 2016年4月28日
2016年4月28日
让程序中的简单if-else在编译期间决定
ex. 1 /*
2 * =====================================================================================
3 *
4 * Filename: 3.cpp
5 *
6 * Description:
7 *
8 * Version: 1.0
9 * Created: 03/01/2016 11:38:53 AM
10 * Revision: none
11 * Compiler: gcc
12 *
13 * Author: shih (Hallelujah), sh19871122@gmail.com
14 * Organization:
15 *
16 * =====================================================================================
17 */
18
19 #include <stdio.h>
20 #include <stdint.h>
21 #include <iostream>
22 #include <type_traits>
23
24 template<typename T>
25 struct is_swapable
26 {
27 static const bool value = std::is_integral<T>::value && sizeof(T) >= 2;
28 };
29
30 template<typename T>
31 T byte_swap(T value, std::true_type)
32 {
33 uint8_t *bytes = reinterpret_cast<uint8_t *>(&value);
34 for (std::size_t i = 0; i < sizeof(T)/2; ++i)
35 {
36 uint8_t v = bytes[i];
37 bytes[i] = bytes[sizeof(T) - 1 - i];
38 bytes[sizeof(T) -1 -i] = v;
39 }
40 return value;
41 }
42
43 template<typename T>
44 T byte_swap(T value, std::false_type)
45 {
46 return value;
47 }
48
49 template<typename T>
50 T byte_swap(T value)
51 {
52 return byte_swap(value, std::integral_constant<bool, is_swapable<T>::value>());
53 }
54
55 int main(int argc, const char *argv[])
56 {
57 int a = 0x11223344;
58 long b = 0x4455221112345678;
59 std::cout << std::hex << a << " " << b << std::endl;
60 std::cout << std::hex << byte_swap(a) << " " << byte_swap(b) << std::endl;
61 uint8_t c = 0x11;
62 char *d = "hello world";
63 std::cout << std::hex << byte_swap(c) << " " << byte_swap(d) << std::endl;
64 return 0;
65 }
66
2014年10月22日
安装额外的EPEL仓库
wget https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-2.noarch.rpm
yum install epel-release-7-2.noarch.rpm
安装后就可以安装R等了
2014年9月12日
最近使用Hive来统计数据,用了pyhs2来实现查询,但是有些复杂的处理比如,自定义对域名的处理等,不能通过hql来实现,发现能够使用udf。
Java来实现Hive的写法
package jsl.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class DomainRoot extends UDF {
public Text evaluate(Text s) {
if (s == null) {return null;}
String tmp = s.toString();
tmp = this.getDomainRoot(tmp);
return new Text(tmp);
}
private String getDomainRoot(String domain) {
throw NoneImplementException("xxxx");
}
}
如果Java的UDF需要当成常用的,不用每次add可以注册到Hive中,
ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java中加入
registerUDF("domain_root", UDFParseUrl.class, false);并重新编译hive即可
下面来说说重点,通过Streaming用Python来写处理。
关于Streaming的基础内容:


使用Transform来指定列,以及使用AS来指定生成的列以及可以指定转换生成列的类型
hive> select transform(col1, clo2)
> using '/bin/cat' as (new_clo1 int, new_clo2 double) from table;
约束:首先必须add file到hive中(当python中引用了其他如自己写的模块时,也需要一并add进去)
其次非常不幸,在单独的一个查询中,不能够使用UDAF的函数如sum()
再次不得为中间结果数据使用cluster by或distribute by
注意:对于优化查询,使用cluster by或distribute by 和sort by一起非常重要
2014年7月29日
在C++中不直接支持约束,用过C#模板的有个where来处理,但是C++中也有些小的技巧来处理。
在不完美C++中的must_have_base如下:
template<typename D, typename B>
struct must_have_base
{
~must_have_base()
{
void (*p)(D*, B*) = constraints;
}
private:
static void constraints(D *pd, B *pb)
{
pb = pd;
}
};
原理是通过不执行的成员函数把函数指针在析构函数中赋值,强迫编译器在编译期间检查成员函数内的约束。
自己写了个小的实例,虽然这儿有点点牵强,但是,很多情况也需要检查是否是某种类型的子类型的时候还是可以的,
完整代码如下:
1
2 template<typename D, typename B>
3 struct must_have_base
4 {
5 ~must_have_base()
6 {
7 void (*p)(D*, B*) = constraints;
8 }
9
10 private:
11 static void constraints(D *pd, B *pb)
12 {
13 pb = pd;
14 }
15 };
16
17 class base
18 {
19 public:
20 virtual ~base() {}
21
22 virtual void run() = 0;
23 };
24
25 class inherit_base: public base
26 {
27 public:
28 virtual void run()
29 {
30
31 }
32 };
33
34 class inherit_not_base
35 {
36 public:
37 virtual void run()
38 {
39
40 }
41 };
42
43 class test
44 {
45 public:
46 template<typename T>
47 void testfunc(T &t)
48 {
49 must_have_base<T, base>();
50
51 t.run();
52 }
53 };
54
55 int main()
56 {
57 test t_ok, t_nok;
58 inherit_base hb;
59 inherit_not_base hnb;
60 t_ok.testfunc(hb);
61 t_nok.testfunc(hnb);
62
63 return 0;
64 }
抛砖引玉,希望这些东西都能用在实际的工程代码中。
2014年6月5日
解决办法:
$ vagrant plugin install vagrant-vbguest
$ vagrang reload
reload会重新编译vbox的additions,然后mount就能成功了
我的环境是CentOS 6.5,在yum中开启了kernel更新的,默认是exclude=kernel*
这是别人给的解决方案:
vagrant up; vagrant ssh -c 'sudo ln -s /opt/VBoxGuestAdditions-4.3.10/lib/VBoxGuestAdditions /usr/lib/VBoxGuestAdditions'; vagrant reload
2014年5月18日
环境:Windows 7 64bits,IDE:IntelliJ IDEA 13.1.2
安装kivy:1. 下载安装包http://kivy.org/#download,我使用的是Python 2.7.6,选择的2.7版本(注意此版本是32位Python)
2. 解压到一个目录,我在我的系统环境变量中将根目录命名为了KIVY_ROOT
