剖析的艺术:使用Intel VTune Amplifier,第1部分
原文:https://hadibrais.wordpress.com/2017/03/15/the-art-of-profiling-using-intel-vtune-amplifier-part-1/
Hadi Brais 著
Intel VTune Amplifier是Intel处理器的最佳性能剖析及分析工具。它不仅支持所有Intel处理器,并能在Windows,Linux,Android和macos下同时工作。其中最基本的剖析功能也能用于非Intel兼容处理器(第2部分讨论)。如果你正处于非商业工作环境,获取它是免费的(obtain it for free)。除此之外,还有30天免费评估时间,要是你老板有钱的话,请购买正版吧。
Intel VTune Amplifier是提供给经验丰富的开发者及性能分析工程师使用的。因此,在这里我假设您能够自行安装它到系统中。在这个教程里,我使用的是非虚拟系统Ubuntu16.04,单颗Intel Core i7-4770处理器。但在学习该教程时可以使用您首选的平台。同样您也可以在虚拟机中使用VTune,参考这里(here)。从现在起,我将Intel VTune Amplifier简称为VTune,使用的版本是VTune 2017 Update 2,当然时下流行的版本都是可以的。
VTune的使用方式有三种GUI mode、CLI mode、Visual Studio中。前面两个使用方式对应的二进制可执行体分别是amplxe-gui和amplxe-cl,我使用的是amplex-gui。
坦白说,VTune的文档和教程一直以来都写得不太好。感觉它们更多的是为VTune的开发者而不是用户写的,过于简洁且含糊不清。看起来就像是Intel有意为之,使它们看上去尽可能简单, 产品看起来不太笨重或复杂, 而吓跑潜在的客户。我很难想像Intel在兜售产品时说“为专家打造“。
反正,本教程是为那些认真的性能分析人员而编写的, 希望他们能够真正理解正在查看的数值和图表。如果您是初学者,从Intel的教程开始会更为适合。
剖析流程
剖析是收集有关程序动态行为信息的活动。这些信息不仅用于聚合、分析,还以某些方式优化程序。不管使用的是哪款剖析器,在流程上都是一样的。
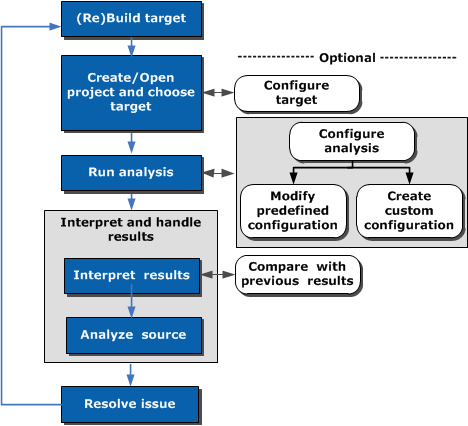
来源: https://software.intel.com/en-us/node/544005
首先,确定剖析目标程序,生成二进制可执行体。最好调用符号是可用的,可以是嵌入到二进制中,或是单独文件。剖析器使用调试信息进行单个执行体剖析或整个系统剖析。
第2步,配置剖析器,剖析哪些内容、收集哪些信息及其他设置。在VTune术语中,称之为分析项。VTune工程就是分析项的集合。
第3步,运行分析,这包括附加到已运行的进程或启动一个新进程来分析。剖析器会对性能带来一定的开销,小至1.1x,大到10,000x,这基于所使用的剖析技术。采样的开销最小,而仪表的开销最大。使用VTune时要根据具体情况择其一。
第4步,VTune将解析结果,更好的展示内容,让您方便定位感兴趣的部分。这时,在VTune的帮助下,您可以进行结果分析了。您也可以进行结果比较,跟之前运行的结果相比,确定您对源代码或系统更改对程序造成了怎样的影响。您还需要决定是否还存在尚未解决的问题。如果没有,工作至此结束(很遗憾,流程图中少了这步)。
最后, 为了确信您所做变更已经解决了问题,需要重新对程序或系统进行剖析。
这个过程一直持续到所有问题得到解决,或是您察觉不到还存在问题为止。
所以,是什么导致了性能问题呢?这取决于程序本身是非功能性规范。应该有一些文档, 说什么是可以接受的, 通过分析, 你可以决定是否满足非功能性要求。
剖析程序
有个叫Kris Kaspersky的人在十年前写了一本很棒的书:Code Optimization: Effective Memory Usage。尽管书中的实验和使用的软件至今已经过时了,但其中的想法和呈现的技术在现在乃至多年后依旧有用。我将在该教程中使用的吞吐量程序改编于书中清单1.17,在这里找到(here)。
