剖析的艺术:使用Intel VTune Amplifier,第4部分
原文:https://hadibrais.wordpress.com/2017/04/07/the-art-of-profiling-using-intel-vtune-amplifier-part-4/
Hadi Brais 著
在该系列的上一部分中,我已经讨论了为目标程序设置VTune的基本热点分析。这里快速过一下目标程序,您会注意到在第18行(line 88)有一个非常重要的函数gen_pswd,有人可能会为觉得gen_pswd就是热点。然而在VTune的分析报告中却并非如此。确保您的CPU占用的热点在VTune显示视图如本文下图所示:
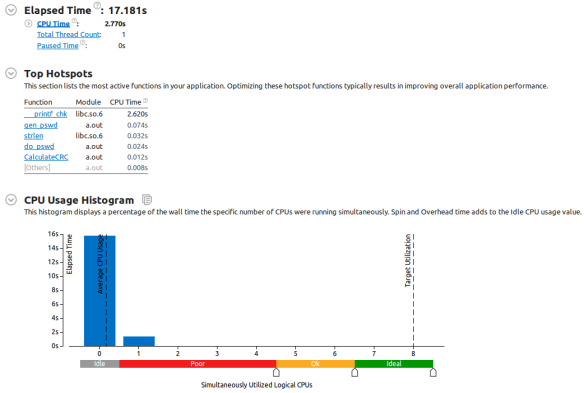
运行时间(Elapsed Time)是指程序在运行过程中并处于剖析时的时钟时间工作总和。S, E, O分区表示开始时间、结束时间、开销时间,运行时间 = E – S + O。通常情况下,剖析所带来的开销时间对于整个剖析程序运行时间来说是可以忽略不计的。在之后的优化代码处理中,可以使用这个运行时间作为关注的运行时间基线,但对于热点分析本身是毫无用处的。
CPU耗时是指所有线程执行代码的活动时间总和。并不包含线程同步请求锁和I/O操作完成的耗时(包括图形绘制)。需要额外注意的是CPU耗时包含了自旋锁处于自旋状态的耗时,这一耗时主要是用于内存请求服务和确保缓存一致性。它们之和在VTune术语中称为自旋开销时间(Spin and Overhead Time)。当CPU耗时大于运行时间时,表明程序是并行化的,这就需要您进行并发或同步分析。如果CPU耗时远远小于运行时间,表明出现了太多的 I/O同步。
当前目标是单线程的,所以等待时间 = 运行时间 – CPU耗时 = 17.181 – 2.770 = 14.411 秒。这足以说明了我们之前的假设,剖析所产生的开销是微乎其微的。同样我们也可以得出这么个结论,执行时间都花在的I/O等待上面,正如上面CPU使用直方图所显示的。
CPU使用直方图(The CPU Usage Histogram)
CPU利用率是一个量化应用程序有多少有效运行的度量。我的CPU有8个逻辑CPU(核心),所以CPU利用率最大为8或800%。CPU利用率是通过所有软件线程的总和计算得到的结果:CPUTime(T ,i),i是软件线程数,T是代码执行时长,它要比采样间隔大些。
与其笼统的报告CPU利用率数值,VTune还对CPU使用率进行了以下灵活的(可手动调整)4个分类:
n Idle:CPU利用率低于0.5。
n Poor:CPU利用率大于等于0.5,且小于或等于最大利用率的50%。
n OK:CPU利用率小于或等于最大使用率的85%。
n Ideal:CPU利用率大于最大利用率的85%。
CPU使用率是一个离散的度量,只是对数据进行归类,相对于CPU利用率作为连续的值要来得直观一些。
CPU使用率直方图的x轴显示的是从0开始跨越多个逻辑核心的CPU利用率。下面彩色条显示的是与之对应的CPU使用率。垂直的两个虚线,右边显示的是最大CPU占用率(图中是目标占用率),左边显示的是平均CPU利用率(图中平均CPU使用率)。高亮选择平均CPU使用率线条告诉您,具体平均CPU利用率为0.161。对于单线程的密码破解程序来说,最佳CPU利用率是1或100%。通过该系列教程,我将一步步接近这个目标,现在它是0.161。
CPU使用率直方图的y轴显示的是CPU运行时间。在图中有两个条蓝色垂直条,用于显示目标程序在不同CPU利用率的占用情况。其中一条处于中间位置,表示CPU占用率在-0.5~+0.5之间。每个垂直条就表示运行时间所处CPU利用率覆盖范围。你可以从直方图看出CPU使用率基本在Idle范围。对于一个单线程来说,一个处于1中间位置的蓝条才是优秀的。
罪魁祸首
当前我们找到了这些昂贵的开销来自于I/O操作,看看是不是能通过减少或消除它们。热点排名摘要面板如下:
| FUNCTION | MODULE | CPU TIME |
| ___printf_chk | libc.so.6 | 2.620s |
| gen_pswd | PasswordCracker | 0.074s |
| strlen | libc.so.6 | 0.032s |
| do_pswd | PasswordCracker | 0.024s |
| CalculateCRC | PasswordCracker | 0.012s |
| [Others] | PasswordCracker | 0.008s |
这个表格显示CPU耗时最高的函数。注意因为采样频率非常高(10ms),对于一些CPU耗时相近的函数,它们的顺序可能出现差异。处于排名靠前的两个函数,它们的CPU耗时非常大,在每次程序剖析中,顺序应该是不变的,其他函数可能会出现不同顺序。通过减少采样频率的方式,可以使剖析结果更稳定一些。
CPU耗时显示的是自身耗时(或是排它耗时),也就是不包括它调用其他函数的耗时。第一个函数___printf_chk,看起来跟标准的printf函数相关。通过调用printf将特定字符串写到标准输出,通常是命令行窗口。这是个I/O操作,但是谁在调用它呢?我们可以在Bottom-up面板中查看有关___printf_chk的堆栈调用列表。列表如下:
libc.so.6 ! ___printf_chk – printf_chk.c
PasswordCracker ! printf + 0x29 – stdio2.h:104
PasswordCracker ! do_pswd + 0x4 – main.cpp:63
PasswordCracker ! gen_pswd + 0x46 – main.cpp:92
PasswordCracker ! main + 0x209 – main.cpp:231
libc.so.6 ! __libc_start_main + 0xef – libc-start.c:291
PasswordCracker ! _start + 0x28 – [unknown source file]
跟之预期的一样,__printf_chk调用printf。更清楚的看到,printf在main.cpp中第63行的do_pswd函数中也被调用了。然后通过在代码中搜索”printf”,我们可以很快的确定printf的调用位置,一个是do_pswd,更多的是print_dot。对于检测这些执行路径使用的采样间隔(10ms)可能太大了,但实际上并无大碍,我们的目的仅是找到热点,63行的printf调用看上去就是了。
让我们修改刚才定位到调用printf代码的位置,让它在每隔10,000个密码时才调用一次。使用优化参数重新编译运行一下。破解的吞吐量变成了每秒107百万次密码破解,对于之前的3百万已经是非常大的优化了。注意重复运行多次,确保优化结果是可重现的。在这里,您可以使用VTune的比较分析功能(compare between two analysis results),在这里我就不过多赘述了。
现在程序能够在1秒内进行至少10百万次迭代。让我们做些更有趣的尝试,看看有没有更多的优化空间,使它能够提升到每秒10亿次迭代。增长迭代次数并不会改变吞吐量,但会增加执行时间。这会给予剖析充足的时间收集信息来了解它的行为。仍然使用基本热点,但这次使用1ms采样间隔。我将会在下一部分讨论结果。