#
在使用VC 2005 的开发者会遇到这样的问题,在使用std命名空间库函数的时候,往往会出现类似于下面的警告:
warning C4996: strcpy was declared deprecated
出现这样的警告,是因为VC2005中认为CRT中的一组函数如果使用不当,可能会产生诸如内存泄露、缓冲区溢出、非法访问等安全问题。这些函数如:strcpy、strcat等。
对于这些问题,VC2005建议使用这些函数的更高级的安全版本,即在这些函数名后面加了一个_s的函数。这些安全版本函数使用起来更有效,也便于识别,如:strcpy_s,calloc_s等。
当然,如果执意使用老版本、非安全版本函数,可以使用_CRT_SECURE_NO_DEPRECATE标记来忽略这些警告问题。办法是在编译选项 C/C++ | Preprocessor | Preprocessor Definitions中,增加_CRT_SECURE_NO_DEPRECATE标记即可。
补充:
然而,本以为上面的说法是件漂亮的法子,不想用后不爽。遂用旧法:
#pragma warning(disable:4996) //全部关掉
#pragma warning(once:4996) //仅显示一个
关于这个话题网上流传的是一个相同的版本,就是那个第一项是头文件的区别,但后面列出的头文件只有#include没有(估计是原版的在不断转载的过程中有人不小心忘了把尖括号转义,让浏览器当html标记解析没了)的那个。现在整理了一下,以后也会不断补充内容。
1)头文件
windows下winsock.h或winsock2.h
linux下netinet/in.h(大部分都在这儿),unistd.h(close函数在这儿),sys/socket.h(在in.h里已经包含了,可以省了)
2)初始化
windows下需要用WSAStartup启动Ws2_32.lib,并且要用#pragma comment(lib,"Ws2_32")来告知编译器链接该lib。
linux下不需要
3)关闭socket
windows下closesocket(...)
linux下close(...)
4)类型
windows下SOCKET
linux下int(我喜欢用long,这样保证是4byte,因为-1我总喜欢写成0xFFFF)
5)获取错误码
windows下getlasterror()/WSAGetLastError()
linux下,未能成功执行的socket操作会返回-1;如果包含了errno.h,就会设置errno变量
6)设置非阻塞
windows下ioctlsocket()
linux下fcntl(),需要头文件fcntl.h
7)send函数最后一个参数
windows下一般设置为0
linux下最好设置为MSG_NOSIGNAL,如果不设置,在发送出错后有可能会导致程序退出
8)毫秒级时间获取
windows下GetTickCount()
linux下gettimeofday()
9)多线程
windows下包含process.h,使用_beginthread和_endthread
linux下包含pthread.h,使用pthread_create和pthread_exit
10)用IP定义一个地址(sockaddr_in的结构的区别)
windows下addr_var.sin_addr.S_un.S_addr
linux下addr_var.sin_addr.s_addr
而且Winsock里最后那个32bit的S_addr也有几个以联合(Union)的形式与它共享内存空间的成员变量(便于以其他方式赋值),而Linux的Socket没有这个联合,就是一个32bit的s_addr。遇到那种得到了是4个char的IP的形式(比如127一个,0一个,0一个和1一个共四个char),WinSock可以直接用4个S_b来赋值到S_addr里,而在Linux下,可以用边向左移位(一下8bit,共四下)边相加的方法赋值。
11)异常处理
linux下当连接断开,还发数据的时候,不仅send()的返回值会有反映,而且还会像系统发送一个异常消息,如果不作处理,系统会出BrokePipe,程序会退出。为此,send()函数的最后一个参数可以设MSG_NOSIGNAL,禁止send()函数向系统发送异常消息。
使用条件变量可以以原子方式阻塞线程,直到某个特定条件为真为止。条件变量始终与互斥锁一起使用。
使用条件变量,线程可以以原子方式阻塞,直到满足某个条件为止。对条件的测试是在互斥锁(互斥)的保护下进行的。
如果条件为假,线程通常会基于条件变量阻塞,并以原子方式释放等待条件变化的互斥锁。如果另一个线程更改了条件,该线程可能会向相关的条件变量发出信号,从而使一个或多个等待的线程执行以下操作:
在以下情况下,条件变量可用于在进程之间同步线程:
-
线程是在可以写入的内存中分配的
-
内存由协作进程共享
调度策略可确定唤醒阻塞线程的方式。对于缺省值 SCHED_OTHER,将按优先级顺序唤醒线程。
必须设置和初始化条件变量的属性,然后才能使用条件变量。表 4–4 列出了用于处理条件变量属性的函数。
表 4–4 条件变量属性
表 4–5 中显示了定义条件变量的范围时 Solaris 线程和 POSIX 线程之间的差异。
表 4–5 条件变量范围比较
|
Solaris
|
POSIX
|
定义
|
|
USYNC_PROCESS
|
PTHREAD_PROCESS_SHARED
|
用于同步该进程和其他进程中的线程
|
|
USYNC_THREAD
|
PTHREAD_PROCESS_PRIVATE
|
用于仅同步该进程中的线程
|
初始化条件变量属性
使用 pthread_condattr_init(3C) 可以将与该对象相关联的属性初始化为其缺省值。在执行过程中,线程系统会为每个属性对象分配存储空间。
pthread_condattr_init 语法
int pthread_condattr_init(pthread_condattr_t *cattr);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* initialize an attribute to default value */
ret = pthread_condattr_init(&cattr);
调用此函数时,pshared 属性的缺省值为 PTHREAD_PROCESS_PRIVATE。pshared 的该值表示可以在进程内使用已初始化的条件变量。
cattr 的数据类型为 opaque,其中包含一个由系统分配的属性对象。cattr 范围可能的值为 PTHREAD_PROCESS_PRIVATE 和 PTHREAD_PROCESS_SHARED。PTHREAD_PROCESS_PRIVATE 是缺省值。
条件变量属性必须首先由 pthread_condattr_destroy(3C) 重新初始化后才能重用。pthread_condattr_init() 调用会返回指向类型为 opaque 的对象的指针。如果未销毁该对象,则会导致内存泄漏。
pthread_condattr_init 返回值
pthread_condattr_init() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下任一情况,该函数将失败并返回对应的值。
ENOMEM
描述:
分配的内存不足,无法初始化线程属性对象。
EINVAL
描述:
cattr 指定的值无效。
删除条件变量属性
使用 pthread_condattr_destroy(3C) 可以删除存储并使属性对象无效。
pthread_condattr_destroy 语法
int pthread_condattr_destroy(pthread_condattr_t *cattr);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* destroy an attribute */
ret
= pthread_condattr_destroy(&cattr);
pthread_condattr_destroy 返回值
pthread_condattr_destroy() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cattr 指定的值无效。
设置条件变量的范围
pthread_condattr_setpshared(3C) 可用来将条件变量的范围设置为进程专用(进程内)或系统范围内(进程间)。
pthread_condattr_setpshared 语法
int pthread_condattr_setpshared(pthread_condattr_t *cattr,
int pshared);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* all processes */
ret = pthread_condattr_setpshared(&cattr, PTHREAD_PROCESS_SHARED);
/* within a process */
ret = pthread_condattr_setpshared(&cattr, PTHREAD_PROCESS_PRIVATE);
如果 pshared 属性在共享内存中设置为 PTHREAD_PROCESS_SHARED,则其所创建的条件变量可以在多个进程中的线程之间共享。此行为与最初的 Solaris 线程实现中 mutex_init() 中的 USYNC_PROCESS 标志等效。
如果互斥锁的 pshared 属性设置为 PTHREAD_PROCESS_PRIVATE,则仅有那些由同一个进程创建的线程才能够处理该互斥锁。PTHREAD_PROCESS_PRIVATE 是缺省值。PTHREAD_PROCESS_PRIVATE 所产生的行为与在最初的 Solaris 线程的 cond_init() 调用中使用 USYNC_THREAD 标志相同。PTHREAD_PROCESS_PRIVATE 的行为与局部条件变量相同。PTHREAD_PROCESS_SHARED 的行为与全局条件变量等效。
pthread_condattr_setpshared 返回值
