对于理解J2EE集群技术不错的文章,虽然是Sun的技术人员撰写的,基本观点还算客观,内容深浅恰当,非常适合刚刚接触集群的朋友阅读,故此大胆翻译过来,放在这里和大家共享,错误难免,欢迎指正。
原链接
Uncover the hood of J2EE Clustering
1 前言
越来越多的关键任务和大型应用正运行在J2EE平台上,象银行之类的应用要求很高的可用性(HA),大型系统比如google和Yahoo则要求更好的伸 缩性。今天高可用性和伸缩性的重要性对于互联世界日益增长,最著名的证明是1999年eBay中断了22小时的服务,原因是超过230万次的拍卖,最终导 致eBay股票下跌了9.2个百分点。
J2EE集群是最常用的技术,用来提供高可用性和伸缩性的容错服务。但由于缺乏J2EE规范的支持,J2EE提供厂商实现的集群尽不相同,引起许多J2EE架构师和开发者的麻烦,比如下面:
1. 为什么附带集群能力的商业J2EE服务器如此昂贵?(比不带集群能力的贵10倍)
2. 为什么我在单机上创建的应用无法运行在集群模式?
3. 为什么我的应用在集群时运行缓慢但不集群时却很快速?
4. 为什么我的集群应用不能与其他提供商的服务器通信?
2 基本术语
讨论不同实现之前,理解集群技术的概念是很有意义的,我希望不仅能给你提供关于J2EE集群产品基本的设计理念和概念,还可以概括性的描绘不同的集群实现,使它们更容易被理解。
2.1 伸缩性(Scalability)
大型系统很难预测终端用户的数量与行为,伸缩性是指系统可以支持用户的快速增长。提高服务器同时处理并发会话的最直觉的方式就是增加服务器资源(内存, CPU,或硬盘),集群是解决伸缩性的另一种可选方式。它允许一组服务器分担处理繁重的任务,而逻辑上就象一台服务器一样。
2.2 高可用性(High Availability)
提高伸缩性的单服务器解决方案(添加内存和CPU)是并不强壮的办法,因为单点失效原因。关键任务应用不能容忍服务中断哪怕一分钟。它要求任何时候都可以合理地可预期的响应时间访问这些服务,集群可以通过提供额外的服务器使其在一台服务器实效时提供服务,从而提高可用性。
2.3 负载均衡(Load balancing)
负载均衡是集群技术之后的一个关键技术,通过分发请求到不同的服务器来提高可用性和更好的性能。负载均衡器可以是一个Servlet或插件(例如a linux box using ipchains),除分发请求之外,负载均衡器应负责其他一些重要的任务,例如“会话黏附”,使得某个用户会话始终在一台服务器上存活,还有“心跳检 测”,防止分发请求到失效的服务器。有时候负载均衡器也参与到“失效转移”处理。
2.4 容错(Fault Tolerance)
高可用性数据不必是严格正确数据.在J2EE集群中,当一个服务器实例失效时,服务仍然可用,因为新的请求可由其他冗余的服务器实例处理。但如果请求正在处理当中时服务器实例失效,则不能能得到正确的数据。然而容错服务则总是保证严格正确的行为。
2.5 失效转移(Failover)
失效转移是另一项使得集群实现容错的关键技术。通过选择集群中另一个节点,原始节点失效时处理将继续下去。失效转移可以显式地编码也可以由低层平台自动执行。
2.6 等幂方法(Idempotent methods)
可以用相同的参数重复调用的方法,并且总是得到相同的结果。这些方法不应该影响系统状态,可以被重复地调用而不必担心改变系统。例如, “getUsername()” 是等幂方法,而“deleteFile()” 就不是等幂方法。等幂是HTTP会话和EJB失效转移的重要概念。
