C语言中的结构是有实现位段的能力的,噢!你问它到底是什么形式是吧?这个问题呆会给你答案。让我们先看看位段的作用:位段是在字段的声明后面加一个冒号以及一个表示字段位长的整数来实现的。这种用法又被就叫作“深入逻辑元件的编程”,如果你对系统编程感兴趣,那么这篇文章你就不应该错过!
我把使用位段的几个理由告诉大家:1、它能把长度为奇数的数据包装在一起,从而节省存储的空间;2、它可以很方便地访问一个整型值的部分内容。
首先我要提醒大家注意几点:1、位段成员只有三种类型:int ,unsigned int 和signed int这三种(当然了,int型位段是不是可以取负数不是我说了算的,因为这是和你的编译器来决定的。位段,位段,它是用来表示字段位长(bit)的,它只有整型值,不会有7.2这种float类型的,如果你说有,那你就等于承认了有7.2个人这个概念,当然也没有char这个类型的);2、成员名后面的一个冒号和一个整数,这个整数指定该位段的位长(bit);3、许多编译器把位段成员的字长限制在一个int的长度范围之内;4、位段成员在内存的实现是从左到右还是从右到左是由编译器来决定的,但二者皆对。
下面我们就来看看,它到底是什么东西(我先假定大家的机器字长为32位):
Struct WORD
{
unsigned int chara: 6:
unsigned int font : 7;
unsigned int maxsize : 19;
};
Struct WORD chone;
这一段是从我编写的一个文字格式化软件摘下来的,它最多可以容纳64(既我说的unsigned int chara :6; 它总共是6位)个不同的字符值,可以处理128(既unsigned int font : 7 ;既2的7次方)种不同的字体,和2的19次方的单位长度的字。大家都可以看到maxsize是19位,它是无法被一个short int 类型的值所容纳的,我们又可以看到其余的成员的长度比char还小,这就让我们想起让他们共享32位机器字长,这就避免用一个32位的整数来表示maxsize的位段。怎么样?还要注意的是刚才的那一段代码在16位字长的机器上是无法实现的,为什么?提醒你一下,看看上面提醒的第3点,你会明白的!
你是不是发现这个东西没有用啊?如果你点头了,那你就错了!这么伟大的创造怎么会没有用呢(你对系统编程不感兴趣,相信你会改变这么一个观点的)?磁盘控制器大家应该知道吧?软驱与它的通信我们来看看是怎么实现的下面是一个磁盘控制器的寄存器:
│←5→│←5→│←9→│←8→│←1→│←1→∣←1→∣←1→∣←1→∣
上面位段从左到右依次代表的含义为:5位的命令,5位的扇区,9位的磁道,8位的错误代码,1位的HEAD LOADED,1位的写保护,1位的DISK SPINNING,1位的错误判断符,还有1位的READY位。它要怎么来实现呢?你先自己写写看:
struct DISK_FORMAT
{
unsigned int command : 5;
unsigned sector : 5;
unsigned track : 9 ;
unsigned err_code : 8;
unsigned ishead_loaded : 1;
unsigned iswrit_protect : 1;
unsigned isdisk_spinning : 1;
unsigned iserr_ocur : 1;
undigned isready :1 ;
};
注:代码中除了第一行使用了unsigned int 来声明位段后就省去了int ,这是可行的,详见ANCI C标准。
如果我们要对044c18bfH的地址进行访问的话,那就这样:
#define DISK ((struct DISK_FORMAT *)0x044c18bf)
DISK->sector=fst_sector;
DISK->track=fst_track;
DISK->command=WRITE;
当然那些都是要宏定义的哦!
我们用位段来实现这一目的是很方便的,其实这也可以用移位或屏蔽来实现,你尝试过就知道哪个更方便了!
我们今天的话题就到这儿,如果诸位还有疑问,可e-mail给我:arhuwen@163.com;
特别声明哦:不要把以上内容用于不法行为,否则后果自负。另外本文不可用于任何谋取商业利益的举动,否则同上!