pthread_condattr_setpshared() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cattr 或 pshared 的值无效。
获取条件变量的范围
pthread_condattr_getpshared(3C) 可用来获取属性对象 cattr 的 pshared 的当前值。
pthread_condattr_getpshared 语法
int pthread_condattr_getpshared(const pthread_condattr_t *cattr,
int *pshared);
#include <pthread.h>
pthread_condattr_t cattr;
int pshared;
int ret;
/* get pshared value of condition variable */
ret = pthread_condattr_getpshared(&cattr, &pshared);
属性对象的值为 PTHREAD_PROCESS_SHARED 或 PTHREAD_PROCESS_PRIVATE。
pthread_condattr_getpshared 返回值
pthread_condattr_getpshared() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cattr 的值无效。
本节介绍如何使用条件变量。表 4–6 列出了可用的函数。
表 4–6 条件变量函数
初始化条件变量
使用 pthread_cond_init(3C) 可以将 cv 所指示的条件变量初始化为其缺省值,或者指定已经使用 pthread_condattr_init() 设置的条件变量属性。
pthread_cond_init 语法
int pthread_cond_init(pthread_cond_t *cv,
const pthread_condattr_t *cattr);
#include <pthread.h>
pthread_cond_t cv;
pthread_condattr_t cattr;
int ret;
/* initialize a condition variable to its default value */
ret = pthread_cond_init(&cv, NULL);
/* initialize a condition variable */
ret = pthread_cond_init(&cv, &cattr);
cattr 设置为 NULL。将 cattr 设置为 NULL 与传递缺省条件变量属性对象的地址等效,但是没有内存开销。对于 Solaris 线程,请参见cond_init 语法。
使用 PTHREAD_COND_INITIALIZER 宏可以将以静态方式定义的条件变量初始化为其缺省属性。PTHREAD_COND_INITIALIZER 宏与动态分配具有 null 属性的 pthread_cond_init() 等效,但是不进行错误检查。
多个线程决不能同时初始化或重新初始化同一个条件变量。如果要重新初始化或销毁某个条件变量,则应用程序必须确保该条件变量未被使用。
pthread_cond_init 返回值
pthread_cond_init() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下任一情况,该函数将失败并返回对应的值。
EINVAL
描述:
cattr 指定的值无效。
EBUSY
描述:
条件变量处于使用状态。
EAGAIN
描述:
必要的资源不可用。
ENOMEM
描述:
内存不足,无法初始化条件变量。
基于条件变量阻塞
使用 pthread_cond_wait(3C) 可以以原子方式释放 mp 所指向的互斥锁,并导致调用线程基于 cv 所指向的条件变量阻塞。对于 Solaris 线程,请参见cond_wait 语法。
pthread_cond_wait 语法
int pthread_cond_wait(pthread_cond_t *cv,pthread_mutex_t *mutex);
#include <pthread.h>
pthread_cond_t cv;
pthread_mutex_t mp;
int ret;
/* wait on condition variable */
ret = pthread_cond_wait(&cv, &mp);
阻塞的线程可以通过 pthread_cond_signal() 或 pthread_cond_broadcast() 唤醒,也可以在信号传送将其中断时唤醒。
不能通过 pthread_cond_wait() 的返回值来推断与条件变量相关联的条件的值的任何变化。必须重新评估此类条件。
pthread_cond_wait() 例程每次返回结果时调用线程都会锁定并且拥有互斥锁,即使返回错误时也是如此。
该条件获得信号之前,该函数一直被阻塞。该函数会在被阻塞之前以原子方式释放相关的互斥锁,并在返回之前以原子方式再次获取该互斥锁。
通常,对条件表达式的评估是在互斥锁的保护下进行的。如果条件表达式为假,线程会基于条件变量阻塞。然后,当该线程更改条件值时,另一个线程会针对条件变量发出信号。这种变化会导致所有等待该条件的线程解除阻塞并尝试再次获取互斥锁。
必须重新测试导致等待的条件,然后才能从 pthread_cond_wait() 处继续执行。唤醒的线程重新获取互斥锁并从 pthread_cond_wait() 返回之前,条件可能会发生变化。等待线程可能并未真正唤醒。建议使用的测试方法是,将条件检查编写为调用 pthread_cond_wait() 的 while() 循环。
pthread_mutex_lock();
while(condition_is_false)
pthread_cond_wait();
pthread_mutex_unlock();
如果有多个线程基于该条件变量阻塞,则无法保证按特定的顺序获取互斥锁。
注 –
pthread_cond_wait() 是取消点。如果取消处于暂挂状态,并且调用线程启用了取消功能,则该线程会终止,并在继续持有该锁的情况下开始执行清除处理程序。
pthread_cond_wait 返回值
pthread_cond_wait() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 或 mp 指定的值无效。
解除阻塞一个线程
对于基于 cv 所指向的条件变量阻塞的线程,使用 pthread_cond_signal(3C) 可以解除阻塞该线程。对于 Solaris 线程,请参见cond_signal 语法。
pthread_cond_signal 语法
int pthread_cond_signal(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* one condition variable is signaled */
ret = pthread_cond_signal(&cv);
应在互斥锁的保护下修改相关条件,该互斥锁用于获得信号的条件变量中。否则,可能在条件变量的测试和 pthread_cond_wait() 阻塞之间修改该变量,这会导致无限期等待。
调度策略可确定唤醒阻塞线程的顺序。对于 SCHED_OTHER,将按优先级顺序唤醒线程。
如果没有任何线程基于条件变量阻塞,则调用 pthread_cond_signal() 不起作用。
示例 4–8 使用 pthread_cond_wait() 和 pthread_cond_signal()
pthread_mutex_t count_lock;
pthread_cond_t count_nonzero;
unsigned count;
decrement_count()
{
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
increment_count()
{
pthread_mutex_lock(&count_lock);
if (count == 0)
pthread_cond_signal(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
pthread_cond_signal 返回值
pthread_cond_signal() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 指向的地址非法。
示例 4–8 说明了如何使用 pthread_cond_wait() 和 pthread_cond_signal()。
在指定的时间之前阻塞
pthread_cond_timedwait(3C) 的用法与 pthread_cond_wait() 的用法基本相同,区别在于在由 abstime 指定的时间之后 pthread_cond_timedwait() 不再被阻塞。
pthread_cond_timedwait 语法
int pthread_cond_timedwait(pthread_cond_t *cv,
pthread_mutex_t *mp, const struct timespec *abstime);
#include <pthread.h>
#include <time.h>
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t abstime;
int ret;
/* wait on condition variable */
ret = pthread_cond_timedwait(&cv, &mp, &abstime);
pthread_cond_timewait() 每次返回时调用线程都会锁定并且拥有互斥锁,即使 pthread_cond_timedwait() 返回错误时也是如此。 对于 Solaris 线程,请参见cond_timedwait 语法。
pthread_cond_timedwait() 函数会一直阻塞,直到该条件获得信号,或者最后一个参数所指定的时间已过为止。
注 –
pthread_cond_timedwait() 也是取消点。
示例 4–9 计时条件等待
pthread_timestruc_t to;
pthread_mutex_t m;
pthread_cond_t c;
...