3 J2EE集群是什么?
一个幼稚的问题,不是吗?但我仍然用一些话语和图表来回答它。通常J2EE集群技术包括“负载均衡”和“失效转移”。
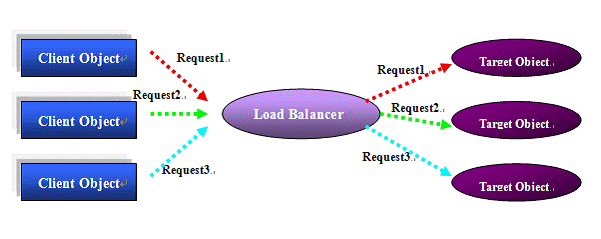
图1 负载均衡
如图1所示,有很多客户端对象并发发送请求到目标对象。负载均衡器则位于调用者和被调用者之间,分发请求到冗余的拥有同样功能的对象上。用此方法可以实现高可用性和高性能。
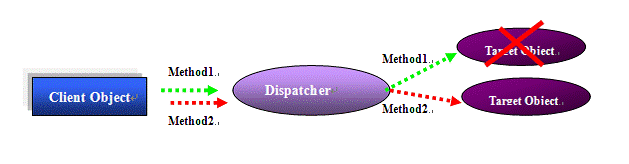
图2:失效转移
如图2所示,失效转移与负载均衡不同。有时候,客户端对象对目标对象发起连续的方法请求。如果目标对象在请求之间失效,失效转移系统应该检测到并将后续请求转向导另一个可用的对象,容错也可用此途径实现。
如果想了解更多J2EE集群,你应该问更多的基本问题,例如:“什么类型的对象可以被集群?”,“在我的J2EE代码中什么地方出现负载均衡和失效转 移?”,对于理解J2EE集群的原理,这些都是非常好的问题。实际上,不是所有对象可以被集群,也不是任何地方都可以负载均衡和失效转移!看看下列代码:

图3:代码例子
当“instance1”失效时,“Class A”的“business()”方法会负载均衡和失效转移到另一个B实例吗?不,不会。对于负载均衡和失效转移,必须要在调用者和被调用者之间存在一个拦 截器,用来分发或者转向方法调用到不同的对象上。A和B的实例对象运行在同一个JVM上,并紧密耦合。很难在方法调用之间添加分发逻辑。
所以,什么类型的对象可以被集群?---只有发布在分布式结构的对象。
所以,什么地方会发生负载均衡和失效转移呢?--只有在调用一个分布式对象的方法时。
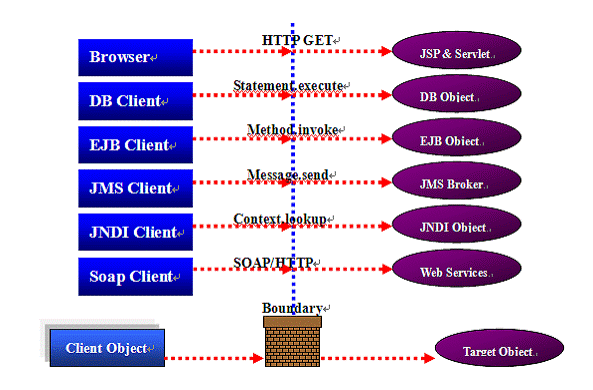
图4:分布式对象
在分布式环境,如图4所示,调用者和被调用者被分离为不同边界的运行容器,边界是JVM,进程或机器。
当客户端调用目标对象时,在目标对象容器内执行功能。客户端和目标对象通过标准的网络协议通信。利用这些特性添加机制到方法调用路由中,以实现负载均衡和失效转移。
如图4所示,浏览器可以通过HTTP协议调用远程JSP对象。JSP在Web服务器上执行,浏览器不关心执行过程,它只需要结果。在这样的场景中,有些东 西可以位于浏览器和web服务器之间用来实现负载均衡和失效转移功能。在J2EE中,分布式技术包括:JSP(Servlet),JDBC ,EJB,JNDI,JMS,Webservices和其他。当分布式方法被调用时可以发生负载均衡和失效转移。下面我们会讨论细节。
4 web层集群实现
web层集群是J2EE集群中最重要和基础的功能。web层集群技术包括:Web负载均衡和HTTPSession失效转移。
4.1 web负载均衡
J2EE提供商有很多方法实现web负载均衡,基本的,在浏览器和web服务器之间放置负载均衡器。
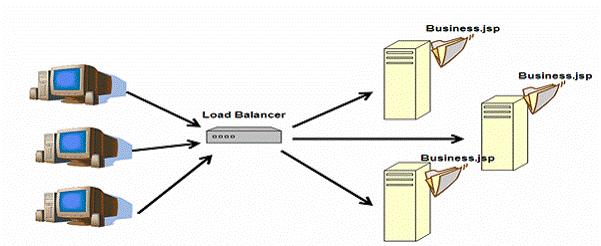
图5:web负载均衡
负载均衡器可以是硬件产品如F5 负载均衡器,也可以是另一个带有负载均衡插件的web服务器。简单的带有ipchains的linux box也可以执行负载均衡的功能。无论何种技术,负载均衡器通常有以下特性:
*实现负载均衡算法
当客户端请求达到时,负载均衡器决定如何分发请求到后端服务器实例。通常的算法包括Round-Robin,(指的是使组中所有成员都能均等地以某种合理 的顺序被选择到的一种安排方式, 通常是从列表的头至尾,而后周而复始),随机和基于权重。 负载均衡器试图使每个服务器实例完成相同的工作量,但以上算法都不能真正达到理想的等量,因为他们只是基于分发到某个服务器实例请求的数量来计算。一些聪 明的负载均衡器实现特别的算法,他们会测试每个服务器的工作负载来决定分发请求。
