Linux IO系统的架构图

一.设备-------- 影响磁盘性能的因素
硬盘的转速影响硬盘的整体性能。一般情况下转速越大,性能会越好。
硬盘的性能因素主要包括两个:1.平均访问时间2传输速率。
平均访问时间包括两方面因素:
平均寻道时间(Average Seek Time)是指硬盘的磁头移动到盘面指定磁道所需的时间。一般在3ms至15ms之间。
平均旋转等待时间(Latency)是指磁头已处于要访问的磁道,等待所要访问的扇区旋转至磁头下方的时间。一般在2ms至6ms之间。
传输速率(Data Transfer Rate) 硬盘的数据传输率是指硬盘读写数据的速度,单位为兆字节每秒(MB/s)。磁盘每秒能传输80M~320M字节。
传输速率包括内部传输速率和外部传输速率。
内部传输率(Internal Transfer Rate) 也称为持续传输率(Sustained Transfer Rate),它反映了硬盘缓冲区未用时的性能。内部传输率主要依赖于硬盘的旋转速度。
外部传输率(External Transfer Rate)也称为突发数据传输率(Burst Data Transfer Rate)或接口传输率,它标称的是系统总线与硬盘缓冲区之间的数据传输率,外部数据传输率与硬盘接口类型和硬盘缓存的大小有关。STAT2 的传输速率在300MB/s级别。
因此在硬件级上,提高磁盘性能的关键主要是降低平均访问时间。
二.设备驱动
内存到硬盘的传输方式:poll,中断,DMA
DMA:当 CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器 来实行和完成。
DMA控制器获得总线控制权后,CPU即刻挂起或只执行内部操作,由DMA控制器输出读写命令,直接控制RAM与I/O接口进行DMA传输。DMA每次传送的是磁盘上相邻的扇区。Scatter-gather DMA允许传送不相邻的扇区。
CPU性能与硬盘与内存的数据传输速率关系不大。
设备驱动内有一个结构管理着IO的请求队列
structrequest_queue(include/linux/Blkdev.h)
这里不仅仅有读写请求的数据块,还有用于IO调度的回调函数结构。每次需要传输的时候,就从队列中选出一个数据块交给DMA进行传输。
所以IO调度的回调函数这是降低平均访问的时间的关键。
三.OS
IO调度器
Linux kernel提供了四个调度器供用户选择。他们是noop,cfq,deadline,as。可以在系统启动时设置内核参数elevator=<name>来指定默认的调度器。也可以在运行时为某个块设备设置IO调度程序。
下面来简要介绍这四个调度器的电梯调度算法。
Noop:最简单的调度算法。新的请求总是被添加到队头或者队尾,然后总是从队头中选出将要被处理的请求。