pthread_mutex_lock(&m);
to.tv_sec = time(NULL) + TIMEOUT;
to.tv_nsec = 0;
while (cond == FALSE) {
err = pthread_cond_timedwait(&c, &m, &to);
if (err == ETIMEDOUT) {
/* timeout, do something */
break;
}
}
pthread_mutex_unlock(&m);
pthread_cond_timedwait 返回值
pthread_cond_timedwait() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下任一情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 或 abstime 指向的地址非法。
ETIMEDOUT
描述:
abstime 指定的时间已过。
超时会指定为当天时间,以便在不重新计算值的情况下高效地重新测试条件,如示例 4–9 中所示。
在指定的时间间隔内阻塞
pthread_cond_reltimedwait_np(3C) 的用法与 pthread_cond_timedwait() 的用法基本相同,唯一的区别在于 pthread_cond_reltimedwait_np() 会采用相对时间间隔而不是将来的绝对时间作为其最后一个参数的值。
pthread_cond_reltimedwait_np 语法
int pthread_cond_reltimedwait_np(pthread_cond_t *cv,
pthread_mutex_t *mp,
const struct timespec *reltime);
#include <pthread.h>
#include <time.h>
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t reltime;
int ret;
/* wait on condition variable */
ret = pthread_cond_reltimedwait_np(&cv, &mp, &reltime);
pthread_cond_reltimedwait_np() 每次返回时调用线程都会锁定并且拥有互斥锁,即使 pthread_cond_reltimedwait_np() 返回错误时也是如此。对于 Solaris 线程,请参见 cond_reltimedwait(3C)。pthread_cond_reltimedwait_np() 函数会一直阻塞,直到该条件获得信号,或者最后一个参数指定的时间间隔已过为止。
注 –
pthread_cond_reltimedwait_np() 也是取消点。
pthread_cond_reltimedwait_np 返回值
pthread_cond_reltimedwait_np() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下任一情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 或 reltime 指示的地址非法。
ETIMEDOUT
描述:
reltime 指定的时间间隔已过。
解除阻塞所有线程
对于基于 cv 所指向的条件变量阻塞的线程,使用 pthread_cond_broadcast(3C) 可以解除阻塞所有这些线程,这由 pthread_cond_wait() 来指定。
pthread_cond_broadcast 语法
int pthread_cond_broadcast(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* all condition variables are signaled */
ret = pthread_cond_broadcast(&cv);
如果没有任何线程基于该条件变量阻塞,则调用 pthread_cond_broadcast() 不起作用。对于 Solaris 线程,请参见cond_broadcast 语法。
由于 pthread_cond_broadcast() 会导致所有基于该条件阻塞的线程再次争用互斥锁,因此请谨慎使用 pthread_cond_broadcast()。例如,通过使用 pthread_cond_broadcast(),线程可在资源释放后争用不同的资源量,如示例 4–10 中所示。
示例 4–10 条件变量广播
pthread_mutex_t rsrc_lock;
pthread_cond_t rsrc_add;
unsigned int resources;
get_resources(int amount)
{
pthread_mutex_lock(&rsrc_lock);
while (resources < amount) {
pthread_cond_wait(&rsrc_add, &rsrc_lock);
}
resources -= amount;
pthread_mutex_unlock(&rsrc_lock);
}
add_resources(int amount)
{
pthread_mutex_lock(&rsrc_lock);
resources += amount;
pthread_cond_broadcast(&rsrc_add);
pthread_mutex_unlock(&rsrc_lock);
}
请注意,在 add_resources() 中,首先更新 resources 还是首先在互斥锁中调用 pthread_cond_broadcast() 无关紧要。
应在互斥锁的保护下修改相关条件,该互斥锁用于获得信号的条件变量中。否则,可能在条件变量的测试和 pthread_cond_wait() 阻塞之间修改该变量,这会导致无限期等待。
pthread_cond_broadcast 返回值
pthread_cond_broadcast() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 指示的地址非法。
销毁条件变量状态
使用 pthread_cond_destroy(3C) 可以销毁与 cv 所指向的条件变量相关联的任何状态。对于 Solaris 线程,请参见cond_destroy 语法。
pthread_cond_destroy 语法
int pthread_cond_destroy(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* Condition variable is destroyed */
ret = pthread_cond_destroy(&cv);
请注意,没有释放用来存储条件变量的空间。
pthread_cond_destroy 返回值
pthread_cond_destroy() 在成功完成之后会返回零。其他任何返回值都表示出现了错误。如果出现以下情况,该函数将失败并返回对应的值。
EINVAL
描述:
cv 指定的值无效。
唤醒丢失问题
如果线程未持有与条件相关联的互斥锁,则调用 pthread_cond_signal() 或 pthread_cond_broadcast() 会产生唤醒丢失错误。
满足以下所有条件时,即会出现唤醒丢失问题:
仅当修改所测试的条件但未持有与之相关联的互斥锁时,才会出现此问题。只要仅在持有关联的互斥锁同时修改所测试的条件,即可调用 pthread_cond_signal() 和 pthread_cond_broadcast(),而无论这些函数是否持有关联的互斥锁。
生成方和使用者问题
并发编程中收集了许多标准的众所周知的问题,生成方和使用者问题只是其中的一个问题。此问题涉及到一个大小限定的缓冲区和两类线程(生成方和使用者),生成方将项放入缓冲区中,然后使用者从缓冲区中取走项。
生成方必须在缓冲区中有可用空间之后才能向其中放置内容。使用者必须在生成方向缓冲区中写入之后才能从中提取内容。
条件变量表示一个等待某个条件获得信号的线程队列。
示例 4–11 中包含两个此类队列。一个队列 (less) 针对生成方,用于等待缓冲区中出现空位置。另一个队列 (more) 针对使用者,用于等待从缓冲槽位的空位置中提取其中包含的信息。该示例中还包含一个互斥锁,因为描述该缓冲区的数据结构一次只能由一个线程访问。
示例 4–11 生成方和使用者的条件变量问题
typedef struct {
char buf[BSIZE];
int occupied;
int nextin;
int nextout;
pthread_mutex_t mutex;
pthread_cond_t more;
pthread_cond_t less;
} buffer_t;
buffer_t buffer;
如示例 4–12 中所示,生成方线程获取该互斥锁以保护 buffer 数据结构,然后,缓冲区确定是否有空间可用于存放所生成的项。如果没有可用空间,生成方线程会调用 pthread_cond_wait()。pthread_cond_wait() 会导致生成方线程连接正在等待 less 条件获得信号的线程队列。less 表示缓冲区中的可用空间。
与此同时,在调用 pthread_cond_wait() 的过程中,该线程会释放互斥锁的锁定。正在等待的生成方线程依赖于使用者线程在条件为真时发出信号,如示例 4–12 中所示。该条件获得信号时,将会唤醒等待 less 的第一个线程。但是,该线程必须再次锁定互斥锁,然后才能从 pthread_cond_wait() 返回。
获取互斥锁可确保该线程再次以独占方式访问缓冲区的数据结构。该线程随后必须检查缓冲区中是否确实存在可用空间。如果空间可用,该线程会向下一个可用的空位置中进行写入。
与此同时,使用者线程可能正在等待项出现在缓冲区中。这些线程正在等待条件变量 more。刚在缓冲区中存储内容的生成方线程会调用 pthread_cond_signal() 以唤醒下一个正在等待的使用者。如果没有正在等待的使用者,此调用将不起作用。
最后,生成方线程会解除锁定互斥锁,从而允许其他线程处理缓冲区的数据结构。
示例 4–12 生成方和使用者问题:生成方
void producer(buffer_t *b, char item)
{
pthread_mutex_lock(&b->mutex);
while (b->occupied >= BSIZE)
pthread_cond_wait(&b->less, &b->mutex);
assert(b->occupied < BSIZE);
b->buf[b->nextin++] = item;
b->nextin %= BSIZE;
b->occupied++;
/* now: either b->occupied < BSIZE and b->nextin is the index
of the next empty slot in the buffer, or
b->occupied == BSIZE and b->nextin is the index of the
next (occupied) slot that will be emptied by a consumer
(such as b->nextin == b->nextout) */
pthread_cond_signal(&b->more);
pthread_mutex_unlock(&b->mutex);
}
请注意 assert() 语句的用法。除非在编译代码时定义了 NDEBUG,否则 assert() 在其参数的计算结果为真(非零)时将不执行任何操作。如果参数的计算结果为假(零),则该程序会中止。在多线程程序中,此类断言特别有用。如果断言失败,assert() 会立即指出运行时问题。assert() 还有另一个作用,即提供有用的注释。