*心跳检测
当一些服务器实例失效时,负载均衡器应该检测到失效,并不再分发请求到失效的服务器上。负载均衡器也需要监视服务器恢复状况,并给它重新分发请求。
*会话粘连
几乎每个web应用都有会话状态,使得记住用户是否登陆或购物车变得非常简单。因为HTTP协议本身没有状态,会话状态需要存在某个地方,并和浏览会话关 联起来,可以在下一次请求时很容易地被检索到。当负载均衡时,最好选择分发相同的浏览器会话请求到同一台服务器实例上,否则应用工作会不正常。
因为会话状态存储在某个web服务器实例的内存中,“会话粘连”对于负载均衡非常重要。但,如果一台服务器实例因为某些原因失效(比如断电),那么该服务 器上多有的会话状态就丢失了。负载均衡器检测到了该失效,不再向其分发请求。但存储在失效服务器上的会话的那些请求将丢失会话信息,这种情况会引起错误, 因此会话失效转移到来了!
4.2 HTTPSession失效转移
几乎所有的流行的J2EE提供商都在他们的集群产品中实现了HTTPSession失效转移,确保所有的客户请求可以不因为一些服务器实例的失效而丢失任 何会话状态。如图6所示,当浏览器访问一个有状态的web应用(第1,2步),此应用可以在内存中创建会话对象存储信息以备后用。同时,向浏览器送回 HTTPSession ID,用来标记该会话对象(第3步)。浏览器以cookie的方式存储该ID,并会在下次发起请求时送回web服务器。为了支持会话失效转移,会话对象将 在某时某处将它自己备份(第4步)。负载均衡器可以检测失效(第5,6步),分发请求到其他服务器实例(第7步)。因为会话对象已经被备份,新的web服 务器实例可以恢复该会话并正确地处理请求。
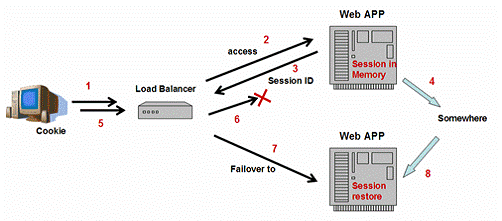
图6:HTTPSession失效转移
为了实现以上功能,注意下列问题:
*全局HTTPSession ID
如上所述,HTTPSession ID用来标记某个服务器实例内存中的会话对象。在J2EE中,HTTPSession ID依赖于JVM实例。每个JVM实例可以控制多个web应用,每个应用又可以控制许多不同用户的HTTPSession,HTTPSession ID是存取当前JVM实例中相关会话对象的键。在会话失效转移实现中,要求不同的JVM实例不应该产生两个同样的HTTPSession ID,因为失效时,在一个JVM的会话可能在另一个JVM中备份和恢复。所以,应该建立全局的HTTPSession ID机制。
*如何备份会话状态
如何备份会话状态是一个使得J2EE服务器与众不同的关键因素。不同的提供商实现不同。
*备份频率和粒度
HTTPSession状态备份有性能消耗,包括CPU周期,网络带宽和写磁盘和数据库的IO消耗。备份频率和粒度严重影响集群的性能。
4.3 数据库持久化方案
几乎所有的J2EE集群产品允许你通过JDBC接口使用关系数据库备份会话状态。如图7所示,该方案只是简单地让服务器实例序列化会话内容,并在适当的时 候写入数据库。当失效转移发生时,另一个可用的服务器实例负责失效的服务器,并从数据库中恢复会话状态。 对象序列化是关键点,使得内存会话对象数据持久化和可移动。更多对象序列化信息请参考
http://java.sun.com/j2se/1.5.0/docs/guide/serialization/index.html
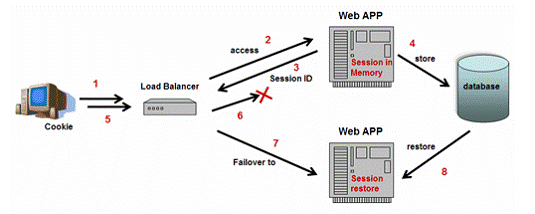
图7:备份会话状态到数据库
象数据库事务一样代价昂贵,该方案的主要缺点是有限的伸缩性:当存储大量会话中的对象时。许多使用数据库会话持久化的应用服务器鼓吹 HTTPSession的最小限度的使用,但其实他们还限制了你的应用架构和设计,特别是如果你使用HTTPSession存储缓冲用户数据。
数据库方案也有一些优点.