我们已经了解什么是位段了, 现在我们继续讨论位段的使用方法。
先看一个例子: 我们需要用到五个变量。 假定, 其中三个用作标志, 称为 f1, f2 和 f3。
第四个称为 type, 取值范围为 1 至 12。 最后一个变量称为 index, 值的范围为 0 至 500。
通常, 我们用下面的语句来说明这些变量:
char f1,f2,f3;
unsigned int type;
unsigned int index;
但是, 实际上标志 f1, f2, f3 分别只需要 1 位。变量 type 只需要 4 位, 而变量 index 只需要 9 位。 总共是 16位 ---- 2 个字节。我们用两个字节就够了。
我们可这样来做:
struct packed_struct
{
unsigned int f1 :1;
unsigned int f2 :1;
unsigned int f3 :1;
unsigned int type :4;
unsigned int index :9;
};
该例中, 我们定义了一个结构 packed_struct。该结构定义了五个成员
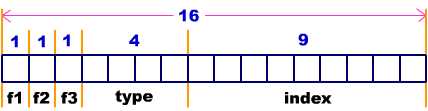
。第一个成员叫做 f1, 是 unsigned int 类型的。紧跟在该成员名之后的 :1 规定了它以 1 位存放。类似地, 标志 f2 和 f3 被定义为长度只有 1 位的。定义成员 type 占有 4 位。定义成员 index 占有 9 位。C 编译器自动地把上面的位段定义压缩在一起。位段的划分如图所示。packed_struct 总共使用了 16 位。
这种方法的好处是, 定义成 packed_struct 类型的变量的位段, 可以如引用一般的结构成员一样方便地引用。同时, 使用了更少的内存单元数。
我们已经定义了一个称作为 packed_struct 的包含着位段的结构。现在, 我们象下面那样定义一个称作为 packet_data 的变量: struct packed_struct packed_data; 于是, 我们就可以用简单的语句, 把 packed_data 的 type 位段设置为 7:
packed_data.type = 7; 类似地, 我们可以用下面的语句把这个位段的值设为 n:
packed_data.type = n; 我们不必担心 n 的值太长, 以致不能放入 type 位段中, C 编译器会自动地仅取出 n 的低四位, 把它赋值给 packed_data.type。取出位段的值也自动地处理的, 因此语句 n = packed_data.type; 将从 packed_data 中取出 type 位段, 并把它的值赋给 n。
在一般的表达式中可以使用位段, 此时, 位段自动地转换成整数。因此, 表达式
i = packed_data.index/5+1; 是完全有效的。
在包含位段的结构中, 也可以包括 "通常的" 数据类型。因此, 如果我们想定义一个结构, 它包含一个 int, 一个 char, 和二个 1 位的标志, 那么, 下面的定义是有效的:
struct table_entry
{
int count ;
char c;
unsigned int f1 :1;
unsigned int f2 :1;
};
当位段出现在结构定义中时, 它们就被压缩成字。如果某个位段无法放入一个字中, 那么该字的剩余部分跳过不用, 该位段被放入下一个字中。
使用位段时, 必须注意下列事项:
- 在某些机器上, 位段总是作为 unsigned 处理, 而不管它们是否被说明成 unsigned 的。
- 大多数C 编译器都不支持超过一个字长的位段。
- 位段不可标明维数; 即, 不能说明位段数组, 例如 flag:l[2]。
- 最后, 不可以取位段地址。原因是, 在这种情况不, 显然没有称作为 "位段指针" 类型的变量。

这里, 我们再深入讨论一下位段。如果使用下面的结构定义:
struct bits
{
unsigned int f1:1;
int word;
unsigned int f3:1;
};
那么, 位段是怎样压缩的呢? 由于成员 word 出现于其间, 故 f1, f3 不会压缩在同一个字内。C 编译器不会重新安排位段定义来试图优化存储空间。
可以指定无名位段, 使得一个字中的某些位被 "跳过"。因此, 定义:
struct x_entry
{
unsigned int type :4;
unsigned int :3;
unsigned int count :9;
};
将定义一个结构 x_entry, 它包含两个位段变量 type 和 count, 而无名位段规定了 type 和 count 间隔三位。
来自:http://its.nbtvu.net.cn/xhyu/cai_c/c_web/c/c8/c83.htm
http://www.cnblogs.com/jincwfly/archive/2007/09/14/892341.html
关于结构体内存对齐
内存对齐”应该是编译器的“管辖范围”。编译器为程序中的每个“数据单元”安排在适当的位置上。但是C语言的一个特点就是太灵活,太强大,它允许你干预“内存对齐”。如果你想了解更加底层的秘密,“内存对齐”对你就不应该再透明了。
一、内存对齐的原因
大部分的参考资料都是如是说的:
1、平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
二、对齐规则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
对齐步骤:
1、数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。
2、结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
3、结合1、2颗推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。
备注:数组成员按长度按数组类型长度计算,如char t[9],在第1步中数据自身长度按1算,累加结构体时长度为9;第2步中,找最大数据长度时,如果结构体T有复杂类型成员A的,该A成员的长度为该复杂类型成员A的最大成员长度。
三、试验
我们通过一系列例子的详细说明来证明这个规则吧!