稍微提醒一下,您的不必拥有这本书,或是在学习该教程后去阅读它。理由嘛,我使用的程序跟Kaspersky书中使用的程序并不是一回事。首先,书中使用的VTune版本非常笨重,VTune从那里起已经大幅变更。其次,Kaspersky在书中讨论的一些技术并不适用于今天的处理器。我所希望的是您通过使用VTune优化程序时收获有用的经验和知识。
现在我们快速浏览一下代码,对它的想法和目的有个基本了解。该系列教程是从处理大型代码库的开发人员的角度出发而编写的, 他们对代码仅有有限的了解或全部理解。这很像现实中您的使用剖析的情景。因此, 这里假设代码太大且复杂, 也无法完全理解。
使用您喜欢的编译器并打开优化选项。在不带任何特殊参数的情况下运行构建得到的二进制可执行程序。程序将会输出密码破解吞吐量,每秒检查的密码数。在我的系统中,大概是3百万每秒。这个度量将是该教程中使用VTune剖析器进行优化的衡量标准。
在我们做任何事之前,先得决定目标吞吐量。换句说,我们将密码破解吞吐量提升了多少呢。在实际的非功能性规范中,这可能是商业目标,提升2百万。然而,在这个教程里,让我们充分利用VTune,尽可能的提升吞吐量吧。
术语基线被用于平台、程序或系统性能的优化参考值。并报告相较于基线的所有优化情况。这里以3百万吞吐量作为基线。如果我们能够对程序实现吞吐量提升2百万,那么就相当于提升了33%或1.5x。
可重现性
可重现性是对某一度量值进行多次测量,并每次得到相同测量结果的能力。可重现性是性能评估的基础。如果一个实验是不可重复的,其结果是不可重现的,那么就无法判断是否优化了或优化了多少。
我们必须保证基本吞吐量的可重现性。这是通过连续多次测量吞吐量并观察结果中的方差来得到的。计算机是极其的复杂,并不能像期望的那样每次都得到相同的测量结果。一些细微的变化通常是可以接受的。当然这确保程序和平台的不变性。我们称之为基于统计的性能评估。
现在我不打算深入讨论性能评估的所有数学知识,那样就在耽搁时间了。对于一个简单的密码破解程序,我们无论如何都无须关注这些。连续运行程序15次,吞吐量结果顺序如下:
2,740,894
3,019,334
2,883,304
2,689,124
3,124,446
2,961,334
2,954,207
2,876,620
2,928,249
3,017,467
3,212,000
2,766,821
2,862,842
2,794,467
2,729,612
我们注意到吞吐量的最小值为2,689,124,最大值为3,212,000,平均值为2,904,048。在忽略吞吐量尾数的同时,我们也不会丢失精度,因为数值已经相当大了。另外注意一下,最小值与最大值实质上相差了17%。这种不确定性是系统与硬件导致的。这是一种常见的做法, 即在执行时间速度或吞吐量方面是根据平均 (又称算术平均数) 观察到的执行时间或吞吐量来衡量的。至此,基线吞吐量定为2,904,048。
调试符号
二进制可执行体包括了一系列指令和附加信息,操作系统使用这些信息确保常量、已初始化和未初始化静态变量能够加载到正确的空间中。对这一层进行剖析,定位其中的热点是困难的。但至少在二进制中函数名称和位置信息是需要知道的,以便在剖析结果时,用于解析函数信息,要是有指令到源代码行的映射就更好。这些信息称之为调试符号或调试信息。
如果正在分析的程序源代码可用, 则可以启用调试符号选项来编译它。否则,就需要检查看作者或开发商是否提供了单独的调试符号。
使用您的喜欢的编译器,打开调试符号选项,编译密码破解程序。这对于用户级的分析已经足够了。但对于内核级的分析,您还需要内核的调试符号。对于如何安装Ubuntu系统的调试符号,您可以查看这遍博客(this)。我安装这些符号只是出于好奇。在没有内核调试符号情况下,VTune将会把所有的内核代码聚合到一个称为[vmlinux]的单独标签中,因为实际的函数名称不可用。
如果VTune没有找到相应的调试符号及源代码,它会向您显示一个警告,您也可以手动将包含这些文件的目录添加到搜索目录中(here)。
在下一部分,我将讨论一下VTune的工程配置及分析类型,敬请期待。