*实现简单。江会话备份处理和请求处理分离,使得集群易于管理并比较健壮。
*会话可以失效转移到任何其它机器上,因为使用共享数据库。
*会话数据可以在整个集群失效后仍然生存。
4.4 内存复制方案
由于性能问题,一些J2EE服务器(Tomcat,JBoss,WebLogic和WebSphere)提供另一种实现:内存复制。
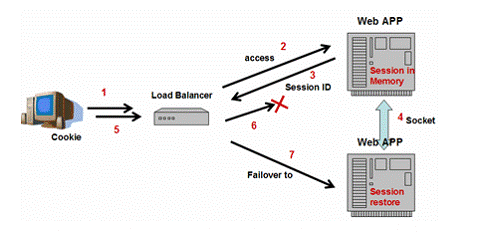
图8:内存复制
基于内存的会话持久化存储会话信息,该方案由于性能好非常流行。和数据库方案比较,在原始服务器和备份服务器之间直接网络通信是非常轻量级的。请注意该方案,数据库方案中的“恢复”阶段是不需要的。请求到来时,所有的会话数据已经存在于备份服务器的内存中了。
”JavaGroups”是目前JBoss和Tomcat集群的通讯层,JavaGroups 是一个实现群通讯和管理的工具包。它提供的核心特性是“Group membership protocols”和“message multicast”更多信息请参考http://www.jgroups.org/javagroupsnew/docs/index.html
4.4.1 Tomcat方案:多机复制
内存复制存在很多变体方案。一中办法是跨集群中的多节点复制会话状态。Tomcat5以此法实现内存复制。

图9:多机复制
如图9所示,当一个服务器实例的会话状态改变时,它将向集群中所有服务器备份它的数据。如果其中一个实例失效,负载均衡器可选择其它任何可用的服务器实例 作为其备份服务器。但该方案在伸缩性上有缺陷。如果集群中有很多实例,网络通讯消耗就不可忽略了,这种情况将严重降低性能和网络交通,成为瓶颈问题。
4.4.2 Weblogic, Jboss and WebSphere的方案--配对复制
因为性能和伸缩性问题,Weblogic, JBoss and Websphere 都提供了另一种方法实现内存复制:每个服务器实例选择任一个备份实例存储会话信息,如图10。
按这种方式,每个服务器实例拥有它自己的配对备份服务器而不是所有其它服务器。该方案消除了伸缩性问题。
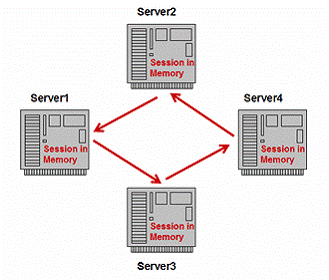
图10:配对复制
虽然该方案实现了会话失效转移的高性能和高伸缩性,仍然有下列限制:
*给负载均衡器带来了复杂性。当一台服务器实例失效,负载均衡器必须记住哪个实例是其配对备份服务器,缩小了负载均衡器 的选择范围,一些硬件均衡器不能在此结构中使用。
* 除了处理正常的请求,服务器同时负责复制。每个服务器实例,请求处理容量被减小,因为CPU周期需要完成复制职责。
*除了正常处理,许多内存被用来存储备份会话状态,即使没有失效转移发生,也增加了JVM垃圾收集的消耗。
*集群中的服务器实例组成复制配对。所以如果会话粘连失效的主服务器,负载均衡器能发送失效转移请求到备份服务器上。备份服务器将在进入的请求中遇到麻烦,引起性能问题。
为了克服以上限制,不同的提供商的变种产生了。Weblogic 为每个会话而不是服务器定义了备份配对。当一台服务器实例失效,失效服务器上的会话被分散到不同备份服务器上,并且被分散地装载。
4.4.4 IBM的方案--中央状态服务器
Websphere 另一个可用的内存复制选择是:备份会话信息到一个中央状态服务器,如图11。
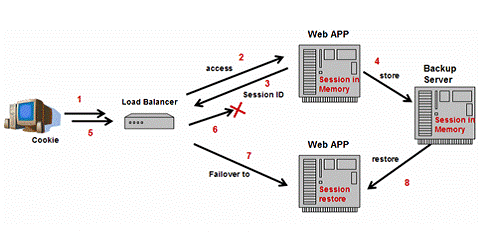
图11:中央服务器复制