3. 虽然kivy中自带了Python的,可以直接使用,也可以自己安装,我是自己下载的Python 2.7.6(记得一定是32位,不然后面写程序会出问题)
4. 如果机器以前没安装git的,可以直接使用KIVY中带的mingw,我自己机器安装了git,所以环境变量就没设置mingw的
5. 设置环境变量,GST_REGISTRY=%KIVY_ROOT%gstreamer\registry.bin
GST_PLUGIN_PATH=%KIVY_ROOT%gstreamer\lib\gstreamer-1.0
PATH变量中加入了%KIVY_ROOT%;%KIVY_ROOT%tools;%KIVY_ROOT%gstreamer\bin;(还有Python的mingw的)
最后,需要在PYTHONPATH中加入%KIVY_ROOT%kivy
最后写入第一个程序来测试:
代码如下
1
2 # -*- coding:utf-8 -*-
3 #/user/bin/env python
4
5 __author__ = 'shih'
6
7 from kivy.app import App
8
9 class Hello(App):
10 pass
11
12 if __name__ == "__main__":
13 Hello().run()
执行结果如下:
2014年4月14日
不知道里面怎么弄表格,就上传图片了
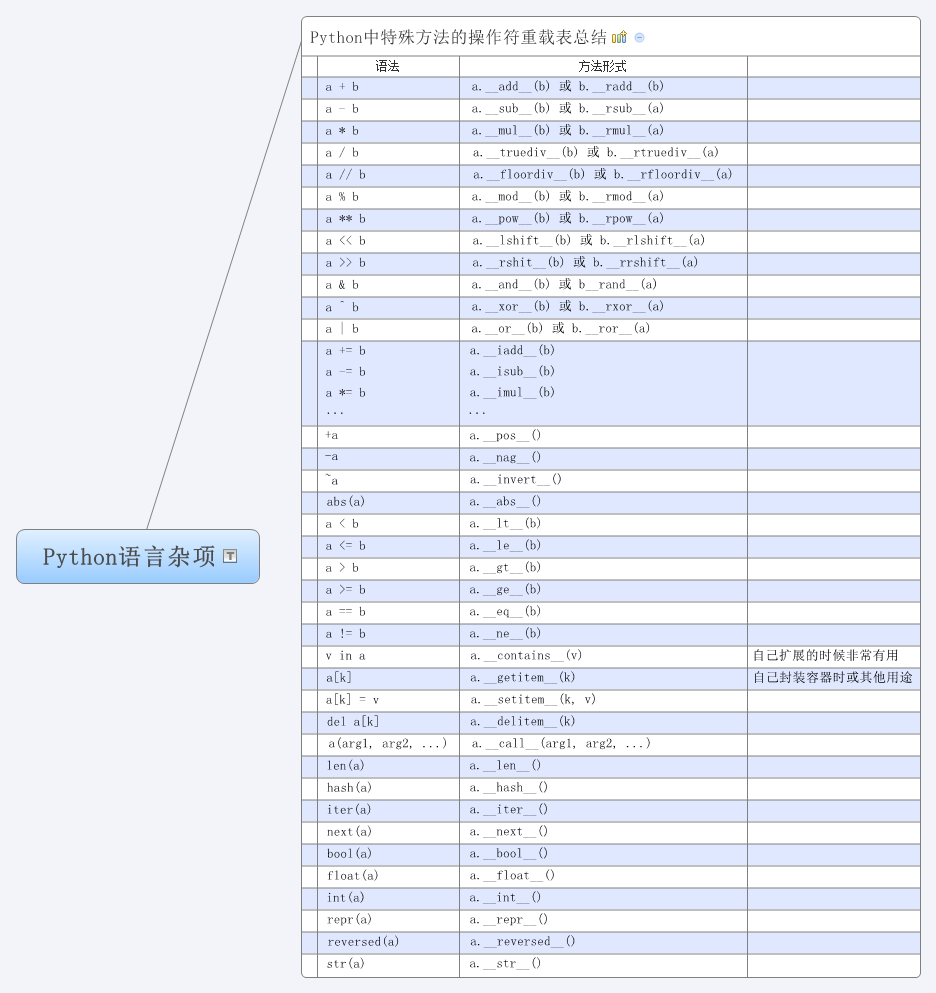
如果用户自定义的类,想有add功能,如果类没提供__add__或__radd__方法的话,会抛出异常
再如,if xxxobj:默认是如果xxxobj不是None则为True,否则为False,如果不是这个逻辑则可以通过实现__bool__方法(自己的测试中2.7需要再加上__nonzero__()方法,3.2中直接就行)
2014年3月16日
Asynchronous Input/Output(AIO):AIO可以在input/output的请求到来之前继续执行。AIO在实时应用程序中是必须的。使用AIO可以映射多个任务到一个线程上去。
首先zeromq的设计是弱中间人的(brokerless,相对于ActiveMQ、RabbitMQ等,使用0zq的程序就可以直接和其他的节点通信而不通过broker的代理。),zeromq不会存储信息到磁盘上,然而可能使用本地的交换文件来存储消息(当设置了zmq.SWAP时)。
示例:HelloWorld(server)
server
#include <string.h>
#include <stdio.h>
#include <unistd.h>
#include <zmq.h>
int main(int argc, char *argv[])
{
void *context = zmq_ctx_new();
void *respond = zmq_socket(context, ZMQ_REQ);
zmq_bind(respond, "tcp://*:4040");
printf("starting \n");
\n");
for (;;)
{
zmq_msg_t request;
zmq_msg_init(&request);
zmq_msg_recv(&request, respond, 0);
printf("received: %s\n", zmq_msg_data(&request));
zmq_msg_close(&request);
sleep(1);
zmq_msg_t reply;
zmq_msg_init_size(&reply, strlen("world"));
memcpy(zmq_msg_data(&reply), "world", 5);
zmq_msg_send(&reply, respond, 0);
zmq_msg_close(&reply);
}
zmq_close(respond);
zmq_ctx_destroy(context);
return 0;
示例:Helloworld(client)
client
1
2 #include <stdio.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <zmq.h>
6
7 int main(int argc, char *argv[])
8 {
9 void *context = zmq_ctx_new();
10 printf("client starting\n");
11
12 void *request = zmq_socket(context, ZMQ_REQ);
13 zmq_connect(request, "tcp://localhost:4040");
14
15 int count = 0;
16
17 for (;;)
18 {
19 zmq_msg_t req;
20 zmq_msg_init_size(&req, strlen("hello"));
21 memcpy(zmq_msg_data(&req), "hello", 5);
22 printf("send msg hello, count = %d\n", count);
