我们现在得到了Blender设计的一个非常重要的规则:在Blender使用块的指针的时候限于指向指向LibraryData的指针的使用。这意味在任何地方都允许使用指向对象或网格的指针(例如在一个顶点),但是指向特定定点的指针不能随意存储。
译者注:不是很明确这里的“指针”的含义,暂且认为是之前ID STRUCT中的C++指针结构相关的东西。
这个规则确保了一个一致的和可预见的结构体,它可以被任何部分的Blender代码(尤其是对于数据库管理和文件)使用。它还明确了对一些东西是否应该成为Library Data该如何进行决定,当你想将它在Blender中到处进行交叉引用(crosslinked , re-used)时会碰到。
当文件被保存后,Direct Data总是紧随Library Data。由于储存的数据可以包含当他们需要读回时的指针。这里的指针规则有助于迅速恢复所有指向Direct Data的指针,因为这些指针只在一个单一的和相对较小的情况下存在。只有指向Library Data的指针才会存储在一个全局表中,并且所有恢复操作都会在一个调用中立即完成(lib_link_***).
(注:当给Blender加入游戏逻辑---传感器,控制器,执行器---最初的决策是将它作为Direct Data驻留在对象的上下文中。后来出现了对象传感器需要在其他对象上触发控制器,这个特性事实上因该在Library Data中完成,但是没有这样做。一个很丑陋的补丁就在急匆匆的就被添加到了文件读取的代码中。直到目前它仍然是一个有争议的设计问题。潜在的可能是应该用消息执行器和消息传感器来代替。)
外部库数据
以前的一个设计要求是能够从其他文件中导入数据,或将作为一种动态链接的模板。评估当时其他3D程序(Alias,Softimage公司)时我注意到他们都使用的真实的操作系统文件系统;创建一个项目目录包含一个目录树并在每一个目录中包含一个数据块对应的文件。除了它非常笨拙和复杂难于维护,我怀疑这种方式相当慢.:)
无论如何,Blender应该至少有这种做的好处。这些名为Blender数据的使用方式非常类似于文件系统的使用方式,Blender文件是一个包含所有单个文件的目录组合。
当使用其他文件(动态链接的)中的数据,很明显,只有LibraryData中的块可以被链接到。Blender然后自动读取其相关联的Direct Data。不过,为了使从外部文件读更有用,还需要展开其所有被连接的树。例如,一个被链接的对象也将调用附加的读取网格、材质和纹理。这种展开的数据被称为“间接”。在接口处可以识别到一个红色的库图标。当保存到一个文件,这些扩展的(间接)数据根本不会被写入。这使得外部文件编辑器可以改变对象的链接,如添加一IPO或添加其他材质。
这个特性的一个典型的用法是从其他文件动态链接一个场景。无论如何这个场景永远会被读取。
当保存被连接的Library Data,仅仅它的ID组成部分被写入文件。然后这个ID包含一个指向被使用的“库”的指针,并且那些真正的IDs有一个统一的名字用于保证那些链接总是被正确的保存。
文件保存和载入
文件保存大概是通过整个主树进行,并将所有用户块保存为原始二进制数据转储到磁盘上。每个保存的块有一个头(struct BHead)用于存储附加信息,如在内存中这个块的原始地址。
读文件时先读整个文件到内存中。 Blender的读文件代码接着遍历所有BHeads,处理Library Data和Indirect Data,创建完整的副本。因此,在最后最初读入的整个文件可以从内存中被释放。(注:读和写大量的数据块是为了防止磁盘和网络开销)。
写入被动态链接的Library Data(Writing dynamic linked library data)
由于Blender的主树仅仅是另外一个可以列表化的结构,它使用多个Main以能够高效的保存和写入被动态链接的数据。这是由函数split_main()完成的,它使用所有的数据创建主树。