以 /* now: either b->occupied ... 开头的注释最好以断言形式表示,但是由于语句过于复杂,无法用布尔值表达式来表示,因此将用英语表示。
断言和注释都是不变量的示例。这些不变量是逻辑语句,在程序正常执行时不应将其声明为假,除非是线程正在修改不变量中提到的一些程序变量时的短暂修改过程中。当然,只要有线程执行语句,断言就应当为真。
使用不变量是一种极为有用的方法。即使没有在程序文本中声明不变量,在分析程序时也应将其视为不变量。
每次线程执行包含注释的代码时,生成方代码中表示为注释的不变量始终为真。如果将此注释移到紧挨 mutex_unlock() 的后面,则注释不一定仍然为真。如果将此注释移到紧跟 assert() 之后的位置,则注释仍然为真。
因此,不变量可用于表示一个始终为真的属性,除非一个生成方或一个使用者正在更改缓冲区的状态。线程在互斥锁的保护下处理缓冲区时,该线程可能会暂时声明不变量为假。但是,一旦线程结束对缓冲区的操作,不变量即会恢复为真。
示例 4–13 给出了使用者的代码。该逻辑流程与生成方的逻辑流程相对称。
示例 4–13 生成方和使用者问题:使用者
char consumer(buffer_t *b)
{
char item;
pthread_mutex_lock(&b->mutex);
while(b->occupied <= 0)
pthread_cond_wait(&b->more, &b->mutex);
assert(b->occupied > 0);
item = b->buf[b->nextout++];
b->nextout %= BSIZE;
b->occupied--;
/* now: either b->occupied > 0 and b->nextout is the index
of the next occupied slot in the buffer, or
b->occupied == 0 and b->nextout is the index of the next
(empty) slot that will be filled by a producer (such as
b->nextout == b->nextin) */
pthread_cond_signal(&b->less);
pthread_mutex_unlock(&b->mutex);
return(item);
}
PowerDesigner设置主键自增方法:选中主键字段,点击进入属性设置框,勾选"Identity",这里注意不同的SQL会有不同的方法,比如MySQL为:ATUO_INCREMENT,而SQL Server为:Identity,请选择你需要的数据库平台。更换平台方法:Tool-->Generate Physical Data Mode--> General(默认就会打开这里)-->DBMS里选择你的数据库平台即可。。。
sql语句中表名与字段名前的引号去除:
打开cdm的情况下,进入Tools-Model Options-Naming Convention,把Name和Code的标签的Charcter case选项设置成Uppercase或者Lowercase,只要不是Mixed Case就行!
或者选择Database->Edit current database->Script->Sql->Format,有一项CaseSensitivityUsingQuote,它的 comment为“Determines if the case sensitivity for identifiers is managed using double quotes”,表示是否适用双引号来规定标识符的大小写, 可以看到右边的values默认值为“YES”,改为“No”即可!
或者在打开pdm的情况下,进入Tools-Model Options-Naming Convention,把Name和Code的标签的Charcter case选项设置成Uppercase就可以!
在修改name的时候,code的值将跟着变动,很不方便修改方法:PowerDesign中的选项菜单里修改,在[Tool]-->[General Options]->[Dialog]->[Operating modes]->[Name to Code mirroring],这里默认是让名称和代码同步,将前面的复选框去掉就行了。
由pdm生成建表脚本时,字段超过15字符就发生错误(oracle) 原因未知,解决办法是打开PDM后,会出现Database的菜单栏,进入Database - Edit Current DBMS -script-objects-column-maxlen,把value值调大(原为30),比如改成60。出现表或者其它对象的长度也有这种错误的话都可以选择对应的objects照此种方法更改!
或者使用下面的这种方法:
生成建表脚本时会弹出Database generation提示框:把options - check model的小勾给去掉,就是不进行检查(不推荐)!
或者可以修改C:\Program Files\Sybase\PowerDesigner Trial 11\Resource Files\DBMS\oracl9i2.xdb文件
修改好后,再cdm转为pdm时,选择“Copy the DBMS definition in model”把把这个资源文件拷贝到模型中。
由CDM生成PDM时,自动生成的外键的重命名PDM Generation Options->Detail->FK index names默认是%REFR%_FK,改为FK_%REFRCODE%,其中%REFRCODE%指的就是CDM中Relationship的code!另外自动生成的父字段的规则是PDM Generation Options->Detail->FK column name template中设置的,默认是%.3:PARENT%_%COLUMN%,可以改为Par%COLUMN%表示是父字段!
建立一个表后,为何检测出现Existence of index的警告 A table should contain at least one column, one index, one key, and one reference.
可以不检查 Existence of index 这项,也就没有这个警告错误了!
意思是说没有给表建立索引,而一个表一般至少要有一个索引,这是一个警告,不用管也没有关系!
如何防止一对一的关系生成两个引用(外键)要定义关系的支配方向,占支配地位的实体(有D标志)变为父表。
在cdm中双击一对一关系->Detail->Dominant role选择支配关系
修改报表模板中一些术语的定义即文件:C:\Program Files\Sybase\PowerDesigner Trial 11\Resource Files\Report Languages\Chinese.xrl
Tools-Resources-Report Languages-选择Chinese-单击Properties或双击目标
修改某些对象的名称:Object Attributes\Physical Data Model\Column\
ForeignKey:外键
Mandatory:为空
Primary:主键
Table:表
用查找替换,把“表格”替换成“表”修改显示的内容为别的:Values Mapping\Lists\Standard,添加TRUE的转化列为是,FALSE的转化列为空
另外Report-Title Page里可以设置标题信息
PowerDesigner11中批量根据对象的name生成comment的脚本'******************************************************************************
'* File: name2comment.vbs
'* Purpose: Database generation cannot use object names anymore
' in version 7 and above.
' It always uses the object codes.
'
' In case the object codes are not aligned with your
' object names in your model, this script will copy
' the object Name onto the object comment for
' the Tables and Columns.
'
'* Title: 把对象name拷入comment属性中
'* Version: 1.0
'* Author:
'* 执行方法:PD11 -- Open PDM -- Tools -- Execute Commands -- Run Script
'******************************************************************************
Option Explicit
ValidationMode = True
InteractiveMode = im_Batch
Dim mdl ' the current model
' get the current active model
Set mdl = ActiveModel
If (mdl Is Nothing) Then
MsgBox "There is no current Model"
ElseIf Not mdl.IsKindOf(PdPDM.cls_Model) Then
MsgBox "The current model is not an Physical Data model."
Else
ProcessFolder mdl
End If
' This routine copy name into code for each table, each column and each view
' of the current folder
Private sub ProcessFolder(folder)
Dim Tab 'running table
for each Tab in folder.tables
if not tab.isShortcut then
tab.comment = tab.name
Dim col ' running column
for each col in tab.columns
col.comment= col.name
next
end if
next
Dim view 'running view
for each view in folder.Views
if not view.isShortcut then
view.comment = view.name
end if
next
' go into the sub-packages
Dim f ' running folder
For Each f In folder.Packages
if not f.IsShortcut then
ProcessFolder f
end if
Next
end sub
PowerDesigner 生成SQL的Existence of refernce错误问题现象:用PowerDesigner生成SQL语句时,提示Existence of refernce错误。
原因:该表没有与其他表的关联(如外键等),而PowerDesigner需要存在一个refernce才能生成SQL.
