剖析的艺术:使用Intel VTune Amplifier,第7部分
原文:https://hadibrais.wordpress.com/2017/07/29/the-art-of-profiling-using-intel-vtune-amplifier-part-7/
Hadi Brais 著
本系列教程的前面部分都可以通过以下链接找到:第1部分,第2部分,第3部分,第4部分,第5部分和第6部分。
在第6部分中,执行时间被优化了14%,密码破解吞吐量变为大概150百万个密码每秒。回到第1部分,基线吞吐量大概为3百万个密码每秒。我们已经取得了长足的进步,但还可以从VTune中获取更多帮助。
在第6部分的最后图表中,热点排行榜出现了新的热点。CalculateCRC累积超过了50%的执行时间,让我们分别从源代码和汇编代码的角度观察一下。

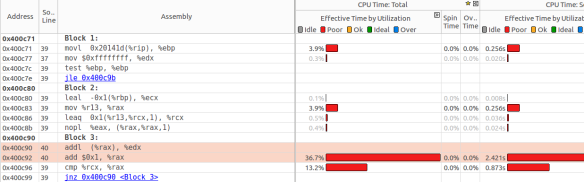
这里是高亮两条代码展开后的指令,其中第40行为热度最高代码。VTune显示的该代码行的汇编指令实现,这些信息是VTune通过带优化编译选项且开启调试信息的二进制可执行体中获取的。例如第41行就是灰色无效的,它表明总是被编译器优化的代码,尤其是编译器会将CalculateCRC内联到它的调用函数中,并省略掉它的返回语句。
VTune显然将36.7%的执行时间归于两条高度的指令,完全是因为第二条指令。但是这条指令仅是简单的将寄存器数据累加,真的开销那么昂贵吗?
记住VTune是定期进行性能指标采样的。在原始性能度量和单独指令之间的关联性取决于VTune,不可避免的在VTune分析中出现错误。但是这些信息仍然是有用的,我们可以使用人为分析技术精确定位到热点。
尽管VTune的分析是不精确的,但通常已经离真相不远了。让我们检查一下附近的指令,看看它们是不是开销很大。除了以下两条指令可能开销大之外其余都是廉价的:一个条在0x400c71,另一条是0x400c90。它们都是进行内存访问。根据内存访问模型,它们之所以可能慢的原因,一个是cache misse,一个是bandwith限制。综上所述,我们并还没有足够的信息来确定它。
不管怎样,我们先退一步,关注整个函数function。该函数会被执行数以10亿次,里面有个for循环。从计算机体系结构角度来说,可以充分地优化它,但题更可能是算法本身。这种情况下,通常去理解算法实现,看看能否进行优化会更好一些。不幸地是,在这世界上,即使是VTune还是其他工具也不能帮助我们对算法进行优化。看上去我们一时不知道能做什么了,所以现在您不得不进行一些手动尝试。然而在这个系列中关注的是VTune,我不会使用这种方法, 并继续追求在体系结构层面上的优化, 希望在这个层次上仍然找到一些重要的优化点。
幸运的是,在这个示例中,大多数的指令都是廉价的。通常情况下,使用TBS剖析查找和优化这些开销昂贵的指令是非常困难的。在这种时候,通用有勘探(General Exploration)微型框架分析或内存访问(Memory Access)微型框架分析可供使用,它们都是使用EBS,Intel Advisor 也能够提供巨大帮助。记住EBS中的事件,VTune使用硬件性能计数器,并为所有的指令维护计数器连续性来度量性能指标。即使剖析结果不是那么的精确,基于EBS结果也趋向于更为精确,并提供更多有用的信息。我不做微型框架分析,所以暂时不管它。
VTune的高级热点分析相比基本热点提供了多得多的信息,尤其是能够帮助你找到热点循环和函数。您可以关注到可并行化热点循环,尝试内联热点函数或使用整体程序优化(whole program optimization)方式优化它们。
创建一个新的分析,选择高级热点类型,保留采样间隔为默认值1毫秒。选择细节级别为“热点,调用计数,循环访问计数和堆栈”。这个细节级别会增加剖析开销,并级程序的CPU耗时带来稍微增长。运行分析,其结果会类似于下图显示的那样。
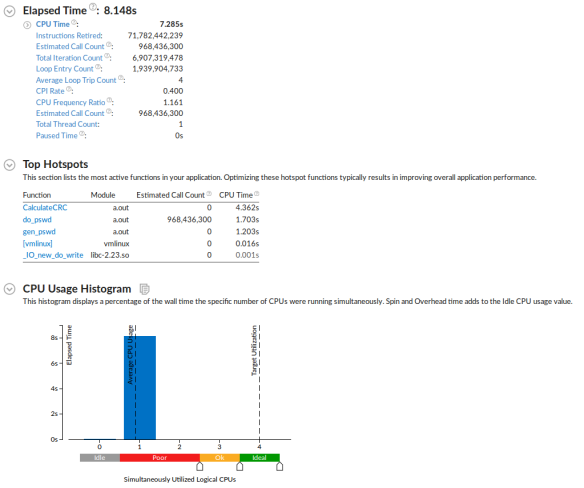
VTune展示了更为丰富的信息,既可以直接定位热点,也可以指导更深入的分析。在这里我们关注循环访问计数和调用次数的评估。
VTune通过观测循环控制流来评估循环访问计数。VTune记录了处于CalculateCRC中大概数以10亿次的循环迭代,与在gen_pswd中数值相近,这足以证明,将努力花在这些函数中的循环并行化上是很有价值的。但在该系统中,我并不打算这么做。
首先,调用计数看上去令人吃惊。CalulateCRC和gen_pswd的调用次数怎么可能会是零呢?好吧,CalulateCRC的调用次数之所以是零,是因为它被编译器内联了。gen_pswd没有被内联,实际上在程序中被调用了一次,但调用次数并不足以在一个采样剖析中能被抓取到。接下来有趣的函数是do_pswd。这个函数显然没被内联,它被调用了数大概数以10亿次。实际上它确实被调用了数以10亿次,但再次提及,采样剖析时并不能抓取所有调用。注意一下,一个准确的调用度量需要使用基于仪表(instrumentation-based)剖析。然而在高级热点分析中,硬件事件用于测量调用次数。
这里稍微简单的关注一下编译器强制内联函数。在gcc中,您总是可以使用总是内联( always_inline )指示符。如果使用得当,不仅是do_pswd还是CalculateCRC和CheckCRC确保它们一样得到内联。进行这个变更,编译代码,重新剖析。在我这边看到的结果是,VTune已经完全忽略掉了所有的调用计数度量,因为没有调用得到记录。密码破解程序的吞吐量变为了大概170百万每秒。
接下来是该系列的最后一部分,我会做个总结。