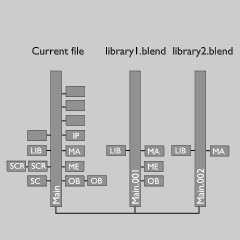
为了节省,当前的主树可以正常处理。至于其他主树则只保存所有IDs(例如类型ID_ID),以分隔来表示它源自哪个文件(通过保存结构库来完成)。
然后,它调用join_main()来再一次合并所有到一个单一的主树。
读取被动态链接的库数据(Reading dynamic linked library data)
这又有点复杂,也允许递归;
1.当从文件中读取数据,Blender遇到库结构,它创建一个新的主结构并记得储存的所有后续ID_IDs到那里。这些ID得到标记LIB_READ。
2.它接着遍历所有主树(Main trees),检查LIB_READ块标记
3.如果一个LIB_READ块发现:
3.1它检查包含该数据的文件是否已经被读取,如果没有则加载这整个文件到内存中和并保存到Main。
3.2然后使用正常的读取规则读取块,连接所有Direct Data到它上面。新的块被链接到当前的Main tree,老的块被清除。
3.3根据快的类型不同,它调用expand_doit()函数,它的像步骤3.2一样读取更多的块,或者检测这个块数据是否已经被正确读取。注:当这样的扩展的数据再一次从另一个文件出现,它只是读取ID部分,将它链接到正确的Main并且标记为LIB_READ。
4.只要LIB_READ标记的块被发现,则返回到步骤2。
5.只有在最后,它才加入到Main,并恢复所有正确的Library Data的指针。
你可以想像得到,这个系统需要相当多的指针技巧,其中指针必须映射到新的指针,然后再一次映射到新的指针,只有用正确的结束方式将真实的数据分配完成才算数。
Struct-DNA (SDNA结构)
随着选择了将文件保存为二进制格式,并了解到Blender的结构总是在变化和扩展,我当初想设计一个系统,可以兼顾到所有的低版本变更。这就是Blender DNA在图片得到的。
简单来说,SDNA是一打包并用二进制预处理过的Blender包含文件的一个版本,其中包含可以保存到文件的数据。De SDNA系统然后可以得到结构的内容本身,包括它的大小,元素类型和名称。
每个编译的Blender都有类似的SDNA被编译在其中,并在每个保存的.blennd文件中这个SDNA块都被加进来。另外,对于每一个文件的BHead它保存了一个索引数字表示了结构类型。
当检测和解析到变化时所有这一切都被允许。例如像一个short到int的转换,一个char到float的转换,或一个数组的元素变得越来越少或越来越多。新的变量总是很好的被清零,并且被删除的变量只是简单的被跳过。在移植到little endian系统(Blender诞生的时候使用big endian)的时候可以很好的进行自动转换。即使移植到到64位系统(DEC Alpha)也成功的使用SDNA完成了。
此外,它允许向后和向上兼容性。从Blender 1997任何可以很好的读取2004版的文件,反之亦然。
主要的限制是碰到要求对一个真实的版本进行改动。例如添加一个新的变量,它需要初始化一个特定的指。或者更糟的是,当一些变量的意义发生了变化(例如像物理属性)。
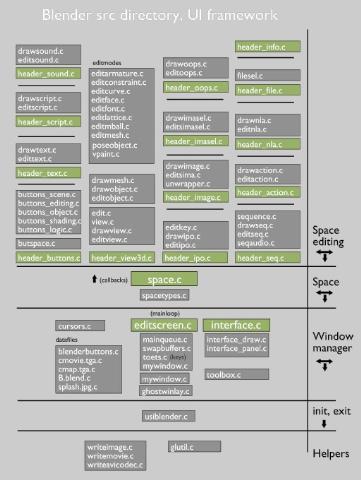
源代码的布局(Source code layout)
当前源代码的布局仍然是一个正在进行的工作的一瞥。一些依赖库已经明确的定了下来,其他仍然只是简短的决定。
在下图中你会发现文档中提及的目录
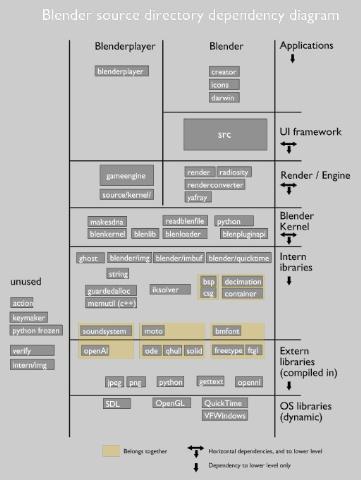
Blender UI framework
在” source/blender/src/”目录中你可以找到所Blender中所有用户界面和工具相关的代码,这个结构非常清晰,也可以反映到一个更好的目录结构上。