解决方法:
在工具栏空白处右键打开Palette面板,选中Link/Extended Dependency 按钮,然后在提示出错的表上添加到自己的Dependency。
重新生成SQL,你将发现刚才提示的错误没有了,问题解决。
利用PowerDesigner批量生成测试数据主要解决方法:
A:在PowerDesigner 建表
B:然后给每一个表的字段建立相应的摘要文件
步骤如下:
Model->Test Data Profiles配置每一个字段摘要文件General:输入Name、Code、
选择Class(数字、字符、时间)类型
选择Generation Source: Automatic、List、ODBC、File Detail:配置字段相关信息
所有字段摘要文件配置完成后双击该表->选择字段->Detail->选择Test Data Parameters 摘要文件如果字段值与其它字段有关系在: Computed Expression 中输入计算列--生成测试数据:
DataBase->Generation Test Data->
选择:Genration 类型(Sript、ODBC)
Selection(选择要生成的表)
Test Data Genration(Default number of rows 生成记录行数)
在使用PowerDesigner的过程中,经常遇到一些设置上面的问题,每次都去找老鸟帮忙解决,隔一段时间不用,下一次又忘掉了,不好意思再去麻烦他们了,所以现在用博客园记录下来,以后上园子来找以前的东西.
1
取消Name和Code关联的设置
在设计PDM文件的时候,设计一张表,在填写栏位的时候,如果我们输入Name,Code会跟着变化.这个完全是西方人的习惯,因为他们的Name和Code都是E文,所以不会出现什么问题.但是,我们使用的时候,就会很不习惯,Name应该是中文名字,Code才是资料库的实际字段名.
下面记录修改设置的步骤:
Step 1:
菜单栏找到Tools,点开,找到General Options,点击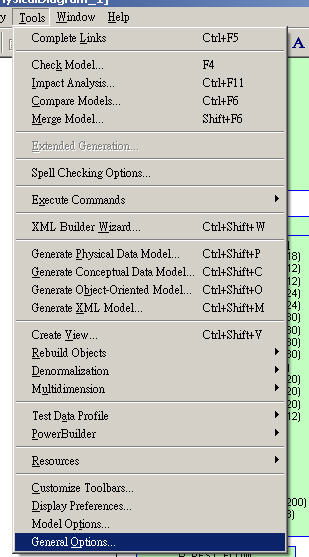
Step 2:打开Dialog将Operating modes中的 Name To Code mirroring 將前面的勾去掉
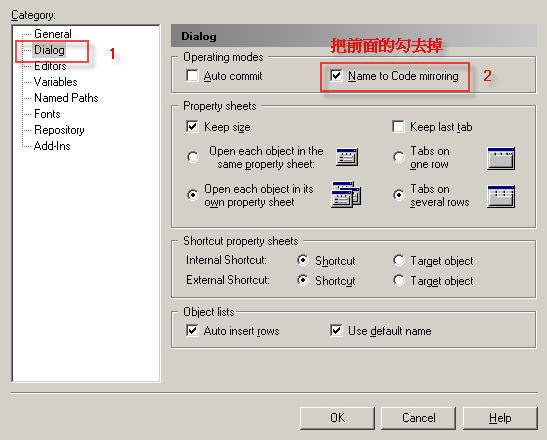
OK!完成
摘要:
··· 2
第一节 全文检索系统与Lucene简介··· 3
一、 什么是全文检索与全文检索系统?··· 3
二、 什么是Lucene?&...
阅读全文
一、Lucene源码实现分析的说明
通过以上对Lucene系统结构的分析,我们已经大致的清楚了Lucene 系统的组成,以及在Lucene系统之上的开发步骤。接下来,我们试图来分析Lucene项目(采用Lucene 1.2版本)的源码实现,考察其实现的细节。这不仅仅是我们尝试用C++语言重新实现Lucene的必须工作,也是进一步做Lucene开发工作的必要准备。因此,这一部分所涉及到的内容,对于Lucene上的应用开发也是有价值的,尤其是本部分所做的文件格式分析。
由于本文建立在我们的毕设项目之上,且同时我们需要实现cLucene项目,因此很遗憾的我们并没有完全的完成Lucene的所有源码实现的分析工作。接下来的部分,我们将涉及的部分为Lucene文件格式分析,Lucene中的存储抽象模块分析,以及Lucene中的索引构建逻辑模块分析。这一部分,我们主要涉及到的是文件格式分析与存储抽象模块分析。
二、Lucene索引文件格式
在Lucene的web站点上,有关于 Lucene的文件格式的规范,其规定了Lucene的文件格式采取的存储单位、组织结构、命名规范等等内容,但是它仅仅是一个规范说明,并没有从实现者角度来衡量这个规范的实现。因此,我们以下的内容,结合了我们自己的分析与文件格式的定义规范,以期望给出一个更加清晰的文件格式说明。具体的文档规范可以参考后面的文献2。
首先在Lucene的文件格式中,以字节为基础,定义了如下的数据类型:
表 3.1 Lucene文件格式中定义的数据类型
| 数据类型 |
所占字节长度(字节) |
说明 |
| Byte |
1 |
基本数据类型,其他数据类型以此为基础定义 |
| UInt32 |
4 |
32位无符号整数,高位优先 |
| UInt64 |
8 |
64位无符号整数,高位优先 |
| VInt |
不定,最少1字节 |
动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下
| 值 |
字节1 |
字节2 |
字节3 |
| 0 |
00000000 |
|
|
| 1 |
00000001 |
|
|
| 2 |
00000010 |
|
|
| 127 |
01111111 |
|
|
| 128 |
10000000 |
00000001 |
|
| 129 |
10000001 |
00000001 |
|
| 130 |
10000010 |
00000001 |
|
| 16383 |
10000000 |
10000000 |
00000001 |
| 16384 |
10000001 |
10000000 |
00000001 |
| 16385 |
10000010 |
10000000 |
00000001 |
|
| Chars |
不定,最少1字节 |
采用UTF-8编码[20]的Unicode字符序列 |
| String |
不定,最少2字节 |
由VInt和Chars组成的字符串类型,VInt表示Chars的长度,Chars则表示了String的值 |
以上的数据类型就是Lucene索引文件格式中用到的全部数据类型,由于它们都以字节为基础定义而来,因此保证了是平台无关,这也是Lucene索引文件格式平台无关的主要原因。接下来我们看看Lucene索引文件的概念组成和结构组成。

以上就是Lucene的索引文件的概念结构。Lucene索引index由若干段(segment)组成,每
一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚的看出,Lucene的索引结构在概念上即为传统的倒排索引结构[21]。
从概念上映射到结构中,索引被处理为一个目录(文件夹),其中含有的所有文件即为其内容,这些文件按照所属的段不同分组存放,同组的文件拥有相同的文件名,不同的扩展名。此外还有三个文件,分别用来保存所有的段的记录、保存已删除文件的记录和控制读写的同步,它们分别是segments, deletable和lock文件,都没有扩展名。每个段包含一组文件,它们的文件扩展名不同,但是文件名均为记录在文件segments中段的名字。让我们看如下的结构图3.2。

关于图3.2中的各个文件具体的内部格式,在参考文献3中,均可以找到详细的说明。接下来我们从宏观关系上说明一下这些文件组成。在这些宏观上的关系理清楚之后,仔细阅读参考文献3,即可清楚的明白具体的Lucene文件格式。
每个段的文件中,主要记录了两大类的信息:域集合与项集合。这两个集合中所含有的文件在图3.2中均有表明。由于索引信息是静态存储的,域集合与项集合中的文件组采用了一种类似的存储办法:一个小型的索引文件,运行时载入内存;一个对应于索引文件的实际信息文件,可以按照索引中指示的偏移量随机访问;索引文件与信息文件在记录的排列顺序上存在隐式的对应关系,即索引文件中按照“索引项1、索引项2…”排列,则信息文件则也按照“信息项1、信息项2…”排列。比如在图3.2所示文件中,segment1.fdx与segment1.fdt之间,segment1.tii与segment1.tis、 segment1.prx、segment1.frq之间,都存在这样的组织关系。而域集合与项集合之间则通过域的在域记录文件(比如 segment1.fnm)中所记录的域记录号维持对应关系,在图3.2中segment1.fdx与segment1.tii中就是通过这种方式保持联系。这样,域集合和项集合不仅仅联系起来,而且其中的文件之间也相互联系起来。此外,标准化因子文件和被删除文档文件则提供了一些程序内部的辅助设施(标准化因子用在评分排序机制中,被删除文档是一种伪删除手段)。这样,整个段的索引信息就通过这些文档有机的组成。