和数据库方案非常相似,不同的是一个专门的“会话备份服务器”代替了数据库服务器。该方案兼有数据库和内存复制的优点:
*分离的请求处理和会话备份,使得集群更强壮。
*所有的会话数据备份到专门的服务器上。bu需要服务器实例浪费内存区保存其它服务器的备份会话数据。
*会话可以失效转移到其它任何实例上。因为会话备份服务器是被集群中的所有节点共享的。所以,大多数负载均衡软件和硬件可以在此集群中使用。更重要的是,请求装载在失效时将均匀分散。
*因为应用服务器和会话备份服务器之间的socket通讯是轻量级的相对于重型的数据库联接。它比数据库方案有着更好的性能和伸缩性。
然而,由于“恢复”阶段覆盖失效服务器的会话数据,它的性能和直接或配对内存复制方案不一样,附加的会话备份服务器对管理员也增加了复杂性,性能瓶颈由备份服务器自己的性能所限制。
4.4.5 Sun的方案--特殊的数据库
Sun 自己的方案,本节略,大家感兴趣可以自己看原文。
4.4.6 其它失效转移实现
JRun 使用Jini,Tangosol 使用分布式缓冲。本节无实质内容,略。
5 JNDI集群实现
暂略。
6 EJB 集群实现
暂略。
7 关于J2EE集群的神话
7.1 失效转移可以完全避免错误。 ---否定
JBoss文档中,有一整章节警告“你真的需要HTTP会话复制吗?”,是的,有时候一个没有失效转移的高可用性方案也是可以接受的,并且便宜。更进一步说,失效转移并不像你想的那样有力。
到底失效转移给了你什么?你们中的一些可能认为它可以避免错误。您瞧,没有失效转移,会话数据在服务器失效时丢失了并引起错误;当会话失效转移,会话可以从备份中恢复,并且请求可以由另一个实例继续处理,客户端不知道该失效。这可能是真的,但它不是必要的条件。
当我定义“失效转移”时,我定义了失效转移发生的条件:“在方法调用之间”,意味着你可以有两个连续的到一个远程对象的方法,失效转移将发生在第一个方法成功完成之后和第二个方法请求发出之前。
那么,在方法调用处理中间,远程服务器失效了会发生什么事情?答案是:处理将停止,大多数案例中,客户端将看到错误信息,除非该方法是等幂的(参考前文)。如果是等幂方法,一些负载均衡器足够聪明,会在其它服务器上重试这些方法。
为什么等幂重要?因为当失效发生时,客户端从来不知道请求在哪里执行,方法被初始化或已经完成了?客户端从不确定它。如果方法不是等幂的,两次调用同样的方法将改变系统状态两次,系统将处于不一致状态。
您可能想把所有的方法放在一个事务中就变成等幂的了。毕竟,如果错误发生,事务将回滚,所有的事务状态没有改变。但是事实是,事务边界不能包括所有远程方法调用。如果事务提交,在返回客户端时网络崩溃,客户端不会知道服务器事务成功与否。
在应用中,将所有方法变成等幂是不可能的。所以,通过失效转移,你可以减少错误,但不能避免它们!以再现购物网站为例,假定每台服务器实例可以同时处理 100个在线用户的请求。当一台服务器失效,没有会话失效转移的方案将丢失所有那100个用户的会话数据并激怒他们;当拥有会话失效转移,只有20个用户 的请求被失效的服务器在处理过程中,只有这些用户被错误激怒了。其它80个用户还处在思考时间(用户行为的间隔时间)或者方法调用之间。这些用户的会话被 透明地失效转移了。所以,你应该考虑以下事项:
*激怒20个和100个用户的不同影响
*拥有失效转移和没有失效转移的成本
7.2 单机应用可以被透明地转换为集群结构 ---- 绝对不是!