CFQ:(Complete FarinessQueueing)它的目标是在所有请求的进程中平均分配IO的带宽。因此,它会根据进程创建自己的请求队列,然后将IO请求放入相应的队列中。在使用轮转法从每个非空的队列中取出IO请求。
Deadline:使用了四个队列,两个以磁盘块序号排序的读写队列,两个以最后期限时间排序的读写队列。算法首先确定下一个读写的方向,读的优先级高于写。然后检查被选方向的最后期限队列:如果最后期限时间的队列中有超时的请求,则将刚才的请求移动至队尾,然后在磁盘号排序队列中从超时请求开始处理。当处理完一个方向的请求后,在处理另一个方向的请求。(读请求的超时时间是500ms,写请求的超时时间是5s)
Anticipatory:它是最复杂的IO调度算法。和deadline算法一样有四个队列。还附带了一些启发式策略。它会从当前的磁头位置后的磁盘号中选择请求。在调度了一个由P进程的IO请求后,会检查下一个请求,如果还是P进程的请求,则立即调度,如果不是,同时预测P进程很快会发出请求,则还延长大约7ms的时间等待P进程的IO请求。
Write/Read函数
以ext3的write为例:
系统调用write()的作用就是修改页高速缓存内的一些页的内容,如果页高速缓存内没有所要的页则分配并追加这些页。
当脏页达到一定数量或者超时后,将脏页刷回硬盘。也可以执行相关系统调用。
为什么要达到一定数量,是因为延迟写能在一定层度上提高系统的性能,这也使得块设备的平均读请求会多于写请求。
在程序中调用write函数,将进入系统调用f_op->write。这个函数将调用ext3的do_sync_write。这个函数将参数封装后调用generic_file_aio_write。由参数名可以看出同步写变成了异步写。如果没有标记O_DIRECT,将调用函数generic_file_buffered_write将写的内容写进kernel的高速页缓存中。Buffer是以page为单位即4k。之后当调用cond_resched()进行进程的调度,DMA会将buffer中的内容写进硬盘。
所以当每次以4k为单位写入硬盘时效率会达到最高。下面是UNIX环境高级编程的实验结果:
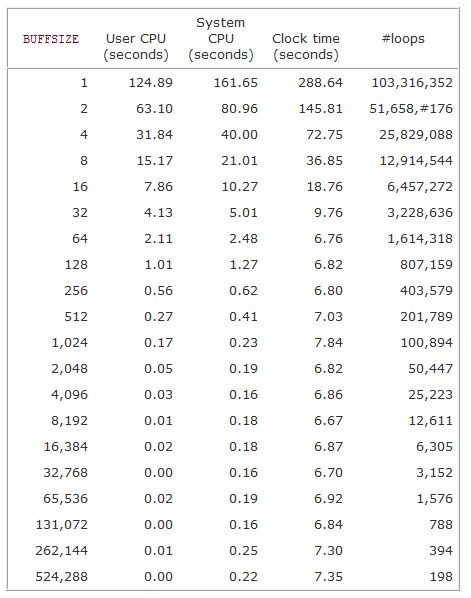
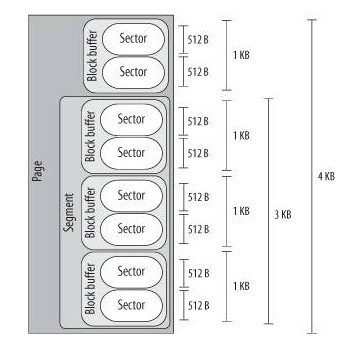
下图是linux 的块设备的数据操作层次:
Sector扇区:是设备驱动和IO调度程序处理数据粒度。
Block块:是VFS和文件系统处理数据的粒度。其大小不唯一,可以是512,1024,2048,4096字节。内核操作的块大小是4096字节。
Segment段:是DMA传送的单位。每一个段包含了相邻的扇区,它能使DMA传送不相邻的扇区。
四.用户程序