以上所阐述的,就是 Lucene所采用的索引文件格式。基本上而言,它是一个倒排索引,但是Lucene在文件的安排上做了一些努力,比如使用索引/信息文件的方式,从文件安排的形式上提高查找的效率。这是一种数据库之外的处理方法,其有其优点(格式平**立、速度快),也有其缺点(独立性带来的共享访问接口问题等等),具体如何衡量两种方法之间的利弊,本文这里就不讨论了。
三、一些公用的基础类
分析完索引文件格式,我们接下来应该着手对存储抽象也就是org.apache.lucenestore中的源码做一些分析。我们先不着急分析这部分,而是分析图2.1中基础结构封装那一部分,因为这是整个系统的基石,然后我们在下一部分再来分析存储抽象。
基础结构封装,或者基础类,由org.apache.lucene.util和org.apache.lucene.document两个包组成,前者定义了一些常量和优化过的常用的数据结构和算法,后者则是对于文档(document)和域(field)概念的一个类定义。以下我们用列表的方式来分析这些封装类,指出其要点。
表 3.2 基础类包org.apache.lucene.util
| 类 |
说明 |
| Arrays |
一个关于数组的排序方法的静态类,提供了优化的基于快排序的排序方法sort |
| BitVector |
C/C++语言中位域的java实现品,但是加入了序列化能力 |
| Constants |
常量静态类,定义了一些常量 |
| PriorityQueue |
一个优先队列的抽象类,用于后面实现各种具体的优先队列,提供常数时间内的最小元素访问能力,内部实现机制是哈析表和堆排序算法 |
表 3.3 基础类包org.apache.lucene.document
| 类 |
说明 |
| Document |
是文档概念的一个实现类,每个文档包含了一个域表(fieldList),并提供了一些实用的方法,比如多种添加域的方法、返回域表的迭代器的方法 |
| Field |
是域概念的一个实现类,每个域包含了一个域名和一个值,以及一些相关的属性 |
| DateField |
提供了一些辅助方法的静态类,这些方法将java中Date和Time数据类型和String相互转化 |
总的来说,这两个基础类包中含有的类都比较简单,通过阅读源代码,可以很容易的理解,因此这里不作过多的展开。
四、存储抽象
有了上面的知识,我们接下来来分析存储抽象部分,也就是org.apache.lucene.store包。存储抽象是唯一能够直接对索引文件存取的包,因此其主要目的是抽象出和平台文件系统无关的存储抽象,提供诸如目录服务(增、删文件)、输入流和输出流。在分析其实现之前,首先我们看一下UML [22]图。

图 3.3 存储抽象实现UML图(一)

图 3.4 存储抽象实现UML图(二)

图 3.4 存储抽象实现UML图(三)
图3.2到3.4展示了整个org.apache.lucene.store中主要的继承体系。共有三个抽象类定义:Directory、 InputStream和OutputStrem,构成了一个完整的基于抽象文件系统的存取体系结构,在此基础上,实作出了两个实现品:(FSDirectory,FSInputStream,FSOutputStream)和(RAMDirectory,RAMInputStream和 RAMOutputStream)。前者是以实际的文件系统做为基础实现的,后者则是建立在内存中的虚拟文件系统。前者主要用来永久的保存索引文件,后者的作用则在于索引操作时是在内存中建立小的索引,然后一次性的输出合并到文件中去,这一点我们在后面的索引逻辑部分能够看到。此外,还定以了 org.apache.lucene.store.lock和org.apache.lucene.store.with两个辅助内部实现的类用在实现 Directory方法的makeLock的时候,以在锁定索引读写之前来让客户程序做一些准备工作。
(FSDirectory, FSInputStream,FSOutputStream)的内部实现依托于java语言中的io类库,只是简单的做了一个外部逻辑的包装。这当然要归功于java语言所提供的跨平台特性,同时也带了一些隐患:文件存取的效率提升需要依耐于文件类库的优化。如果需要继续优化文件存取的效率,应该还提供一个文件与目录的抽象,以根据各种文件系统或者文件类型来提供一个优化的机会。当然,这是应用开发者所不需要关系的问题。
(RAMDirectory,RAMInputStream和RAMOutputStream)的内部实现就比较直接了,直接采用了虚拟的文件 RAMFile类(定义于文件RAMDirectory.java中)来表示文件,目录则看作一个String与RAMFile对应的关联数组。 RAMFile中采用数组来表示文件的存储空间。在此的基础上,完成各项操作的实现,就形成了基于内存的虚拟文件系统。因为在实际使用时,并不会牵涉到很大字节数量的文件,因此这种设计是简单直接的,也是高效率的。
这部分的实现在理清楚继承体系后,相当的简单。因此接下来的部分,我们可以通过直接阅读源代码解决。接下来我们看看这个部分的源代码如何在实际中使用的。
一般来说,我们使用的是抽象类提供的接口而不是实际的实现类本身。在实现类中一般都含有几个静态函数,比如createFile,它能够返回一个 OutputStream接口,或者openFile,它能够返回一个InputStream接口,利用这些接口之中的方法,比如 writeString,writeByte等等,我们就能够在抽象的层次上处理Lucene定义的数据类型的读写。简单的说,Lucene中存储抽象这部分设计时采用了工厂模式(Factory parttern)[23]。我们利用静态类的方法也就是工厂来创建对象,返回接口,通过接口来执行操作。
五、关于cLucene项目
这一部分详细的说明了Lucene系统中所采用的索引文件格式、一些基础类和存储抽象。接下来我们来叙述一下我们在项目cLucene中重新实现这些结构时候的一些考虑。
cLucene彻底的遵守了Lucene所定义的索引文件格式,这是Lucene对于各个兼容系统的基本要求。在此基础上,cLucene系统和Lucene系统才能够共享索引文件数据。或者说,cLucene生成的索引文件和Lucene生成的索引文件完全等价。
在基础类问题上,cLucene同样封装了类似的结构。我们同样列表描述,请和前面的表3.2与3.3对照比较。
表 3.4 基础类包cLucene::util
| 类 |
说明 |
| Arrays |
没有实现,直接利用了STL库中的快排序算法实现 |
| BitVector |
C/C++语言版本的实现,与java实现版本类似 |
| Constants |
常量静态类,定义了一些常量,但是与java版本不同的是,这里主要定义了一些宏 |
| PriorityQueue |
这是一个类型定义,直接利用STL库中的std::priority_queue |
表 3.3 基础类包cLucene::document
| 类 |
说明 |
| Document |
C/C++语言版本的实现,与java实现版本类似 |
| Field |
C/C++语言版本的实现,与java实现版本类似 |
| DateField |
没有实现,直接利用OpenTop库中的ot::StringUtil |
存储抽象的实现上,也同样是类似于java实现。由于我们采用了OpenTop库,因此同样得以借助其中对于文件系统抽象的ot::io包来解决文件系统问题。这部分问题与前面一样,存在优化的可能。在实现的类层次上、对外接口上,均与java版本的一样。
作者
Winter
一切复杂的排序操作,都可以通过STL方便实现 !
