剖析的艺术:使用Intel VTune Amplifier,第6部分
原文:https://hadibrais.wordpress.com/2017/07/27/the-art-of-profiling-using-intel-vtune-amplifier-part-6/
Hadi Brais 著
本系列的前面部分都可以通过以下链接找到:第1部分,第2部分,第3部分,第4部分和第5部分。
VTune报告的热点如下面所示:
| FUNCTION | MODULE | CPU TIME |
| gen_pswd | PasswordCracker | 4.302s |
| do_pswd | PasswordCracker | 1.548s |
| CalculateCRC | PasswordCracker | 1.544s |
| ___printf_chk | libc.so.6 | 0.036s |
函数gen_pswd占用了CPU耗时总和的50%以上。定位到该函数的调用堆栈,点击它的堆栈帧实体,VTune将会为您显示该函数每个语句执行的耗时情况(这是根据每个语句的采样次数进行计算的)。
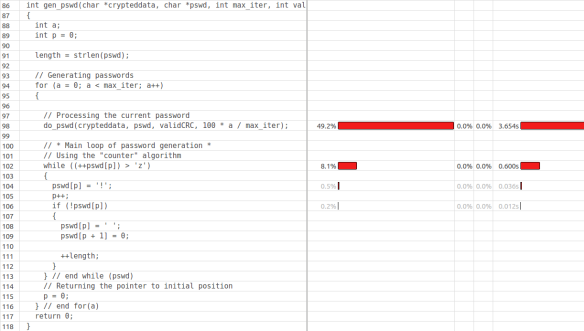
第98行几乎占用了整个程序CPU耗时的49%,大概是3.6秒。注意一点,第98行代码是函数gen_pswd函数所有引用的,而不是do_pwsd函数引用的。查看一下汇编指令的CPU耗时:
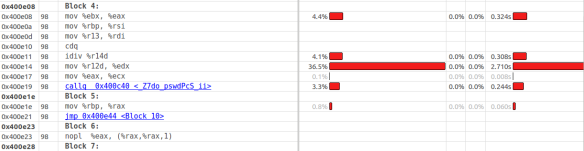
VTune已经标明外部CPU耗时为49%,36%以上的执行开销在指令 mov %r12d, %edx 。如果您的仅从字面上理解,这是毫无意义的,因为寄存器之间进行值拷贝的开销要比除法操作廉价的多。这很可能剖析采样问题,误导了您。这里更为普遍的问题是采样间隔为10毫秒,但是在这个间隔中能够执行数以100万计的指令,热点很可能出现在循环中。在这种情况下,继续剖析与分析微型框架是必要的,但是在这里我不打算这么做。取而代之,我们将尝试通过检查代码的方式确定热点。For循环中主要包括两块:调用do_pswd函数和嵌套的while循环。如果您可以优化掉任何一个,我们就有理由相信预期的性能优化是有效的。函数do_pswd做了两件事件:报告进度和检查当前候选密码。语句printf用于报告进度是之前的热点。由于总共迭代次数10亿次,printf将会每隔1万次迭代执行一次。总共迭代次数为10,0000。这里您能够做一件事件,就是尽可能的减少进度的报告频率。让我们减少它基本迭代数的总和,如这样ITER/10。另外,gen_pswd调用数以10亿次,只执行ITER/10次迭代。我们在do_pswd调用printf之前先计算好进度。剖析结果如下:
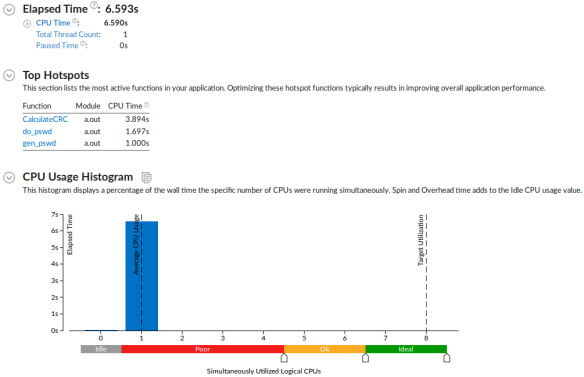
很棒。执行时间大约改善了14%,但出现了其他有意思的热点。现在没有什么能比报告中CPU利用率已经相当于100%超过99%更有价值了。让我们看看下次还能做什么吧。