根据以上的分析,我们的write buffer一般设置为4K的倍数。
在程序中有意识的延迟写。这个是os的策略,当然也可以应用到程序的设计中。当然也会有缺点:1.如果硬件错误或掉电,则会丢失内容(做额外的备份)2.需要额外的内存空间。(牺牲内存来提高IO的效率)
我们还需根据系统的IO调度器的调度策略,设计出不同的IO策略。尽量降低磁盘的平均访问时间,降低请求队列,提高数据传输的速率。
五.监控硬盘的工具和指标
Iostat–x –k 1
-x显示更多的消息 -k数据以KB为单位 1每秒显示一次
输出显示的信息
Iowait:cpu等待未完成的IO请求而空闲的时间的比例。
Idle:cpu空闲且无IO请求的比例。
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了。
wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
r/s:每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s:每秒完成的写 I/O 设备次数。即 delta(wio)/s
await:每一个IO请求的处理的平均时间(单位是毫秒)。包括加入请求队列和服务的时间。
svctm: 平均每次设备I/O操作的服务时间。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。即 delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
下面我们做一个实验来分析一下
我们使用命令
time dd if=/dev/zero of=/home/zhouyuan/mytest bs=1M count=3000
向mytest写入数据,写入3G。
截取部分的状态监控:
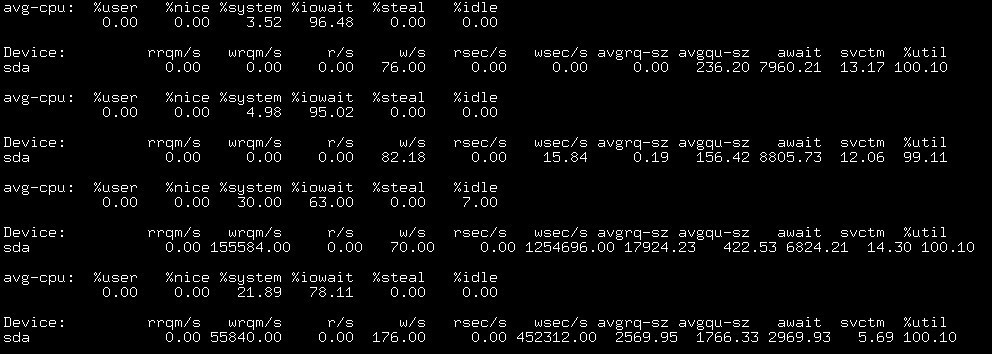
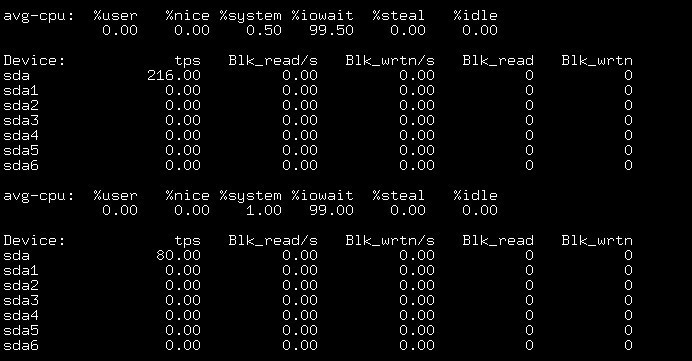

如图2,当两条数据 iowait 达到了 99% 以上,写入的数据是0,这是因为DMA将内存的中的数据传输给设备。结合图1的前两条数据,利用率达到了99%+却没有写入的磁盘块。
如图3,iowait下降,说明cpu开始执行相关程序,而此时块设备开始写入的数据。这两个操作是异步进行的。
Vmstat–k –n 1
Swap
si: 从磁盘交换到内存的交换页数量,单位:KB/秒
so: 从内存交换到磁盘的交换页数量,单位:KB/秒
IO
bi: 从块设备接受的块数,单位:块/秒
bo: 发送到块设备的块数,单位:块/秒

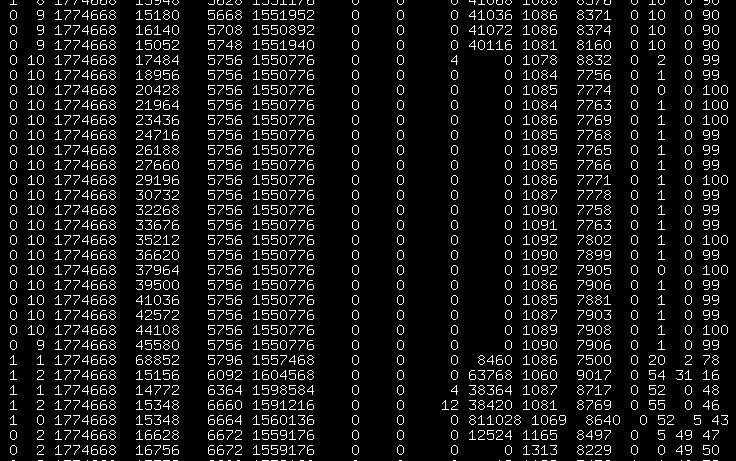
从图中我们可以看出系统的延迟写。