我试验用的编译器包括GCC 3.4.2和VC6.0的C编译器,平台为Windows XP + Sp2。
我们将用典型的struct对齐来说明。首先我们定义一个struct:
#pragma pack(n) /* n = 1, 2, 4, 8, 16 */
struct test_t {
int a;
char b;
short c;
char d;
};
#pragma pack(n)
首先我们首先确认在试验平台上的各个类型的size,经验证两个编译器的输出均为:
sizeof(char) = 1
sizeof(short) = 2
sizeof(int) = 4
我们的试验过程如下:通过#pragma pack(n)改变“对齐系数”,然后察看sizeof(struct test_t)的值。
1、1字节对齐(#pragma pack(1))
输出结果:sizeof(struct test_t) = 8 [两个编译器输出一致]
分析过程:
1) 成员数据对齐
#pragma pack(1)
struct test_t {
int a; /* 长度4 < 1 按1对齐;起始offset=0 0%1=0;存放位置区间[0,3] */
char b; /* 长度1 = 1 按1对齐;起始offset=4 4%1=0;存放位置区间[4] */
short c; /* 长度2 > 1 按1对齐;起始offset=5 5%1=0;存放位置区间[5,6] */
char d; /* 长度1 = 1 按1对齐;起始offset=7 7%1=0;存放位置区间[7] */
};
#pragma pack()
成员总大小=8
2) 整体对齐
整体对齐系数 = min((max(int,short,char), 1) = 1
整体大小(size)=$(成员总大小) 按 $(整体对齐系数) 圆整 = 8 /* 8%1=0 */ [注1]
2、2字节对齐(#pragma pack(2))
输出结果:sizeof(struct test_t) = 10 [两个编译器输出一致]
分析过程:
1) 成员数据对齐
#pragma pack(2)
struct test_t {
int a; /* 长度4 > 2 按2对齐;起始offset=0 0%2=0;存放位置区间[0,3] */
char b; /* 长度1 < 2 按1对齐;起始offset=4 4%1=0;存放位置区间[4] */
short c; /* 长度2 = 2 按2对齐;起始offset=6 6%2=0;存放位置区间[6,7] */
char d; /* 长度1 < 2 按1对齐;起始offset=8 8%1=0;存放位置区间[8] */
};
#pragma pack()
成员总大小=9
2) 整体对齐
整体对齐系数 = min((max(int,short,char), 2) = 2
整体大小(size)=$(成员总大小) 按 $(整体对齐系数) 圆整 = 10 /* 10%2=0 */
3、4字节对齐(#pragma pack(4))
输出结果:sizeof(struct test_t) = 12 [两个编译器输出一致]
分析过程:
1) 成员数据对齐
#pragma pack(4)
struct test_t {
int a; /* 长度4 = 4 按4对齐;起始offset=0 0%4=0;存放位置区间[0,3] */
char b; /* 长度1 < 4 按1对齐;起始offset=4 4%1=0;存放位置区间[4] */
short c; /* 长度2 < 4 按2对齐;起始offset=6 6%2=0;存放位置区间[6,7] */
char d; /* 长度1 < 4 按1对齐;起始offset=8 8%1=0;存放位置区间[8] */
};
#pragma pack()
成员总大小=9
2) 整体对齐
整体对齐系数 = min((max(int,short,char), 4) = 4
整体大小(size)=$(成员总大小) 按 $(整体对齐系数) 圆整 = 12 /* 12%4=0 */
4、8字节对齐(#pragma pack(8))
输出结果:sizeof(struct test_t) = 12 [两个编译器输出一致]
分析过程:
1) 成员数据对齐
#pragma pack(8)
struct test_t {
int a; /* 长度4 < 8 按4对齐;起始offset=0 0%4=0;存放位置区间[0,3] */
char b; /* 长度1 < 8 按1对齐;起始offset=4 4%1=0;存放位置区间[4] */
short c; /* 长度2 < 8 按2对齐;起始offset=6 6%2=0;存放位置区间[6,7] */
char d; /* 长度1 < 8 按1对齐;起始offset=8 8%1=0;存放位置区间[8] */
};
#pragma pack()
成员总大小=9
2) 整体对齐
整体对齐系数 = min((max(int,short,char), 8) = 4
整体大小(size)=$(成员总大小) 按 $(整体对齐系数) 圆整 = 12 /* 12%4=0 */
5、16字节对齐(#pragma pack(16))
输出结果:sizeof(struct test_t) = 12 [两个编译器输出一致]
分析过程:
1) 成员数据对齐
#pragma pack(16)
struct test_t {
int a; /* 长度4 < 16 按4对齐;起始offset=0 0%4=0;存放位置区间[0,3] */
char b; /* 长度1 < 16 按1对齐;起始offset=4 4%1=0;存放位置区间[4] */
short c; /* 长度2 < 16 按2对齐;起始offset=6 6%2=0;存放位置区间[6,7] */
char d; /* 长度1 < 16 按1对齐;起始offset=8 8%1=0;存放位置区间[8] */
};
#pragma pack()
成员总大小=9
2) 整体对齐
整体对齐系数 = min((max(int,short,char), 16) = 4
整体大小(size)=$(成员总大小) 按 $(整体对齐系数) 圆整 = 12 /* 12%4=0 */