剖析的艺术:使用Intel VTune Amplifier,第5部分
原文:https://hadibrais.wordpress.com/2017/07/27/the-art-of-profiling-using-intel-vtune-amplifier-part-5/
Hadi Brais 著
本系列的前面部分都可以通过以下链接找到:第1部分,第2部分,第3部分和第4部分。
在上一部分中,我们对程序进行了修改和分析之后,您将可以看到以下的类似结果:
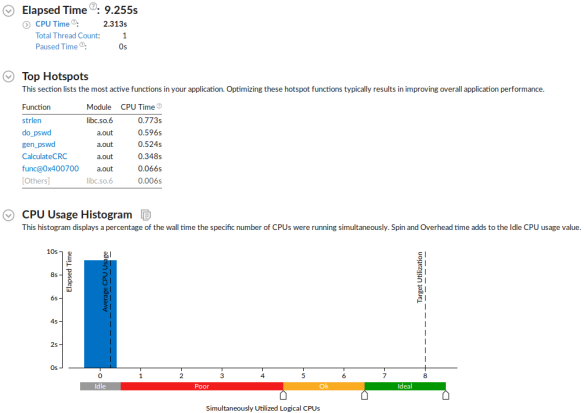
平均CPU利用率为0.25,CPU耗时为2.3秒。等等,现在还不是高兴的时候。VTune之前告诉我们CPU耗时为2.7秒,运行时间为17.1秒。这意味着花费在printf函数的总共执行时间为17.1 – 2.7 = 14.4。优化之前printf被调用次数是以10百万数,现在只有数以10万次。因此, 应该只有百分之14.4 < 0.2 秒的I/O开销。但从结果显示超过了7秒,很显然哪里出问题了。
起初这令我很困惑,我怀疑是不是当采样间隔太小时,VTune使用TBS模式时触发采样导致的问题。然后我将采样间隔修改回了默认的10毫秒,并重新进行剖析:
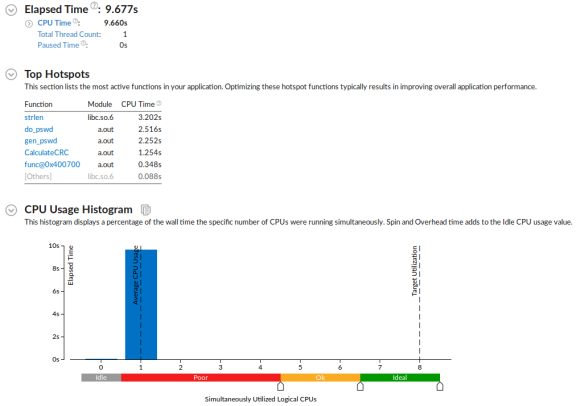
漂亮!这才是有意义的结果。CPU耗时为9.6秒,比运行时间稍微大一点。同样CPU利用率为0.99,已经很接近理想值了,这意味着printf函数已不在是热点。从VTune的热点排名中,这次可以很清楚的看到strlen函数像是罪魁祸首。它大概占用了CPU耗时的33%,让我们检查一下堆栈吧:
libc.so.6 ! strlen – strlen.S
a.out ! do_pswd + 0x3a – main.cpp:60
a.out ! gen_pswd + 0x45 – main.cpp:94
a.out ! main + 0x1d5 – main.cpp:233
libc.so.6 ! __libc_start_main + 0xef – libc-start.c:291
a.out ! _start + 0x28 – [unknown source file]
注意一下,您可能会看到一个不同的堆栈或比这里多一些,这是因为在程序代码中有多个位置对strlen进行调用 ,这也取决在进行采样的时候,当前捕捉的是哪个被编译优化内联的函数。这个堆栈告诉您的,从do_pswd方法中调用的strlen函数开销最大。不管怎么样,看一下这个函数只有一个位置调用了strlen,并且是在一个条件语句当中。从终端的输出当中,您可以看到输出只有在12倍数条件才为真。然而do_pswd会被调用数以10亿次,因此纠结strlen并没有太大的意义,这是怎么回事呢?
通过检查do_pswd函数,你可以看到条件里面会调用CheckCRC,这个函数转而调用CalculateCRC,它是个条件终止循环( loop termination condition)调用strlen。基于循环计数,调用strlen次数少于10亿次。不幸的是,我使用的编译器在优化代码时会在循环里面的strlen调用移到外面,使所有的迭代只会调用一次(通过查看汇编代码得到的),因此实际上strlen被调用了数以10亿次。如果您的编译没有这么处理,就手动完成了。
我们又能对strlen怎么样呢?这个函数用于计算以终止字符结束的字符串个数。我们能够完全避免调用它吗?让我们来检查一下生成的密码,看上去只是一些简单的普通数字模式。
在main函数中生成了第一个密码,在gen_pswd函数中会重新生成密码。只有在 !psw[d] 为真时,密码长度才会增长一个字符,这就是我们所看到的模式。这里还定义了一个全局变量用于保存密码字符串长度。当每次条件为真时,长度会增长1位。这个变量在gen_pswd起始处进行初始化。因此修改代码重新剖析一下,平均CPU利用率并未变化,因为变更并没有减少I/O的等待时间,反正现在已经接近最优了。结果只有CPU耗时减少了,变为大概7.4秒,有23%的优化,还不赖。在下一部分中,我们尝试做得更好吧。