虽然一些提供商声称他们的J2EE产品的适应性,不要相信他们!实际上,你应该在系统设计开始时就考虑集群,并影响到开发和测试的所有阶段。
7.2.1 Http会话
在集群环境,对HTTPSession的使用有着严格的限制正如我在前边提及的一样,你的应用服务器依赖不同的机制使用会话失效转移。最重要的限制是所有 存储在HTTPSession里的对象必须是可序列化的,这一点限制了应用的结构和设计。一些设计模式和MVC框架使用HTTPSession存储不可序 列化对象(如Servlet Context,Local EJB 接口,web services引用),这样的设计不能在集群中工作。其次,对象序列化和反序列化在性能上消耗很大特别是数据库方案。在这样的环境中,存储巨大或众多的 会话对象,应该避免。如果你已经选择内存复制方案,小心HTTPSession的交叉引用属性的限制。另一主要的区别是,你需要在每次改变 HTTPSession属性的时候调用“setAttribute ()”方法。调用这些方法在单机应用中不是必须的。其目的是将改变的属性和未改变的属性分离开来,所以系统可以只备份必要的数据。
7.2.2 缓冲
几乎我经历过的每一个J2EE项目都使用缓冲提升性能,所有的流行服务器提供不同程度的缓冲以提升应用性能。但这些缓冲是单机应用的典型设计,只能在一个 JVM实例上工作。我们需要缓冲是因为创建这些新对象的代价是如此昂贵,所以我们维护一个对象池来重用对象实例。每个JVM实例都拥有自己的缓冲拷贝,它 们也应该被同步,以在所有服务器实例上维持一致的状态。有时,这种同步导致性能恶劣还不如不要缓冲。
7.7.3 静态变量
一些设计模式,比如“Singleton”(单例) 使用静态变量来给其它对象共享状态。这种方案在单一的服务器上工作得很好,但在集群中失效了。集群中的每个实例都会在其JVM实例中维护它自己的静态变量 拷贝,因此就破坏了该设计模式的共享机制。一个使用静态变量的例子是保持在线用户的总数。简单的办法就是将改数字存储到静态变量中,当用户登录或下线时增 加或减少它。在单一服务器上该应用绝对运行得非常好,但在集群中就失效了。更可取的办法是将所有状态存储到数据库中去。
7.7.4 外部资源
虽然J2EE规范不推荐使用,外部I/O操作还是有很多的用途。例如一些应用使用文件系统存储用户上载的文件,或者创建动态的配置XML文件。在集群中, 英勇服务器没法跨实例复制这些文件。为了在集群中工作,解决方案是如有可能,使用数据库替代外部文件。也可以选择SAN作为中央文件存储。(备注:SAN 英文全称:Storage Area Network,即存储区域网络。它是一种通过光纤集线器、光纤路由器、光纤交换机等连接设备将磁盘阵列、磁带等存储设备与相关服务器连接起来的高速专用 子网。)
7.7.5 特殊的服务
有一些特殊的服务只有在单机模式下才有意义。定时器服务就是一种,给予一个恒定的间隔有规律地发生。定时器服务通常用来自动执行管理任务,比如日志文件转 储,系统数据备份,数据库consistence 检测和冗余数据清除。一些基于事件的服务也很难移植到集群环境中。初始化服务就是很好的例子。邮件通知服务也是如此。
这些服务由事件而非请求触发,应当只执行一次。这样的服务将使得集群的负载均衡和失效转移的意义降低。
一些产品对这样的服务早有准备,例如,JBoss使用“集群单一设施”协调所有实例,保证只执行这些服务一次或仅仅一次。基于你选择的产品平台,这些服务有可能成为移植到集群的障碍。
7.8 分布式结构比排列式结构更有弹性? -- 不一定!