23 zmq_msg_send(&req, request, 0);
24 zmq_msg_close(&req);
25
26 zmq_msg_t reply;
27 zmq_msg_init(&reply);
28 zmq_msg_recv(&reply, request, 0);
29 printf("recv msg %s, count = %d\n", zmq_msg_data(&reply), count);
30 zmq_msg_close(&reply);
31 count++;
32 }
33
34 zmq_close(request);
35 zmq_ctx_destroy(context);
36
37 return 0;
38 }
39
40 这里使用了最基本的请求应答架构。详细解析代码:
第一步:创建了context和socket,zmq_ctx_new方法创建了一个新的
context,这是线程安全的,即一个context可用于多个线程操作。 zmq_socket方法创建了一个在context中定义的socket,
ZeroMQ的socket不是线程安全。传统的socket是同步的,然而ZMQ的socket在客户端和服务端都维护了一个队列来管理request-reply的异步模式。ZMQ自动的处理连接、重连、断开连接和内容交付。
服务端创建了Reply(ZMQ_REP)用来处理接收消息并应答消息。如果客户端和服务端遗失(lost),应答的消息将在没有任何通知的情况下丢掉。
客户端创建了一个Request(ZMQ_REQ)来发送消息并接收来自服务的应答。ZMQ_REQ下不会丢弃任何信息,不管是没有没有可用与发送消息的服务或是服务处于忙状态,所有的发送操作zmq_send函数会阻塞,直到一个服务变为可用于发送消息。ZMQ_REQ和ZMQ_REP、ZMQ_ROUTER类型兼容。
消息的发送zmq_send函数的第三个参数是flags,是ZMQ_DONTWAIT或ZMQ_SNDMORE。ZMQ_DONTWAIT表明消息是异步的发送。ZMQ_SNDMORE表明消息有多部分,其余的部分已经“在路上了”。消息接收函数zmq_msg_recv函数,如服务端,在先前接收的消息是无效的。第三个参数flugs可能是ZMQ_DONTWAIT。
先睡觉了
2013年12月31日
1 def args_unpacking_test(x, y):
2 print 'x = ', x, ' y = ', y
3
4 A = namedtuple('A', 'y x')
5
6 list_foo = [3, 4]
7 tuple_foo = (3, 4)
8 ntuple_foo = A(4, 3)
9 dict_foo = {'y':4, 'x':3}
10
11
12 args_unpacking_test(*list_foo)
13 args_unpacking_test(*tuple_foo)
14 args_unpacking_test(*ntuple_foo)
15 args_unpacking_test(**dict_foo)
16
17 他们的结果输出都是一样的
这个方式处理非常有用,如果参数个数不一致的话会报错
2013年12月17日
首先下载Instant Client,我下载的11.2
下载的文件包括如下列表:
1. instantclient-basic-nt-11.2.0.3.0.zip
2. instantclient-odbc-nt-11.2.0.3.0.zip
3. instantclient-sdk-nt-11.2.0.3.0.zip
4. instantclient-sqlplus-nt-11.2.0.3.0.zip
5. instantclient-tools-nt-11.2.0.3.0.zip
最后两个随便了,解压文件到instantclient_11_2目录中
命令行下到解压的目录instantclient_11_2中执行>odbc_install
在环境变量中的系统变量PATH中加入instantclient_11_2目录的全路径
创建一个用户变量ORACLE_HOME,指向ic的安装目录,这点很关键,特别是用cmake编译soci,并需要支持Oracle的话。
在ic目录中创建network/admin目录,并加入OCI的.ora文件,在环境变量中加入TNS_ADMIN来指定刚才创建的目录
创建一个用户变量NLS_LANG来设置语言,我的设置是SIMPLIFIED CHINESE_CHINA.ZHS16GBK,这个要和数据库那边一致?
创建一个用户变量SQLPATH来指定sqlpath工具的文件路径,下载的第四个文件
OK,所有安装就此。
再安装Oracle的访问工具,我使用的是Navicat for Oracle工具
1. 普通安装
2. 破解、注解
3. 非常重要:在软件的option中OCI选项中将OCI library(oci.dll)的路径指向安装的instant clent的oci.dll上
4. SQL*PLUS以相同方式处理,不过不用这个的话初步处理无所谓了。
好了,可以尝试你的第一次Oracle连接之旅了(是我的……)