0 前言: STL,为什么你必须掌握
对于程序员来说,数据结构是必修的一门课。从查找到排序,从链表到二叉树,几乎所有的算法和原理都需要理解,理解不了也要死记硬背下来。幸运的是这些理论都已经比较成熟,算法也基本固定下来,不需要你再去花费心思去考虑其算法原理,也不用再去验证其准确性。不过,等你开始应用计算机语言来工作的时候,你会发现,面对不同的需求你需要一次又一次去用代码重复实现这些已经成熟的算法,而且会一次又一次陷入一些由于自己疏忽而产生的bug中。这时,你想找一种工具,已经帮你实现这些功能,你想怎么用就怎么用,同时不影响性能。你需要的就是STL, 标准模板库!
西方有句谚语:不要重复发明轮子!
STL几乎封装了所有的数据结构中的算法,从链表到队列,从向量到堆栈,对hash到二叉树,从搜索到排序,从增加到删除......可以说,如果你理解了STL,你会发现你已不用拘泥于算法本身,从而站在巨人的肩膀上去考虑更高级的应用。
排序是最广泛的算法之一,本文详细介绍了STL中不同排序算法的用法和区别。
1 STL提供的Sort 算法
C++之所以得到这么多人的喜欢,是因为它既具有面向对象的概念,又保持了C语言高效的特点。STL 排序算法同样需要保持高效。因此,对于不同的需求,STL提供的不同的函数,不同的函数,实现的算法又不尽相同。
1.1 所有sort算法介绍
所有的sort算法的参数都需要输入一个范围,[begin, end)。这里使用的迭代器(iterator)都需是随机迭代器(RadomAccessIterator), 也就是说可以随机访问的迭代器,如:it+n什么的。(partition 和stable_partition 除外)
如果你需要自己定义比较函数,你可以把你定义好的仿函数(functor)作为参数传入。每种算法都支持传入比较函数。以下是所有STL sort算法函数的名字列表:
| 函数名 |
功能描述 |
| sort |
对给定区间所有元素进行排序 |
| stable_sort |
对给定区间所有元素进行稳定排序 |
| partial_sort |
对给定区间所有元素部分排序 |
| partial_sort_copy |
对给定区间复制并排序 |
| nth_element |
找出给定区间的某个位置对应的元素 |
| is_sorted |
判断一个区间是否已经排好序 |
| partition |
使得符合某个条件的元素放在前面 |
| stable_partition |
相对稳定的使得符合某个条件的元素放在前面 |
其中nth_element 是最不易理解的,实际上,这个函数是用来找出第几个。例如:找出包含7个元素的数组中排在中间那个数的值,此时,我可能不关心前面,也不关心后面,我只关心排在第四位的元素值是多少。
1.2 sort 中的比较函数
当你需要按照某种特定方式进行排序时,你需要给sort指定比较函数,否则程序会自动提供给你一个比较函数。
vector < int > vect;
//...
sort(vect.begin(), vect.end());
//此时相当于调用
sort(vect.begin(), vect.end(), less<int>() );
上述例子中系统自己为sort提供了less仿函数。在STL中还提供了其他仿函数,以下是仿函数列表:
| 名称 |
功能描述 |
| equal_to |
相等 |
| not_equal_to |
不相等 |
| less |
小于 |
| greater |
大于 |
| less_equal |
小于等于 |
| greater_equal |
大于等于 |
需要注意的是,这些函数不是都能适用于你的sort算法,如何选择,决定于你的应用。另外,不能直接写入仿函数的名字,而是要写其重载的()函数:
less<int>()
greater<int>()
当你的容器中元素时一些标准类型(int float char)或者string时,你可以直接使用这些函数模板。但如果你时自己定义的类型或者你需要按照其他方式排序,你可以有两种方法来达到效果:一种是自己写比较函数。另一种是重载类型的'<'操作赋。
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
class myclass {
public:
myclass(int a, int b):first(a), second(b){}
int first;
int second;
bool operator < (const myclass &m)const {
return first < m.first;
}
};
bool less_second(const myclass & m1, const myclass & m2) {
return m1.second < m2.second;
}
int main() {
vector< myclass > vect;
for(int i = 0 ; i < 10 ; i ++){
myclass my(10-i, i*3);
vect.push_back(my);
}
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
sort(vect.begin(), vect.end());
cout<<"after sorted by first:"<<endl;
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
cout<<"after sorted by second:"<<endl;
sort(vect.begin(), vect.end(), less_second);
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
return 0 ;
}
知道其输出结果是什么了吧:
(10,0)
(9,3)
(8,6)
(7,9)
(6,12)
(5,15)
(4,18)
(3,21)
(2,24)
(1,27)
after sorted by first:
(1,27)
(2,24)
(3,21)
(4,18)
(5,15)
(6,12)
(7,9)
(8,6)
(9,3)
(10,0)
after sorted by second:
(10,0)
(9,3)
(8,6)
(7,9)
(6,12)
(5,15)
(4,18)
(3,21)
(2,24)
(1,27)
1.3 sort 的稳定性
你发现有sort和stable_sort,还有 partition 和stable_partition, 感到奇怪吧。其中的区别是,带有stable的函数可保证相等元素的原本相对次序在排序后保持不变。或许你会问,既然相等,你还管他相对位置呢,也分不清楚谁是谁了?这里需要弄清楚一个问题,这里的相等,是指你提供的函数表示两个元素相等,并不一定是一摸一样的元素。
例如,如果你写一个比较函数:
bool less_len(const string &str1, const string &str2)
{
return str1.length() < str2.length();
}
此时,"apple" 和 "winter" 就是相等的,如果在"apple" 出现在"winter"前面,用带stable的函数排序后,他们的次序一定不变,如果你使用的是不带"stable"的函数排序,那么排序完后,"Winter"有可能在"apple"的前面。
1.4 全排序
全排序即把所给定范围所有的元素按照大小关系顺序排列。用于全排序的函数有
template <class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void sort(RandomAccessIterator first, RandomAccessIterator last,
StrictWeakOrdering comp);
template <class RandomAccessIterator>
void stable_sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void stable_sort(RandomAccessIterator first, RandomAccessIterator last,
StrictWeakOrdering comp);
在第1,3种形式中,sort 和 stable_sort都没有指定比较函数,系统会默认使用operator< 对区间[first,last)内的所有元素进行排序, 因此,如果你使用的类型义军已经重载了operator<函数,那么你可以省心了。第2, 4种形式,你可以随意指定比较函数,应用更为灵活一些。来看看实际应用:
班上有10个学生,我想知道他们的成绩排名。
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <string>
using namespace std;
class student{
public:
student(const string &a, int b):name(a), score(b){}
string name;
int score;
bool operator < (const student &m)const {
return score< m.score;
}
};
int main() {
vector< student> vect;
student st1("Tom", 74);
vect.push_back(st1);
st1.name="Jimy";
st1.score=56;
vect.push_back(st1);
st1.name="Mary";
st1.score=92;
vect.push_back(st1);
st1.name="Jessy";
st1.score=85;
vect.push_back(st1);
st1.name="Jone";
st1.score=56;
vect.push_back(st1);
st1.name="Bush";
st1.score=52;
vect.push_back(st1);
st1.name="Winter";
st1.score=77;
vect.push_back(st1);
st1.name="Andyer";
st1.score=63;
vect.push_back(st1);
st1.name="Lily";
st1.score=76;
vect.push_back(st1);
st1.name="Maryia";
st1.score=89;
vect.push_back(st1);
cout<<"------before sort..."<<endl;
for(int i = 0 ; i < vect.size(); i ++) cout<<vect[i].name<<":\t"<<vect[i].score<<endl;
stable_sort(vect.begin(), vect.end(),less<student>());
cout <<"-----after sort ...."<<endl;
for(int i = 0 ; i < vect.size(); i ++) cout<<vect[i].name<<":\t"<<vect[i].score<<endl;
return 0 ;
}
其输出是:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Bush: 52
Jimy: 56
Jone: 56
Andyer: 63
Tom: 74
Lily: 76
Winter: 77
Jessy: 85
Maryia: 89
Mary: 92
sort采用的是成熟的"快速排序算法"(目前大部分STL版本已经不是采用简单的快速排序,而是结合内插排序算法)。
注1,可以保证很好的平均性能、复杂度为n*log(n),由于单纯的快速排序在理论上有最差的情况,性能很低,其算法复杂度为n*n,但目前大部分的STL版本都已经在这方面做了优化,因此你可以放心使用。stable_sort采用的是"归并排序",分派足够内存是,其算法复杂度为n*log(n), 否则其复杂度为n*log(n)*log(n),其优点是会保持相等元素之间的相对位置在排序前后保持一致。
1.5 局部排序
局部排序其实是为了减少不必要的操作而提供的排序方式。其函数原型为:
template <class RandomAccessIterator>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
StrictWeakOrdering comp);
template <class InputIterator, class RandomAccessIterator>
RandomAccessIterator partial_sort_copy(InputIterator first, InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last);
template <class InputIterator, class RandomAccessIterator,
class StrictWeakOrdering>
RandomAccessIterator partial_sort_copy(InputIterator first, InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last, Compare comp);
理解了sort 和stable_sort后,再来理解partial_sort 就比较容易了。先看看其用途: 班上有10个学生,我想知道分数最低的5名是哪些人。如果没有partial_sort,你就需要用sort把所有人排好序,然后再取前5个。现在你只需要对分数最低5名排序,把上面的程序做如下修改:
stable_sort(vect.begin(), vect.end(),less<student>());
替换为:
partial_sort(vect.begin(), vect.begin()+5, vect.end(),less<student>());
输出结果为:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Bush: 52
Jimy: 56
Jone: 56
Andyer: 63
Tom: 74
Mary: 92
Jessy: 85
Winter: 77
Lily: 76
Maryia: 89
这样的好处知道了吗?当数据量小的时候可能看不出优势,如果是100万学生,我想找分数最少的5个人......