J2EE技术,特别是EJB,因为分布式计算而产生。解耦业务功能,重用远程对象使得多层应用流行。但我们也不能把所有东西都分布式化吧。一些J2EE架构师认为将web层和EJB层紧密排列更好。
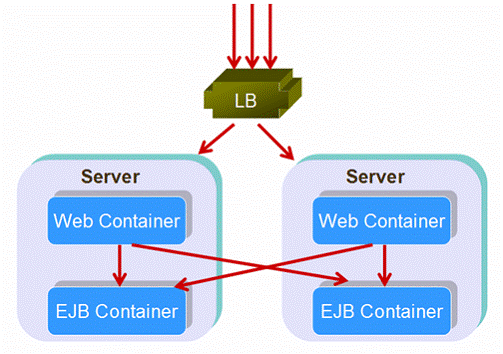
图20:分布式结构
如图20分布式结构,当请求到来时,负载均衡器将它们分发到不同的服务器上的web容器,如请求中包括EJB调用,web容器将重新分发EJB调用到布通的EJB容器。这样,请求被负载均衡和失效转移了两次。
一些人不看好分布式结构,他们指出:
*第二次负载均衡是不必要的,因为它不能使任务分配更均匀。每个服务器实例在同一个JVM实例中都拥有它自己的web容器和EJB容器。让EJB容器处理其它实例的web容器的请求,看不出比实例内部调用有更多的优点。
*第二次失效转移是不必要的,因为它并不增加可用性。多数提供商的产品都是在同一JVM实例中集成了web容器和EJB容器。如果EJB容器失效,在多数情况下,web容器此时也是失效的。
*性能降低了。设想应用中的一个方法将调用几个EJB,若对每个EJB进行负载均衡,最终应用实例跨越了很多的服务器实例运行。这些服务器对服务器的横跨通信是不必要的。还有,如果方法在一个事务中,事务边界将包括许多服务器实例,严重影响了性能。
在实际的运行状态,多数提供商(包括Sun JES, Weblogic and JBoss)优化了EJB负载均衡使得请求首先选择在同一个服务器中的EJB容器。用这种办法,只在web层进行负载均衡,后续的服务都在同一服务器上处 理。这种结构称为排列式结构。技术上说,也是分布式结构的一种。
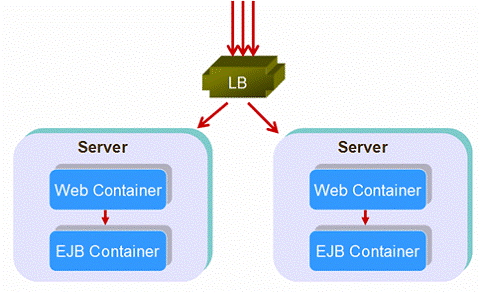
图2:排列式结构
一个有趣的问题是,因为大部分发布运行时最后都成为了排列式结构,为什么不直接使用本地接口代替远程接口,这将提升性能。当然可以这样。但请记住,使用本 地接口,web组件和EJB就紧密耦合了,使得方法直接调用而非通过IIOP/RMI。负载均衡器和失效转移分发器没有机会拦截本地调用,“Web+ EJB”过程就被作为一个整体了。
不幸的是,集群中,在J2EE服务器上使用本地接口有很多限制。EJB是带有本地接口的本地对象,但他们不可序列化。限制就是本地引用不允许存储在 HTTPSession中。一些产品,如Sun JES区别处理本地EJB,使他们可序列化也能存储在HTTPSession中。
另一个有趣的问题是:因为排列式结构很流行也有良好的性能,为什么还需要分布式结构?大多苏h情况,事出有因,有时分布式结构不可替代。
*EJB不仅仅给web容器使用,富客户端也是用户之一。
*EJB组件和web组件可能在不同的安全级别,需要物理地分隔开来。所以,防火墙可能用来保护运行EJB的更重要的机器。
*Web层和EJB层的极端不对称也许是选择分布式结构的一个好理由,例如,一些EJB组件太复杂资源消耗巨大,那么它们只能在一些昂贵的 大服务器上运行;另一方面,web组件(HTML,JSP,Servlet)非常简单可以在便宜的PC服务器上运行。在这种条件下,专门的web服务器接 收客户端请求,提供静态数据(HTML和图片)和简单的web组件(JSP和Servlet)。大型服务器只用来进行复杂计算。
8 结论
集群和单机环境是不同的。J2EE提供商以不同的方式实现集群。为了构建一个大型的系统,在项目开始时,你就应该为J2EE集群做准备。选择合适的 J2EE产品是g和你的应用。选择合适的第三方软件和框架时确保它们可以被集群。然后设计合适的架构以得到集群带来的实际利益。
概述
一个集群系统是一群松散结合的服务器组,形成一个虚拟的服务器,为客户端用户提供统一的服务。对于这个客户端来说,通常在访问集群系统时不会意识到它的服务是由具体的哪一台服务器提供。集群系统一般应具高可用性、可伸缩性、负载均衡、故障恢复和可维护性等特殊性能。越来越多的关键任务和大型应用正运行在J2EE平台上,象银行之类的应用要求很高的可用性(HA),大型系统比如大型网站则要求更好的伸缩性。J2EE集群是最常用的技术,用来提供高可用性和伸缩性的容错服务,单机部署和多机集群化部署差别很大,网上的资料大多语焉不详,即使文档图文并茂,也是到了关键处就部署成功,其实后面还要做些工作才行,且多以单机部署多个server来模拟集群化部署,其实和真正多机部署还是有比较大的差别。本文仅以weblogic应用服务器为例说明集群化部署。
集群层次说明
