Trie—单词查找树
l 简介
Trie,又称单词查找树、前缀树,是一种哈希树的变种。应用于字符串的统计与排序,经常被搜索引擎系统用于文本词频统计。
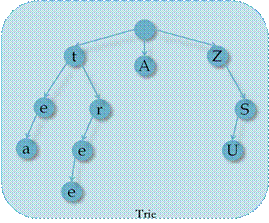
含有单词“tea”“tree”“A”“ZSU”的一棵Trie。
l 性质
n 根节点不包含字符,除根节点外的每一个节点都只包含一个字符。
n 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
n 每个节点的所有子节点包含的字符都不相同。
l 优点
n 查询快。对于长度为m的键值,最坏情况下只需花费O(m)的时间;而BST最坏情况下需要O(m log n)的时间。
n 当存储大量字符串时,Trie耗费的空间较少。因为键值并非显式存储的,而是与其他键值共享子串。
n Trie适用于“最长前缀匹配”。
l 操作
n 初始化或清空
遍历Trie,删除所有节点,只保留根节点。
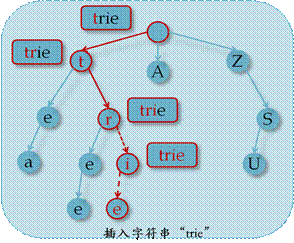
n 插入字符串
1. 设置当前节点为根节点,设置当前字符为插入字符串中的首个字符;
2. 在当前节点的子节点上搜索当前字符,若存在,则将当前节点设为值为当前字符的子节点;否则新建一个值为当前字符的子节点,并将当前结点设置为新创建的节点。.
3. 将当前字符设置为串中的下个字符,若当前字符为0,则结束;否则转2.
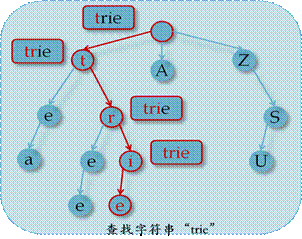
n 查找字符串
搜索过程与插入操作类似,当字符找不到匹配时返回假;若全部字符都存在匹配,判断最终停留的节点是否为树叶,若是,则返回真,否则返回假。

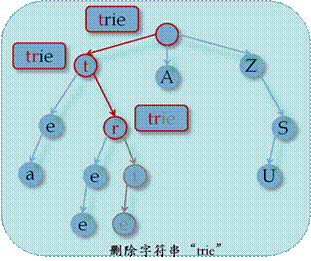
n 删除字符串
首先查找该字符串,边查询边将经过的节点压栈,若找不到,则返回假;否则依次判断栈顶节点是否为树叶,若是则删除该节点,否则返回真。
l 实现
对于字符表大小为S的字符串集,需建立一个S叉树来代表这些字符串的集合。
l 代码

 trie.h
trie.h
/**//** 版权所有 (C) 2009 喻扬 中山大学
 /* 本程序只作学习用途,未经许可,不得用于任何商业目的。
/* 本程序只作学习用途,未经许可,不得用于任何商业目的。
 */
*/
 #include <string.h>
#include <string.h>
/**//* trie的节点类型 */
template <int Size> //Size为字符表的大小
struct trie_node  {
{

 /**//* 数据成员 */
/**//* 数据成员 */
bool terminable; //当前节点是否可以作为字符串的结尾
int node; //子节点的个数
trie_node *child[Size]; //指向子节点指针
/**//* 构造函数 */
trie_node() : terminable(false), node(0) { memset(child, 0, sizeof(child)); }
};
/**//* trie */
template <int Size, typename Index> //Size为字符表的大小,Index为字符表的哈希函数
class trie {
public:
/**//* 定义类型别名 */
typedef trie_node<Size> node_type;
typedef trie_node<Size>* link_type;
/**//* 构造函数 */
trie(Index i = Index()) : index(i) {}
/**//* 析构函数 */
~trie() { clear(); }
/**//* 清空 */
void clear() {
clear_node(root);
for (int i = 0; i < Size; ++i) root.child[i] = 0;
 }
}
/**//* 插入字符串 */
template <typename Iterator>
void insert(Iterator begin, Iterator end) {
link_type cur = &root; //当前节点设置为根节点
for (; begin != end; ++begin) {
if (!cur->child[index[*begin]]) { //若当前字符找不到匹配,则新建节点
cur->child[index[*begin]] = new node_type;
++cur->node; //当前节点的子节点数加一
}
cur = cur->child[index[*begin]]; //将当前节点设置为当前字符对应的子节点
}
cur->terminable = true; //设置存放最后一个字符的节点的可终止标志为真
}
/**//* 插入字符串,针对C风格字符串的重载版本 */
void insert(const char *str) { insert(str, str + strlen(str)); }
/**//* 查找字符串,算法和插入类似 */
template <typename Iterator>
bool find(Iterator begin, Iterator end) {
link_type cur = &root;
for (; begin != end; ++begin) {
if (!cur->child[index[*begin]]) return false;
cur = cur->child[index[*begin]];
}
return cur->terminable;
}
/**//* 查找字符串,针对C风格字符串的重载版本 */
bool find(const char *str) { return find(str, str + strlen(str)); }
/**//* 删除字符串 */
template <typename Iterator>
bool erase(Iterator begin, Iterator end) {
bool result; //用于存放搜索结果
erase_node(begin, end, root, result);
return result;
}
/**//* 删除字符串,针对C风格字符串的重载版本 */
bool erase(char *str) { return erase(str, str + strlen(str)); }
/**//* 按字典序遍历单词树 */
template <typename Functor>
void traverse(Functor &execute = Functor()) {
visit_node(root, execute);
}
private:
/**//* 访问某结点及其子结点 */
template <typename Functor>
void visit_node(node_type cur, Functor &execute) {
execute(cur);
for (int i = 0; i < Size; ++i) {
if (cur.child[i] == 0) continue;
visit_node(*cur.child[i], execute);
}
}
/**//* 清除某个节点的所有子节点 */
void clear_node(node_type cur) {
for (int i = 0; i < Size; ++i) {
if (cur.child[i] == 0) continue;
clear_node(*cur.child[i]);
delete cur.child[i];
cur.child[i] = 0;
if (--cur.node == 0) break;
}
}
/**//* 边搜索边删除冗余节点
返回值用于向其父节点声明是否该删除该节点 */
template <typename Iterator>
bool erase_node(Iterator begin, Iterator end, node_type &cur, bool &result) {
if (begin == end) { //当到达字符串结尾:递归的终止条件
result = cur.terminable; //如果当前节点可以作为终止字符,那么结果为真
cur.terminable = false; //设置该节点为不可作为终止字符,即删除该字符串
return cur.node == 0; //若该节点为树叶,那么通知其父节点删除它
}
if (cur.child[index[*begin]] == 0) return result = false; //当无法匹配当前字符时,将结果设为假并返回假,
//即通知其父节点不要删除它
else if (erase_node(++begin--, end, *(cur.child[index[*begin]]), result)) { //判断是否应该删除该子节点
delete cur.child[index[*begin]]; //删除该子节点
cur.child[index[*begin]] = 0; //子节点数减一
if (--cur.node == 0 && cur.terminable == false) return true; //若当前节点为树叶,那么通知其父节点删除它
}
return false; //其他情况都返回假
}
/**//* 根节点 */
node_type root;
/**//* 将字符转换为索引的转换表或函数对象 */
Index index;
};
l 参考资料
英文维基 http://en.wikipedia.org/wiki/Trie
中文维基 http://zh.wikipedia.org/w/index.php?title=Trie&variant=zh-cn