partial_sort采用的堆排序(heapsort),它在任何情况下的复杂度都是n*log(n). 如果你希望用partial_sort来实现全排序,你只要让middle=last就可以了。
partial_sort_copy其实是copy和partial_sort的组合。被排序(被复制)的数量是[first, last)和[result_first, result_last)中区间较小的那个。如果[result_first, result_last)区间大于[first, last)区间,那么partial_sort相当于copy和sort的组合。
1.6 nth_element 指定元素排序
nth_element一个容易看懂但解释比较麻烦的排序。用例子说会更方便:
班上有10个学生,我想知道分数排在倒数第4名的学生。
如果要满足上述需求,可以用sort排好序,然后取第4位(因为是由小到大排), 更聪明的朋友会用partial_sort, 只排前4位,然后得到第4位。其实这是你还是浪费,因为前两位你根本没有必要排序,此时,你就需要nth_element:
template <class RandomAccessIterator>
void nth_element(RandomAccessIterator first, RandomAccessIterator nth,
RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void nth_element(RandomAccessIterator first, RandomAccessIterator nth,
RandomAccessIterator last, StrictWeakOrdering comp);
对于上述实例需求,你只需要按下面要求修改1.4中的程序:
stable_sort(vect.begin(), vect.end(),less<student>());
替换为:
nth_element(vect.begin(), vect.begin()+3, vect.end(),less<student>());
运行结果为:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Jone: 56
Bush: 52
Jimy: 56
Andyer: 63
Jessy: 85
Mary: 92
Winter: 77
Tom: 74
Lily: 76
Maryia: 89
第四个是谁?Andyer,这个倒霉的家伙。为什么是begin()+3而不是+4? 我开始写这篇文章的时候也没有在意,后来在
ilovevc 的提醒下,发现了这个问题。begin()是第一个,begin()+1是第二个,... begin()+3当然就是第四个了。
1.7 partition 和stable_partition
好像这两个函数并不是用来排序的,'分类'算法,会更加贴切一些。partition就是把一个区间中的元素按照某个条件分成两类。其函数原型为:
template <class ForwardIterator, class Predicate>
ForwardIterator partition(ForwardIterator first,
ForwardIterator last, Predicate pred)
template <class ForwardIterator, class Predicate>
ForwardIterator stable_partition(ForwardIterator first, ForwardIterator last,
Predicate pred);
看看应用吧:班上10个学生,计算所有没有及格(低于60分)的学生。你只需要按照下面格式替换1.4中的程序:
stable_sort(vect.begin(), vect.end(),less<student>());
替换为:
student exam("pass", 60);
stable_partition(vect.begin(), vect.end(), bind2nd(less<student>(), exam));
其输出结果为:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Jimy: 56
Jone: 56
Bush: 52
Tom: 74
Mary: 92
Jessy: 85
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
看见了吗,Jimy,Jone, Bush(难怪说美国总统比较笨

)都没有及格。而且使用的是stable_partition, 元素之间的相对次序是没有变.
2 Sort 和容器
STL中标准容器主要vector, list, deque, string, set, multiset, map, multimay, 其中set, multiset, map, multimap都是以树结构的方式存储其元素详细内容请参看:
学习STL map, STL set之数据结构基础. 因此在这些容器中,元素一直是有序的。
这些容器的迭代器类型并不是随机型迭代器,因此,上述的那些排序函数,对于这些容器是不可用的。上述sort函数对于下列容器是可用的:
如果你自己定义的容器也支持随机型迭代器,那么使用排序算法是没有任何问题的。
对于list容器,list自带一个sort成员函数list::sort(). 它和算法函数中的sort差不多,但是list::sort是基于指针的方式排序,也就是说,所有的数据移动和比较都是此用指针的方式实现,因此排序后的迭代器一直保持有效(vector中sort后的迭代器会失效).
3 选择合适的排序函数
为什么要选择合适的排序函数?可能你并不关心效率(这里的效率指的是程序运行时间), 或者说你的数据量很小, 因此你觉得随便用哪个函数都无关紧要。
其实不然,即使你不关心效率,如果你选择合适的排序函数,你会让你的代码更容易让人明白,你会让你的代码更有扩充性,逐渐养成一个良好的习惯,很重要吧 。
如果你以前有用过C语言中的qsort, 想知道qsort和他们的比较,那我告诉你,qsort和sort是一样的,因为他们采用的都是快速排序。从效率上看,以下几种sort算法的是一个排序,效率由高到低(耗时由小变大):
- partion
- stable_partition
- nth_element
- partial_sort
- sort
- stable_sort
记得,以前翻译过Effective STL的文章,其中对
如何选择排序函数总结的很好:
- 若需对vector, string, deque, 或 array容器进行全排序,你可选择sort或stable_sort;
- 若只需对vector, string, deque, 或 array容器中取得top n的元素,部分排序partial_sort是首选.
- 若对于vector, string, deque, 或array容器,你需要找到第n个位置的元素或者你需要得到top n且不关系top n中的内部顺序,nth_element是最理想的;
- 若你需要从标准序列容器或者array中把满足某个条件或者不满足某个条件的元素分开,你最好使用partition或stable_partition;
- 若使用的list容器,你可以直接使用partition和stable_partition算法,你可以使用list::sort代替sort和stable_sort排序。若你需要得到partial_sort或nth_element的排序效果,你必须间接使用。正如上面介绍的有几种方式可以选择。
总之记住一句话:
如果你想节约时间,不要走弯路, 也不要走多余的路!
4 小结
讨论技术就像个无底洞,经常容易由一点可以引申另外无数个技术点。因此需要从全局的角度来观察问题,就像观察STL中的sort算法一样。其实在STL还有make_heap, sort_heap等排序算法。本文章没有提到。本文以实例的方式,解释了STL中排序算法的特性,并总结了在实际情况下应如何选择合适的算法。
5 参考文档
条款31:如何选择排序函数 The Standard Librarian: Sorting in the Standard Library Effective STL中文版 Standard Template Library Programmer's Guide