Web级集群,是J2EE集群中最重要和基础的功能。web层集群技术包括:Web负载均衡和HTTPSession失效转移。web负载均衡,基本的是在浏览器和web服务器之间放置负载均衡器。<o:p></o:p>
应用级集群,是ejb集群,EJB是J2EE应用平台的核心,EJB是用于开发和部署具多层结构的、分布式的、面向对象的Java应用系统跨平台的构件体系结构。主要是业务应用,部署在EJB容器上。<o:p></o:p>
数据库级集群,是oracle数据库设置多个数据库实例,全部映射到数据库。
Weblogic集群概念
Ø Domain:由配置为Administrator Server的WebLogic Server实例管理的逻辑单元,这个单元是有所有相关资源的集合。
Ø Server: 一个相对独立的,为实现某些特定功能而结合在一起的单元。按功能可分为domain server 和managed server。一个Domain 可以包含一个或多个WebLogic Server实例,甚至是Server集群。一个Domain中有一个且只能有一个Server 担任管理Server的功能,其它的Server具体实现一个特定的逻辑功能。
Ø Domain Server:在一个集群中,有且仅有一个domain server,即管理server,该server只负责管理多个Managed server(被管理server),即domain server仅仅是行政领导,考勤之类的活动,如某个managed Sever的状态,是未知(unKnown),还是运行(run),还是停止(shutdown),远程启动等等,不负责具体业务。因此部署时domain server上不要部署具体任务,毕竟人家是当官的吗。
Ø Managed Server:真正的实干家,部署具体的应用。应用及业务逻辑组件被分发在多个受管服务器(Managed Server)。<o:p></o:p>
Weblogic集群要求
Ø 集群中的所有Server必须位于同一网段,并且必须是IP广播(UDP)可到达的
Ø 集群中的所有Server必须使用相同的版本,包括Service Pack
Ø 集群中的Server必须使用永久的静态IP地址。动态IP地址分配不能用于集群环境。如果服务器位于防火墙后面,而客户机位于防火墙外面,那么服务器必须有公共的静态IP地址,只有这样,客户端才能访问服务器 <o:p></o:p>
Ø 使用weblogic的支持集群的licence<o:p></o:p>
项目实战
项目概况
我们的项目是struts—ejb—hibernate—spring,因为hibernate和spring都必须进行初始化且初始化都依赖于servlet,在系统启动时就初始化数据,并且我们在web层和ejb层分别部署为web集群和ejb集群,而hibernate和spring都部署在应用服务器上。为此,我们打了两个部署包,一个是cnlife.war, cnlife_app.ear,其中cnlife.war包部署在web集群上,cnlife
_app.ear部署在ejb集群上,cnlife_app.ear包括两个包,其中一个是cnlifeejb.jar(ejb包),
另外一个是backgroudinit.war,backgroudinit.war用来初始化spring,hibernate的初始化数据。
<o:p> </o:p>
cnlife.war (部署在Web Server)
_backgroudinit.war
|
cnlife_app.ear-| (部署在 Application Server)
|_cnlifeejb.jar
<o:p> </o:p>
Ejb是stateless Session bean,使用ejb的目的就是应用服务器集群,部署示意图如下:
![]()
Web级集群
Web集群中使用内存复制策略<o:p></o:p>
weblogic.xml 如下
<o:p></o:p>
8.1//EN" "http://www.bea.com/servers/wls810/dtd/weblogic810-web-jar.dtd"><o:p></o:p>
<o:p> </o:p>
<weblogic-web-app><o:p></o:p></weblogic-web-app>
<session-descriptor><o:p></o:p></session-descriptor>
原文地址:http://hqman.iteye.com/blog/92684